目标检测综述:(199条消息) 目标检测(Object Detection)_图像算法AI的博客-CSDN博客
目标检测涨点方法:目标框加权融合-Weighted Boxes Fusion(源码分享) (qq.com)
图像分割涨点技巧!从39个Kaggle竞赛中总结出的分割Tips和Tricks - 知乎 (zhihu.com)
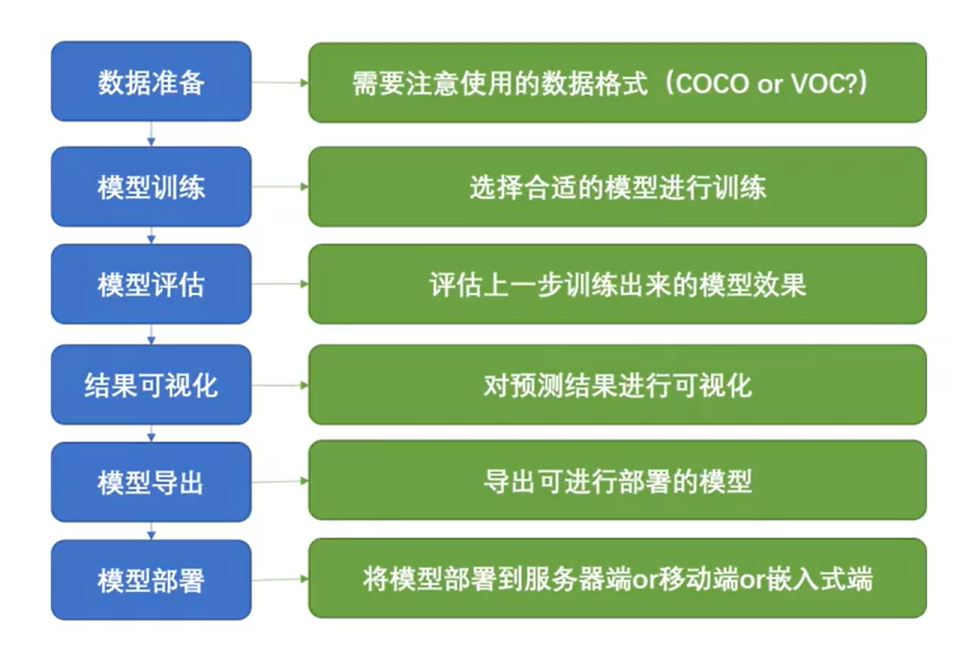
基本流程:
开发套件的使用:
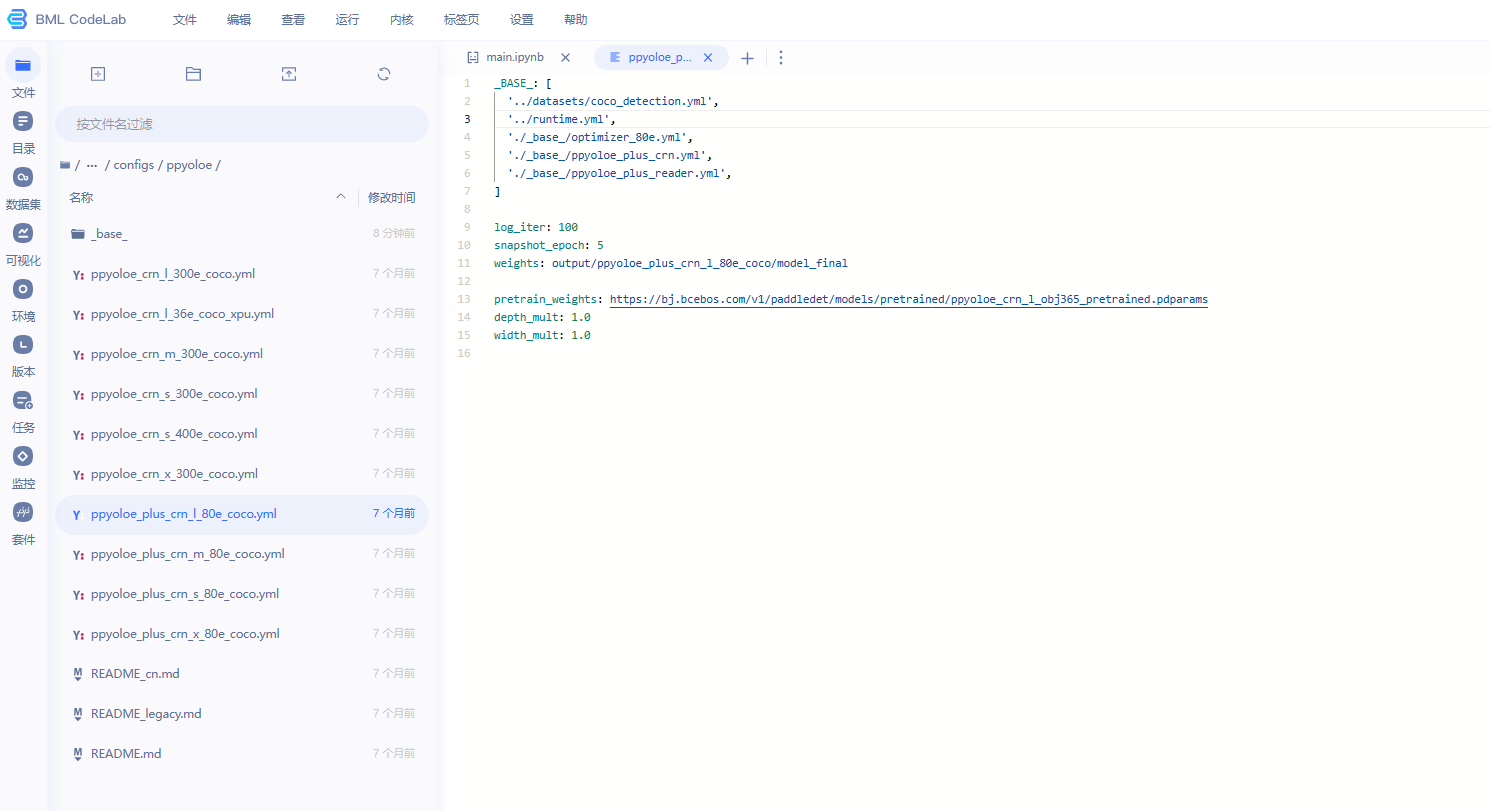
主配置入口
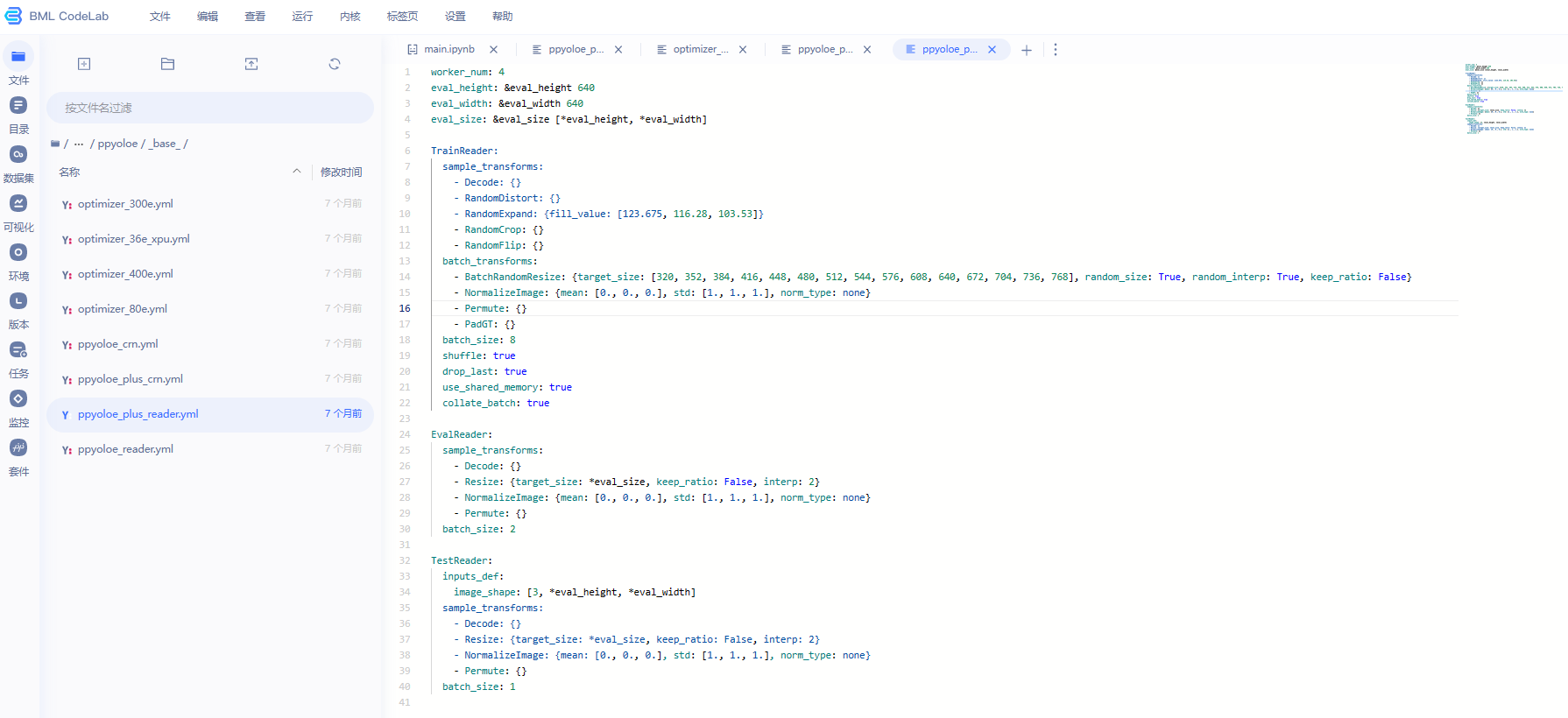
定义数据预处理方式
如果要进行数据预处理,应该修改 TrainReader、EvalReader、TestReader 中的 sample_transforms 和 batch_transforms 部分的代码,这些部分包含了对输入数据进行预处理的具体实现。