一 、CPU与GPU的异同
CPU:延迟导向内核,所谓延迟,指指令发出到得到结果中间经历的时间。
GPU:吞吐导向内核,所谓吞吐量指单位时间内处理的指令数量。其适合于计算密集或者数据并行的场合。
二、CUDA
2.1 简介
CUDA(Compute Unified Device Architecture)是由英伟达公司2007年开始推出,初衷是为GPU增加一个易用的编程接口,让开发者无需学习复杂的着色语言或者图形处理原语。
2.2 并行计算整体流程
void GPUkernel(float* A, float* B, float* C, int n)
{
Part1(开辟显存并将host中的数据拷贝到此处). //Allocate device memory for A, B, and C
//copy A and B to device memory
Part2(执行计算). //Kernel launch code – to have the device
//to perform the actual vector addition
Part3(将运算结果拷贝到host上并释放显存). //copy C from the device memory
//Free device vectors
}
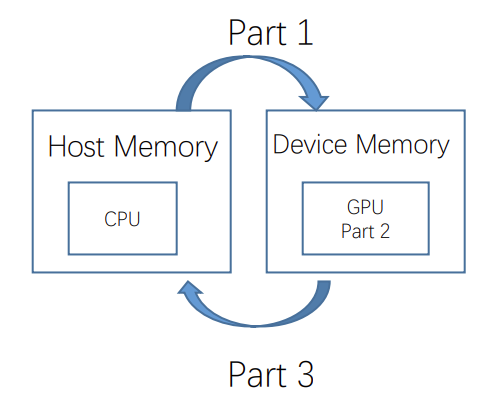
具体编程实现上有三种做法:
//1、 逐个文件编译 --->将与GPU相关的头文件放到.h或者.cuh中,将设备端(GPU上)执行的程序,即被__global__或者__device__修饰的核函数放到.cu文件中,然后使用NVCC编译,然后将主机端的程序放到.h与.cpp/.c中,继续使用gcc或者g++编译,最后分别使用ncvv和g++生成.o文件连接成可执行程序。
//2、使用nvcc将GPU的程序编译成.so,链接的时候只使用.so就可以。
//3、cmake的方式。
针对上述流程,还有如下几点需要说明
2.2.1 术语
Device=GPU
Host=CPU
Kernel=GPU上运行的函数
2.2.2 内存模型
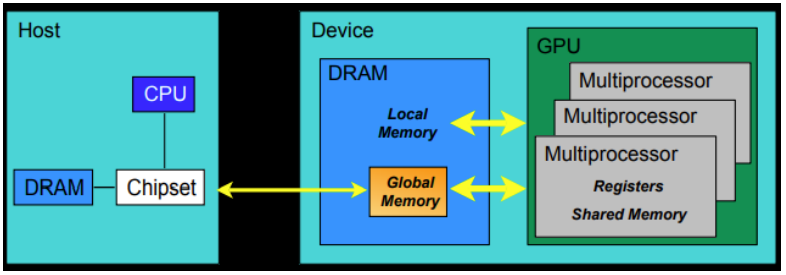
CPU和GPU之间通过内存和显存之间的互相拷贝来进行参数的传递,于是就引出了cuda编程中的内存模型。
硬件侧解释:
- 每个线程处理器(SP)都用自己的registers(寄存器)
- 每个SP都有自己的local memory(局部内存),register和local memory只能被线程自己访问
- 每个多核处理器(SM)内都有自己的shared memory(共享内存),shared memory 可以被线程块内所有线程访问
- 一个GPU的所有SM共有一块global memory(全局内存),不同线程块的线程都可使用
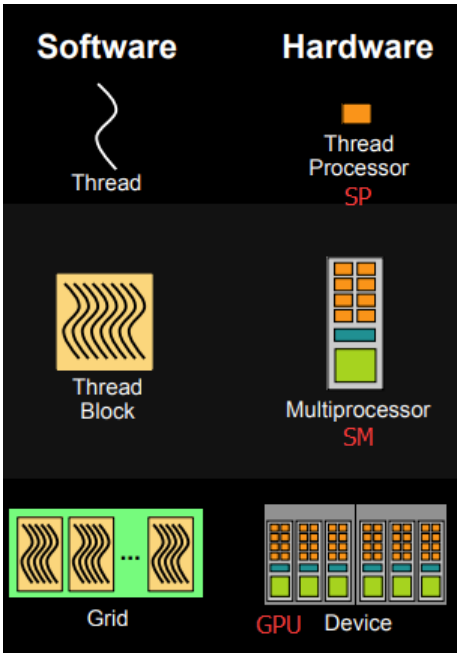
软件侧解释:
- 线程处理器(SP)对应线程(thread)
- 多核处理器(SM)对应线程块(thread block)
- 设备端(device)对应线程块组合体(grid)
- 一个kernel其实由一个grid来执行
- 一个kernel一次只能在一个GPU上执行
2.2.3 线程块id和线程id的概念
之前提到核函数是要在Device端进行计算和处理, 那么在执行核函数的过程中,需要访问到网格中(grid)每一个线程中的寄存器和独立的内存,继而需确定每一个线程在显存中的位置,从而引出了线程块id(1D、2D、3D)和线程id(1D、2D、3D)的概念。
2.2.4 线程束(wrap)的概念
SM采用的SIMT(Single-Instruction, Multiple-Thread,单指令多线程)架构,warp(线程束)是最基本的执行单元,一个 warp包含32个并行thread,这些thread以不同数据资源执行相同的指令。
其本质是线程在GPU上运行的最小单元,且由于wrap的大小为32,所以block所含的thread的大小一般要设置为32的倍数。