1.前言
最近找工作找的心灰意冷,闲来无事,同学让我帮忙写一个爬虫,爬取某校的过程表。我看了看网站就答应了下来,反正也没有面试就帮忙写了写。不写不知道,一写吓一跳,技术学了不用就会忘记。
2.初始化项目
我们先查看登录网址结构,发现登录页面有验证码
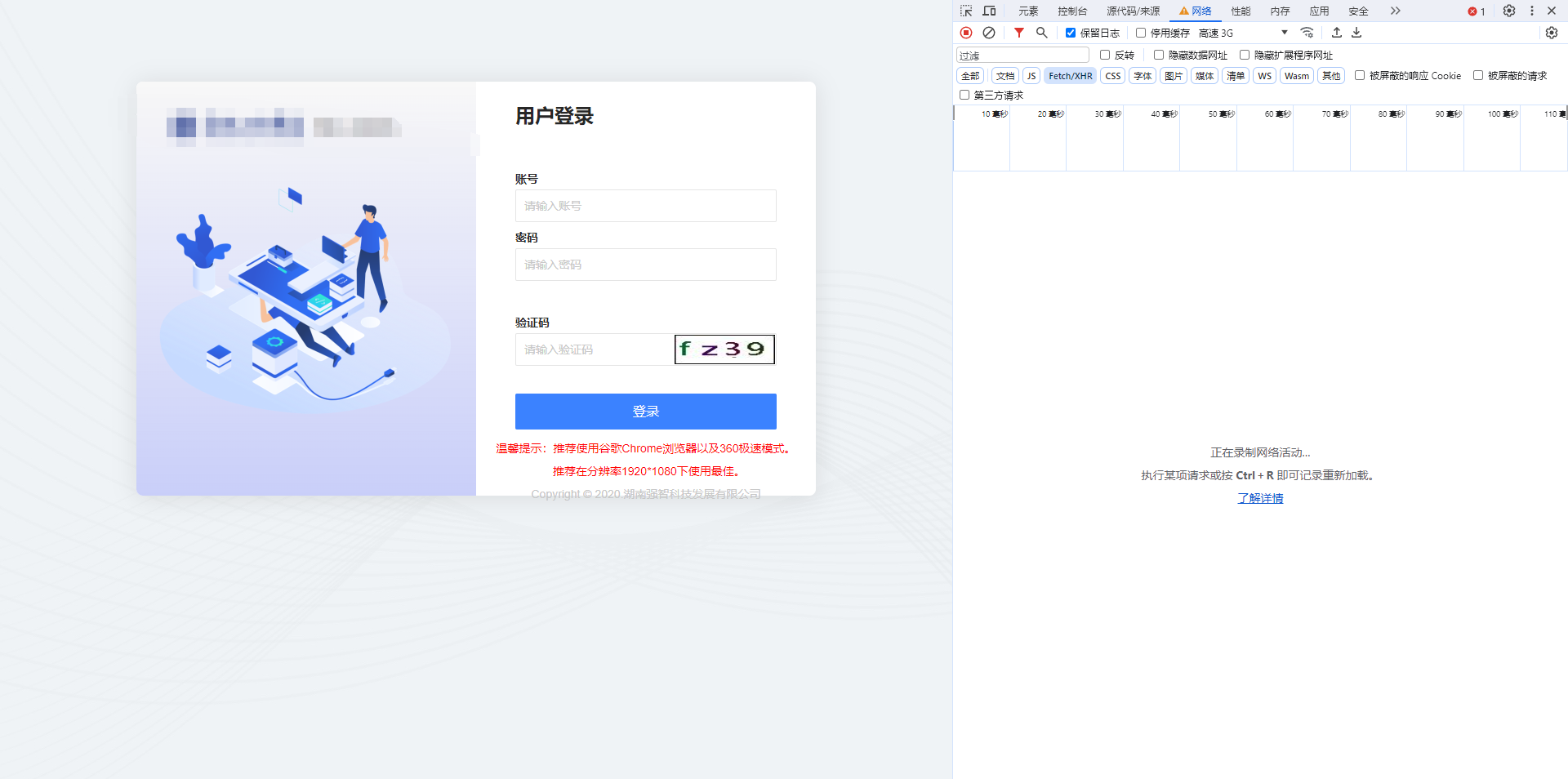
先创建一个python工程项目创建好文件夹,定义一个__init__方法
class Spider:
def __init__(self, url, header, username, password, cookies: dict = None):
if cookies is None:
cookies = {}
self.user_url = url # 地址
self.username = username # 登录账号
self.password = password # 登录密码
self.header = header # 请求头
self.cookies = cookies # Cookie
self.session = requests.session() # session
3.验证码
我们先获取到验证码网址请求路径,发现一下路径并把这个验证码下载下来以便我们后面识别
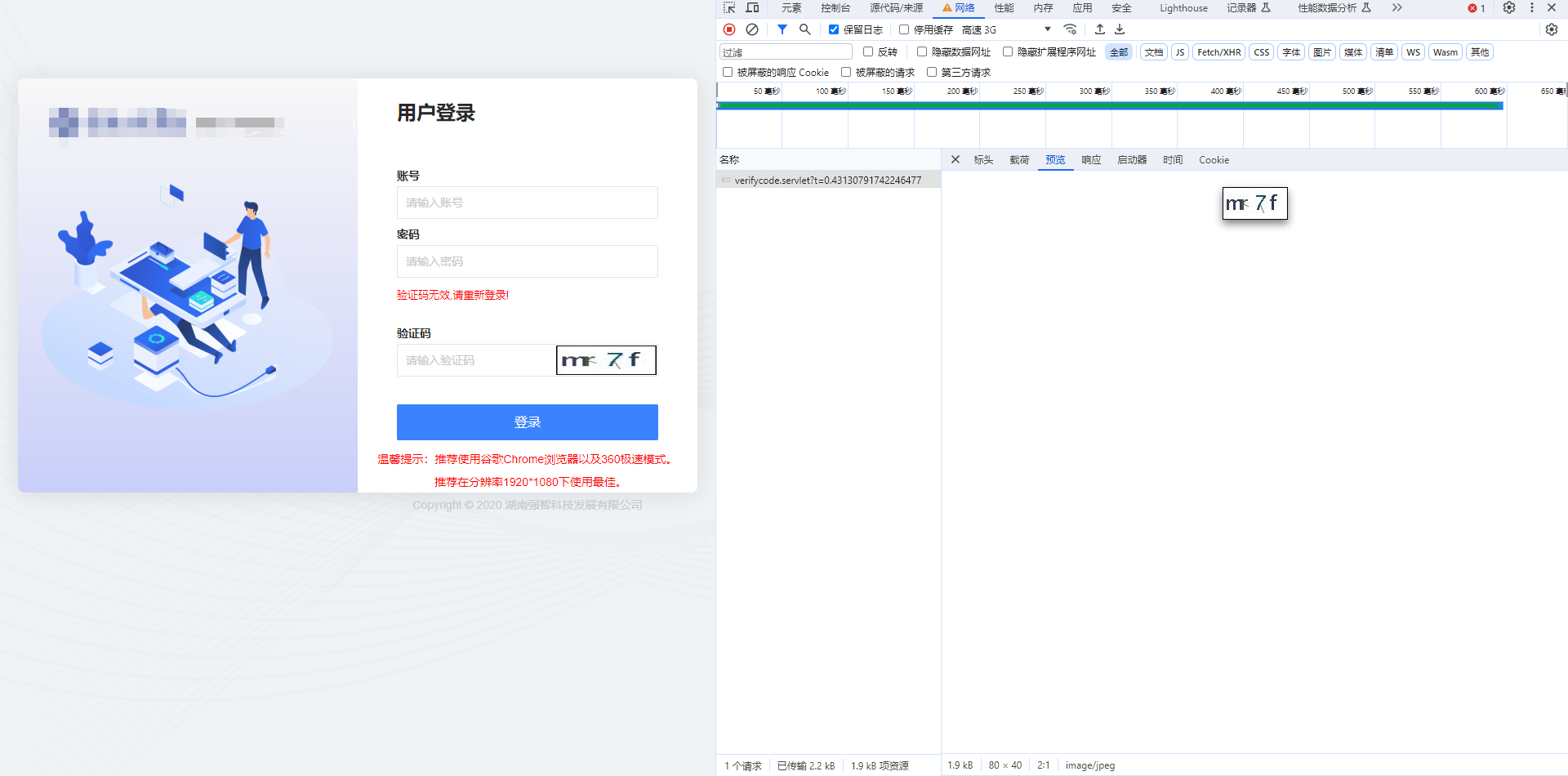
# 获取到验证码图片
def res_images(self):
img_url = "http://jwcmis.hnie.edu.cn/verifycode.servlet?t=0.2596572863703799"
verification_code = self.session.get(img_url, headers=self.header)
if verification_code.status_code != 200:
print("获取验证码失败")
return False
print("这是验证码图片cookie", verification_code.cookies)
for data in verification_code.cookies:
print(data.name, data.value)
self.cookies[data.name] = data.value
print(self.cookies)
verify_path = os.getcwd() + r"\images" # 验证码保存路径
verify_name = r"\yefeng" + "001" + ".png" # 验证码名称
images_path = verify_path + verify_name
with open(images_path, "wb") as fp:
fp.write(verification_code.content)
return images_path
在获取验证码之后我们要借用PIL去打开我们下载好的验证码,在利用pytesseract去识别验证码,并把识别好的文本保存
# 验证码识别
def image_identify(self, images_path):
if not os.path.exists(images_path):
print("没有图片文件", images_path)
raise Exception("没有图片文件")
# 边缘保留滤波 去噪
# 读取验证码图片
image = Image.open(images_path)
# 将图像转换为灰度
image = image.convert('L')
_, image = cv.threshold(np.array(image), 128, 255, cv.THRESH_BINARY)
# 使用Tesseract进行识别
verify_text = pytesseract.image_to_string(image)
analysis_text = re.sub(u"([^\u0041-\u005a\u0061-\u007a\u0030-\u0039])", "", verify_text)
# 打印识别结果
print("验证码识别结果:", analysis_text)
return analysis_text
4.登录
