巅峰极客 WriteUp
m1_read
白盒 AES,其他师傅也写的比较清楚了。我当时用的 Frida
var baseAddr = Module.findBaseAddress("m1_read.exe");
var whiteAES = new NativeFunction(baseAddr.add(0x4BF0), 'pointer', ['pointer', 'pointer'])
var count = 9;
Interceptor.attach(baseAddr.add(0x4C2C), {
onEnter: function(args) {
count++;
if(count == 9) {
this.context.rdi.add(Math.floor(Math.random() * 16)).writeU8(Math.floor(Math.random() * 256))
}
},
onLeave: (retval) => {
}
})
for (let index = 0; index < 33; index++) {
var l = Memory.allocAnsiString("1234567890abcdef");
var b = Memory.alloc(16);
whiteAES(l, b);
console.log(b.readByteArray(16));
count = 0;
}
把拿到的结果 xor 一下
str_table = ["ca429fdc6bfa9b5e540c8f14b03bae88", "ca429f436bfa575e541f8f14f73bae88", "ca709fdc77fa9b5e540c8faab03bc288",
"ca1d9fdc24fa9b5e540c8f53b03b6388", "ca4231dc6bdd9b5ece0c8f14b03bae1f", "34429fdc6bfa9b2a540c4c14b025ae88",
"ca4260dc6bfd9b5eb30c8f14b03baecb", "ca889fdc5dfa9b5e540c8f95b03b1e88", "d2429fdc6bfa9bba540c3314b03dae88",
"fd429fdc6bfa9b72540ca814b048ae88", "ca429f6e6bfa355e54a18f14c23bae88", "ca42c6dc6b349b5e450c8f14b03bae15",
"ca449fdc39fa9b5e540c8f26b03bbb88", "ca42fcdc6b3e9b5e7d0c8f14b03baecd", "ca429bdc6bb49b5eab0c8f14b03bae6c",
"ca429fb46bface5e54798f14213bae88", "ca429f2d6bfa805e547b8f140c3bae88"]
for s in str_table:
val = bytearray(bytes.fromhex(s))
for i in range(16):
val[i] ^= 0x66
print(val.hex())
DFA 攻击白盒AES的最后一轮密钥
import phoenixAES
with open('tracefile', 'wb') as t:
t.write("""
ac24f9ba0d9cfd38326ae972d65dc8ee
ac24f9250d9c31383279e972915dc8ee
ac16f9ba119cfd38326ae9ccd65da4ee
ac7bf9ba429cfd38326ae935d65d05ee
ac2457ba0dbbfd38a86ae972d65dc879
5224f9ba0d9cfd4c326a2a72d643c8ee
ac2406ba0d9bfd38d56ae972d65dc8ad
aceef9ba3b9cfd38326ae9f3d65d78ee
b424f9ba0d9cfddc326a5572d65bc8ee
9b24f9ba0d9cfd14326ace72d62ec8ee
ac24f9080d9c533832c7e972a45dc8ee
ac24a0ba0d52fd38236ae972d65dc873
