chapter7
文件操作级别
文件操作分五个级别,从低到高排序如下:
1.硬件级别:硬件级别的文件操作包括
- fdisk:将硬盘、U盘或SDC盘分区。
- mkfs:格式化磁盘分区,为系统做好准备。
- fsck:检查和维修系统。
- 碎片整理:压缩文件系统中的文件。
其中大多说是针对系统的实用程序。
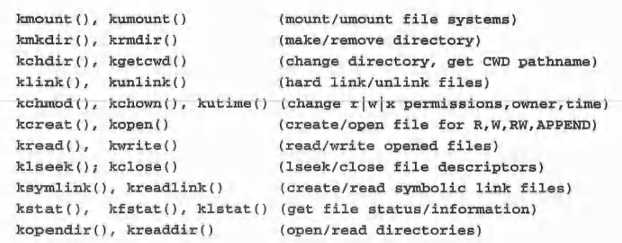
2.操作系统内核中的文件系统函数:每个操作系统内核均可为基本文件操作提供支持。下面是一些前缀k的函数(内核函数)。
3.系统调用:用户模式程序使用系统调用来访问内核函数。
4.I/O库函数:系统调用可让用户读/写多个数据块,这些数据块只是一系列字节。它们不知道,也不关心数据的意义。用户通常需要读/写单独的字符、行或数据结构记录等。如果只有系统调用,用户模式程序则必须自己从缓冲区执行这些操作。多数用户认为这非常不方便。为此,C语言库提供了一系列标准的I/O函数,同时提高了运行效率。I/O库函数包括:

除读/写内存位置的sscanf()/sprintf()函数外,其他所有I/O库函数都建立在系统调用之上,也就是说,它们最终会通过系统内核发出实际数据传输的系统调用。
5.用户命令:用户可以使用Unix/Linux命令来执行文件操作,而不是编写程序。用户命令的示例如下:
mkdir,rmdir,cd,pwd,ls,link,unlink,rm,cat,cp,mv,chmod,etc.
每个用户命令实际上是一个可执行程序(cd除外),通常会调用库I/O函数,而库I/O函数再发出系统调用来调用相应的内核函数。用户命令的处理顺序为:
Command => Library I/O function => System call => Kernel function
或者
Command ======================= => System call => Kernel function
6.sh脚本:虽然比系统调用方便得多,但是必须要手动输入命令,如果使用的是GUI,必须要拖放文件图标和指向设备来输入,操作繁琐且耗时。sh脚本是用sh编程语言编写的程序,可通过命令解释程序sh来执行。sh语言包含所有的有效Unix/Linux命令。它还支持变量和控制语句,如if、do、for、while、case等。实际上,sh脚本广泛应用于Unix/Linux系统编程。
文件I/O操作
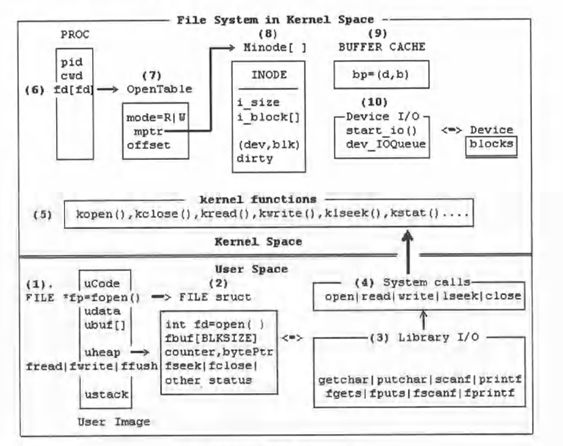
文件I/O操作示意图
在上图中,双线上半区域为内核空间,下半区域为进程的用户控件。
(1)~(4)是用户模式下的操作,(5)~(10)是内核模式下的操作。
(1)用户模式下的程序执行操作
FILE *fp = fopen("file","r");or FILE *fp = fopen("file","w");
可以打开一个读/写文件流。
(2)fopen()在用户(heap)空间中创建一个FILE结构体,包含一个文件描述符fd、一个fbuf[BLKSIZE]和一些控制变量。它会向内核中的kopen()发出一个fd=open("file",flags=READ or WRITE)系统调用,构建一个OpenTable来表示打开文件示例。OpenTable的mptr指向内存中的文件INODE。对于非特殊文件,INODE的i_block数组指向存储设备上的数据块。成功后,fp会指向FILE结构体,其中fd是open()系统调用返回的文件描述符。
(3)fread(ubuf,size,nitem,fp):将nitem个size字节读取到ubuf上,通过:
- 将数据从FILE结构体的fbuf上复制到ubuf上,若数据足够,则返回。
- 如果fbuf没有更多数据,则执行(4a)。
(4a)发出read(fd,fbuf,BLKSIZE)系统调用,将文件数据块从内核读取到fbuf上,然后将数据复制到ubuf上,直到数据足够或者文件无更多数据可复制。
(4b)fwrite(ubuf,size,nitem,fp):将数据从ubuf复制到fbuf。
- 若(fbuf有空间):将数据复制到fbuf上,并返回。
- 若(fbuf已满):发出write(fd,fbuf,BLKSIZE)系统调用,将数据块写入内核,然后再次写入fbuf。
这样,fread()/fwrite()会向内核发出read()/write()系统调用,但仅在必要时发出,而且它们会以块集大小来传输数据,提高效率。同样,其他库I/O函数,如fgetc/fputc、fgets/fputs、fscanf/fprintf等也可以在用户空间内的FILE结构体中对fbuf进行操作。
(5)内核中的文件系统函数:
假设非特殊文件中的read(fd,fbuf[],BLKSIZE)系统调用。
(6)在read()系统调用中,fd是一个打开的文件描述符,它是运行进程的fd数组中的一个索引,指向一个表示打开文件的OpenTable。
(7)OpenTable包含文件的打开模式、一个指向内存中文件INODE的指针和读/写文件的当前字节偏移量。从OpenTable的偏移量,
- 计算逻辑块编号lbk。
- 通过INODE.i_block[]数组将逻辑块编号转换为物理块编号blk。
(8)Minode包含文件的内存INODE。EMODE.i_block[]数组包含指向物理磁盘块的指针。文件系统可使用物理块编号从磁盘块直接读取数据或将数据直接写入磁盘块,但将会导致过多的物理磁盘I/O。
(9)为提高磁盘I/O效率,操作系统内核通常会使用一组I/O缓冲区作为高速缓存,以减少物理I/O的数量。
(9a)对于read(fd,buf,BLKSIZE)系统调用,要确定所需的(dev,blk)编号,然后查询I/O缓冲区高速缓存,以执行以下操作:
.get a buffer = (dev,blk);
.if (buffer's data are invalid{
start_io on buffer;
wait for I/O completion;
}
.copy data from buffer to fbuf;
.release buffer to buffer cache;
(9b)对于write(fd,fbuf,BLKSIZE)系统调用,要确定需要的(dev,blk)编号,然后查询I/O缓冲区高速缓存,以执行以下操作:
.get a buffer = (dev,blk);
.write data to the I/O buffer;
.mark buffer as dataValid and DIRTY(for delay-write to disk);
.release the buffer to buffer cache;
(10)设备I/O:I/O缓存区上的物理I/O最终会仔细检查设备驱动程序,设备驱动程序由上半部分的start_io()和下半部分的磁盘中断处理程序组成。