当我们拿到识别好的验证码之后我们可以尝试去发送登录请求,这个地方重点来了这个网站登录的时候有好几个坑,它的第一个坑就是在我们访问到这个页面的时候要携带两个Cookie,而这个两个Cookie当你访问这个登录页面的时候会给你保存到浏览器当中,如果我们使用request请求的话是没有这两个Cookie的所以我们要先拿到这个Cookie
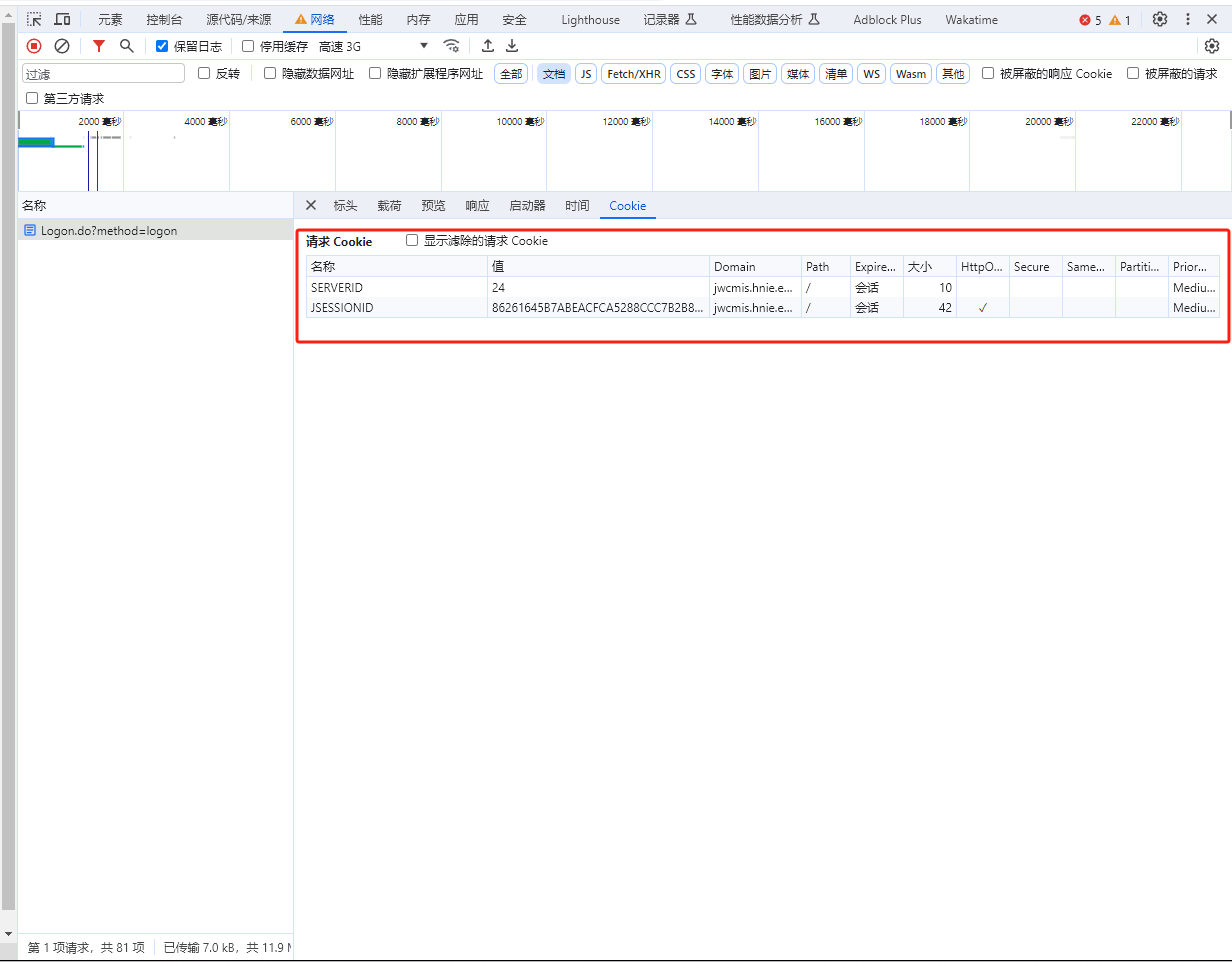
# 登录前加载页面获取cookie
def get_login_page(self):
url = "http://jwcmis.hnie.edu.cn/"
res = self.session.get(url, headers=self.header)
print("登录页面加载cookie", res.cookies)
if res.status_code != 200:
print("登录页面加载异常")
return False
for cookie in res.cookies:
self.cookies[cookie.name] = cookie.value
return True
拿到这两个Cookie这还是第一步,第二步是拿到密码加密密钥,这个网站它给了一个密码加密密钥
# 获取dataStr
def get_dataStr(self):
url = "http://jwcmis.hnie.edu.cn/Logon.do?method=logon&flag=sess"
res = self.session.post(url, headers=self.header)
if res.status_code == 200:
return res.text
return False
拿到这个加密密钥我们要对密码进行处理,这个处理方式就不介绍了因为我在爬取的时候踩了一个大坑,直接看代码吧
# 获取encode
def get_encode(self, dataStr):
data_split = dataStr.split("#")
scode = data_split[0]
sxh = data_split[1]
code = self.username + "%%%" + self.password
encoded = ""
i = 0
while i < len(code):
if i < 20:
encoded += code[i:i + 1] + scode[0:int(sxh[i:i + 1])]
scode = scode[int(sxh[i:i + 1]):len(scode)]
else:
encoded += code[i:len(code)]
i = len(code)
i += 1
return encoded
拿到之后,我们处理好这个密钥就可以去尝试发送登录请求了,具体代码如下
# 登录
def login(self, captcha_text, encode):
url = "http://jwcmis.hnie.edu.cn/Logon.do?method=logon"
data = {
"userAccount": self.username,
"userPassword": "",
"RANDOMCODE": captcha_text,
"encoded": encode
}
print("登录参数", data)
response = self.session.post(url, data=data, headers=self.header, cookies=self.cookies, allow_redirects=True)
print("登录状态", response.status_code)
print("登录状态", response.headers)
print("登录状态", response.cookies)
# print(response.text)
if response.status_code == 200:
if response.text.__contains__("该帐号不存在或密码错误"):
print("账号密码错误")
elif response.text.__contains__("验证码错误"):
print("验证码错误")
if response.status_code == 200:
# 将Cookie保存下来
self.cookies = ""
for data in response.cookies:
self.cookies[data.name] = data.value
print(self.cookies)
# 保存登录时跳转的页面
url = "http://jwcmis.hnie.edu.cn/jsxsd/framework/xsMainV.htmlx"
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0",
'Accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
'Accept-Encoding': "gzip, deflate",
'Cache-Control': "max-age=0",
'Upgrade-Insecure-Requests': "1",
'Referer': "http://jwcmis.hnie.edu.cn/jsxsd/",
'Accept-Language': "zh-CN,zh;q=0.9",
}
self.header = headers
response = self.session.get(url, headers=headers, cookies=self.cookies)
return response
else:
print("error")
return False
这个时候我们登录成功之后,分析网页得出以下代码:
# 处理列表
def handle_list(self, st_list):
if len(st_list) > 0:
return st_list[0].replace(" ", "").strip()
return ""
# 解析课程
def Analysis_course(self):
url = "http://jwcmis.hnie.edu.cn/jsxsd/framework/mainV_index_loadkb.htmlx?rq=all&sjmsValue=A8D5DE61BEA64EB79D2C4FDCE246D8FB&xnxqid=2023-2024-1&xswk=false"
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0",
'Accept': "text/html, */*; q=0.01",
'Accept-Encoding': "gzip, deflate",
'X-Requested-With': "XMLHttpRequest",
'Referer': "http://jwcmis.hnie.edu.cn/jsxsd/framework/xsMainV_new.htmlx?t1=1",
'Accept-Language': "zh-CN,zh;q=0.9",
}
res = self.session.get(url, headers=headers, cookies=self.cookies)
print("下载课程情况", res.status_code)
if res.status_code != 200:
raise Exception("获取异常")
html = etree.HTML(res.text)
headers = []
head_node = html.xpath("/html/body/table/thead/tr/th")
for i in head_node:
name = self.handle_list(i.xpath("./text()"))
headers.append(name)
body_data = html.xpath("/html/body/table/tbody/tr")
bady = []
for i in body_data:
data = []
class_node = i.xpath("./td")
flag = False
for j in range(len(class_node)):
if flag:
value = self.handle_list(class_node[j].xpath("./text()"))
data.append(value)
elif j == 0:
value = "".join(class_node[j].xpath("./text()")).replace(" ", "").strip()
data.append(value)
