一、背景与挖掘目标
本章通过对用户访问的网页日志数据进行分析与处理,采用基于物品的协同过滤算法对处理后的数据进行建模分析,并应用模型实现智能推荐,进行个性化推荐,帮助用户更加便捷地获取信息。
某法律网站是北京一家电子商务类的大型法律资讯网站,致力于为用户提供丰富的法律信息与专业咨询服务,本案例主要是为律师与律师事务所提供互联网整合营销解决方案。随着企业经营水平的提高,其网站访问量逐步增加,随之而来的数据信息量也在大幅增长。带来的问题是用户在面对大量信息时无法快速获取需要的信息,使得信息使用效率降低。用户在浏览、搜寻想要的信息的过程中需要花费大量的时间,这种情况的出现造成了用户的不断流失,对企业造成巨大的损失。
为了节省用户时间并帮助用户快速找到感兴趣的信息,利用网站海量的用户访问数据研究用户的兴趣偏好,分析用户的需求和行为,引导用户发现需求信息,将长尾网页准确地推荐给所需用户,帮助用户发现他们感兴趣但很难发现的网页信息。总而言之,智能推荐服务可以为用户提供个性化的服务、改善用户浏览体验、增加用户黏性、从而使用户与企业之间建立稳定的交互关系,实现客户链式反应增值。
二、分析方法与过程
(一)分析步骤与流程
为了帮助用户从海量的信息中快速发现感兴趣的网页,本案例主要采用协同过滤算法进行推荐,其推荐原理如图所示。
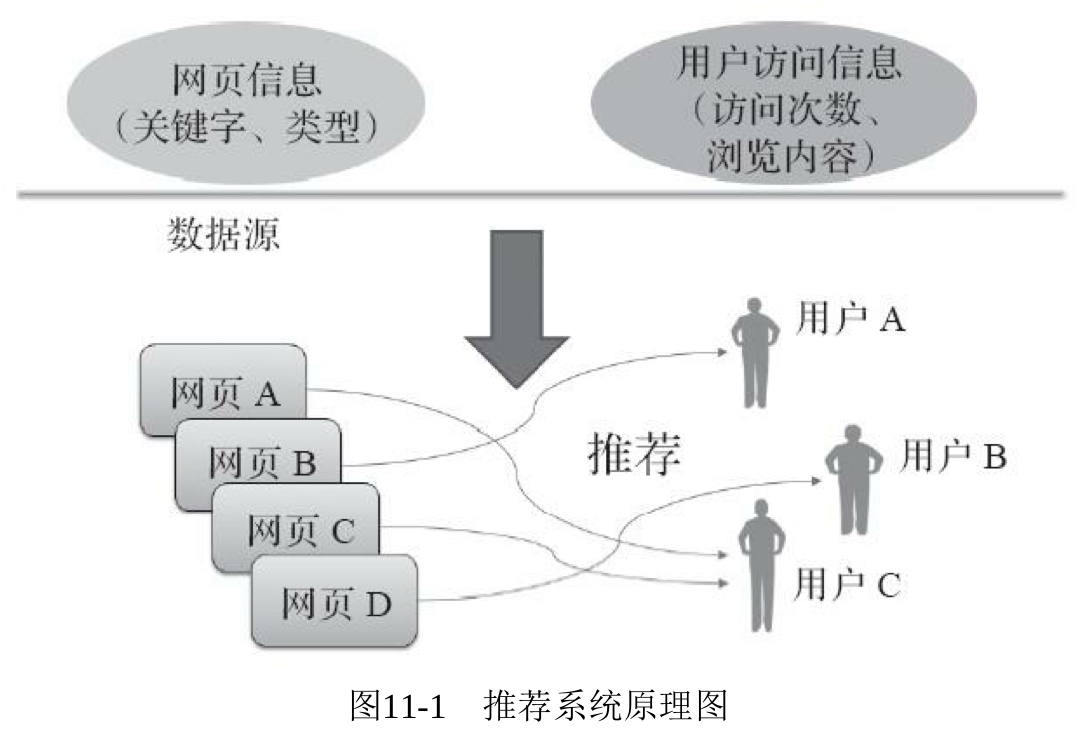
由于用户访问网站的数据记录较多,若不进行分类处理直接采用协同过滤算法进行推荐,会存在以下问题:1)数据量大说明物品数与用户数较多,在模型构建用户与物品的稀疏矩阵时,模型计算需要消耗大量的时间,并且会造成设备内存空间不足的问题。2)不同的用户关注的信息不同,其推荐结果不能满足用户的个性化需求。
为了避免上述问题,需要对用户访问记录进行分类处理与分析。在用户访问记录日志中,没有用户访问网页时间长短的记录,不能根据用户在网页的停留时间判断用户是否对浏览网页感兴趣。
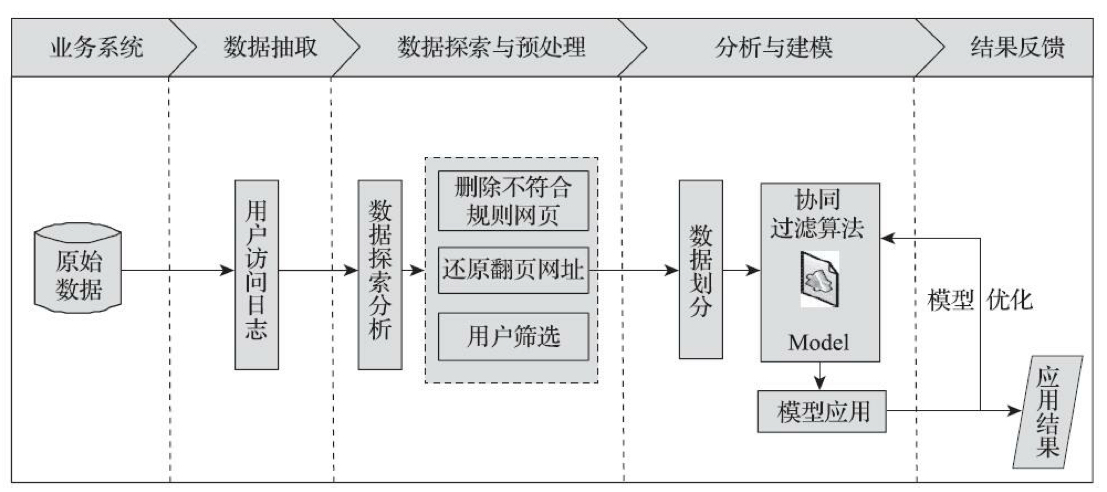
本案例采用基于用户浏览网页的类型的方法进行分类,然后对每个类型中的内容进行智能推荐。采用上述分析方法与思路,结合原始数据及分析目标,整理的网站智能推荐流程如下图所示,主要步骤如下:
1)从系统中获取用户访问网站的原始记录。
2)分析用户访问内容、用户流失等。
3)对数据进行预处理,包含数据去重、数据变换等过程。
4)以用户访问html后缀的网页为关键条件,对数据进行处理。
5)对比多种推荐算法的效果,选择效果较好的模型。通过模型预 测,获得推荐结果。
(二)数据抽取
以用户的访问时间为条件,选取3个月内(2015年2月1日至2015年4月29日)用户的访问数据作为原始数据集。由于每个地区的用户访问习惯以及兴趣爱好存在差异性,因此抽取广州地区的用户访问数据进行分析,其数据量总共有837450条,其中包括用户号、访问时间、来源网站、访问页面、页面标题、来源网页、标签、网页类别、关键词等。
在数据抽取过程中,由于数据量较大且存储在数据库中,为了提高数据处理的效率,采取用Python读取数据库的操作方式。本案例用到的数据库为开源数据库(MySQL-community-5.6.39.0)。安装数据库后导入本案例的数据原始文件7law.sql,然后可以利用Python对MySQL数据库进行连接以及其他相关操作,如以下代码。
首先在MySQL中创建test数据库,然后把表数据导入数据库,最后连接数据库并选取3个月内用户的访问数据,如以下代码所示。
1 import os 2 import pandas as pd 3 4 5 # 修改工作路径到指定文件夹 6 os.chdir("E:/大三下/数据分析/数据/第十一章") 7 8 # 第一种连接方式 9 #from sqlalchemy import create_engine 10 11 #engine = create_engine('mysql+pymysql://root:123@192.168.31.140:3306/test1?charset=utf8') 12 #sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) 13 14 # 第二种连接方式 15 import pymysql as pm 16 17 con = pm.connect(host = 'localhost',user = 'root',password = '123456',database = 'test1',charset='utf8') 18 data = pd.read_sql('select * from all_gzdata',con=con) 19 con.close() #关闭连接 20 21 # 保存读取的数据 22 data.to_csv('E:/大三下/数据分析/数据/第十一章/all_gzdata.csv', index=False, encoding='utf-8')