---------------- Upper-half of disk driver ----------------
start_io(bp)://bp=a locked buffer in dev_list, opcode=R|W(ASYNC)
{
enter bp into dev's I/O_queue;
if(bp is FIRST in I/O_queue)
issue I/O command to device;
}
---------------- Lower-half of disk driver ----------------
Device_Interrupt_Handler:
{
bp = dequeue(first buffer from dev.I/O_queue);
if (bp was READ){
mark bp data VALID;
wakeup/unblock waiting process on bp;
}
else // bp was for delay write
release bp into buffer cache;
if(dev.I/O_queue NOT empty)
issue I/O command for first buffer in dev.I/O_queue;
}
低级别文件操作
1.分区
一个块储存设备,如硬盘、U盘、SD卡等,可以分为几个逻辑单元,称为分区。各分区均可以格式化为特定的文件系统,也可以安装在不同的操作系统上。大多数引导程序,如GRUB、LILO等,都可以配置为从不同的分区引导不同的操作系统。分区表位于第一个扇区的字节偏移446(0x1BE)处,该扇区称为设备的主引导记录(MBR)。表有4个条目,每个条目由一个16字节的分区结构体定义,即:
struct partition{
u8 drive; //0x80-active
u8 head; //starting head
u8 sector; //starting sector
u8 cylinder; //starting cylinder
u8 sys_type; //partition type
u8 end_head; //end head
u8 end_sector; //end sector
u8 end_cylinder;//end cylinder
u32 start_sector;//starting sector counting from 0
u32 nr_sectors; //number of sectors in partition
};
如果某分区时扩展类型(类型编号=5),那么它可以划分为更多分区。假设分区P4是扩展类型,它被划分为扩展分区P5、P6、P7。扩展分区在扩展分区区域内形成一个链表,如下图。

每个扩展分区的第一个扇区是一个本地MBR。每个本地MBR在字节偏移量0x1BE处也有一个分区表,只包含两个条目。第一个条目定义了扩展分区的起始扇区和大小。第二个条目指向下一个本地MBR。所有本地MBR的扇区编号都与P4的起始扇区有关。照例,链表以最后一个本地MBR中的0结尾。在分区表中,CHS值仅小于8GB的磁盘有效。对大于8GB但小于4GB扇区的磁盘,只有最后两个条目start_sector和nr_sector有意义。可以通过fdisk命令分区。
2.格式化分区
划分好分区后,每个分区都有特定的文件系统类型,但分区还不能使用。为了存储文件,必须先为特定的文件系统准备好分区。该操作习惯上称为格式化磁盘或磁盘分区。在Linux中,它被称为mkfs,表示Make文件系统。Linux支持多种不同类型的文件系统。每个文件系统都期望存储设备上有特定的格式。Linux中,命令
mkfs -t TYPE [-b bsize] device nblocks
在一个nblocks设备上创建一个TYPE文件系统,每个块都是bsize字节。如果bsize未指定,则默认块大小为1KB。格式化分区后还需要挂载分区。如果某个虚拟磁盘包含多个分区,那么必须先将这些分区与循环设备关联起来。
3.挂载分区
man 8 losetup:显示用于系统管理的losetup实用工具命令:
(1)用dd命令创建一个虚拟磁盘映像:
dd if=/dev/zero of=vdisk bs=1024 count=32768 #32K(1KB)blocks
(2)在vdisk上运行fdisk来创建一个分区P1:
fdisk vdisk
输入n(new)命令,使用默认的起始和最后扇区编号来创建一个分区P1。然后,输入w命令将分区表写入vdisk并退出fdisk。vdisk应包含一个分区P1[start=2048,end=65535]。该分区的大小是63488个扇区。
(3)使用以下扇区数在vdisk的分区1上创建一个循环设备:
losetup -o $(expr 2048 \* 512) --sizelimit $(expr 65535 \* 512) /dev/loop1vdisk
losetup需要分区的开始字节(start_sector * 512)和结束字节(end_sector * 512)。可用类似方法设置其他分区的循环设备。循环设备创建完成后,读进程可以使用命令
losetup -a
将所有循环设备显示为/dev/loopN。
(4)格式化/dev/loop1,它是一个EXT2文件系统:
mke2fs -b 4096 /dev/loop1 7936 #mke2fs with 7936 4KB blocks
该分区的大小是63488个扇区。4KB块的扇区大小是63488/8=7936。
(5)挂载循环设备:
mount /dev/loop1 /mnt #mount as loop device
(6)访问作为文件系统一部分的挂载设备:
(cd /mnt;mkdir bin boot dev etc user) #populate with DIRs
(7)设备使用完毕后,将其卸载。
umount /mnt
(8)循环设备使用完毕后,通过以下命令将其断开:
losetup -d /dev/loop1 #detach a loop device
EXT2文件系统
简介
- EXT2:Linux默认文件系统。
- EXT3:EXT2的扩展,主要增加内容是一个日志文件,记录更改内容。
- EXT4:EXT3的最新扩展,主要变化在磁盘块的分配,块编号是48位。EXT4不是分配不连续的磁盘块,而是分配连续的磁盘块区,称为区段。
EXT2文件系统数据结构
在Linux中,可以创建一个包含简单EXT2文件系统的虚拟磁盘:
(1). dd if=/dev/zero of=mydisk bs=1024 count=1440
(2). mke2fs -b 1024 mydisk 1440
得到的EXT2文件系统有1440个块,每个块大小为1KB。简单的ETX2文件系统布局如下图。

Block#0:引导块
B0是引导块,文件系统不会使用它。它用于容纳从磁盘引导操作系统的引导程序。
