数据结构
/* ZSETs use a specialized version of Skiplists */ typedef struct zskiplistNode { sds ele; double score; struct zskiplistNode *backward; struct zskiplistLevel { struct zskiplistNode *forward; unsigned long span; } level[]; } zskiplistNode; typedef struct zskiplist { struct zskiplistNode *header, *tail; unsigned long length; int level; } zskiplist; typedef struct zset { dict *dict; zskiplist *zsl; } zset;
- score:分值,用于排序。
- backward:是第一层的前一个数据,即span=1。
- level[]:每一个层所代表的节点node。
- forward:该层级的下一个节点。
- span:到达该层级的下一个节点,实际跨越了多少个节点,也是方便用于zrange等排行榜查询的用处。
有序链表只能逐一查找元素,导致操作起来非常缓慢,于是就出现了跳表。具体来说,跳表在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位,如下图所示:
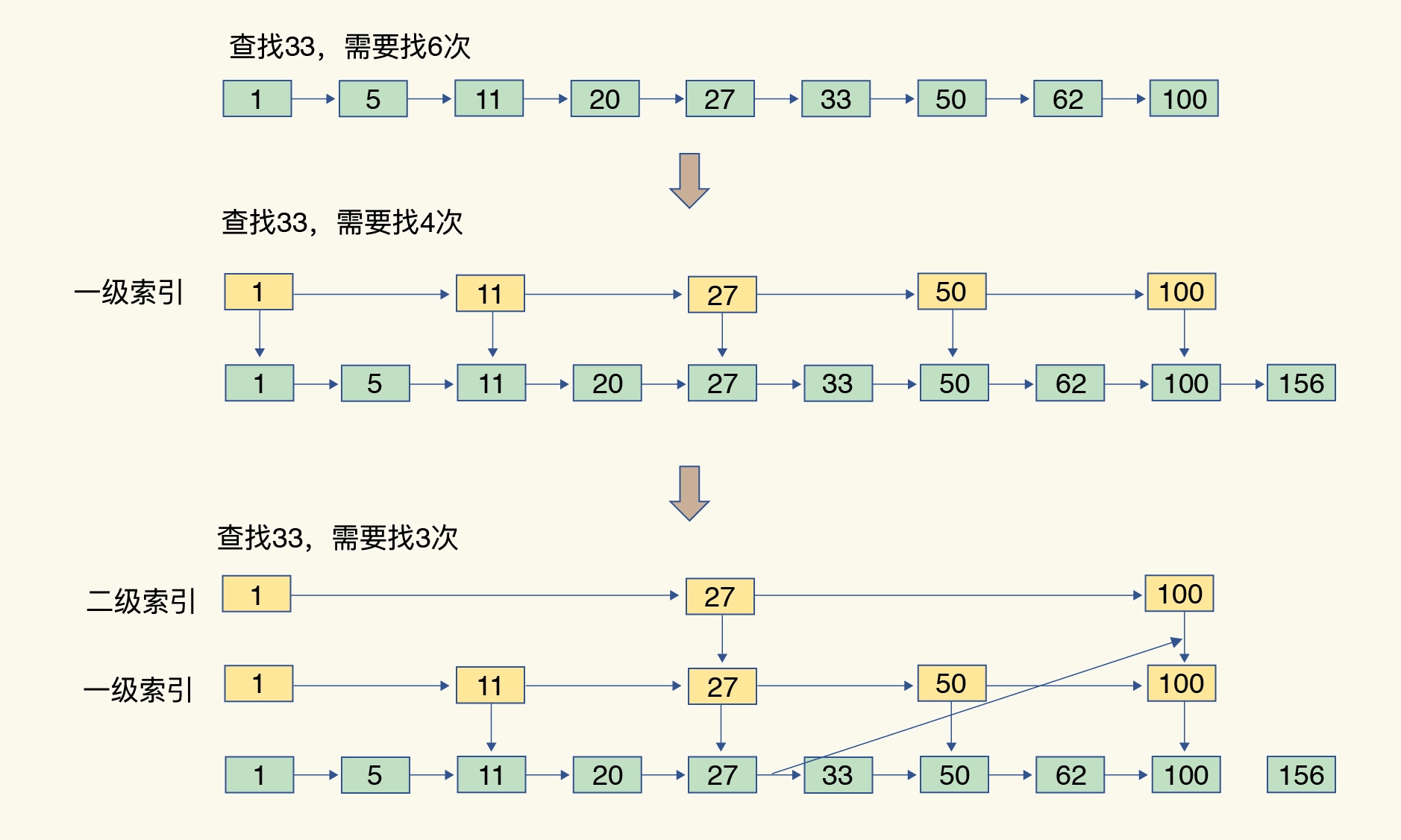
跳表性质
- 由很多层组成
- 每一层都是一个有序链表
- 最底层的链表包含所有元素
- 如果一个元素出现在第i层的链表中,则它在i-1层中也会出现。
- 上层节点可以跳转到下层。
跳表的查找、插入复杂度就是 O(logN)。
Redis为什么使用skiplist而不是平衡树
Redis中的skiplist主要是为了实现sorted set相关的功能,红黑树当然也能实现其功能,为什么redis作者当初在实现的时候用了skiplist而不是红黑树、b树之类的平衡树? 而且显然红黑树比skiplist更节省内存啊! Redis的作者antirez也曾经亲自回应过这个问题,原文见:https://news.ycombinator.com/item?id=1171423
- skiplist并不是特别耗内存,只需要调整下节点到更高level的概率,就可以做到比B树更少的内存消耗。
- sorted set可能会面对大量的zrange和zreverange操作,跳表作为单链表遍历的实现性能不亚于其他的平衡树。
- 实现和调试起来比较简单。 例如,实现O(log(N))时间复杂度的ZRANK只需要简单修改下代码即可。