TensorFlow实现
TensorFlow框架
神经网络训练的过程
- 准备数据集
- 定义模型
- 训练模型
- 评估模型
- 使用模型
实现详情
-
定义模型Dense:指定输入、输出和参数模型
model = tf.keras.Sequential([ tf.keras.layers.Dense(1, input_shape=(1,)) ]) -
编译模型:指定损失函数和优化器
model.compile(loss=BinaryCrossentropy()) -
训练模型:指定训练数据、训练轮数和批次大小
model.fit(x_train, y_train, epochs=500, batch_size=100)
激活函数的选择
常见的激活函数
-
sigmoid函数
sigmoid函数的表达式为:$$f(x)=\frac{1}{1+e^{-x}}$$
图像如下:
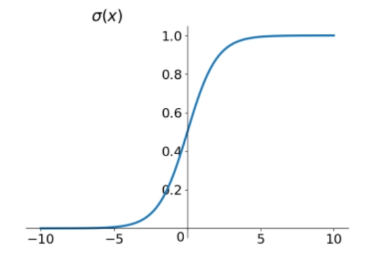
优点:输出范围为(0,1),单调连续,输出映射在(0,1)之间,可以作为概率值,也可以用于输出层的多分类问题,也可以用于二分类问题。
缺点:容易出现梯度消失,当输入值较大或较小时,梯度接近于0,导致权重无法更新,训练无法收敛。
-
ReLU函数
ReLU函数的表达式为:$$f(x)=max(0,x)$$
图像如下:
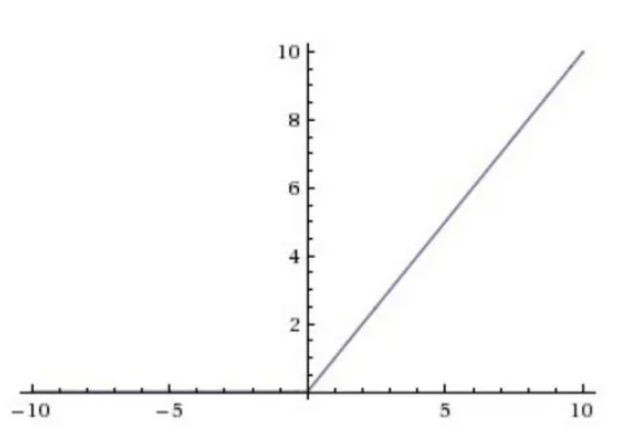
优点:解决了梯度消失的问题,计算速度快,收敛速度快。
缺点:输出不是zero-centered,导致收敛慢,容易出现dead ReLU问题,当输入值小于0时,梯度为0,导致权重无法更新,训练无法收敛。
-
softmax函数
softmax函数的表达式为:$$f(x)=\frac{e{x_i}}{\sum_{j=1}e^{x_j}}$$
- softmax函数是sigmoid函数的推广,sigmoid函数只能处理二分类问题,softmax函数可以处理多分类问题。
- softmax函数的输出是一个概率分布,所有输出的概率之和为1,可以作为多分类问题的概率输出。
- softmax函数的输出值都在(0,1)之间,可以作为概率值,也可以用于输出层的多分类问题。
softmax的损失函数是交叉熵损失函数,公式如下:
\[L=-\sum_{i=1}^{n}y_ilog(\hat{y_i}) \] -
线性激活函数
线性激活函数的表达式为:$$f(x)=x$$
激活函数的选择
-
输出层
输出层的激活函数一般根据不同的问题选择不同的激活函数
- 二分类问题,一般选择sigmoid函数
- 多分类问题,一般选择softmax函数
- 回归问题,一般选择线性激活函数
- 只能输出正数,一般选择ReLU函数
-
隐藏层
隐藏层的激活函数一般选择ReLU函数,因为ReLU函数的计算速度快,收敛速度快,解决了梯度消失的问题。
激活函数的功能
激活函数的主要功能是引入非线性因素,使得神经网络可以解决非线性问题。
激活函数实现的优化
数值稳定性
计算机在进行浮点数运算时,会出现数值溢出和数值下溢的问题,这会导致计算结果不准确。
TensorFlow优化
在使用TensorFlow框架时,可以避免中间结果的使用,从而减少数值溢出和数值下溢的问题。
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=25, activation='relu')
tf.keras.layers.Dense(units=15, activation='relu')
# 修改原先的输出层激活函数
#tf.keras.layers.Dense(units=1, activation='sigmoid')
tf.keras.layers.Dense(units=1,a ctivation='linear')
])
model.compile(loss=BinaryCrossentropy(from_logits=True)
model.fit(x_train, y_train, epochs=500, batch_size=100)
logits = model(x_test)
# 由于输出层的激活函数是线性激活函数
# 需要使用sigmoid函数将输出值映射到(0,1)之间
y_pred = tf.nn.sigmoid(logits)
其中from_logits=True表示输出层的输出值不经过激活函数,直接输出。`
其他神经网络概念
Adam优化器
Adam优化器是一种基于梯度下降的优化算法,它的主要思想是将梯度的一阶矩估计和二阶矩估计结合起来,计算出更新步长。
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
卷积层
卷积层是神经网络中的一种特殊的层,它的特点是每个神经元只看到局部的输入,而不是全局的输入。
Dense层的缺点:
- Dense层的参数量太大,导致计算量太大,训练时间太长。
- Dense层的参数量太大,容易出现过拟合的问题。
卷积层的优点:
- 卷积层的参数量较少,导致计算量较小,训练时间较短。
- 卷积层的参数量较少,容易避免过拟合的问题。