1.普通列表页面+内容页,这种通常url都带页码
1.1普通列表页+内容页需要登录访问的,按步骤123到页面第三步登录成功之后关闭页面回去详情页就能采集到了
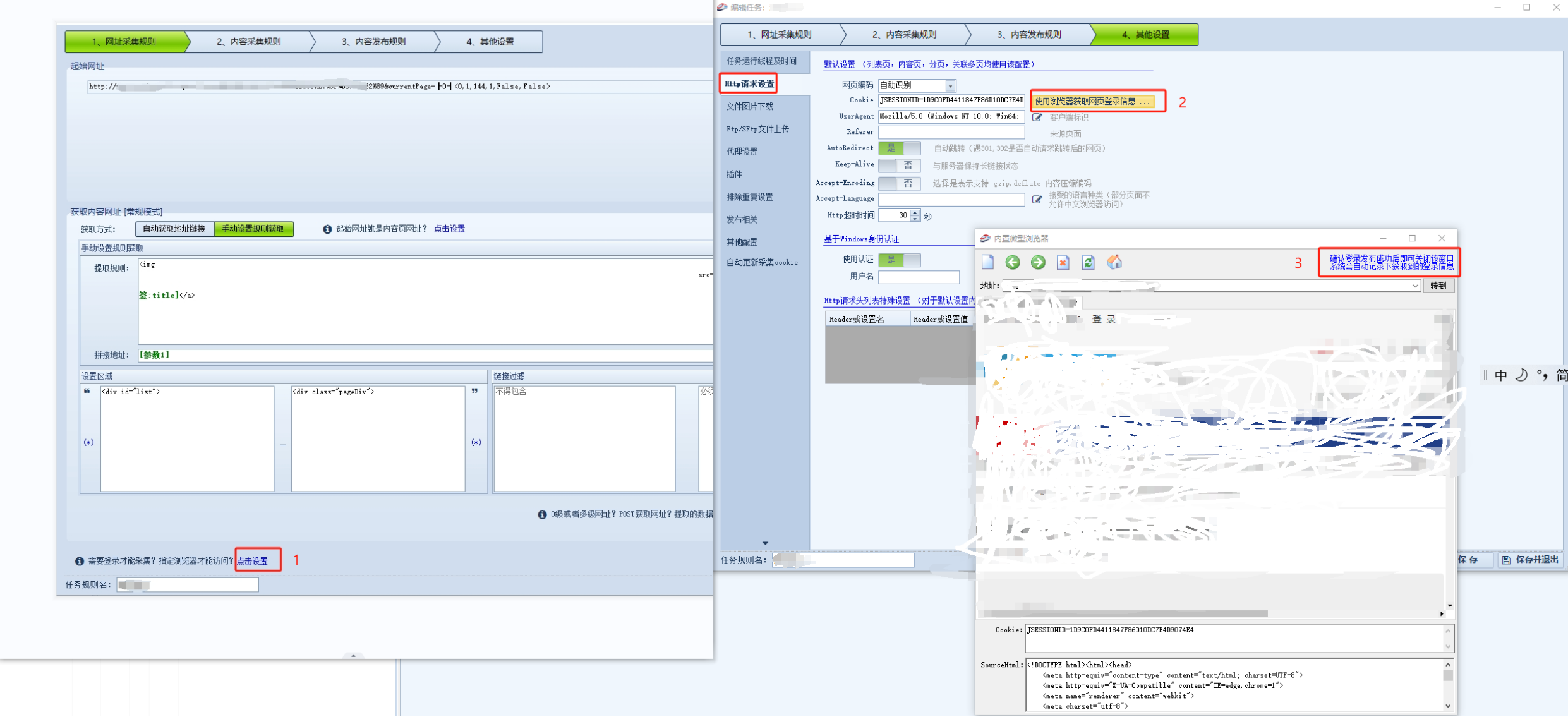
2.列表页数据是POST获取的,一般post路径中带分页码,这个可以通过F12开发者模式观察规律或者使用fiddler抓包工具分析请求的页面
2.2列表页面和内容页都是POST获取的,列表可以轻松通过POST方式获取,内容页没办法在用POST获取,这时候可以通过设置里面的插件进行内容二次处理,插件支持python或者php自定义代码的运行,需要懂一点相关代码
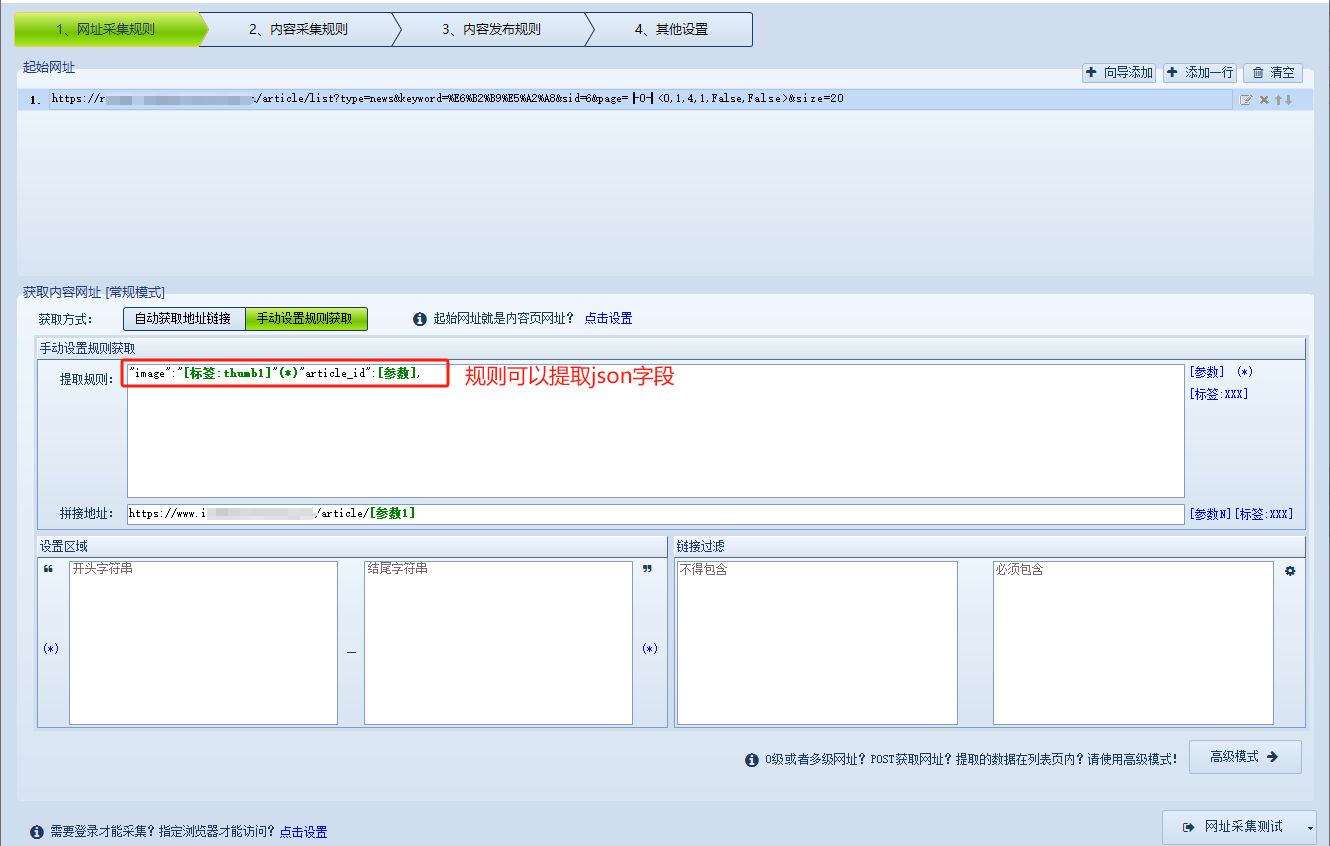
(上图)普通html页面抓取规则可以填写html标签,如果是post数据基本都是json格式这时候可以添加json字段作为抓取规则
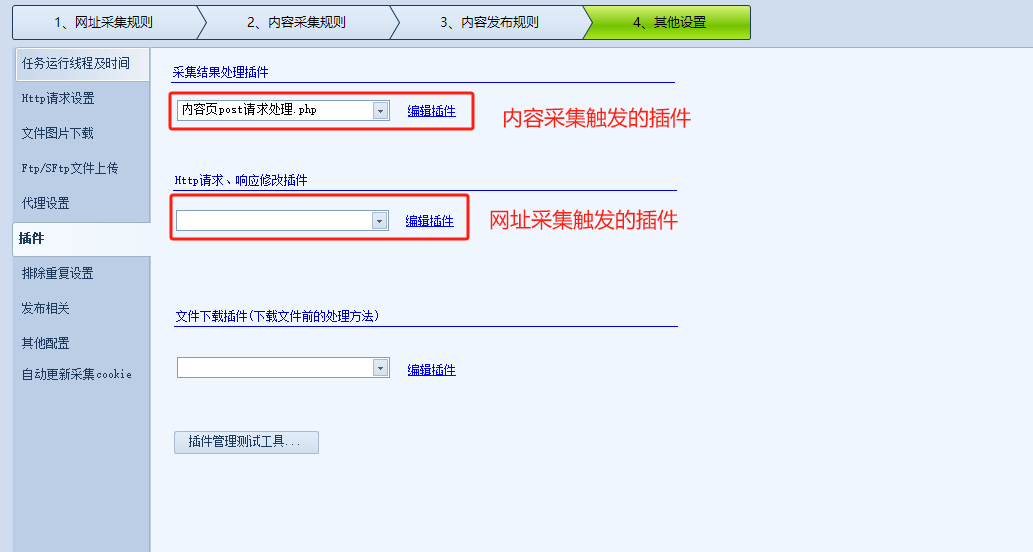
(上图)采集插件设置位置,设置之后在对于操作时自动触发
3.数据入库,采集器抓取完的数据保存在采集器中,可以同步到自定义数据库和web站点以及本地文件
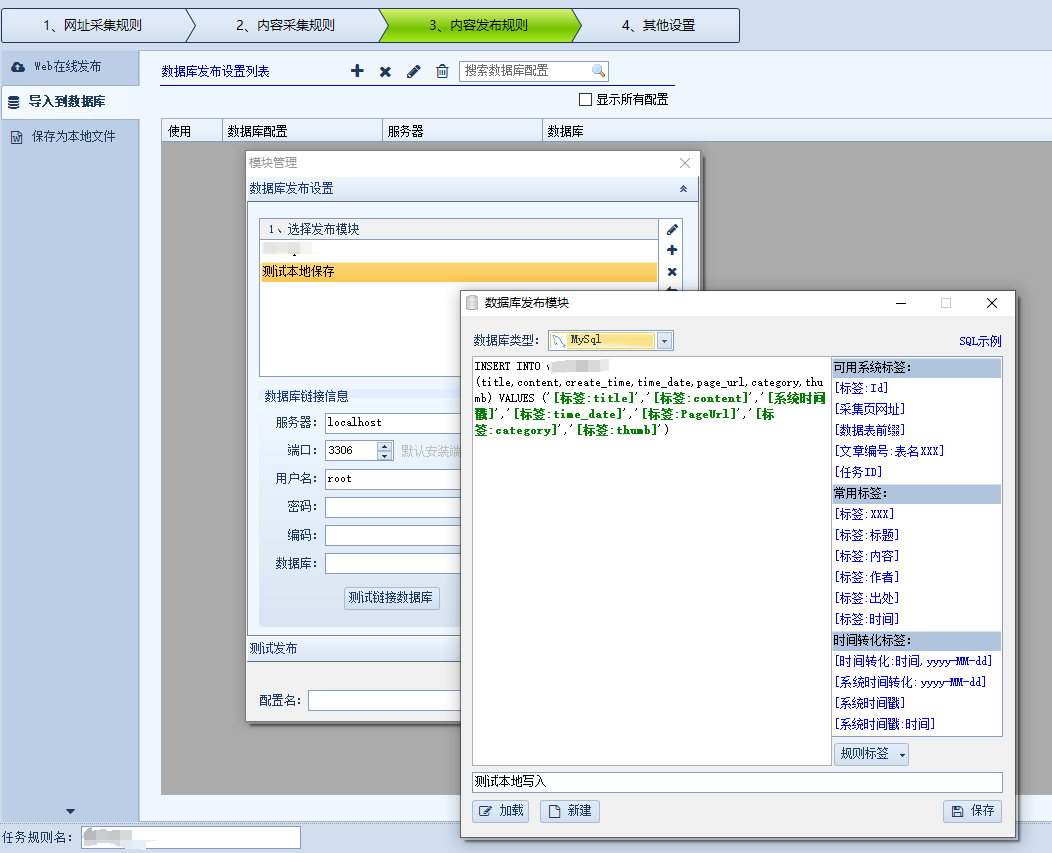
(上图)数据库导入配置
4.图片保存,可以设置抓取图片的自定义路径和保存地址以及同步上传到云存储服务器上
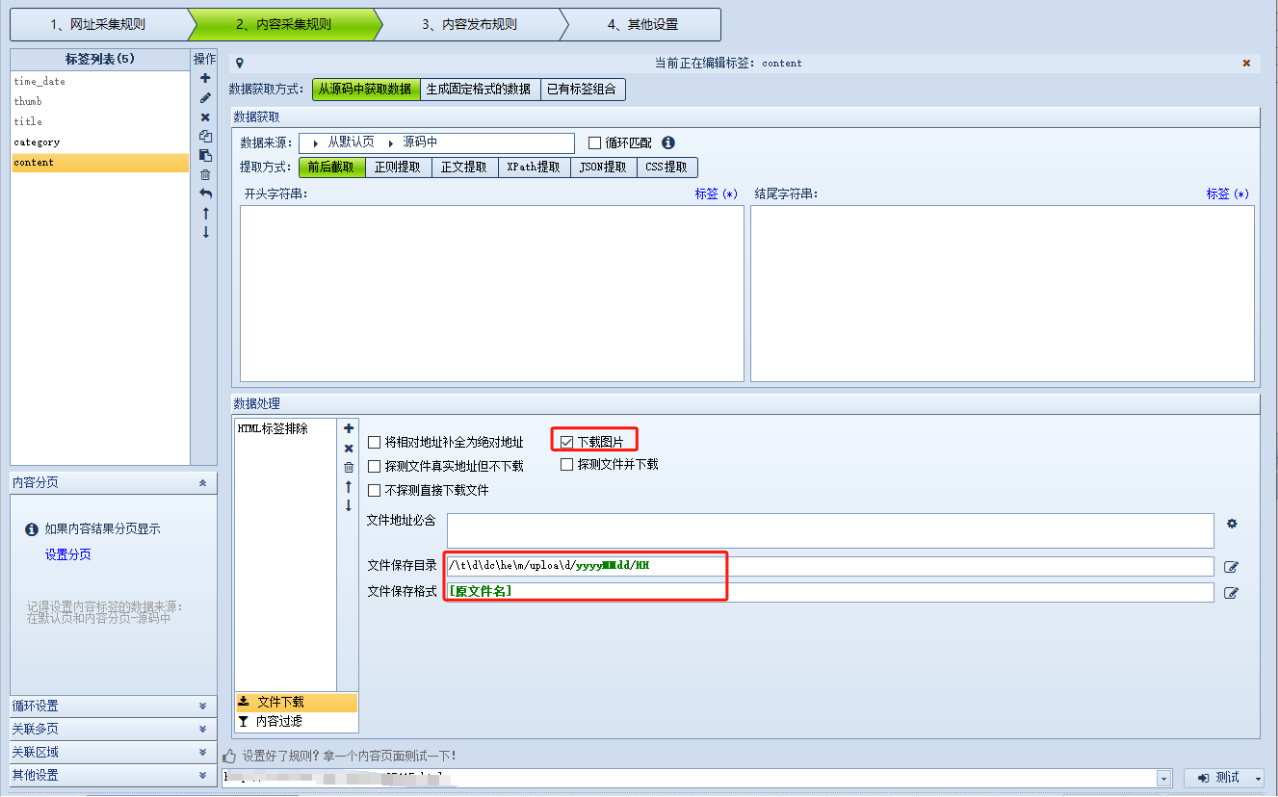
(上图)设置文件下载位置,这一步设置之后抓取内容的中的图片路径就是设置的这个路径了,不过路径不带域名,想要补全域名可在下图位置设置
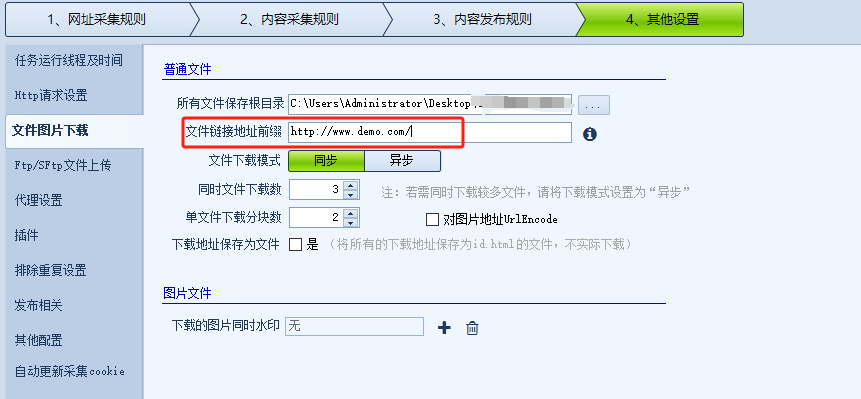
(上图)设置文件前缀域名
5.html内容过滤
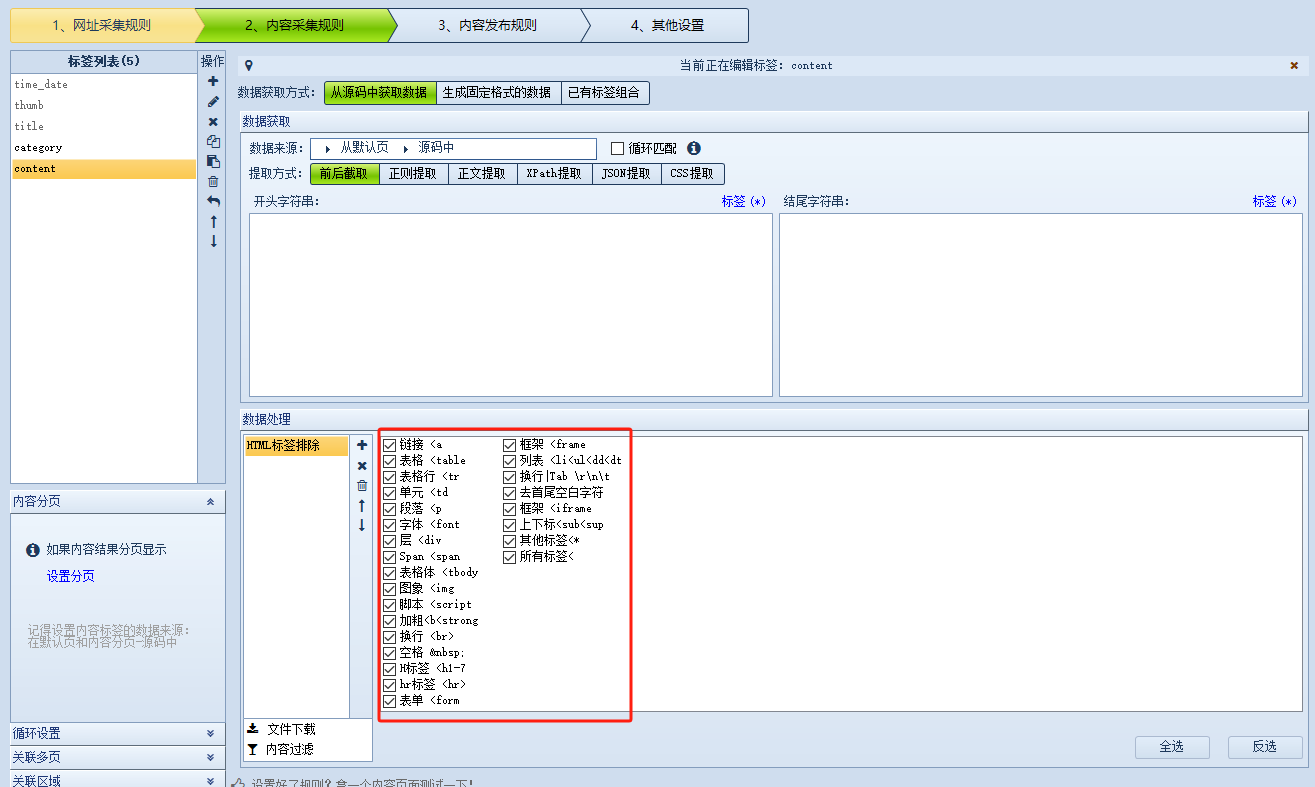
(上图)html内容过滤