专有名词概念
标签(Labels):预测列,需要预测的内容
特征(Features):用于帮助预测标签的列
模型(Model):模型是通过训练数据学习到的机器学习算法。它可以用来预测未知数据的标签
官方地址:ML.NET |专为 .NET 设计的机器学习 (microsoft.com)
准备环境
必须开发工具:Visual Studio 2022
必须组件:需要开启 Visual Studio 中 .NET桌面开发=》ML.NET Model Builder

Visual Studio 2022 版本:17.8.3
.net core 版本: 8.0
下面都是用控制台应用程序演示的,所以自己新建一个控制台应用程序,我这里取名 myMLApp。
数据分类
示例说明:对现有的情绪数据进行训练,现有的情绪数据包含两列,一列是情绪语句(也就是特征);一列是对应的情绪,只有两个值0(悲观情绪)和1(乐观情绪)。生成训练模型后会根据输入的情绪语句进行预测判定对应的情绪
1. 添加机器学习模型模型,取名为MLModel.mbconfig

2. 选取方案,数据分类
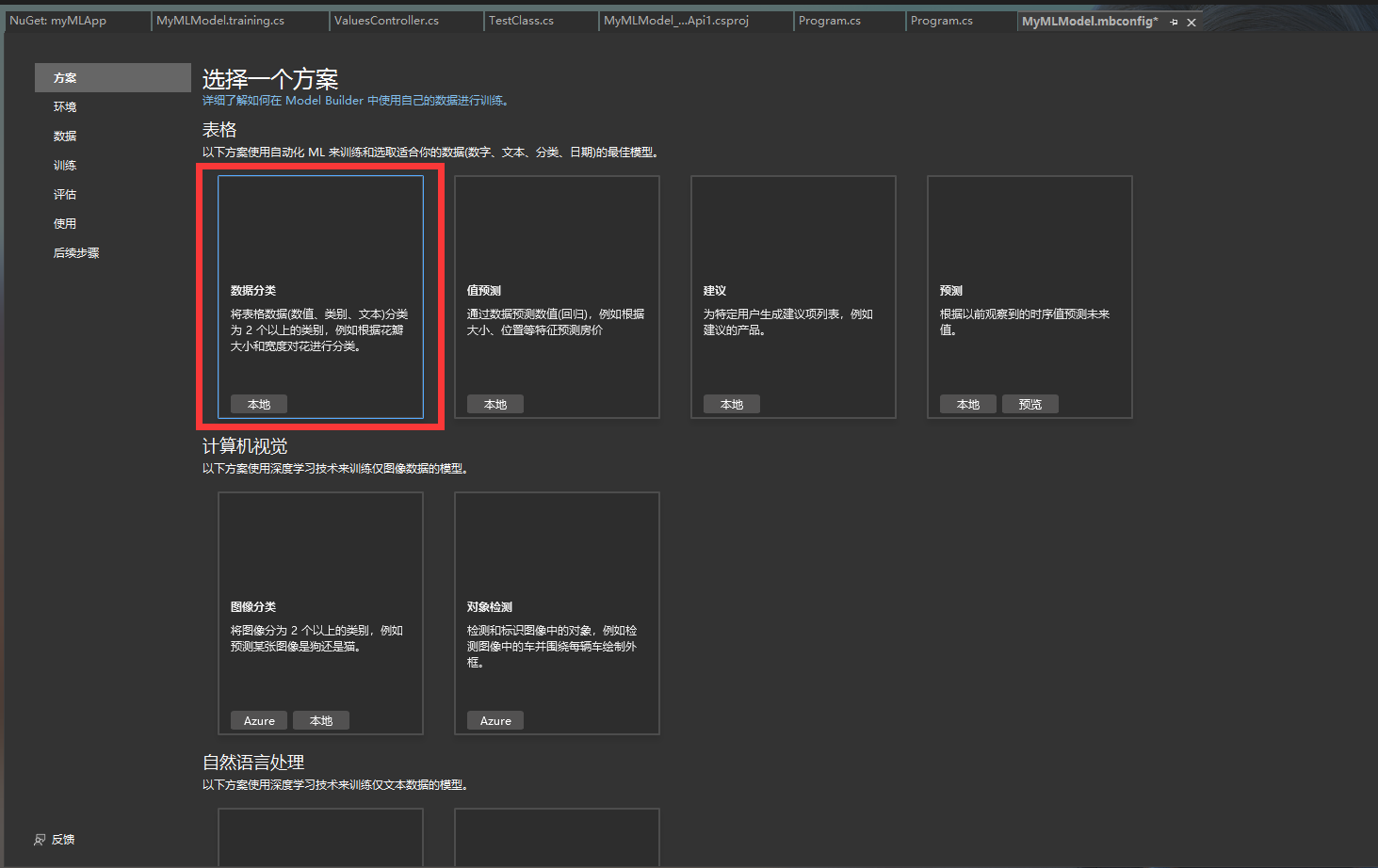
3. 选择环境,这里只有一个选项
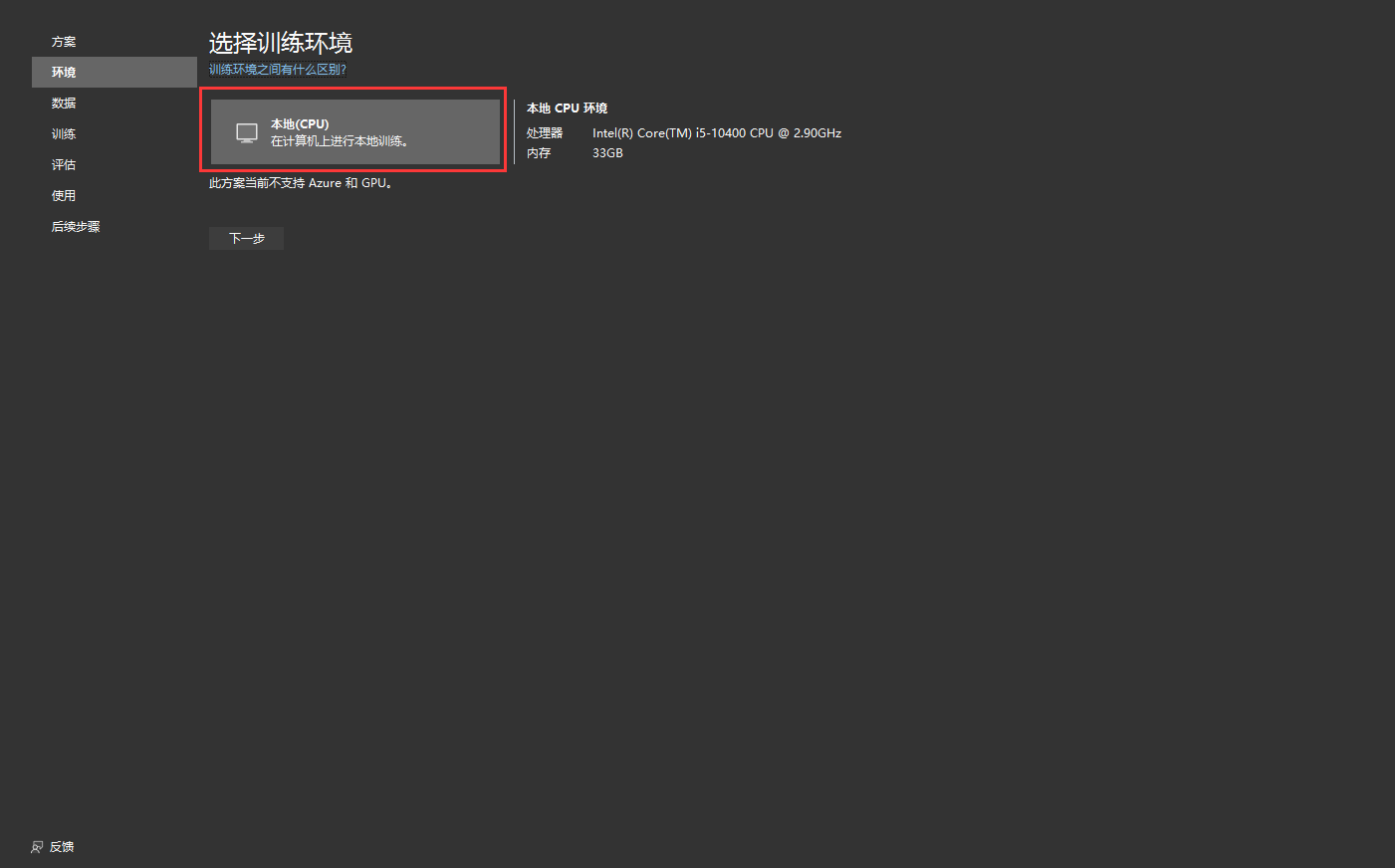
4. 导入数据。点击直接下载。更多其他数据可以访问Datasets - UCI Machine Learning Repository
4.1 数据下载后解压缩 sentiment labelled sentences.zip 并保存 yelp_labelled.txt 文件到 myMLApp 目录。yelp_labelled.txt 中的每一行代表用户在 Yelp 上对餐厅的不同评论。第一列代表用户留下的评论,第二列代表文本的情绪(0 为负面,1 为正面)。这些列由制表符分隔,并且数据集没有标头。
4.2 数据来源选择文件,数据集浏览 yelp_labelled.txt 文件路径。数据预览会自动生成表头col0 和 col1.