ac22f9ba5f9cfd38326ae940d65dddee
ac249aba0d58fd381b6ae972d65dc8ab
ac24fdba0dd2fd38cd6ae972d65dc80a
ac24f9d20d9ca838321fe972475dc8ee
ac24f94b0d9ce638321de9726a5dc8ee
ac24f94b0d9ce638321de9726a5dc8ee
""".encode('utf8'))
phoenixAES.crack_file('tracefile')
使用 https://github.com/SideChannelMarvels/Stark 工具求得第一轮密钥为 00000000000000000000000000000000
求解脚本:
from Crypto.Cipher import AES
key = bytes.fromhex('00000000000000000000000000000000')
cipher = AES.new(key, AES.MODE_ECB)
final = bytes.fromhex('0B987EF5D94DD679592C4D2FADD4EB89')
final = bytearray(final)
for i in range(16):
final[i] ^= 0x66
flag = cipher.decrypt(final)
print(flag)
g0Re
不想废话,直接脚本吧
import base64
import struct
from Crypto.Cipher import AES
v28 = [0] * 8
v28[0] = 0xC9F5C5CFC889CEE6
v28[1] = 0xCCAC7FCE91C0D9D2
v28[2] = 0x92EAD496C0B7CFE9
v28[3] = 0x93AEA5CB84DFD7E2
v28[4] = 0xC9F0CEDF97BECAA6
v28[5] = 0xDB65B1C46BAEE1B7
v28[6] = 0xC3ED8CD69392EDCE
v28[7] = 0xA7B5B2AAA594DAA3
target = struct.pack("<8Q", v28[0], v28[1], v28[2], v28[3], v28[4], v28[5], v28[6], v28[7])
my_b64_table = '456789}#IJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123ABCDEFGH'
std_b64_table = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
key = b'wvgitbygwbk2b46d'
target = bytearray(target)
for i in range(len(target)):
target[i] = target[i] - key[i % 16]
target[i] ^= 0x1a
f = ''.join(chr(_) for _ in target)
m = str.maketrans(my_b64_table, std_b64_table)
f = f.translate(m)
f = base64.b64decode(f)
cipher = AES.new(key, mode=AES.MODE_ECB)
flag = cipher.decrypt(f)
print(flag)
ezlua
等了两天没看到有师傅发预期解法,只能自己动手了。
主程序东西不多,都在 main 函数了,主要就是把输入(40位hex 字符串),20位一组进行 hex 解码分别设置到要执行的 luajit 二进制代码中两处位置(中间隔着一个03,先剧透一下这是有用的)
第一步,我们要先判断输入的内容的作用,这里直接对输入内容下内存断点,看看会断到哪。
主程序调用 luaL_loadbuffer后,断到了下图所示位置
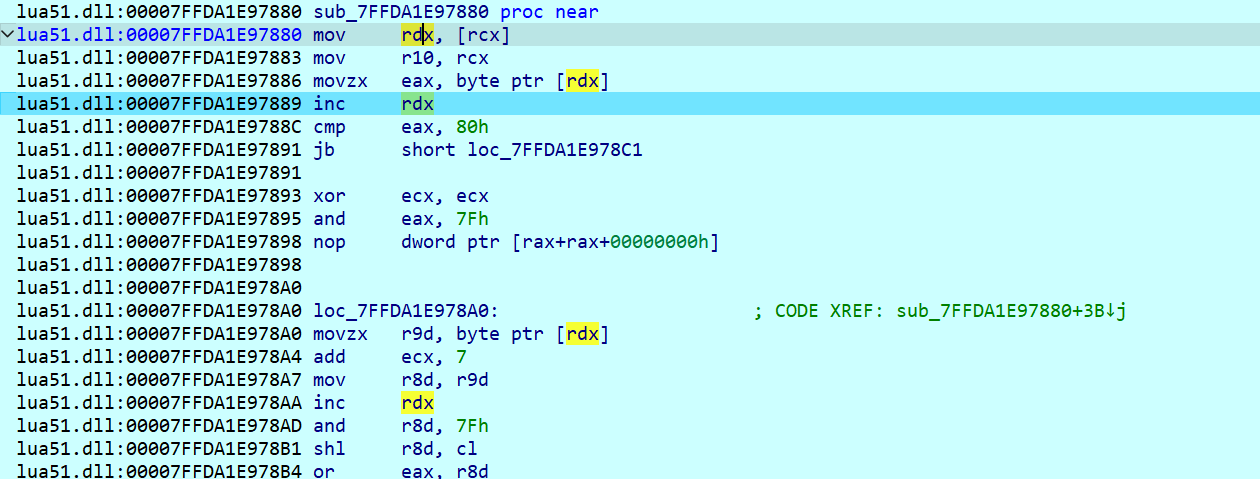
f5 一下,可以看出来这个函数是对 uleb128格式数据的解码
