Scrapy基本使用
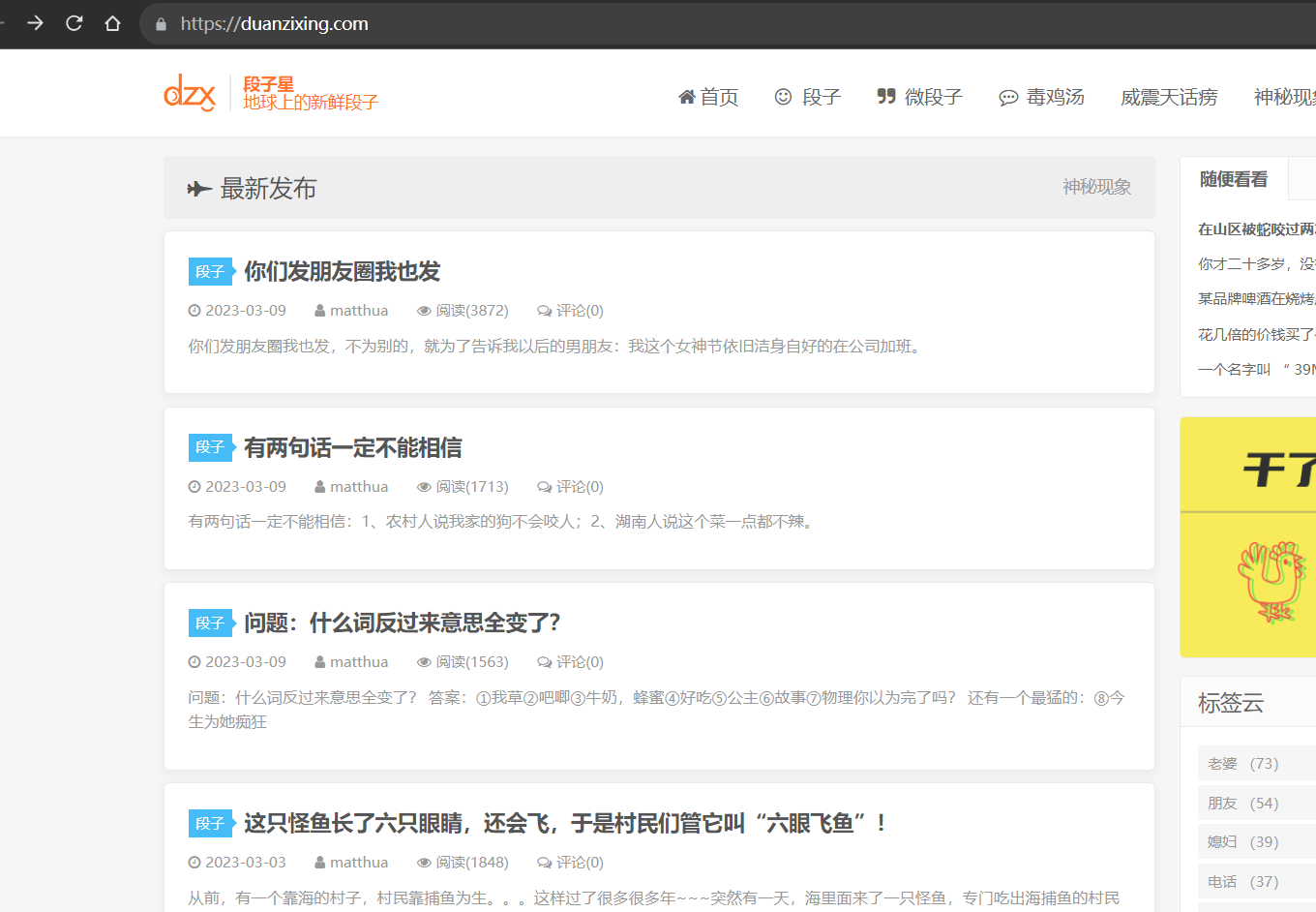
以抓取段子星中的标题和内容为例:https://duanzixing.com/
1. Windows下安装:
pip install twisted
pip install pywin32
pip install scrapy
2. 创建工程
# scrapy startproject <projectName>
scrapy startproject duanzixing
3. 新建爬虫源文件
# 进入工程目录
cd duanzixing
# 创建爬虫源文件(spiderName是一个爬虫源文件的唯一标识,www.xxx.com后续可以在源文件中更改)
# scrapy genspider <spiderName> <www.xxx.com>
scrapy genspider main www.xxx.com
4. 修改一些配置
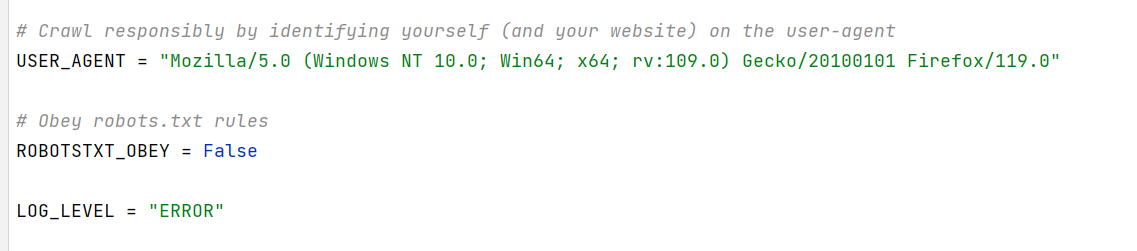
在项目目录的settings.py中修改
-
设置
User-Agent进行UA伪装USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/119.0" -
设置不遵从robots协议(如果遵守那就没什么能爬的了哈哈)
ROBOTSTXT_OBEY = False -
配置只显示错误日志信息,否则过多的日志让我们不容易看到控制台的输出信息
LOG_LEVEL = "ERROR"
5. 编写代码
