- 参考
- http://www.dizhixiong.cn/class1/slides/2-3.pdf
- https://www.jianshu.com/p/9b342e1b73f0
- 《硬件架构的艺术》
- 《计算机组成与设计 第五版》
1. 流水线延迟
- 首先考虑未加流水线的电路延迟
- $ T_{latency}=T_{comb}+T_{register}+T_{clocking}$
- 其中$ T_{register}$是寄存器开支 $ = T_{CQ} + T_{setup}$
- 其中$ T_{clocking}$是时钟开支 \(= T_{skew} + T_{jitter}\)
- $ T_{latency}=T_{comb}+T_{register}+T_{clocking}$
- 添加n级流水线
- $ T_{pipeline} = T_{comb}/n + T_{register} + T_{clocking}$
- $ T_{latency} = nT_{pipeline} = T_{comb} + n(T_{register} + T_{clocking})$
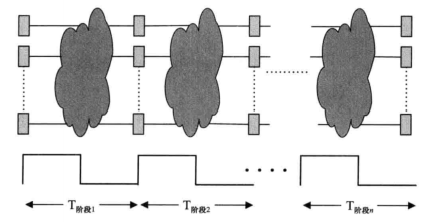
- 根据前面的计算可以得到 对于任意的流水线阶段时钟频率可以提升多少
\[ \frac{T_{comb} + T_{register} + T_{clocking}}{T_{comb}/n + T_{register} + T_{clocking}}
\]
- 差别在于组合逻辑的延迟减小了1/n。
2. 流水线深度
- 由于在使用流水线时会引入额外的开销,如时钟偏移和寄存器延迟等。这种开销会限制电路所能达到的最大频率值。
- 如果一味的增加流水线深度,收益反而会下降。
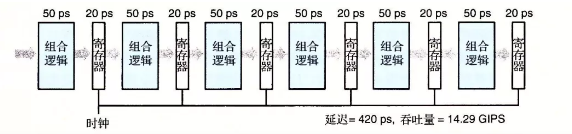
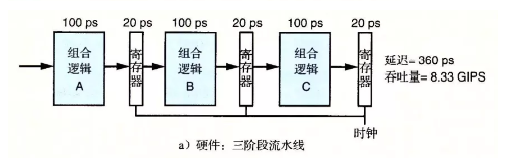
- 上面两张图分别为三级流水和六级流水,但是吞吐量并没有翻倍。因为当组合逻辑被划分的很小时,寄存器的延迟就成为一个限制因素。
3. 流水线应用
- 以RISC-V指令为例,介绍流水线的使用。
- RISC-V指令通常包含五个步骤:
- (1)从存储器中取出指令
- 从存储器中通过PC指针取出指令,放入指令寄存器(IR)中。并将PC递增,指向下一个指令地址。
- (2)读寄存器并译码指令
- 分析IR中的指令格式,并访问寄存器堆,读取寄存器值放到临时寄存器中。
- 由于指令格式是固定的,所以读寄存器和解码是可以并行进行的。
- (3)执行操作或计算地址
- ALU对上一个时钟周期准备好的操作数进行处理,根据指令格式,为下面四种情况之一。
- Store/Load
ALUoutput <= A + IMM - 寄存器-寄存器 R型指令
ALUoutput <= A op B - 寄存器-立即数 ALU指令
ALUoutput <= A op IMM - 分支指令
ALUoutput <= NPC + IMM
- Store/Load
- ALU对上一个时钟周期准备好的操作数进行处理,根据指令格式,为下面四种情况之一。
- (4)访问数据存储器中的操作数(如有必要)
- (5)将结果写入寄存器(如有必要)
- (1)从存储器中取出指令
- 针对不同的指令可能没有后两步。例如:store指令没有(5),R型指令没有(4),B型指令没有(4)和(5).
