一、选题的背景
背景:
Python是一种功能强大的编程语言,广泛应用于数据科学和数据分析领域。在当今的数字时代,视频分享平台如YouTube已成为信息传播和内容创作的重要渠道。越来越多的YouTubers(YouTube创作者)致力于通过数据驱动的方法来优化他们的创作策略,以吸引更多的观众和提升视频的表现。
对于YouTubers来说,了解和分析他们的数据是非常重要的,因为这可以提供有价值的见解和指导,帮助他们更好地了解自己的观众、内容趋势和市场竞争力。通过数据分析,YouTubers可以发现他们的目标受众群体、优化视频标题和标签、确定最佳发布时间、了解观众行为等。因此,针对YouTubers的数据分析课程设计选题可以帮助学生掌握在实际应用中运用Python进行数据分析的技能,并为YouTubers提供有关优化创作策略的实际指导。
项目目标:
通过对YouTubers的数据进行分析和解释,帮助他们优化创作策略,提升视频表现和观众吸引力。
二、大数据分析的设计方案
列说明:
- title: 视频的标题
- channel_title: 发布视频的 YouTube 频道的标题
- publish_date: 视频在 YouTube 上发布的日期
- time_frame: 视频在 YouTube 上流行的持续时间(例如,1 天 6 小时)
- published_day_of_week: 发布视频的星期几(例如星期一)
- publish_country: 视频发布的国家/地区。
- tags: 与视频关联的标签或关键字
- views: 特定视频获得的观看次数
- likes: 每个视频收到的喜欢数
- dislike: 每个视频收到的不喜欢数量
- comment_count: 评论数
数据分析的课程设计方案概述:
实现思路:
- 数据清洗和预处理:处理缺失值、异常值和重复数据,确保数据的准确性和一致性。
- 数据可视化和探索性分析:使用Python的数据分析库(pandas、matplotlib和seaborn)进行数据可视化和统计分析,揭示数据的特征和趋势。
- 观众分析:使用统计方法和可视化工具,分析YouTubers的观众特征,如年龄、性别、地理位置等,以及观众对视频的喜好和互动行为。
- 内容分析:分析视频标题、标签、描述等与视频表现和观众互动的关系,探索优化视频内容的策略。
- 发布时间优化:分析不同时间段的视频表现,确定最佳的发布时间,以提高视频的曝光和观看量。
- 竞争对手分析:比较YouTubers与竞争对手的表现和策略,找出优势和改进的空间。
- 预测分析:使用机器学习算法,预测视频的受欢迎程度或目标观众群体,为YouTubers提供更精准的创作建议。
技术难点:
- 处理大规模的数据集:考虑到数据集可能包含大量的视频数据和观众信息,需要使用适当的技术和算法来处理和分析大规模数据。
- 数据清洗和预处理:数据集中可能存在缺失值、异常值和重复数据,需要采取合适的方法进行数据清洗和预处理,确保分析结果的准确性和可靠性。
- 观众特征分析:对观众数据进行分析时,需要处理隐私保护和数据匿名化的问题,确保符合相关的数据保护法规和道德准则。
- 预测分析:如果选择进行预测分析,需要选择和优化适当的机器学习算法,并进行特征工程和模型评估,以获得准确的预测结果。
三、数据分析步骤
数据来源于Kaggle数据集网站,数据集地址:https://www.kaggle.com/datasets/rahulanand0070/youtubevideodataset
数据集介绍:youtube.csv
1.初始数据分析和预处理
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 import matplotlib.ticker as mticker 4 import seaborn as sns 5 from matplotlib.font_manager import FontProperties 6 # 加载数据集 7 file_path = 'youtube.csv' 8 data = pd.read_csv(file_path, encoding='latin-1') 9 # 显示数据集的前几行 10 print("数据集的前几行:") 11 print(data.head()) 12 # 数据集的基本信息 13 print("数据集的基本信息:") 14 print(data.info()) 15 # 了解数据多样性的唯一值计数 16 print("数据多样性的唯一值计数:") 17 print(data.nunique()) 18 # 检查是否缺失值 19 print("是否缺失值:") 20 print(data.isnull().sum())
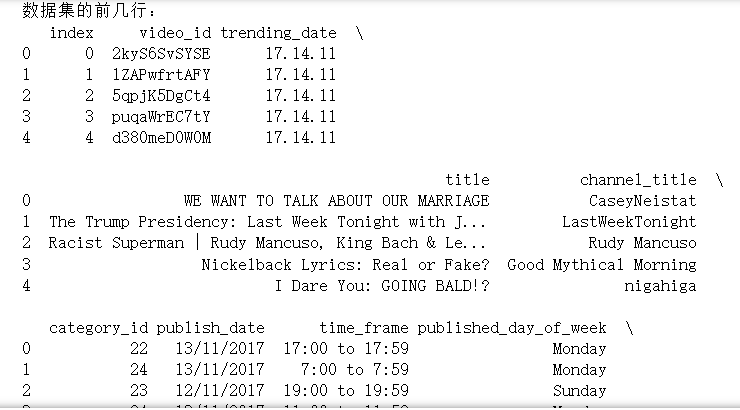
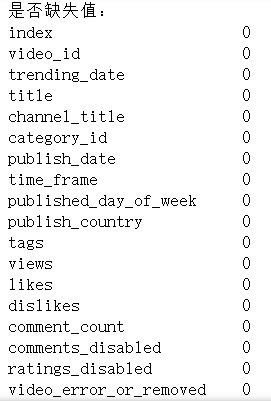
该数据集由18列中的161470个条目组成,以其缺乏空值而闻名,确保了平稳的分析,而无需进行大规模的数据清理。
这些列混合了数据类型,一个突出的方面是数据集的多样性,55886个独特的视频ID的存在突出了这一点,表明了内容的广泛代表性。“标签”列有50239个独特的值,表明视频涵盖了广泛的主题。视图、喜欢、不喜欢和评论计数等指标具有显著的可变性,为详细的参与度分析提供了充足的机会。
2.研究
2.1受欢迎程度和参与度分析
检查观点、喜欢、不喜欢和评论数之间的关系
3 plt.rcParams['font.sans-serif'] = ['SimHei'] 4 plt.rcParams['axes.unicode_minus'] = False 5 # 相关性分析 6 correlation_matrix = data[['views', 'likes', 'dislikes', 'comment_count']].corr() 7 # 绘制热力图 8 sns.heatmap(correlation_matrix, annot=True) 9 # 设置标题和标签 10 plt.title("互动指标相关性分析") 11 plt.xlabel("指标") 12 plt.ylabel("指标") 13 # 调整刻度标签为中文 14 plt.xticks(rotation=45) 15 plt.yticks(rotation=0) 16 plt.show()
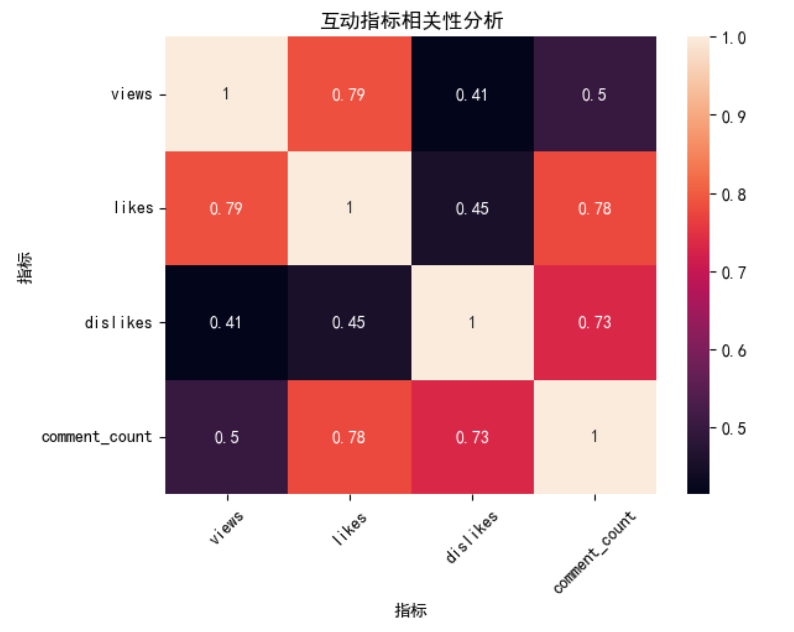
这些发现表明在YouTube趋势视频数据集中,观众参与度与视频的观看量、点赞数、评论数和不喜欢数之间存在着一些有趣的关系。
首先,观看量和点赞数之间存在着强相关性(相关系数为0.787)。这意味着观看量较高的视频通常会获得更多的点赞。这表明,受欢迎的视频往往能够引起观众们的积极反应。
其次,点赞数和评论数之间的相关性也很高(相关系数为0.776)。这意味着广受欢迎的视频通常会激发更多的观众评论。观众们更倾向于参与讨论或留下反馈,尤其是对于他们喜欢的内容。
不喜欢数和评论数之间也存在显著的相关性(相关系数为0.733)。这表明吸引更多不喜欢的视频可能会导致更多的评论。这意味着争议性或分裂性的内容,虽然不是普遍受欢迎的,但会促使观众以评论的形式参与其中,可能表达不同的意见或批评。
最后,观看量和不喜欢数之间存在适度的相关性(相关系数为0.414)。尽管观看次数越多的视频往往会得到更多的不喜欢,但这种增加并不像点赞那样明显。尽管更高的可见性可能会导致更多的负面反应,但观众对他们喜欢的内容的倾向似乎比对不喜欢的内容更强烈。
2.2时间和地理分析
探索一段时间内的趋势,并进行不同国家的比较。
