参数访问
当使用nn.Sequential类创建模型时,我们可以通过索引来访问模型的任意层。我们首先创建一个nn.Sequential:
net = nn.Sequential( nn.Linear(64,32), nn.ReLU(), nn.Dropout(0.2), nn.Linear(32,8), nn.Linear(8,2) ) net[4].state_dict()
(1)使用state_dict()访问模型的参数状态:

state为“状态”的意思,这可以从自动机的角度理解。上面的代码访问了net的第5层的参数状态。从输出可以看出,第5层参数包含weight以及bias,它们对应的张量及其值被打印了出来。
同样可以访问其weight及bias:
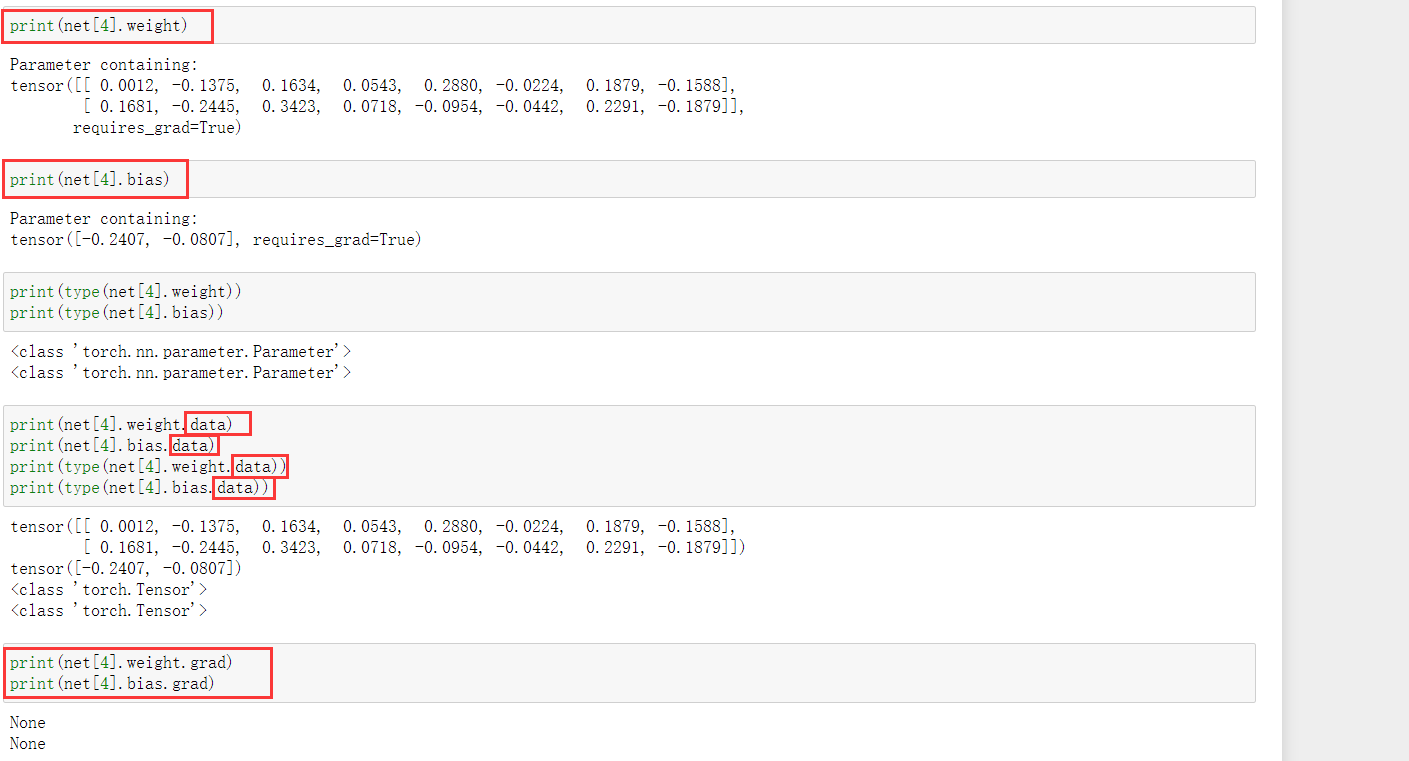
注意,所有参数都是参数类的一个实例。比如访问weight这个参数,我们使用net[4].weight访问到的是这个参数实例,要访问其底层的数值,需要使用net[4].weight.data.
接下来是书中给出的例子:
import torch
from torch import nn
net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 1))
X = torch.rand(size=(2, 4))
net(X)
访问网络中的所有参数:

拿第一行代码举例子。这里面, net[0].named_parameters()返回的是一个迭代器,其中包含了net第0层的所有参数的名字(name)和对应的张量。
[(name, param.shape) for name, param in net[0].named_parameters()]是一个列表解析,它创建了一个包含元组的列表,元组的两个元素分别为net[0]中参数的名字以及该参数张量的形状,这是通过用name以及param遍历迭代器中参数的名字和张量实现的,圆括号(name,param.shape)表示用网络第0层中参数的名字(name)以及张量的形状(param.shape)创建元组。最后,*是将列表中的所有元组展开成单独的参数。
举一个简单的列表解析的例子,下面的代码根据相应条件推导出一个列表:
>>> [ i*2 for i in range(10) if i % 2 == 0 ] [0, 4, 8, 12, 16]
还要注意:输出中的0.weight , 0.bias; 2.weight , 2.bias就分别表示的是第0层的权重及偏置;第2层的权重及偏置。这里第1层是ReLU层,没有参数,所以没打印任何东西。
这为我们提供了访问参数的另一种方式,如下所示:

这等价于:

从嵌套块收集参数
我们定义一个嵌套块:
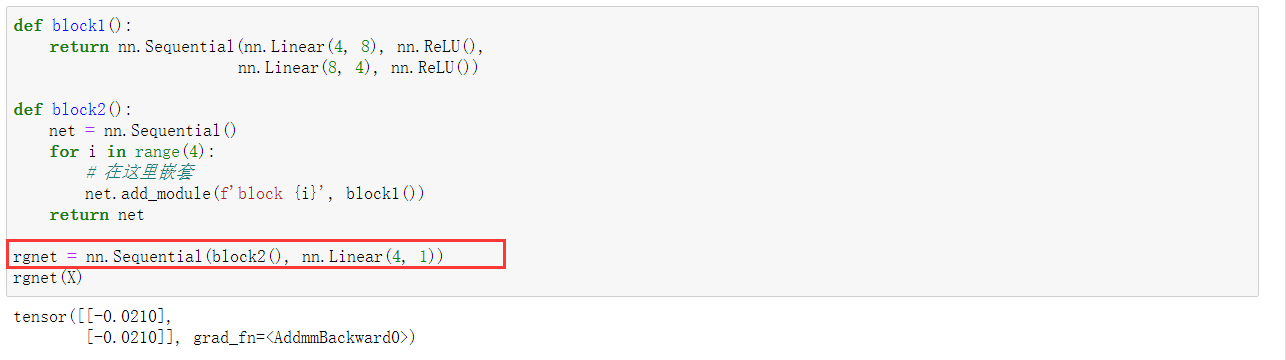
打印一下看看:

我们用如下方式访问第一个主要的块中、第二个子块的第一层的偏置项。

参数初始化
我们可以对不同的层应用不同的初始化函数:

由nn.Sequential创建的net是nn.Module的实例,它可以用net.apply()进行初始化。net中的net[0]和net[2]两个层为nn.Linear,也是nn.Module的实例,同样可以用net[0].apply及net[2].apply进行初始化。上面的例子中,我们对net[0]应用了xavier初始化方法,对net[2]应用了常量初始化。注意,这里是按照uniform的分布进行xavier初始化,同样可以用高斯分布进行xavier初始化。
参数绑定
深度学习中有时会有共享参数的需求。即神经网络中的某些层我们希望它们的参数是一样的。参数绑定可以实现这种参数共享。

可以看到,改了net[2]的参数值后,net[2]和net[4]的参数值依然是相等的。实际上,它们是指向同一个parameter对象的,所以改了一个,另一个也会变。