main.py源文件
import scrapy
class MainSpider(scrapy.Spider):
name = "main"
# 允许的域名:用来限定start_urls中哪些url可以进行请求发送(通常都不会用)
# allowed_domains = ["www.xxx.com"] # 这个注释掉就行,基本不用
# 起始url列表:该列表中存放的url会被scrapy自动进行请求的发送
start_urls = ["https://duanzixing.com/"]
# 用作于数据解析,response参数表示的就是返回的响应对象
# start_urls中元素的个数等于该函数调用的次数
def parse(self, response):
articleList = response.xpath('//section[@class="container"]//article')
for article in articleList:
title = article.xpath('./header/h2/a/text()')[0].extract()
content = article.xpath('./p[2]/text()')[0].extract()
print(f"{title}:\n\t{content}\n")
6. 执行代码
在项目目录中执行以下代码:
# scrapy crawl <spiderName>
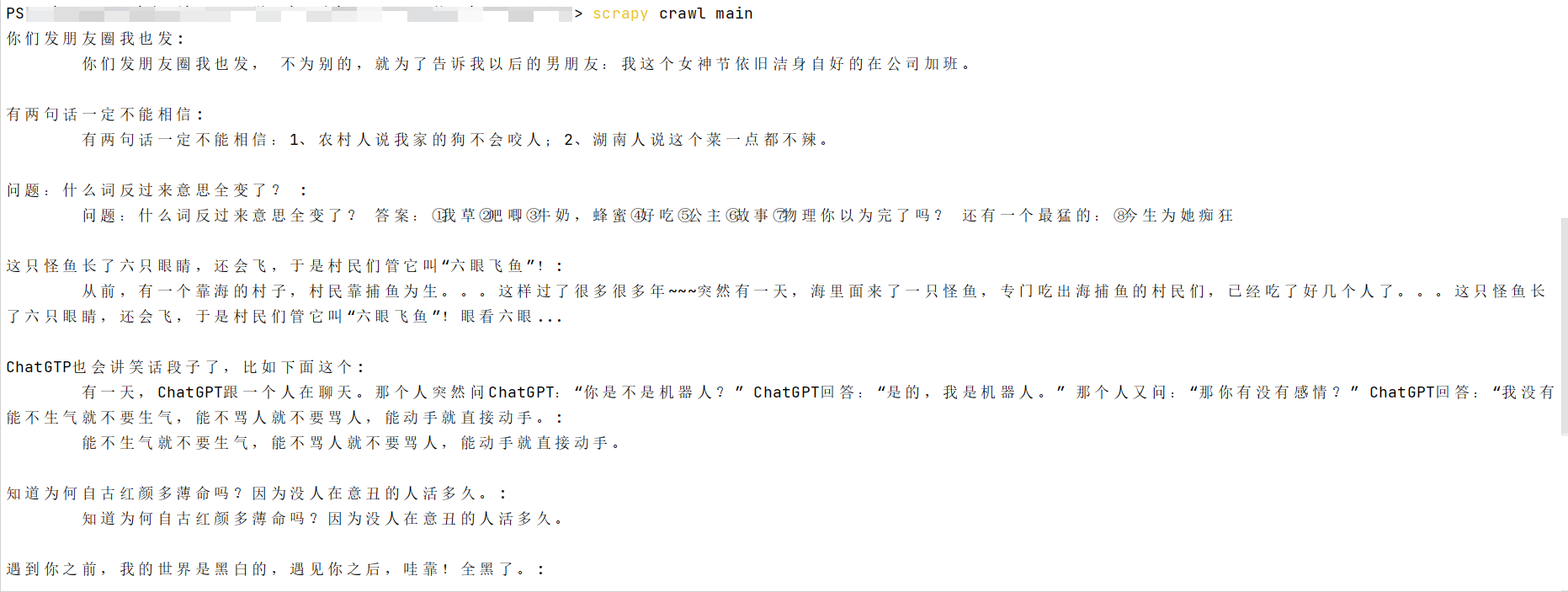
scrapy crawl main