if value.__contains__("备注"):
flag = True
else:
# 课程
name = class_node[j].xpath("./div[@class='item-box']/p/text()")
# 学分
tch_name = class_node[j].xpath("./div[@class='item-box']/div[@class='tch-name']/span/text()")
# 上课地址 以及 上课周期
address = class_node[j].xpath("./div[@class='item-box']/div[not(@class)]/span[1]/text()")
num_class = class_node[j].xpath("./div[@class='item-box']/div[not(@class)]/span[2]/text()")
teacher_name = self.handle_list(class_node[j].xpath("./span[1]/p[2]/text()"))
# print(name)
# print(tch_name)
# print(address)
# print(num_class)
# print(teacher_name)
str_msg = ""
str_msg += teacher_name
for num in range(len(name)):
str_msg += "\n" + name[num]
for u in range(num, (num + 1) * 2):
str_msg += "\n" + tch_name[u]
str_msg += "\n" + address[num]
str_msg += "\n" + num_class[num]
data.append(str_msg)
bady.append(data)
print(bady)
return bady
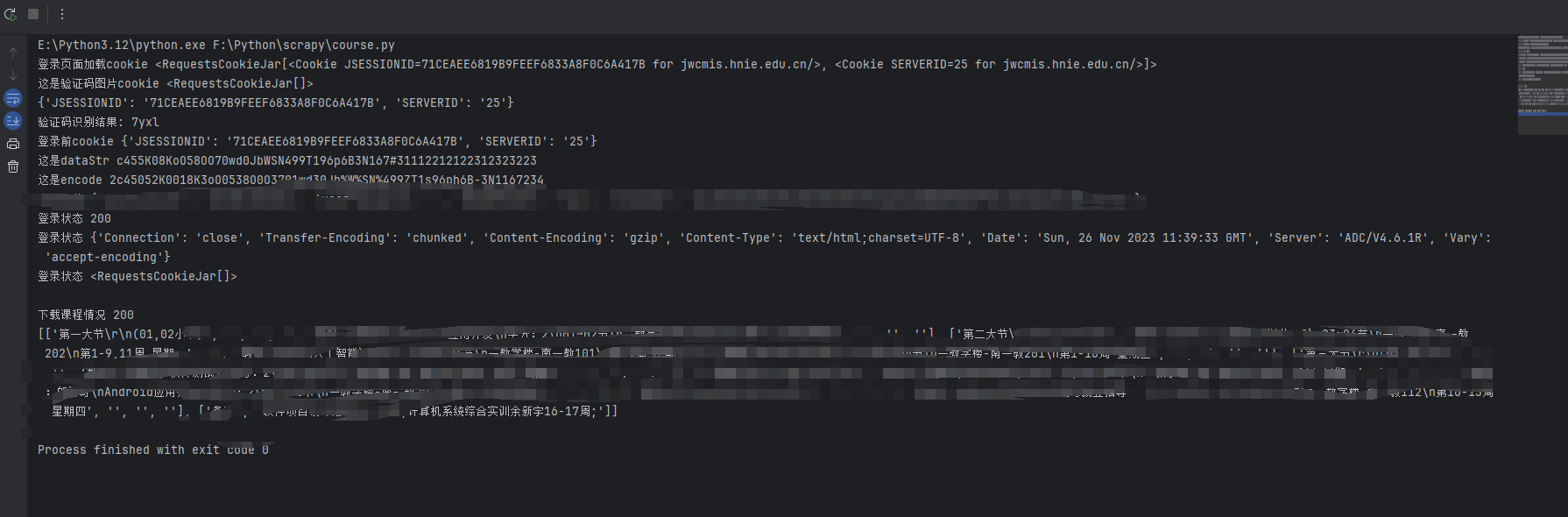
验证码识别会有点问题,会出现识别错误的情况,出现这种问题就在跑一次,完整代码如下
import os
import re
import requests
import cv2 as cv
import numpy as np
from lxml import etree
import pytesseract
from PIL import Image
class Spider:
def __init__(self, url, header, username, password, cookies: dict = None):
if cookies is None:
cookies = {}
self.user_url = url
self.username = username
self.password = password
self.header = header
self.cookies = cookies
self.session = requests.session()
def run(self):
# 加载登录页面获取登录Cookie
logis = self.get_login_page()
if not logis:
print("登录页面加载失败")
exit()
images_path = self.res_images()
analysis_text = self.image_identify(images_path)
print("登录前cookie", self.cookies)
dataStr = self.get_dataStr()
if not dataStr:
print("获取dataStr失败")
return
print("这是dataStr", dataStr)
encode = self.get_encode(dataStr)
print("这是encode", encode)
response = self.login(analysis_text, encode=encode)
if not response:
raise Exception("登录失败")
self.Analysis_course()
# 登录前加载页面获取cookie
def get_login_page(self):
url = "http://jwcmis.hnie.edu.cn/"
res = self.session.get(url, headers=self.header)
print("登录页面加载cookie", res.cookies)
if res.status_code != 200:
print("登录页面加载异常")
return False
for cookie in res.cookies:
self.cookies[cookie.name] = cookie.value
return True
# 获取dataStr
def get_dataStr(self):
url = "http://jwcmis.hnie.edu.cn/Logon.do?method=logon&flag=sess"
res = self.session.post(url, headers=self.header)
if res.status_code == 200:
return res.text
return False
# 获取到验证码图片
def res_images(self):
img_url = "http://jwcmis.hnie.edu.cn/verifycode.servlet?t=0.2596572863703799"
verification_code = self.session.get(img_url, headers=self.header)
if verification_code.status_code != 200:
print("获取验证码失败")
return False
print("这是验证码图片cookie", verification_code.cookies)
for data in verification_code.cookies:
print(data.name, data.value)
self.cookies[data.name] = data.value
print(self.cookies)
verify_path = os.getcwd() + r"\images"
verify_name = r"\yefeng" + "001" + ".png"
images_path = verify_path + verify_name
with open(images_path, "wb") as fp:
fp.write(verification_code.content)
return images_path
# 验证码识别
def image_identify(self, images_path):
if not os.path.exists(images_path):
print("没有图片文件", images_path)
raise Exception("没有图片文件")
# 边缘保留滤波 去噪
# 读取验证码图片
image = Image.open(images_path)
# 将图像转换为灰度
image = image.convert('L')
_, image = cv.threshold(np.array(image), 128, 255, cv.THRESH_BINARY)
# 使用Tesseract进行识别
verify_text = pytesseract.image_to_string(image)
analysis_text = re.sub(u"([^\u0041-\u005a\u0061-\u007a\u0030-\u0039])", "", verify_text)
# 打印识别结果
print("验证码识别结果:", analysis_text)
return analysis_text
# 获取encode
def get_encode(self, dataStr):
data_split = dataStr.split("#")
scode = data_split[0]
sxh = data_split[1]
code = self.username + "%%%" + self.password
encoded = ""
i = 0
while i < len(code):
if i < 20:
encoded += code[i:i + 1] + scode[0:int(sxh[i:i + 1])]
scode = scode[int(sxh[i:i + 1]):len(scode)]
else:
encoded += code[i:len(code)]
i = len(code)
i += 1
return encoded
# 登录
def login(self, captcha_text, encode):
url = "http://jwcmis.hnie.edu.cn/Logon.do?method=logon"
data = {
"userAccount": self.username,
"userPassword": "",
"RANDOMCODE": captcha_text,
"encoded": encode
}
print("登录参数", data)
response = self.session.post(url, data=data, headers=self.header, cookies=self.cookies, allow_redirects=True)
print("登录状态", response.status_code)
print("登录状态", response.headers)
print("登录状态", response.cookies)
# print(response.text)
if response.status_code == 200:
if response.text.__contains__("该帐号不存在或密码错误"):
print("账号密码错误")
elif response.text.__contains__("验证码错误"):
print("验证码错误")
if response.status_code == 200:
# 将Cookie保存下来
self.cookies = ""
for data in response.cookies:
self.cookies[data.name] = data.value
print(self.cookies)
# 保存登录时跳转的页面
url = "http://jwcmis.hnie.edu.cn/jsxsd/framework/xsMainV.htmlx"
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0",
'Accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
'Accept-Encoding': "gzip, deflate",
'Cache-Control': "max-age=0",
'Upgrade-Insecure-Requests': "1",
'Referer': "http://jwcmis.hnie.edu.cn/jsxsd/",
'Accept-Language': "zh-CN,zh;q=0.9",
}
self.header = headers
response = self.session.get(url, headers=headers, cookies=self.cookies)
return response
else:
print("error")
return False
# 处理列表
def handle_list(self, st_list):
if len(st_list) > 0:
return st_list[0].replace(" ", "").strip()
return ""
# 解析课程
def Analysis_course(self):
url = "http://jwcmis.hnie.edu.cn/jsxsd/framework/mainV_index_loadkb.htmlx?rq=all&sjmsValue=A8D5DE61BEA64EB79D2C4FDCE246D8FB&xnxqid=2023-2024-1&xswk=false"
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0",
'Accept': "text/html, */*; q=0.01",
'Accept-Encoding': "gzip, deflate",
'X-Requested-With': "XMLHttpRequest",
'Referer': "http://jwcmis.hnie.edu.cn/jsxsd/framework/xsMainV_new.htmlx?t1=1",
'Accept-Language': "zh-CN,zh;q=0.9",
}
res = self.session.get(url, headers=headers, cookies=self.cookies)
print("下载课程情况", res.status_code)
if res.status_code != 200:
raise Exception("获取异常")
html = etree.HTML(res.text)
headers = []
head_node = html.xpath("/html/body/table/thead/tr/th")
for i in head_node:
name = self.handle_list(i.xpath("./text()"))
headers.append(name)
body_data = html.xpath("/html/body/table/tbody/tr")
bady = []
for i in body_data:
data = []
class_node = i.xpath("./td")
flag = False
for j in range(len(class_node)):
if flag:
value = self.handle_list(class_node[j].xpath("./text()"))
data.append(value)
elif j == 0:
value = "".join(class_node[j].xpath("./text()")).replace(" ", "").strip()
data.append(value)
if value.__contains__("备注"):
flag = True
else:
# 课程
name = class_node[j].xpath("./div[@class='item-box']/p/text()")
# 学分
tch_name = class_node[j].xpath("./div[@class='item-box']/div[@class='tch-name']/span/text()")
# 上课地址 以及 上课周期
address = class_node[j].xpath("./div[@class='item-box']/div[not(@class)]/span[1]/text()")
num_class = class_node[j].xpath("./div[@class='item-box']/div[not(@class)]/span[2]/text()")
teacher_name = self.handle_list(class_node[j].xpath("./span[1]/p[2]/text()"))
# print(name)
# print(tch_name)
# print(address)
# print(num_class)
# print(teacher_name)
str_msg = ""
str_msg += teacher_name
for num in range(len(name)):
str_msg += "\n" + name[num]
for u in range(num, (num + 1) * 2):
str_msg += "\n" + tch_name[u]
str_msg += "\n" + address[num]
str_msg += "\n" + num_class[num]
data.append(str_msg)
bady.append(data)
print(bady)
return bady
if __name__ == '__main__':
url = "http://jwcmis.hnie.edu.cn/verifycode.servlet?t=0.2596572863703799"
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0",
}
session = requests.Session()
s = Spider(url, headers, "账号", "密码")
s.run()