Block#1:超级块(在硬盘分区中字节偏移量为1024)
B1是超级块,用于容纳关于整个文件系统的信息。下面是超级块结构中的一些重要字段。
struct ext2_super_block{
u32 s_inodes_count; /* Inodes count */
u32 s_blocks_count; /* Blocks count */
u32 s_r_blocks_count; /* Reserved blocks count */
u32 s_free_blocks_count;/* Free blocks count */
u32 s_free_inodes_count;/* Free inodes count */
u32 s_first_data_block; /* First Data Block */
u32 s_log_block_size; /* Block size */
u32 s_log_cluster_size; /* Allocation cluster size */
u32 s_blocks_per_group; /* #Blocks per group */
u32 s_clusters_per_group;/* #Fragments per group */
u32 s_inodes_per_group; /* #Inodes per group */
u32 s_mtime; /* Mount time */
u32 s_wtime; /* Write time */
u16 s_mnt_count; /* Mount count */
s16 s_max_mnt_count; /* Maximal mount count */
u16 s_magic; /* Magic signature */
//more non-essential fields
u16 s_inode_size; /* size of inode structure */
}
s_first_data_block:0表示4KB块大小,1表示1KB块大小。它用于确定块组描述符的起始块,即s_first_data_block+1。
s_log_block_size:确定文件块大小,为1KB * (2**s_log_block_size),例如0表示1KB块大小,1表示2KB块大小,2表示4KB块大小等。最常用的块大小是用于小文件系统的1KB和用于大文件系统的4KB。
s_mnt_count:已挂载文件系统的次数。当次数达到这个数时fsck会话将被迫检查文件系统的一致性。
s_magic:标识文件系统类型的幻数。EXT2/3/4文件系统的幻数时0xEF53。
Block#2:块组描述符块(硬盘上的s_first_data_blocks-1)
EXT2将磁盘块分成几个组。每个组有8192个块(硬盘上的大小为32K)。每组用一个块组描述符结构体描述。
struct ext2_group_desc{
u32 bg_block_bitmap; //Bmap block number
u32 bg_inode_bitmap; //Imap block number
u32 bg_inode_table; //Inodes begin block number
u16 bg_free_blocks_count; //THESE are OBVIOUS
u16 bg_free_inodes_count;
u16 bg_used_dirs_count;
u16 bg_pad; //ignore these
u32 bg_reserved[3];
}
由于一个软盘只有1440个块,B2只包含一个块组描述符。其余的都是0。在有大量块组的硬盘上,块组描述符可以跨越多个块。块组描述符中最重要的字段是bg_block_bitmap、bg_inode_bitmap和bg_inode_table,它们分别指向块组的块位图、索引节点位图和索引节点起始块。对于Linux格式的EXT2文件系统,保留了块3到块7,所以,bmap=8,imap=9,inode_table=10。
Block#8:块位图(Bmap)(bg_block_bitmap)
位图是用来表示某种项的位序列,例如磁盘块或索引节点。位图用于分配和回收项。在位图中,0位表示对应项处于FREE状态,1位表示对应项处于IN_USE状态。一个软盘有1440个块,但是Block#0未被文件系统使用。所以,位图只有1439个有效位。无效位视作IN_USE处理,设置为1。
Block#9:索引节点位图(Imap)(bg_inode_bitmap)
一个索引节点就是用来代表一个文件的数据结构。EXT2文件系统是使用有限数量的索引节点创建的。各索引节点的状态用B9中Imap中的一个位表示。在EXT2 FS中,前10个索引节点是预留的。所以,空EXT2 FS的Imap以10个1开头,然后是0。无效位再次设置为1。
Block#10:索引(开始)节点块(bg_inode_table)
每个文件都用一个128字节(EXT4中的是256字节)的独特索引节点结构体表示。下面是主要索引节点字段。
struct ext2_inode{
u16 i_mode; //16 bits = |tttt|ugs|rwx|rwx|rwx|
u16 i_uid; //owner uid
u32 i_size; //file size in bytes
u32 i_atime; //time fields in seconds
u32 i_ctime; //since 00:00:00,1-1-1970
u32 i_mtime;
u32 i_dtime;
u16 i_gid; //group ID
u16 i_links_count; //hard-link count
u32 i_blocks; //number of 512-byte sectors
u32 i_flags; //IGNORE
u32 i_reserved1; //IGNORE
u32 i_block[15]; //See details below
u32 i_pad[7]; //for inode size = 128 bytes
}
在索引节点结构体中,i_mode为u16或2字节无符号整数。
| 4 | 3 | 9 |
i_mode = |tttt|ugs|rwxrwxrwx|
在i_mode字段中,前四位表示文件类型。例如,tttt=1000表示REG文件,0100表示DIR文件等。接下来的3位ugs表示文件的特殊用法。最后9位是文件保护的rwx权限位。
i_size字段表示文件大小(以字节为单位)。各时间字段表示自1970年1月1日0时0分0秒以来经过的秒数(时间戳)。所以,每个时间字段都是一个非常大的无符号整数。可借助以下库函数将它们转换为日历形式:
char *ctime(&time_field)
将指针指向时间字段,然后返回一个日历形式的字符串。例如:
printf("%s",ctime(&inode.i_atime)); //note:pass & of time field
以日历形式打印i_atime。
i_block[15]数组包含指向文件磁盘块的指针,这些磁盘块有:
- 直接块:i_block[0]至i_block[11],指向直接磁盘块。
- 间接块:i_block[12]指向一个包含256个块编号(对于1KB BLKSIZE)的磁盘块,每个块编号指向一个磁盘块。
- 双重间接块:i_block[13]指向一个指向256个块的块,每个块指向256个磁盘块。
- 三重间接块:i_block[14]是三重间接块。对于“小型”EXT2文件系统,可以忽略。
索引节点大小(128或256)用于平均分割块大小(1KB或4KB),所以每个索引节点块都包含整数个索引节点。在简单的EXT2文件系统中,索引节点的数量是184个(Linux默认值)。索引节点块数等于184/8=23个。因此,索引节点块为B10至B32。每个索引节点都有一个独特的索引节点编号,即索引节点在索引节点块上的位置+1。注意,索引节点位置从0开始计数,而索引节点编号从1开始计数。0索引节点编号表示没有索引节点。根目录的索引节点编号为2。同样,磁盘块编号也从1开始计数,因为文件系统从未使用块0.块编号0表示没有磁盘块。
数据块:紧跟在索引节点块后面的是文件存储块。假设有184个索引节点,第一个实际数据块是B33,它就是根目录/的i_block[0]。
EXT2目录条目:目录包含dir_entry结构,即:
struct ext2_dir_entry_2{
u32 inode; //inode number;count from 1,NOT 0
u16 rec_len; //this entry's length in bytes
u8 name_len; //name length in bytes
u8 file_type; //not used
char name[EXT2_NAME_LEN]; //name:1-255 chars,no ending NULL
};
dir_entry是一种可扩充结构。名称字段包含1到255个字符,不含终止NULL字节。所以dir_entry的rec_len也各不相同。
chapter8
系统调用
操作系统中进程以两种不同模式运行,即内核模式(Kmode)和用户模式(Umode)。Umode中进程权限非常有限,不能执行任何需要特殊权限的操作。Kmode可以。系统调用(syscall)是一种允许进程进入Kmode以执行Umode不允许操作的机制。复刻子进程、修改执行映像,甚至是终止等操作都必须在内核中执行。
系统调用手册页
在Unix和大多数版本的Linux中在线手册页保存在/usr/man/目录中。在Ubuntu Linux中则保存在/usr/share/man目录中。man2子目录中列出了所有系统调用手册页。sh命令man 2 NAME显示了系统调用名称的手册页。
例如:
man 2 stat:display man pages of stat(), fstat() and lstat() syscalls
man 2 open:display man pages of open() syscall
man 2 read:display man pages of read() syscall, etc.
许多系统调用需要特别包含头文件,手册页的SYNOPSIS(概要)部分列出了这些文件。如果没有合适的头文件,C编译器可能会因为syscall函数名称类型不匹配而发出许多警告。一些系统调用可能还需要特定的数据结构作为参数,必须在手册页中描述这些参数。
使用系统调用进行文件操作
系统调用必须由程序发出。每个系统调用都是一个库函数,汇集系统调用参数,最终向操作系统内核发出一个系统调用。
int syscall(int a, int b, int c, int d);
a是系统调用编号,b、c、d是对应内核函数的参数。在基于Intel x86的Linux中,系统调用是由INT 0x80汇编指令实现的,可将CPU从用户模式切换到内核模式。内核的系统调用处理程序根据系统调用编号将调用路由到一个相应的内核函数。当进程结束执行内核函数时,会返回到用户模式,并得到所需的结果。返回值>=0表示成功,-1表示失败。如果失败,errno变量(在errno.h中)会记录错误编号,它们会被映射到描述错误原因的字符串。
简单的系统调用
access:检查对某个文件的权限
int access(char *pathname,int mode);
chdir:更改目录
int chdir(const char *path);
chmod:更改某个文件的权限
int chmod(char *path,mode_t mode);
chown:更改文件所有人
int chown(char *name,int uid,int gid);
chroot:将(逻辑)根目录更改为路径名
int chroot(char *pathname);
getcwd:获取CWD的绝对路径名
char *getcwd(char *buf,int size);
mkdir:创建目录
int mkdir(char *pathname,mode_t mode);
rmdir:移除目录(必须为空)
int rmdir(char *pathname);
link:将新文件名硬链接到旧文件名
int link(char *oldpath,char *newpath);
unlink:减少文件的链接数;如果链接数达到0,则删除文件
int unlink(char *pathname);
symlink:为文件创建一个符号链接
int symlink(char *oldpath,char *newpath);
rename:更改文件名称
int rename(char *oldpath,char *newpath);
utime:更改文件的访问和修改时间
int utime(char *pathname,struct utimebuf *time);
以下系统调用需要超级用户权限(sudo)
mount:将文件系统添加到挂载点目录上
int mount(char *specialfile,char *mountDir);
umount:分离挂载的文件系统
int umount(char *dir);
mknod:创建特殊文件
int mknod(char *path,int mode,int device);
常用系统调用
stat:获取文件状态信息
int stat(char *filename,struct stat *buf);
int fstat(int filedes,struct stat *buf);
int lstat(char *filename,struct stat *buf);
open:打开一个文件进行读、写、追加
