Blog / 阅读
本人C++新手,搞正则搞了一天。。试了各种方法。C 的正则 C++正则 boost正则。 真是头都大了。
匹配中文内容一直乱码,最后功夫不负有心人,让我整理出来了方法。这里写出来给大家分享。
高手勿喷。
std::string getvalue(char *regstr,char *str)
{}
//将单字节char*转化为宽字节wchar_t*
wchar_t* AnsiToUnicode( const char* szStr )
{
int nLen = MultiByteToWideChar( CP_ACP, MB_PRECOMPOSED, szStr, -1, NULL, 0 );
if (nLen == 0)
{
return NULL;
}
wchar_t* pResult = new wchar_t[nLen];
MultiByteToWideChar( CP_ACP, MB_PRECOMPOSED, szStr, -1, pResult, nLen );
return pResult;
}
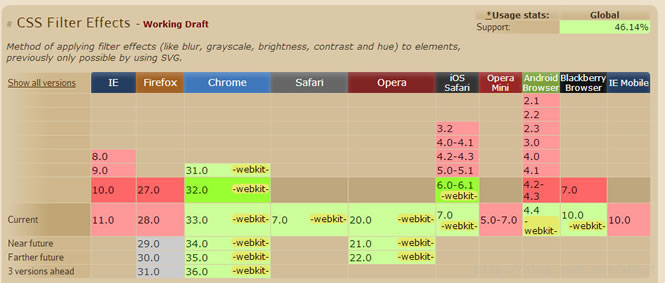
526互联致力于最新开发技术,为您的网站或软件提供最新最优质的的服务是我们应尽的责任。



 地址: 郑州花园路86号
地址: 郑州花园路86号
评论