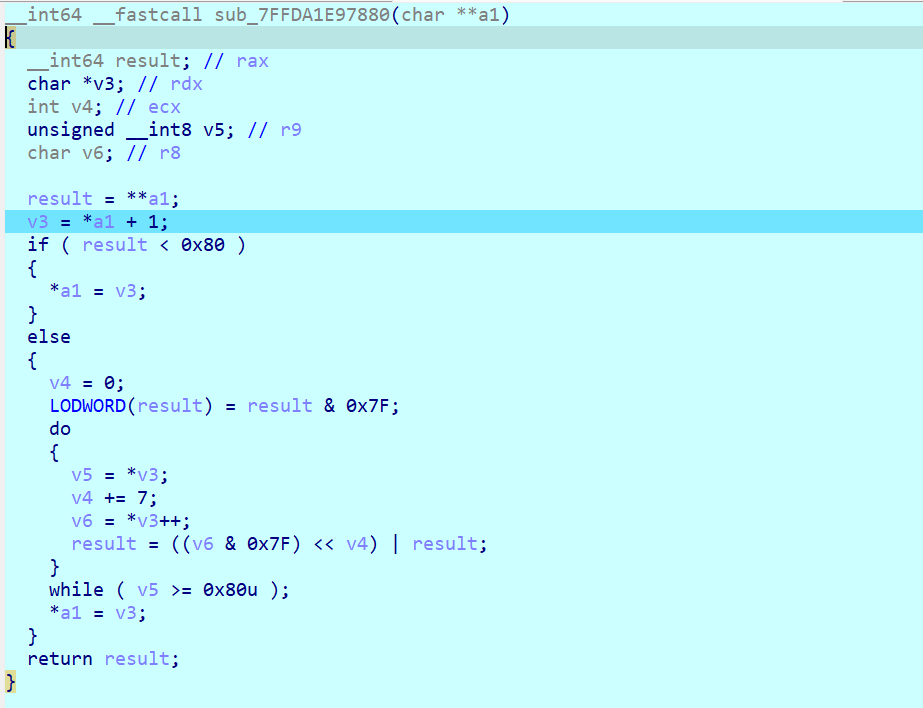
对照 luajit的源码搜索 uleb128后发现是函数 lj_buf_ruleb128
继续跟,来到上层函数 sub_7FFDA1E95EC0,在下面的一处 lj_buf_ruleb128中又读取了输入。

通过对 luaL_loadbuffer 源码的分析,发现这个函数是 bcread_kgc 函数(就是读取常量的一部分),代码如下:
/* Read GC constants of a prototype. */
static void bcread_kgc(LexState *ls, GCproto *pt, MSize sizekgc)
{
MSize i;
GCRef *kr = mref(pt->k, GCRef) - (ptrdiff_t)sizekgc;
for (i = 0; i < sizekgc; i++, kr++)
{
MSize tp = bcread_uleb128(ls); // 读取数据类型
... // 此处省略一堆无关代码
else if (tp != BCDUMP_KGC_CHILD)
{
CTypeID id = tp == BCDUMP_KGC_COMPLEX ? CTID_COMPLEX_DOUBLE : tp == BCDUMP_KGC_I64 ? CTID_INT64
: CTID_UINT64;
CTSize sz = tp == BCDUMP_KGC_COMPLEX ? 16 : 8;
GCcdata *cd = lj_cdata_new_(ls->L, id, sz);
TValue *p = (TValue *)cdataptr(cd);
setgcref(*kr, obj2gco(cd));
p[0].u32.lo = bcread_uleb128(ls); // 读取一个uint32
p[0].u32.hi = bcread_uleb128(ls); // 读取一个uint32
if (tp == BCDUMP_KGC_COMPLEX)
{
p[1].u32.lo = bcread_uleb128(ls);
p[1].u32.hi = bcread_uleb128(ls);
}
... // 此处省略一堆无关代码
}
else
{
... // 此处省略一堆无关代码
}
}
}
根据调试结果,发现输入的数据其实是两个 u64 类型的数字使用 uleb128 编码成 4 个 32bit 的值。判断依据是 tp的值均为 3(这就是为啥前面中间要隔一个 03)

到现在就知道了,输入的内容其实是两个 u64 类型的常量,也被存放在了 luajit文件的常量部分。
而且这两个常量的高32bit和低32bit被编码为
uleb128后长度都必须是5个字节,也就是前4个字节大于等于 0x80,第五个字节小于 0x80,否则就会解析失败报错
下面就是反汇编或者反编译了。经过可靠的对比,题目中附带的 dll 并没有改变 luajit 的 opcode 顺序,只是添加了一个导出函数
luaL_checkcdata,这个应该是作者基于 https://github.com/tarantool/tarantool/blob/03db58fb05baebeea22f8d764559d4b950ab6514/src/lua/utils.c#L278 这个代码改了一下加的,用于获取 lua 中的值到 C 语言,对反汇编没啥作用
验证是否修改 opcode 顺序的时候,可以对开源的版本加这个函数,编译出 dll 和题目附带的 dll 执行效果一样,说明没有改变
luajit的 opcode 顺序。
反编译阶段,我先是用 https://github.com/bobsayshilol/luajit-decomp/tree/deprecated 工具拿到了,反汇编的结果(这个工具也反编译出来了两个版本的 lua 文件,但是反编译的一塌糊涂可以说不堪入目,而且经过后面对 luajit 指令执行代码的调试,发现其中的 CALL 指令参数全识别错了,估计按老版本的吧,但是还好反汇编结果是对的)

根据反汇编结果,对 luajit的 vm 进行调试
如何找每个指令对应的处理函数?