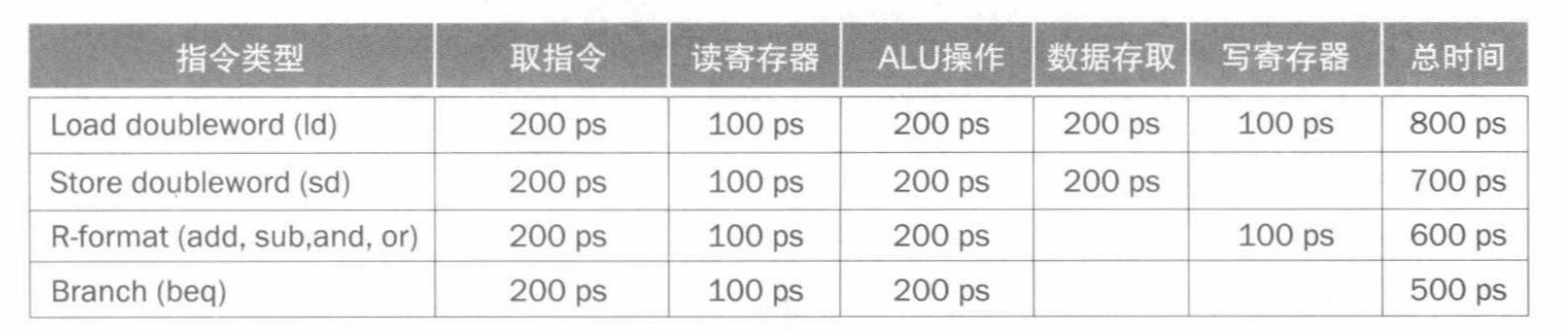
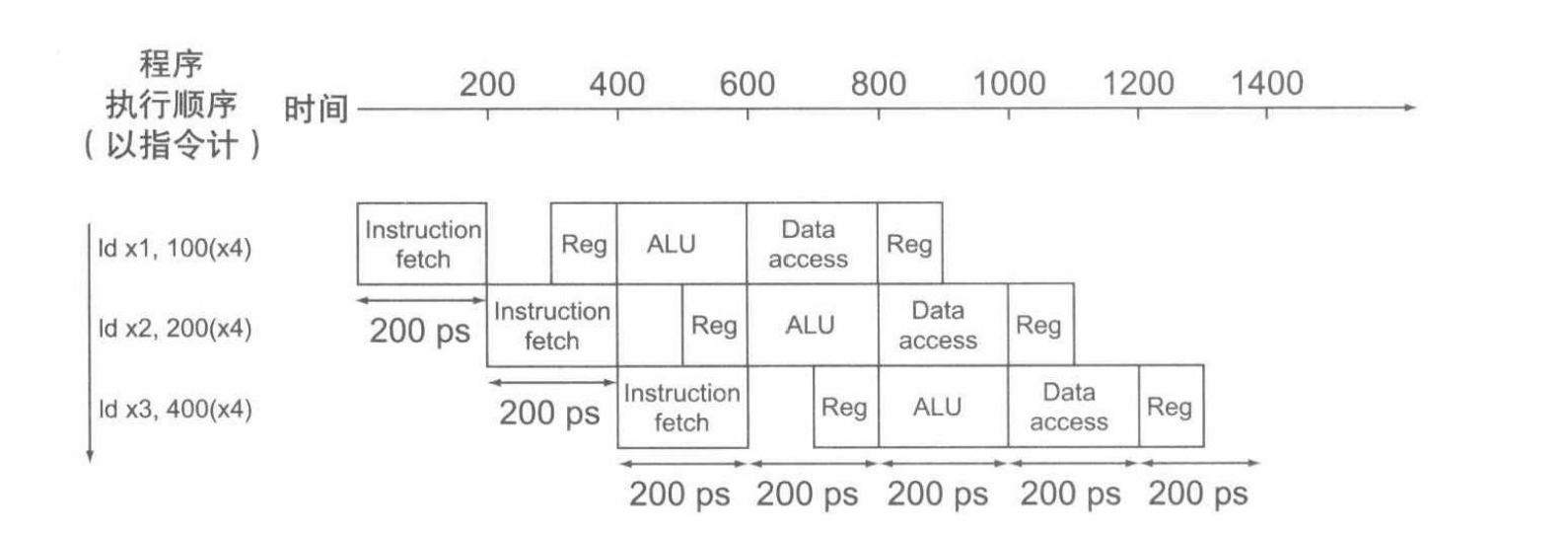
3.1 RISC-V 流水线概述
- 流水线实现指令如下图所示。
- 这里假设写寄存器和读寄存器为100ps,其余操作为200ps。
- 读寄存器发生在时钟周期的后半段,而写寄存器发生在时钟周期的前半段。
3.2 流水线冒险
-
RISC-V 流水线冒险主要有三类,下面将展开介绍。
-
结构冒险
- 硬件不支持多条指令在同一时钟周期执行。
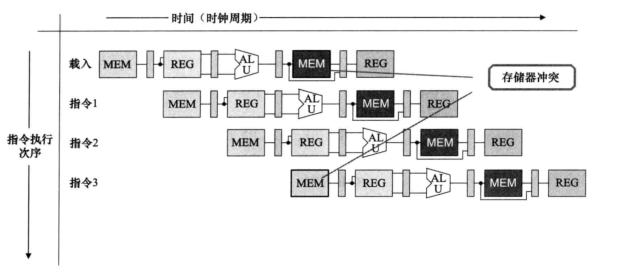
- 解决方法
- 增加一个时钟延迟,避开冲突位置。
- 在IF和MEM阶段使用不同的存储器,不会出现访问同一块存储器的冲突,但是消耗了更多的资源。
-
数据冒险
- 第一条指令后的三条指令都需要使用到R1。

- 解决方法
- 除了使用硬件技术,可以使用基于编译器调度的软件方式来解决数据冒险的问题。编译器跟踪每个寄存器中的数据并重新安排指定次序以阻止数据冒险的发生。但是效果并不好,还是需要使用硬件技术进行处理。
- 数据/寄存器转发技术(旁路)
- 第一条指令的EX到MEM中间的缓存输出的数据送到下一条指令的EX输入端。第三条和第四条R1的数据来源分别为2和3.
