创建hadoop用户
首先打开终端窗口,输入如下命令创建hadoop用户,这条命令创建可以登录的hadoop用户,并使用/bin/bash作为shell:
$ sudo useradd -m hadoop -s /bin/bash
接着为hadoop设置登录密码,可简单设为123456,按提示输入两次:
$ sudo passwd hadoop
为 hadoop 用户增加管理员权限,方便安装配置:
$ sudo adduser hadoop sudo
切换至hadoop用户,hadoop的安装和配置都是在hadoop用户下进行,提示时输入hadoop的用户名密码123456:
$ su hadoop
更新apt
切换hadoop用户后需要更新一下apt-get,因为后续需要 apt 安装软件,如果没更新可能有一些软件安装不了。
$ sudo apt-get update
后续需要编辑一些配置文件,安装vim工具:
$ sudo apt-get install -y vim
安装SSH、配置SSH无密码登录
1、hadoop不管是集群、单机版都需要用到 SSH 登陆,系统默认已安装了 SSH client,此外还需要安装 SSH server:
$ sudo apt-get install openssh-server
2、安装后,尝试登陆本机,提示时输入yes,然后按提示输入密码123456:
$ ssh localhost
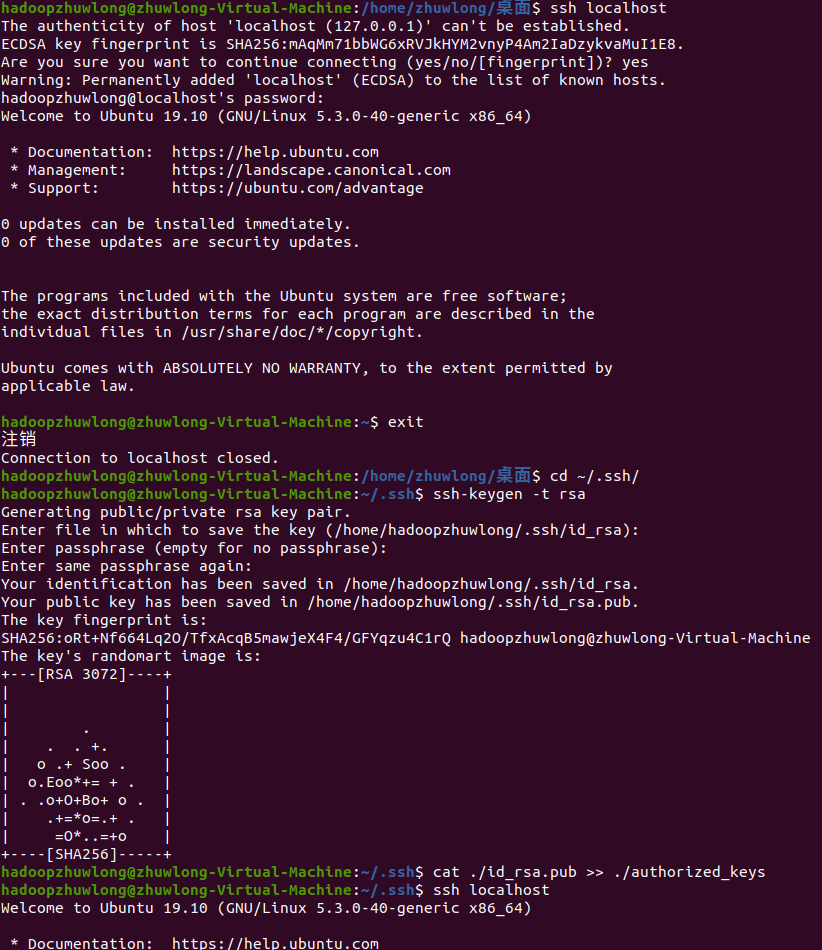
3、在hadoop中,我们需要配置成SSH无密码登陆,首先退出输入exit,退出刚才的 ssh,回到我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
$ exit # 退出刚才的 ssh localhost
$ cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
$ ssh-keygen -t rsa # 会有提示,都按回车就可以
$ cat ./id_rsa.pub >> ./authorized_keys # 加入授权
4、此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了,如下图所示:
$ ssh localhost
$ exit
安装java环境
hadoop的运行依赖java环境,使用下面的命令,如果出现以下输出,说明没有安装java
$ java -version
使用以下命令安装java:
$ sudo apt-get install -y default-jdk
查询java版本,系统响应已安装的java版本时,代表已经成功安装了jdk:
$ java -version

2.5安装hadoop
hadoop可以到官网下载,首先访问hadoop官网https://archive.apache.org/dist/hadoop/common/ 找到Hadoop相应的版本,然后复制其版本连接,或者也可以到国内镜像站查找对应版本。
在终端中执行命令下载hadoop (wget 后面的链接就是刚才复制的hadoop链接):
$ cd /usr/local/
$ sudo wget
解压文件并重命名:
$ sudo tar -zxvf hadoop-2.7.0.tar.gz
$ sudo mv ./hadoop-2.7.0/ ./hadoop # 将文件夹名改为hadoop
$ sudo chown -R hadoop ./hadoop