参考 in1t ✌ 的博客 https://in1t.top/2023/04/02/7th-xctf-final-super-flagio/
在 lua51.dll 的 0x7FFD9E6F3034(基地址 0x7FFD9E6F0000)处下断点,执行我这里提供的脚本即可为所有分支设置 Name
from idaapi import *
ins = ("ISLT", "ISGE", "ISLE", "ISGT", "ISEQV", "ISNEV", "ISEQS", "ISNES", "ISEQN", "ISNEN", "ISEQP", "ISNEP", "ISTC", "ISFC",
"IST", "ISF", "ISTYPE", "ISNUM", "MOV", "NOT", "UNM", "LEN", "ADDVN", "SUBVN", "MULVN", "DIVVN", "MODVN", "ADDNV",
"SUBNV", "MULNV", "DIVNV", "MODNV", "ADDVV", "SUBVV", "MULVV", "DIVVV", "MODVV", "POW", "CAT", "KSTR", "KCDATA",
"KSHORT", "KNUM", "KPRI", "KNIL", "UGET", "USETV", "USETS", "USETN", "USETP", "UCLO", "FNEW", "TNEW", "TDUP", "GGET",
"GSET", "TGETV", "TGETS", "TGETB", "TGETR", "TSETV", "TSETS", "TSETB", "TSETM", "TSETR", "CALLM", "CALL", "CALLMT",
"CALLT", "ITERC", "ITERN", "VARG", "ISNEXT", "RETM", "RET", "RET0", "RET1", "FORI", "JFORI", "FORL", "IFORL", "JFORL",
"ITERL", "IITERL", "JITERL", "LOOP", "ILOOP", "JLOOP", "JMP", "FUNCF", "IFUNCF", "JFUNCF", "FUNCV", "IFUNCV", "JFUNCV",
"FUNCC", "FUNCCW")
base_addr = get_reg_val('rbx')
ins_len = len(ins)
for i in range(ins_len):
addr = base_addr + 8 * i
create_qword(addr, 8)
set_name(get_qword(addr), ins[i])
根据反汇编结果在 KCDATA 处下断点,发现第一个 KCDATA 加载的值是我们的输入的后半段 0x645F40745F4A3154,继续调试发现第二个 KCDATA 加载的值是我们的输入的前半段 0x755F72655F673030,第三个则是加载的一个常量 0xDEADBEEF12345678
调试 + 读汇编代码, 可以做,但是我看着那 4000 多行汇编代码,陷入了沉思....
反编译!必须反编译!听说这个项目 https://github.com/Dr-MTN/luajit-decompiler 好使,但是直接反编译报错了,
File "D:\TaskFile\CTF\luajit-decompiler\ljd\ast\slotworks.py", line 585, in leave_assignment
assert self._last_multres_value is None
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
调试后发现,出问题的代码是下面这个。
CALL 7 0 3 ; bit.lshift(9, 10)
他确实不太正常,第二个参数是 0,第二个参数正常是返回值个数 + 1,对于这个函数也就是说应该是 2
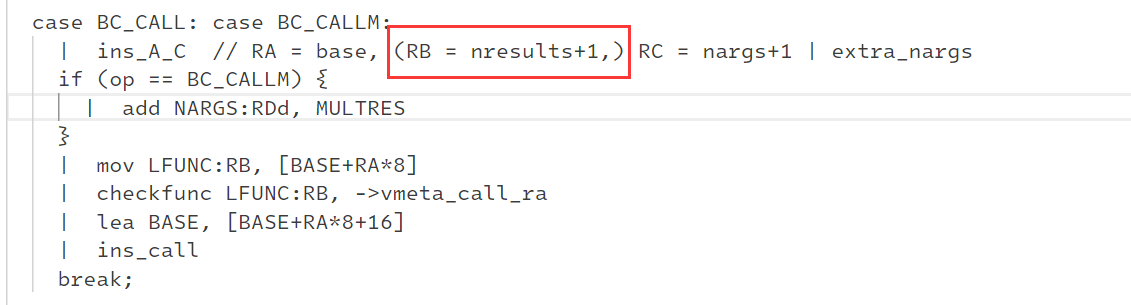
确实其他的大部分地方对于类似函数的调用都是 2,通过对虚拟机的调试,发现 2 和 0的效果好像一样,所以我让反编译器把它按2处理就是了!直接大力出奇迹!
结果啪一下的就出来了哈,很快哈,但是为啥一堆浮点数啊,我这是 u64 啊!
好好好,我继续改,发现这里有个转 double,我反手就是一个注释(对不对先不管,先爽了再说

啪的一下就好了,这次舒服了,运行一下?当场就得出了一个和原来的结果不一样的结果,然后发现是刚才爽过头了,应该是不支持 u64 ,但是无所谓逻辑没错就行(真没错吗?)
用 c 语言换 uint64 重写一遍,发现结果还是不对!这不是欺负老实人吗!还好我刚开始分析了一会汇编代码,发现是这个最长的操作,忽略了中间值。正确的写法应该是下面这样。
slot1 = bor(rshift(slot1, 8), lshift(slot1, 56));
slot1 = bxor(slot0 + slot1, slot2);
slot0 = bor(lshift(slot0, 3), rshift(slot0, 61));
slot0 = bxor(slot0, slot1);
终于,得到了预期的结果,反编译大业成功!!!!!!!!!
然后就是作者插入的一堆虚假控制流了,无所谓,操作只有一种只需要记录每次用的 slot2 运行一次即可获得正确的控制流顺序,然后根据结果逆序来一圈就行了。

反编译得到的完整代码太长了,就不贴了。
写个求解脚本
import leb128
def decrypt(_slot0, _slot1, _slot2):
_slot0 ^= _slot1
_slot0 = ((_slot0 >> 3) | (_slot0 << 61)) & 0xffffffffffffffff
slot1_and_slot0 = _slot1 ^ _slot2
_slot1 = slot1_and_slot0 - _slot0
_slot1 &= 0xffffffffffffffff
_slot1 = ((_slot1 >> 56) | (_slot1 << 8)) & 0xffffffffffffffff
return _slot0, _slot1
def u64_to_uleb128(u):
high = u >> 32
low = u & 0xffffffff
return leb128.u.encode(low).hex() + leb128.u.encode(high).hex()
slot2_array = [0xdeadbeef12345678, 0x28539dc5904d8141, 0xf2ac321ccf237a7b, 0xf03df21e866b1a36, 0x584cde754c325b4b, 0x97407269ac231f8b,
0xd2960ba60ee82d09, 0xb34efc0e8d197592, 0x15011adba4d8613d, 0x1598470b72677cea, 0xb497efc6db87c606, 0xae0f3ba8a4eeb218,
0xab6036ab64121254, 0x663ae5cc72c5eb7f, 0x71af0f7e9c371b0e, 0xeb97fc6b58f9eb33, 0x774108a83f7c75f6, 0x5a6542d5c9968681,
0x5e6fb973117ccfb1, 0xea8134ba653ce534, 0xfc92946aa1cc9678, 0x38af8cc9553071e4, 0x99f7a1b258084992, 0x82e920e890bb99da,
0xc67f72528ed05d6c, 0x4cab3a53d2598281, 0x517358620b3249f9, 0xcf3d41fd5e5e0786, 0x626be66ab995efe3, 0x24d85b01f54e2ab1,
0xe9cd3a65e3f95992, 0x4bf5996751882d17]
slot2_array.reverse()
slot0 = 0xdd26c29515a28396
slot1 = 0xbd722d4baf99b9c7
for slot2 in slot2_array:
slot0, slot1 = decrypt(slot0, slot1, slot2)
print(u64_to_uleb128(slot1) + u64_to_uleb128(slot0))