其中,sample_transforms 是对单个数据样本进行预处理,如解码、随机裁剪、随机翻转等;batch_transforms 是在组成小批量数据前,对经过 sample_transforms 处理过的数据进行进一步的变换,如归一化、通道维度的变换等。根据具体需求,你可以选择添加、删除、修改这些预处理操作。
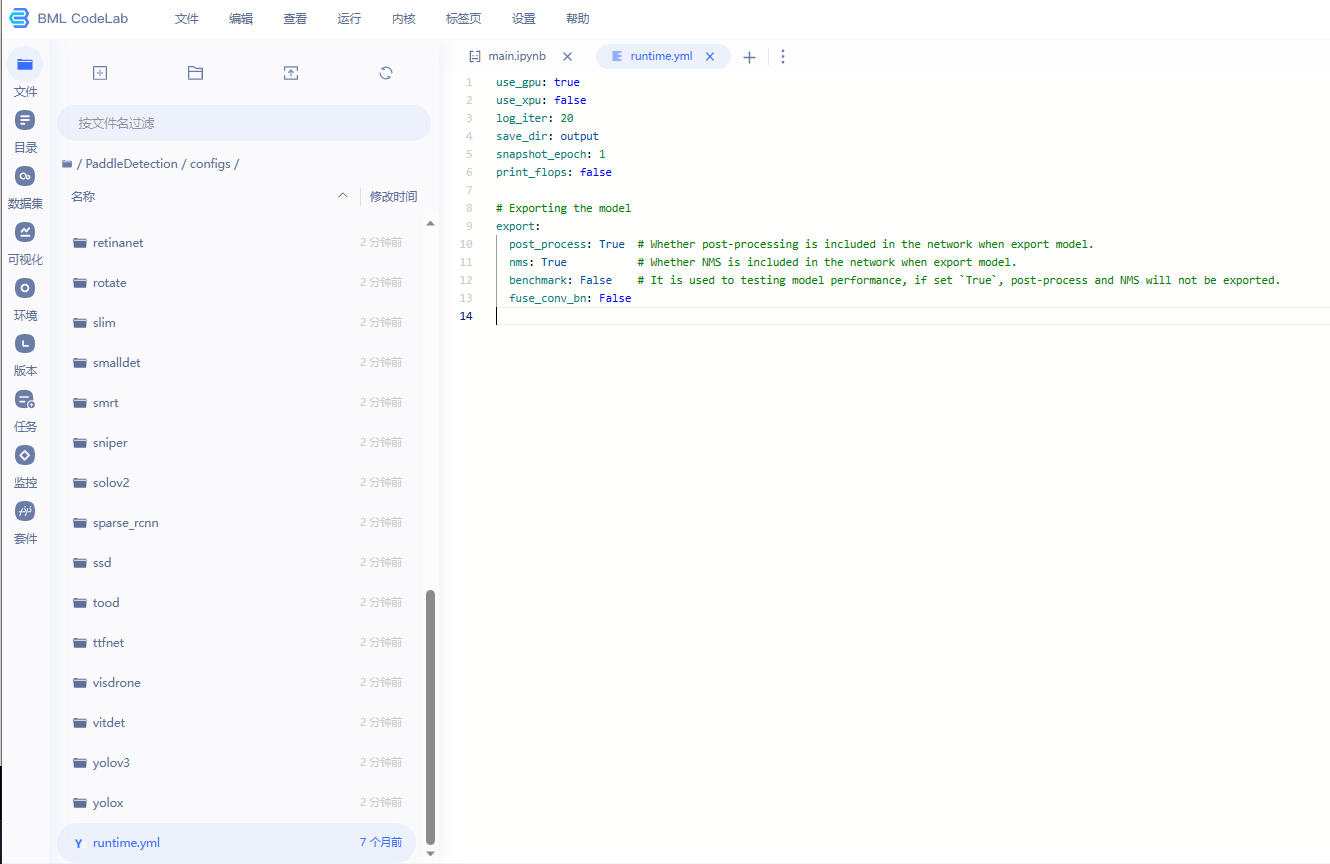
定义运行状态
定义模型和骨干网络的情况
1.这是一个训练神经网络模型的配置文件,包含了模型训练的超参数设置。
- epoch: 80 表示模型训练的总共轮数为 80。
- LearningRate: 表示学习率的设置。
- base_lr: 0.001 表示模型初始的学习率为 0.001。
- schedulers: 表示学习率调度器的设置,包括 CosineDecay 和 LinearWarmup 两个调度器。
- !CosineDecay 表示使用 Cosine 学习率调度器,max_epochs: 96 表示在训练的前 96 轮使用 Cosine 学习率调度器。
- !LinearWarmup 表示使用线性学习率预热调度器,start_factor: 0. 表示预热时的学习率为 0,epochs: 5 表示预热的轮数为 5 轮。
- OptimizerBuilder: 表示优化器的设置。
- optimizer: 表示使用 Momentum 优化器,其中 momentum: 0.9 表示动量因子为 0.9。
- regularizer: 表示使用 L2 正则化,其中 factor: 0.0005 表示正则化系数为 0.0005。
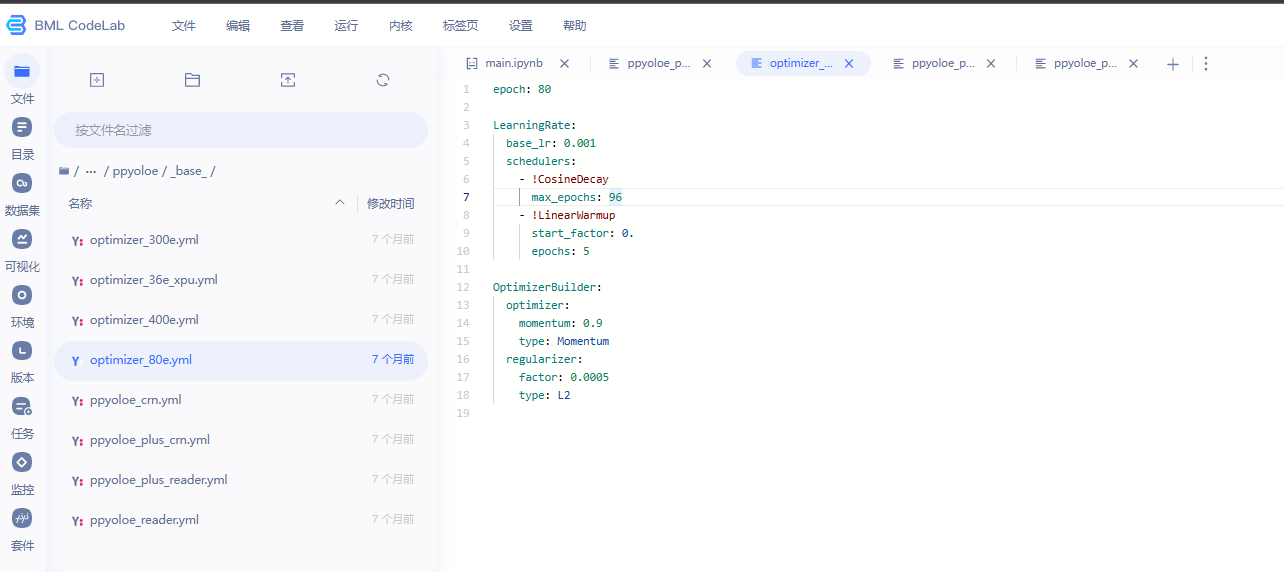
2.这是一个目标检测模型的配置文件,使用的是 YOLOv3 架构,包括以下部分:
- norm_type: sync_bn 表示使用同步批量归一化(SyncBN)进行参数归一化。
- use_ema: true 和 ema_decay: 0.9998 表示使用指数滑动平均(Exponential Moving Average,EMA)对模型权重进行平均,其中 ema_decay 表示 EMA 的衰减率。
- ema_black_list: ['proj_conv.weight'] 表示不对 proj_conv.weight 参数进行 EMA 平均。
- custom_black_list: ['reduce_mean'] 表示自定义不需要进行 EMA 平均的参数。
然后是模型各组件的具体配置:
-
YOLOv3: 包含了模型的主干网络、neck 和 head 部分,其中
- backbone: CSPResNet 表示使用 CSPResNet 作为主干网络。
- neck: CustomCSPPAN 表示使用自定义的 CSPPAN 作为 neck 部分。
- yolo_head: PPYOLOEHead 表示使用自定义的 PPYOLOEHead 作为 head 部分。
- post_process: ~ 表示后处理部分为空。
-
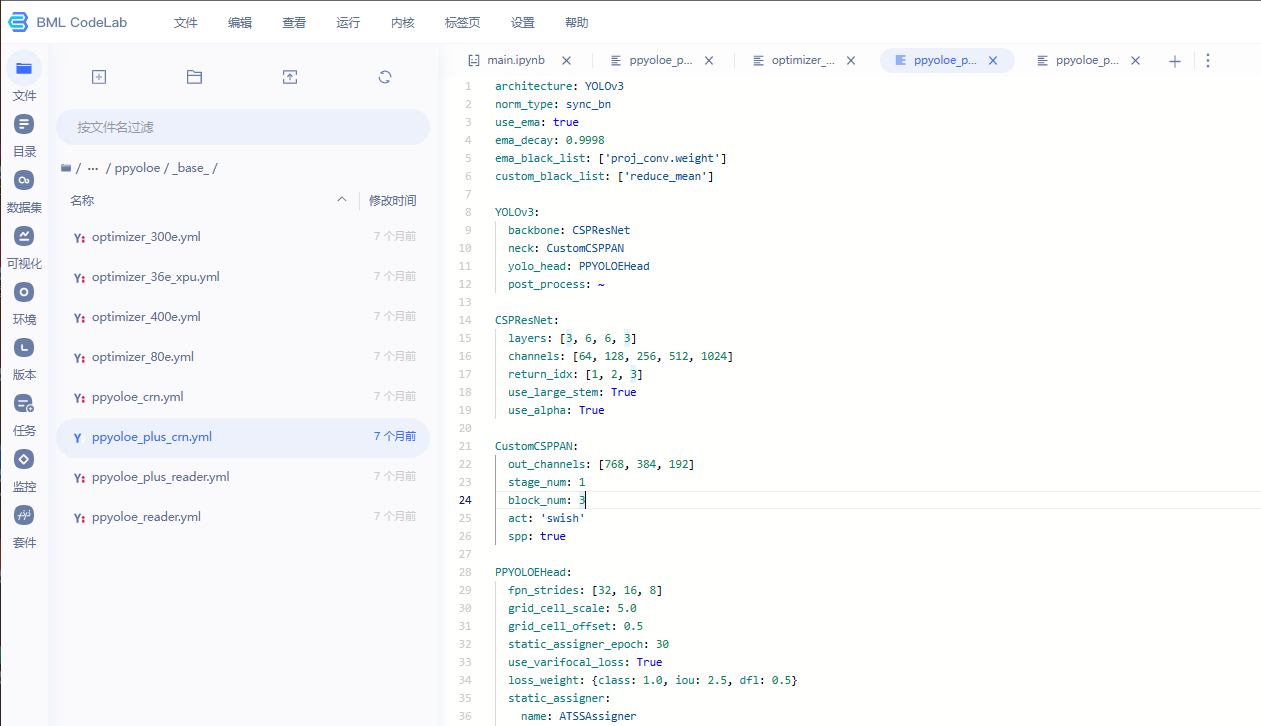
CSPResNet: 包含了 CSPResNet 的具体配置,包括
- layers: [3, 6, 6, 3] 表示 CSPResNet 的各个阶段的层数。
- channels: [64, 128, 256, 512, 1024] 表示 CSPResNet 各个阶段的通道数。
