join 用法及原理
- Sql查询的基本原理
- 表查询的分类
- 单表查询
- 根据
WHERE条件过滤表中的记录,然后根据SELECT指定的列返回查询结果
- 根据
- 两表连接查询
- 使用
ON条件对两表进行连接形成一张虚拟结果集,然后根据WHERE条件过滤结果集中的记录,再根据SELECT指定的列返回查询结果
- 使用
- 多表连接查询
- 先对第一张和第二张表按照两表连接查询,然后再用连接后的虚拟结果集和第三张表做连接记录,依次类推,直到所有表都连接上为止,最终形成一张虚拟结果集,然后根据
WHERE条件过滤虚拟结果集中的记录,再根据SELECT指定的列返回结果
- 先对第一张和第二张表按照两表连接查询,然后再用连接后的虚拟结果集和第三张表做连接记录,依次类推,直到所有表都连接上为止,最终形成一张虚拟结果集,然后根据
- 单表查询
- 多表连接结果通过是三个属性来决定
- 方向性:在外连接中写在前边的表是左表,写在后边的表为右表
- 主附关系
- 对应关系
- 表对应关系分类
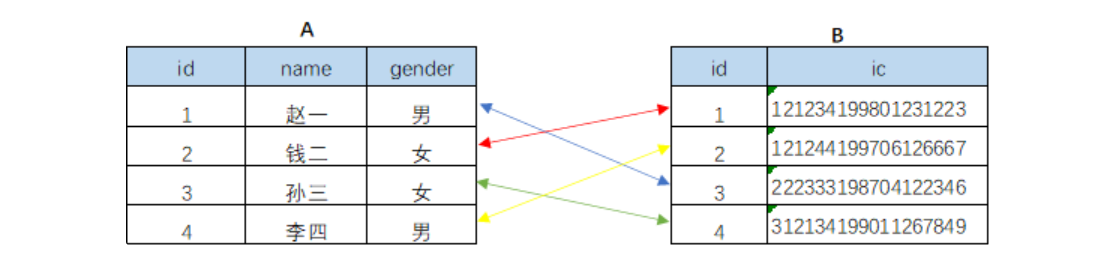
- 一对一
- A表中的一行最多只能匹配B表中的一行
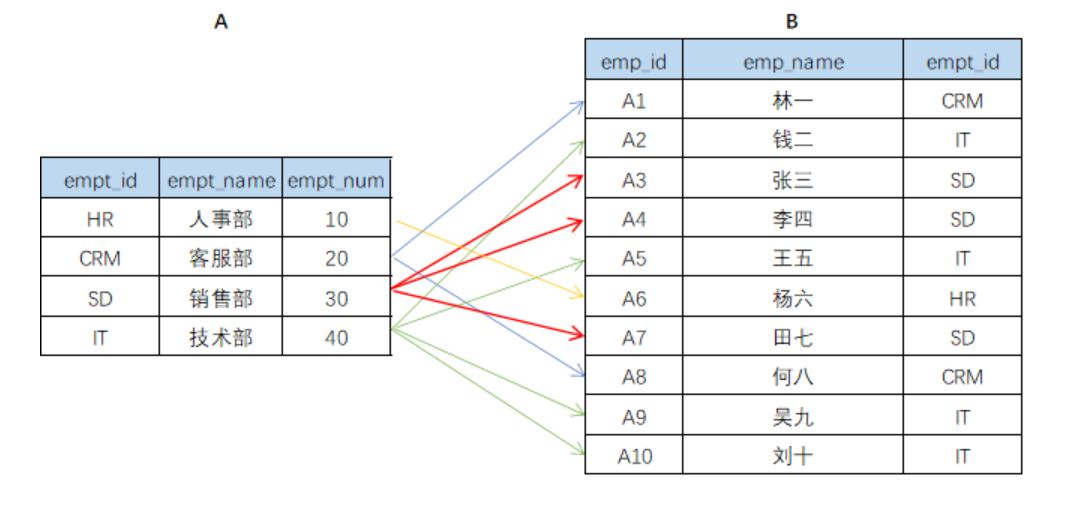
- 一对多