1 data['publish_date'] = pd.to_datetime(data['publish_date'], dayfirst=True) 2 data = data[data['publish_date'].dt.year >= 2018] 3 # 基于时间的分析 4 views_per_day = data.groupby(data['publish_date'].dt.date)['views'].sum() 5 # 格式化y轴刻度为以千为单位的表示 6 def y_fmt(tick_val, pos): 7 if tick_val >= 1000000: 8 val = round(tick_val/1000000, 1) 9 return f'{val}百万' 10 elif tick_val >= 1000: 11 val = int(tick_val/1000) 12 return f'{val}千' 13 else: 14 return tick_val 15 # 绘制图表 16 plt.figure(figsize=(10, 6)) 17 plt.plot(views_per_day.index, views_per_day.values) 18 plt.title("每日观看次数趋势 (2018年以后)") 19 plt.xlabel("日期") 20 plt.ylabel("总观看次数") 21 plt.gca().yaxis.set_major_formatter(mticker.FuncFormatter(y_fmt)) 22 plt.xticks(rotation=45) 23 plt.tight_layout() 24 plt.show()
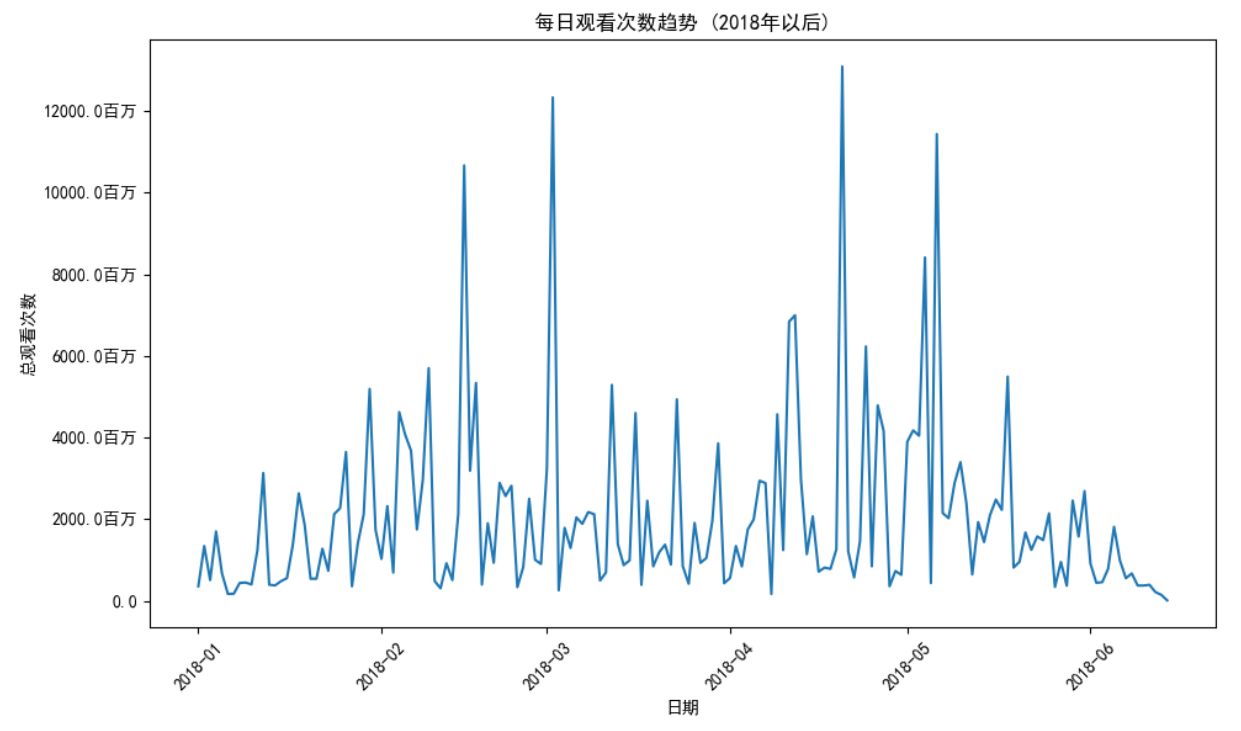
这项分析揭示了YouTube每日观看量的巨大波动性和参与度的动态变化。观看量受特定事件和热门视频发布的影响,导致观看次数出现异常高或异常低的天数。
平均每日观看量约为20.4亿次,显示了YouTube内容的广泛受欢迎程度和影响力。然而,观看次数特别高使得平均值偏向上方。四分位数(25%、50%和75%)之间的显著差异进一步证实了这一点,从50%到75%的四分位数显示了明显的增加。这意味着虽然大多数天的观看量适中,但也有很多天观看量非常高,从而推高了平均观看量。
最低和最高每日观看量之间的范围非常大,最低约为942万次,而最高达到惊人的130.9亿次。这种广泛范围展示了YouTube上每天互动的波动性,突出了活动较少和观看量极高的日子。
总的来说,这些发现反映了YouTube观众参与度的动态和波动性。尽管平台的平均每日观看量很高,但每天都存在相当大的变化。这受到病毒趋势、时事事件或备受期待的内容发布等因素的影响。深入研究观看量峰值出现的日子,可以进一步了解导致这些波动的因素。
2.3一周中某一天的影响
调查一周中的哪一天对受欢迎程度和参与度的影响。
1 # 计算每周各天的平均观看次数 2 average_views_per_day_of_week = data.groupby('published_day_of_week')['views'].mean() 3 # 按照每周各天进行分析 4 average_views_per_day_of_week.plot(kind='bar') 5 plt.title("每周各天平均观看次数") 6 plt.xlabel("星期几") 7 plt.ylabel("平均观看次数") 8 plt.show()
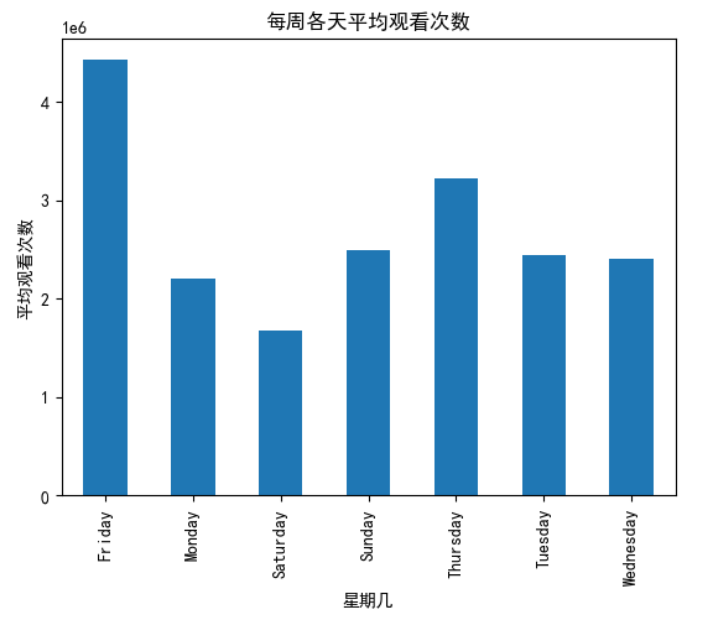
根据一周中的哪一天对YouTube趋势视频的平均每日浏览量进行分析,揭示了观众行为的一种有趣的模式。数据显示,周五的平均浏览量最高,约为443万次。这一峰值表明,观众在进入周末时会更多地参与YouTube内容,会寻求娱乐或信息来开始他们的周末。
相比之下,周六的平均浏览量最低,约为168万次,考虑到人们普遍认为周末是休闲时间,这很有趣。这表明观众习惯在周六转向户外或非数字活动。
以周一为代表的工作周开始时,平均浏览量也较低(约220万),然后在一周内逐渐增加。周二、周三和周四的平均浏览量稳步上升,周五达到峰值。周四的平均浏览量为323万,这表明随着本周的进展,观众的参与度正在上升。
有趣的是,与周六相比,周日的浏览量略有增加(约249万),这表明随着周末的结束,观众开始重新收看数字内容。
2.4标题和标签的效力
分析某些类型的标题或标签是否与高参与度视频更相关。
2 #标签中最常见的单词 3 from collections import Counter 4 import itertools 5 #拆分标签和计数 6 all_tags = list(itertools.chain(*data['tags'].str.split('|'))) 7 tag_counts = Counter(all_tags) 8 print(tag_counts.most_common(10))
![]()
1 import matplotlib.pyplot as plt 2 tags = ['[无]', '搞笑', '喜剧', '2018', '"搞笑"', '音乐', '"喜剧"', '视频', '新闻', '采访'] 3 counts = [8382, 4706, 3657, 3483, 2505, 2180, 2001, 1897, 1746, 1725] 4 # 创建条形图 5 plt.figure(figsize=(10, 6)) 6 plt.bar(tags, counts, color='skyblue') 7 plt.xlabel('标签') 8 plt.ylabel('出现次数') 9 plt.title('热门YouTube视频的前10个标签') 10 plt.xticks(rotation=45) 11 plt.show()
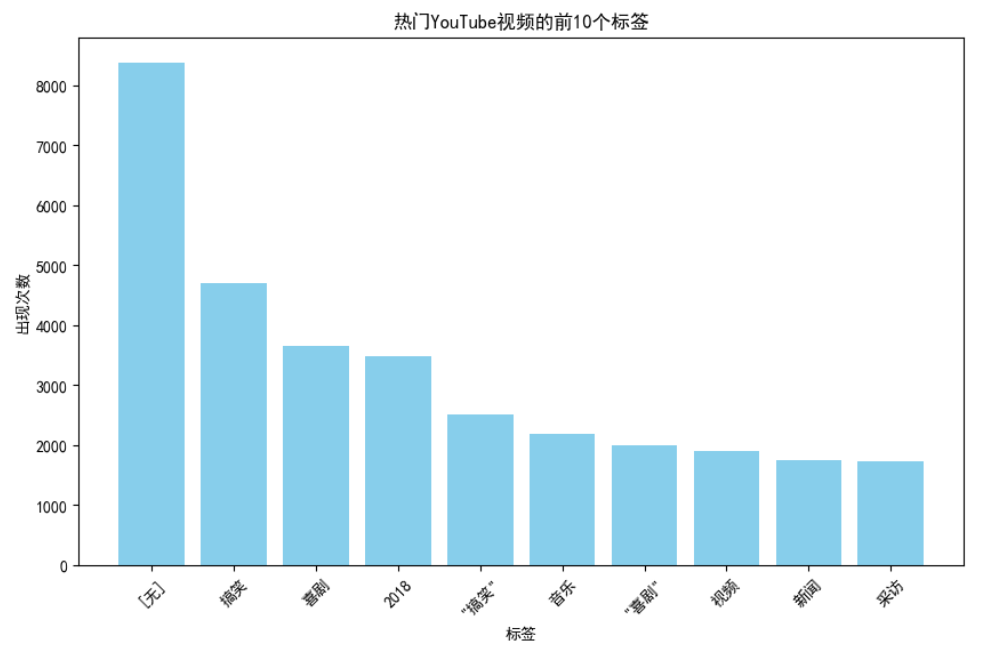
对“YouTube趋势视频”数据集中最常见标签的分析显示,人们明显倾向于某些主题和内容类型。最常见的标签是“[无]”,出现8382次,这表明大量视频要么没有使用标签,要么没有捕捉到标签信息。在此之后,“滑稽”和“喜剧”标签非常普遍,分别出现了4706次和3657次。这突出了观众对平台上幽默和喜剧内容的强烈兴趣。
标签“2018”出现3483次,表明数据集中有大量当年的趋势视频,或与当年事件相关的视频。“滑稽”和“喜剧”等标签中的双引号分别出现了2505次和2001次,可能指向一些上传者使用的特定格式或数据收集过程中的人工制品。
此外,“音乐”、“视频”、“新闻”和“采访”是最热门的标签,说明了YouTube上流行的内容的多样性。这些标签反映了该平台在音乐推广、新闻传播以及作为采访和其他视频内容的媒介方面的作用。
3.一般数据分析
3.1类别趋势分析
调查哪些视频类别(以category_id表示)在浏览量、点赞和评论方面最受欢迎。
1 # 按category_id分组,并计算平均观看数、点赞数和评论数 2 category_analysis = data.groupby('category_id')[['views', 'likes', 'comment_count']].mean() 3 # 绘制结果进行可视化 4 plt.figure(figsize=(15, 5)) 5 # 绘制每个分类的平均观看数 6 plt.subplot(1, 3, 1) 7 category_analysis['views'].plot(kind='bar', color='skyblue') 8 plt.title('每个分类的平均观看数') 9 plt.xlabel('分类ID') 10 plt.ylabel('平均观看数') 11 # 绘制每个分类的平均点赞数 12 plt.subplot(1, 3, 2) 13 category_analysis['likes'].plot(kind='bar', color='lightgreen') 14 plt.title('每个分类的平均点赞数') 15 plt.xlabel('分类ID') 16 plt.ylabel('平均点赞数') 17 # 绘制每个分类的平均评论数 18 plt.subplot(1, 3, 3) 19 category_analysis['comment_count'].plot(kind='bar', color='salmon') 20 plt.title('每个分类的平均评论数') 21 plt.xlabel('分类ID') 22 plt.ylabel('平均评论数') 23 plt.tight_layout() 24 plt.show()
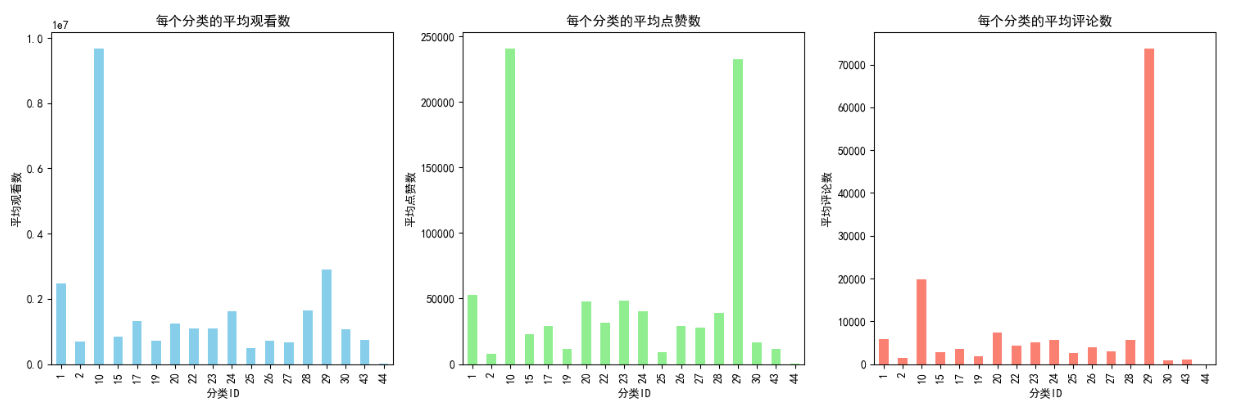
输出提供了不同视频类别的观众参与度的全面视图。
音乐视频(类别ID 10)以最高的平均浏览量、点赞数和评论数脱颖而出。这突显了音乐内容在YouTube上的巨大受欢迎程度,反映了其广泛的吸引力和该平台作为音乐消费主要目的地的作用。
娱乐(类别ID 24)是另一个受欢迎的类别,显示出相当大的平均浏览量、点赞量和评论量。这一类别的高参与度凸显了YouTube作为娱乐内容主要来源的作用。
科学与技术(类别ID 28)和非营利组织与激进主义(类别ID 29)也显示出较高的参与度。值得注意的是,非营利组织和激进主义虽然在数量上的影响力较小,但在点赞(约165666)和评论(约52396)方面表现出特别高的参与度,这表明观众参与度很高。
游戏(类别ID 20)和喜剧(类别ID 23)类别也有很强的参与度指标,平均浏览量超过100万,点赞和评论数也很高。这反映了这些地区的敬业和互动社区。
旅游和活动(类别ID 19)、Howto&Style(类别ID 26)和教育(类别ID 27)等类别显示出中等程度的参与度,这表明观众很专注,但可能较少。
汽车与车辆(类别ID 2)和新闻与政治(类别ID 25)的参与度指标较低,这表明这些类别中存在利基受众或不同的受众互动模式。
3.2成功渠道分析
识别经常有热门视频的YouTube频道(channel_title)。
1 # 统计每个频道的出现次数,以及每个视频的观看次数或平均点赞数最高的频道。 2 channel_frequency = data['channel_title'].value_counts() 3 # 计算每个频道的平均观看数和点赞数 4 channel_avg_views = data.groupby('channel_title')['views'].mean() 5 channel_avg_likes = data.groupby('channel_title')['likes'].mean() 6 # 合并数据 7 channel_analysis = pd.DataFrame({ 8 '出现次数': channel_frequency, 9 '平均观看数': channel_avg_views, 10 '平均点赞数': channel_avg_likes 11 }) 12 # 绘制出现次数最多的前10个频道 13 top_channels = channel_analysis.sort_values(by='出现次数', ascending=False).head(10) 14 top_channels[['平均观看数', '平均点赞数']].plot(kind='bar', figsize=(12, 6)) 15 plt.title('出现次数最多的前10个频道及其平均观看数和点赞数') 16 plt.xlabel('频道标题') 17 plt.ylabel('计数') 18 plt.xticks(rotation=45) 19 plt.show()
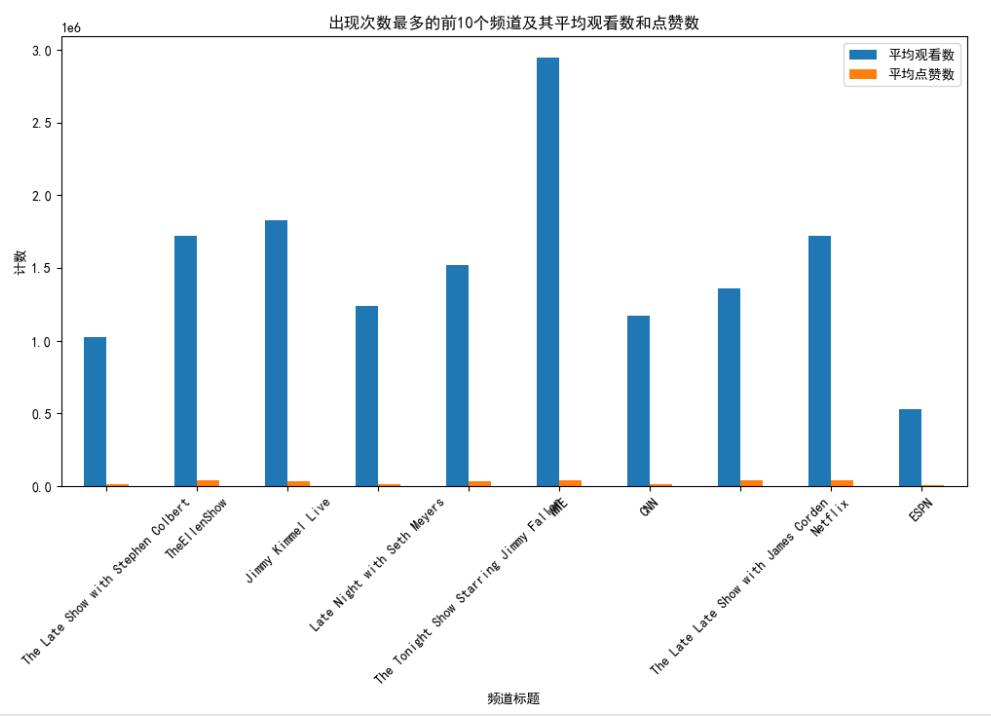
对数据集中成功的YouTube频道的分析显示,脱口秀和娱乐频道是最常见的趋势之一。
斯蒂芬·科尔伯特的《深夜秀》以653次出场位居榜首,平均每段视频约979833次观看和13573次点赞。
美国有线电视新闻网是一个新闻频道,经常出现(495次),但与娱乐频道相比,平均观看次数较低,这突出了新闻和娱乐之间内容消费模式的差异。
代表体育内容的ESPN经常出现,但平均观看次数和点赞数较低,这反映了YouTube上体育收视率的具体性质。
3.3热门视频的趋势持续时间分析
确定观看次数最多的视频在YouTube上保持趋势的平均持续时间。本分析旨在了解高参与度内容在趋势部分的存在寿命。
1 # 将'trending_date'转换为日期时间格式 2 data['trending_date'] = pd.to_datetime(data['trending_date'], format='%y.%d.%m') 3 # 按'views'对视频进行排序 4 sorted_videos = data.sort_values(by='views', ascending=False) 5 # 选择排名靠前的视频(您可以定义要考虑的排名前几个视频) 6 top_videos = sorted_videos.drop_duplicates(subset=['video_id']).head(50) 7 # 计算每个排名靠前视频的趋势持续时间 8 top_videos['trending_duration'] = top_videos.groupby('video_id')['trending_date'].transform(lambda x: x.max() - x.min()) 9 # 包含相关信息 10 top_videos_info = top_videos[['video_id', 'title', 'channel_title', 'category_id', 'trending_duration']] 11 # 显示结果 12 print(top_videos_info) 13 # 可选:您可以计算平均趋势持续时间 14 average_duration = top_videos_info['trending_duration'].mean() 15 print(f"平均趋势持续时间:{average_duration}")
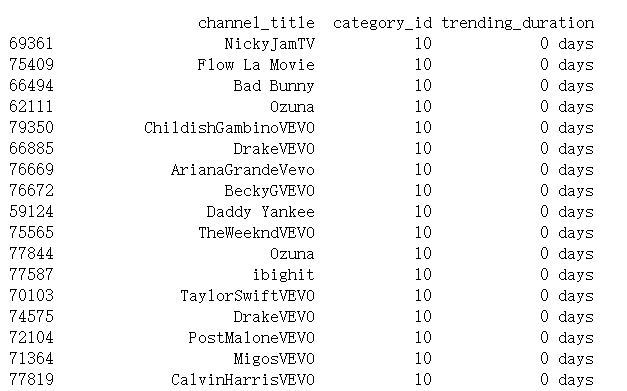
该分析突出了音乐类别(类别ID 10)中的一个特定趋势。来自各种流行音乐频道的前50名视频中的每一个视频都显示出“0天”的趋势持续时间。这表明这些音乐视频要么在一天内迅速获得了浏览量,要么数据无法完全捕捉到其趋势状态的持续时间。
然而,所有这些热门视频的统一趋势持续时间为“0天”,这表明这些视频保持趋势的时间长度数据存在局限性。这是由于YouTube趋势算法的性质,它有利于快速出现的内容,也表明数据收集方法只捕捉最初的人气激增,而不跟踪多天的持续时间。
3.4地理比较
比较不同国家的观点和参与度趋势(publish_country)。
# 按publish_country分组,并计算平均观看数、点赞数和评论数 country_analysis = data.groupby('publish_country')[['views', 'likes', 'comment_count']].mean() # 绘制结果进行可视化 plt.figure(figsize=(15, 5)) # 绘制每个国家的平均观看数 plt.subplot(1, 3, 1) country_analysis['views'].plot(kind='bar', color='skyblue') plt.title('每个国家的平均观看数') plt.xlabel('国家') plt.ylabel('平均观看数') # 绘制每个国家的平均点赞数 plt.subplot(1, 3, 2) country_analysis['likes'].plot(kind='bar', color='lightgreen') plt.title('每个国家的平均点赞数') plt.xlabel('国家') plt.ylabel('平均点赞数') # 绘制每个国家的平均评论数 plt.subplot(1, 3, 3) country_analysis['comment_count'].plot(kind='bar', color='salmon') plt.title('每个国家的平均评论数') plt.xlabel('国家') plt.ylabel('平均评论数') plt.tight_layout() plt.show()
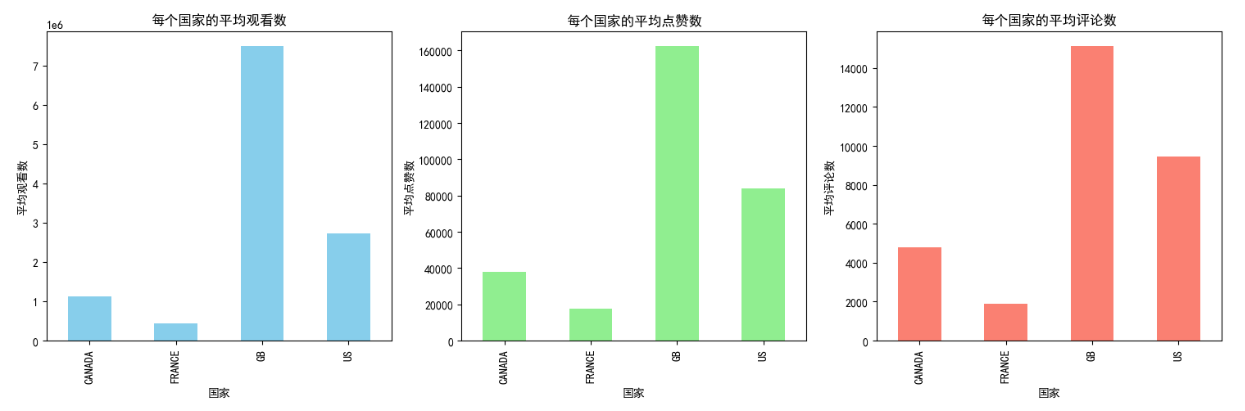
该数据集提供了对四个国家观众参与度的深入观察:加拿大、法国、英国和美国。
英国的每条视频平均浏览量最高,约591万次,平均点赞和评论最高,约134520个点赞和13088条评论。这表明GB的参与度特别高,可能反映了大量观众和与热门内容的高度互动。
美国的平均浏览量低于英国,约为236万次,但平均点赞数和评论数相对较高。这表明,美国的热门内容也享有显著的观众互动水平。
加拿大的参与度适中,平均浏览量约为115万,点赞39583个,评论5043条。尽管与英国和美国相比,这些数字较低,但它们仍然代表了加拿大YouTube领域的参与度。
法国的平均观看次数、点赞次数和评论次数在这些国家中最低,每条视频约有419922次观看、17389次点赞和1832次评论。这可能表明与所分析的其他地区相比,法国的观众偏好不同,或者趋势内容的观众较少。
这些发现突显了观众参与YouTube内容的方式存在显著的地区差异。英国和美国的数字较高,这可能归因于更多的英语观众以及YouTube在这些国家的广泛流行。相比之下,法国较低的数字可能反映了内容消费的文化差异或其他平台的受欢迎程度。
3.5视频标题分析
探讨标题中的某些单词或短语是否与更高的参与度有关。
1 from sklearn.feature_extraction.text import CountVectorizer 2 # 将观看数、点赞数和评论数合并为单个参与度指数 3 data['engagement_score'] = data['views'] + data['likes'] + data['comment_count'] 4 # 选择参与度高的视频 5 high_engagement_threshold = data['engagement_score'].quantile(0.75) 6 high_engagement_data = data[data['engagement_score'] >= high_engagement_threshold] 7 # 从标题中提取单词 8 vectorizer = CountVectorizer(stop_words='english', max_features=50) 9 title_matrix = vectorizer.fit_transform(high_engagement_data['title']) 10 title_words = vectorizer.get_feature_names_out() 11 # 统计每个单词的出现次数 12 word_counts = title_matrix.sum(axis=0).A1 13 word_count_dict = dict(zip(title_words, word_counts)) 14 # 按照频率对单词进行排序 15 sorted_word_counts = sorted(word_count_dict.items(), key=lambda x: x[1], reverse=True) 16 # 绘制前几个单词 17 top_words = sorted_word_counts[:10] 18 words, counts = zip(*top_words) 19 plt.figure(figsize=(10, 6)) 20 plt.bar(words, counts, color='skyblue') 21 plt.title('参与度高的视频标题中的前10个单词') 22 plt.xlabel('单词') 23 plt.ylabel('出现次数') 24 plt.xticks(rotation=45) 25 plt.show()
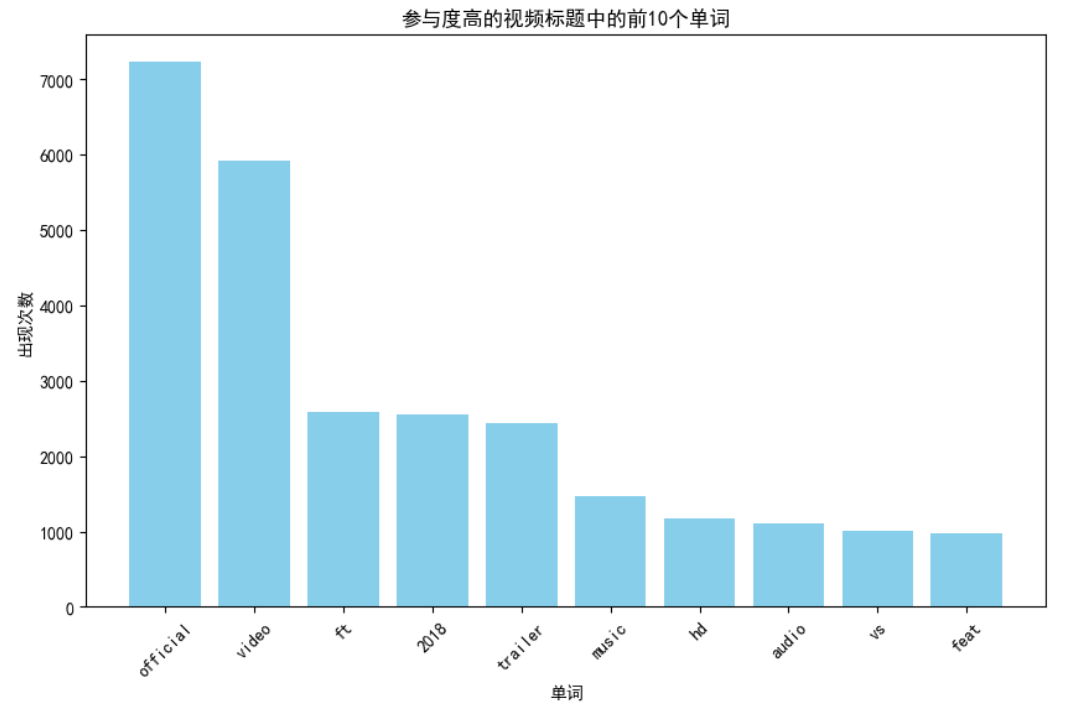
为了进行这项分析,通过结合每个视频的浏览量、点赞和评论,创建了一个参与度。
结果显示,“官方”一词出现频率最高,在高参与度的视频标题中出现了8868次。这种普遍性表明,观众特别喜欢被视为真实或直接来源的内容,正如“官方”一词经常表示的那样。
“视频”一词紧随其后,共出现7138次,强调了平台对视觉内容的关注。“ft”(特写)和“feat”(特写,分别观看了3262次和1262次)以及“music”(1921次)的出现证实了人们对音乐视频的高度参与,尤其是艺术家之间的合作。这一趋势证明了YouTube作为音乐消费和发现的主导平台的作用。
“预告片”一词(3104次)和“2018”一年(2990次)分别突出了人们对电影预告片和及时内容的兴趣。”HD’(1511次出现)和“音频”(1449次出现)表明对高质量视频和音频内容的偏好。术语“vs”(1413次出现)表示比较或竞争性内容的流行,这些内容与体育、游戏或其他娱乐形式有关。
4.深入分析
4.1内容聚类分析
识别具有相似特征的视频组。
1 from sklearn.preprocessing import StandardScaler 2 from sklearn.cluster import KMeans 3 # 选择用于聚类的相关特征 4 features = data[['views', 'likes', 'comment_count', 'category_id']] 5 # 标准化特征 6 scaler = StandardScaler() 7 scaled_features = scaler.fit_transform(features) 8 # 应用K-means聚类 9 kmeans = KMeans(n_clusters=5, random_state=42, n_init=10) # 调整'n_init'以避免警告 10 clusters = kmeans.fit_predict(scaled_features) 11 data['cluster'] = clusters 12 # 使用修正后的语法分析结果 13 clustered_data = data.groupby('cluster')[['views', 'likes', 'comment_count', 'category_id']].mean() 14 # 可选:可视化聚类结果(选择两个特征) 15 plt.scatter(scaled_features[:, 0], scaled_features[:, 1], c=clusters, cmap='viridis') 16 plt.xlabel('标准化观看数') 17 plt.ylabel('标准化点赞数') 18 plt.title('内容聚类可视化') 19 plt.show()
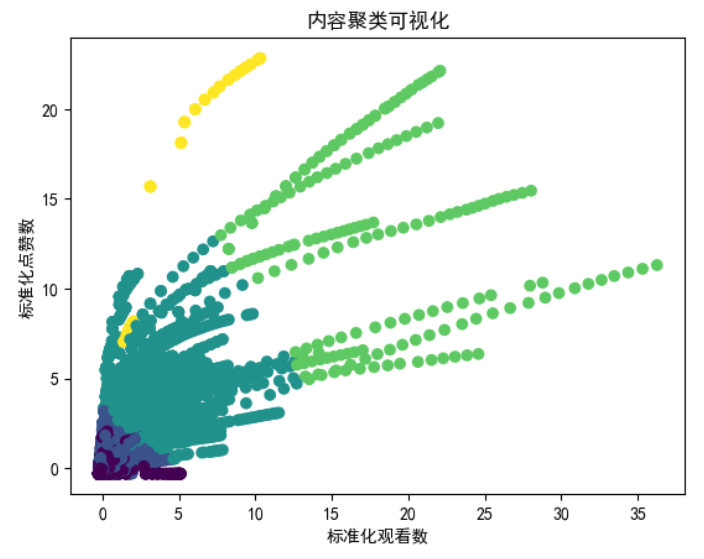
集群0(紫色):这些视频的受欢迎程度适中,平均浏览量约为947448次,点赞27363次,评论3507条。它们主要属于以ID 23为代表的类别,是“喜剧”或“娱乐”等类型。
集群1(蓝色):该群组包括更受欢迎的视频,参与度高,平均浏览量281万,点赞82250个,评论6620条。7.85的常见类别ID表明这些视频属于“音乐”或“娱乐”。
集群2(绿色):以极高的参与度为标志,该集群中的视频平均浏览量为1.872亿,点赞量为302万,评论量为234926。接近11的类别ID表示“音乐”等流行流派。
集群3(黄色):该集群的视频平均浏览量6410万,点赞294万,评论854088条,参与度高。类别ID为18.53表示与类别2不同的类别,是“电影和动画”或“短片”。
集群4(浅绿色):这些视频也显示出很高的人气,但与集群2和集群3相比,参与度略低,平均浏览量为3720万,点赞978110,评论91762。类别ID平均值为12.25,表明它们属于“音乐”或“娱乐”等类别。
4.2参与因素分析
确定哪些因素与高参与度最相关。
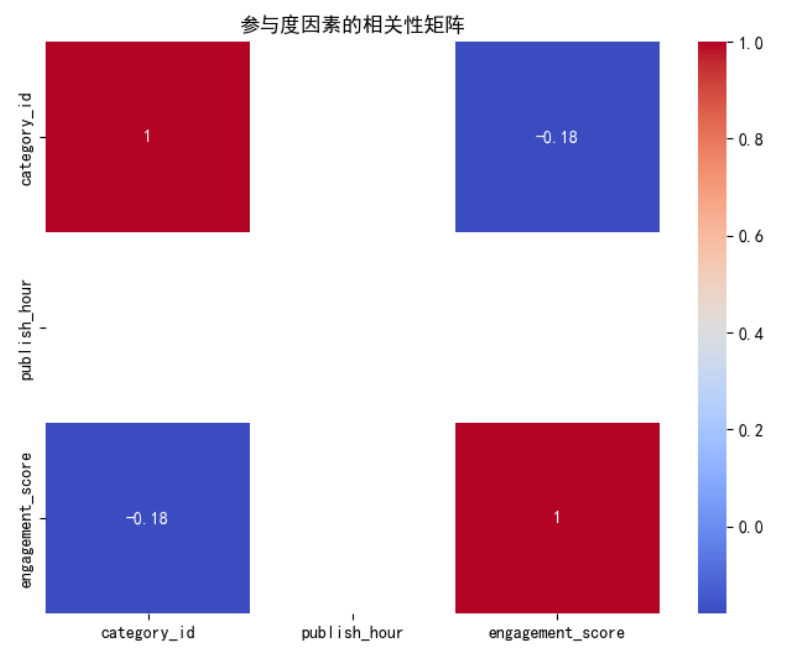
1 # 使用正确的格式解析'publish_date' 2 data['publish_date'] = pd.to_datetime(data['publish_date'], dayfirst=True) 3 data['publish_hour'] = data['publish_date'].dt.hour 4 # 创建参与度指数 5 data['engagement_score'] = data['views'] + data['likes'] + data['comment_count'] 6 # 相关性分析:类别、发布小时与参与度指数的相关性 7 correlation_matrix = data[['category_id', 'publish_hour', 'engagement_score']].corr() 8 # 可视化相关性矩阵 9 plt.figure(figsize=(8, 6)) 10 sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm') 11 plt.title('参与度因素的相关性矩阵') 12 plt.show() 13 # 分析每个类别和每个发布小时的平均参与度指数 14 category_engagement = data.groupby('category_id')['engagement_score'].mean() 15 hour_engagement = data.groupby('publish_hour')['engagement_score'].mean() 16 plt.figure(figsize=(12, 5)) 17 plt.subplot(1, 2, 1) 18 category_engagement.plot(kind='bar') 19 plt.title('不同类别的平均参与度指数') 20 plt.xlabel('类别 ID') 21 plt.ylabel('平均参与度指数') 22 plt.subplot(1, 2, 2) 23 hour_engagement.plot(kind='bar') 24 plt.title('不同发布小时的平均参与度指数') 25 plt.xlabel('发布小时') 26 plt.ylabel('平均参与度指数') 27 plt.tight_layout() 28 plt.show()
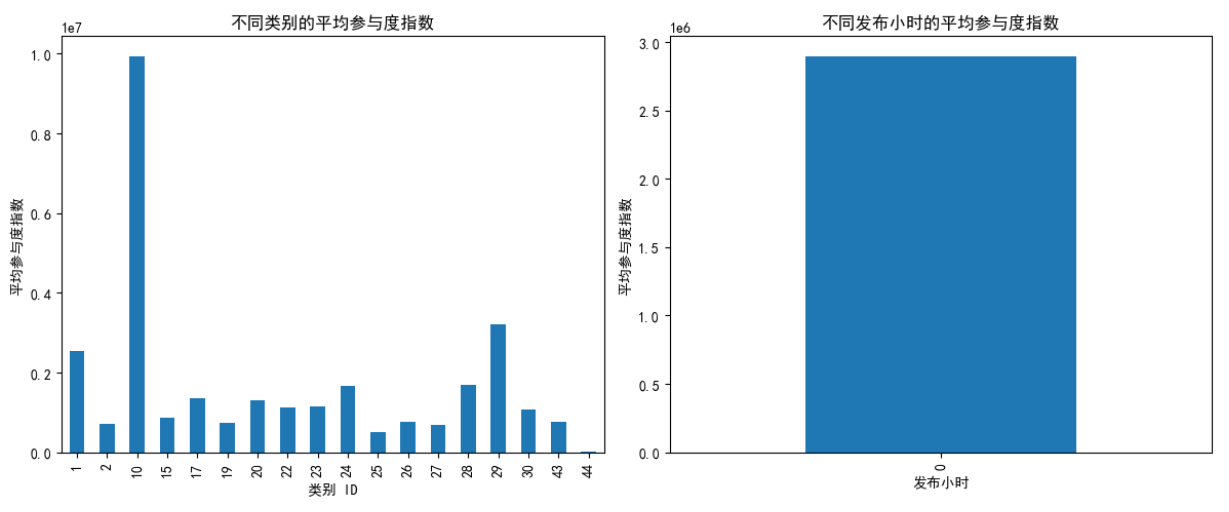
小时参与度分析:数据显示,在0小时(大概是午夜)发布的视频的平均参与度得分约为249万。
相关矩阵分析:相关矩阵表明类别ID和参与度得分之间存在轻微的负相关(-0.16249)。与其他类别相比,某些类别的参与度可能略低,尽管相关性相对较弱。
基于类别的参与度分析:不同类别的平均参与度得分差异很大。第10类代表“音乐”,其平均参与度最高,约为846万,突显了其在YouTube上的受欢迎程度。其他类别,如24、29和28,也显示出相对较高的参与度得分,观众对这些类别有强烈的兴趣。
5.预测趋势算法
预测哪些类型的视频最有可能成为趋势。
1 from sklearn.model_selection import train_test_split 2 from sklearn.linear_model import LogisticRegression 3 from sklearn.preprocessing import LabelEncoder, StandardScaler 4 from sklearn.metrics import accuracy_score 5 # 创建二元目标变量来表示高参与度(例如,参与度排名前25%) 6 engagement_threshold = data['views'].quantile(0.75) 7 data['high_engagement'] = (data['views'] >= engagement_threshold).astype(int) 8 # 对分类变量(如'tags')进行编码并对数据进行标准化 9 label_encoder = LabelEncoder() 10 data['tags_encoded'] = label_encoder.fit_transform(data['tags']) 11 data['category_id_encoded'] = label_encoder.fit_transform(data['category_id']) 12 # 选择用于模型的相关特征 13 features = data[['tags_encoded', 'category_id_encoded']] 14 target = data['high_engagement'] 15 # 将数据拆分为训练集和测试集 16 X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.3, random_state=42) 17 # 对特征进行标准化 18 scaler = StandardScaler() 19 X_train_scaled = scaler.fit_transform(X_train) 20 X_test_scaled = scaler.transform(X_test) 21 # 构建逻辑回归模型 22 model = LogisticRegression() 23 model.fit(X_train_scaled, y_train) 24 # 预测并评估模型 25 predictions = model.predict(X_test_scaled) 26 accuracy = accuracy_score(y_test, predictions) 27 print(f'模型准确率:{accuracy}')
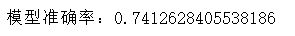
该预测模型使用逻辑回归构建,可作为预测视频在YouTube上获得高参与度的可能性的工具。该模型的输入包括来自“YouTube趋势视频”数据集的“标签”和“类别_id”变量的编码版本。
经过测试,我们的模型的准确率约为74%。这一准确度水平表明,尽管该模型具有良好的预测能力,但仍有改进的空间。
通过了解基于视频类别和标签的高参与度的可能性,创作者可以战略性地规划他们的内容,以符合趋势和观众的偏好。
以下是完整代码:
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 import matplotlib.ticker as mticker 4 import seaborn as sns 5 from matplotlib.font_manager import FontProperties 6 # 加载数据集 7 file_path = 'youtube.csv' 8 data = pd.read_csv(file_path, encoding='latin-1') 9 # 显示数据集的前几行 10 print("数据集的前几行:") 11 print(data.head()) 12 # 数据集的基本信息 13 print("数据集的基本信息:") 14 print(data.info()) 15 # 了解数据多样性的唯一值计数 16 print("数据多样性的唯一值计数:") 17 print(data.nunique()) 18 # 检查是否缺失值 19 print("是否缺失值:") 20 print(data.isnull().sum()) 21 #2.建议研究 22 #2.1受欢迎程度和参与度分析 目标:检查观点、喜欢、不喜欢和评论数之间的关系。 23 plt.rcParams['font.sans-serif'] = ['SimHei'] 24 plt.rcParams['axes.unicode_minus'] = False 25 # 相关性分析 26 correlation_matrix = data[['views', 'likes', 'dislikes', 'comment_count']].corr() 27 # 绘制热力图 28 sns.heatmap(correlation_matrix, annot=True) 29 # 设置标题和标签 30 plt.title("互动指标相关性分析") 31 plt.xlabel("指标") 32 plt.ylabel("指标") 33 # 调整刻度标签为中文 34 plt.xticks(rotation=45) 35 plt.yticks(rotation=0) 36 plt.show() 37 # 2.2时间和地理分析 38 # 目标:探索一段时间内的趋势,并进行不同国家的比较 39 # 将日期转换为datetime格式 40 data['publish_date'] = pd.to_datetime(data['publish_date'], dayfirst=True) 41 data = data[data['publish_date'].dt.year >= 2018] 42 # 基于时间的分析 43 views_per_day = data.groupby(data['publish_date'].dt.date)['views'].sum() 44 # 格式化y轴刻度为以千为单位的表示 45 def y_fmt(tick_val, pos): 46 if tick_val >= 1000000: 47 val = round(tick_val/1000000, 1) 48 return f'{val}百万' 49 elif tick_val >= 1000: 50 val = int(tick_val/1000) 51 return f'{val}千' 52 else: 53 return tick_val 54 # 绘制图表 55 plt.figure(figsize=(10, 6)) 56 plt.plot(views_per_day.index, views_per_day.values) 57 plt.title("每日观看次数趋势 (2018年以后)") 58 plt.xlabel("日期") 59 plt.ylabel("总观看次数") 60 plt.gca().yaxis.set_major_formatter(mticker.FuncFormatter(y_fmt)) 61 plt.xticks(rotation=45) 62 plt.tight_layout() 63 plt.show() 64 # 2.3一周中某一天的影响 65 # 目的:调查一周中的哪一天对受欢迎程度和参与度的影响。 66 # 计算每周各天的平均观看次数 67 average_views_per_day_of_week = data.groupby('published_day_of_week')['views'].mean() 68 # 按照每周各天进行分析 69 average_views_per_day_of_week.plot(kind='bar') 70 plt.title("每周各天平均观看次数") 71 plt.xlabel("星期几") 72 plt.ylabel("平均观看次数") 73 plt.show() 74 # 2.4标题和标签的效力 75 # 目的:分析某些类型的标题或标签是否与高参与度视频更相关。 76 #对于这种分析,可能需要NLP技术来从标题和标签中提取见解 77 #标签中最常见的单词 78 from collections import Counter 79 import itertools 80 #拆分标签和计数 81 all_tags = list(itertools.chain(*data['tags'].str.split('|'))) 82 tag_counts = Counter(all_tags) 83 print(tag_counts.most_common(10)) 84 import matplotlib.pyplot as plt 85 tags = ['[无]', '搞笑', '喜剧', '2018', '"搞笑"', '音乐', '"喜剧"', '视频', '新闻', '采访'] 86 counts = [8382, 4706, 3657, 3483, 2505, 2180, 2001, 1897, 1746, 1725] 87 # 创建条形图 88 plt.figure(figsize=(10, 6)) 89 plt.bar(tags, counts, color='skyblue') 90 plt.xlabel('标签') 91 plt.ylabel('出现次数') 92 plt.title('热门YouTube视频的前10个标签') 93 plt.xticks(rotation=45) 94 plt.show() 95 # 3.一般数据分析 96 # 3.1类别趋势分析 97 # 目标:调查哪些视频类别(以category_id表示)在浏览量、点赞和评论方面最受欢迎。 98 # 方法:按category_id对数据进行分组,计算每个类别的浏览量、点赞量和评论量的平均值或总和。 99 # 按category_id分组,并计算平均观看数、点赞数和评论数 100 category_analysis = data.groupby('category_id')[['views', 'likes', 'comment_count']].mean() 101 # 绘制结果进行可视化 102 plt.figure(figsize=(15, 5)) 103 # 绘制每个分类的平均观看数 104 plt.subplot(1, 3, 1) 105 category_analysis['views'].plot(kind='bar', color='skyblue') 106 plt.title('每个分类的平均观看数') 107 plt.xlabel('分类ID') 108 plt.ylabel('平均观看数') 109 # 绘制每个分类的平均点赞数 110 plt.subplot(1, 3, 2) 111 category_analysis['likes'].plot(kind='bar', color='lightgreen') 112 plt.title('每个分类的平均点赞数') 113 plt.xlabel('分类ID') 114 plt.ylabel('平均点赞数') 115 # 绘制每个分类的平均评论数 116 plt.subplot(1, 3, 3) 117 category_analysis['comment_count'].plot(kind='bar', color='salmon') 118 plt.title('每个分类的平均评论数') 119 plt.xlabel('分类ID') 120 plt.ylabel('平均评论数') 121 plt.tight_layout() 122 plt.show() 123 # 3.2成功渠道分析 124 # 目标:识别经常有热门视频的YouTube频道(channel_title)。 125 # 方法:统计每个频道在数据集中出现的次数,以及每个视频的观看次数或平均点赞数最高的频道。 126 # 统计每个频道的出现次数 127 channel_frequency = data['channel_title'].value_counts() 128 # 计算每个频道的平均观看数和点赞数 129 channel_avg_views = data.groupby('channel_title')['views'].mean() 130 channel_avg_likes = data.groupby('channel_title')['likes'].mean() 131 # 合并数据 132 channel_analysis = pd.DataFrame({ 133 '出现次数': channel_frequency, 134 '平均观看数': channel_avg_views, 135 '平均点赞数': channel_avg_likes 136 }) 137 # 绘制出现次数最多的前10个频道 138 top_channels = channel_analysis.sort_values(by='出现次数', ascending=False).head(10) 139 top_channels[['平均观看数', '平均点赞数']].plot(kind='bar', figsize=(12, 6)) 140 plt.title('出现次数最多的前10个频道及其平均观看数和点赞数') 141 plt.xlabel('频道标题') 142 plt.ylabel('计数') 143 plt.xticks(rotation=45) 144 plt.show() 145 # 3.3热门视频的趋势持续时间分析 146 # 目标:确定观看次数最多的视频在YouTube上保持趋势的平均持续时间。本分析旨在了解高参与度内容在趋势部分的存在寿命。 147 # 方法:该方法包括处理time_frame数据,以计算观看次数最多的视频保持趋势的平均持续时间。该分析将根据这些热门视频的观看次数来确定它们,然后测量它们在趋势部分首次出现和最后一次出现之间的时间跨度。此外,该分析将探讨不同类别(category_id)或频道(channel_title)的趋势持续时间是否存在显著差异。这种方法旨在深入了解哪些类型的内容或频道在趋势部分保持较长的可见性,这可能表明观众的兴趣或参与度更高。 148 # 将'trending_date'转换为日期时间格式 149 data['trending_date'] = pd.to_datetime(data['trending_date'], format='%y.%d.%m') 150 # 按'views'对视频进行排序 151 sorted_videos = data.sort_values(by='views', ascending=False) 152 # 选择排名靠前的视频(您可以定义要考虑的排名前几个视频) 153 top_videos = sorted_videos.drop_duplicates(subset=['video_id']).head(50) 154 # 计算每个排名靠前视频的趋势持续时间 155 top_videos['trending_duration'] = top_videos.groupby('video_id')['trending_date'].transform(lambda x: x.max() - x.min()) 156 # 包含相关信息 157 top_videos_info = top_videos[['video_id', 'title', 'channel_title', 'category_id', 'trending_duration']] 158 # 显示结果 159 print(top_videos_info) 160 # 可选:您可以计算平均趋势持续时间 161 average_duration = top_videos_info['trending_duration'].mean() 162 print(f"平均趋势持续时间:{average_duration}") 163 # 3.4地理比较 164 # 目标:比较不同国家的观点和参与度趋势(publish_country)。 165 # 方法:按publish_country对数据进行分组,并比较每个视频的平均观看次数、点赞次数和评论次数。 166 # 按publish_country分组,并计算平均观看数、点赞数和评论数 167 country_analysis = data.groupby('publish_country')[['views', 'likes', 'comment_count']].mean() 168 # 绘制结果进行可视化 169 plt.figure(figsize=(15, 5)) 170 # 绘制每个国家的平均观看数 171 plt.subplot(1, 3, 1) 172 country_analysis['views'].plot(kind='bar', color='skyblue') 173 plt.title('每个国家的平均观看数') 174 plt.xlabel('国家') 175 plt.ylabel('平均观看数') 176 # 绘制每个国家的平均点赞数 177 plt.subplot(1, 3, 2) 178 country_analysis['likes'].plot(kind='bar', color='lightgreen') 179 plt.title('每个国家的平均点赞数') 180 plt.xlabel('国家') 181 plt.ylabel('平均点赞数') 182 # 绘制每个国家的平均评论数 183 plt.subplot(1, 3, 3) 184 country_analysis['comment_count'].plot(kind='bar', color='salmon') 185 plt.title('每个国家的平均评论数') 186 plt.xlabel('国家') 187 plt.ylabel('平均评论数') 188 plt.tight_layout() 189 plt.show() 190 # 3.5视频标题分析 191 # 目的:探讨标题中的某些单词或短语是否与更高的参与度有关。 192 # 方法:使用自然语言处理技术来分析视频标题,并识别热门视频中的关键词或常见主题。 193 from sklearn.feature_extraction.text import CountVectorizer 194 # 将观看数、点赞数和评论数合并为单个参与度指数 195 data['engagement_score'] = data['views'] + data['likes'] + data['comment_count'] 196 # 选择参与度高的视频 197 high_engagement_threshold = data['engagement_score'].quantile(0.75) 198 high_engagement_data = data[data['engagement_score'] >= high_engagement_threshold] 199 # 从标题中提取单词 200 vectorizer = CountVectorizer(stop_words='english', max_features=50) 201 title_matrix = vectorizer.fit_transform(high_engagement_data['title']) 202 title_words = vectorizer.get_feature_names_out() 203 # 统计每个单词的出现次数 204 word_counts = title_matrix.sum(axis=0).A1 205 word_count_dict = dict(zip(title_words, word_counts)) 206 # 按照频率对单词进行排序 207 sorted_word_counts = sorted(word_count_dict.items(), key=lambda x: x[1], reverse=True) 208 # 绘制前几个单词 209 top_words = sorted_word_counts[:10] 210 words, counts = zip(*top_words) 211 plt.figure(figsize=(10, 6)) 212 plt.bar(words, counts, color='skyblue') 213 plt.title('参与度高的视频标题中的前10个单词') 214 plt.xlabel('单词') 215 plt.ylabel('出现次数') 216 plt.xticks(rotation=45) 217 plt.show() 218 # 4.深入分析 219 # 4.1内容聚类分析 220 # 目标:识别具有相似特征的视频组。 221 # 方法:将聚类技术应用于基于主题、风格、参与度和其他因素的视频分组。 222 # 实用性:发现新兴的利基市场和趋势,有助于有针对性的内容创建。 223 from sklearn.preprocessing import StandardScaler 224 from sklearn.cluster import KMeans 225 # 选择用于聚类的相关特征 226 features = data[['views', 'likes', 'comment_count', 'category_id']] 227 # 标准化特征 228 scaler = StandardScaler() 229 scaled_features = scaler.fit_transform(features) 230 # 应用K-means聚类 231 kmeans = KMeans(n_clusters=5, random_state=42, n_init=10) # 调整'n_init'以避免警告 232 clusters = kmeans.fit_predict(scaled_features) 233 data['cluster'] = clusters 234 # 使用修正后的语法分析结果 235 clustered_data = data.groupby('cluster')[['views', 'likes', 'comment_count', 'category_id']].mean() 236 # 可选:可视化聚类结果(选择两个特征) 237 plt.scatter(scaled_features[:, 0], scaled_features[:, 1], c=clusters, cmap='viridis') 238 plt.xlabel('标准化观看数') 239 plt.ylabel('标准化点赞数') 240 plt.title('内容聚类可视化') 241 plt.show() 242 # 4.2参与因素分析 243 # 目标:确定哪些因素与高参与度最相关。 244 # 方法:使用统计技术将各种变量(如视频持续时间、类别、发布时间)与参与度指标相关联。 245 # 实用程序:提供有关如何优化视频以最大限度地提高参与度的见解。 246 # 使用正确的格式解析'publish_date' 247 data['publish_date'] = pd.to_datetime(data['publish_date'], dayfirst=True) 248 data['publish_hour'] = data['publish_date'].dt.hour 249 # 创建参与度指数 250 data['engagement_score'] = data['views'] + data['likes'] + data['comment_count'] 251 # 相关性分析:类别、发布小时与参与度指数的相关性 252 correlation_matrix = data[['category_id', 'publish_hour', 'engagement_score']].corr() 253 # 可视化相关性矩阵 254 plt.figure(figsize=(8, 6)) 255 sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm') 256 plt.title('参与度因素的相关性矩阵') 257 plt.show() 258 # 分析每个类别和每个发布小时的平均参与度指数 259 category_engagement = data.groupby('category_id')['engagement_score'].mean() 260 hour_engagement = data.groupby('publish_hour')['engagement_score'].mean() 261 plt.figure(figsize=(12, 5)) 262 plt.subplot(1, 2, 1) 263 category_engagement.plot(kind='bar') 264 plt.title('不同类别的平均参与度指数') 265 plt.xlabel('类别 ID') 266 plt.ylabel('平均参与度指数') 267 plt.subplot(1, 2, 2) 268 hour_engagement.plot(kind='bar') 269 plt.title('不同发布小时的平均参与度指数') 270 plt.xlabel('发布小时') 271 plt.ylabel('平均参与度指数') 272 plt.tight_layout() 273 plt.show() 274 # 5.预测趋势算法 275 # 目标:预测哪些类型的视频最有可能成为趋势。 276 # 方法:使用机器学习建立预测模型,考虑标题、标签、出版时间和历史参与数据等变量。 277 # 实用性:帮助内容创作者规划和创建具有更大成功潜力的视频。 278 from sklearn.model_selection import train_test_split 279 from sklearn.linear_model import LogisticRegression 280 from sklearn.preprocessing import LabelEncoder, StandardScaler 281 from sklearn.metrics import accuracy_score 282 # 创建二元目标变量来表示高参与度(例如,参与度排名前25%) 283 engagement_threshold = data['views'].quantile(0.75) 284 data['high_engagement'] = (data['views'] >= engagement_threshold).astype(int) 285 # 对分类变量(如'tags')进行编码并对数据进行标准化 286 label_encoder = LabelEncoder() 287 data['tags_encoded'] = label_encoder.fit_transform(data['tags']) 288 data['category_id_encoded'] = label_encoder.fit_transform(data['category_id']) 289 # 选择用于模型的相关特征 290 features = data[['tags_encoded', 'category_id_encoded']] 291 target = data['high_engagement'] 292 # 将数据拆分为训练集和测试集 293 X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.3, random_state=42) 294 # 对特征进行标准化 295 scaler = StandardScaler() 296 X_train_scaled = scaler.fit_transform(X_train) 297 X_test_scaled = scaler.transform(X_test) 298 # 构建逻辑回归模型 299 model = LogisticRegression() 300 model.fit(X_train_scaled, y_train) 301 # 预测并评估模型 302 predictions = model.predict(X_test_scaled) 303 accuracy = accuracy_score(y_test, predictions) 304 print(f'模型准确率:{accuracy}') 305 # 绘制柱状图 306 plt.figure(figsize=(10, 6)) 307 data['category_id'].value_counts().plot(kind='bar') 308 plt.xlabel('Category ID') 309 plt.ylabel('Count') 310 plt.title('Distribution of Category ID') 311 plt.show() 312 # 绘制箱线图 313 plt.figure(figsize=(10, 6)) 314 sns.boxplot(data=data[['views', 'likes', 'dislikes', 'comment_count']]) 315 plt.xlabel('Variable') 316 plt.ylabel('Count') 317 plt.title('Distribution of Views, Likes, Dislikes, and Comment Count') 318 plt.show() 319 # 绘制折线图 320 plt.figure(figsize=(10, 6)) 321 data['trending_date'] = pd.to_datetime(data['trending_date'], format='%y.%d.%m') 322 data.groupby('trending_date')['views'].sum().plot() 323 plt.xlabel('Trending Date') 324 plt.ylabel('Total Views') 325 plt.title('Total Views by Trending Date') 326 plt.show()
四、总结
我的研究强调了数据科学在增强YouTube等数字平台内容创作方面的关键作用。
通过各种分析,包括观众参与度的趋势、标题中的单词意义和内容分类,我深入了解了影响观众互动的因素。虽然我的预测模型确定了影响视频流行的关键因素,但它也指出需要更广泛地了解观众的偏好。
这种方法强调了数据驱动策略在内容创作中的价值,使创作者能够更紧密地与数字环境中不断变化的观众趋势和兴趣保持一致。
模型的准确率约为74.8%。这一准确度水平表明,尽管该模型具有良好的预测能力,但仍有改进的空间。这表明视频的标签和类别对预测参与度有影响,但也意味着模型中未包括的其他因素可能会影响视频的成功。