一、连接数据库
import os import pandas as pd # 修改工作路径到指定文件夹 os.chdir(r"D:\py_project\a_三下\chapter11\demo") import pymysql as pm #con = pm.connect('localhost','root','123456','test',charset='utf8') con=pm.connect(host='localhost',user='root',password='123',db='test',charset='utf8') data = pd.read_sql('select * from all_gzdata',con=con) con.close() #关闭连接 # 保存读取的数据 data.to_csv("D:\py_project\a_三下\chapter11\tmp", index=False, encoding='utf-8')
二、分析网页类型
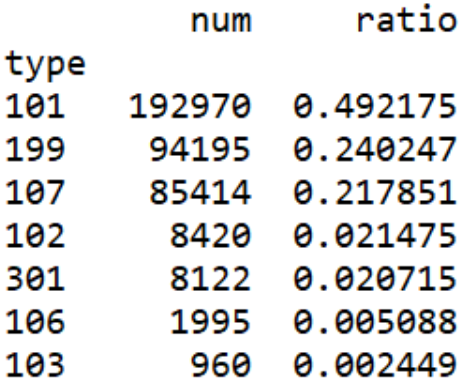
import pandas as pd from sqlalchemy import create_engine engine = create_engine('mysql+pymysql://root:@localhost:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) # 分析网页类型 counts = [i['fullURLId'].value_counts() for i in sql] #逐块统计 counts = counts.copy() counts = pd.concat(counts).groupby(level=0).sum() # 合并统计结果,把相同的统计项合并(即按index分组并求和) counts = counts.reset_index() # 重新设置index,将原来的index作为counts的一列。 counts.columns = ['index', 'num'] # 重新设置列名,主要是第二列,默认为0 counts['type'] = counts['index'].str.extract('(\d{3})') # 提取前三个数字作为类别id counts_ = counts[['type', 'num']].groupby('type').sum() # 按类别合并 counts_.sort_values(by='num', ascending=False, inplace=True) # 降序排列 counts_['ratio'] = counts_.iloc[:,0] / counts_.iloc[:,0].sum()
print(counts_)
三、知识类型内部统计
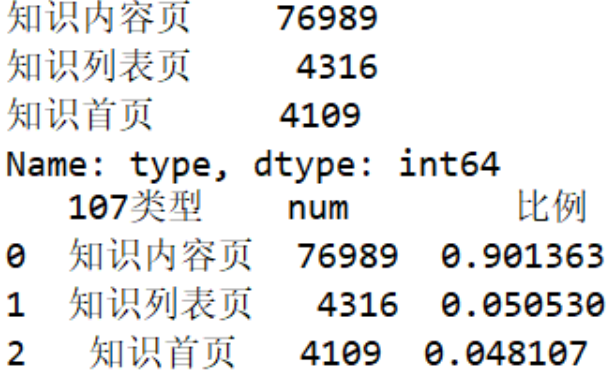
# 细分成三类:知识内容页、知识列表页、知识首页 def count107(i): #自定义统计函数 j = i[['fullURL']][i['fullURLId'].str.contains('107')].copy() # 找出类别包含107的网址 j['type'] = None # 添加空列 j['type'][j['fullURL'].str.contains('info/.+?/')]= '知识首页' j['type'][j['fullURL'].str.contains('info/.+?/.+?')]= '知识列表页' j['type'][j['fullURL'].str.contains('/\d+?_*\d+?\.html')]= '知识内容页' return j['type'].value_counts() # 注意:获取一次sql对象就需要重新访问一下数据库(!!!) #engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) counts2 = [count107(i) for i in sql] # 逐块统计 counts2 = pd.concat(counts2).groupby(level=0).sum() # 合并统计结果 print(counts2) #计算各个部分的占比 res107 = pd.DataFrame(counts2) # res107.reset_index(inplace=True) res107.index.name= '107类型' res107.rename(columns={'type':'num'}, inplace=True) res107['比例'] = res107['num'] / res107['num'].sum() res107.reset_index(inplace = True) print(res107)
四、统计带"?"的数据
def countquestion(i): # 自定义统计函数 j = i[['fullURLId']][i['fullURL'].str.contains('\?')].copy() # 找出类别包含107的网址 return j #engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) counts3 = [countquestion(i)['fullURLId'].value_counts() for i in sql] counts3 = pd.concat(counts3).groupby(level=0).sum() print(counts3) # 求各个类型的占比并保存数据 df1 = pd.DataFrame(counts3) df1['perc'] = df1['fullURLId']/df1['fullURLId'].sum()*100 df1.sort_values(by='fullURLId',ascending=False,inplace=True) print(df1.round(4))