(三)数据探索分析
原始数据集中包括用户号、访问时间、来源网站、访问页面、页面标题、来源网页、标签、网页类别和关键词等信息,需要对原始数据进行网页类型、点击次数、网页排名等各个维度的分布分析,了解用户浏览网页的行为及关注内容,获得数据内在的规律。
1、分析网页类型
对原始数据中用户点击的网页类型进行统计分析,如以下代码所示。
1 import pandas as pd 2 from sqlalchemy import create_engine 3 4 engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test1?charset=utf8') 5 sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) 6 # 分析网页类型 7 counts = [i['fullURLId'].value_counts() for i in sql] #逐块统计 8 counts = counts.copy() 9 counts = pd.concat(counts).groupby(level=0).sum() # 合并统计结果,把相同的统计项合并(即按index分组并求和) 10 counts = counts.reset_index() # 重新设置index,将原来的index作为counts的一列。 11 counts.columns = ['index', 'num'] # 重新设置列名,主要是第二列,默认为0 12 counts['type'] = counts['index'].str.extract('(\d{3})') # 提取前三个数字作为类别id 13 counts_ = counts[['type', 'num']].groupby('type').sum() # 按类别合并 14 counts_.sort_values(by='num', ascending=False, inplace=True) # 降序排列 15 counts_['ratio'] = counts_.iloc[:,0] / counts_.iloc[:,0].sum() 16 print(counts_)
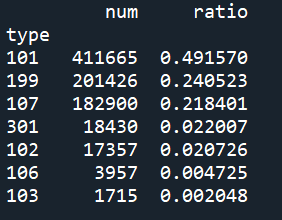
通过输出结果可以发现,点击与咨询相关(网页类型为101,http://www.****.com/ask/)的记录占了49.16%,其他类型(网页类型为199)占比24%左右,知识相关(网页类型为107,http://www.****.com/info/)占比22%左右。
根据统计结果对用户点击的页面类型进行排名,依次为咨询相关、知识相关、其他方面的网页、法规(类型为301)、律师相关(类型为102)等。然后进一步对咨询类别内部进行统计分析,如下述代码所示。
1 # 因为只有107001一类,但是可以继续细分成三类:知识内容页、知识列表页、知识首页 2 def count107(i): #自定义统计函数 3 j = i[['fullURL']][i['fullURLId'].str.contains('107')].copy() # 找出类别包含107的网址 4 j['type'] = None # 添加空列 5 j['type'][j['fullURL'].str.contains('info/.+?/')]= '知识首页' 6 j['type'][j['fullURL'].str.contains('info/.+?/.+?')]= '知识列表页' 7 j['type'][j['fullURL'].str.contains('/\d+?_*\d+?\.html')]= '知识内容页' 8 return j['type'].value_counts() 9 # 注意:获取一次sql对象就需要重新访问一下数据库(!!!) 10 #engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8') 11 sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) 12 13 counts2 = [count107(i) for i in sql] # 逐块统计 14 counts2 = pd.concat(counts2).groupby(level=0).sum() # 合并统计结果 15 print(counts2) 16 #计算各个部分的占比 17 res107 = pd.DataFrame(counts2) 18 # res107.reset_index(inplace=True) 19 res107.index.name= '107类型' 20 res107.rename(columns={'type':'num'}, inplace=True) 21 res107['比例'] = res107['num'] / res107['num'].sum() 22 res107.reset_index(inplace = True) 23 print(res107)
