| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 个人项目 |
| 这个作业的目标 | 熟悉软件开发整体流程 |
GitHub链接?:https://github.com/HaoDavis/3121004649
计算模块接口的设计与实现过程
get_file_contents 函数
- 读取文本。
- 去除文本中的“\n”(即将一篇文章展开成一行)。
filter 函数
-
利用 jieba.lcut 函数将文本串分词。
例如:
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式 print(", ".join(seg_list))Run:
他, 来到, 了, 网易, 杭研, 大厦 -
去除标点符号
calc_similarity 函数
- 将文本中的单词映射到唯一的整数标识符
- 转换为词袋
词袋(Bag of Words,简称BoW)是一种在自然语言处理(NLP)中常用的文本表示方法,用于将文本数据转换为数字形式,以便计算机可以处理和分析。
- 丢弃词序信息:词袋模型忽略了文本中单词的顺序,只关注文本中包含哪些单词以及它们的频率。
- 单词独立性:词袋模型假设文本中的单词是相互独立的,即不考虑单词之间的语法和语义关系。
- 计算词袋中所有词的频率
- 计算余弦相似度
函数间关系

计算模块接口部分的性能改进
改进思路
主要在于 filter 函数。采用正则表达式的方法,筛选字符,仅保留中文、数字、英文。
性能分析图
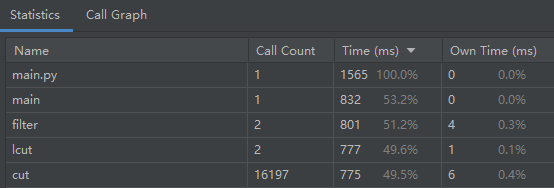
消耗最大的函数
# 主函数
def main(original_file, plagiarized_file, output_file):
if not os.path.exists(original_file):
print("原文文件不存在")
sys.exit(1)
if not os.path.exists(plagiarized_file):
print("抄袭版论文文件不存在")
sys.exit(2)
# 记录程序开始时间
start_time = time.time()
# 读取原文件和抄袭文件
str1 = get_file_contents(original_file)
str2 = get_file_contents(plagiarized_file)
text1 = filter(str1)
text2 = filter(str2)
# 计算相似度
similarity = calc_similarity(text1, text2)
# 将相似度写入输出文件
with open(output_file, 'w', encoding='utf-8') as file:
file.write(f"文件{original_file}和文件{plagiarized_file}的相似度为:{similarity:.2f}")
# 记录程序结束时间
end_time = time.time()
print(f"相似度: {similarity:.2f} | 运行时间: {end_time - start_time:.2f}秒")
计算模块部分单元测试展示
单元测试
利用unittest单元测试框架,实现单元测试自动化。以下仅列举部分用例。
测试文本预处理函数。
用简单的句子测试能否正确分词,以及去除标点符号。
def test_filter(self):
# 测试文本预处理函数是否正确
text = "这是一个测试文本,包含标点符号!"
filtered_text = filter(text)
expected_result = ['这是', '一个', '测试', '文本', '包含', '标点符号']
self.assertEqual(filtered_text, expected_result)
测试相似度计算函数
用值为 0 1 的情形进行简单的测试。
def test_calc_similarity1(self):
# 测试相似度计算函数是否正确
text1 = "这是一个测试文本,包含标点符号!"
text2 = "这是一个测试文本,包含标点符号!"
text1 = filter(text1)
text2 = filter(text2)
similarity = calc_similarity(text1, text2)
self.assertEqual(similarity, 1)
def test_calc_similarity0(self):
# 测试相似度计算函数是否正确
text1 = "这是一个测试文本,包含标点符号!"
text2 = ""
text1 = filter(text1)
text2 = filter(text2)
similarity = calc_similarity(text1, text2)
self.assertEqual(similarity, 0)
测试主函数
def test_main_test2(self):
# 测试主函数是否正确
original_file = 'test/orig.txt'
plagiarized_file = 'test/empty.txt'
output_file = 'test/output.txt'
main_test(original_file, plagiarized_file, output_file)
with open(output_file, 'r', encoding='utf-8') as file:
result = file.read()
expected_result = "文件test/orig.txt和文件test/empty.txt的相似度为:0.00"
self.assertEqual(result, expected_result)
def test_main_test7(self):
# 测试主函数是否正确
original_file = 'test/orig.txt'
plagiarized_file = 'test/orig_del.txt'
output_file = 'test/output.txt'
main_test(original_file, plagiarized_file, output_file)
with open(output_file, 'r', encoding='utf-8') as file:
result = file.read()
expected_result = "文件test/orig.txt和文件test/orig_del.txt的相似度为:0.81"
self.assertEqual(result, expected_result)
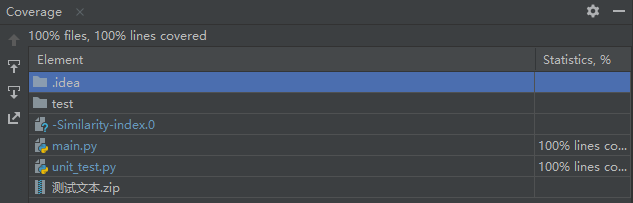
测试覆盖率
代码覆盖率100%,满足要求:
计算模块部分异常处理说明
异常1
场景
原文文件或抄袭版论文文件的文件路径不存在的情形。
设计目标
提示用户哪个文件的文件路径不存在,并退出程序。
if not os.path.exists(original_file):
print("原文文件不存在")
sys.exit(1)
if not os.path.exists(plagiarized_file):
print("抄袭版论文文件不存在")
sys.exit(2)
单元测试样例
def test_main_test6(self):
# 测试原文文件不存在的情形
original_file = 'test/orig1.txt'
plagiarized_file = 'test/orig_0.8_dis_15.txt'
output_file = 'test/output.txt'
# 如果原文文件不存在,应该打印错误消息并返回非零退出码
with self.assertRaises(SystemExit) as cm:
main(original_file, plagiarized_file, output_file)
# 检查退出码是否为1(表示错误退出)
self.assertEqual(cm.exception.code, 1)
def test_main_test8(self):
# 测试抄袭文件不存在的情形
original_file = 'test/orig.txt'
plagiarized_file = 'test/orig_0.txt'
output_file = 'test/output.txt'
# 如果抄袭文件不存在,应该打印错误消息并返回非零退出码
with self.assertRaises(SystemExit) as cm:
main(original_file, plagiarized_file, output_file)
# 检查退出码是否为2(表示错误退出)
self.assertEqual(cm.exception.code, 2)
附录
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 180 | 200 |
| Analysis | 需求分析 (包括学习新技术) | 120 | 30 |
| Design Spec | 生成设计文档 | 60 | 45 |
| Design Review | 设计复审 | 30 | 15 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 10 |
| Design | 具体设计 | 10 | 20 |
| Coding | 具体编码 | 120 | 120 |
| Code Review | 代码复审 | 10 | 5 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 20 |
| Reporting | 报告 | 30 | 20 |
| Test Repor | 测试报告 | 20 | 10 |
| Size Measurement | 计算工作量 | 5 | 5 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 5 | 5 |
| Total | 合计 | 690 | 525 |