- A表中的一行可以匹配B表中的多行,但B表中的一行只能匹配A表中的一行
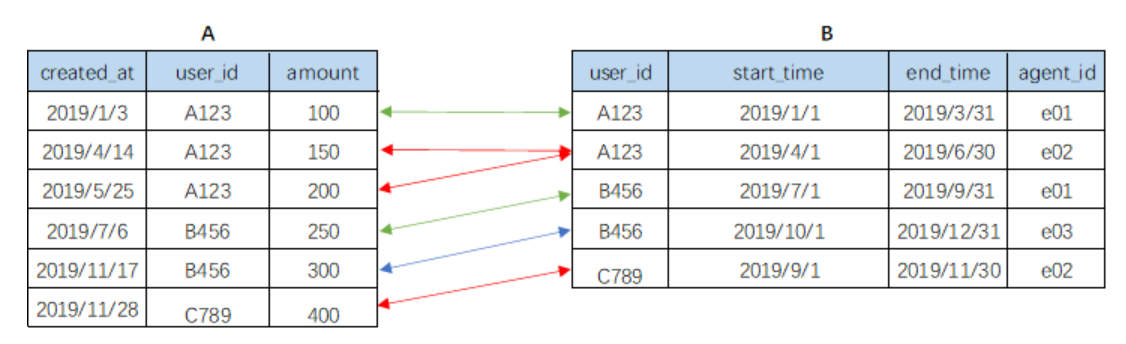
- 多对多
- A表中的一行对应B表中的多行,反之亦然
- 一对一
- 表查询的分类
- 表连接算法
- Simple Nested-Loop Join(简单的嵌套循环连接)
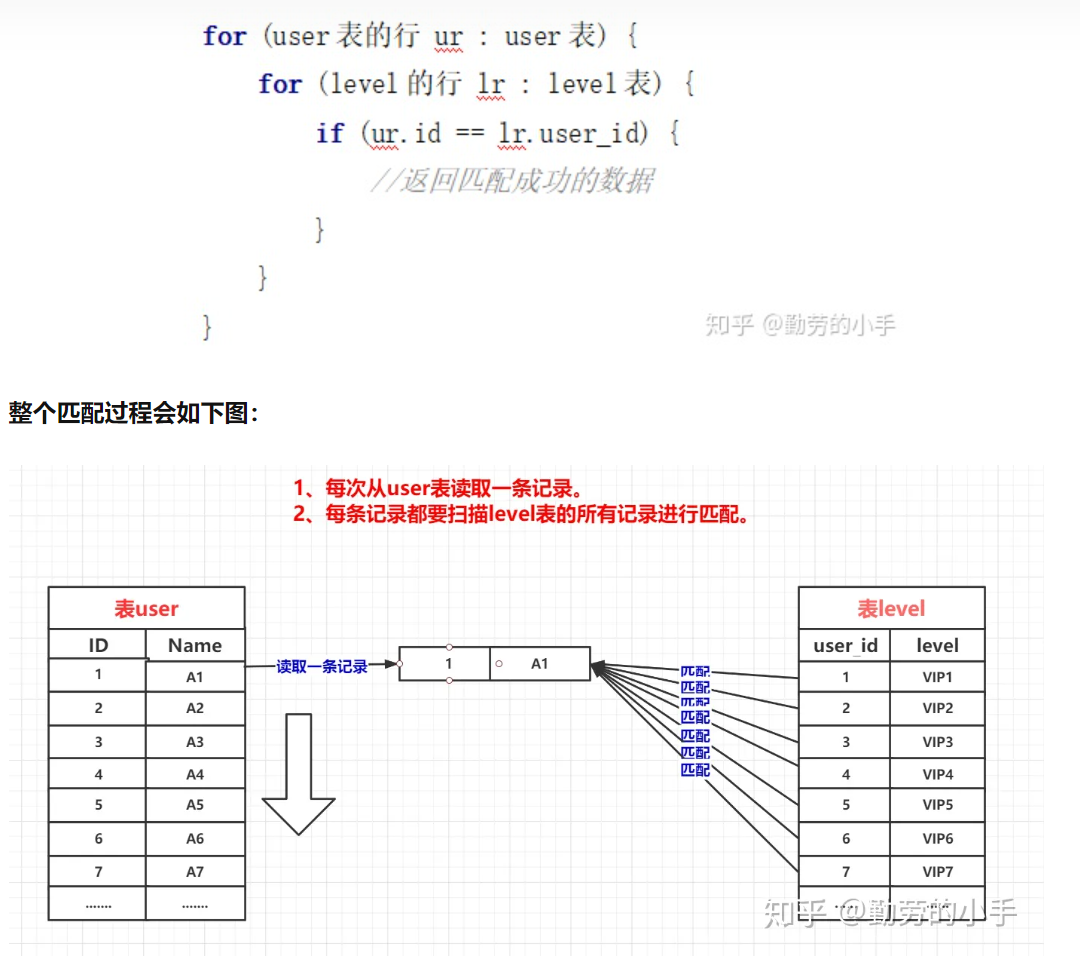
- 嵌套循环连接算法就是一个双层For循环,通过循环外层表的行数据,逐个与内层表的所有行数据进行比较来获取结果,当执行
SELECT * from tb1 LEFT JOIN level tb2 on tb1.id=tb2.user_id
- 特点
- 简单粗暴,通过双层循环比较数据来获得结果,但算法显然太过于粗鲁,假如每个表有1万条数据,那么对数据比较的次数=1万* 1万 =1亿次,查询效率非常慢
- 嵌套循环连接算法就是一个双层For循环,通过循环外层表的行数据,逐个与内层表的所有行数据进行比较来获取结果,当执行
- Index Nested-Loop Join(索引嵌套循环连接)
- 索引嵌套循环连接算法主要是为了减少内层表数据的匹配次数,通过外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每个记录去进行比较,匹配次数=外层表的行数 * 内层表索引的高度
