Deep Residual Learning for Image Recognition
* Authors: [[Kaiming He]], [[Xiangyu Zhang]], [[Shaoqing Ren]], [[Jian Sun]]
- DOI: 10.1109/CVPR.2016.90
初读印象
comment:: (ResNet)提出残差链接以解决网络训练效率随着深度增加而下降的情况。
Why

网络深度对图像识别很重要,但是随着网络深度的增加,网络会退化。
- 梯度消失和梯度爆炸。
- 假设有神经网络\(x_1\xrightarrow{\omega_1}b_1\xrightarrow{\omega_2}b_2\xrightarrow{\omega_3}b_3\xrightarrow{\omega_4}b_4\xrightarrow{} output\)
- \(x_{i+1} = y_i = \sigma({z_i}) = \sigma({\omega_i}{x_i}+b_i),output = y_4\)
- \(\frac{\partial loss}{\partial \omega_1} = \frac{\partial loss}{\partial y_4}\frac{\partial y_4}{\partial z_4}\frac{\partial z_4}{\partial x_4}\frac{\partial x_4}{\partial z_3}\frac{\partial z_3}{\partial x_3}\frac{\partial x_3}{\partial z_2}\frac{\partial z_2}{\partial x_2}\frac{\partial x_2}{\partial z_1}\frac{\partial z_1}{\partial \omega_1}\)
\(=\frac{\partial loss}{\partial y_4}\sigma'(z_4)\omega_4\sigma'(z_3)\omega_3\sigma'(z_2)\omega_2\sigma'(z_1)x_1\)- \(\sigma(z)=\frac{1}{1+e^{-x}},\sigma'(z)=\sigma(z)(1-\sigma(z))\)
- 假设有神经网络\(x_1\xrightarrow{\omega_1}b_1\xrightarrow{\omega_2}b_2\xrightarrow{\omega_3}b_3\xrightarrow{\omega_4}b_4\xrightarrow{} output\)
* $\sigma'(z_i)$导致梯度消失,$\omega_i$导致梯度爆炸。
- 现有的网络无法让新增的层变为浅层的恒等映射导致模型偏离最优解。
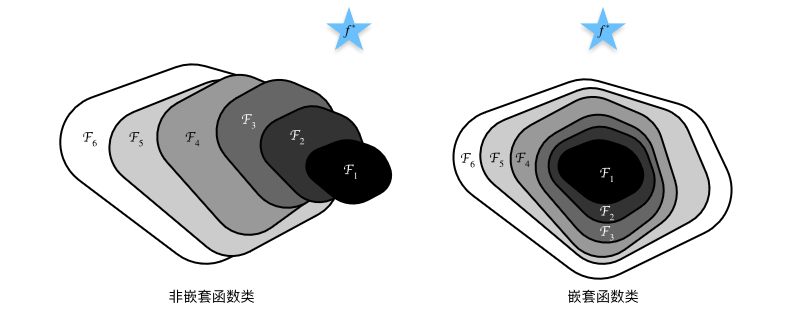
过去的解决方法:
- 选取合适的初始化权重、使用Batch Normalization可以解决梯度爆炸。
- 在早期的机器学习和深层感知机里用过一些“残差表示”和“快捷连接”方法。
What
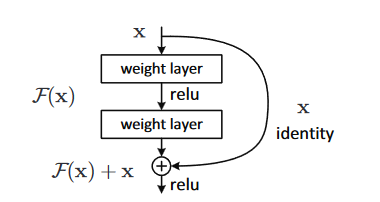
引入残差连接,每一层不再学习目标函数\(H(x)\),而是学习目标函数相较浅层值\(x\)的残差\(F(x) = H(x)-x\)
How
- 残差连接如何解决以上两大问题:
- 梯度消失:
原:\(\frac{\partial f(g(x))}{\partial \omega} = \frac{\partial f(g(x))}{\partial g(x)}\frac{\partial g(x)}{\partial \omega}\)
后:\(\frac{\partial [f(g(x))+g(x)]}{\partial \omega} = \frac{\partial f(g(x))}{\partial g(x)}\frac{\partial g(x)}{\partial \omega}+\frac{\partial g(x)}{\partial \omega}\),其中\(\frac{\partial g(x)}{\partial \omega }\)保证了梯度不会消失。 - 模型偏离最优解:深层网络是浅层网络的嵌套函数。当恒等映射已经逼近最优解时,剩余网络只需要学习最优解到恒等映射的残差即可。
- 梯度消失:
网络细节
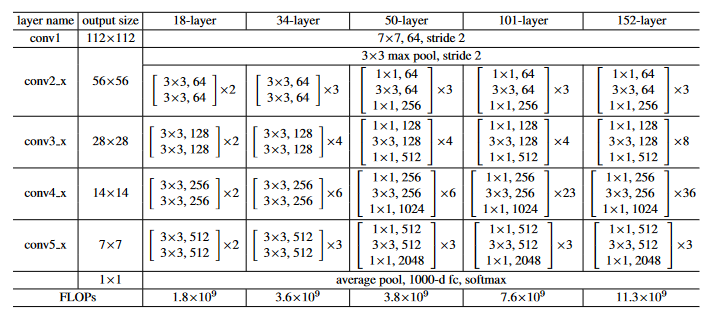
- 设计原则:
- 类似于VGG,Resnet也是由块组成的网络,根据块的输入输出维度可以把Resnet分为五个阶段
- 每个块的输入和输出中间带有“恒等映射”
- 一个块的输入和输出的feature map大小相同时,通道数不变(此时的恒等映射是直接相加)
- conv3_1, conv4_1, 和conv5_1都以步长为2做下采样,同时增加一倍的通道数(此时恒等映射需要投影:也要使用conv1×1(s2)减小map大小,增加通道数)
- 每个块的输入和输出中间带有“恒等映射”
- 类似于VGG,Resnet也是由块组成的网络,根据块的输入输出维度可以把Resnet分为五个阶段
- 不同深度resnet之间的区别:
- resnet18到resnet34:每个阶段的残差块数目增加
- resnet到resnet50:加入Bottleneck架构(保持特征通道数的同时减少运算量)。每个残差块的卷积层从2层变成3层(1×1,3×3,1×1)
- 第一个1×1:减少一半通道数(除了conv2_x不用减少)
- 第二个3×3:在减少的通道数下做卷积以减少运算量
- 第三个1×1:增加通道数为第一个卷积后的4倍(也就是原来的两倍)
具体实现
- 实现:
- 每个卷积后、激活函数前都使用Batch normalization
- batchsize=256,动量为0.9的SGD,使用0.0001的权重衰退
- 学习率初始为0.1,每次误差稳定时都缩小10倍。
- 测试时使用10-crop
- 数据增强:
- 随机把图片大小改变为[256,480]
- 从图像或其水平翻转中随机采样并裁剪为224×224大小,每个像素减去像素平均值。
- 改变颜色
Conclusion
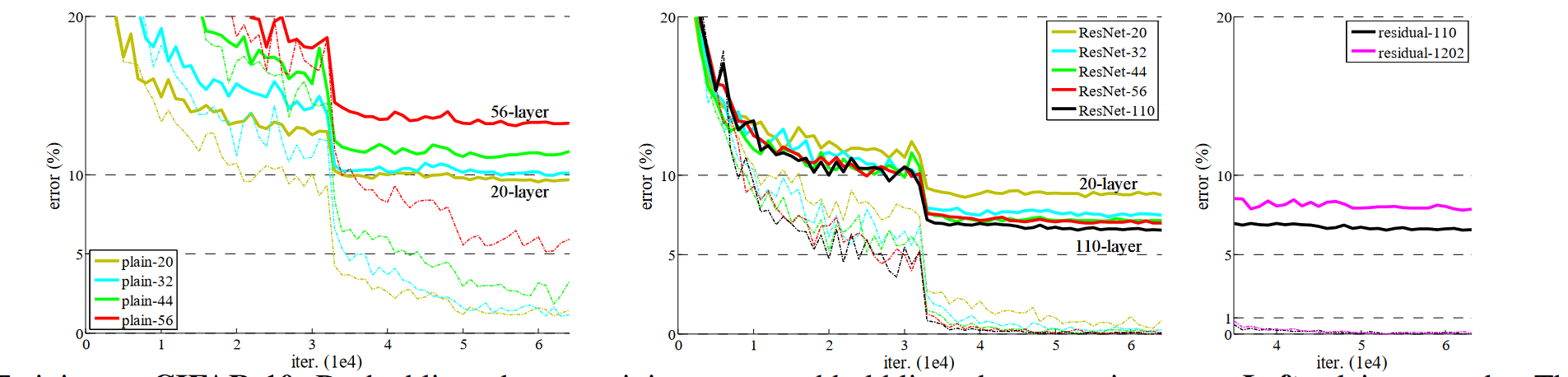 残差连接在不增加参数和模型复杂度的情况下,让深度网络更加容易训练,而且越深效果越好。
残差连接在不增加参数和模型复杂度的情况下,让深度网络更加容易训练,而且越深效果越好。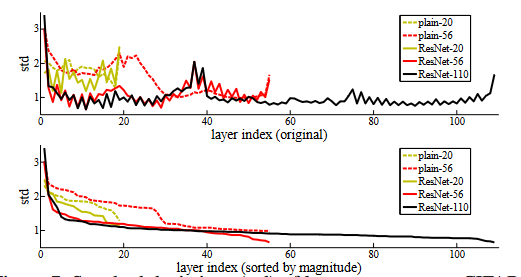
带残差的网络输出更加稳定,说明当恒等映射接近最优时,残差块学到的内容更接近0?
- Recognition Residual Learning ResNet Imagerecognition residual learning resnet recognition residual learning笔记 identification residual learning buoyancy image transformers recognition 16x image transformers recognition笔记 机器recognition learning教材 image representation continuous learning residual residual network simple cnn end-to-end end rfn-nest residual