int open(char *file,int flags,int mode);
close:关闭打开的文件描述符
int close(int fd);
read:读取打开的文件描述符
int read(int fd,char buf[],int count);
write:写入打开的文件描述符
int write(int fd,char buf[],int count);
lseek:重新定位文件描述符的读/写偏移量
int lseek(int fd,int offset,int whence);
dup:将文件描述符复制到可用的最小描述符编号中
int dup(int oldfd);
dup2:将oldfd复制到newfd中,如果newfd已打开,先将其关闭
int dup2(int oldfd,int newfd);
link:将新文件硬链接到旧文件
int link(char *oldPath,char *newPath);
unlink:取消某个文件的链接;如果文件链接数为0,则删除文件
int unlink(char *pathname);
symlink:创建一个符号链接
int symlink(char *target,char *newpath);
readlink:读取符号链接文件的内容
int readlink(char *path,char *buf,int bufsize);
umask:设置文件创建掩码;文件权限为(mask & ~umask)
int umask(int umask);
链接文件
Unix/Linux中允许使用不同路径名表示同一文件,这些文件叫LINK(链接)文件,有两种类型,硬链接和符号链接(软链接)
硬链接
使用
ln oldpath newpath
创建从newpath到oldpath的硬链接。对应系统调用为:
link(char *oldpath,char *newpath)
硬链接文件会共享系统文件中相同的文件表示数据结构(索引节点)。文件链接数会记录链接到同一索引节点的硬链接数。硬链接仅适用于非目录文件。否则它可能会在文件系统名称空间中创建循环,这并不允许。相反,系统调用:
unlink(char *pathname)
会减少文件的链接数。若链接数为0,文件会被完全删除。这就是rm(file)命令的作用。如果某个文件包含非常重要的信息,最好创建多个链接到文件的硬链接,防止意外删除。
符号链接
使用
ln -s oldpath newpath #ln command with the -s flag
创建从newpath到oldpath的软链接或符号链接。对应系统调用为:
symlink(char *oldpath,char *newpath)
newpath是LNK类型普通文件,包含oldpath字符串。它可作为一个绕行标志,使访问指向链接好的目标文件。与硬链接不同,软链接适用于任何文件,包括目录。软链接在以下情况非常有用。
(1)通过一个较短的名称来访问一个经常使用的较长路径名称,例如:x->aVeryLongPathnameFile
(2)将标准动态库名称链接到实际版本动态库,例如:libc.so.6->libc.2.7.so
当将实际动态库更改为不同版本时,库安装程序只需更改(软)链接以指向新安装的库。
软链接的一个缺点是目标文件可能不复存在。在Linux中,会通过ls命令以适当的深色RED显示此类危险,提醒用户链接已断开。此外,若foo->/a/b/c是软链接,open("foo",0)系统调用将打开被链接的文件/a/b/c,而不是链接文件本身。所以open()/read()系统调用不能读取软链接文件,反而必须要使用readlink系统调用来读取软链接文件的内容。
stat系统调用
stat/lstat/fstat系统调用可将一个文件的信息返回。可以使用man 2 stat显示stat系统调用的手册页。
stat结构体
所有的stat系统调用都以stat结构体形式返回信息,其中包含以下字段:
struct stat{
dev_t st_dev; /*device*/
ino_t st_ino; /*inode*/
mode_t st_mode; /*protection*/
nlink_t st_nlink; /*number of hard links*/
uid_t st_uid; /*user ID of owner*/
gid_t st_gid; /*group ID of owner*/
dev_t st_rdev; /*device type(if inode device)*/
off_t st_size; /*total size,in bytes*/
u32 st_blksize; /*blocksize for filesystem I/O*/
u32 st_blocks; /*number of blocks allocated*/
time_t st_atime; /*time of last access*/
time_t st_mtime; /*time of last modification*/
time_t st_ctime; /*time of last change*/
};
st_size是用字节表示的文件大小。符号链接的大小是指它所包含的路径名称长度,末尾没有NULL。
st_blocks值使用512字节块表示的文件大小。(可能小于st_size/512,例如当文件有漏洞时。)st_blksize值表示有效文件系统I/O的“首选”块大小。(以较小的块写入文件可能导致低效的读取-修改-重写。)
并非所有Linux文件系统都能实现所有时间字段。一些文件系统类型允许以这种方式挂载,即文件访问不会导致st_atime字段更新。
通过文件访问更改所含的st_atime,例如exec(2)、mknod(2)、pipe(2)、utime(2)和read(2)(大于零字节)。其他如mmap(2),可能会也可能不会更新st_atime。
通过文件修改,如mknod(2)、truncate(2)、utime(2)和write(2)(大于零字节),更改所包含的st_mtime。此外还能通过创建或删除目录中的文件来更改目录的st_mtime。所包含的st_mtime不会因为所有者、组、硬链接数或模式的变化而变化。
通过写入或设置索引节点信息(即所有者、组、链接数、模式等)更改所包含的st_ctime。
定义以下POSIX宏来检查文件类型:
S_ISREG(m) is it a regular file?
S_ISDIR(m) directory?
S_ISCHR(m) character device?
S_ISBLK(m) block device?
S_ISFIFO(m) fifo?
S_ISLNK(m) symbolic link?(Not in POSIX.1-1996.)
S_ISSOCK(m) socket?(Not in POSIX.1-1996.)
定义st_mode字段的以下标志:
S_IFMT 0170000 bitmask for the file type bitfields
S_IFSOCK 0140000 socket
S_IFLNK 0120000 symbolic link
S_IFREG 0100000 regular file
S_IFBLK 0060000 block device
S_IFDIR 0040000 directory
S_IFCHR 0020000 character device
S_IFIFO 0010000 fifo
S_ISUID 0004000 set UID bit
S_ISGID 0002000 set GID bit(see below)
S_ISVTX 0001000 sticky bit(see below)
S_IRWXU 00700 mask for file owner permissions
S_IRUSR 00400 owner has read permission
S_IWUSR 00200 owner has write permission
S_IXUSR 00100 owner has execute permission
S_IRWXG 00070 mask for group permissions
S_IRGRP 00040 group has read permission
S_IWGRP 00020 group has write permission
S_IXGRP 00010 group has execute permission
S_IRWXO 00007 mask for permissions for others(not in group)
S_IROTH 00004 others have read permission
S_IWOTH 00002 others have write permission
S_IXOTH 00001 others have execute permission
返回值:如果成功返回0,否则返回-1,并适当设置errno。
stat与文件索引节点
每个文件都有一个独有的索引节点数据结构,包含文件的所有信息。下面是Linux中EXT2文件系统的索引节点结构体。
struct ext2_inode{
u16 i_mode;
u16 i_uid;
u32 i_size;
u32 i_atime;
u32 i_ctime;
u32 i_mtime;
u32 i_dtime;
u16 i_gid;
u16 i_links_count;
u32 i_blocks;
u32 i_flags;
u32 i_reserved1;
u32 i_block[15];
u32 pad[7];
}; //inode=128 bytes in ext2/3 FS;256 bytes in ext4
每个索引节点在存储设备上都有唯一的索引节点编号(ino)。每个设备都由一对(主、次)设备号标识,例如0x0302表示/dev/hda2,0x0803表示/dev/sda2等。stat系统调用只是查找文件的索引节点并将信息从索引节点复制到stat结构体中,但是st_dev和st_ino除外,它们分别是设备号和索引节点编号。
文件类型和权限
st_mode的类型是一个u16(16位),这16位的含义如下:
|Type| |permissions|
----------------------
|tttt|fff|uuu|ggg|ooo|
----------------------
前4位是文件类型,可以(以八进制形式)解释为:
S_IFMT 0170000 bitmask for the file type bitfields
S_IFSOCK 0140000 socket
S_IFLNK 0120000 symbolic link
S_IFREG 0100000 regular file
S_IFBLK 0060000 block device
s_IFDIR 0040000 directory
S_IFCHR 0020000 character device
S_IFIFO 0010000 fifo
为方便起见,用十六进制重新定义它们,例如:
S_IFDIR 0x4000 directory
S_IFREG 0x8000 regular file
S_IFLNK 0xA000 symbolic link
st_mode接下来的3位表示文件的特殊用法:
S_ISUID 0004000 set UID bit
S_ISGID 0002000 set GID bit
S_ISVTX 0001000 sticky bit
其余9位是文件保护权限位。可按进程的(有效)uid和gid把这些位分为3类:
owner group other
rwx rwx rwx
通过解释这些位,可将st_mode表示为:
-rwxr-xr-x (REG file with r,x but w by owner only)
drwxr-xr-x (DIR with r,x,but w by owner only)
lrw-r--r-- (LNK file with permissions)
其中第一个字母(-|d|l)表示文件类型,后面9个字符基于权限位。如果位是1,则每个字符打印为r|w|x;如果位是0,则打印为-。对于目录文件而言,x位表示是否允许访问(cd到)目录。
opendir-readdir函数
目录也是一个文件。根据文件系统的不同,目录文件的内容可能会有不同。因此,用户可能无法正确读取和解释目录的内容。POSIX为目录文件制定了以下接口函数。
#include <dirent.h>
DIR *open(dirPath); //open a directory named dirPath for READ
struct dirent *readdir(DIR *dp); //return a dirent pointer
Linux中dirent结构体是:
struct dirent{
u32 d_ino; //inode number
u16 d_reclen;
char d_name[]
}
在dirent结构体中,POSIX只要求必须保留d_name字段。其他字段取决于具体的系统。opendir()返回一个DIR指针dirp。每个readdir(dirp)调用返回一个dirent指针,指向目录中下一个条目的dirent结构体。当目录中没有更多条目时,则返回一个NULL指针。
readlink函数
Linux的open()系统调用遵循符号链接。因此,无法打开符号链接并读取其内容。想要读取符号链接文件的内容,必须使用readlink系统调用,即:
int readlink(char *pathname,char buf[],int bufsize);