- return_idx: [1, 2, 3] 表示 CSPResNet 返回的 feature map 的索引。
- use_large_stem: True 表示 CSPResNet 使用较大的卷积核作为第一个卷积层。
- use_alpha: True 表示 CSPResNet 使用 Alpha 激活函数。
-
CustomCSPPAN: 包含了自定义的 CSPPAN 的具体配置,包括
- out_channels: [768, 384, 192] 表示 CSPPAN 输出的各个 feature map 的通道数。
- stage_num: 1 表示 CSPPAN 的阶段数。
- block_num: 3 表示 CSPPAN 中每个阶段的 block 数量。
- act: 'swish' 表示激活函数使用 swish。
- spp: true 表示使用空间金字塔池化(Spatial Pyramid Pooling,SPP)模块。
-
PPYOLOEHead: 包含了自定义的 PPYOLOEHead 的具体配置,包括
- fpn_strides: [32, 16, 8] 表示 feature map 的步幅。
- grid_cell_scale: 5.0 表示 anchor box 的大小缩放因子。
- grid_cell_offset: 0.5 表示 anchor box 的偏移量。
- static_assigner_epoch: 30 表示在训练的前 30 轮
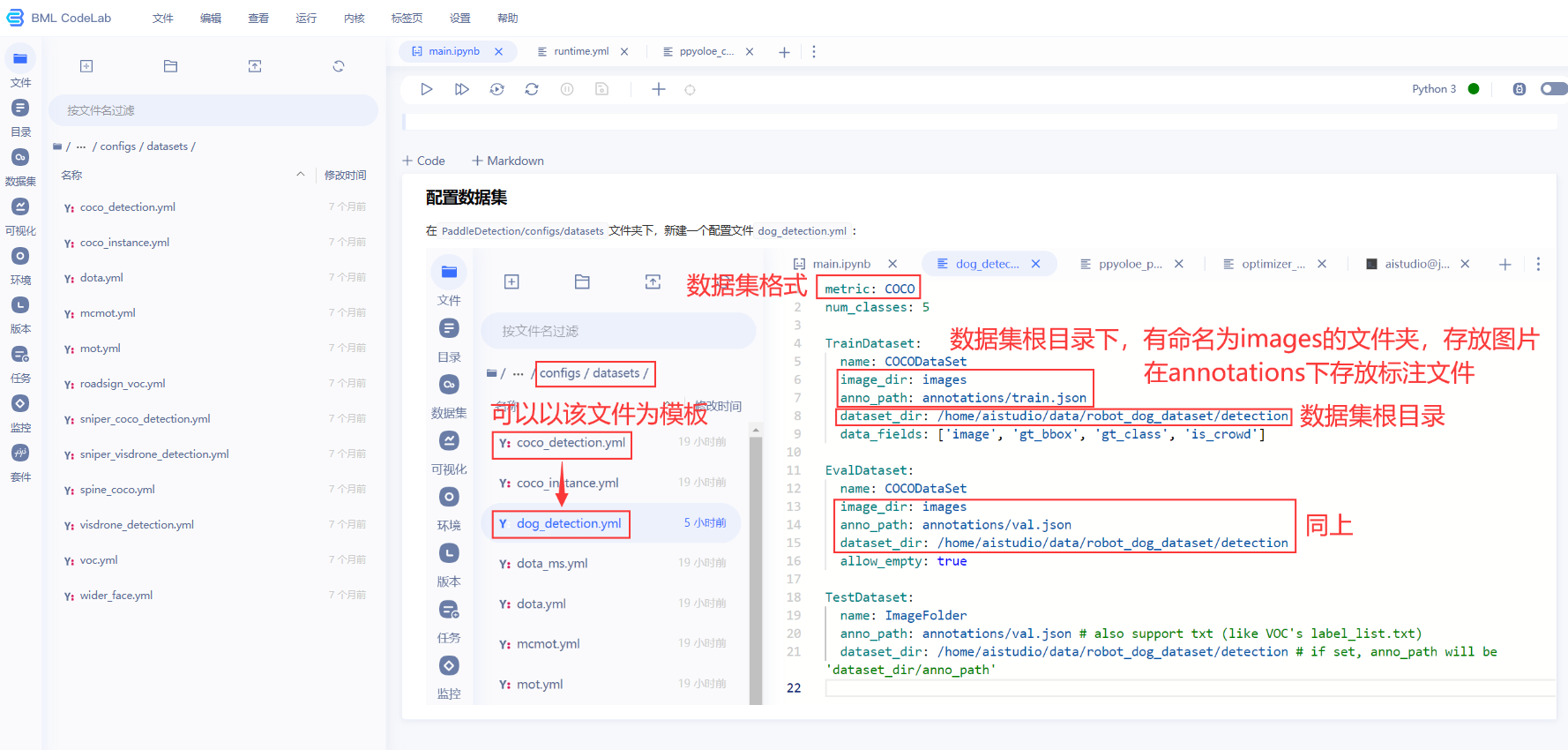
定义数据路径和格式
比赛分析:
比赛包含两个任务,图像检测和语义分割,两个任务其实是分开的,对于语义分割,不涉及图像检测,只做好分割的部分就行了,最后打榜的分数也是单独计算然后合起来的
对于目标检测的难点分析(难点也是突破点):
难点主要集中在数据集上:
- 标签质量参差不齐,个别图像中的标注框过大(测评数据中心也存在这类数据)——怎么改善?我的思路:①直接手动修改标签?②对相关部分的代码进行调整,使得在数据质量差的情况下也能训练出一个好的模型
- 标注数据不平衡,少数图像中会将任务用“person”这一类别标注出来,而大部分图像没有将人物标注出来,导致模型很难收敛还有一些干扰的图片,人物站在水面上,它的倒影也被标注了。
我的思路:可以尝试不把特殊图片的人物算进去 - 遮挡、目标尺寸不一,各类别数量差异较大等
对于语义分割的难点分析:
各类别数量差异较大,背景占的面积较多。但是此次比赛该现象不是特别严重
对检测数据集:检测数据集涉及3个场景,分别是“火灾检测”、“工业仪表检测”和“安全帽检测”
对其标签进行统计分析出来以下结果
fire: 2683 //火灾 head: 4487 //安全帽 helmet: 15141 //头盔 person: 676 //人 meter: 66 //仪表
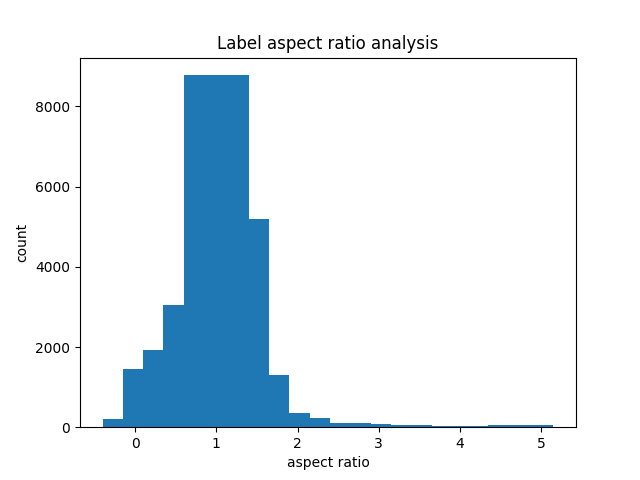
对其进行高宽比分析

对对比度和亮度的分析:对比度集中在0-500之间,亮度很散

其他需要注意的点:
- 两个模型加起来不能超过400M,注意是加起来,而不是分开算。平台的评估中,目标检测占9分,语义分割占1分。也就是说,我们要更偏向于目标检测,用一些更大的模型,不一定局限于yoloe
- FPS计算方法:(模型1的FPS+模型2的FPS)/ 2