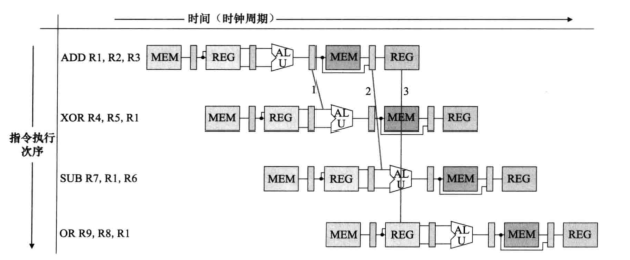
- 第一条指令的EX到MEM中间的缓存输出的数据送到下一条指令的EX输入端。第三条和第四条R1的数据来源分别为2和3.
- 无法使用转发技术的数据冒险
- 对于第一条指令是load,如下图所示。
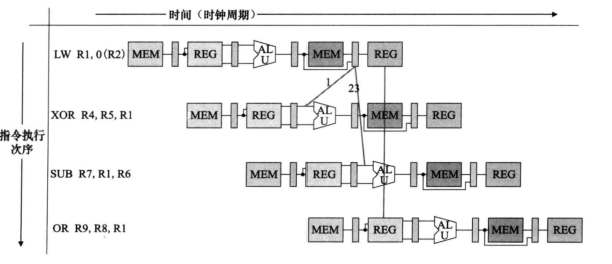
- 图中路径1永远无法实现,可以通过插入一个纵向的气泡将下面所有指令都延迟一个周期。如下图所示。
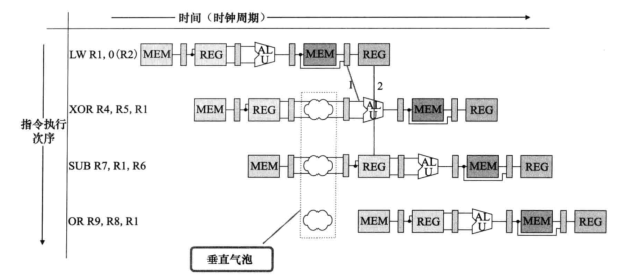
- 对于第一条指令是load,如下图所示。
- 第一条指令后的三条指令都需要使用到R1。
-
控制冒险
- 一般发生在分支跳转时,我们更在乎的是有条件跳转,因为无条件跳转的跳转地址在取值阶段就可以获得,可以设计旁路,更早的将计算结果反馈给流水线,做下一步处理,此时不需要额外插入气泡。
- 对于有条件跳转,如下图所示。DADD指令在T2时需要BENZ指令的PC值,只有在BENZ的MEM阶段后面才能获取到。
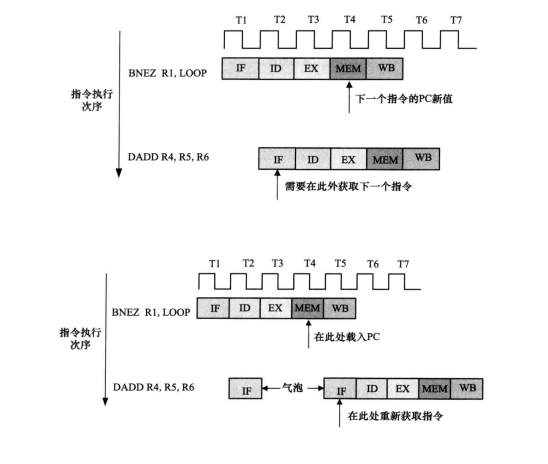
- 解决方法
- (1)一种简单的方法:插入一些气泡,等待几个周期之后,再获取。但是如果每个条件分支指令都停顿,那么将导致严重的速度下降。
- (2)采用分支预测来处理,主要分为静态分支预测和动态分支预测。
- 静态分支预测:假设跳转条件都不满足,继续向后取指,当ALU计算之后得到跳转结果,若发生跳转则再将先前完成的指令置为失效。
- 动态分支预测:根据程序执行的历史情况,进行动态预测调整。预测错误时,仍需保证分支指令后的指令失效,并从正确的分支地址处重新启动流水线。
- 后面若有时间再学习。
- (3)延迟转移:MIPS架构常用的解决方案。
- 前面介绍到可以通过插入气泡来阻塞分支指令下一条指令,等待计算出是否需要跳转后,再执行下一条指令。
- 但是可以选择更换指令排序,将与分支指令没有依赖关系的指令放在分支指令下一条。这样在等待计算跳转结果的同时可以处理其它指令,保证没有空闲。
- 这个重排序的过程是编译器自己做的,程序员看不到这个过程。
- 举例说明,如下代码,由于第2,3条指令都与beq指令相关,所以可以将第1条指令放在beq下面。
xor $s1,$s2,$s3 addi $t1,$t3,1 subi $t2,$t4,2 beq $t1,$t2,Next slt $s4,$5,-50 ... Next:... #延迟转移后 addi $t1,$t3,1 subi $t2,$t4,2 beq $t1,$t2,Next xor $s1,$s2,$s3 slt $s4,$5,-50 ... Next:... - 局限:如果从取指到计算出跳转地址之间的时钟周期太长(延迟分支太长),不适合使用延迟转移,并不是都很容易在分支指令前找到无关指令。较长的一般使用基于硬件的分支预测。