配置hadoop环境
查看java的安装路径,从图可以得知,java安装在/usr/lib/jvm/java-11-openjdk-amd64:
$ update-alternatives --display Java
编辑~/.bashrc:
$ sudo vim ~/.bashrc
按“insert”建,如图输入如下内容(复制粘贴即可):
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-DJava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
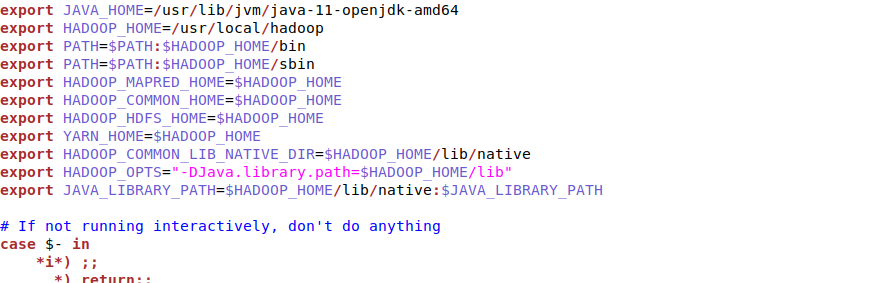
编辑完之后按“Esc”键,输入“:wq”退出。然后让~/.bashrc设置生效。
$ source ~/.bashrc
编辑hadoop-env.sh文件(和上面两个步骤一样)
$ sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
在hadoop-env.sh中export JAVA_HOME后面添加以下信息(JAVA_HOME路径改为实际路径):
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop/

保存之后运行下面命令使配置生效
$ source /usr/local/hadoop/etc/hadoop/hadoop-env.sh
查看java和hadoop环境配置
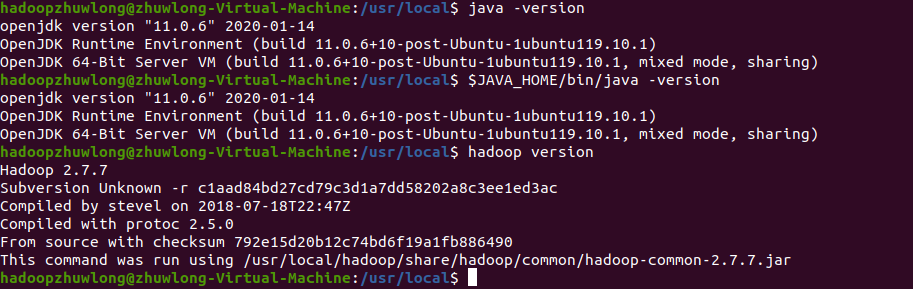
如图,输入命令查看java和hadoop版本信息,说明环境配置成功
$ java -version
$ JAVA_HOME/bin/java -version
$ hadoop version
测试
在hadoop目录下新建input文件夹
$ cd /usr/local/hadoop
$ sudo mkdir input
将etc中的所有文件拷贝到input文件夹中
$ sudo cp -r etc/* input

在hadoop目录下运行wordcount程序,并将结果保存到output中(注意input所在路径、jar所在路径)
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar wordcount input/hadoop output
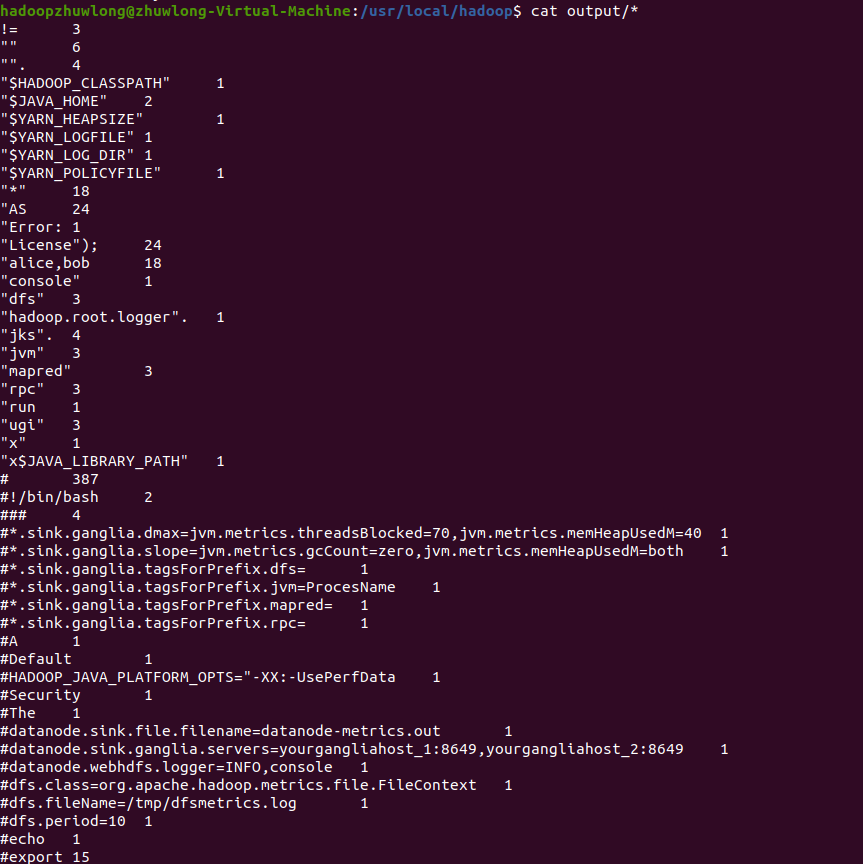
会看到conf所有文件的单词和频数都被统计出来。
$ cat output/*
注意的是,因为hadoop无法覆盖原来的文件,所以当执行了一次程序后想再次执行,需要手动删除output文件夹。