简介
在训练好模型之后,往往需要将其搭建为一个服务,使得他人能够进行调用。最常见的方案,可能就是借助flask、fastapi等配置较为容易web框架进行服务搭建。但是,根据需求,有时不仅会让我们搭建一个基本的服务,还需要进行前端样式配置,比如毕设的演示系统。笔者作为一名算法人员,前端的知识不能说不会,但是每次写前端的内容,都会有些力不从心。还记得笔者在研究生毕业时搭建的演示系统,一通操作,最后的效果也还是有些差强人意。
那么,有没有一款能够快速搭建演示系统的工具的呢?答案是有的,本章节将要讲解的Gradio便是一款非常简洁易用的演示系统搭建工具。只需要几行代码,便可以得到一个效果非常好的演示系统。
本章节中,将介绍如何使用Gradio搭建演示系统,下面让我们开始吧!
环境配置
直接使用pip进行gradio的安装即可
pip install gradio快速启动
在Gradio中搭建一个实用的自然语言处理应用最少只需要三行代码!
下面,让我们三行代码来搭建一个文本分类模型的演示系统,这里使用的模型是uer/roberta-base-finetuned-dianping-chinese,代码如下
# 导入gradio
import gradio as gr
# 导入transformers相关包
from transformers import *
# 通过Interface加载pipeline并启动服务
gr.Interface.from_pipeline(pipeline("text-classification", model="uer/roberta-base-finetuned-dianping-chinese")).launch()直接运行即可,运行后,服务默认会启动在本地的7860端口,输入http://127.0.0.1:7860/,即可得到如下的界面,非常的干净简洁
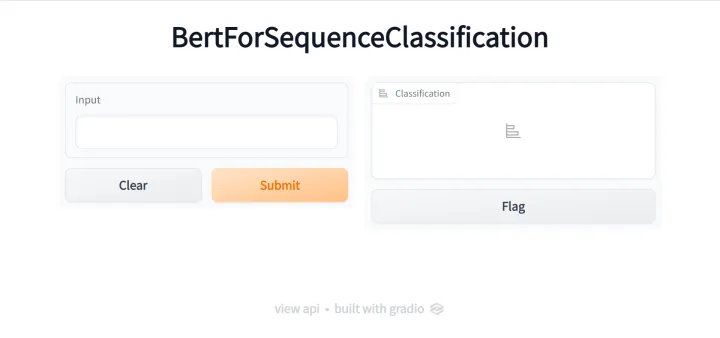
我们可以在左侧输入待分类文本,而后点击submit按钮,右侧便会展示出预测的标签及概率,如下图所示

有些简单是不是,那如果是阅读理解任务呢?我们只需要修改pipeline的内容即可。
# 导入gradio
import gradio as gr
# 导入transformers相关包
from transformers import *
# 通过Interface加载pipeline并启动服务
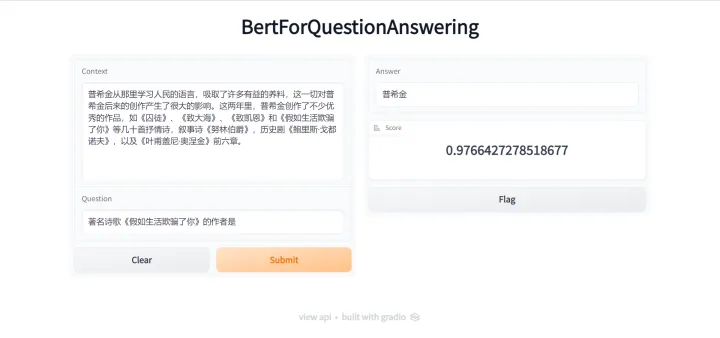
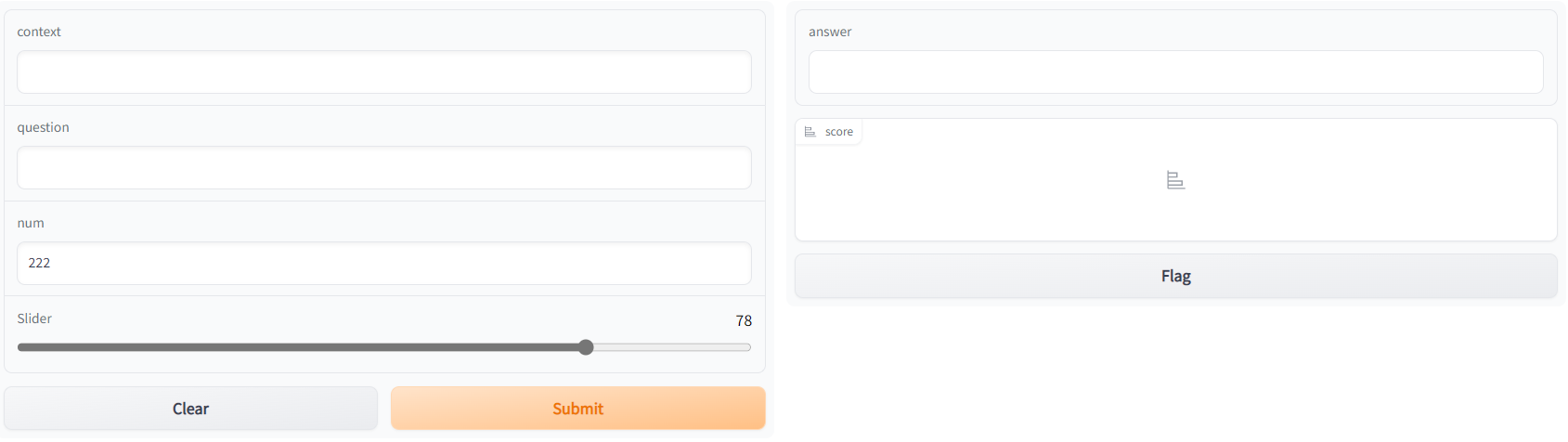
gr.Interface.from_pipeline(pipeline("question-answering", model="uer/roberta-base-finetuned-dianping-chinese")).launch()再次打开http://127.0.0.1:7860/,可以看到界面中除了几个按钮外的内容全部进行了更新,变成了阅读理解相关的内容,输入部分包括了context和question两部分,输出也变成了answer和score两部分

同样,我们也可以输入一个示例,看下效果
完善页面
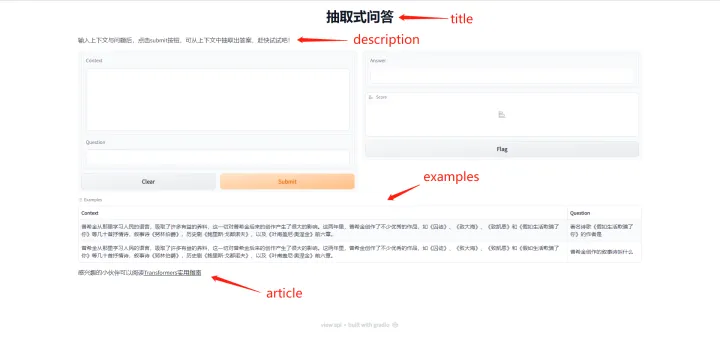
尽管我们快速的启动了一个demo,但是页面整体还是较为简陋的,除了标题和实际的调用部分,缺少一些其他内容,我们可以通过配置几个简单的参数,将页面进行完善,还是以阅读理解任务为例,代码如下:
import gradio as gr
from transformers import *
# 标题
title = "抽取式问答"
# 标题下的描述,支持md格式
description = "输入上下文与问题后,点击submit按钮,可从上下文中抽取出答案,赶快试试吧!"
# 输入样例
examples = [
["普希金从那里学习人民的语言,吸取了许多有益的养料,这一切对普希金后来的创作产生了很大的影响。这两年里,普希金创作了不少优秀的作品,如《囚徒》、《致大海》、《致凯恩》和《假如生活欺骗了你》等几十首抒情诗,叙事诗《努林伯爵》,历史剧《鲍里斯·戈都诺夫》,以及《叶甫盖尼·奥涅金》前六章。", "著名诗歌《假如生活欺骗了你》的作者是"],
["普希金从那里学习人民的语言,吸取了许多有益的养料,这一切对普希金后来的创作产生了很大的影响。这两年里,普希金创作了不少优秀的作品,如《囚徒》、《致大海》、《致凯恩》和《假如生活欺骗了你》等几十首抒情诗,叙事诗《努林伯爵》,历史剧《鲍里斯·戈都诺夫》,以及《叶甫盖尼·奥涅金》前六章。", "普希金创作的叙事诗叫什么"]
]
# 页面最后的信息,可以选择引用文章,支持md格式
article = "感兴趣的小伙伴可以阅读[Transformers实用指南](https://zhuanlan.zhihu.com/p/548336726)"
gr.Interface.from_pipeline(
pipeline("question-answering", model="uer/roberta-base-chinese-extractive-qa"),
title=title, description=description, examples=examples, article=article).launch()运行上述代码,将看到如下页面,这里的example是可以点击的,点击后将自动填充至context和question中
由于description和article字段支持md语法,因此我们可以根据需求,自行的去丰富完善各部分内容,这里就不再过多介绍了。
Interface使用
前面的内容中,我们构建演示系统都是基于pipeline的,各个部分的模块都是定义好的,快速启动的同时,在灵活性上有所欠缺,那么我们该如何自定义的去构建演示系统呢?
简单的说,就需要两步:第一步,定义执行函数;第二步,绑定执行函数并指定输入输出组件。
假设还是阅读理解任务,但是我们这次不适用基于pipeline的加载方式,而是自定义实现,要求输入包含context、question,输出包含answer和score,但是这里的answer要求要把问题拼接上,如前面的示例,answer为普希金,这里的答案要变为:著名诗歌《假如生活欺骗了你》的作者是:普希金 ,针对这一需求,我们看下要如何实现。
首先,定义执行函数。该函数输入包括context和question两部分,输出包括answer和score,本质上还是调用pipeline进行推理,但是在答案生成时我们做了额外的拼接处理。
qa = pipeline("question-answering", model="uer/roberta-base-chinese-extractive-qa")
def custom_predict(context, question):
answer_result = qa(context=context, question=question)
answer = question + ": " + answer_result["answer"]
score = answer_result["score"]
return answer, score接下来,在Interface中绑定执行函数并指定输入输出组件,fn字段绑定执行函数;inputs字段指定输入组件,这里是context和question两个文本输入,因此inputs字段的值为["text", "text"]数组(这里的text表示输入组件为TextBox,text只是一种便捷的指定方式);outputs字段指定输出组件,answer是文本输出,score可以用标签输出,这里采取了和inputs字段不一样的创建方式,我们直接创建了对应的组件,这种方式的使用优势在于可以对组件进行更精细的配置,例如这里我们便分别指定了两个输出模块的label 。
gr.Interface(fn=custom_predict, inputs=["text", "text"], outputs=[gr.Textbox(label="answer"), gr.Label(label="score")],
title=title, description=description, examples=examples, article=article).launch()1、输入输出要与函数的输入输出个数一致
2、outputs字段,推荐使用创建的方式,否则页面显示的标签都是output*,不够清晰
接下来,便可以进行运行啦~
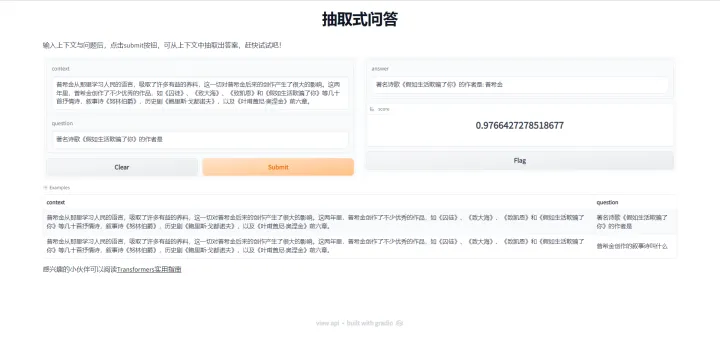
可以看到,其他的部分与我们使用pipeline创建的方式都一致,只是在answer部分有了变化。
通过这种方式,我们可以创建出更加复杂的包含任意输入、输出的系统。
关于具体可以使用哪些组件,可以参考官方的文档。
Blocks使用
事实上,Interface是一个更加高级的组件,虽然它已经支持了了一定的自定义内容,但是灵活性还是略差一些,如果有注意的话,可以回到上文看下,所有的组件都是被划分为了左右两部分,左侧输入,右侧输出。使用Interface就要接受这样的默认设定,那么假设你现在就想做成上下结构,上面输入,下面输出,那么,我们就需要用到Block。
Blocks是比Interface更加底层一些的模块,支持一些简单的自定义排版,那么下面就让我们来重构一下上面组件排列。
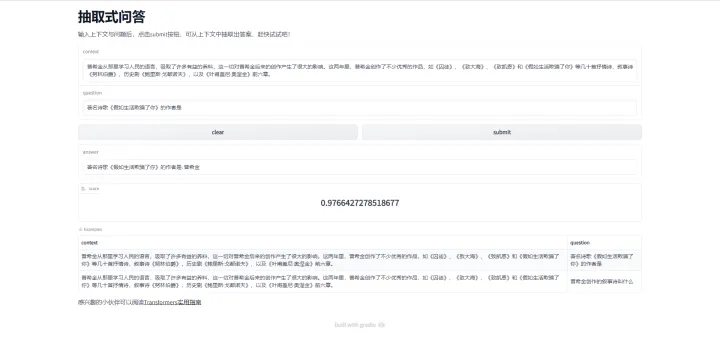
整体是上下结构,从上到下,依次是context输入、question输入,clear按钮和submit按钮(在一横排),answer输出,score输出,其余如title、examples等内容不变,代码如下
import gradio as gr
from transformers import *
title = "抽取式问答"
description = "输入上下文与问题后,点击submit按钮,可从上下文中抽取出答案,赶快试试吧!"
examples = [
["普希金从那里学习人民的语言,吸取了许多有益的养料,这一切对普希金后来的创作产生了很大的影响。这两年里,普希金创作了不少优秀的作品,如《囚徒》、《致大海》、《致凯恩》和《假如生活欺骗了你》等几十首抒情诗,叙事诗《努林伯爵》,历史剧《鲍里斯·戈都诺夫》,以及《叶甫盖尼·奥涅金》前六章。", "著名诗歌《假如生活欺骗了你》的作者是"],
["普希金从那里学习人民的语言,吸取了许多有益的养料,这一切对普希金后来的创作产生了很大的影响。这两年里,普希金创作了不少优秀的作品,如《囚徒》、《致大海》、《致凯恩》和《假如生活欺骗了你》等几十首抒情诗,叙事诗《努林伯爵》,历史剧《鲍里斯·戈都诺夫》,以及《叶甫盖尼·奥涅金》前六章。", "普希金创作的叙事诗叫什么"]
]
article = "感兴趣的小伙伴可以阅读[Transformers实用指南](https://zhuanlan.zhihu.com/p/548336726)"
# 预测函数
qa = pipeline("question-answering", model="uer/roberta-base-chinese-extractive-qa")
def custom_predict(context, question):
answer_result = qa(context=context, question=question)
answer = question + ": " + answer_result["answer"]
score = answer_result["score"]
return answer, score
# 清除输入输出
def clear_input():
return "", "", "", ""
# 构建Blocks上下文
with gr.Blocks() as demo:
gr.Markdown("# 抽取式问答")
gr.Markdown("输入上下文与问题后,点击submit按钮,可从上下文中抽取出答案,赶快试试吧!")
with gr.Column(): # 列排列
context = gr.Textbox(label="context")
question = gr.Textbox(label="question")
with gr.Row(): # 行排列
clear = gr.Button("clear")
submit = gr.Button("submit")
with gr.Column(): # 列排列
answer = gr.Textbox(label="answer")
score = gr.Label(label="score")
# 绑定submit点击函数
submit.click(fn=custom_predict, inputs=[context, question], outputs=[answer, score])
# 绑定clear点击函数
clear.click(fn=clear_input, inputs=[], outputs=[context, question, answer, score])
gr.Examples(examples, inputs=[context, question])
gr.Markdown("感兴趣的小伙伴可以阅读[Transformers实用指南](https://zhuanlan.zhihu.com/p/548336726)")
demo.launch()运行代码,我们便可以在浏览器中看到如下样式
整体来看,Blocks的代码确实是比Interface的代码要复杂一些,但是整理的逻辑是类似的,可以根据需要,选择合适的使用方式。
分享服务
最后要介绍的一点内容非常简单,也非常有意思。
当我们的服务启动起来后,还是在本地的,虽然访问是能访问了,但是还是会受到网络的限制。
Gradio提供了一种非常方便的方式,可以使得本地的服务在任何地方都可以调用。
代码上,我们只需要在launch方法调用时,指定share参数值为True。
而后,启动程序,便可以看到这样的输出

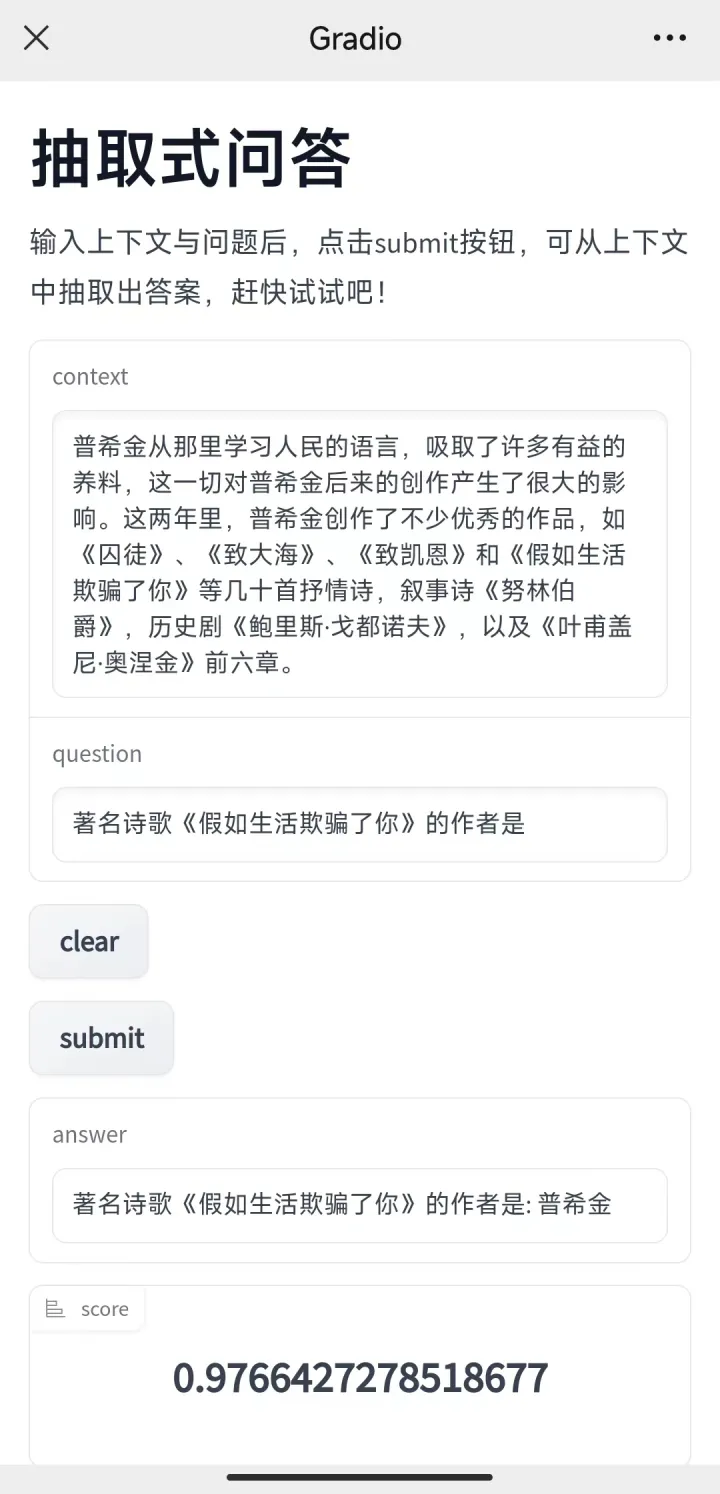
我们的服务除了有一个本地地址,还有一个公网的地址https://11886.gradio.app,虽然时间只有72小时。使用这个公网的地址,我们便可以在任何地方使用该服务,笔者使用手机打开了该链接,效果如下
总结
本章节中介绍了Gradio的基本使用,内容也比较浅,Gradio能做的还远不止这些,内容感兴趣的小伙伴们可以自行到官网中查阅~