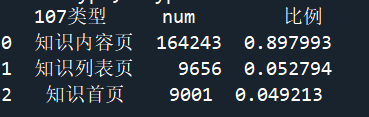
通过输出结果可以发现,浏览咨询内容页(101003)记录最多,其次是咨询列表页(101002)和咨询首页(101001)。初步分析可以得知用户都喜欢通过浏览问题的方式找到自己需要的信息,而不是以提问的方式或者查看长篇内容的方式寻找信息。
通过分析其他(199)页面的情况可知,其中网址中带有“?”的占了 32%左右,其他咨询相关与法规专题占比达到41%,地区和律师占比为 20%左右。同时,在进行网页分类过程中发现,律师、地区、咨询相关的网页还会在其他类别中存在,并且大部分是以以下网址的形式存在:
1)http://www.****.com/guangzhou/p2lawfirm,地区律师事务所。
2)http://www.****.com/guangzhou,地区网址。
3)http://www.****.com/ask/ask.php,咨询内容提交页。
4)http://www.****.com/ask/midques_10549897.html,中间类型网 页。
5)http://www.****.com/ask/exp/4317.html,咨询经验。
6)http://www.****.com/ask/online/138.html,在线咨询页。
首先是网址中带有lawfirm关键字的对应律师事务所,其次是带有 ask/exp、ask/online关键字的对应咨询经验和在线咨询页。大多数用户浏览网页的情况为咨询内容页、知识内容页、法规专题页、在线咨询页等,其中咨询内容页和知识内容页占比最高。对原始数据的网址中带“?”的数据进行统计,如以下代码所示。
1 def countquestion(i): # 自定义统计函数 2 j = i[['fullURLId']][i['fullURL'].str.contains('\?')].copy() # 找出类别包含107的网址 3 return j 4 5 #engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8') 6 sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) 7 8 counts3 = [countquestion(i)['fullURLId'].value_counts() for i in sql] 9 counts3 = pd.concat(counts3).groupby(level=0).sum() 10 print(counts3) 11 12 # 求各个类型的占比并保存数据 13 df1 = pd.DataFrame(counts3) 14 df1['perc'] = df1['fullURLId']/df1['fullURLId'].sum()*100 15 df1.sort_values(by='fullURLId',ascending=False,inplace=True) 16 print(df1.round(4))
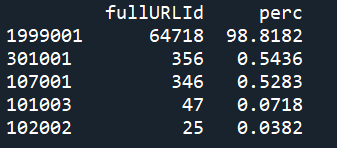
通过输出结果可以看出,网址中带有“?”的记录一共有65492条,且不仅仅出现在其他类别中,同时也会出现在咨询内容页和知识内容页中,但在其他类型(1999001)中占比最高,可达到98.82%。因此需要进一 步分析其类型内部的规律,如以下代码所示。
1 def page199(i): #自定义统计函数 2 j = i[['fullURL','pageTitle']][(i['fullURLId'].str.contains('199')) & 3 (i['fullURL'].str.contains('\?'))] 