案例一题目:



案例二题目:

一、案例分析中的要点剖析
实验一:书城信息管理系统
个人思考过程:
对于问题一:
- 识别实体与属性
通读问题叙述后首先列出实体与属性的雏形:
书籍信息(书号,书名,封面,出版社,作者,单价);
大类(大类类别编号,大类类别名称);
小类(小类类别编号,小类类别名称);
每本书归属于一个小类,小类与书之间的关系为“1对n”,则可以把小类的主码加入到书籍信息之中,同理将大类的主码加入到小类中,将大类的主码加入到书籍信息中。
最终形成的实体为:
书籍信息(书号,小类类别编号,大类类别编号,书名,封面,出版社,作者,单价,);
大类(大类类别编号,大类类别名称);
小类(小类类别编号,大类类别编号,小类类别名称,);
- 做出满足需求的E-R图:
考虑到大类、小类、书籍本身可以单独存在,这里使用的均为非标定联。
对于问题二:
- 识别实体与属性
在问题一的基础上,根据题目得出需要增加的实体及其属性:
订单(订单号,订单总价,下单日期,订单状态,订单明细);其中订单明细为多值属性。
订单明细(订单明细号,书籍信息,购买数量);
用户(用户ID,姓名,地址,电话)
考虑到用户的地址可能存在一个或多个,并且必须要有用户,才能存在地址属性,我们将地址作为一个多值属性处理,并将其与用户之间的关系作为标定关系:地址(收货地址编号,用户ID,省,市,区);
书与订单明细之间的关系是“1对n”的关系,需要将书号加入到订单明细之中,则:订单明细(订单明细号,书号,购买数量);
订单明细与订单之间、与书之间均为“1对1”的关系,则:订单明细(订单明细号,书号,购买数量);
由于用户与订单之间的联系是“1对n”,需要将用户ID纳入到订单的主码之中,即:订单(订单号,用户ID,订单总价,下单日期,订单状态);
订单明细(订单明细号,订单号,书号,用户ID,购买数量);
- 做出满足需求的E-R图:
与第一问中的考量相类似,必须要有用户才会有订单,有订单才会有订单明细,同时也必须要有书籍信息才会有订单明细,所以将用户-订单、订单-订单明细、订单明细-书籍信息之间的联系设为了标定联系,其余设为非标定联系。
对于问题三:
由于查询是对于数据库的操作而不是实体之间的联系,所以查询订单状态不需要进行E-R建模。
对于扩展问题:
要将书按照新书速递、畅销书、特价书等多种方式展示,我们认为主观复制在工作量与维修成本上都是较高的,因而直接由书籍本身的信息作为分类的依据更可行。
分别用书籍出版时间反映是否为新书速递;通过销售量可以反映书籍是否为畅销书,这部分可以通过派生属性利用冗余实现;用售价、定价反映书籍是否为畅销书。
但是可能需要有人为更改的余地,我们增加了标签实体:标签(标签号)来代表书籍具有的销售热点,并且标签不需要依附于书籍存在,可以将二者之间的联系设为非标定联系。
此外,为了简化E-R图,在最终结果的展示时,我们将类别作为一个复合属性,描述该书本属于第一问中的哪个小类、哪个大类,于是没有展示大类、小类两个实体。
因而我们的实体与属性更改为:
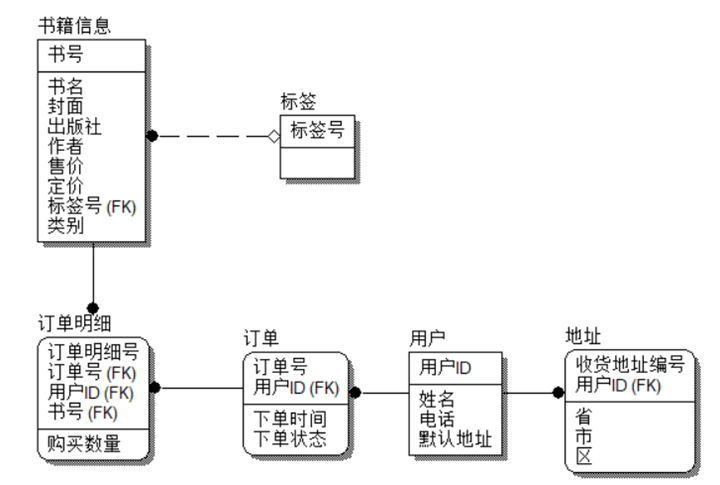
书籍信息(书号,书名,封面,售价,定价,类型,出版社,出版日期);
用户(用户ID,姓名,电话,默认地址);
订单(订单号,用户ID,订单总价,下单时间,订单状态)
并且在该种需求的情况下,地址是多值属性,需要单独存放在一张二维表之中,E-R图结果在第三部分“案例的IDEF1X建模”中进行展示。
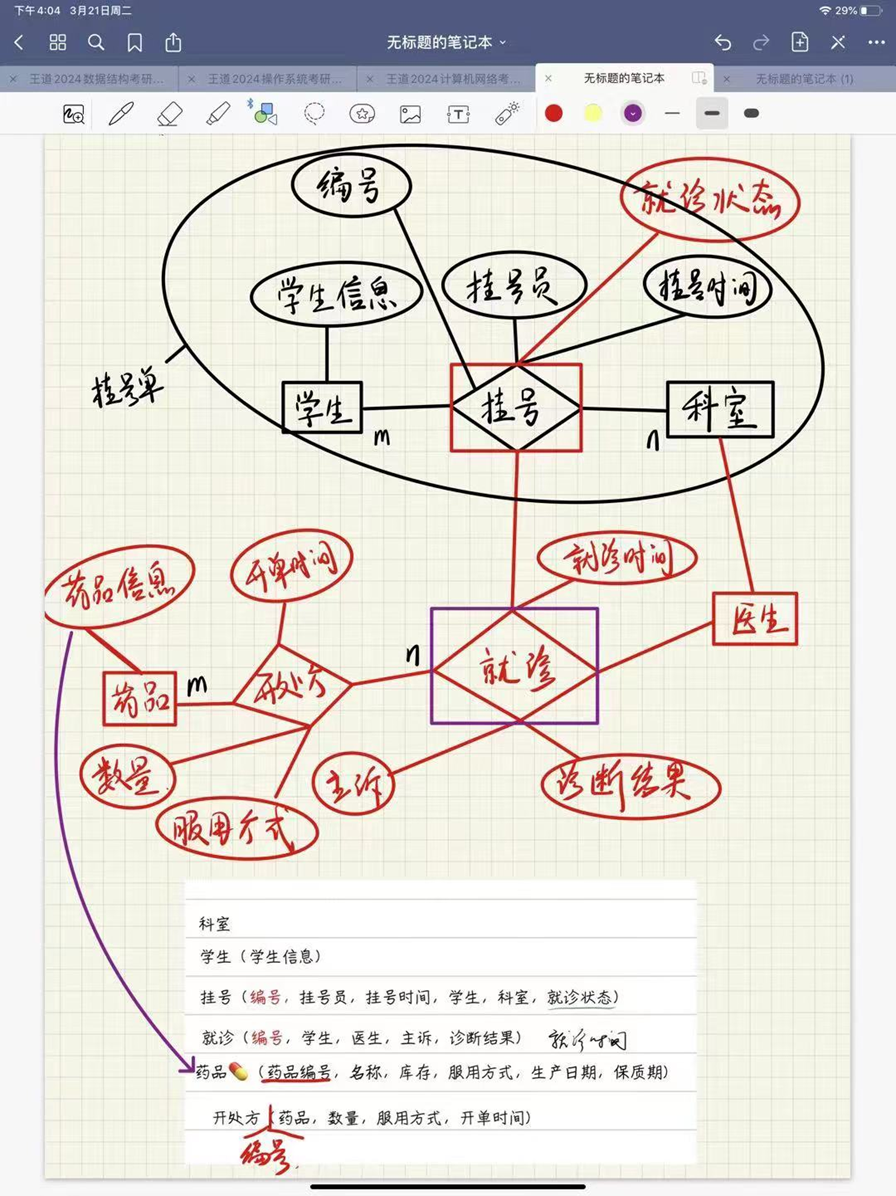
实验二:校医院挂号就诊系统
对于挂号功能:
- 识别实体与属性
根据功能是需要实现学生在校医院中挂号就诊的过程,可以确定该需求中的实体有学生、科室,则实体与联系为:
学生(学号,姓名,性别,年龄);
科室(科室编号);
挂号(挂号编号,挂号员工号,挂号时间,学号,科室编号);
2. E-R图展示:
通过查询该图中所含信息即可表示挂号单中的内容。
- 就诊断功能实现
1. 识别实体与属性
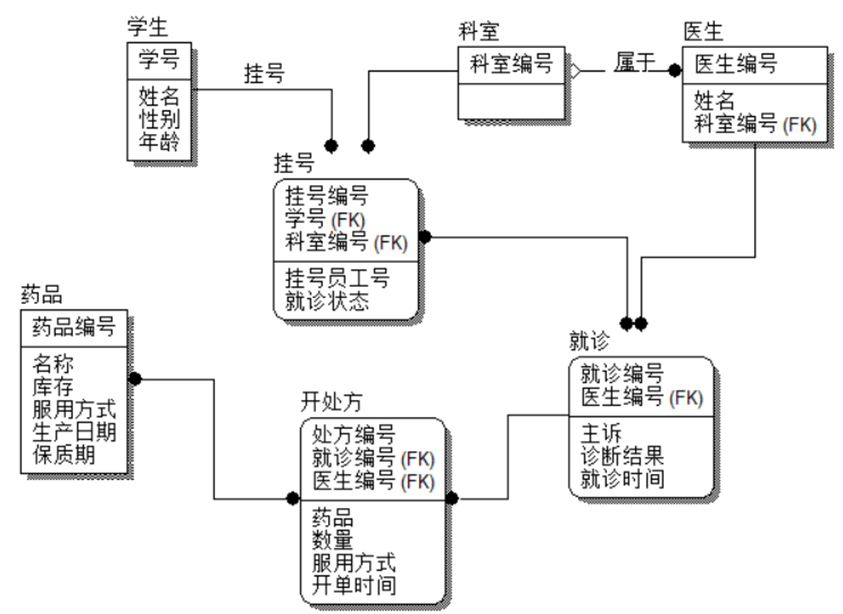
在挂号功能实现的基础上,还需要增加就诊联系、药品实体、开处方联系,则实体为:
科室(科室编号);
学生(学号,姓名,性别,年龄);
挂号(挂号编号,挂号员工号,挂号时间,学号,科室编号,就诊状态);
就诊(就诊编号,学生,医生,主诉,诊断结果,就诊时间);
药品(药品编号,名称,库存,服用方式,生产日期,保质期);
开处方(处方编号,药品,数量,服用方式,开单时间);
2.E-R图的实现
在案例二IDEF1X建模中进行了展示。
二、知识点总结
- 重视需求:
在整个模型建立当中应当将用户需求作为一个中心角色,将设计与需求相对应。此外,一个对象是实体还是属性是由实际需求决定的。
E-R图的建立是为了更直观地反映用户需求,其实现方法不限,但应该充分考虑后期维护、适用场景等因素的影响。
2.区别实体与属性:
属性是用来描述实体的某一特性。如果属性可以被拆分为更小部分的属性,则其是复合属性,并不是实体;复合属性使用与一个用户希望在一些场景中引用完整的属性,在另外的场景中近应用属性的一部分。
在将复合属性转换成关系模型时,需要将复合属性替换为分割后的属性。
但如果某一属性拥有能够描述该属性的属性,则须将其作为实体。
若一个属性是多值属性,需要对该属性建立一个表格记录该属性可能取得的所有值。
3.联系与实体:
联系就是一个实体,因此联系也可以有用于描述其特性的属性。
4.实体之间的关系与主码处理:
两个实体之间的联系:
一对一联系:可以将任一方主码纳入到另一方中,具体如何选择需要参考需求。
一对多联系:需要将“1”方主码纳入到“n”方主码之中。
多对多联系:需要对联系单独建立一个新的关系模式,新的关系模式需要包含两个实体的主码以及联系的属性。
两个以上实体之间的联系:
需要对联系单独建立一个新的关系模式,其中包括各个实体的主码以及联系的属性。
5. 聚集的理解:
“聚集”能够体现出操作的先后顺序,并且在将包含聚集的E-R图转换成关系模式时直接将其视为一般实体对待即可,并将定义该聚集的联系看作高层实体。
“聚集”允许联系与实体,联系与联系之间存在联系。
6. 功能分析步骤:
遵循一定的思考步骤既能确保需求信息读取准确,也能帮助思考,构建完整的E-R图形,依次考虑:
- 需求描述(陈述功能地细节)
- 前提条件(想要开启本功能需要提前准备什么,聚集)
- 操作该功能的人员所在岗位的名称(尽量准确描述员工工作岗位,而非管理员)
- 输入信息(功能的实现需要外界或者其他功能模块提供哪些输入信息)
- 输出信息(本功能向外界或者其他功能模块)
- E-R概念图设计
7. IDEF1X建模过程中的更细化分类 (这部分有参考网上资料,如有误请标注♥):
1.实体集分为:独立实体与从属实体;
独立实体(强实体):实体的实例都被唯一的标识而不决定于与其他实体的联系。
从属实体(弱实体):实体的实例都是由它与复实体之间的联系而确定的,父实体的主关键字是其主关键字的一部分。
在IDEF1X中,用直角矩形表示独立实体,用圆角矩形表示从属实体。
2.联系分为:分类关系、标定型联系、非标定型联系与不确定联系。
由于将联系与实体之间画上了等号,所以在画图过程中联系也用矩形框表示,标定型实体用直角矩形,非标定型联系用圆角矩形。
- “1对1”或者“1对n”关系:分类联系
是两个或多个实体集之间的关系,且在这些实体集中存在一个一般实体集,它的每一个实例都恰好与一个且仅一个分类实体集的一个实体集相联系。
其中一个表的主键在另一个表中作为外键,建立两个表之间的关联关系。
- “1对n”关系:标定型联系与非标定型联系
标定型联系:如果子女实体集中的每个实例都是由它的双亲的联系决定的,这个关系就称为“标定型联系”。
非标定型联系:如果子女实体集中的每个实例都能被唯一地确认而无需了解与之相联系的双亲实体集的实例,这个关系就称为“非标定型联系”。
如果两个实体之间有关系,并且是一个非标定型联系,则将这两者用虚线连接。
- “多对多”:不确定关系:
两个实体之间,任一实体的一个实例都对应另一实体的0,1或者多个实例,用一个两端带有实心圆的线段表示多对多的连接关系。
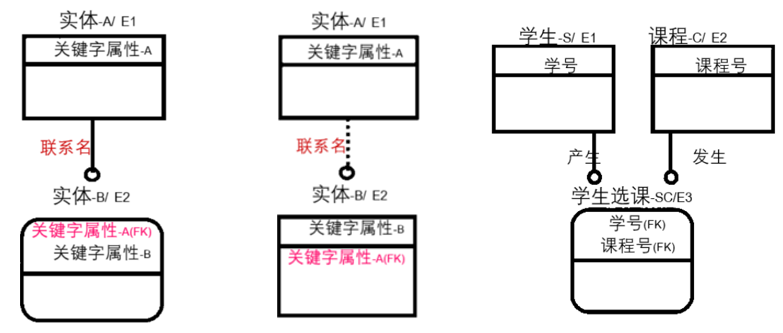
从左往右依次为:标定联系,非标定联系,不确定联系。
三、案例的IDEF1X建模
1、案例一IDEF1X建模
2、案例二IDEF1X建模
我的收获
- 除了知识点总结部分的收获,在实验过程中我认为两个实验都提升了我对于“操作”和“查询”的区别的认识。第一个实验中关于“查询”的思考题、第二个实验中“输出”的实现方法,实际上都是对于数据库的“操作”,在建立逻辑模型时不能将其作为实体或关系。
- 用客观值反映数据特征是一种效率比较高的方法,但是也需要结合到产品使用的场景。
- 如何在IDEF1X建模时表现出“聚集”?
目前存在的疑惑
虽然在IDEF1X模型建立时,将联系视为实体,而“聚集”在理解时可将定义其的实体视为高级实体,但如何在IDEF1X模型图中进行表示呢?
- 为什么需要在功能分析步骤中考虑“操作人员岗位”?这对于模型的建立有什么影响吗?
我认为模型的建立是根据用户需求,即需要实现的功能来划定的,这和人员岗位之间的联系较小。
2.不是很明确什么时候应该选用多个外码做主码,什么时候单独单独生成一个编码作为主码,我认为均独立生成一个编码作为主码效率更高,能够避免由于相关属性值为空而无法生成新实体信息的情况。
3.有些情况实体之间对应关系会有纠结:
例如医生和就诊,一般认为一对多,但是多对多的可能性也存在,应该是以普遍情况为准,这样的理解正确吗?
4.一对一关系可以直接合成一个表,为什么不直接这样做?
查阅资料:一对一在有些情况下可以优化数据库,提高查询效率或降低冗余,但这是为什么呢?
5.如果多个实体之间存在关系,可能会使得冗余量过大,如何优化呢?
例如:在我们的实例二的方案中:就诊与挂号、医生、开处方之间均存在联系。