在前面的几个章节中,我们介绍了查询语句的基本用法,这一节,我们介绍查询语句语句中的排序和分组。
排序
如果我们希望将查询结果展现在窗口中,或者输出至外部文件以供他人查看,那么有可能会涉及到对查询结果的排序。PROC SQL 使用 ORDER BY 子句进行排序。PROC SQL 的排序非常灵活,支持单个变量或多个变量的组合排序,支持根据表达式的结果排序,甚至支持根据‘匿名变量’的结果进行排序。
例1:
/*单变量排序*/
proc sql;
select * from sashelp.class order by name;
quit;
/*多变量组合排序*/
proc sql;
select * from sashelp.class order by age, name;
quit;
基于多变量的排序时,PROC SQL 根据排序变量出现的先后顺序,先排第一个变量,若某些观测的第一个变量的值相同,则依据第二个变量的值进行排序,以此类推。
可以在变量后面指定排序方向,ASC 表示正序,DESC 表示倒序,如果没有指定排序方向,则默认为正序排列。
例2:
proc sql;
select
USUBJID,
AESEQ,
AETERM,
AESTDTC
from AE order by input(AESTDTC, yymmdd10.), USUBJID, AESEQ;
quit;
这个例子对不良事件按照发生日期从早到晚进行排序,由于原始的发生日期是字符型的,因此使用了一个表达式先将字符型的日期转换为数值型的日期,然后基于该转换结果进行排序。
例3:
proc sql;
select
USUBJID,
AESEQ,
AETERM,
AESTDTC,
input(AESTDTC, yymmdd10.) format = yymmdd10.
from AE order by 4, USUBJID, AESEQ;
quit;
这个例子与前一个例子的作用相同,不同之处在于,这里在对字符型日期进行转换之后,并没有给转换后的数值型日期指定一个变量名,为了使得输出结果可以按照不良事件的发生日期进行排序,这里的 ORDER BY 语句指定了查询结果的第 4 列变量进行排序,也就是数值型日期所在的变量。
? 在这个例子中,用于排序的第一个变量没有被显式指定变量名,我们可以姑且称之为‘匿名变量’,需要注意的是,这并非官方文档中的说法,仅仅是从其他语言中的一个类似概念类比过来而已。
SORTSEQ = LINGUISTIC
总所周知,SAS 支持多个国家和地区的语言,针对不同语言、地域、文化习惯,SAS 会有不同的数据处理方式。当我们尝试在 Unicode 环境下对含有中文的数据集进行排序时,结果可能是非预期的。例如:
proc sql;
select USUBJID, AETERM from ae order by USUBJID, AETERM;
quit;
排序结果:
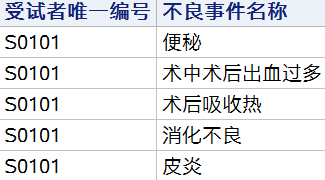
可以发现,输出结果并非按照我们通常期望的汉语拼音进行排序,使用 SORTSEQ = LINGUISTIC,并指定系统选项 LOCALE = zh_CN,即可解决这个问题。
options locale = zh_CN;
proc sql sortseq = linguistic;
select USUBJID, AETERM from ae order by USUBJID, AETERM;
quit;
排序结果:
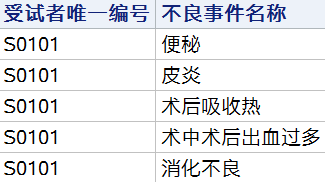
分组
上一节中,我们介绍了聚集函数,实现了对数据集的纵向汇总。但是,有时候我们可能需要根据不同人群,不同访视对数据集进行纵向汇总,这时候就需要用到分组汇总了。PROC SQL 使用 GROUP BY 子句进行分组。
GROUP BY 的用法与 ORDER BY 完全一致,也支持根据单变量、多变量、表达式,甚至‘匿名变量’进行分组汇总。
proc sql;
select
sex,
mean(height) as MEAN_HEIGHT label = "平均身高(英寸)" format = 8.2
from sashelp.class
group by sex;
quit;
在这里例子中,GROUP BY 语句指定根据性别对平均身高进行汇总,查询的结果如下:
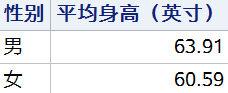
分组过滤
使用 HAVING 子句可以对汇总的结果进行过滤,HAVING 子句通常会与 GROUP BY 子句一起使用,实现分组汇总的过滤。
proc sql;
select * from sashelp.class
group by sex
having height > mean(height);
quit;
在这里例子中,HAVING 子句定义了 height > mean(height) 的分组过滤条件,表示筛选超过平均身高的学生信息,由于指定了分组变量 SEX,因此 HAVING 子句过滤的行为在各性别组内进行。查询的结果中,学生的身高均超过了其自身性别在班级中的平均身高。
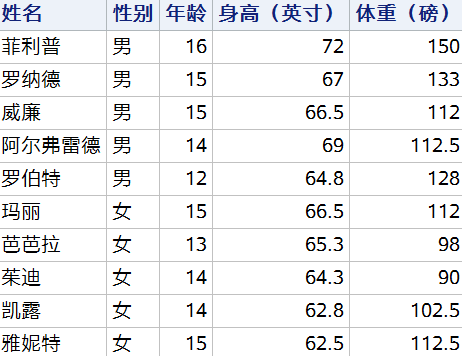
? WHERE 和 HAVING 子句的作用都是过滤,两者的不同之处在于:WHERE 子句根据观测的数据进行过滤,而 HAVING 根据汇总的数据进行过滤。