4 j['pageTitle'].fillna('空',inplace=True) 5 j['type'] = '其他' # 添加空列 6 j['type'][j['pageTitle'].str.contains('法律快车-律师助手')]= '法律快车-律师助手' 7 j['type'][j['pageTitle'].str.contains('咨询发布成功')]= '咨询发布成功' 8 j['type'][j['pageTitle'].str.contains('免费发布法律咨询' )] = '免费发布法律咨询' 9 j['type'][j['pageTitle'].str.contains('法律快搜')] = '快搜' 10 j['type'][j['pageTitle'].str.contains('法律快车法律经验')] = '法律快车法律经验' 11 j['type'][j['pageTitle'].str.contains('法律快车法律咨询')] = '法律快车法律咨询' 12 j['type'][(j['pageTitle'].str.contains('_法律快车')) | 13 (j['pageTitle'].str.contains('-法律快车'))] = '法律快车' 14 j['type'][j['pageTitle'].str.contains('空')] = '空' 15 16 return j 17 18 # 注意:获取一次sql对象就需要重新访问一下数据库 19 #engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8') 20 sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)# 分块读取数据库信息 21 #sql = pd.read_sql_query('select * from all_gzdata limit 10000', con=engine) 22 23 counts4 = [page199(i) for i in sql] # 逐块统计 24 counts4 = pd.concat(counts4) 25 d1 = counts4['type'].value_counts() 26 print(d1) 27 d2 = counts4[counts4['type']=='其他'] 28 print(d2) 29 # 求各个部分的占比并保存数据 30 df1_ = pd.DataFrame(d1) 31 df1_['perc'] = df1_['type']/df1_['type'].sum()*100 32 df1_.sort_values(by='type',ascending=False,inplace=True) 33 print(df1_)

通过输出结果可以看出,在1999001类型中,标题为“快车—律师助手”这类信息占比为77.09%,这类页面是律师的登录页面。标题为“咨询 发布成功”类信息占比为8.07%,这类页面是自动跳转页面。其他类型的页面大部分为http://www.****.com/ask/question_9152354.html?&from=androidqq类型的网页。根据业务了解该类网页为被分享过的网 页,这类网页需要对其进行处理,处理方式为截取网址中“?”前面的网址并还原网址类型。
在采取截取网址“?”前面网址的处理过程中发现,快搜网址中的类型混杂,不能直接处理。考虑其数据集占比较小,所以在数据处理环节对这部分数据进行删除。同时分析其他类型的网址得出,不包含主网址和关键字的网址有359条记录,如http://www.baidu.com/link?url=O7iBD2KmoJdkHWTZHagDXrxfBFM0AwLmpid12j2d_aejNfq6bwSBe1Ov2jWOFMpIt5XUpXGmNiLDlGg0rMCwstskhB5ftAYtO2_voEnu。
访问记录中有一部分用户并没有点击具体的网页,这类网页以“.html”后缀结尾,且大部分是目录网页,这样的用户可以称为“瞎逛”,漫无目的,总共有165654条记录,统计过程如以下代码所示。
1 #统计无目的浏览用户中各个类型占比 2 def xiaguang(i): #自定义统计函数 3 j = i.loc[(i['fullURL'].str.contains('\.html'))==False, 4 ['fullURL','fullURLId','pageTitle']] 5 return j 6 7 # 注意获取一次sql对象就需要重新访问一下数据库 8 engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test1?charset=utf8') 9 sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)# 分块读取数据库信息 10 11 counts5 = [xiaguang(i) for i in sql] 12 counts5 = pd.concat(counts5) 13 14 xg1 = counts5['fullURLId'].value_counts() 15 print(xg1) 16 # 求各个部分的占比 17 xg_ = pd.DataFrame(xg1) 18 xg_.reset_index(inplace=True) 19 xg_.columns= ['index', 'num'] 20 xg_['perc'] = xg_['num']/xg_['num'].sum()*100 21 xg_.sort_values(by='num',ascending=False,inplace=True) 22 23 xg_['type'] = xg_['index'].str.extract('(\d{3})') #提取前三个数字作为类别id 24 25 xgs_ = xg_[['type', 'num']].groupby('type').sum() #按类别合并 26 xgs_.sort_values(by='num', ascending=False,inplace=True) #降序排列 27 xgs_['percentage'] = xgs_['num']/xgs_['num'].sum()*100 28 29 print(xgs_.round(4))
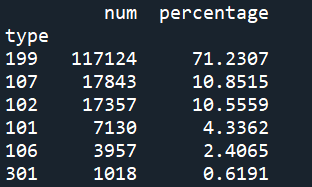
通过输出结果可以看出,小部分网页类型是与知识、咨询相关的,大部分网页类型是与地区、律师和事物所相关的,这类用户可能是找律师服务的,也可能是“瞎逛”的。
综合以上分析,得到一些与分析目标无关数据的规则,记录这些规则有利于在数据清洗阶段对数据进行清洗操作。
1)咨询发布成功页面。 2)中间类型网页(带有midques_关键字)。 3)网址中带有“?”类型,无法还原其本身类型的快搜网页。 4)重复数据(同一时间同一用户,访问相同网页)。 5)其他类别的数据(主网址不包含关键字)。 6)无点击“.html”行为的用户记录。 7)律师的行为记录(通过快车—律师助手判断)。
2、分析网页点击次数
统计原始数据中用户浏览网页次数的情况,如以下代码所示。
1 # 分析网页点击次数 2 # 统计点击次数 3 engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test1?charset=utf8') 4 sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)# 分块读取数据库信息 5 6 counts1 = [i['realIP'].value_counts() for i in sql] # 分块统计各个IP的出现次数 7 counts1 = pd.concat(counts1).groupby(level=0).sum() # 合并统计结果,level=0表示按照index分组 8 print(counts1) 9 10 counts1_ = pd.DataFrame(counts1) 11 counts1_ 12 counts1['realIP'] = counts1.index.tolist() 13 14 counts1_[1]=1 # 添加1列全为1 15 hit_count = counts1_.groupby('realIP').sum() # 统计各个“不同点击次数”分别出现的次数 16 # 也可以使用counts1_['realIP'].value_counts()功能 17 hit_count.columns=['用户数'] 18 hit_count.index.name = '点击次数' 19 20 # 统计1~7次、7次以上的用户人数 21 hit_count.sort_index(inplace = True) 22 hit_count_7 = hit_count.iloc[:7,:] 23 time = hit_count.iloc[7:,0].sum() # 统计点击次数7次以上的用户数 24 hit_count_7 = hit_count_7.append([{'用户数':time}], ignore_index=True) 25 hit_count_7.index = ['1','2','3','4','5','6','7','7次以上'] 26 hit_count_7['用户比例'] = hit_count_7['用户数'] / hit_count_7['用户数'].sum() 27 print(hit_count_7)
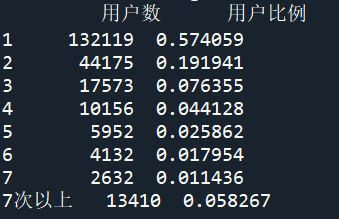
根据统计结果可知,浏览一次的用户最多,占所有用户的58%左右。
分析浏览次数为一次的用户的行为,如以下代码。
1 # 分析浏览一次的用户行为 2 3 engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test1?charset=utf8') 4 all_gzdata = pd.read_sql_table('all_gzdata', con = engine) # 读取all_gzdata数据 5 6 #对realIP进行统计 7 # 提取浏览1次网页的数据 8 real_count = pd.DataFrame(all_gzdata.groupby("realIP")["realIP"].count()) 9 real_count.columns = ["count"] 10 real_count["realIP"] = real_count.index.tolist() 11 user_one = real_count[(real_count["count"] == 1)] # 提取只登录一次的用户 12 # 通过realIP与原始数据合并 13 real_one = pd.merge(user_one, all_gzdata, left_on="realIP", right_on="realIP") 14 15 # 统计浏览一次的网页类型 16 URL_count = pd.DataFrame(real_one.groupby("fullURLId")["fullURLId"].count()) 17 URL_count.columns = ["count"] 18 URL_count.sort_values(by='count', ascending=False, inplace=True) # 降序排列 19 # 统计排名前4和其他的网页类型 20 URL_count_4 = URL_count.iloc[:4,:] 21 time = hit_count.iloc[4:,0].sum() # 统计其他的 22 URLindex = URL_count_4.index.values 23 URL_count_4 = URL_count_4.append([{'count':time}], ignore_index=True) 24 URL_count_4.index = [URLindex[0], URLindex[1], URLindex[2], URLindex[3], 25 '其他'] 26 URL_count_4['比例'] = URL_count_4['count'] / URL_count_4['count'].sum() 27 print(URL_count_4)
(四)数据预处理
1、删除不符合规则的网页
通过分析原始数据发现,不符合规则的网页包括中间页面的网址、咨询发布成功页面、律师登录助手页面等,需要对其进行删除处理,如以下代码所示。
1 # 删除不符合规则的网页 2 import os 3 import re 4 import pandas as pd 5 import pymysql as pm 6 from random import sample 7 8 # 修改工作路径到指定文件夹 9 os.chdir("E:/大三下/数据分析/数据/第十一章") 10 11 # 读取数据 12 con = pm.connect(host = 'localhost',user = 'root',password = '123456',database = 'test1',charset='utf8') 13 data = pd.read_sql('select * from all_gzdata',con=con) 14 con.close() # 关闭连接 15 16 # 取出107类型数据 17 index107 = [re.search('107',str(i))!=None for i in data.loc[:,'fullURLId']] 18 data_107 = data.loc[index107,:] 19 20 # 在107类型中筛选出婚姻类数据 21 index = [re.search('hunyin',str(i))!=None for i in data_107.loc[:,'fullURL']] 22 data_hunyin = data_107.loc[index,:] 23 24 # 提取所需字段(realIP、fullURL) 25 info = data_hunyin.loc[:,['realIP','fullURL']] 26 27 # 去除网址中“?”及其后面内容 28 da = [re.sub('\?.*','',str(i)) for i in info.loc[:,'fullURL']] 29 info.loc[:,'fullURL'] = da # 将info中‘fullURL’那列换成da 30 # 去除无html网址 31 index = [re.search('\.html',str(i))!=None for i in info.loc[:,'fullURL']] 32 index.count(True) # True 或者 1 , False 或者 0 33 info1 = info.loc[index,:]
清洗后数据依旧存在大量的目录网页(可理解为用户浏览信息的路径),这类网页不但对构建推荐系统没有作用,反而会影响推荐结果的准确性,同样需要处理。
2、还原翻页网址
本案例主要对知识相关的网页类型数据进行分析。处理翻页情况最直接的方法是将翻页的网址删掉,但是用户是通过搜索引擎进入网站的,访问入口不一定是原始页面,采取删除方法会损失大量有效数据,影响推荐结果。因此对该类网页的处理方式是:首先识别翻页的网址,然后对翻页的网址进行还原,最后针对每个用户访问的页面进行去重操作,如以下代码所示。
1 # 找出翻页和非翻页网址 2 index = [re.search('/\d+_\d+\.html',i)!=None for i in info1.loc[:,'fullURL']] 3 index1 = [i==False for i in index] 4 info1_1 = info1.loc[index,:] # 带翻页网址 5 info1_2 = info1.loc[index1,:] # 无翻页网址 6 # 将翻页网址还原 7 da = [re.sub('_\d+\.html','.html',str(i)) for i in info1_1.loc[:,'fullURL']] 8 info1_1.loc[:,'fullURL'] = da 9 # 翻页与非翻页网址合并 10 frames = [info1_1,info1_2] 11 info2 = pd.concat(frames) 12 # 或者 13 info2 = pd.concat([info1_1,info1_2],axis = 0) # 默认为0,即行合并 14 # 去重(realIP和fullURL两列相同) 15 info3 = info2.drop_duplicates() 16 # 将IP转换成字符型数据 17 info3.iloc[:,0] = [str(index) for index in info3.iloc[:,0]] 18 info3.iloc[:,1] = [str(index) for index in info3.iloc[:,1]] 19 len(info3)
3、筛去浏览次数不满两次的用户
根据数据探索的结果可知,数据中存在大量仅浏览一次就跳出的用户,浏览次数在两次及以上的用户的浏览记录更适于推荐,而浏览次数仅一次的用户的浏览记录进入推荐模型会影响推荐模型的效果,因此需要筛去浏览次数不满两次的用户,如以下代码所示。
1 # 筛选满足一定浏览次数的IP 2 IP_count = info3['realIP'].value_counts() 3 # 找出IP集合 4 IP = list(IP_count.index) 5 count = list(IP_count.values) 6 # 统计每个IP的浏览次数,并存放进IP_count数据框中,第一列为IP,第二列为浏览次数 7 IP_count = pd.DataFrame({'IP':IP,'count':count}) 8 # 3.3筛选出浏览网址在n次以上的IP集合 9 n = 2 10 index = IP_count.loc[:,'count']>n 11 IP_index = IP_count.loc[index,'IP']
4、划分数据集
将数据集按8:2的比例划分为训练集和测试集。
1 # 划分IP集合为训练集和测试集 2 index_tr = sample(range(0,len(IP_index)),int(len(IP_index)*0.8)) # 或者np.random.sample 3 index_te = [i for i in range(0,len(IP_index)) if i not in index_tr] 4 IP_tr = IP_index[index_tr] 5 IP_te = IP_index[index_te] 6 # 将对应数据集划分为训练集和测试集 7 index_tr = [i in list(IP_tr) for i in info3.loc[:,'realIP']] 8 index_te = [i in list(IP_te) for i in info3.loc[:,'realIP']] 9 data_tr = info3.loc[index_tr,:] 10 data_te = info3.loc[index_te,:] 11 print(len(data_tr)) 12 IP_tr = data_tr.iloc[:,0] # 训练集IP 13 url_tr = data_tr.iloc[:,1] # 训练集网址 14 IP_tr = list(set(IP_tr)) # 去重处理 15 url_tr = list(set(url_tr)) # 去重处理 16 len(url_tr)
(五)构建智能推荐模型
1、模型构建
将训练集中的数据转换成0-1二元型数据,使用ItemCF算法对数据进行建模,并给出预测推荐结果。
1 import pandas as pd 2 # 利用训练集数据构建模型 3 UI_matrix_tr = pd.DataFrame(0,index=IP_tr,columns=url_tr) 4 # 求用户-物品矩阵 5 for i in data_tr.index: 6 UI_matrix_tr.loc[data_tr.loc[i,'realIP'],data_tr.loc[i,'fullURL']] = 1 7 sum(UI_matrix_tr.sum(axis=1)) 8 9 # 求物品相似度矩阵(因计算量较大,需要耗费的时间较久) 10 Item_matrix_tr = pd.DataFrame(0,index=url_tr,columns=url_tr) 11 for i in Item_matrix_tr.index: 12 for j in Item_matrix_tr.index: 13 a = sum(UI_matrix_tr.loc[:,[i,j]].sum(axis=1)==2) 14 b = sum(UI_matrix_tr.loc[:,[i,j]].sum(axis=1)!=0) 15 Item_matrix_tr.loc[i,j] = a/b 16 17 # 将物品相似度矩阵对角线处理为零 18 for i in Item_matrix_tr.index: 19 Item_matrix_tr.loc[i,i]=0 20 21 # 利用测试集数据对模型评价 22 IP_te = data_te.iloc[:,0] 23 url_te = data_te.iloc[:,1] 24 IP_te = list(set(IP_te)) 25 url_te = list(set(url_te)) 26 27 # 测试集数据用户物品矩阵 28 UI_matrix_te = pd.DataFrame(0,index=IP_te,columns=url_te) 29 for i in data_te.index: 30 UI_matrix_te.loc[data_te.loc[i,'realIP'],data_te.loc[i,'fullURL']] = 1 31 32 # 对测试集IP进行推荐 33 Res = pd.DataFrame('NaN',index=data_te.index, 34 columns=['IP','已浏览网址','推荐网址','T/F']) 35 Res.loc[:,'IP']=list(data_te.iloc[:,0]) 36 Res.loc[:,'已浏览网址']=list(data_te.iloc[:,1]) 37 38 # 开始推荐 39 for i in Res.index: 40 if Res.loc[i,'已浏览网址'] in list(Item_matrix_tr.index): 41 Res.loc[i,'推荐网址'] = Item_matrix_tr.loc[Res.loc[i,'已浏览网址'], 42 :].argmax() 43 if Res.loc[i,'推荐网址'] in url_te: 44 Res.loc[i,'T/F']=UI_matrix_te.loc[Res.loc[i,'IP'], 45 Res.loc[i,'推荐网址']]==1 46 else: 47 Res.loc[i,'T/F'] = False 48 49 # 保存推荐结果 50 Res.to_csv('E:/大三下/数据分析/数据/第十一章/Res.csv',index=False,encoding='utf8')
2、模型评价
计算推荐结果的准确率、召回率和F1指标。
1 import pandas as pd 2 # 读取保存的推荐结果 3 Res = pd.read_csv('./tmp/Res.csv',keep_default_na=False, encoding='utf8') 4 5 # 计算推荐准确率 6 Pre = round(sum(Res.loc[:,'T/F']=='True') / (len(Res.index)-sum(Res.loc[:,'T/F']=='NaN')), 3) 7 8 print(Pre) 9 10 # 计算推荐召回率 11 Rec = round(sum(Res.loc[:,'T/F']=='True') / (sum(Res.loc[:,'T/F']=='True')+sum(Res.loc[:,'T/F']=='NaN')), 3) 12 13 print(Rec) 14 15 # 计算F1指标 16 F1 = round(2*Pre*Rec/(Pre+Rec),3) 17 print(F1)