4.3 在“预测列 (标签)”下,选择 "col1"。“标签”是预测内容,在本例中是在数据集的第二列 ("col1") 中发现的情绪。
4.4用于帮助预测标签的列称为“特征”。除“标签”外,数据集中的所有列都将自动选择为“特征”。在这种情况下,审阅评论列(“col0”)是特征列。可以在“高级数据选项”中更新特征列并修改其他数据加载选项,但在本示例中不是必需的。
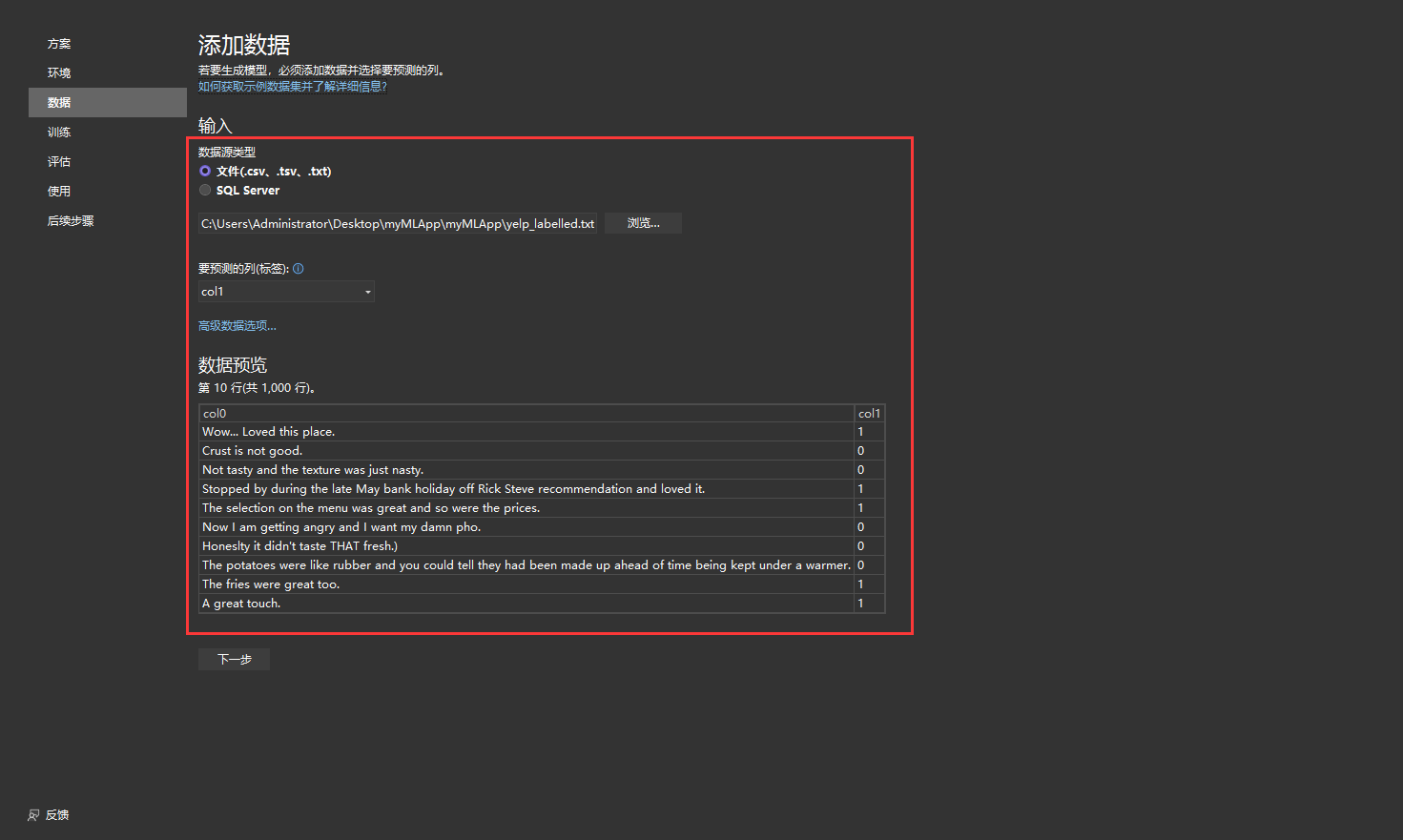
5. 训练模型。选择方案、环境、数据和标签后,模型生成器会训练该模型。
训练是一个自动的过程,模型生成器通过该过程教模型如何回答方案相关的问题。 训练后,模型可以对其没有见过的输入数据进行预测。因为模型生成器使用自动机器学习 (AutoML),所以在训练期间不需要任何人工输入或微调操作。
训练时长:模型生成器使用 AutoML 浏览多个模型,以查找性能最佳的模型。更长的训练周期允许 AutoML 通过更多设置来浏览更多模型。下表汇总了在本地计算机上为一组示例数据集获取良好性能所花的平均时间。
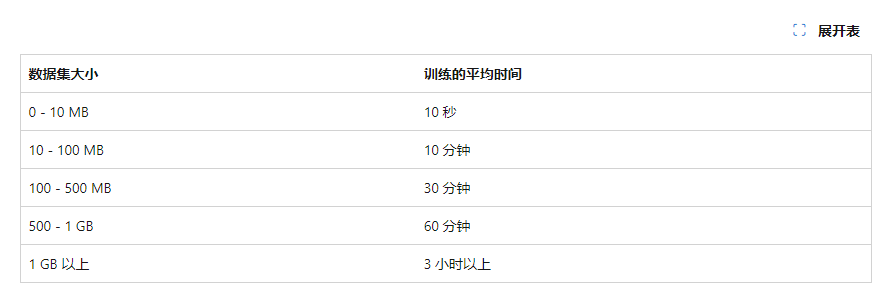
这些数字仅用于指南。 训练的确切长度取决于:
- 用作模型输入的特征(列)数
- 列的类型
- ML 任务
- 用于训练的计算机的 CPU、磁盘和内存性能
通常建议使用超过 100 行的数据集,否则可能不会生成任何结果。
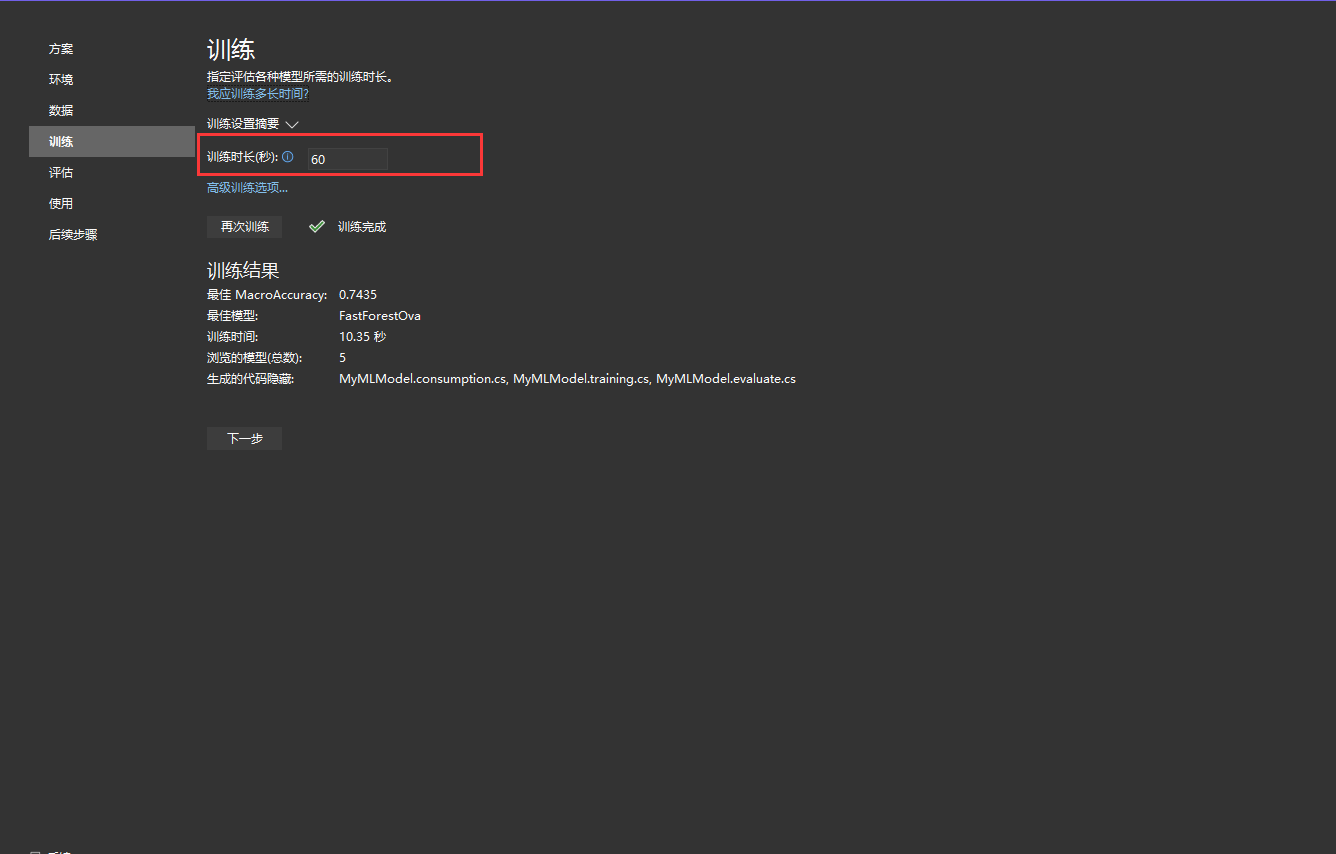
最佳 MacroAccuracy - 这将向你展示 Model Builder 找到的最佳模型的准确性。准确性越高意味着模型对于测试数据的预测越正确。 最佳模型 - 这将显示在 Model Builder 探索期间表现最佳的算法。 训练时间 - 显示训练/探索模型所花费的总时间量。 已浏览的模型(总计) - 这将显示 Model Builder 在给定时间内浏览的模型总数。 生成的代码隐藏 - 这显示为帮助使用模型或训练新模型而生成的文件的名称。
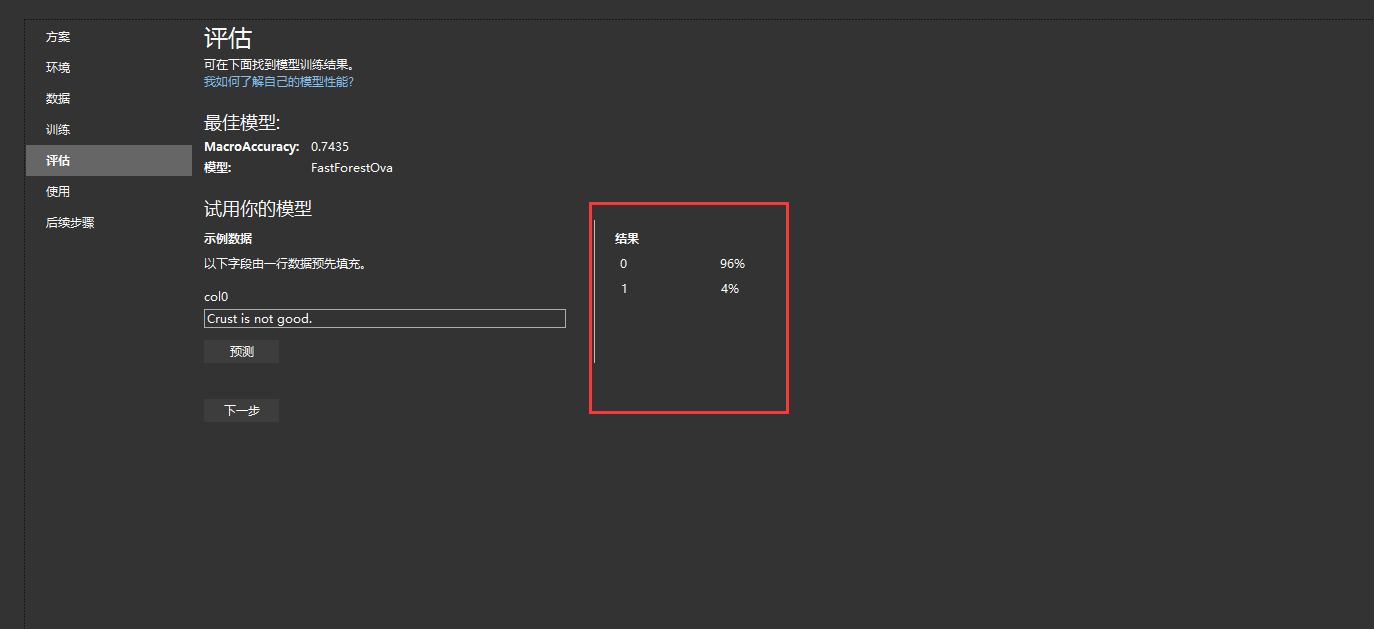
6. 评估是衡量模型品质的过程。 模型生成器使用经过训练的模型对新的测试数据进行预测,然后度量预测效果的过程
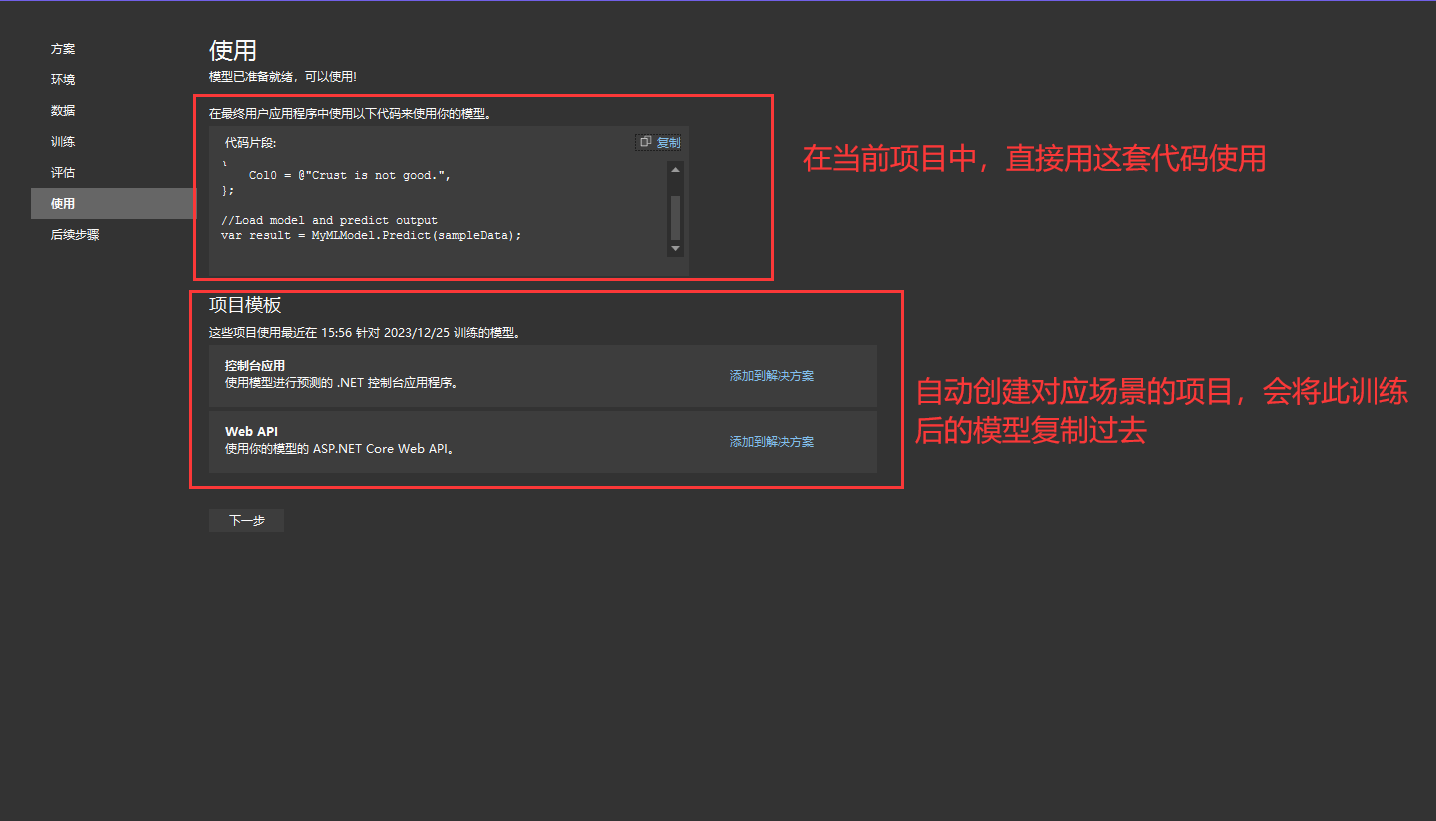
7. 使用。前面已经训练好模型了,这里提供了两种使用方式示例:一种是直接复制代码在当前模型所在应用程序就可以使用了,一种是生成对应的控制台或web api项目,生成的项目会自动复制刚刚训练的模型,我这里测试就用的第一种
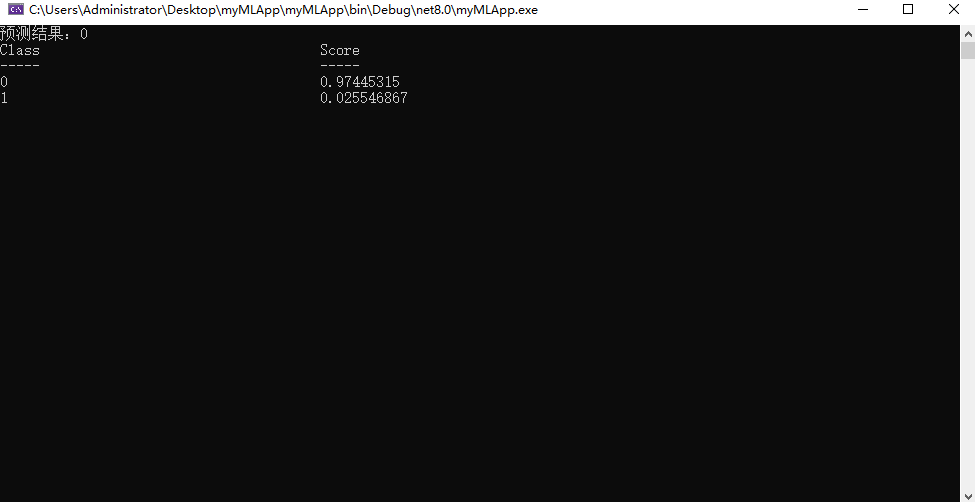
8. 将刚刚的示例代码复制到控制台直接运行(我这里新加了几行代码便于观察)
using MyMLApp; var sampleData = new MyMLModel.ModelInput() { Col0 = @"I advise EVERYONE DO NOT BE FOOLED!", }; //Load model and predict output var result = MyMLModel.Predict(sampleData); Console.WriteLine("预测结果:"+ result.PredictedLabel); var sortedScoresWithLabel = MyMLModel.GetSortedScoresWithLabels(result); Console.WriteLine($"{"Class",-40}{"Score",-20}"); Console.WriteLine($"{"-----",-40}{"-----",-20}"); foreach (var score in sortedScoresWithLabel) { Console.WriteLine($"{score.Key,-40}{score.Value,-20}"); } Console.ReadLine();
注意:如果模型性能评分不符合预期,可以:
1. 延长训练时间。 有了更多时间,自动机器学习引擎可以体验更多算法和设置。 2. 添加更多数据。 有时,数据量不足以训练高质量的机器学习模型。对于包含少量示例的数据集,尤其如此。 3. 均衡分配数据。 对于分类任务,请确保在各个类别间均匀分配训练集。 例如,若有四个类别和 100 个训练示例,前两类(标记 1 和标记 2)包含 90 个记录,而剩下两类(标记 3 和标记 4)只包含 10 个记录,这就存在数据不均衡的问题,
可能会导致模型很难正确预测标记 3 或标记 4。
利用回归函数进行值预测
场景:可以根据打车的时间,行驶里程数等因素预测车费,根据房子大小、地理位置来预测房价等等
示例说明:手动模拟了一百多条数据,来预测打车的费用,数据包含四列:第一列为行车时间(秒),第二列为里程数,第三列为支付方式(这里有两种支付方式,支付宝和微信),第四列为车费。默认使用车费=行车时间*0.1+里程数*0.2,如果使用微信支付打0.88折,支付宝则不打折(这个规则只是随便编的为了验证后面的数据)
具体步骤和上面数据分类的步骤差不多,这里就省略了很多相同的步骤
1. 方案选择值预测
2. 数据:导入准备的测试数据

3. 训练:选择了30秒,训练完成后会自动覆盖之前的模型代码
4. 评估:可以直接在这里测试
5. 使用:不同的方案生成的代码不一样,输入输出的类和方法不同,但是使用方式是差不多的
var sampleData = new MyMLModel.ModelInput() { Col0 = 200, Col1 = 12, Col2 = @"ZFB", }; //Load model and predict output var result = MyMLModel.Predict(sampleData); Console.WriteLine("预测结果值:"+ result.Score); Console.ReadLine();

按照之前预置的规则费用如果是支付宝支付,车费应该=行车时间*0.1+里程数*0.2=200*0.1+12*0.2=22.4。 这里预测出来是24.78054,因为我这里数据只有一百多条进行训练,肯定有偏差,如果进行大量的数据训练,这个数据偏差肯定会更小
其他环境使用类似