它将符号链接文件的内容复制到bufsize的buf[]中,并将实际复制的字节数返回。
open-close-lseek系统调用
打开文件和文件描述符:
#include <sys/type.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(char *pathname,int flags,mode_t mode);
关闭文件描述符:
#include <unistd.h>
int close(int fd);
使用close(int fd);关闭指定的文件描述符fd,可重新用它来打开另一个文件。
lseek文件描述符:
#include <sys/type.h>
#include <unistd.h>
off_t lseek(int fd,of_t offset,int whence);
使用lseek(int fd,of_t offset,int whence);(whence参数指定SEEK_SET(从文件开头)、SEEK_CUR(当前RW-指针加上偏移量)、SEEK_EXD(文件大小加上偏移量),RW-指针的初始位置为0)
read()系统调用
#include <unistd.h>
int read(int fd,void *buf,int nbytes);
使用read()将n个字节读入用户空间的buf[]中,返回值是实际读取的字节数,若失败,会返回-1,例如当fd无效时。注意,buf[]必须要有足够空间来接收n字节,并且返回值可能小于n字节,例如文件小于n个字节,或者文件无更多需要读取的数据。返回值是一个整数,而不是文件结束(EOF)符。文件结束符是I/O库函数在文件流无更多数据时返回的一个特殊整数值(-1)。
write()系统调用
#include <unistd.h>
int write(int fd,void *buf,int nbytes);
使用write()将n字节从用户空间的buf[]中写入文件描述符,必须打开该文件描述符进行写、读写或追加。返回值是实际写入的字节数,通常等于n字节,若失败,则为-1,例如由于出现无效fd或打开fd用于只读等。
GPT提问环节
文件操作




系统调用





在学习中遇到的一些问题
问题
在编译代码是出现下图错误:

然后我向GPT求助

根据GPT的方法,我很快解决了这个问题

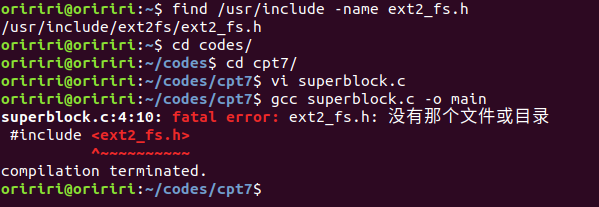
这里又有个小问题,但是后面才发现,include目录中还有一个ext2fs目录,所以代码中还要加上这一段才能正常编译。
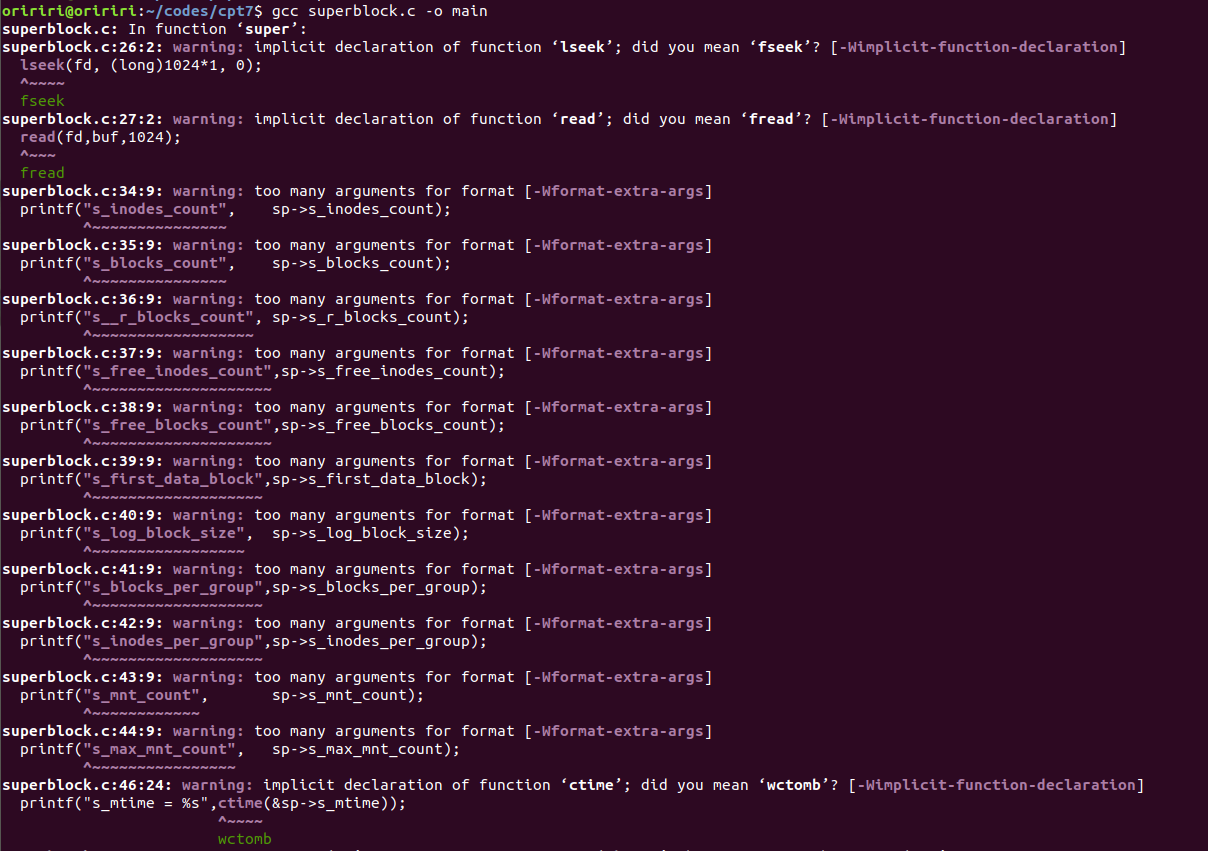

可以看到这里就正常编译了。
代码实践
教材代码实践
系统调用
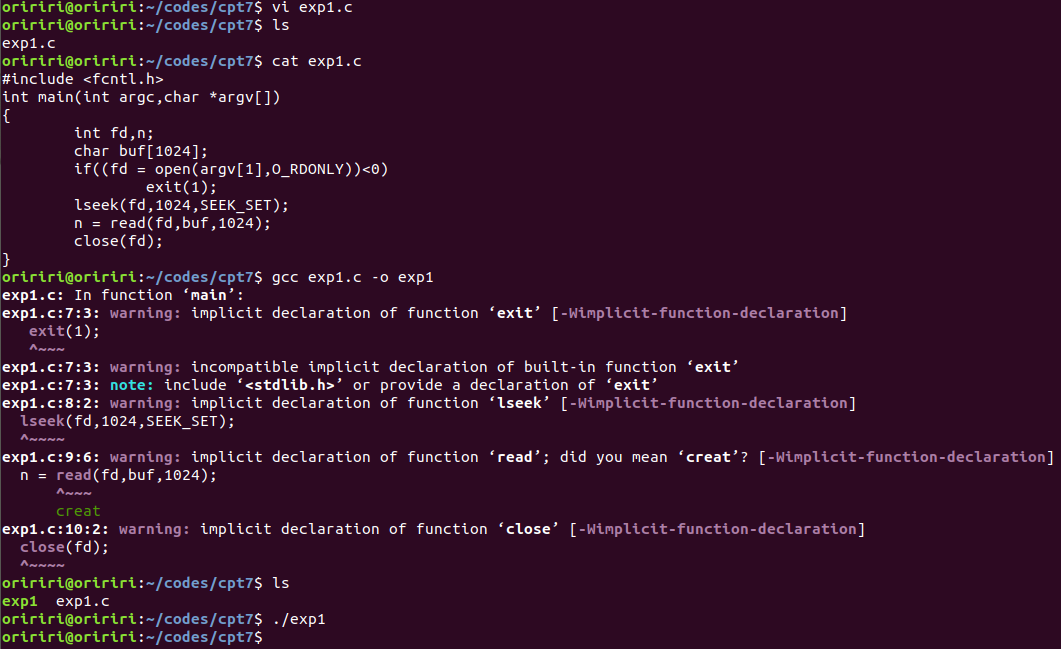
创建包含简单ext2文件系统的虚拟磁盘
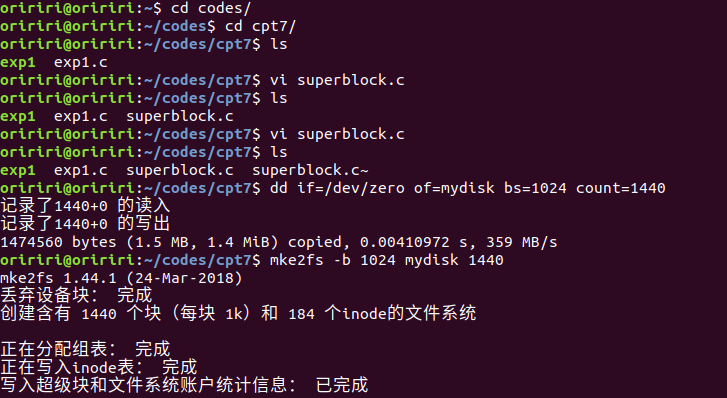
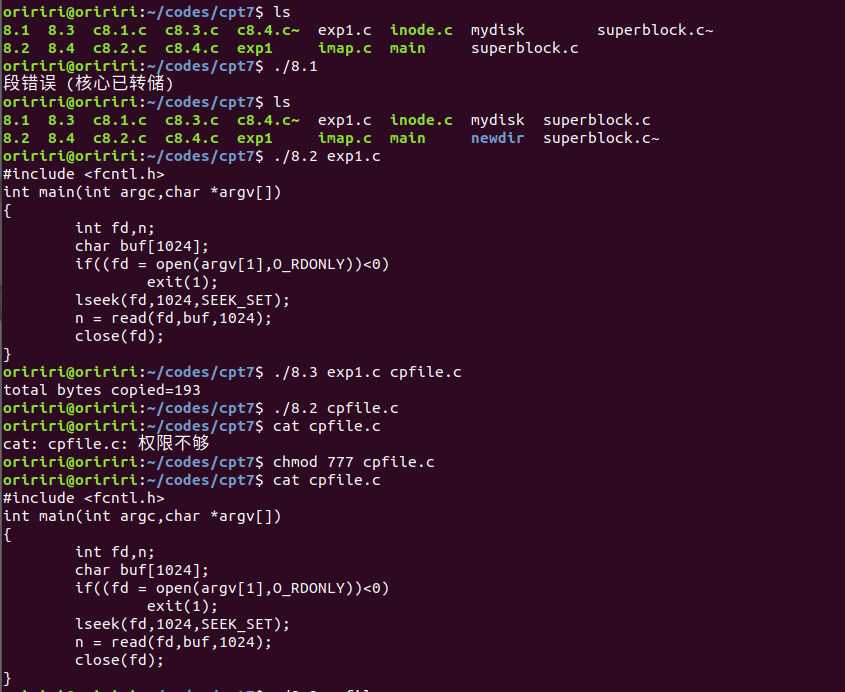
上面三个代码的运行结果如下图。

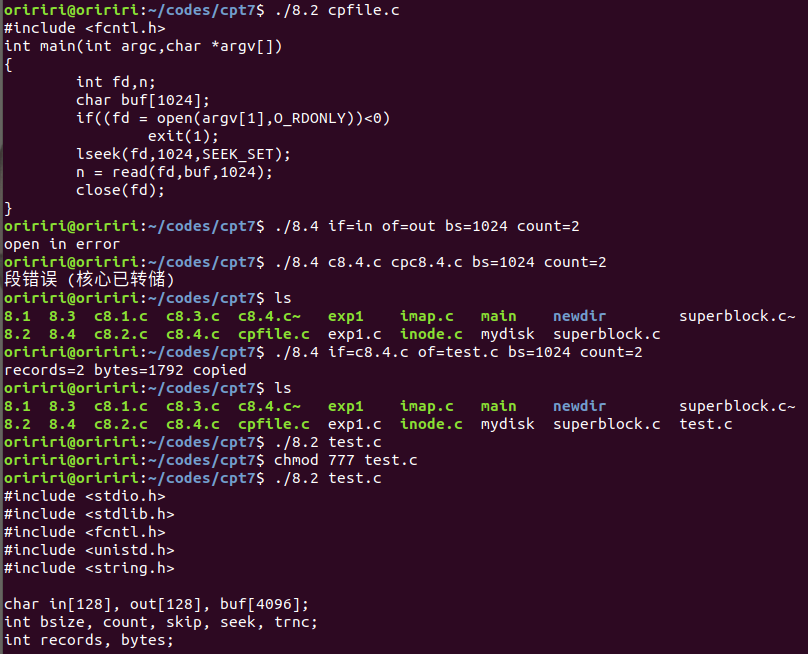
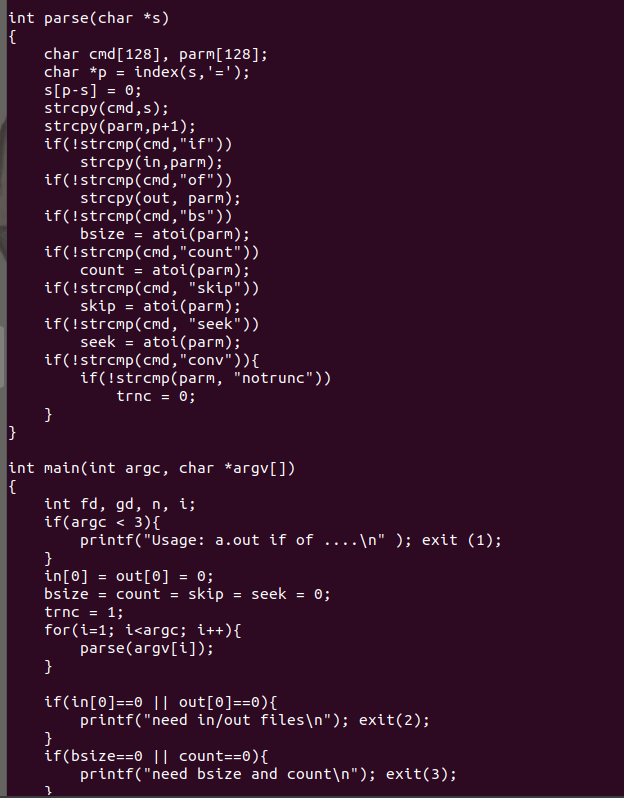
上面四种功能代码运行结果如下图。