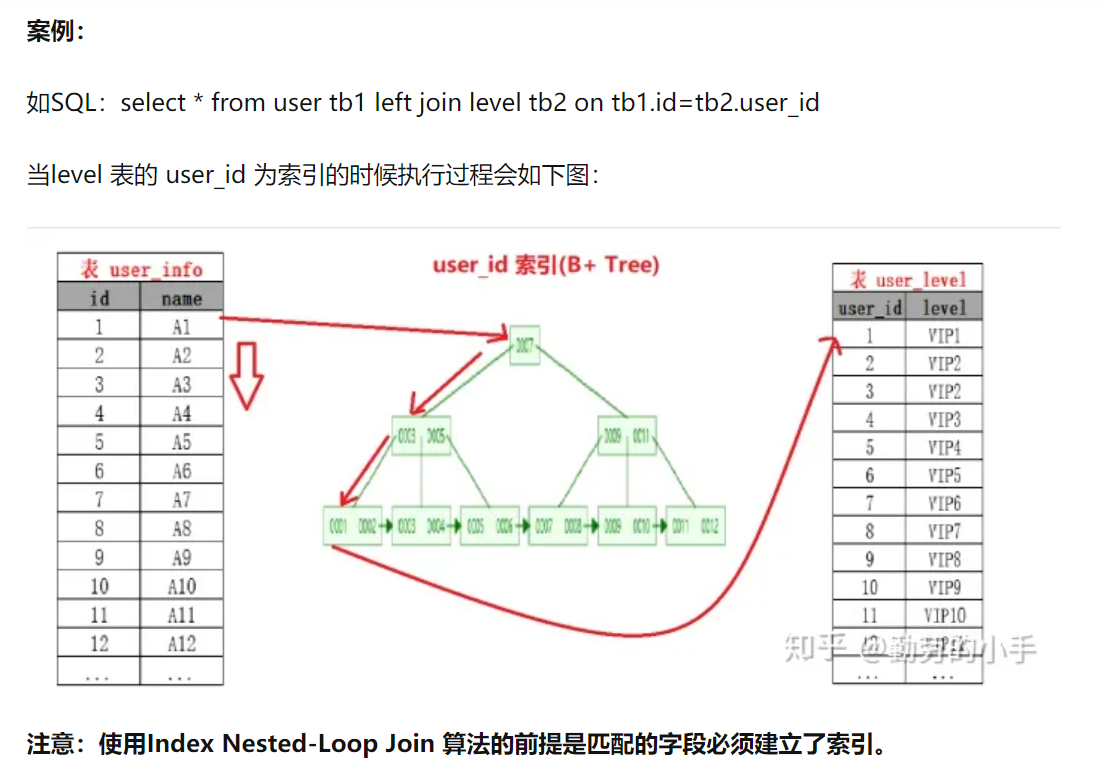
- 索引嵌套循环连接算法主要是为了减少内层表数据的匹配次数,通过外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每个记录去进行比较,匹配次数=外层表的行数 * 内层表索引的高度
- Block Nested-Loop Join(缓存块嵌套循环连接)
- 缓存块嵌套循环连接其优化思路是减少内层表的扫表次数,通过简单的嵌套循环查询图,左边的每一条记录都会对右表进行一次扫表,扫表的过程其实就是从内存读取数据的过程,这个过程比较消耗性能的
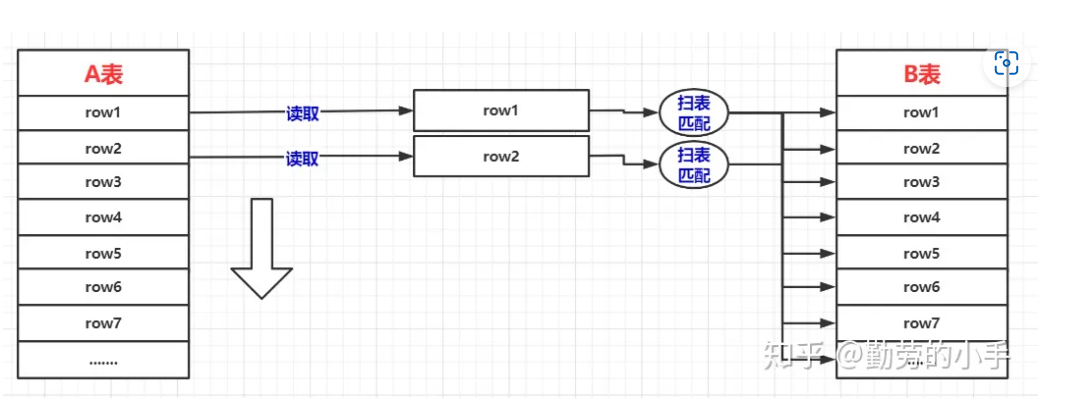
所以缓存块嵌套循环连接算法在通过一次性缓存外层表的多条数据,来减少内层表的扫表次数,如果无法使用索引嵌套连接算法的时候,数据库默认是使用缓存块嵌套循环算法
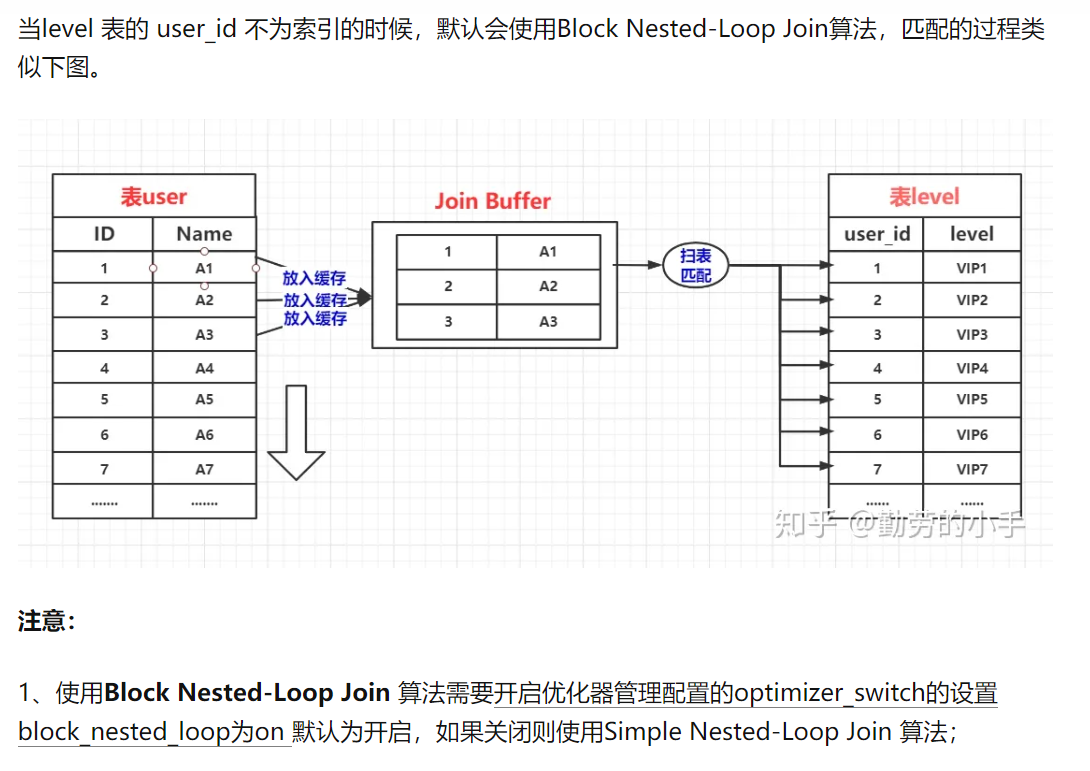
- 注意:
- 使用Block Nested-Loop Join算法需要开启优化器管理配置的optimizer_switc的设置,默认为开启
通过指令:SHOW VARIABLES LIKE 'optimizer_switc%'查看配置

- 设置Join buffer的大小
通过join_buffer_size参数可设置join buffer的大小
指令:SHOW VARIABLES LIKE 'join_buffer_size%'

- 使用Block Nested-Loop Join算法需要开启优化器管理配置的optimizer_switc的设置,默认为开启
- 缓存块嵌套循环连接其优化思路是减少内层表的扫表次数,通过简单的嵌套循环查询图,左边的每一条记录都会对右表进行一次扫表,扫表的过程其实就是从内存读取数据的过程,这个过程比较消耗性能的
- Simple Nested-Loop Join(简单的嵌套循环连接)
- 影响性能的因素
- 内循环的次数
- 小表驱动大表能够减少内循环的次数
- 设置合理的缓冲区大小能够提高连接效率
- 快速匹配
- 扫描被驱动表寻找合适的记录可以看做一个查询,建索引,在被驱动表建立索引能够提高连接速度,
- 例如在左连接中,左表是驱动表,右表是被驱动表,要想快速查找表中匹配的记录,可以在右表中建立索引,右连接相反
- 排序
- 优先选择驱动表的属性进行排序能够提高效率
- 内循环的次数
- 链接: