原文:The Deep Learning with PyTorch Workshop
译者:飞龙
本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
不要担心自己的形象,只关心如何实现目标。——《原则》,生活原则 2.3.c
一、深度学习和 PyTorch 简介
概述
本章介绍了本书的两个主要主题:深度学习和 PyTorch。 在这里,您将能够探索深度学习的一些最受欢迎的应用,了解什么是 PyTorch,并使用 PyTorch 构建单层网络,这将是您将学习应用于现实生活的数据问题的起点。 在本章结束时,您将能够使用 PyTorch 的语法来构建神经网络,这在后续章节中将是必不可少的。
简介
深度学习是机器学习的子集,它专注于使用神经网络来解决复杂的数据问题。 如今,由于软件和硬件的进步使我们能够收集和处理大量数据(我们正在谈论数以亿计的条目),它变得越来越流行。 考虑到深度神经网络需要大量数据才能表现良好,这一点很重要。
深度学习的一些最著名的应用是自动驾驶汽车,流行的聊天机器人以及各种语音激活助手,这些将在本章中进一步说明。
PyTorch 于 2017 年推出,其主要特点是它使用图形处理单元(GPU)来使用“张量”处理数据。 这使算法可以高速运行,同时,它为用户提供了灵活性和标准语法,可以为许多数据问题获得最佳结果。 此外,PyTorch 使用动态计算图,使您可以随时随地更改网络。 本书使用 PyTorch 揭开了神经网络神秘面纱,并帮助您了解神经网络架构的复杂性。
为什么选择深度学习?
在本节中,我们将介绍深度学习的重要性及其普及的原因。
深度学习是机器学习的子集,它使用多层神经网络(大型神经网络),受人脑的生物结构启发,其中一层中的神经元接收一些输入数据,对其进行处理, 并将输出发送到下一层。 这些神经网络可以由成千上万个相互连接的节点(神经元)组成,大多数情况下组织在不同的层中,其中一个节点连接到上一层中的多个节点,从那里接收输入数据,还连接到上一层中的几个节点。 下一层,在处理完输出数据后,它将输出数据发送到下一层。
深度学习的普及是由于其准确率。 对于诸如自然语言处理(NLP)之类的复杂数据问题,它已达到比其他算法更高的准确率。 深度学习的出色表现能力已经达到了机器可以胜过人类的水平,例如在欺诈检测中。 深度学习模型不仅可以优化流程,而且可以提高其质量。 这意味着在诸如安全性之类的出于安全原因至关重要的革命性领域(例如自动驾驶汽车)的进步。
尽管神经网络在几十年前就已经理论化了,但神经网络最近变得流行有两个主要原因:
-
神经网络需要并实际上利用大量标记数据来实现最佳解决方案。 这意味着,要使用该算法创建出色的模型,就需要成千上万甚至上百万个条目,其中包含特征和目标值。 例如,关于猫的图像识别,您拥有的图像越多,该模型能够检测的特征就越多,这使其变得更好。
注意
标记数据是指包含一组特征(描述实例的特征)和目标值(要实现的值)的数据; 例如,包含人口统计和财务信息的数据集,其目标特征确定一个人的工资。
下图显示了在数据量方面深度学习相对于其他算法的表现:
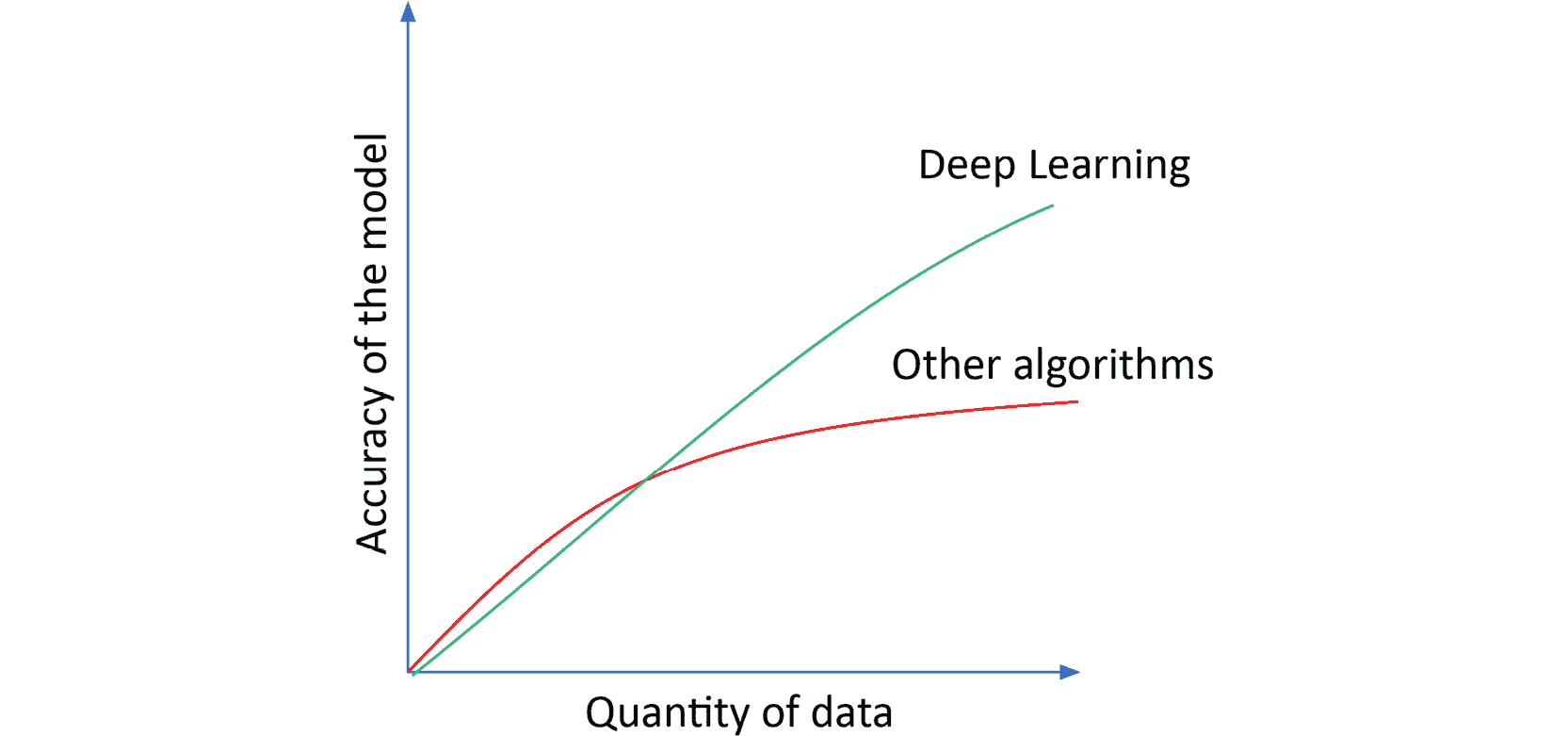
图 1.1:相对于其他算法的深度学习表现
如今,由于软件和硬件的进步使我们能够收集和处理这种粒度,这成为可能。
-
神经网络需要相当大的计算能力才能处理如此大量的数据,而无需花费数周(甚至更长)的时间来进行训练。 由于获得最佳模型的过程是基于反复试验的,因此有必要能够尽可能高效地运行训练过程。
今天,这可以通过使用 GPU 来实现,它可以将神经网络的训练时间从数周缩短至数小时。
注意
为了加速深度学习,以便能够利用大量训练数据并构建最新模型,现场可编程门阵列(FPGA)和张量处理单元(TPU)正在由主要的云计算提供商开发,例如 AWS,Microsoft Azure 和 Google。
深度学习的应用
深度学习正在革新技术,并且已经在影响我们的生活。 深度学习可应用于各种情况,从医疗和安全(例如欺诈检测)目的到更琐碎的任务,例如为黑白图像着色或实时翻译文本。
深度学习的一些正在开发中或正在使用的应用包括:
- 自动驾驶汽车:诸如 Google 之类的多家公司一直在致力于开发部分或全部自动驾驶汽车,这些汽车通过使用数字传感器识别周围的物体来学习驾驶。
- 医学诊断:深度学习通过提高诸如脑和乳腺癌等绝症的诊断准确率,正在对该行业产生影响。 这是通过根据以前有或没有癌症的患者的标记 X 射线对新患者的 X 射线(或其他诊断影像机制)进行分类来完成的。
- 语音助手:由于各种语音激活的智能助手(例如 Apple 的 Siri,Google Home 和亚马逊的 Alexa)的激增,它可能是当今最受欢迎的应用之一。
- 自动生成文本:这意味着根据输入的句子生成新文本。 这通常用于电子邮件编写中,其中电子邮件提供者根据已编写的文本向用户建议接下来的几个单词。
- 广告:在商业世界中,深度学习通过瞄准合适的受众并制作更有效的广告来帮助提高广告系列的投资回报。 这样的一个例子是生成内容,以产生最新的和信息丰富的博客,以帮助吸引当前客户并吸引新客户。
- 价格预测:对于初学者来说,这是使用机器学习算法可以实现的典型示例。 价格预测包括根据实际数据训练模型。 例如,在房地产领域,这将包括提供具有房地产特征及其最终价格的模型,以便能够仅基于房地产特征来预测未来入场券的价格。
PyTorch 简介
PyTorch 是一个开放源代码库,主要由 Facebook 的人工智能研究小组开发为 Python 版本的 Torch。
注意
Torch 是一个开放源代码,科学的计算框架,支持多种机器学习算法。
PyTorch 于 2017 年 1 月首次向公众发布。它使用 GPU 的功能来加速张量的计算,从而加快了复杂模型的训练时间。
该库具有 C++ 后端,并结合了 Torch 的深度学习框架,与具有许多深度学习功能的本机 Python 库相比,它可以提供更快的计算速度。 前端使用 Python,这有助于使其流行,从而使刚接触该库的数据科学家能够构建复杂的神经网络。 可以将 PyTorch 与其他流行的 Python 包一起使用。
尽管 PyTorch 相当新,但由于它是根据该领域许多专家的反馈开发的,因此迅速获得了普及。 这使得 PyTorch 成为对用户有用的库。
PyTorch 中的 GPU
GPU 最初是为了加速图形渲染中的计算而开发的,尤其是对于视频游戏等。 但是,由于它们能够帮助加快任何领域的计算速度,包括深度学习计算,它们最近变得越来越受欢迎。
有几种平台可以将变量分配给计算机的 GPU,其中计算统一设备架构(CUDA)是最常用的平台之一。 CUDA 是 Nvidia 开发的计算平台,由于使用 GPU 来执行计算,因此可以加快计算密集型程序的速度。
在 PyTorch 中,可以通过使用torch.cuda包将变量分配给 CUDA,如以下代码片段所示:
x = torch.Tensor(10).random_(0, 10)
x.to("cuda")
在这里,第一行代码创建了一个张量,该张量填充有随机整数(介于 0 和 10 之间)。 第二行代码将该张量分配给 CUDA,以便所有与该张量有关的计算都由 GPU 而不是 CPU 处理。 要将变量分配回 CPU,请使用以下代码片段:
x.to("cpu")
在 CUDA 中,当解决深度学习数据问题时,优良作法是分配保存网络架构的模型以及输入数据。 这将确保在训练过程中执行的所有计算均由 GPU 处理。
但是,只有在您的计算机具有可用的 GPU 且您已将 CUDA 包安装了 PyTorch 的情况下,才能进行此分配。 要验证您是否能够在 CUDA 中分配变量,请使用以下代码段:
torch.cuda.is_available()
如果前一行代码的输出为True,那么您都准备开始在 CUDA 中分配变量。
注意
要与 CUDA 包一起安装 PyTorch,请访问 PyTorch 的网站,并确保选择包含 CUDA(两个版本)的选项。
什么是张量?
与 NumPy 相似,PyTorch 使用张量表示数据。 张量是n尺寸的矩阵状结构,不同之处在于 PyTorch 张量可以在 GPU 上运行(而 NumPy 张量不能),这有助于加速数值计算。 对于张量,尺寸也称为秩。 下图显示了不同尺寸的张量的直观表示:
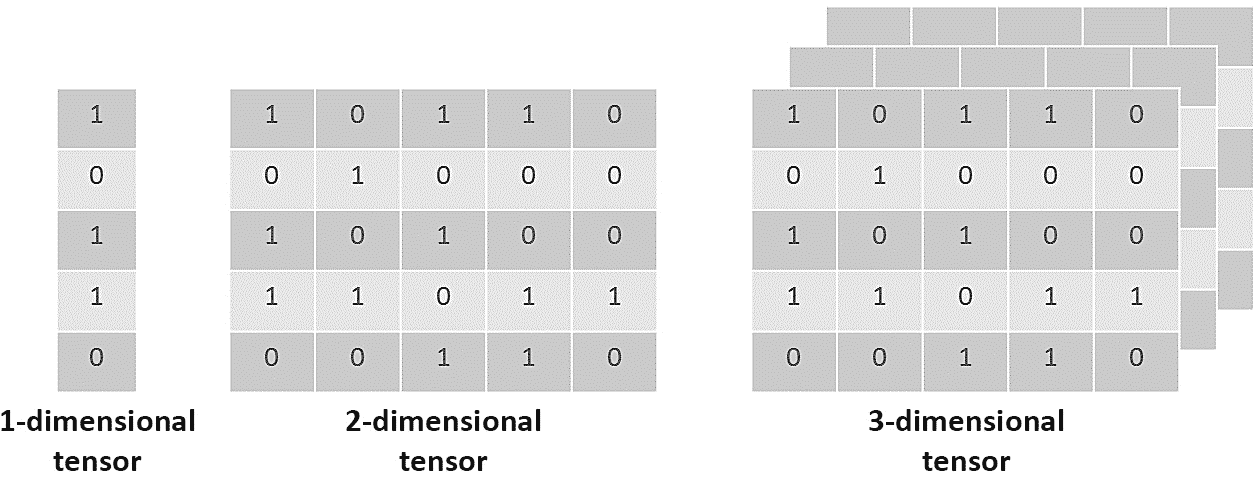
图 1.2:不同尺寸张量的可视化表示
与矩阵相反,张量是包含在结构中的数学实体,可以与其他数学实体进行交互。 当一个张量转换另一个张量时,前者也进行自己的转换。
这意味着张量不仅是数据结构,而且是容器,当容器提供某些数据时,它们可以与其他张量以多线性方式映射。
类似于 NumPy 数组或任何其他类似矩阵的结构,PyTorch 张量可以具有所需的任意多个尺寸。 可以使用以下代码片段在 PyTorch 中定义一维张量(tensor_1)和二维张量(tensor_2):
tensor_1 = torch.tensor([1,1,0,2])
tensor_2 = torch.tensor([[0,0,2,1,2],[1,0,2,2,0]])
请注意,前面的代码片段中的数字没有含义。 重要的是不同维度的定义,其中用随机数填充。 根据前面的代码段,第一个张量在一个维度上的大小为 4,而第二张量在两个维度中的每个维度的大小为 5,可以通过验证张量变量的shape属性,如下所示:
tensor_1.shape
输出为torch.Size([4])。
tensor_2.shape
输出为torch.Size([2], [5])。
使用支持 GPU 的计算机时,将进行以下修改以定义张量:
tensor = torch.tensor([1,1,0,2]).cuda
使用 PyTorch 张量创建伪数据非常简单,类似于您在 NumPy 中执行的操作。 例如,torch.randn()返回一个用括号内指定尺寸的随机数填充的张量,而torch.randint()返回一个以整数填充的张量(最小和最大值可以定义)括号内定义的尺寸:
注意
此处显示的代码段使用反斜杠(\)将逻辑划分为多行。 执行代码时,Python 将忽略反斜杠,并将下一行中的代码视为当前行的直接延续。
example_1 = torch.randn(3,3)
example_2 = torch.randint(low=0, high=2, \
size=(3,3)).type(torch.FloatTensor)
可以看出,example_1是填充有随机数的二维张量,每个维的大小等于 3,而example_2是填充有 0,1 和 2 的二维张量(high参数是上限),每个尺寸的大小等于 3。
任何填充有整数的张量都必须转换为浮点数,以便我们可以将其馈送到任何 PyTorch 模型。
练习 1.01:使用 PyTorch 创建不同等级的张量
在本练习中,我们将使用 PyTorch 库创建秩为 1、2 和 3 的张量。 执行以下步骤以完成本练习:
注意
对于本章中的练习和活动,您将需要安装 Python 3.7,Jupyter 6.0,Matplotlib 3.1 和 PyTorch 1.3+(最好是 PyTorch 1.4,有或没有 CUDA)(如“前言”中的说明) )。 它们将主要在 Jupyter 笔记本电脑中开发,建议您为不同的作业保留一个单独的笔记本电脑,除非建议不要这样做。
-
导入名为
torch的 PyTorch 库:import torch -
创建以下等级的张量:
1,2和3。使用
0和1之间的值填充张量。 张量的大小可以根据您的需要进行定义,前提是正确创建了等级:tensor_1 = torch.tensor([0.1,1,0.9,0.7,0.3]) tensor_2 = torch.tensor([[0,0.2,0.4,0.6],[1,0.8,0.6,0.4]]) tensor_3 = torch.tensor([[[0.3,0.6],[1,0]], \ [[0.3,0.6],[0,1]]])如果您的计算机具有可用的 GPU,则可以使用 GPU 语法创建等效张量:
tensor_1 = torch.tensor([0.1,1,0.9,0.7,0.3]).cuda() tensor_2 = torch.tensor([[0,0.2,0.4,0.6], \ [1,0.8,0.6,0.4]]).cuda() tensor_3 = torch.tensor([[[0.3,0.6],[1,0]], \ [[0.3,0.6],[0,1]]]).cuda() -
就像使用 NumPy 数组一样,使用
shape属性输出每个张量的形状:print(tensor_1.shape) print(tensor_2.shape) print(tensor_3.shape)考虑到张量每个维度的大小可能会根据您的选择而变化,因此
print语句的输出应如下所示:torch.Size([5]) torch.Size([2, 4]) torch.Size([2, 2, 2])注意
要访问此特定部分的源代码,请参考这里。
您也可以通过这里在线运行此示例。 您必须执行整个笔记本才能获得所需的结果。
要访问此源代码的 GPU 版本,请参考这里。 此版本的源代码无法作为在线交互示例使用,需要通过 GPU 设置在本地运行。
您已经成功创建了不同等级的张量。
在下一节中,我们将讨论使用 PyTorch 的优缺点。
使用 PyTorch 的优点
如今有几个库可用于开发深度学习解决方案,那么为什么要使用 PyTorch? 答案是 PyTorch 是一个动态库,它允许用户极大的灵活性来开发可适应特定数据问题的复杂架构。
PyTorch 已被许多研究人员和人工智能开发人员采用,这使其成为机器学习工程师工具包中的重要工具。
要强调的关键方面如下:
- 易于使用:就 API 而言,PyTorch 具有简单的接口,可轻松开发和运行模型。 许多早期采用者认为它比 TensorFlow 等其他库更直观。
- 速度:使用 GPU 使该库的训练速度比其他深度学习库更快。 当必须测试不同的近似值以获得最佳的模型时,这特别有用。 此外,即使其他库也可以选择使用 GPU 加速计算,您也可以在 PyTorch 中通过键入几行简单的代码来实现。
- 便利性:PyTorch 灵活。 它使用动态计算图,使您可以随时随地更改网络。 由于易于对常规架构进行调整,因此在构建架构时还具有极大的灵活性。
- 急切执行:PyTorch 也是急切执行。 每行代码都是单独执行的,使您可以实时跟踪模型,并以方便的方式调试模型。
- 预训练模型:最后,它包含许多易于使用的预训练模型,它们是某些数据问题的一个很好的起点。
使用 PyTorch 的缺点
尽管优点很多,但仍然存在一些要考虑的缺点,在这里进行了说明:
- 小型社区:与其他库(例如 TensorFlow)相比,该库的适配器社区很小。 但是,它仅对公众开放了三年,今天,它已成为实现深度学习解决方案的最受欢迎的前五个库之一,并且它的社区每天都在增长。
- 参差不齐的文档:与其他深度学习库相比,该库是一个相当新的文档,因此该文档并不完整。 但是,由于库的特性和功能正在增加,因此文档正在扩展。 此外,随着社区的不断发展,互联网上将提供更多信息。
- 有关生产准备就绪的问题:尽管有关该库的许多投诉都集中在无法将其部署到生产中,但在发布 1.0 版之后,该库包含了生产能力,可以导出最终模型并在生产环境中使用它们。
PyTorch 的关键元素
像任何其他库一样,PyTorch 具有用于开发不同功能的各种模块,库和包。 在本节中,将解释构建深度神经网络的三个最常用元素以及语法的简单示例。
PyTorch autograd库
autograd库由称为自动微分的技术组成。 其目的是通过数值计算函数的导数。 这对于我们将在下一章中学习的称为反向传播的概念至关重要,该概念是在训练神经网络时执行的。
元素的导数(也称为梯度)是指该元素在给定时间步长中的变化率。 在深度学习中,梯度是指维数和大小,其中必须在训练步骤中更新神经网络的参数,以最小化损失函数。 在下一章中将进一步探讨该概念。
注意
神经网络的详细解释和训练模型所采取的不同步骤将在后续章节中给出。
要计算梯度,只需调用backward()函数,如下所示:
a = torch.tensor([5.0, 3.0], requires_grad=True)
b = torch.tensor([1.0, 4.0])
ab = ((a + b) ** 2).sum()
ab.backward()
在前面的代码中,创建了两个张量。 我们在这里使用require_grad参数来告诉 PyTorch 计算该张量的梯度。 但是,在构建神经网络时,不需要此参数。
接下来,使用两个张量的值定义一个函数。 最后,使用backward()函数来计算梯度。
通过打印a和b的梯度,可以确认仅对第一个变量(a)计算梯度,而对第二个(b)计算梯度,则会引发错误:
print(a.grad.data)
输出为Tensor([12., 14.])。
print(b.grad.data)
输出如下:
AttributeError: 'NoneType' object has no attribute 'data'
PyTorch nn模块
考虑到已经解决了棘手的部分(梯度的计算),仅autograd库可用于构建简单的神经网络。 但是,这种方法可能很麻烦,因此引入了nn模块。
nn模块是一个完整的 PyTorch 模块,用于创建和训练神经网络,该神经网络通过使用不同的元素,可以进行简单而复杂的开发。 例如,Sequential()容器可轻松创建遵循一系列预定义模块(或层)的网络架构,而无需太多的定义网络架构的知识。
注意
在随后的章节中将进一步解释可用于每种神经网络架构的不同层。
该模块还具有定义损失函数以评估模型的能力,以及将在本书中讨论的许多更高级的功能。
只需几行就可以完成将神经网络架构构建为一系列预定义模块的过程,如下所示:
import torch.nn as nn
model = nn.Sequential(nn.Linear(input_units, hidden_units), \
nn.ReLU(), \
nn.Linear(hidden_units, output_units), \
nn.Sigmoid())
loss_funct = nn.MSELoss()
首先,导入模块。 然后,定义模型架构。 input_units表示输入数据包含的特征数量,hidden_units表示隐藏层的节点数量, output_units表示输出层的节点数量。
从前面的代码中可以看出,网络的架构包含一个隐藏层,其后是 ReLU 激活函数和一个输出层,然后是一个 Sigmoid 激活函数,从而使其成为两层网络。
最后,损失函数定义为均方误差(MSE)。
注意
本书将介绍针对不同数据问题的最流行的损失函数。
要创建不遵循现有模块顺序的模型,请使用自定义nn模块。 我们将在本书后面介绍这些内容。
练习 1.02:定义单层架构
在本练习中,我们将使用 PyTorch 的nn模块为单层神经网络定义模型,并定义损失函数以评估模型。 这将是起点,以便您能够构建更复杂的网络架构来解决实际数据问题。 执行以下步骤以完成本练习:
-
从 PyTorch 导入
torch和nn模块:import torch import torch.nn as nn注意
本练习中使用
torch.manual_seed(0),以确保在本书的 GitHub 存储库中获得的结果具有可重复性。 但是,在出于其他目的训练网络时,不得定义种子。要了解有关 PyTorch 中种子的更多信息,请访问这里。
-
定义输入数据的特征数为
10(input_units),输出层的节点数为1(output_units)。input_units = 10 output_units = 1 -
使用
Sequential()容器,定义单层网络架构并将其存储在名为model的变量中。 确保定义一层,然后定义Sigmoid激活函数:model = nn.Sequential(nn.Linear(input_units, output_units), \ nn.Sigmoid()) -
打印模型以验证是否已相应创建:
print(model)前面的代码段将显示以下输出:
Sequential( (0): Linear(in_features=10, out_features=1, bias=True) (1): Sigmoid() ) -
将损失函数定义为 MSE 并将其存储在名为
loss_funct的变量中:loss_funct = nn.MSELoss() -
打印损失函数以验证是否已相应创建:
print(loss_funct)运行前面的代码片段将显示以下输出:
MSELoss()注意
要访问此特定部分的源代码,请参考这里。
您也可以通过这里在线运行此示例。 您必须执行整个笔记本才能获得所需的结果。
您已经成功定义了单层网络架构。
PyTorch optim包
optim包用于定义优化器,该优化器将使用autograd计算出的梯度来更新每次迭代中的参数(将在以下各章中进一步说明)。 模块。 在这里,可以从可用的不同优化算法中进行选择,例如 Adam,随机梯度下降(SGD)和均方根传播(RMSprop)等。
注意
后续章节将介绍最流行的优化算法。
要设置要使用的优化程序,在导入包后,以下代码行就足够了:
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
在此,model.parameters()参数是指先前创建的模型的权重和偏差,而lr是指学习率,该学习率已设置为0.01。
权重是用于确定一般情况下某些信息的重要性级别的值。 这意味着信息的每一位对于网络中的每个神经元都有相应的权重。 此外,偏差类似于添加到线性函数中的拦截元素,用于调整给定神经元中相关性计算的输出。
学习率是一个运行参数,在优化过程中用于确定为使损失函数最小化而应采取的步骤的程度。
接下来,此处显示了运行 100 次迭代的优化过程,如您所见,它使用nn模块创建的模型以及autograd库计算出的梯度 :
注意
以下代码段中的#符号表示代码注释。 注释已添加到代码中,以帮助解释特定的逻辑位。 下面的代码片段中的三引号(""")用来表示多行代码注释的起点和终点。在代码中添加了注释,以帮助解释特定的逻辑位 。
for i in range(100):
# Call to the model to perform a prediction
y_pred = model(x)
# Calculation of loss function based on y_pred and y
loss = loss_funct(y_pred, y)
# Zero the gradients so that previous ones don't accumulate
optimizer.zero_grad()
# Calculate the gradients of the loss function
loss.backward()
"""
Call to the optimizer to perform an update
of the parameters
"""
optimizer.step()
对于每次迭代,调用模型以获得预测(y_pred)。 该预测和真实情况值(y)被馈送到损失函数,以确定模型逼近真实情况的能力。
接下来,将梯度归零,并使用backward()函数计算损失函数的梯度。
最后,调用step()函数,以基于优化算法和先前计算的梯度来更新权重和偏差。
练习 1.03:训练神经网络
注意
对于本练习,请使用与上一个练习相同的 Jupyter 笔记本(“练习 1.02”,“定义单层架构”)。
在本练习中,我们将使用 PyTorch 的optim包,学习如何从上一练习中训练单层网络。 考虑到我们将使用虚拟数据作为输入,训练网络不会解决数据问题,但是将其用于学习目的。 执行以下步骤以完成本练习:
-
导入
torch、PyTorch 的optim包和matplotlib。import torch import torch.optim as optim import matplotlib.pyplot as plt -
创建随机值的虚拟输入数据(
x)和仅包含零和一的虚拟目标数据(y)。 张量x的大小应为(20, 10),而y的大小应为(20, 1):x = torch.randn(20,10) y = torch.randint(0,2, (20,1)).type(torch.FloatTensor) -
将优化算法定义为 Adam 优化器。 将学习率设置为等于 0.01:
optimizer = optim.Adam(model.parameters(), lr=0.01) -
运行优化 20 次迭代,将损失值保存在变量中。 每五次迭代,输出损失值:
losses = [] for i in range(20): y_pred = model(x) loss = loss_funct(y_pred, y) losses.append(loss.item()) optimizer.zero_grad() loss.backward() optimizer.step() if i%5 == 0: print(i, loss.item())输出应如下所示:
0 0.25244325399398804 5 0.23448510468006134 10 0.21932794153690338 15 0.20741790533065796前面的输出显示周期号以及损失函数的值,可以看出,该函数正在减小。 这意味着训练过程使损失函数最小化,这意味着模型能够理解输入特征和目标之间的关系。
-
绘制线图以显示每个周期的损失函数的值:
plt.plot(range(0,20), losses) plt.show()输出应如下所示:
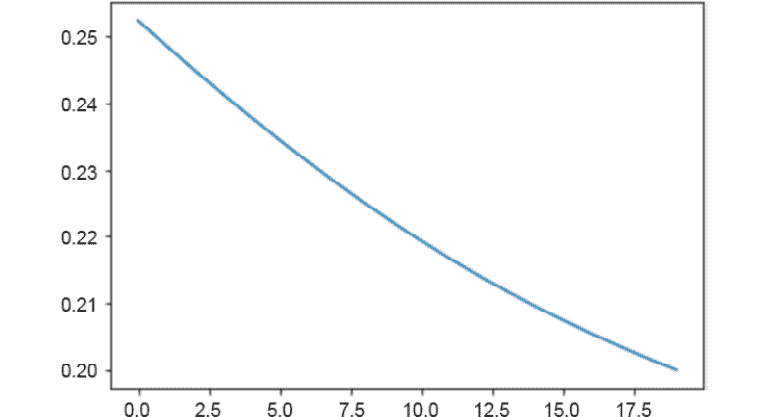
图 1.3:损失函数被最小化
如您所见,损失函数已被最小化。
注意
要访问此特定部分的源代码,请参考这里。
您也可以通过这里在线运行此示例。 您必须执行整个笔记本才能获得所需的结果。
这样,您就成功地训练了单层神经网络。
活动 1.01:创建单层神经网络
对于此活动,我们将创建一个单层神经网络,这将是我们在以后的活动中创建深度神经网络的起点。 让我们看一下以下情况。
您是萨默维尔市市长的助理,人事部门要求您建立一个模型,该模型能够根据人们对本市服务的满意度来预测人们对当前政府是否满意。 为此,您已经决定使用 PyTorch 并根据之前的调查结果构建一个单层神经网络。 执行以下步骤以完成此活动:
注意
用于此活动的数据集来自 UC Irvine 机器学习存储库,该存储库可使用以下 URL 从数据文件夹超链接中下载。 也可以在本书的 GitHub 存储库中找到它。
-
导入所需的库,包括用于读取 CSV 文件的 Pandas。
-
读取包含数据集的 CSV 文件。
注意
建议使用 Pandas 的
read_csv函数加载 CSV 文件。 要了解有关此函数的更多信息,请访问这里。 -
将输入特征与目标分开。 请注意,目标位于 CSV 文件的第一列中。 接下来,将值转换为张量,确保将值转换为浮点数。
注意
要切片 pandas
DataFrame,请使用 pandas 的iloc方法。 要了解有关此方法的更多信息,请访问这里。 -
定义模型的架构,并将其存储在名为
model的变量中。 记住要创建一个单层模型。 -
定义要使用的损失函数。 在这种情况下,请使用 MSE 损失函数。
-
定义模型的优化器。 在这种情况下,请使用 Adam 优化器,并将学习率设为
0.01。 -
对 100 次迭代运行优化,保存每次迭代的损失值。 每 10 次迭代打印一次损失值。
-
绘制线图以显示每个迭代步骤的损失值。
注意
有关此活动的解决方案,请参阅第 236 页。
总结
深度学习是机器学习的一个子集,其灵感来自人脑的生物结构。 它使用深度神经网络通过使用大量数据来解决复杂的数据问题。 尽管该理论是数十年前开发的,但由于硬件和软件的进步使我们能够收集和处理数百万条数据,因此该理论最近得到了使用。
随着深度学习解决方案的普及,已经开发了许多深度学习库。 其中,最新的一种是 PyTorch。 PyTorch 使用 C++ 后端,这有助于加快计算速度,同时具有 Python 前端,以使该库易于使用。
它使用张量存储数据,这些数据是 n 阶矩阵状结构,可以在 GPU 上运行以加快处理速度。 它提供了三个主要元素,这些元素对于创建复杂的神经网络架构非常有用。
autograd库可以计算函数的导数,这些导数用作优化模型权重和偏差的梯度。 此外,nn模块可帮助您轻松地将模型的架构定义为一系列预定义的模块,并确定用于测量模型的损失函数。 最后,考虑到先前计算的梯度,optim包用于选择用于更新参数的优化算法。
在下一章中,我们将学习神经网络的构建块。 我们将介绍三种类型的学习过程以及三种最常见的神经网络类型。 对于每个神经网络,我们将学习网络架构的结构以及训练过程的工作方式。 最后,我们将了解数据准备的重要性并解决回归数据问题。
二、神经网络的构建块
概述
本章介绍了神经网络的主要组成部分,并解释了当今的三种主要神经网络架构。 此外,它解释了训练任何人工智能模型之前数据准备的重要性,并最终解释了解决回归数据问题的过程。 在本章的最后,您将牢固地掌握不同网络架构及其不同应用的学习过程。
简介
在上一章中,已经解释了为什么深度学习如今变得如此流行,并且 PyTorch 被介绍为开发深度学习解决方案的最受欢迎的库之一。 尽管已解释了使用 PyTorch 构建神经网络的主要语法,但在本章中,我们将进一步探讨神经网络的概念。
尽管神经网络理论是在几十年前发展起来的,但是自从感知器概念演变成神经网络理论以来,最近就已经创建了不同的架构来解决不同的数据问题。 这部分是由于在现实生活中的数据问题(例如文本,音频和图像)中可以找到不同的数据格式。
本章的目的是深入探讨神经网络及其主要优点和缺点的主题,以便您了解何时以及如何使用它们。 然后,我们将解释最流行的神经网络架构的构建块:人工神经网络(ANN),卷积神经网络(CNN)和循环神经网络(RNN)。
接下来,将通过解决现实生活中的回归问题来说明建立有效模型的过程。 这包括准备要馈送到神经网络的数据(也称为数据预处理),定义要使用的神经网络架构以及评估模型的表现,目的是确定如何对其进行改进以实现最佳表现。 最佳解决方案。
上述过程将使用将在本章中讨论的一种神经网络架构来完成,同时考虑到每个数据问题的解决方案应使用对所讨论的数据类型表现最佳的架构进行。 其他架构将在后续章节中使用,以解决更复杂的数据问题,这些问题涉及使用图像和文本序列作为输入数据。
注意
神经网络介绍
神经网络从训练数据中学习,而不是通过遵循一组规则进行编程来解决特定任务。 此学习过程可以遵循以下方法之一:
-
监督学习:这是最简单的学习形式,因为它包含一个标记的数据集,其中神经网络会找到解释特征和目标之间关系的模式。 学习过程中的迭代旨在最小化预测值和基本事实之间的差异。 一个例子是根据植物的叶子属性对植物进行分类。
-
无监督学习:与前面的方法相反,无监督学习包括使用未标记数据(意味着没有目标值)训练模型。 这样做的目的是为了更好地理解输入数据。 通常,网络获取输入数据,对其进行编码,然后从编码版本中重建内容,理想情况下保留相关信息。 例如,给定一个段落,神经网络可以映射单词,然后建议哪个单词对该段落最重要或最具描述性。 然后可以将它们用作标签。
-
强化学习:这种方法包括从输入数据中学习,其主要目标是从长远来看最大化奖励函数。 这是通过从传入的数据中学习来实现的,而不是通过对静态数据进行训练(如在监督式学习中)来实现的。 因此,决策不是基于即时奖励,而是基于整个学习过程中累积的奖励。 这样的一个示例是一个模型,该模型将资源分配给不同的任务,其目的是最大程度地减少使总体表现变慢的瓶颈。
注意
从我们在这里提到的学习方法中,最常用的一种是有监督的学习,这将主要在后续部分中使用。 这意味着本章中的所有练习,活动和示例都将使用标记的数据集作为输入数据。
什么是神经网络?
正如我们之前所讨论的,神经网络是一种机器学习算法,它以人脑的解剖结构为模型,并使用数学方程式从训练数据得出的观察结果中学习模式。
但是,要真正理解神经网络通常遵循的训练过程背后的逻辑,重要的是要了解感知器的概念。
感知器由弗兰克·罗森布拉特(Frank Rosenblatt)在 1950 年代开发,是一种人造神经元,它需要多个输入并产生二进制输出,类似于人脑中的神经元。 然后,这成为后续感知器(神经元)的输入。 感知器是神经网络的基本组成部分(就像神经元是人脑的组成部分一样):
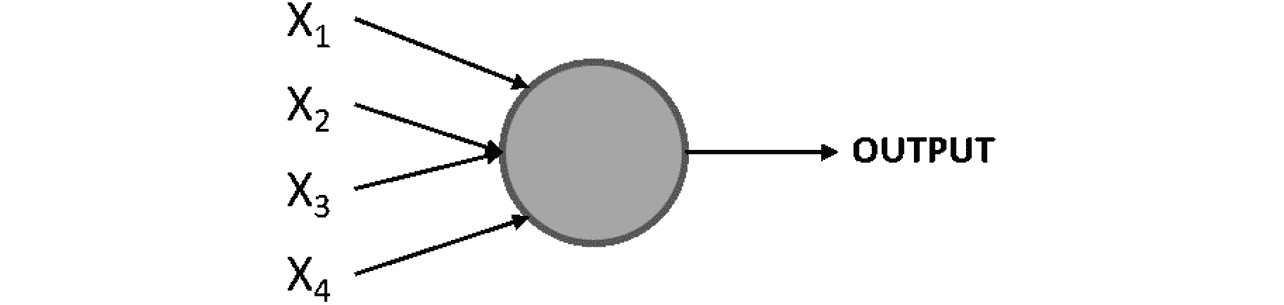
图 2.1:感知器图
在这里,X1,X2,X3和X4代表感知器的不同输入,并且这些可能是任何数字。 圆是感知器,在该处处理输入以达到输出。
Rosenblatt 还介绍了权重的概念(w1,w2,...,wn),这些数字表示每个输入的重要性。 输出可以是 0 或 1,并且取决于输入的加权总和是高于还是低于给定阈值(由开发人员设置的数值限制或由数据问题的约束设置),该阈值可以设置为感知器的参数,如下所示:
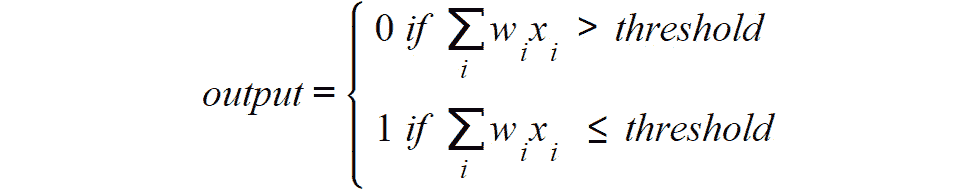
图 2.2:感知器输出方程
练习 2.01:执行感知器的计算
以下练习不需要任何编程。 相反,它由简单的计算组成,可帮助您理解感知器的概念。 要执行这些计算,请考虑以下情形。
下个星期五在您的镇上有一个音乐节,但是您生病了,想决定是否要去(0 表示您不参加,1 表示您要参加)。 您的决定取决于三个因素:
- 天气会好吗? (
X1) - 你要和谁一起去? (
X2) - 音乐是您喜欢的吗? (
X3)
对于前面的因素,如果问题的答案为是,则将使用 1,如果答案为否,则将使用 0。 此外,由于您病得很重,因此与天气相关的因素非常重要,因此您决定赋予该因素比其他两个因素大两倍的权重。 因此,您决定因素的权重将为 4(w1),2(w2)和 2(w3)。 现在,考虑阈值 5:
- 考虑到下周五的天气不好,但是您要和某人一起去,并且您喜欢音乐节上的音乐,请根据提供的信息来计算感知器的输出:

图 2.3:感知器的输出
考虑到输出小于阈值,最终结果将等于 0,这意味着您不应该参加音乐节以避免生病的风险。
您已经成功执行了感知器的计算,这是了解神经网络内部学习过程的起点。
多层感知器
考虑到我们在上一节中学到的知识,多层网络的概念由堆叠在一起的多个感知器(也称为节点或神经元)组成的网络组成,如下所示:
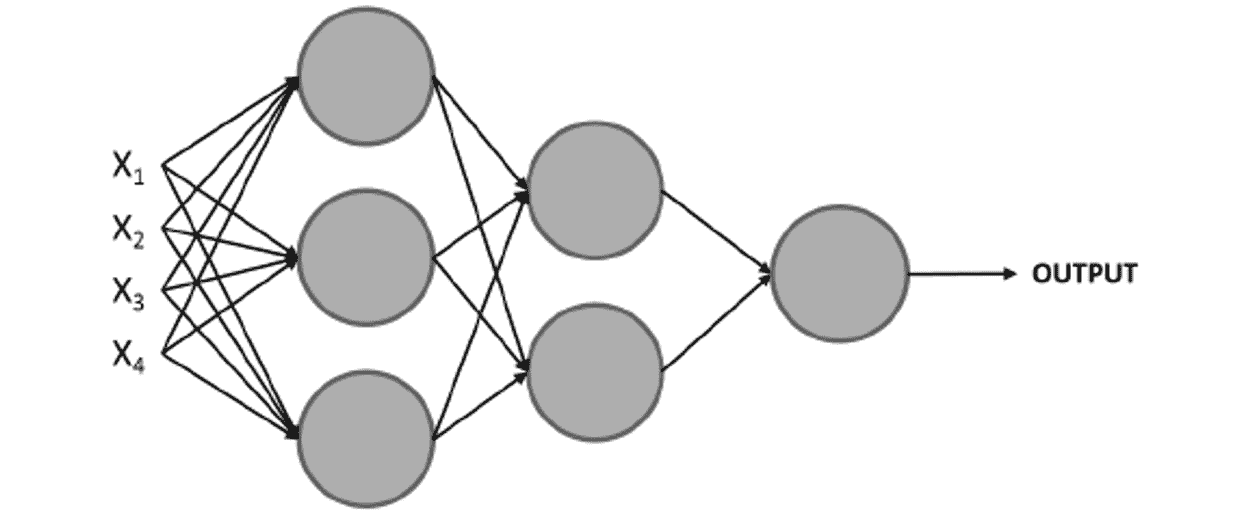
图 2.4:多层感知器图
注意
在神经网络中引用层的常规方法如下:
第一层是输入层,最后一层是输出层,中间的所有层都是隐藏层。
在这里,再次使用一组输入来训练模型,但是不是馈入单个感知器,而是将它们馈入第一层中的所有感知器(神经元)。 接下来,将从这一层获得的输出用作后续层中的感知器的输入,依此类推,直到到达最后一层为止,该层负责输出结果。
请注意,感知器的第一层通过对输入进行加权来处理简单的决策过程,而下一层可以根据前一层的输出来处理更复杂和抽象的决策,从而实现最新的表现。 复杂数据问题的深度神经网络(使用多层的网络)。
与传统的感知器不同,神经网络已经演化为在输出层中具有一个或多个节点,因此它们能够将结果呈现为二进制或多类。
神经网络的学习过程
一般而言,神经网络由多个神经元组成,其中每个神经元都会计算线性函数以及激活函数,以根据某些输入得出输出(激活函数旨在打破线性关系,稍后在本章中有更详细的说明)。 该输出与权重相关联,该权重代表其重要性级别,并将在下一层中用于计算。
而且,这些计算是在整个网络架构中进行的,直到达到最终输出为止。 与地面实况相比,此输出用于确定网络的表现,然后将其用于调整网络的不同参数以重新开始计算过程。
考虑到这一点,神经网络的训练过程可以看作是迭代过程,该过程在网络的各个层中前进和后退以达到最佳结果,如下图所示(损失函数将在后面介绍) 在这一章当中):
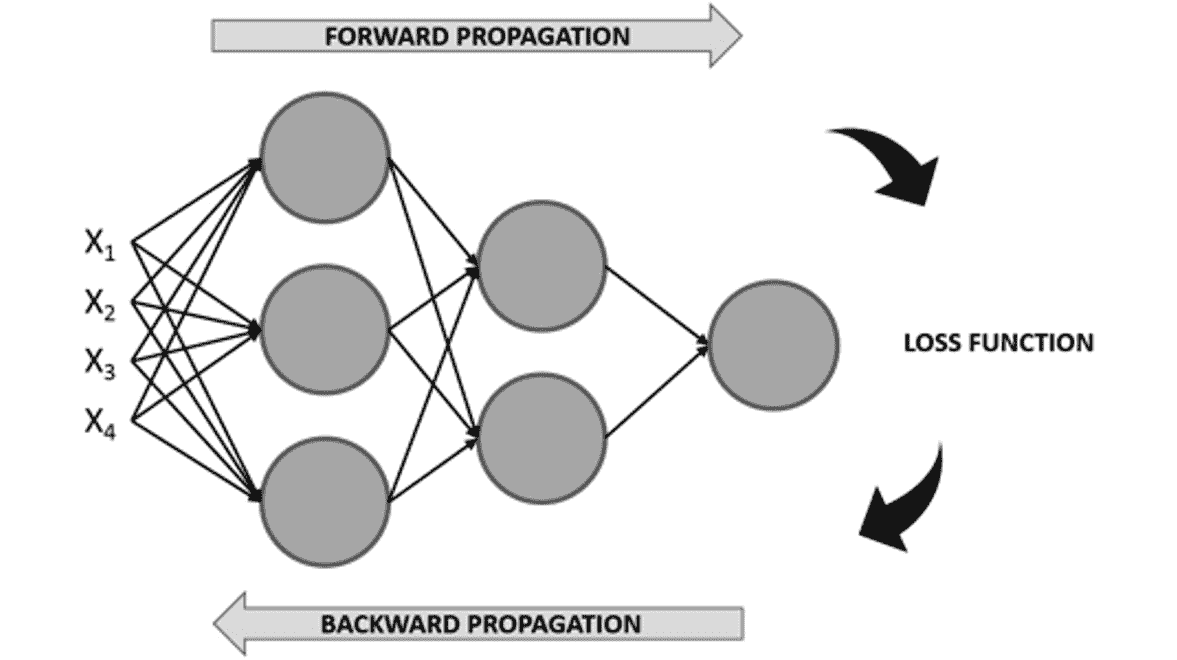
图 2.5:神经网络的学习过程图
正向传播
这是从左到右遍历网络架构的过程,同时使用输入数据执行计算以得出可以与基本事实进行比较的预测。 这意味着网络中的每个神经元都会根据与之关联的权重和偏差来转换输入数据(初始数据或从上一层接收的数据),并将输出发送到下一层,直到达到最后一层并做出预测。
注意
在神经网络中,偏差是帮助移动每个神经元的激活函数的数值,以避免可能影响训练过程的零值。 它们在神经网络训练中的作用将在本章后面解释。
在每个神经元中执行的计算都包括一个线性函数,该函数会将输入数据乘以某个权重再加上一个偏差,然后将其传递给激活函数。 激活函数的主要目的是打破模型的线性,这是至关重要的,因为考虑到使用神经网络解决的大多数实际数据问题不是由一条线定义,而是由一个复杂的函数定义。 这些公式如下:
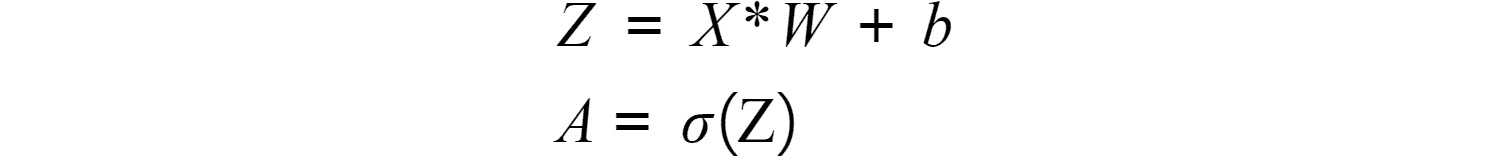
图 2.6:每个神经元执行的计算
在这里,如前所述,X是指输入数据,W是确定输入数据重要程度的权重,b是偏置值和 sigma(σ)表示应用于线性函数的激活函数。
激活函数的目的是将非线性引入模型。 有不同的激活函数可供选择,当今最常用的激活函数列表如下:
- Sigmoid:这是 Sigmoid,它基本上将值转换为 0 到 1 之间的简单概率,其中通过 Sigmoid 函数获得的大多数输出将接近 0 和 1 的极限。
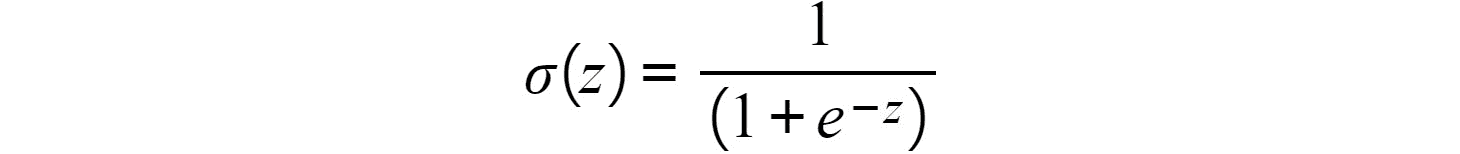
图 2.7:Sigmoid 激活函数
下图显示了 Sigmoid 激活函数的图形表示:
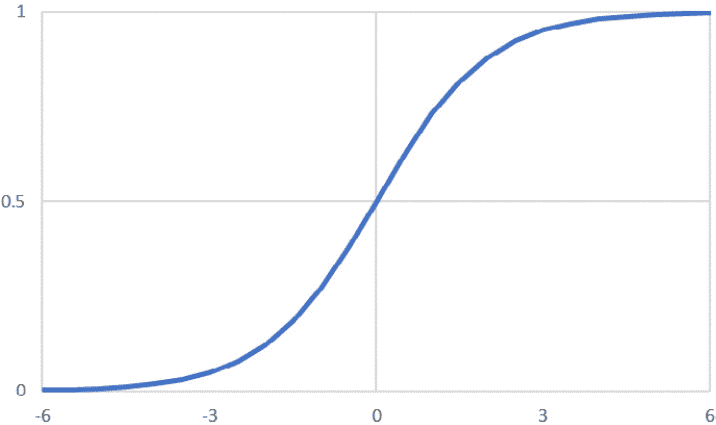
图 2.8:Sigmoid 激活函数的图形表示
- Softmax:类似于 Sigmoid 函数,它计算
n个事件的事件概率分布,这意味着其输出不是二进制的。 简而言之,此函数将计算输出与其他类别相比是目标类别之一的概率:
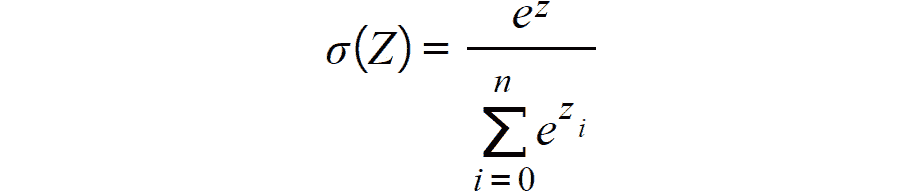
图 2.9:Softmax 激活函数
考虑到其输出是概率,因此通常在分类网络的输出层中找到此激活函数。
- Tanh:此函数表示双曲正弦和双曲余弦之间的关系,结果介于 -1 和 1 之间。此激活函数的主要优点是可以更轻松地处理负值:

图 2.10:Tanh 激活函数
下图显示了 tanh 激活函数的图形表示:
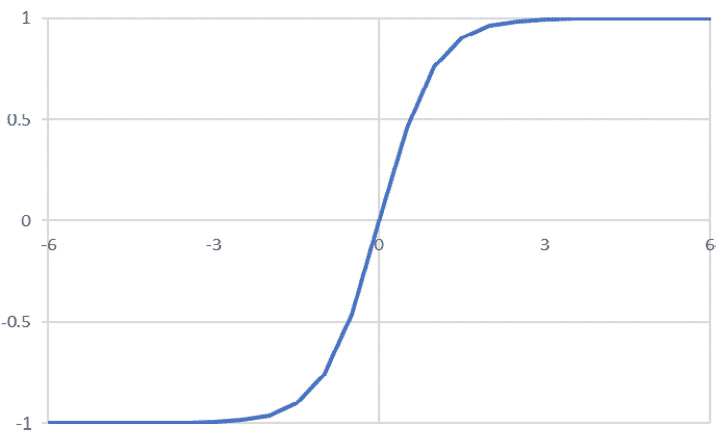
图 2.11:tanh 激活函数的图形表示
- 整流线性函数(ReLU):如果线性函数的输出大于 0,则这基本上激活了一个节点; 否则,其输出将为 0。如果线性函数的输出大于 0,则此激活函数的结果将是其作为输入接收的原始数字:
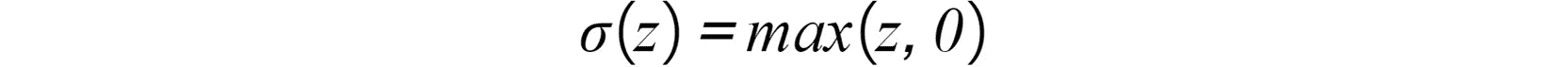
图 2.12:ReLU 激活函数
按照惯例,此激活函数用于所有隐藏层。 我们将在本章的后续部分中了解有关隐藏层的更多信息。 下图显示了 ReLU 激活函数的图形表示:
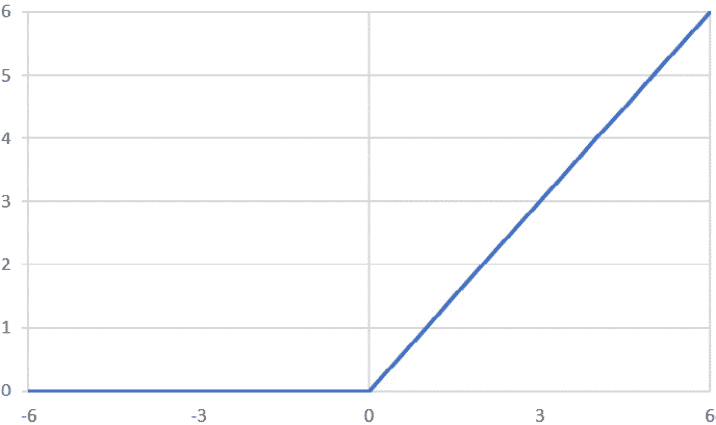
图 2.13:ReLU 激活函数的图形表示
损失函数的计算
一旦正向传播完成,训练过程的下一步就是计算损失函数,以通过比较预测相对于真实情况值的好坏来估计模型的误差。 考虑到这一点,要达到的理想值为 0,这意味着两个值之间没有差异。
这意味着训练过程的每次迭代的目标是通过更改在正向传播过程中用于执行计算的参数(权重和偏差)来最小化损失函数。
同样,有多种损失函数可供选择。 但是,用于回归和分类任务的最常用损失函数如下:
- 均方误差(MSE):MSE 函数广泛用于衡量回归模型的表现,它计算真实情况值与预测值之间的距离之和:
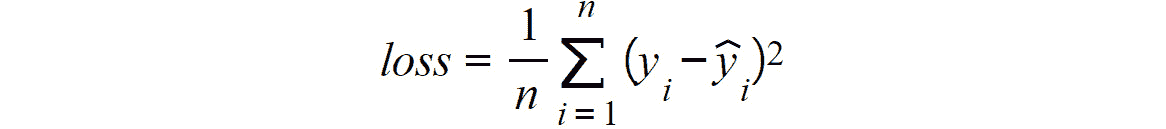
图 2.14:MSE 损失函数
此处,n是指样本数,y[i]是基本真值,y_hat[i]是预测值。
- 交叉熵/多类交叉熵:此函数通常用于二进制或多类分类模型。 它测量两个概率分布之间的差异; 较大的损失函数将表示较大的差异。 因此,这里的目标是使损失函数最小化:
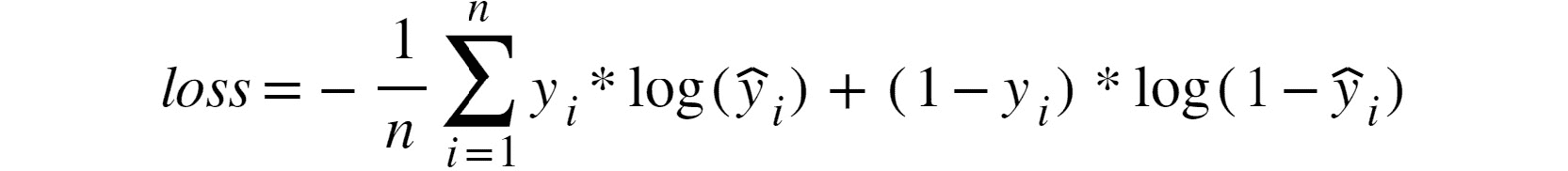
图 2.15:交叉熵损失函数
同样,n是指样本数。 y[i]和y_hat[i]分别是基本事实和预测值。
反向传播
训练过程的最后一步包括在网络架构中从右向左移动以计算损失函数相对于每一层的权重和偏差的偏导数(也称为梯度),以便更新这些参数(权重和偏差),以便在下一个迭代步骤中,损失函数较低。
优化算法的最终目标是找到损失函数达到最小可能值的全局最小值,如下图所示:
注意
局部最小值是指函数域的一部分内的最小值。 另一方面,全局最小值是指函数整个域的最小值。
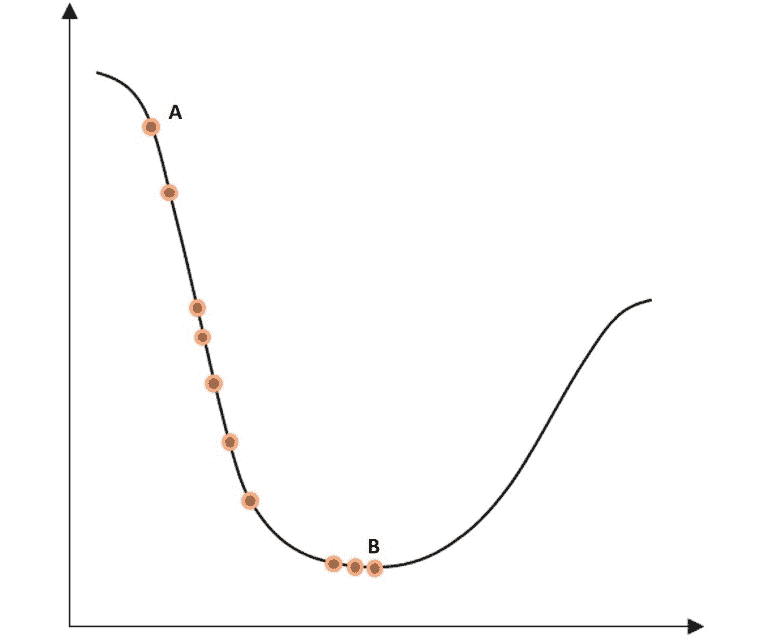
图 2.16:二维空间中迭代步骤的损失函数优化
在此,最左边的点A是任何优化之前的损失函数的初始值。 曲线底部最右边的点B是经过多次迭代步骤后的损失函数,其值已最小化。 从一个点到另一个点的过程称为步骤。
但是,重要的是要提到损失函数并不总是像前面的函数那样平滑,这可能会带来在优化过程中达到局部最小值的风险。
此过程也称为优化,并且有不同的算法在实现相同目标的方法上有所不同。 接下来将解释最常用的优化算法。
梯度下降
梯度下降是数据科学家中使用最广泛的优化算法,它是许多其他优化算法的基础。 计算完每个神经元的梯度后,权重和偏差会沿梯度的相反方向更新,应将其乘以学习率(用于控制每次优化中所采取步骤的大小),例如以下等式。
学习率在训练过程中至关重要,因为它防止权重和过冲/下冲偏差的更新,这可能会阻止模型分别收敛或延迟训练过程。
梯度下降算法中权重和偏差的优化如下:

图 2.17:梯度下降算法中的参数优化
此处,α是指学习率,dw / db表示给定神经元中权重或偏差的梯度。 从权重或偏差的原始值中减去两个值的乘积,以惩罚较高的值,这有助于计算较大的损失函数。
梯度下降算法的一种改进版本称为随机梯度下降,它基本上遵循相同的过程,区别在于它以随机批量而不是一个块的形式获取输入数据,从而缩短了训练时间,同时达到了出色的表现。 此外,此方法允许使用较大的数据集,因为通过将小批数据集用作输入,我们不再受计算资源的限制。
优缺点
以下是对神经网络的优缺点的解释。
优势
在最近几年中,神经网络变得越来越流行,其原因有四个:
- 数据:神经网络以利用大量数据的能力而广为人知,并且由于硬件和软件的进步,现在可以收集和存储海量数据库。 随着更多数据输入到神经网络中,这使神经网络能够显示其真正的潜力。
- 复杂数据问题:如前所述,神经网络非常适合解决其他机器学习算法无法解决的复杂数据问题。 这主要是由于它们具有处理大型数据集和发现复杂模式的能力。
- 计算能力:技术的进步也增加了当今可用的计算能力,这对于训练使用数百万条数据的神经网络模型至关重要。
- 学术研究:由于前面的三点,有关此主题的学术研究在互联网上得以广泛传播,这不仅促进了每天新研究的浸入,而且还有助于保持算法和硬件 /最新的软件要求。
劣势
仅仅因为使用神经网络有很多优点,并不意味着每个数据问题都应该以这种方式解决。 这是一个常见的错误。 没有一种算法可以很好地解决所有数据问题,并且选择使用哪种算法应取决于可用的资源以及数据问题。
尽管人们认为神经网络的表现优于几乎所有机器学习算法,但也必须考虑它们的缺点,以便您可以权衡最重要的数据问题。 让我们现在通过它们:
-
黑盒:这是神经网络最常见的缺点之一。 从根本上讲,尚不清楚神经网络如何以及为什么达到特定输出。 例如,当神经网络错误地将猫的图片预测为狗时,就不可能知道错误的原因是什么。
-
数据要求:为获得最佳结果而需要的大量数据可能是同一个优点和缺点。 神经网络比传统的机器学习算法需要更多的数据,这可能是在某些数据问题和其他算法之间进行选择的主要原因。 当监督手头的任务时,这将成为一个更大的问题,这意味着需要对数据进行标记。
-
训练时间:由于上述缺点,对大量数据的需求也使训练过程比传统的机器学习算法持续时间更长,在某些情况下,这是不可行的。 使用 GPU 可以减少训练时间,从而加快计算速度。
-
计算上非常昂贵:同样,神经网络的训练过程在计算上也很昂贵。 虽然一个神经网络可能需要花费数周的时间才能收敛,但其他机器学习算法却可能需要数小时或数分钟才能得到训练。 所需的计算资源量取决于手头的数据量以及网络的复杂性。 更深的神经网络需要更长的时间来训练。
注意
有各种各样的神经网络架构。 本章将解释三种最常用的方法,并在后续各章中对它们的实际实现进行说明。 但是,如果您想了解其他架构,请访问这里。
人工神经网络简介
人工神经网络(人工神经网络)也称为多层感知器,是多个感知器的集合。 感知器之间的连接通过层发生。 一层可以具有所需数量的感知器,并且它们都与先前和后续层中的所有其他感知器相连。
网络可以具有一层或多层。 具有四层以上的网络被认为是深度神经网络,通常用于解决复杂和抽象的数据问题。
人工神经网络通常由三个主要元素组成,这些元素已在前面进行了解释,也可以在下图中看到:
-
输入层:这是网络的第一层,通常位于网络图形表示中最左侧。 在执行任何计算之前,它会接收输入数据,并完成第一组计算。 这是发现最普通模式的地方。
对于监督学习问题,输入数据包含一对特征和目标。 网络的工作是发现特征与目标之间的相关性或依赖性。
-
隐藏层:接下来,可以找到隐藏层。 神经网络可以具有许多隐藏层,这意味着在输入层和输出层之间可以有任意数量的层。 它具有的层越多,可以解决的数据问题就越复杂,但训练时间也将更长。 还有一些神经网络架构根本不包含隐藏层,单层网络就是这种情况。
在每一层中,都会根据从上一层作为输入接收的信息执行计算,然后将其用于输出将成为下一层输入的值。
-
输出层。这是网络的最后一层,位于网络图示的最右边。它接收网络中所有神经元处理数据后的数据,以做出最终预测。
输出层可以具有一个或多个神经元。 前者是指解决方案是二进制的模型,其形式为 0 或 1s。 另一方面,后一种情况由模型组成,这些模型输出实例属于每个可能的类标签(目标变量具有的可能值)的概率,这意味着该层将具有与类标签一样多的神经元:
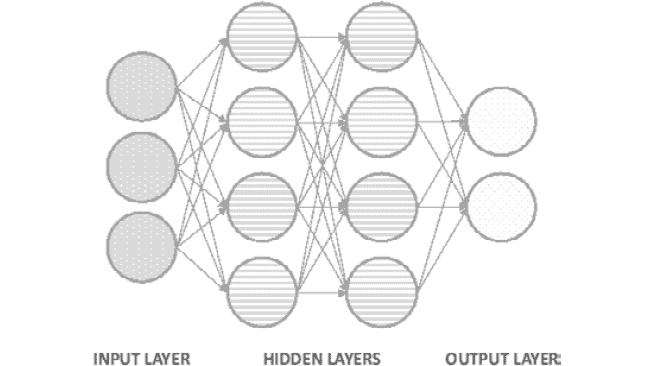
图 2.18:具有两个隐藏层的神经网络的架构
卷积神经网络简介
卷积神经网络(CNN)主要用于计算机视觉领域,在最近几十年中,机器达到的准确率水平超过了人类的能力。
CNN 创建的模型使用神经元的子组来识别图像的不同方面。 这些组应该能够相互通信,以便它们可以一起形成完整的图像。
考虑到这一点,CNN 的架构中的层划分了它们的识别任务。 第一层专注于琐碎的模式,而网络末端的层则使用该信息来揭示更复杂的模式。
例如,当识别图片中的人脸时,前几层专注于寻找将一个特征与另一个特征分开的边缘。 接下来,后续层强调面部的某些特征,例如鼻子。 最后,最后两层使用此信息将人的整个面孔放在一起。
当遇到某些特征时激活一组神经元的想法是通过使用过滤器(核)来实现的,过滤器(核)是 CNN 架构的主要组成部分之一。 但是,它们不是架构中存在的唯一元素,这就是为什么在此将对 CNN 的所有组件进行简要说明的原因:
注意
在使用 CNN 时可能已经听说过的填充和跨步的概念,将在本书的后续章节中进行解释。
-
卷积层。在这些层中,图像(用像素矩阵表示)和过滤器之间进行卷积计算。这种计算产生一个特征映射作为输出,最终作为下一层的输入。
该计算对过滤器形状相同的图像矩阵进行细分,然后对这些值进行乘法运算。 然后,将乘积之和设置为该图像部分的输出,如下图所示:
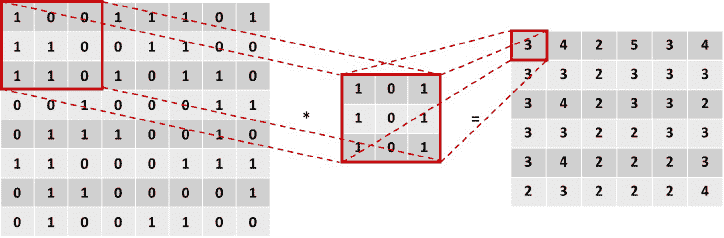
图 2.19:图像和过滤器之间的卷积运算
在这里,左边的矩阵是输入数据,中间的矩阵是过滤器,右边的矩阵是计算的输出。 在方框中突出显示的值所发生的计算可以在这里看到:
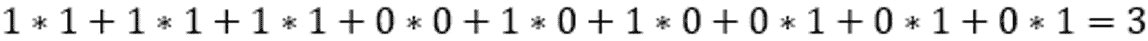
图 2.20:图像第一部分的卷积
对图像的所有子部分都进行了卷积乘法。 下图显示了同一示例的另一个卷积步骤:
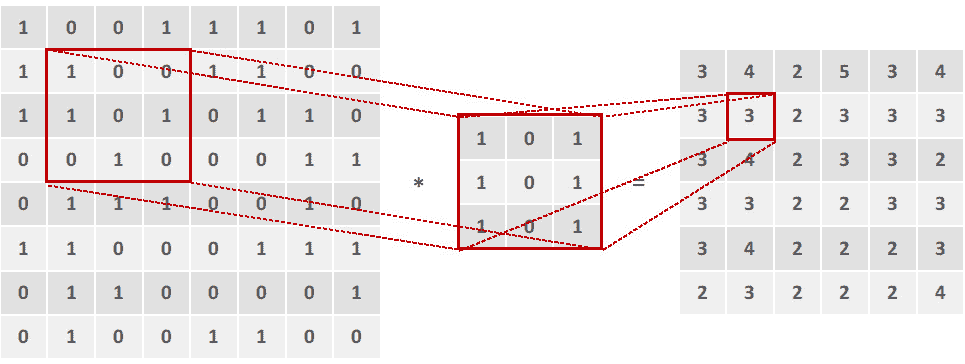
图 2.21:卷积运算的进一步步骤
卷积层的一个重要概念是它们是不变的,因此每个过滤器都将具有特定的函数,该函数在训练过程中不会发生变化。 例如,负责检测耳朵的过滤器将仅在整个训练过程中专门用于该函数。
此外,考虑到所使用的过滤器,考虑到每个 CNN 都将专注于识别图像的特定特征或一组特征,因此 CNN 通常将具有多个卷积层。 通常,在两个卷积层之间有一个池化层。
-
池化层:尽管卷积层能够从图像中提取相关特征,但是当分析复杂的几何形状时它们的结果可能会变得非常巨大,这将使训练过程在计算能力方面成为不可能,因此发明了池化层。
这些层不仅实现了减少卷积层输出的目标,而且还消除了已提取特征中存在的任何噪声,最终最终有助于提高模型的准确率。
可以应用两种主要类型的池化层,其背后的想法是检测在图像中表现出较强影响的区域,以便可以忽略其他区域。
最大池化:此操作包括将给定大小的矩阵的一个子部分作为该最大子集操作的输出,并采用该子部分中的最大数目:
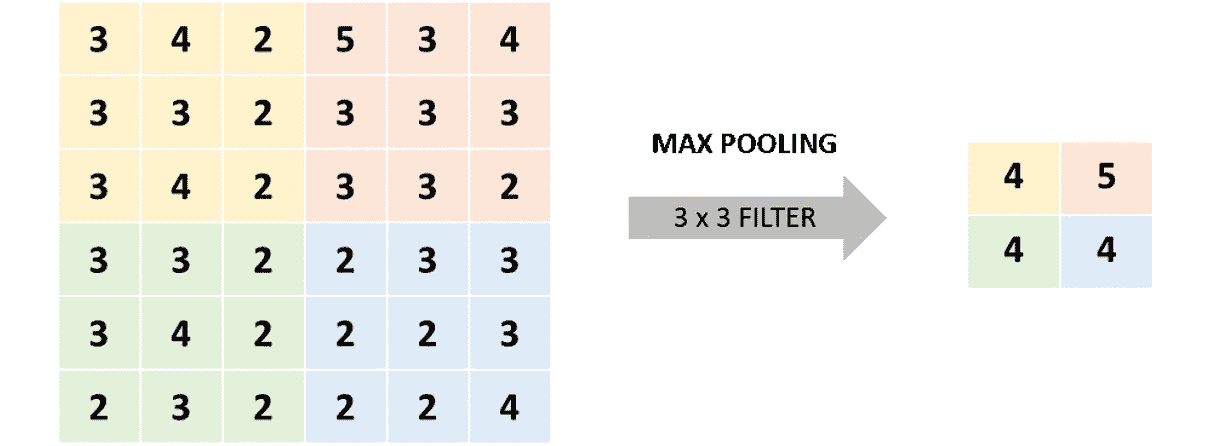
图 2.22:最大池化操作
在上图中,通过使用
3 x 3最大池化过滤器,可以实现右侧的结果。 在此,黄色部分(左上角)的最大数量为 4,而橙色部分(右上角)的最大数量为 5。平均池化:类似地,平均池操作采用矩阵的各个子部分,并将符合规则的数字作为输出,在这种情况下,该数字是所讨论的子部分中所有数字的平均值:
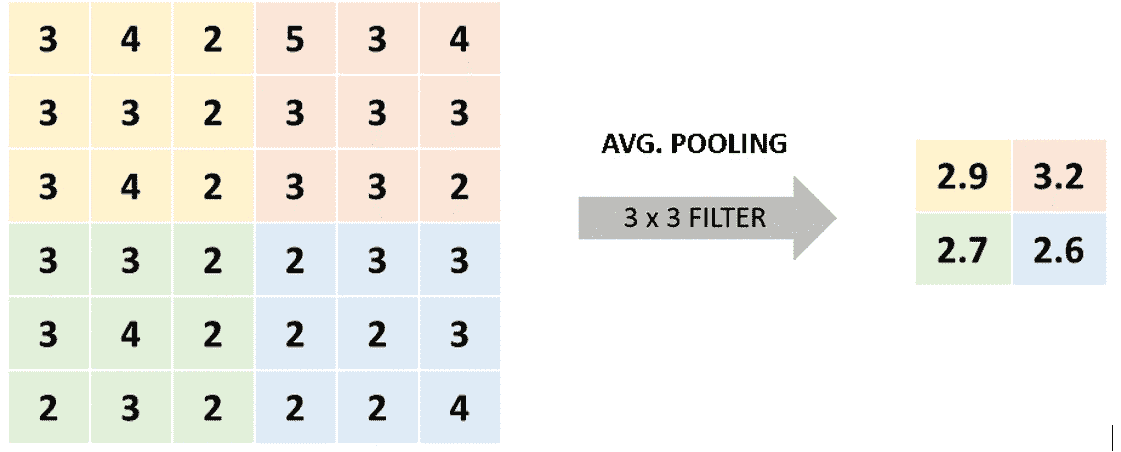
图 2.23:平均池化操作
在这里,使用
3 x 3过滤器,我们得到 2.9,这是黄色部分(左上角)中所有数字的平均值,而 3.2 是橙色部分(右上角)中所有数字的平均值。 。 -
全连接层:最后,考虑到如果网络仅能够检测一组特征而不具有将其分类为类标签的能力,则该网络将无用,最后 CNN 使用全连接层采取前一层检测到的特征(称为特征映射),并输出属于类别标签的那组特征的概率,用于进行最终预测。
像人工神经网络一样,全连接层使用感知器根据给定的输入来计算输出。 此外,至关重要的是要提到 CNN 在架构的末尾通常具有不止一个全连接层。
通过组合所有这些概念,可以获得 CNN 的常规架构。 每个类型可以有任意数量的层,每个卷积层可以具有任意数量的过滤器(每个过滤器用于特定任务)。 此外,池化层应具有与上一个卷积层相同数量的过滤器,如下图所示:
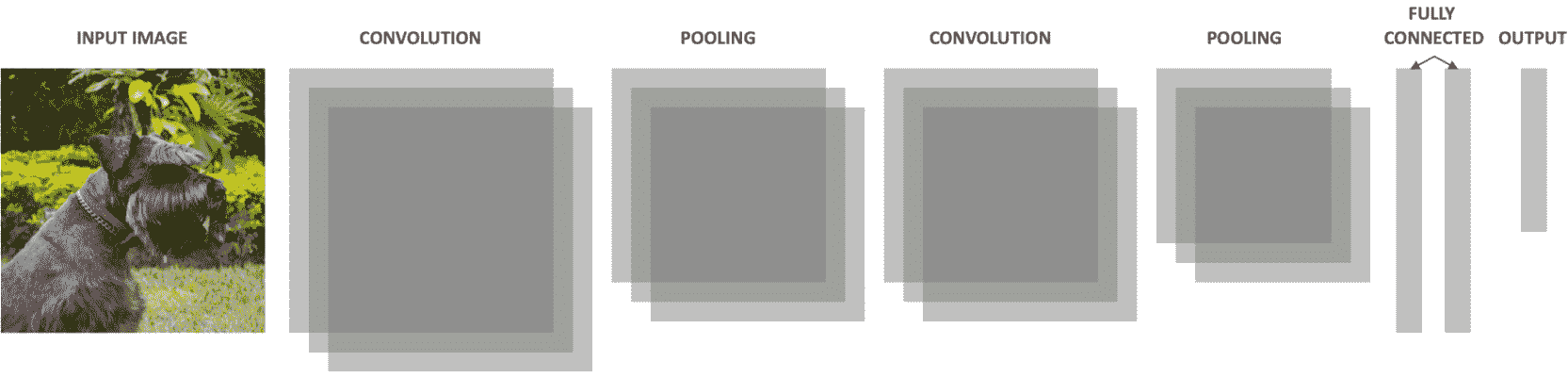
图 2.24:CNN 架构图
循环神经网络简介
前述神经网络(ANN 和 CNN)的主要局限性在于,它们只能通过考虑当前事件(正在处理的输入)来学习,而不会考虑先前或后续事件,因此考虑到我们人类并不这样思考,这是不便的。 例如,当阅读一本书时,通过考虑上一段或更多段中的上下文,您可以更好地理解每个句子。
因此,并考虑到神经网络旨在优化传统上由人类完成的多个过程这一事实,至关重要的是考虑一个能够考虑输入和输出序列的网络,因此循环神经网络(RNN)。 它们是一种强大的神经网络,可以通过使用内部存储器找到复杂数据问题的解决方案。
简而言之,这些网络中包含循环,即使在处理后续的一组信息时,这些循环也可以使信息在其内存中保留更长的时间。 这意味着 RNN 中的感知器不仅将输出传递到下一个感知器,而且还保留了一些信息给自己,这对于分析下一信息很有用。 这种内存保留功能使他们可以非常准确地预测下一步。
与其他网络类似,RNN 的学习过程尝试映射输入(x)和输出(y)之间的关系,不同之处在于这些模型还考虑了先前输入的全部或部分历史。
RNN 允许以输入序列,输出序列或什至同时以两种形式处理数据序列,如下图所示:
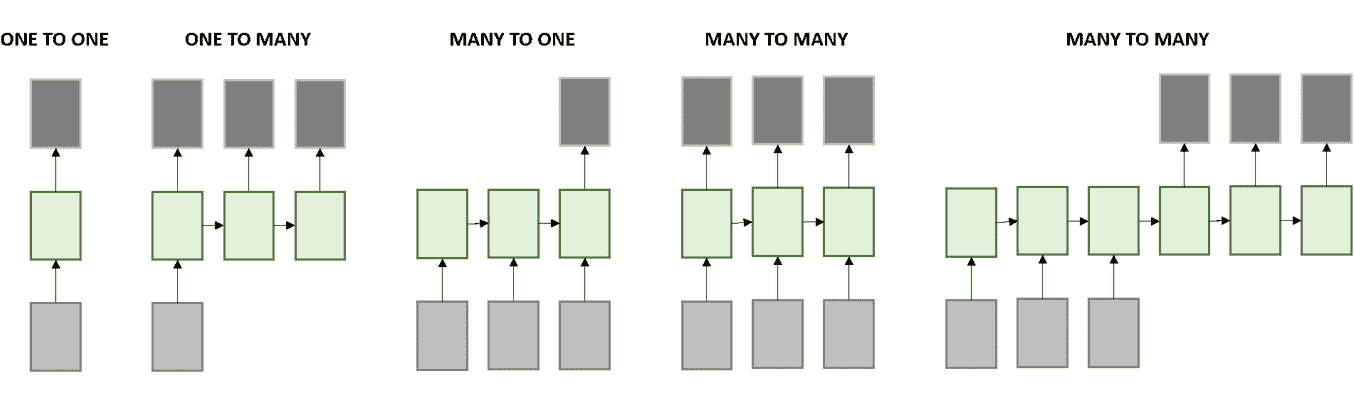
图 2.25:RNN 处理的数据序列
在此,每个框都是一个矩阵,箭头表示发生的函数。 底部的框是输入,顶部的框是输出,中间的框代表 RNN 在该点的状态,该状态保存网络的内存。
从左至右,上述各图可以解释如下:
- 一个不需要解决 RNN 的典型模型。 它具有固定的输入和固定的输出。 例如,这可以指图像分类。
- 该模型接受输入并产生一系列输出。 例如,以接收图像作为输入的模型; 输出应为图像标题。
- 与前面的模型相反,该模型采用一系列输入并产生单个结果。 在情感分析问题上可以看到这种类型的架构,其中输入是要分析的句子,输出是句子后面的预测情感。
- 最后的两个模型采用一系列输入,并返回一系列输出,不同之处在于第一个模型同时分析输入并生成输出。 例如,当视频的每个帧都被单独标记时。 另一方面,第二个多对多模型分析整个输入集,以生成输出集。 语言翻译就是一个例子,在进行实际翻译之前,需要先理解一种语言的整个句子。
数据准备
当然,在收集数据之后,开发任何深度学习模型的第一步都应该是准备数据。 如果我们希望了解手边的数据以正确地概述项目范围,那么这一点至关重要。
许多数据科学家没有这样做,这导致模型的表现很差,甚至导致模型无用,因为他们没有从一开始就回答数据问题。
数据准备过程可以分为三个主要任务:
- 了解数据并处理任何潜在问题
- 重新缩放特征,以确保不会因错误引入偏差
- 拆分数据以能够准确地衡量表现
所有这三个任务将在下一节中进一步说明。
注意
在应用任何机器学习算法时,考虑到它们指的是事先准备数据所需的技术,我们前面解释的所有任务几乎都是相同的。
处理混乱数据
该任务主要包括执行探索性数据分析(EDA),以了解可用数据,以及检测可能影响模型开发的潜在问题。
EDA 流程很有用,因为它有助于开发人员发现对于定义操作过程至关重要的信息。 此处说明此信息:
-
数据量:这既指实例数,也指特征数。 前者对于确定是否有必要甚至有可能使用神经网络甚至是深度神经网络解决数据问题至关重要,因为考虑到此类模型需要大量数据才能达到较高的准确率。 另一方面,后者对于确定是否提前开发某些特征选择方法以减少特征数量,简化模型并消除任何冗余信息是否有用是有用的。
-
目标特征:对于受监督的模型,需要标记数据。 考虑到这一点,选择目标特征(我们希望通过构建模型来实现的目标)以评估特征是否具有许多缺失值或离群值非常重要。 此外,这有助于确定开发目标,该目标应与可用数据一致。
-
噪音数据/异常值:噪音数据是指明显不正确的值,例如 200 岁的人。 另一方面,离群值所指的值虽然可能是正确的,但与平均值相差甚远,例如,一个 10 岁的大学生。
没有检测异常值的确切科学方法,但是有一些通常被接受的方法。 假设数据集呈正态分布,那么最受欢迎的数据集之一就是确定离平均值约 3-6 标准差的任何值。
识别异常值的一种同样有效的方法是选择第 99 个百分点和第 1 个百分点的值。
当此类值代表特征数据的 5% 以上时,处理此类值非常重要,因为不这样做可能会给模型带来偏差。 与其他任何机器学习算法一样,处理这些值的方法是使用均值或回归插补技术删除异常值或分配新值。
-
缺失值:类似于上述内容,考虑到不同的模型会对这些值做出不同的假设,因此具有许多缺失值的数据集会给模型带来偏差。 同样,当缺失值占特征值的 5% 以上时,应再次使用均值或回归插补技术,通过消除或替换它们来处理它们。
-
定性特征:最后,考虑到删除或编码数据可能会导致更准确的模型,因此检查数据集是否包含定性数据也是关键的一步。
此外,在许多研究开发中,对同一数据测试了几种算法,以确定哪种算法表现更好,并且其中某些算法不能容忍使用定性数据,就像神经网络一样。 这证明了转换或编码它们以便能够向所有算法提供相同数据的重要性。
练习 2.02:处理混乱数据
注意
本章中的所有练习都将使用从 UC Irvine 机器学习存储库获得的电器能耗预测数据集完成,该数据集可从这里下载。 也可以在本书的 GitHub 存储库中找到它。
电器能耗预测数据集包含 4.5 个月的数据,涉及低能耗建筑物中不同房间的温度和湿度测量,目的是预测某些电器使用的能耗。
在本练习中,我们将使用pandas(这是一个受欢迎的 Python 包)来探索手头的数据并学习如何检测缺失值,离群值和定性值。 执行以下步骤以完成本练习:
注意
对于本章中的练习和活动,您将需要在本地计算机上安装 Python 3.7,Jupyter 6.0,NumPy 1.17 和 Pandas 0.25。
-
打开 Jupyter 笔记本以实现此练习。
-
导入 Pandas 库:
import pandas as pd -
使用 Pandas 读取 CSV 文件,其中包含我们从 UC Irvine 机器学习存储库站点下载的数据集。
接下来,删除名为
date的列,因为我们不想在以下练习中考虑它:data = pd.read_csv("energydata_complete.csv") data = data.drop(columns=["date"])最后,打印
DataFrame的头部:data.head()输出应如下所示:
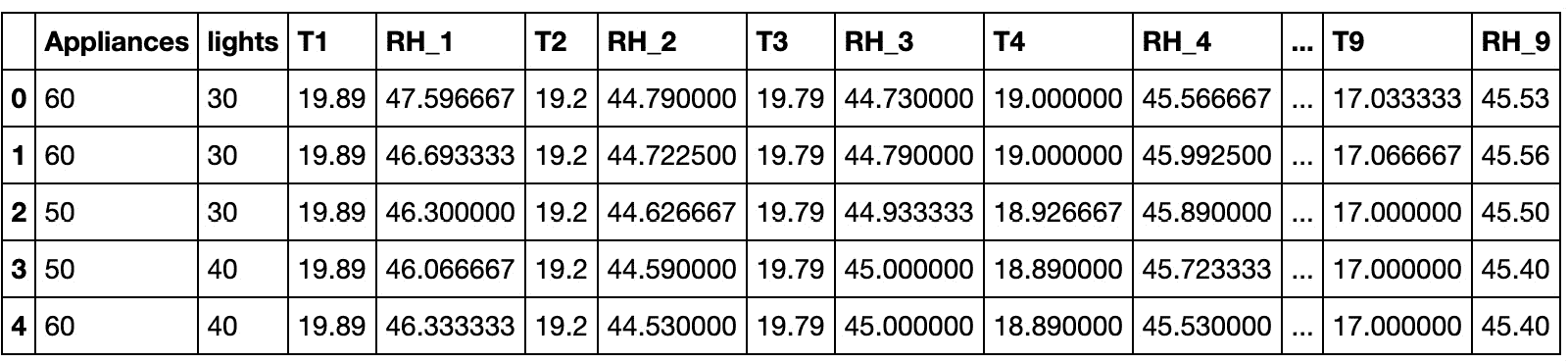
图 2.26:设备能源预测数据集的主要实例
-
检查数据集中的分类特征:
cols = data.columns num_cols = data._get_numeric_data().columns list(set(cols) - set(num_cols))第一行生成数据集中所有列的列表。 接下来,包含数值的列也存储在变量中。 最后,通过从整个列列表中减去数字列,可以获得非数字列。
结果列表为空,表示没有分类特征要处理。
-
使用 Python 的
isnull()和sum()函数来查找数据集各列中是否缺少任何值:data.isnull().sum()此命令计算每列中空值的数量。 对于正在使用的数据集,不应缺少任何值,如在此处所示:

图 2.27:缺失值计数
-
使用三个标准差作为度量来检测数据集中所有特征的离群值:
outliers = {} for i in range(data.shape[1]): min_t = data[data.columns[i]].mean() \ - (3 * data[data.columns[i]].std()) max_t = data[data.columns[i]].mean() \ + (3 * data[data.columns[i]].std()) count = 0 for j in data[data.columns[i]]: if j < min_t or j > max_t: count += 1 percentage = count / data.shape[0] outliers[data.columns[i]] = "%.3f" % percentage outliers前面的代码段循环遍历数据集中的列,以评估每个异常值的存在。 它会继续计算最小和最大阈值,以便可以计算超出阈值之间范围的实例数。
最后,它计算离群值的百分比(即离群值除以实例总数),以便输出显示每列此百分比的字典。
通过打印结果字典(离群值),可以显示数据集中所有特征(列)的列表以及离群值的百分比。 根据结果,可以得出结论,无需考虑异常值,因为考虑到它们仅占数据的 5%,如以下屏幕截图所示:
注意
请注意,只要将变量放在笔记本中单元格的末尾,Jupyter 笔记本便可以打印变量的值,而无需使用打印函数。 在任何其他编程平台或任何其他情况下,请确保使用打印函数。
例如,打印包含异常值的结果字典的等效方法(也是最佳实践)将使用
print语句,如下所示:print(outliers)。 这样,在不同的编程平台上运行时,代码将具有相同的输出。

图 2.28:离群参与每个特征
注意
要访问此特定部分的源代码,请参考这里。
您也可以通过这里在线运行此示例。 您必须执行整个笔记本才能获得所需的结果。
您已经成功浏览了数据集并处理了潜在问题。
数据缩放
尽管不需要重新缩放数据就可以将其馈送到算法中进行训练,但是如果您希望提高模型的准确率,这是重要的一步。 这主要是因为每个特征具有不同的比例可能会导致模型假定给定特征比其他特征更重要,因为它具有更高的数值。
以两个特征为例,一个特征测量一个人的孩子数量,另一个特征描述一个人的年龄。 即使年龄特征可能具有较高的数值,但在推荐学校的研究中,孩子特征的数目可能更为重要。
考虑到这一点,如果所有特征均等地缩放,则模型实际上可以赋予那些相对于目标特征最重要的特征更高的权重,而不是赋予它们具有的数值。 此外,它还可以消除模型从数据不变性中学习的需要,从而有助于加快训练过程。
有两种主要的重新缩放方法在数据科学家中很流行,尽管没有选择一个或另一个的规则,但重要的是要强调它们必须单独使用(一个或另一个)。
可以在这里找到这两种方法的简要说明:
- 规范化:这包括重新缩放值,以便所有特征的所有值都介于零和一之间。 使用以下公式完成此操作:
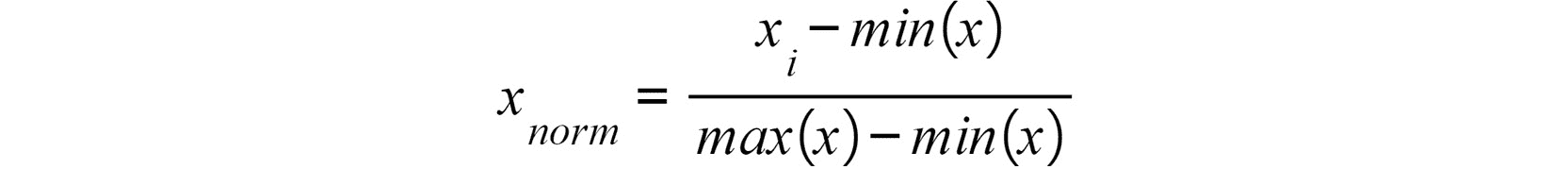
图 2.29:数据标准化
- 标准化:相反,此缩放方法将转换所有值,以使其平均值为 0 且其标准差等于 1。这可使用以下公式完成:
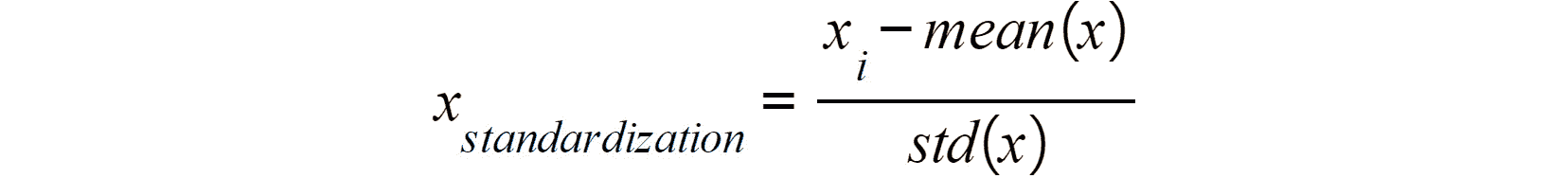
图 2.30:数据标准化
练习 2.03:重新缩放数据
在本练习中,我们将重新缩放上一练习中的数据。 请执行以下步骤:
注意
使用与上一练习相同的 Jupyter 笔记本。
-
将特征与目标分开。 我们这样做只是为了重新特征特征数据:
X = data.iloc[:, 1:] Y = data.iloc[:, 0]前面的代码片段获取数据并使用切片将特征与目标分离。
-
通过使用规范化方法重新缩放特征数据。 显示结果
DataFrame的标题(即前五个实例)以验证结果:X = (X - X.min()) / (X.max() - X.min()) X.head()输出应如下所示:
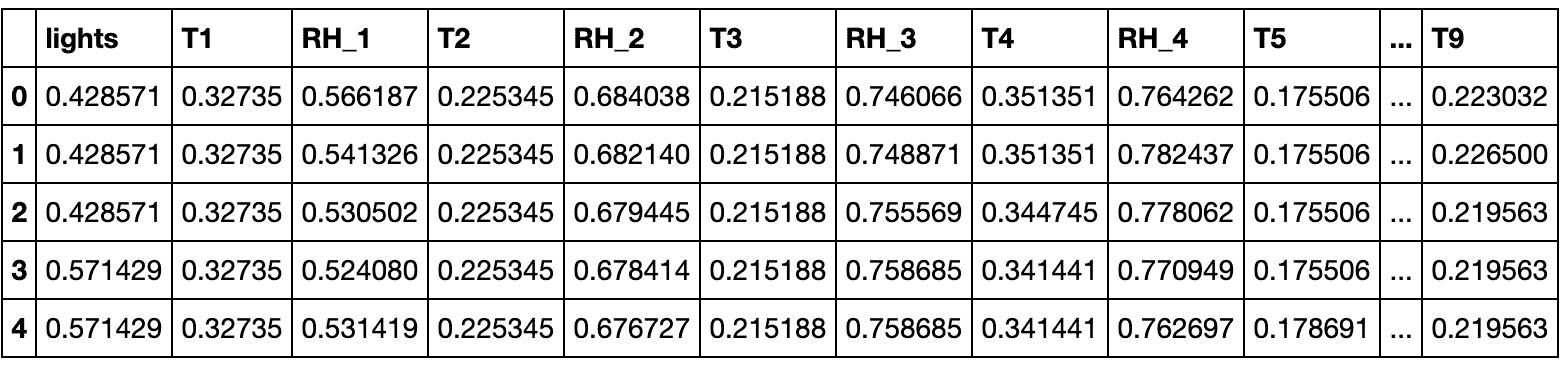
图 2.31:标准化设备能源预测数据集的主要实例
注意
要访问此特定部分的源代码,请参考这里。
您也可以通过这里在线运行此示例。 您必须执行整个笔记本才能获得所需的结果。
您已成功缩放数据集。
分割数据
将数据集分为三个子集的目的是,可以在不引入偏差的情况下对模型进行适当的训练,微调和测量。 这是每个集合的说明:
-
训练集:顾名思义,该集合被馈送到要训练的神经网络。 对于监督学习,它由特征和目标值组成。 如前所述,考虑到神经网络需要训练大量数据,通常这是三者中最大的集合。
-
验证集(开发集):该集主要用于测量模型的表现,以便对超参数进行调整以提高性能。 完成此微调过程是为了使我们可以配置能获得最佳结果的超参数。
尽管没有对模型进行数据训练,但模型会对模型产生间接影响,这就是为什么不应该对模型进行最终表现评估的原因,因为它可能是有偏差的度量。
-
测试集:该集对模型没有影响,这就是为什么它用于对看不见的数据进行模型的最终评估的原因,这成为模型在未来的数据集上的表现如何的指南。
考虑到每个数据问题都是不同的,并且开发深度学习解决方案通常需要反复试验的方法,因此没有理想的科学方法可以将数据分为上述三组。 尽管如此,众所周知,对于较大的数据集(数十万个实例),每个集合的分割比例应为 98:1:1,因为对于训练集使用尽可能多的数据至关重要。 对于较小的数据集,常规拆分比率为 60:20:20。
练习 2.04:拆分数据集
在本练习中,我们将前一练习的数据集分为三个子集。 为了学习的目的,我们将探索两种不同的方法。 首先,将使用索引分割数据集。 接下来,将 scikit-learn 的train_test_split()函数用于相同的目的,从而通过两种方法获得相同的结果。 执行以下步骤以完成本练习:
注意
使用与上一练习相同的 Jupyter 笔记本。
-
打印数据集的形状,以确定要使用的拆分比率:
shape此操作的输出应为
(19735, 27)。 这意味着可以使用 60:20:20 的分配比例进行训练,验证和测试。 -
获取将用作训练和验证集上限的值。 这将用于通过索引拆分数据集:
train_end = int(len(X) * 0.6) dev_end = int(len(X) * 0.8)前面的代码确定将用于通过切片划分数据集的实例的索引。
-
打乱数据集:
X_shuffle = X.sample(frac=1, random_state=0) Y_shuffle = Y.sample(frac=1, random_state=0)使用 Pandas
sample函数,可以对特征和目标矩阵中的元素进行混洗。 通过将frac设置为 1,我们确保所有实例都经过打乱并在函数的输出中返回。 使用random_state参数,我们确保两个数据集均被混洗。 -
使用索引将经过打乱的数据集分为特征和目标数据这三组:
x_train = X_shuffle.iloc[:train_end,:] y_train = Y_shuffle.iloc[:train_end] x_dev = X_shuffle.iloc[train_end:dev_end,:] y_dev = Y_shuffle.iloc[train_end:dev_end] x_test = X_shuffle.iloc[dev_end:,:] y_test = Y_shuffle.iloc[dev_end:] -
打印所有三组的形状:
print(x_train.shape, y_train.shape) print(x_dev.shape, y_dev.shape) print(x_test.shape, y_test.shape)以上操作的结果应为:
(11841, 27) (11841,) (3947, 27) (3947,) (3947, 27) (3947,) -
从 scikit-learn 的
model_selection模块导入train_test_split()函数:from sklearn.model_selection import train_test_split注意
尽管根据实际学习的需要导入了不同的包和库,但是在代码开始时导入它们始终是一种好习惯。
-
拆分打乱后的数据集:
x_new, x_test_2, \ y_new, y_test_2 = train_test_split(X_shuffle, Y_shuffle, \ test_size=0.2, \ random_state=0) dev_per = x_test_2.shape[0]/x_new.shape[0] x_train_2, x_dev_2, \ y_train_2, y_dev_2 = train_test_split(x_new, y_new, \ test_size=dev_per, \ random_state=0)代码的第一行执行初始拆分。 该函数将以下内容作为参数:
X_shuffle,Y_shuffle:要拆分的数据集,即特征数据集,以及目标数据集(也称为X和Y)test_size:测试集中要包含的实例的百分比random_state:用于确保结果的可重复性此行代码的结果是将每个数据集(
X和Y)分为两个子集。要创建其他集(验证集),我们将执行第二次拆分。 前面代码的第二行负责确定要用于第二个拆分的
test_size,以便测试集和验证集具有相同的形状。最后,代码的最后一行使用先前计算为
test_size的值执行第二次拆分。 -
打印所有三组的形状:
print(x_train_2.shape, y_train_2.shape) print(x_dev_2.shape, y_dev_2.shape) print(x_test_2.shape, y_test_2.shape)以上操作的结果应为:
(11841, 27) (11841,) (3947, 27) (3947,) (3947, 27) (3947,)我们可以看到,两种方法的结果集具有相同的形状。 使用一种方法还是另一种方法是优先考虑的问题。
注意
要访问此特定部分的源代码,请参考这里。
您也可以通过这里在线运行此示例。 您必须执行整个笔记本才能获得所需的结果。
您已成功将数据集分为三个子集。
无法准备数据的缺点
尽管准备数据集的过程很耗时,并且在处理大型数据集时可能很累,但这样做的缺点更加不便:
- 较长的训练时间:包含噪声,缺失值以及冗余或无关列的数据需要花费相当长的时间来训练,并且在大多数情况下,此时间延迟甚至比准备数据所需的时间更长。 例如,在数据准备期间,可以确定五列与该研究目的无关,这可能会大大减少数据集,从而大大减少训练时间。
- 偏差的引入:未清理的数据通常包含错误或缺失值,可能会使模型偏离真实情况。 例如,缺少值可能会导致模型做出不正确的推断,进而导致创建不代表数据的模型。
- 避免泛化:异常值和嘈杂的值会阻止模型对数据进行泛化,这对于构建代表当前训练数据以及未来看不见的数据的模型至关重要。 例如,包含年龄变量的数据集包含 100 岁以上人群的条目,则可能会导致模型说明那些实际上只代表人口很小一部分的用户。
活动 2.01:执行数据准备
在本活动中,我们将准备一个数据集,其中包含歌曲列表,每首歌曲具有几个有助于确定其发行年份的属性。 数据准备步骤对于本章的下一个活动至关重要。 让我们看一下以下情况。
您在一家音乐唱片公司工作,您的老板想揭示表示不同时间段唱片的细节,这就是为什么他们汇总了一个包含 515,345 条唱片的数据的数据集,发布年份从 1922 年到 2011 年。 要求您准备数据集,以便准备将其馈送到神经网络。 执行以下步骤以完成此活动:
注意
要下载此活动的数据集,请访问以下 UC Irvine 机器学习存储库 URL。
引用:Dua, D. and Graff, C. (2019). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
-
导入所需的库。
-
使用 Pandas,加载
.csv文件。 -
验证数据集中是否存在任何定性数据。
-
检查缺失值。
您还可以添加一个附加的
sum()函数,以获取整个数据集中的缺失值之和,而无需按列进行区分。 -
检查异常值。
-
将特征与目标数据分开。
-
使用标准化方法重新缩放数据。
-
将数据分为三组:训练,验证和测试。 使用您喜欢的任何一种方法。
注意
有关此活动的解决方案,请参阅第 239 页。
构建深度神经网络
一般而言,可以使用 scikit-learn(不适用于深度学习)之类的库在非常简单的级别上构建神经网络,该库可以为您执行所有数学运算而没有很大的灵活性,或者在非常复杂的级别上,通过从头开始编码训练过程的每个步骤,或使用更强大的框架,可以提供极大的灵活性。
PyTorch 的构建考虑了该领域许多开发人员的意见,其优点是可以将两个近似值放在同一位置。 正如我们前面提到的,它具有一个神经网络模块,该模块被构建为允许使用顺序容器对简单架构进行简单的预定义实现,同时允许创建自定义模块,从而为构建非常复杂的架构的过程引入灵活性 。
在本节中,我们将讨论使用顺序容器开发深度神经网络,以揭开其复杂性。 不过,在本书的后续章节中,我们将继续研究更复杂和抽象的应用,而这些应用也可以非常轻松地实现。
正如我们前面提到的,顺序容器是一个模块,它被构建为包含遵循顺序的模块序列。 它包含的每个模块都将对给定的输入进行一些计算以得出结果。
可以在顺序容器中使用一些最流行的模块(层)来开发常规分类模型,在这里进行了解释:
注意
在随后的章节中将解释用于其他类型的架构(例如 CNN 和 RNN)的模块。
-
线性层:这将线性变换应用于输入数据,同时保持内部张量来容纳权重和偏差。 它接收输入样本的大小(数据集的特征数量或上一层的输出数量),输出样本的大小(当前层中的单元数量,即输出数量) ),以及是否在训练过程中使用偏差张量(默认设置为
True)作为参数。 -
激活函数:它们接收线性层的输出作为输入,以破坏线性。 如前所述,有几个激活函数可以添加到顺序容器中。 最常用的解释如下:
ReLU:这将校正后的线性单元函数应用于包含输入数据的张量。 它接受的唯一参数是是否应在原位进行操作,默认情况下将其设置为
False。Tanh:这会将基于元素的 tanh 函数应用于包含输入数据的张量。 它不需要任何参数。
Sigmoid:这将前面解释的 Sigmoid 函数应用于包含输入数据的张量。 它不需要任何参数。
Softmax:将 softmax 函数应用于包含输入数据的 n 维张量。 重新缩放输出,以使张量的元素位于零与一之间的范围内,并且总和为一。 它采用应沿着其计算 softmax 函数的维度作为参数。
-
丢弃层:此模块根据设置的概率将输入张量的某些元素随机归零。 它使用概率进行随机选择,以及是否应在原位进行操作,默认情况下将其设置为
False作为参数。 该技术通常用于处理过拟合模型,稍后将对其进行详细说明。 -
规范化层:可以使用不同的方法在顺序容器中添加规范化层。 其中一些包括
BatchNorm1d,BatchNorm2d和BatchNorm3d。 其背后的想法是对来自上一层的输出进行归一化,最终在较短的训练时间上达到相似的精度水平。
练习 2.05:使用 PyTorch 构建深度神经网络
在本练习中,我们将使用 PyTorch 库定义四层深度神经网络的架构,然后将使用我们在先前练习中准备的数据集对其进行训练。 请执行以下步骤:
注意
使用与上一练习相同的 Jupyter 笔记本。
-
从 PyTorch 导入名为
torch的 PyTorch 库,以及nn模块。import torch import torch.nn as nn注意
此练习中使用了
torch.manual_seed(0),以确保在本书的 GitHub 存储库中获得的结果具有可重复性。 -
对于我们在上一个练习中创建的每个集合,将特征列与目标分开。 此外,将最终的
DataFrame转换为张量:x_train = torch.tensor(x_train.values).float() y_train = torch.tensor(y_train.values).float() x_dev = torch.tensor(x_dev.values).float() y_dev = torch.tensor(y_dev.values).float() x_test = torch.tensor(x_test.values).float() y_test = torch.tensor(y_test.values).float() -
使用
sequential()容器定义网络架构。 确保创建四层网络。 考虑到我们正在处理回归问题,请在前三层使用 ReLU 激活函数,而在最后一层不使用激活函数。每层的单元数应为 100、50、25 和 1:
model = nn.Sequential(nn.Linear(x_train.shape[1], 100), \ nn.ReLU(), \ nn.Linear(100, 50), \ nn.ReLU(), \ nn.Linear(50, 25), \ nn.ReLU(), \ nn.Linear(25, 1)) -
将损失函数定义为 MSE:
loss_function = torch.nn.MSELoss() -
将优化器算法定义为 Adam 优化器:
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) -
使用
for循环在训练数据上训练 1,000 个迭代步骤来训练网络:for i in range(1000): y_pred = model(x_train).squeeze() loss = loss_function(y_pred, y_train) optimizer.zero_grad() loss.backward() optimizer.step() if i%100 == 0: print(i, loss.item())注意
squeeze()函数用于删除y_pred的附加尺寸,该尺寸已从大小[3000,1]转换为[3000]。考虑到
y_train是一维的,并且两个张量都必须具有相同的维数才能馈送到损失函数,这一点至关重要。运行前面的代码片段将产生类似于以下内容的输出:

图 2.32:不同迭代步骤的损失值
可以看出,损失值随时间连续减小。
-
为了测试模型,对测试集的第一个实例进行预测,并与真实情况(目标值)进行比较。
pred = model(x_test[0]) print("Ground truth:", y_test[0].item(), \ "Prediction:",pred.item())输出应类似于以下内容:
Ground truth: 60.0 Prediction: 69.5818099975586如您所见,真实情况值(
60)非常接近预测值(69.58)。注意
要访问此特定部分的源代码,请参考这里。
您也可以通过这里在线运行此示例。 您必须执行整个笔记本才能获得所需的结果。
您已经成功创建并训练了一个深度神经网络来解决回归问题。
练习 2.02:开发回归问题的深度学习解决方案
在本活动中,我们将创建并训练一个神经网络来解决我们在上一活动中提到的回归问题。 让我们看一下场景。
您继续在唱片公司工作,在看到您准备好数据集的出色工作后,您的老板已经信任您定义网络架构以及使用准备好的数据集进行训练的任务。 执行以下步骤以完成此活动:
注意
使用与上一活动相同的 Jupyter 笔记本。
- 导入所需的库。
- 从目标中为我们在上一个活动中创建的所有三组数据拆分函数。 将
DataFrame转换为张量。 - 定义网络的架构。 随意尝试层数和每层单元数的不同组合。
- 定义损失函数和优化器算法。
- 使用循环对训练网络进行 3,000 个迭代步骤。
- 通过对测试集的第一个实例执行预测并将其与基本事实进行比较来测试模型。
您的输出应类似于以下内容:
Ground truth: 1995.0 Prediction: 1998.0279541015625
注意
有关此活动的解决方案,请参见第 242 页。
总结
产生神经网络的理论是由弗兰克·罗森布拉特(Frank Rosenblatt)于几十年前提出的。 它始于感知器的定义,感知器是受人类神经元启发的单元,其将数据作为输入以对其进行转换。 感知器背后的理论包括将权重分配给输入数据以执行计算,以便最终结果取决于结果而为一件事或另一件事。
神经网络最广为人知的形式是由一系列感知器创建的神经网络,这些感知器分层堆叠在一起,其中一列感知器(层)的输出是下一个感知器的输入。
解释了神经网络的典型学习过程。 在此,需要考虑三个主要过程:前向传播,损失函数的计算和反向传播。
该过程的最终目标是通过更新网络每个神经元中每个输入值所伴随的权重和偏差来最小化损失函数。 这可以通过迭代过程来实现,该过程可能要花费几分钟,几小时甚至几周的时间,具体取决于数据问题的性质。
还讨论了三种主要类型的神经网络的主要架构:人工神经网络,卷积神经网络和循环神经网络。 第一个用于解决传统的分类或回归问题,第二个由于具有解决计算机视觉问题(例如图像分类)的能力而广受欢迎,第三个可按顺序处理数据,用于语言翻译等任务。
在下一章中,将讨论解决回归问题和分类数据问题之间的主要区别。 您还将学习如何解决分类数据问题,以及如何改善其表现以及如何部署模型。
三、使用 DNN 的分类问题
概述
在本章中,我们将看一个银行业中的实际例子,以解决分类数据问题。 您将学习如何利用 PyTorch 的自定义模块来定义网络架构并训练模型。 您还将探索误差分析的概念,以提高模型的表现。 最后,您将研究部署模型的不同方法,以便将来使用它。 到本章结束时,您将对该过程有深刻的了解,以便可以使用深度神经网络(DNN)在 PyTorch 中。
简介
在上一章中,我们了解了 DNN 的构建块,并回顾了三种最常见的架构的特征。 此外,我们学习了如何使用 DNN 解决回归问题。
在本章中,我们将使用 DNN 解决分类任务,其目的是从一系列选项中预测结果。
利用这种模型的一个领域是银行业务。 这主要是由于他们需要根据人口统计数据预测未来的行为,以及确保长期盈利的主要目标。 银行业的一些用途包括评估贷款申请,信用卡批准,预测股票市场价格以及通过分析行为来检测欺诈。
本章将重点介绍使用深层人工神经网络(ANN)解决分类库问题的步骤,并遵循建立有效模型所需的所有步骤:数据探索,数据准备, 架构定义和模型训练,模型微调,误差分析,以及最后部署最终模型。
注意
问题定义
定义问题与建立模型或提高准确率一样重要。 这是因为,虽然您可以使用最强大的算法并使用最先进的方法来改善其结果,但是如果您解决错误的问题或使用错误的数据,这可能毫无意义。
至关重要的是,学习如何深入思考以了解可以做什么和不能做什么以及如何可以完成。 考虑到当我们在学习应用机器学习或深度学习算法时,大多数课程中出现的问题总是清晰定义的,因此除训练模型和提高其表现外无需进行进一步分析,这一点尤其重要。 另一方面,在现实生活中,问题常常令人困惑,数据经常混乱。
在本节中,您将学习一些根据组织的需求和手头的数据来定义问题的最佳实践。
为此,您需要遵循的步骤如下:
- 了解问题的原因,原因和方式。
- 分析手头的数据,以确定我们模型的一些关键参数,例如要执行的学习任务的类型,必要的准备工作以及表现指标的定义。
- 执行数据准备,以减少将偏差引入模型的可能性。
银行的深度学习
银行和金融实体每天处理大量信息,这是必需的,以便它们可以做出至关重要的决定,这些决定不仅影响其组织的未来,而且影响数百万信任它们的个人的未来。
这些决定每秒钟做出一次,早在 1990 年代,银行部门的人们就过去依靠专家系统来编写基于规则的程序。 也就是说,基于人类专家知识的程序要制定一套要遵循的规则。 不足为奇的是,这样的程序不足,因为它们要求对所有信息或可能的情况进行预先编程,这使得它们无法有效应对不确定性和瞬息万变的市场。
随着技术的进步,银行业一直在向更专业的系统过渡,这些系统利用统计模型来帮助做出此类决策。 此外,由于银行既要考虑自身的盈利能力,也要考虑客户的盈利能力,因此在不断追随技术进步的众多行业中,银行被认为是杰出的。
如今,随着医疗保健市场的发展,银行和金融业正在驱动神经网络的市场。 这主要是由于神经网络具有通过使用大量先前数据来预测未来行为来处理不确定性的能力。 考虑到人脑无法分析如此大量的数据,这是基于专家知识的人类系统无法实现的。
此处简要介绍并解释了使用深度学习的银行和金融服务中的某些领域:
-
贷款申请评估:银行根据不同的因素(包括人口统计信息,信用记录等)向客户发放贷款。 他们在此过程中的主要目标是最大程度地减少将拖欠贷款的客户数量(使失败率最小),从而使通过已发行贷款获得的回报最大化。
神经网络用于帮助决定是否授予贷款。 通常使用以前未偿还贷款的贷款人以及按时偿还贷款的人的数据对他们进行训练。 创建模型后,想法是将新申请人的数据输入模型中,以便预测他们是否会偿还贷款,考虑到模型的重点应该是减少假正例的数量(模型预测的客户会拖欠贷款,但实际上没有)。
在行业中,已知神经网络的故障率低于依靠人类专业知识的传统方法。
-
欺诈检测:欺诈检测对于银行和金融服务提供商至关重要,考虑到技术的进步,尽管使我们的生活更轻松,但也使我们面临更大的金融风险。
在该域中,特别是 CNN,使用神经网络进行字符和图像识别,以检测字符图像中的隐藏和抽象图案,以确定用户是否遭受欺诈。
-
信用卡客户选择:为了长期保持盈利,信用卡提供商需要找到合适的客户。 例如,将信用卡批准给信用卡需求有限的客户(即不会使用的客户)将导致信用卡收入较低。
另一方面,信用卡发行商也有兴趣预测客户是否会拖欠下一次付款。 这将帮助发卡机构提前知道将拖欠的资金数量,以便他们进行准备,以保持盈利。
使用持有一张或几张信用卡的客户的历史数据来训练网络。 目标是创建能够确定新客户是否会充分利用信用卡,从而使收入取代成本的模型,以及能够预测付款行为的模型。
注意
本章其余部分将重点解决与信用卡使用有关的数据问题。 要下载将要使用的数据集,请转到这里,单击数据文件夹链接,然后下载
.xls文件。 该数据集也可在本书的 GitHub 存储库中找到。
探索数据集
在以下各节中,我们将重点关注使用信用卡客户默认值(DCCC)数据集解决与信用卡付款有关的分类任务,该数据集先前是从 UC Irvine 储存库站点下载的。
本节的主要思想是清楚说明数据问题的内容,原因和方式,这将有助于确定研究目的和评估指标。 此外,我们将详细分析手头的数据,以识别数据准备过程中所需的一些步骤(例如,将定性特征转换为其数值表示形式)。
首先,让我们定义什么,为什么以及如何。 考虑到应该这样做以确定组织的实际需求:
内容:建立一个模型,该模型能够确定客户是否会拖欠即将到来的付款。
意义:能够预测下个月要收到的付款金额(以货币为单位)。 这将帮助公司确定该月的支出策略,并允许他们定义要与每个客户一起执行的操作,既可以确保将要付款的客户将来的付款,也可以提高将要付款的客户的付款可能性。 默认。
方式:使用历史数据包含人口统计信息,信用历史记录以及有或没有拖欠付款的客户以前的账单,以训练模型。 在对输入数据进行训练之后,该模型应该能够确定客户是否可能拖欠下一次付款。
考虑到这一点,似乎目标函数应该是说明客户是否会在下次付款时违约,这将导致二进制结果(是/否)。 这意味着要开发的学习任务是分类任务,因此损失函数应该能够测量这种学习类型的差异(例如,交叉熵函数,如上一章所述)。 。
明确定义问题后,您需要确定最终模型的优先级。 这意味着确定所有输出类别是否同样重要。 例如,建立模型的时候,测量肺部肿块是否恶变的模型应主要集中在使假负例最小化(模型预测为无恶性肿块,但实际上是恶性的患者)上。 识别手写字符不应只关注一个特定的字符,而应最大化其在平等地识别所有字符方面的表现。
考虑到这一点以及“意义”语句中的解释,信用卡客户默认数据集的模型优先级应该是在不优先考虑任何类别标签的情况下最大化模型的整体表现 。 这主要是因为“为什么”声明宣称研究的主要目的应该是更好地了解银行将要收到的资金,并对可能拖欠付款的客户采取某些措施(例如,提供将债务分成较小的付款),以及针对那些不会违约的人采取不同的行动(例如,提供优惠作为对行为良好的客户的奖励)。
据此,本案例研究中使用的表现指标是准确率,其重点是使正确分类的实例最大化。 这是指任何类别标签正确分类的实例与实例总数的比率。
下表简要说明了数据集中存在的每个特征,这些特征可以帮助确定它们与研究目的的相关性,并确定一些需要执行的准备任务:
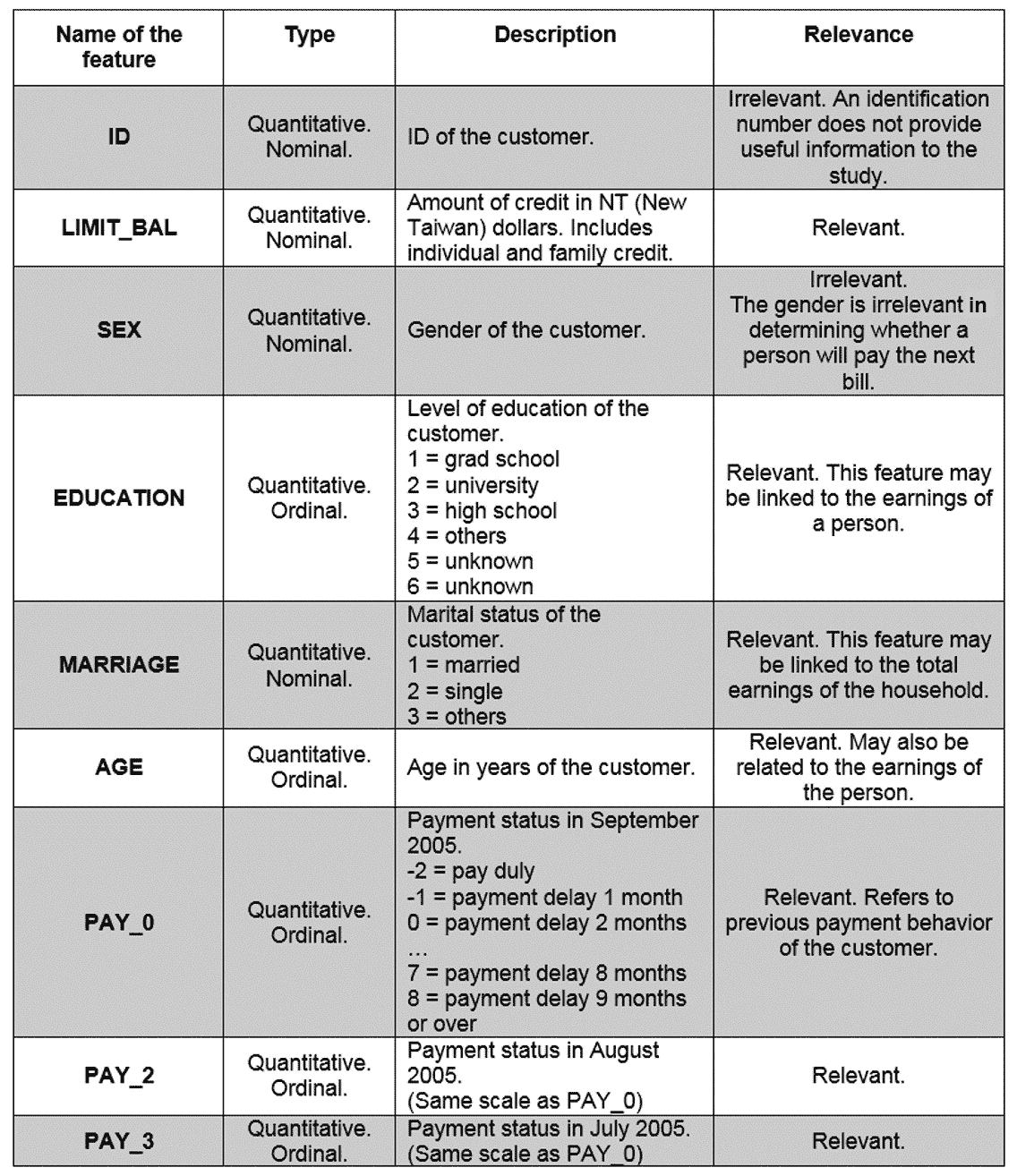
图 3.1:DCCC 数据集中的特征描述

图 3.2:DCCC 数据集中的特征描述(续)
考虑到此信息,可以得出结论,在 25 个特征(包括目标特征)中,有 2 个需要从数据集中删除,因为它们与研究目的无关。 请记住,与这项研究无关的特征可能与其他研究有关。 例如,一项有关私密卫生产品的研究可能认为性别特征是相关的。
此外,所有特征都是定量的,这意味着无需转换其值。 我们需要做的就是调整它们的规模。 目标特征也已转换为其数字表示形式,其中下一笔付款违约的客户用 1 表示,而未下一笔付款的客户用 0 表示。
数据准备
尽管在这方面有一些良好的做法,但是并没有固定的一组步骤来准备(预处理)数据集以开发深度学习解决方案,并且在大多数情况下,要采取的步骤取决于现有数据,要使用的算法以及研究的其他特征。
注意
准备 DCCC 数据集的过程将在本节中进行处理,并附带简要说明。 考虑到它将是后续活动的起点,请随时打开 Jupyter 笔记本并复制此过程。
但是,在开始训练模型之前,必须处理一些关键方面。 您已经从上一章中了解了其中的大多数内容,这些内容将应用于当前数据集,并在目标特征中添加了类不平衡的修订:
-
看看数据:使用 Pandas 读取数据集后,打印数据集的标题。 这有助于确保已加载正确的数据集。 此外,它还提供了准备后转换数据集的证据。
注意
为了能够使用 Pandas 读取 Excel 文件,请确保已在计算机或虚拟环境上安装了
xlrd。 要安装xlrd,您需要在 Anaconda 提示符下运行conda install -c anaconda xlrd。以下是用于使用 Pandas 读取 Excel 文件并打印出数据集标题的代码段:
import pandas as pd data = pd.read_excel("default of credit card clients.xls", \ skiprows=1) data.head()我们使用
skipline参数删除 Excel 文件的第一行,该行无关,因为它包含第二组标题。执行代码后,将获得以下结果:
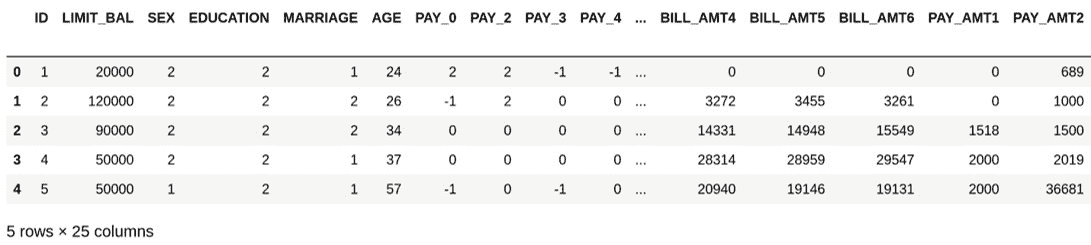
图 3.3:DCCC 数据集的标题
数据集的形状为 30,000 行 25 列,可以使用以下代码行获得:
print("rows:",data.shape[0]," columns:", data.shape[1])
-
删除不相关的特征:通过对每个特征进行分析,可以确定应从数据集中删除两个特征,因为它们与研究目的无关:
data_clean = data.drop(columns=["ID", "SEX"]) data_clean.head()结果数据集应包含 23 列,而不是原始的 25 列,如以下屏幕截图所示:
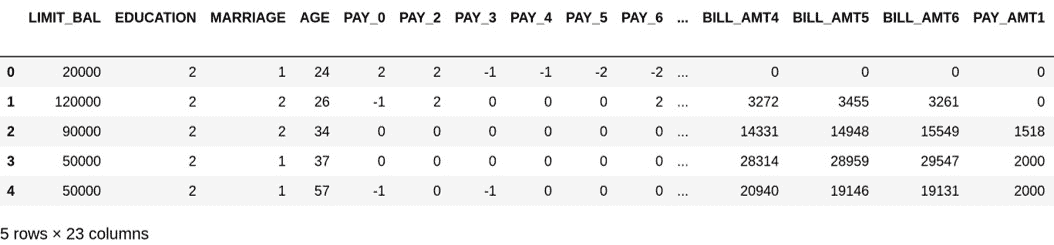
图 3.4:删除无关特征后的 DCCC 数据集的标题
-
检查缺失值:接下来,是时候检查数据集是否缺失任何值,如果是,则计算它们代表每个特征的百分比,这可以使用以下代码行完成 :
total = data_clean.isnull().sum() percent = (data_clean.isnull().sum()\ /data_clean.isnull().count()*100) pd.concat([total, percent], axis=1, \ keys=['Total', 'Percent']).transpose()第一行对数据集的每个特征执行缺失值的总和。 接下来,我们计算每个特征缺失值的参与度。 最后,我们将先前计算的两个值连接起来,并将结果显示在表中。 结果如下:

图 3.5:DCCC 数据集中的缺失值计数
根据这些结果,可以说数据集没有丢失任何值,因此这里不需要采取进一步的措施。
-
检查异常值:正如我们在“第 2 章”,“神经网络的构建块”中提到的,有几种方法可以检查异常值。 但是,在本书中,我们将坚持使用标准差方法,将偏离均值三个标准差的值视为离群值。 使用以下代码,可以从每个特征中识别离群值,并计算它们在整个值集中所占的比例:
outliers = {} for i in range(data_clean.shape[1]): min_t = data_clean[data_clean.columns[i]].mean() \ - (3 * data_clean[data_clean.columns[i]].std()) max_t = data_clean[data_clean.columns[i]].mean() \ + (3 * data_clean[data_clean.columns[i]].std()) count = 0 for j in data_clean[data_clean.columns[i]]: if j < min_t or j > max_t: count += 1 percentage = count/data_clean.shape[0] outliers[data_clean.columns[i]] = "%.3f" % percentage print(outliers)这将导致一个字典,其中包含每个特征名称作为键,并且该值表示该特征离群值的比例。 从这些结果中,可以观察到包含更多异常值的特征是
BILL_AMT1和BILL_AMT4,它们各自占总数的 2.3%。这意味着,鉴于异常值对每个特征的参与度太低,因此不需要采取进一步的措施,因此它们不太可能对最终模型产生影响。
-
检查类不平衡:当目标特征中的类标签未均等表示时,发生类不平衡; 例如,一个数据集包含 90% 的未拖欠下次付款的客户,而 10% 的客户未拖欠下一次付款,则被认为是不平衡的。
有几种处理类不平衡的方法,其中一些方法在这里说明:
收集更多数据:尽管这并非总是可用的途径,但它可能有助于平衡类或允许删除过度代表的类而不会严重减少数据集。
更改表现指标:某些指标(例如准确率)不适用于测量不平衡数据集的表现。 反过来,建议使用诸如精度或召回分类问题之类的指标来衡量表现。
重采样数据集:这需要修改数据集以平衡类。 可以通过两种不同的方式来完成此操作:在代表性不足的类中添加实例的副本(称为过采样),或删除代表性不足的类的实例(称为欠采样)。
可以通过简单地计算
target属性中每个类的出现来检测类不平衡,如下所示:target = data_clean["default payment next month"] yes = target[target == 1].count() no = target[target == 0].count() print("yes %: " + str(yes/len(target)*100) + " - no %: " \ + str(no/len(target)*100))根据前面的代码,可以得出结论,拖欠付款的客户数量占数据集的 22.12%。 这些结果也可以使用以下代码行显示在绘图中:
import matplotlib.pyplot as plt fig, ax = plt.subplots(figsize=(10,5)) plt.bar("yes", yes) plt.bar("no", no) ax.set_yticks([yes,no]) plt.xticks(fontsize=15) plt.yticks(fontsize=15) plt.show()结果如下图:
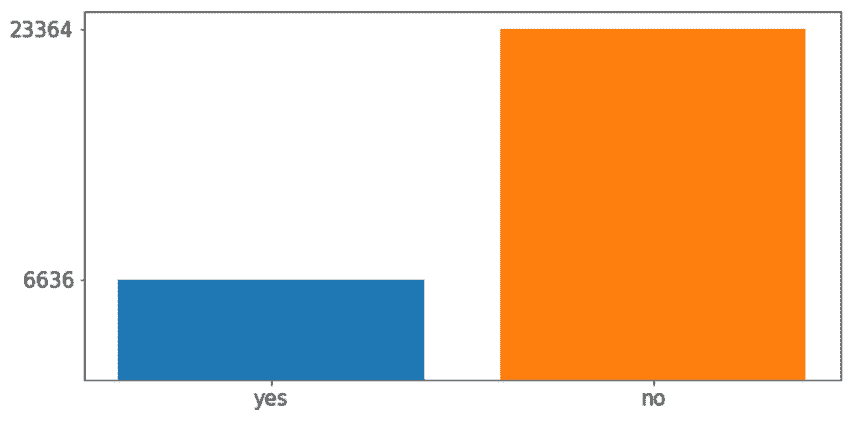
图 3.6:目标特征的类数
为了解决此问题,并且鉴于没有更多数据要添加并且表现指标实际上是准确率的事实,有必要执行数据重采样。
以下是对数据集执行过采样的代码片段,随机创建了代表性不足的类的重复行:
```py
data_yes = data_clean[data_clean["default payment next month"] == 1]
data_no = data_clean[data_clean["default payment next month"] == 0]
over_sampling = data_yes.sample(no, replace=True, \
random_state = 0)
data_resampled = pd.concat([data_no, over_sampling], \
axis=0)
```
首先,我们将每个类标签的数据分成独立的DataFrame。 接下来,我们使用 Pandas 的sample()函数来构造一个新的DataFrame,其中包含的重复表示实例数与过量表示的实例数据帧一样多。
注意
请记住, sample()函数的第一个参数(no)是指先前计算的过分代表类中的项目数。
最后, concat()函数用于连接过度代表的类的DataFrame和大小相同的新创建的DataFrame,以便创建要在后续步骤中使用的最终数据集。
使用新创建的数据集,可以再次计算整个数据集中目标特征中每个类标签的参与度,这现在应该反映出具有相同参与度的两个类标签的均等表示的数据集。 此时,数据集的最终形状应等于(46728,23)。
-
从目标拆分特征:我们将数据集拆分为特征矩阵和目标矩阵,以避免重新调整目标值:
data_resampled = data_resampled.reset_index(drop=True) X = data_resampled.drop(columns=["default payment next month"]) y = data_resampled ["default payment next month"] -
重新缩放数据:最后,我们重新缩放特征矩阵的值,以避免对模型造成偏差:
X = (X - X.min())/(X.max() - X.min()) X.head()前几行代码的结果如下:
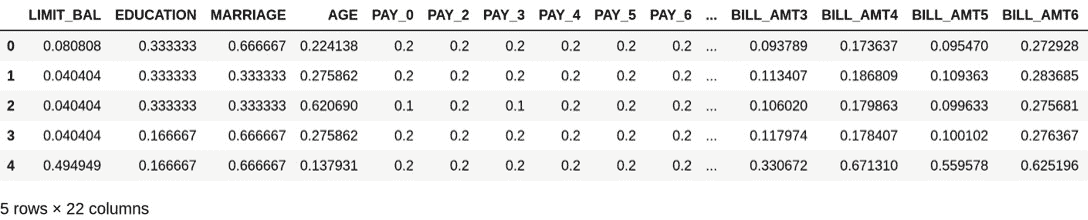
图 3.7:归一化后的特征矩阵
注意
考虑到婚姻和教育都是顺序特征,这意味着它们遵循顺序或等级; 选择重新缩放方法时,请确保保持顺序。
为了便于为即将进行的活动使用准备好的数据集,将特征(X)和目标(y)矩阵连接到一个 Pandas DataFrame中, 使用以下代码将其保存到 CSV 文件中:
final_data = pd.concat([X, y], axis=1)
final_data.to_csv("dccc_prepared.csv", index=False)
执行完上述步骤后,DCCC 数据集已转换并准备就绪(在新的 CSV 文件中)可用于训练模型,这将在以下部分中进行说明。
构建模型
一旦确定了问题并且已经探究和准备了手头的数据,就可以定义模型了。 网络架构的定义,层的类型,损失函数等应在前面的分析之后处理。 这主要是因为在机器学习中没有“千篇一律”的方法,而在深度学习中则没有。
与聚类,计算机视觉和机器翻译一样,回归任务需要与分类任务不同的方法。 在以下部分中,您将找到构建用于解决分类任务的模型的关键特征,并说明如何实现“良好”架构,以及如何以及何时使用 PyTorch 中的自定义模块。 。
用于分类任务的 ANN
如“活动 2.02”中所示,从“第 2 章”,“神经网络的构建模块”开发用于回归问题的深度学习解决方案,为回归任务而构建的神经网络使用输出作为连续值,这就是为什么在输出层不具有激活函数且仅具有一个输出节点(实际值)的原因,就像在根据房屋和邻里的特征,构建用于预测房价的模型的情况下一样。
鉴于此,要测量与此类模型相关的表现,您应该计算真实情况值和预测值之间的差,例如,计算 125.3(预测)与 126.38(真实情况值)之间的距离 。 如前所述,有许多方法可以测量此差异,例如均方误差(MSE),或另一种变化是均方根误差(RMSE),是最常用的指标。
与此相反,分类任务的输出是属于每个输出标签或类的某些输入特征集合的概率,这是使用 Sigmoid(用于二分类)或 softmax(用于多类分类)完成的 )激活函数。 对于二元分类任务,输出层应包含一个(对于 Sigmoid)或两个(对于 softmax)输出节点,而对于多类分类任务,输出层应等于类标签的数量。
计算属于每个输出类别的输入特征的似然性的这种能力,再加上argmax函数,将以较高的概率检索类别作为最终预测。
注意
在 Python 中, argmax 函数是能够沿轴返回最大值索引的函数。
考虑到这一点,模型的表现应与实例是否已分类到正确的类别标签有关,而不是与测量两个值之间的距离有关—因此要使用不同的损失函数( 熵是最常用的),用于训练神经网络进行分类问题,以及使用不同的表现指标,例如准确率,准确率和召回率。
好的架构
如本章所述,了解当前的数据问题对于确定神经网络的一般拓扑非常重要。 同样,常规分类问题并不需要与计算机视觉相同的网络架构。
修改并准备好数据后,考虑到在确定隐藏层数或每层中的单元数方面没有正确答案,最好的方法是从初始架构开始(可以进行改进) 以提高性能)。
这一点很重要,因为有时需要使用大量参数进行调整,可能难以承诺某些事情并开始开发解决方案。 但是,考虑到这一点,在训练神经网络时,有几种方法可以确定一旦对初始架构进行了训练和测试,就需要改进哪些内容。 实际上,将您的数据集分为三个子集的全部原因是允许使用一组训练数据集,使用另一组测量和微调模型,最后使用一组模型测量最终模型的表现。 最终未使用过的子集。
考虑到所有这些,将解释以下一组惯例和经验法则,以帮助决策过程定义 ANN 的初始架构:
-
输入层:这很简单; 只有一个输入层,其单元数量取决于训练数据的形状。 具体来说,输入层中的单元数应等于输入数据包含的特征数。
-
隐藏层:隐藏层的数量可能有所不同。 ANN 可以有一个隐藏层,也可以没有,也可以没有。 要选择正确的号码,请考虑以下几点:
数据问题越简单,所需的隐藏层就越少。 请记住,线性可分离的简单数据问题应该只有一个隐藏层。 另一方面,可以并且应该使用许多隐藏层(没有限制)解决更复杂的数据问题。
隐藏单元的数量应介于输入层中的单元数和输出层中的单元数之间。
-
输出层:同样,任何 ANN 仅具有一个输出层。 它包含的单元数取决于要开发的学习任务以及数据问题。 对于回归任务,将只有一个单元,即预测值。 但是,对于分类问题,考虑到模型的输出应该是属于每个类别标签的一组特征的概率,单元数量应等于可用的类别标签的数量。
-
其他参数:对于网络的第一种配置,其他参数应保留其默认值。 这主要是因为,在考虑可能表现相同或较差但需要更多资源的更复杂的近似值之前,最好先对数据问题进行最简单的模型测试。
一旦定义了初始架构,就该训练和测量模型的表现以进行进一步分析了,这很可能导致网络架构或其他参数值的更改,例如更改学习率或增加正则化项。
PyTorch 自定义模块
自定义模块由 PyTorch 的开发团队创建,以为用户提供更大的灵活性。 与我们在前几章中探讨的顺序容器相反,每当需要构建更复杂的模型架构,或者希望进一步控制每一层中的计算时,都应使用自定义模块 。
这并不意味着定制模块方法只能在这种情况下使用。 相反,一旦您学会了使用这两种方法,则选择较简单的数据问题时使用哪个方法(顺序容器或自定义模块)就成为优先考虑的问题。
以使用顺序容器定义的两层神经网络的以下代码段为例:
import torch
import torch.nn as nn
model = nn.Sequential(nn.Linear(D_i, D_h), \
nn.ReLU(), \
nn.Linear(D_h, D_o), \
nn.Softmax())
此处,D_i表示输入尺寸(输入数据中的特征),D_h表示隐藏尺寸(隐藏层中的节点数),D_o是指输出尺寸。
使用自定义模块,可以构建等效的网络架构,如下所示:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Classifier(torch.nn.Module):
def __init__(self, D_i, D_h, D_o):
super(Classifier, self).__init__()
self.linear1 = torch.nn.Linear(D_i, D_h)
self.linear2 = torch.nn.Linear(D_h, D_o)
def forward(self, x):
z = F.relu(self.linear1(x))
o = F.softmax(self.linear2(z))
return o
可以看出,在该类的初始化方法内部定义了输入层和输出层。 接下来,定义执行计算的另一种方法。
注意
对于本章中的练习和活动,您将需要安装 Python 3.7,Jupyter 6.0,Matplotlib 3.1,PyTorch 1.3,NumPy 1.17,scikit-learn 0.21,Pandas 0.25 和 Flask 1.1。
练习 3.01:使用自定义模块定义模型的架构
使用前面解释的理论,我们将使用定制模块的语法定义模型的架构:
-
打开 Jupyter 笔记本并导入所需的库:
import torch import torch.nn as nn import torch.nn.functional as F -
定义输入,隐藏和输出尺寸的必要变量。 将它们分别设置为
10,5和2:D_i = 10 D_h = 5 D_o = 2 -
使用 PyTorch 的自定义模块,创建一个名为
Classifier的类并定义模型的架构,使其具有两个线性层-第一个层是 ReLU 激活函数,第二层是 Softmax 激活函数:class Classifier(torch.nn.Module): def __init__(self, D_i, D_h, D_o): super(Classifier, self).__init__() self.linear1 = torch.nn.Linear(D_i, D_h) self.linear2 = torch.nn.Linear(D_h, D_o) def forward(self, x): z = F.relu(self.linear1(x)) o = F.softmax(self.linear2(z)) return o -
实例化该类,并将我们在“步骤 2”中创建的三个变量输入该类。打印模型。
model = Classifier(D_i, D_h, D_o) print(model)print语句的输出应如下所示:Classifier( (linear1): Linear(in_features=10, out_features=5, bias=True) (linear2): Linear(in_features=5, out_features=2, bias=True) )注意
要访问此特定部分的源代码,请参考这里。
您也可以通过这里在线运行此示例。 您必须执行整个笔记本才能获得所需的结果。
这样,您就可以使用 PyTorch 的自定义模块成功构建神经网络架构。 现在,您可以继续学习有关训练深度学习模型的过程。
定义损失函数并训练模型
重要的是要提到,交叉熵损失函数要求网络的输出是原始的(在通过使用softmax激活函数获得概率之前),这就是为什么通常会发现,用于分类问题的神经网络架构,没有针对输出层的激活函数。 此外,为了通过这种方法进行预测,必须在训练模型后将softmax激活函数应用于网络的输出。
解决此问题的另一种方法是对输出层使用log_softmax激活函数。 这样,损失函数可以定义为负对数似然损失(nn.NLLLoss)。 最后,可以通过从网络输出中获取指数来获得属于每个类别标签的一组特征的概率。 这是本章活动中将使用的方法。
一旦定义了模型架构,下一步将是对负责根据训练数据进行模型训练的部分进行编码,并在训练和验证集上测量其表现。
按照我们讨论的这些逐步说明进行操作的代码如下:
model = Classifier()
criterion = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr=0.005)
epochs = 10
batch_size = 100
从前面的片段中可以看出,第一步是定义在训练网络时将使用的所有变量。
接下来,循环的第一个用于遍历我们之前定义的周期数。
请记住,周期是指整个数据集通过网络架构前后传递的次数。batch_size是指单个批量(数据集的一部分)中训练示例的数量。 最后,迭代是指完成一个周期所需的批量数量。
第二个for循环遍历总数据集的每个批量,直到完成一个周期为止。 在此循环中,发生以下计算:
-
在一批训练集上训练模型。 在此获得预测。
-
通过比较上一步的预测值和训练集的标签(真实情况)来计算损失。
-
将梯度设置为零并针对当前步骤再次计算。
-
网络的参数基于梯度进行更新。
-
该模型对训练数据的准确率计算如下:
获取模型预测的指数,以便获得属于每个类标签的给定数据片段的概率。
使用
topk方法可以获得较高的类标签。使用 scikit-learn 的“度量”部分,计算准确率,精确度或查全率。 您还可以探索其他表现指标。
将所有批量的训练数据输入模型后,将关闭梯度计算,以通过验证数据验证当前模型的表现,如下所示:
-
该模型对验证集中的数据执行预测。
-
通过将先前的预测与验证集中的标签进行比较来计算损失函数。
-
准确率是根据验证集计算得出的。 要在验证集上计算模型的准确率,请使用对训练数据进行相同计算所用的同一组步骤:
注意
以下代码段不会自行运行。 您将需要加载一个数据集并将其划分为不同的集合,并定义和实例化一个网络架构。 还需要定义损失函数和优化算法(在本章前面的部分中进行了说明)。
train_losses, dev_losses, \ train_acc, dev_acc= [], [], [], [] for e in range(epochs): X, y = shuffle(X_train, y_train) running_loss = 0 running_acc = 0 iterations = 0 for i in range(0, len(X), batch_size): iterations += 1 b = i + batch_size X_batch = torch.tensor(X.iloc[i:b,:].\ values).float() y_batch = torch.tensor(y.iloc[i:b].values) pred = model(X_batch) loss = criterion(pred, y_batch) optimizer.zero_grad() loss.backward() optimizer.step() running_loss += loss.item() ps = torch.exp(pred) top_p, top_class = ps.topk(1, dim=1) running_acc += accuracy_score(y_batch, top_class) dev_loss = 0 acc = 0 with torch.no_grad(): pred_dev = model(X_dev_torch) dev_loss = criterion(pred_dev, y_dev_torch) ps_dev = torch.exp(pred_dev) top_p, top_class_dev = ps_dev.topk(1, dim=1) acc = accuracy_score(y_dev_torch, top_class_dev) train_losses.append(running_loss/iterations) dev_losses.append(dev_loss) train_acc.append(running_acc/iterations) dev_acc.append(acc) print("Epoch: {}/{}.. ".format(e+1, epochs), \ "Training Loss: {:.3f}.. "\ .format(running_loss/iterations),\ "Validation Loss: {:.3f}.. "\ .format(dev_loss),\ "Training Accuracy: {:.3f}.. "\ .format(running_acc/iterations),\ "Validation Accuracy: {:.3f}".format(acc))
前面的代码片段将打印两组数据的损失和准确率。 在下面的活动中,我们将介绍的有关构建和训练 DNN 的所有概念都将付诸实践。
活动 3.01:构建人工神经网络
对于此活动,使用先前准备的数据集,我们将构建一个四层模型,该模型能够确定客户是否会拖欠下一次付款。 为此,我们将使用自定义模块的方法。
让我们看一下以下情况:您在一家数据科学精品店工作,该精品店专门为世界各地的银行提供机器/深度学习解决方案。 他们最近为一家银行开展了一个项目,该项目希望能够预测下个月将收到或将不会收到的款项。 探索性数据分析团队已经为您准备了数据集,他们已要求您构建模型并计算模型的准确率。 请按照以下步骤完成此活动:
-
导入以下库:
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.utils import shuffle from sklearn.metrics import accuracy_score import torch from torch import nn, optim import torch.nn.functional as F import matplotlib.pyplot as plt注意
即使使用种子,考虑到训练集在每个周期之前都经过了打乱,该活动的确切结果也无法重现。
-
读取先前准备的数据集,该数据集应已命名为
dccc_prepared.csv。 -
将特征与目标分开。
-
使用 scikit-learn 的
train_test_split函数,将数据集分为训练,验证和测试集。 使用 60:20:20 的分配比例。 将random_state设置为0。 -
考虑到特征矩阵应为浮点型,而目标矩阵则应为非浮点型,将验证和测试集转换为张量。 目前暂时不要转换训练集,因为它们将进行进一步的转换。
-
构建用于定义网络层的自定义模块类。 包括一个正向函数,该函数指定将应用于每层输出的激活函数。 对于除输出之外的所有层,请使用 ReLU,在此处应使用
log_softmax。 -
实例化模型并定义训练模型所需的所有变量。 将周期数设置为
50,并将批大小设置为128。 使用0.001的学习率。 -
使用训练集的数据训练网络。 使用验证集来衡量表现。 为此,请保存每个周期中训练集和验证集的损失和准确率。
注意
训练过程可能需要几分钟,具体取决于您的资源。 如果您希望查看训练过程的进度,则添加打印语句是一种很好的做法。
-
绘制两组损失。
-
绘制两组数据的准确率。
最终图将如下所示:
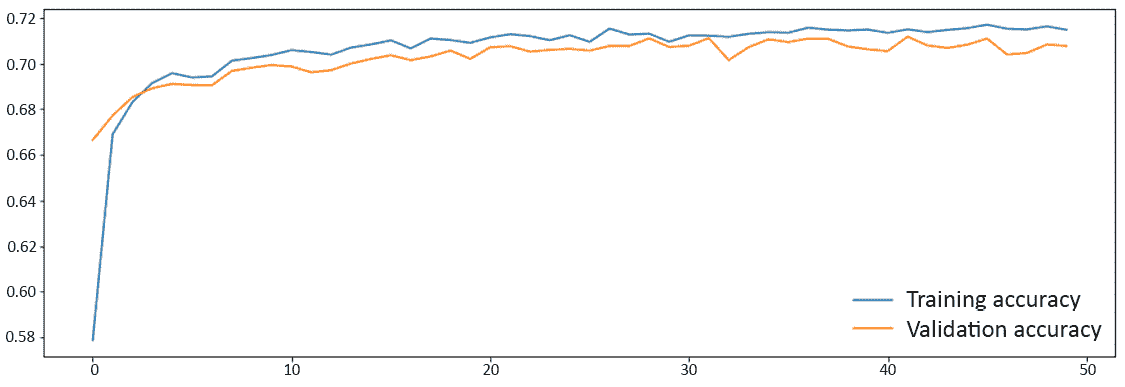
图 3.8:显示集合精度的图
注意
有关此活动的解决方案,请参见第 245 页。
您现在已经成功地编程和训练了一个四层神经网络,该网络能够根据历史数据执行推理。 接下来,您将学习如何提高模型的表现,以便对看不见的数据产生可信赖的推断。
处理欠拟合或过拟合的模型
建立深度学习解决方案不仅是定义架构,然后使用输入数据训练模型的问题; 相反,大多数人同意这是容易的部分。 创建高科技模型的技巧要求达到超越人类表现的高精确度。 本节将介绍误差分析主题,该主题通常用于诊断经过训练的模型,以发现哪些操作更可能对模型的表现产生积极影响。
误差分析
误差分析是指对训练和验证数据集上的错误率进行的初始分析。 然后,使用此分析来确定改善模型表现的最佳措施。
为了执行误差分析,有必要确定贝叶斯误差(也称为不可约误差),它是可实现的最小误差。 几十年前,贝叶斯误差等同于人为误差,这意味着专家认为可以达到的最低误差级别。
如今,随着技术和算法的改进,由于机器具有超越人类表现的能力,因此难以估计此值。 没有办法衡量他们与人类相比能做的更好,因为我们只能了解我们的能力。
为了执行误差分析,通常首先将贝叶斯误差设置为等于人为误差。 然而,这种局限性并非一成不变,研究人员认为,超越人类的表现也应是最终目标。
执行误差分析的过程如下:
-
计算选择的度量标准以衡量模型的表现。 应该在训练和验证数据集上计算该度量。
-
使用此度量,通过减去以前从 1 中计算出的表现指标来计算每个集合的错误率。以下面的等式为例:
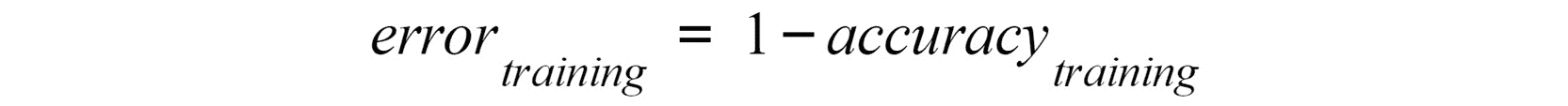
图 3.9:用于在训练集上计算模型错误率的方程式
-
从训练集误差
A)中减去贝叶斯误差。 保存差异,将用于进一步分析。 -
从验证集误差
B)中减去训练集误差,并保存差值。 -
取步骤 3 和步骤 4 中计算出的差值,并使用以下一组规则。
如果在“步骤 3”中计算出的差大于在“步骤 4”中计算出的差,则该模型不适合,也称为遭受高偏差。
如果在“步骤 4”中计算出的差大于在“步骤 3”中计算出的差,则模型过拟合,也称为遭受高方差,如下图所示:

图 3.10:显示如何执行误差分析的图
这些规则并不表示该模型只能遭受上述问题之一(高偏差或高方差),而是通过误差分析检测到的问题对模型的表现影响更大,这意味着修复它会在很大程度上提高性能。
让我们解释一下如何处理这些问题:
-
高偏差:欠拟合的模型或遭受高偏差的模型是无法理解训练数据的模型,因此无法发现模式并不能与其他数据集进行概括 。 这意味着该模型在任何数据集上的表现都不理想。
为了减少影响模型的高偏差,建议您定义一个更大/更深的网络(更多隐藏层)或训练更多迭代。 通过添加更多的层并增加训练时间,网络将拥有更多资源来发现描述训练数据的模式。
-
高方差:过拟合模型或遭受高方差的模型是难以归纳训练数据的模型; 太好地学习了训练数据的细节(这意味着通过训练过程,模型从训练集中学习的信息也太好了,这意味着它无法推广到其他数据集),包括其异常值 。 这意味着该模型在训练数据上的表现很好,但在其他数据集上的表现却很差。
通常可以通过将更多数据添加到训练集中,或通过将正则项添加到损失函数来解决此问题。 第一种方法旨在迫使网络将数据概括化,而不是理解少量示例的细节。 另一方面,第二种方法对权重较高的输入进行惩罚,以忽略异常值,并平等地考虑所有值。
鉴于此,处理影响模型的一种情况可能导致另一种情况出现或增加。 例如,遭受高偏差的模型在经过处理后,可能会在训练数据上而非在验证数据上提高其表现,这意味着该模型将开始遭受高方差,并且将需要另一组要采取的补救措施。
一旦诊断出模型并采取了必要的措施以改善表现,就应该选择最佳模型进行最终测试。 这些模型中的每一个都应用于对测试集(唯一不影响模型构建的集合)进行预测。
考虑到这一点,可以选择最终模型作为对测试数据表现最佳的模型。 这主要是因为测试数据的表现可以作为模型在未来未见数据集上的表现指标,这是最终目标。
练习 3.02:执行误差分析
使用我们在上一个活动中计算的准确率指标,在此活动中,我们将执行误差分析,这将有助于我们确定在即将到来的活动中针对模型执行的操作。 请按照以下步骤完成此练习:
注意
该练习不需要进行任何编码,而是需要对先前活动的结果进行分析。
-
假设贝叶斯误差为 0.15,执行误差分析并诊断模型:
Bayes error (BE) = 0.15 Training set error (TSE) = 1 – 0.716 = 0.284 Validation set error (VSE) = 1 – 0.71 = 0.29用作两组精度的值(
0.716和0.71)是在“活动 3.01”,“建立 ANN”:High bias = TSE – BE = 0.134 High variance = VSE – TSE = 0.014据此,该模型存在高偏差,这意味着该模型不适合。
-
确定提高模型准确率所需的操作。
为了提高模型的表现,可以遵循的两个操作过程是增加周期数并增加隐藏层数和/或单元数(每层中的神经元)。
据此,可以执行一组测试以便获得最佳结果。
这样,您就成功地执行了误差分析。 该方法是开发最先进的深度学习解决方案的关键,该解决方案在看不见的数据上表现出色。
练习 3 .02:提高模型的表现
对于此活动,我们将实现在练习中定义的操作,以减少影响模型表现的高偏差。 请考虑以下情形:团队成员对您所做的工作和代码的组织印象深刻,但是考虑到他们对客户的承诺,他们却要求您尝试将表现提高到 80%。 请按照以下步骤完成此活动:
注意
为此活动使用其他 Jupyter 笔记本。 在那里,您将再次加载数据集并执行与上一个活动中类似的步骤,不同之处在于,将多次执行训练过程以训练不同的架构和训练时间。
-
导入与上一个活动相同的库。
-
加载数据并从目标拆分特征。 接下来,使用 60:20:20 的分割比例将数据分割为三个子集(训练,验证和测试)。 最后,将验证和测试集转换为 PyTorch 张量,就像在上一个活动中一样。
-
考虑到该模型存在较高的偏差,因此重点应放在通过向每个层添加其他层或单元来增加周期数或网络规模。 目的应该是将测试范围内的准确率近似为 80%。
注意
没有正确的方法来选择首先执行哪个测试,因此要有创造性和分析性。 如果模型架构中的更改减少或消除了高偏差但引入了高方差,则应考虑保留这些更改,但增加措施以应对高方差。
-
绘制两组数据的损失和准确率。
-
使用表现最佳的模型,对测试集进行预测(在微调过程中不应使用该预测)。 通过计算该组模型的准确率,将预测结果与真实情况进行比较。
预期输出:通过模型架构和此处定义的参数获得的精度应为 80% 左右。
注意
可以在第 250 页上找到此活动的解决方案。
这样,您就可以使用误差分析成功改善模型的表现。 接下来,您将学习如何部署模型以在生产环境中使用它。
部署模型
到目前为止,您已经学习并实践了为常规回归和分类问题构建出色的深度学习模型的关键概念和技巧。 在现实生活中,模型不仅仅是为了学习而构建的。 相反,当出于研究目的以外的目的训练模型时,主要思想是能够在将来重用它们以对新数据进行预测,尽管该模型未经过训练,但该模型应具有相似的良好表现。
在小型组织中,可以对模型进行序列化和反序列化。 但是,当模型要由大型公司,用户使用或更改非常重要的大型任务时,将模型转换为可以在大多数生产环境中使用的格式(例如 API, 网站以及在线和离线应用)。
在本节中,我们将学习如何保存和加载模型,以及如何使用 PyTorch 的最新功能将我们的模型转换为高度通用的 C++ 应用。 我们还将学习如何创建 API 以利用经过训练的模型。
保存和加载模型
就像您想象的那样,每次都要对模型进行重新训练是非常不切实际的,尤其是考虑到大多数深度学习模型可能需要花费很多时间进行训练(取决于您的资源)。
取而代之的是,可以训练,保存和重新加载 PyTorch 中的模型,以执行进一步的训练或进行推理。 可以考虑将 PyTorch 模型中每一层的参数(权重和偏差)保存到state_dict字典中来实现。
此处提供了有关如何保存和加载经过训练的模型的分步指南:
-
最初,模型的检查点将仅包含模型的参数。 但是,在加载模型时,这不是唯一需要的信息。 根据分类器采用的参数(即包含网络架构的类),可能有必要保存更多信息,例如** input **单元的数量。 考虑到这一点,第一步是定义要保存的信息:
checkpoint = {"input": X_train.shape[1], \ "state_dict": model.state_dict()}这会将输入层中的单元数保存到检查点中,这在加载模型时会派上用场。
-
使用 PyTorch 的
save()函数保存模型。torch.save(checkpoint, "checkpoint.pth")第一个参数指的是我们之前创建的字典,第二个参数是要使用的文件名。
-
使用您选择的文本编辑器,创建一个 Python 文件,该文件导入 PyTorch 库并包含创建模型的网络架构的类。 这样做是为了使您可以方便地将模型加载到新的工作表中,而无需使用用于训练模型的工作表。
-
要加载模型,让我们创建一个函数,它将执行三个主要操作。
def load_model_checkpoint(path): checkpoint = torch.load(path) model = final_model.Classifier(checkpoint["input"], \ checkpoint["output"], \ checkpoint["hidden"]) model.load_state_dict(checkpoint["state_dict"]) return model model = load_model_checkpoint("checkpoint.pth")该函数将输入保存的模型文件(检查点)的路径作为输入。 首先,加载检查点。 接下来,使用保存在 Python 文件中的网络架构实例化模型。 在这里,
final_model指的是应该已经导入到新工作表中的 Python 文件的名称,而Classifier()指的是该文件中保存的类的名称。 该模型将具有随机初始化的参数。 最后,将来自检查点的参数加载到模型中。调用时,此函数将返回已训练的模型,该模型现在可用于进一步的训练或执行推理。
用于生产的 C++ 和 PyTorch
按照框架的名称,PyTorch 的主要接口是 Python 编程语言。 这主要是由于在开发机器学习解决方案时,由于该语言的动态性和易用性,因此许多用户偏爱该编程语言。
但是,在某些情况下,Python 属性变得不利。 对于为生产而开发的模型,情况恰恰如此,在该模型中,其他编程语言被证明更有用。 C++ 就是这种情况,C++ 已广泛用于机器/深度学习解决方案的生产目的。
鉴于此,PyTorch 最近提出了一种简单的方法,使用户可以享受两全其美的好处。 尽管他们可以继续使用 Pythonic 进行编程,但是现在可以将模型序列化为可以从 C++ 加载和执行的表示形式,而无需依赖 Python。 这种表示称为 TorchScript。
通过 PyTorch 的即时(JIT)编译器模块可以将 PyTorch 模型转换为 TorchScript。 这是通过将模型以及示例输入通过torch.jit.trace()函数传递来实现的,如下所示:
traced_script = torch.jit.trace(model, example)
请记住,名为model的变量应包含以前训练过的模型,而名为example的变量应包含希望提供给模型的特征以便执行预测。 这将返回一个脚本模块,可以将其用作常规的 PyTorch 模块,如下所示:
prediction = traced_script(input)
前面的代码将返回通过运行模型中的输入数据获得的输出。
构建 API
应用编程接口(API)包含一个专门创建供其他程序使用的程序(与网站或界面相反,后者是由人为操纵的) 。 据此,API 在创建要在生产环境中使用的深度学习解决方案时使用,因为它们允许通过其他方式(例如网站)访问从运行模型(例如预测)获得的信息。
在本节中,我们将探讨 Web API(通过互联网与其他程序共享信息的 API)的创建。 该 API 的功能是加载先前保存的模型并根据一组给定的特征进行预测。 向 API 发出 HTTP 请求的程序可以访问此预测。
关键术语解释如下:
-
超文本传输协议(HTTP):这是在网络上传输数据的主要方式。 它使用方法来运作,这有助于确定数据传输的方式。 两种最常用的方法解释如下:
POST:此方法允许您将消息中的数据从客户端(正在向 API 发出请求的 Web 浏览器或平台)发送到服务器(使用该信息运行的程序) 身体。GET:与POST方法相反,此方法将数据作为 URL 的一部分发送,这在发送大量数据时可能不方便。 -
Flask:这是一个为 Python 开发的库,可让您创建 API(以及其他东西)。
要使用 Flask 创建简单的 Web API,请执行以下步骤:
-
导入必要的库:
import flask from flask import request import torch import final_model -
初始化 Flask 应用:
app = flask.Flask(__name__) app.config["DEBUG"] = TrueDEBUG配置在开发期间设置为True,但在生产中应设置为False。 -
加载之前训练的模型。
def load_model_checkpoint(path): checkpoint = torch.load(path) model = final_model.Classifier(checkpoint["input"]) model.load_state_dict(checkpoint["state_dict"]) return model model = load_model_checkpoint("checkpoint.pth -
定义可访问 API 的路径,以及可用于向 API 发送信息以执行操作的方法。 该语法称为装饰器,应位于函数之前:
@app.route('/prediction', methods=['POST']) -
定义一个执行所需动作的函数。在这种情况下,该函数将获取发送到 API 的信息,并将其反馈给之前加载的模型,以执行预测。一旦获得预测,该函数应返回一个响应,该响应将作为 API 请求的结果显示。
def prediction(): body = request.get_json() example = torch.tensor(body['data']).float() pred = model(example) pred = torch.exp(pred) _, top_class_test = pred.topk(1, dim=1) top_class_test = top_class_test.numpy() return {"status":"ok", "result":int(top_class_test[0][0])} -
运行 Flask 应用。以下命令可以开始使用 Web API。
app.run(debug=True, use_reloader=False)同样,在开发过程中,
DEBUG设置为True。use_reloader参数设置为False,以允许该应用在 Jupyter 笔记本上运行。 但是,不建议从 Jupyter 笔记本运行该应用。 这仅出于教学目的。 在现实生活中,应将use_reloader设置为True,并且应通过命令提示符实例或终端将应用作为 Python 文件运行。
练习 3.03:创建 Web API
使用 Flask,我们将创建一个 Web API,该 Web API 会在调用时接收一些数据,并返回一段显示在浏览器中的文本。 请按照以下步骤完成此练习:
-
在 Jupyter 笔记本中,导入所需的库。
import flask from flask import request -
初始化 Flask 应用。
app = flask.Flask(__name__) app.config["DEBUG"] = True -
定义 API 的路由,使其为
/<name>。将方法设置为GET。接下来,定义一个函数,该函数接收一个参数(name)并返回一个字符串,该字符串包含一个h1标签,其中有HELLO字样,后面是函数接收的参数。@app.route('/<name>', methods=['GET']) def hello(name): return "<h1>HELLO {}</h1>".format(name.upper()) -
运行 Flask 应用。
app.run(debug=True, use_reloader=False)前一行代码的输出如下所示:
图 3.11:执行代码后的警告
它包含一些警告,这些警告指定了正在运行的 Flask 应用的条件,以及包含类似于以下内容的 URL 的一行文本:
http://127.0.0.1:5000/ -
将网址复制到浏览器中,后面加上你的名字,如下。
http://127.0.0.1:5000/your_name按
Enter,然后将加载一个简单的网站,该网站应类似于以下内容:
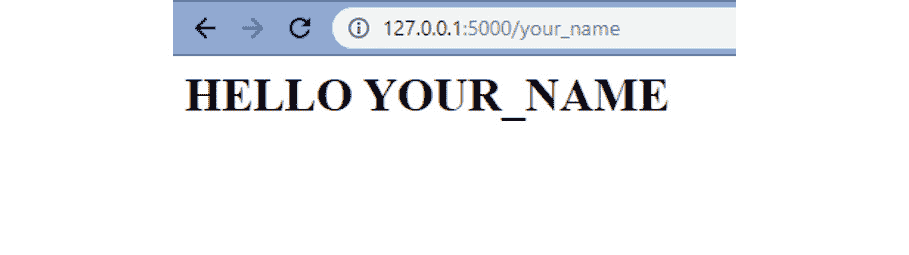
图 3.12:执行对 API 的请求的结果
注意
要访问此特定部分的源代码,请参考这里。
本部分当前没有在线交互示例,需要在本地运行。
这样,您就成功创建了一个 Web API。 通过允许模型与用户之间的轻松通信,此功能将成为您在生产环境中使用模型的关键。 在下一个活动中,将把在本章中学习到的模型的部署的不同概念付诸实践。
练习 3.0 3:利用模型
对于此活动,保存在上一个活动中创建的模型。 此外,保存的模型将被加载到新笔记本中以供使用。 接下来,我们将模型转换为可以在 C++ 上执行的序列化表示形式,并创建 Flask API。 让我们看一下以下情况:每个人都对您对改进模型的承诺以及模型的最终版本感到满意,因此他们要求您保存模型并将其转换为可用于构建模型的格式。 客户的在线申请。 请按照以下步骤完成此活动:
注意
该活动将使用三个 Jupyter 笔记本。 首先,我们将使用上一个活动中的同一笔记本来保存最终模型。 接下来,我们将打开一个新的笔记本,该笔记本将用于加载保存的模型。 最后,将使用第三个笔记本创建 API。
-
打开用于“活动 3.02”和“提高模型表现”的 Jupyter 笔记本。
-
复制包含最佳表现模型的架构的类,并将其保存在 Python 文件中。 确保导入 PyTorch 所需的库和模块。 将其命名为
final_model.py。 -
在 Jupyter 笔记本中,保存表现最佳的模型。 确保保存与输入单元有关的信息以及模型参数。 将其命名为
checkpoint.pth。 -
打开一个新的 Jupyter 笔记本。
-
导入 PyTorch 以及我们在“步骤 2”中创建的 Python 文件。
-
创建一个加载模型的函数。
-
通过将以下张量输入到你的模型中进行预测。
torch.tensor([[0.0606, 0.5000, 0.3333, 0.4828, 0.4000, \ 0.4000, 0.4000, 0.4000, 0.4000, 0.4000, \ 0.1651, 0.0869, 0.0980, 0.1825, 0.1054, \ 0.2807, 0.0016, 0.0000, 0.0033, 0.0027, \ 0.0031, 0.0021]]).float() -
使用 JIT 模块转换模型。
-
通过从“步骤 7”中输入张量到模型的跟踪脚本中来执行预测。
-
打开一个新的 Jupyter 笔记本,然后导入使用 Flask 创建 API 所需的库以及加载已保存模型的库。
-
初始化 Flask 应用。
-
定义一个函数来加载保存的模型并实例化该模型。
-
定义 API 的路由,使其为
/prediction,并定义方法为POST。 然后,定义将接收POST数据并将其馈送到模型以执行预测的函数。 -
运行 Flask 应用。
运行后,该应用将如下所示:
图 3.13:应用运行后的屏幕截图
注意
有关此活动的解决方案,请参阅第 257 页。
总结
在涵盖了前几章的大部分理论知识之后,本章使用了一个实际案例研究来巩固我们的知识。 这样做的目的是鼓励通过动手实践来学习。
本章首先介绍了深度学习对要求准确率的众多行业的影响。 推动深度学习发展的主要行业之一是银行和金融业,这些算法被用于诸如贷款申请评估,欺诈检测以及过去决策评估以预测未来行为等领域,这主要是由于在这些方面,算法具有超越人类表现的能力。
本章使用来自台湾一家银行的真实数据集,目的是预测客户是否会拖欠付款。 本章通过解释定义任何数据问题的内容,原因和方式以及分析手头的数据以对其进行最佳利用的重要性,开始开发针对此问题的解决方案。
根据问题定义准备好数据后,我们就探索了定义“良好”架构的想法。 即使可以考虑一些经验法则,但主要的收获还是要构建一个初始架构而又不去想太多,以便获得一些可用于执行误差分析以改善模型表现的结果。
误差分析的思想需要在训练和验证集上分析模型的误差率,以便确定模型是遭受更大的偏差还是承受更大的偏差。 然后,对模型的这种诊断将用于更改模型的架构和一些学习参数,这将导致表现的提高。
最后,我们探索了使用最佳表现模型的三种主要方法。 第一种方法是保存模型,然后将其重新加载到任何编码平台中,以便我们可以继续训练或执行推理。 第二种方法主要用于将模型投入生产,并通过使用 PyTorch 的 JIT 模块来实现,该模块创建可以在 C++ 上运行的模型的序列化表示。 最后,第三种方法包括创建一个可供其他程序访问的 API,以便它可以向模型发送信息或从模型接收信息。
在下一章中,我们将重点介绍使用 CNN 解决图像分类任务。
四、卷积神经网络
概述
本章介绍了训练卷积神经网络(CNN)的过程-也就是说,发生在不同层的计算通常可以在 CNN 架构中找到,其目的可在训练过程中发现。 您将学习如何通过对模型应用数据扩充和批量规范化来改善计算机视觉模型的表现。 到本章末,您将能够使用 CNN 通过 PyTorch 解决图像分类问题。 这将是在计算机视觉领域实现其他解决方案的起点。
简介
在上一章中,解释了最传统的神经网络架构并将其应用于现实生活中的数据问题。 在本章中,我们将探讨 CNN 的不同概念,这些概念主要用于解决计算机视觉问题(即图像处理)。
即使当今所有神经网络领域都很流行,但 CNN 可能是所有神经网络架构中最流行的。 这主要是因为,尽管它们在许多领域中都可以使用,但是它们尤其擅长处理图像,并且技术的进步已使大量图像的收集和存储成为可能,从而可以解决当今使用图像处理各种挑战。 图像作为输入数据。
从图像分类到物体检测,CNN 被用于诊断癌症患者和检测系统中的欺诈行为,以及用于构建将彻底改变未来的深思熟虑的自动驾驶汽车。
本章将重点介绍在处理图像时 CNN 优于其他架构的原因,并更详细地说明其架构的组成部分。 它将涵盖用于构建 CNN 来解决图像分类数据问题的主要编码结构。
此外,我们将探讨数据扩充和批量规范化的概念,这些概念将用于改善模型的表现。 本章的最终目标是比较三种不同方法的结果,以便使用 CNN 解决图像分类问题。
注意
构建 CNN
CNN 是处理图像数据问题时的理想架构。 但是,由于它们通常用于图像分类任务,因此即使它们的功能扩展到图像处理领域的其他领域,它们也常常未被充分利用。 本章不仅将说明 CNN 为何如此擅长理解图像的原因,还将识别可以解决的不同任务,并提供一些实际应用的示例。
此外,本章还将探讨 CNN 的不同构建块及其在 PyTorch 中的应用,以最终构建一个使用 PyTorch 的数据集进行图像分类来解决数据问题的模型。
为什么将 CNN 用于图像处理?
图像是像素矩阵,那么为什么不将矩阵展平为向量并使用传统的神经网络架构对其进行处理呢? 答案是,即使使用最简单的图像,也存在一些像素相关性会改变图像的含义。 例如,猫眼,汽车轮胎甚至物体边缘的表示都是由以某种方式布置的几个像素构成的。 如果我们将图像展平,则这些依赖关系将丢失,传统模型的准确率也会丢失:
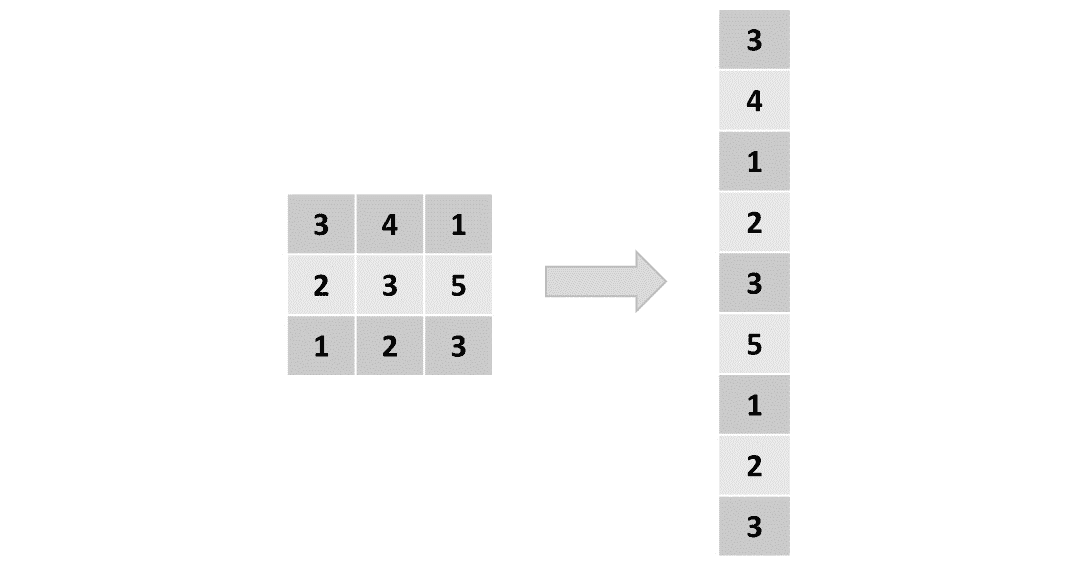
图 4.1:展平矩阵的表示
CNN 能够捕获图像的空间相关性,因为它根据过滤器的大小将它们作为矩阵进行处理并一次分析整个图像块。 例如,使用大小为3 x 3的过滤器的卷积层将一次分析 9 个像素,直到它覆盖了整个图像。
图像的每个块都具有一组参数(权重和偏差),这些参数将取决于该组像素与整个图像的相关性,具体取决于手边的过滤器。 这意味着垂直边缘过滤器将为包含垂直边缘的图像块分配更大的权重。 据此,通过减少参数数量并通过分块分析图像,CNN 可以呈现更好的图像表示形式。
作为输入的图像
如前所述,CNN 的典型输入是矩阵形式的图像。 矩阵的每个值代表图像中的一个像素,其中的数字由颜色的强度决定,其范围为 0 到 255。
在灰度图像中,白色像素用数字 255 表示,黑色像素用数字 0 表示。灰色像素是介于两者之间的任何数字,具体取决于颜色的强度。 灰色越浅,数字越接近 255。
彩色图像通常使用 RGB 系统表示,该系统将每种颜色表示为红色,绿色和蓝色的组合。 在这里,每个像素将具有三个尺寸,每种颜色一个。 每个维度中的值的范围从 0 到 255。这里,颜色越深,数字越接近 255。
根据上一段,给定图像的矩阵是三维的。 这里,第一维是指图像的高度(以像素数为单位),第二维是指图像的宽度(以像素数为单位),而第三维是指通道,是指图像的配色方案。
彩色图像的通道数为三个(RGB 系统中每种颜色一个通道)。 另一方面,灰度图像只有一个通道:
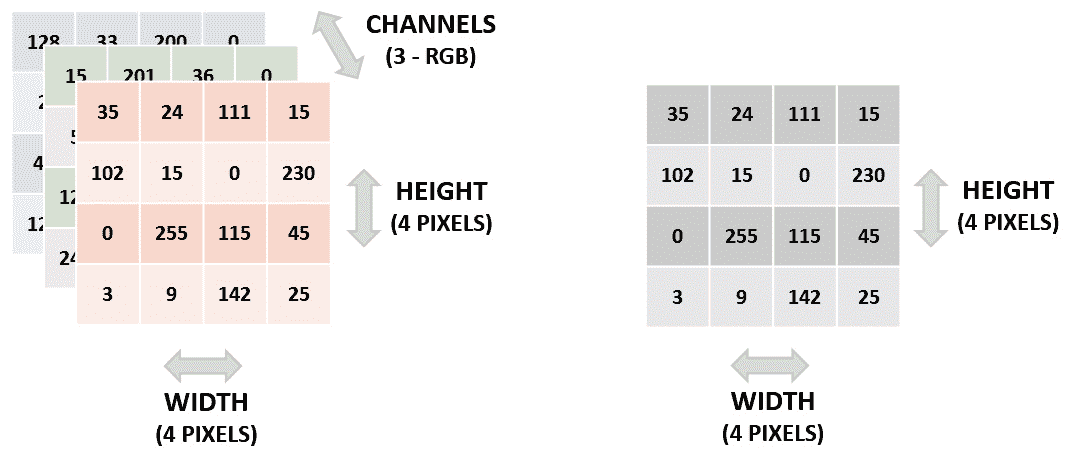
图 4.2:图像的矩阵表示–左侧是彩色图像; 右边是灰度图像
与文本数据相比,馈入 CNN 的图像不需要太多预处理。 图像通常按原样提供,最常见的更改如下:
- 标准化像素值来加快学习过程并提高性能
- 缩小图像(即减小其宽度和长度)以加快学习过程
归一化输入的最简单方法是取每个像素的值并将其除以 255,这样我们最终得到的值介于 0 到 1 之间。但是,使用了不同的方法来归一化图像,例如均值中心技术 。 在大多数情况下,选择一个或另一个的决定是一个优先事项。 但是,在使用预训练模型时,强烈建议您使用与第一次训练模型相同的技术。 该信息通常在预训练模型的文档中可用。
CNN 的应用
尽管 CNN 主要用于解决计算机视觉问题,但重要的是要提及它们解决其他学习问题的能力,主要是在分析数据序列方面。 例如,已知 CNN 在文本,音频和视频的序列上表现良好,有时与其他网络架构结合使用,或者通过将序列转换为可以由 CNN 处理的图像。 使用带有数据序列的 CNN 可以解决的一些特定数据问题包括文本的机器翻译,自然语言处理和视频帧标记等。
CNN 可以执行不同的任务,这些任务适用于所有监督学习问题。 但是,本章将重点介绍计算机视觉。 以下是对每个任务的简要说明,以及每个任务的真实示例。
分类
这是计算机视觉中最常见的任务。 主要思想是将图像的一般内容分类为一组类别,称为标签。
例如,分类可以确定图像是狗,猫还是任何其他动物的。 通过输出图像属于每个类别的概率来完成此分类,如下图所示:

图 4.3:分类任务
定位
定位的主要目的是生成一个边界框,以描述对象在图像中的位置。 输出由一个类标签和一个边界框组成。
此任务可用于传感器中,以确定对象在屏幕的左侧还是右侧:

图 4.4:定位任务
检测
该任务包括对图像中的所有对象执行对象定位。 输出由多个边界框以及多个类标签(每个框一个)组成。
此任务用于自动驾驶汽车的构造,目的是能够找到交通标志,道路,其他汽车,行人和其他与确保安全驾驶体验有关的其他物体:

图 4.5:检测任务
分割
这里的任务是输出图像中存在的每个对象的类标签和轮廓。 这主要用于标记图像的重要对象以进行进一步分析。
例如,该任务可用于严格划定对应于患者肺部图像中肿瘤的区域。 下图描述了如何概述感兴趣的对象并为其分配标签:

图 4.6:分割任务
从本节开始,本章将重点介绍训练模型以使用 PyTorch 的图像数据集之一进行图像分类。
CNN 的基础
深度卷积网络是一种将图像作为输入并通过一系列卷积层和过滤器,池化层和全连接层(FC)的网络,以最终应用 softmax 激活函数,该函数将图像分类为类标签。 与 ANN 一样,这种分类形式是通过为图像赋予每个类别标签一个介于 0 和 1 之间的值来计算属于每个类别标签的图像的概率来执行的。 具有较高概率的类别标签被选择为该图像的最终预测。
以下是对每个层的详细说明,以及如何在 PyTorch 中定义此类层的代码示例。
卷积层
这是从图像中提取特征的第一步。 目的是通过学习图像一小部分的特征来保持附近像素之间的关系。
数学运算在该层中进行,其中给出两个输入(图像和过滤器),并获得一个输出。 如前所述,该操作包括对过滤器和与过滤器大小相同的图像部分进行卷积。 对图像的所有子部分重复此操作。
注意
再次访问 “第 2 章”,“神经网络 CNN 的简介”部分,以提醒您在输入和过滤器之间执行的确切计算。
所得矩阵的形状取决于输入的形状,其中包含大小为[hxwxc的图像矩阵) 大小(fhxfwxc)的大小将根据以下公式输出:
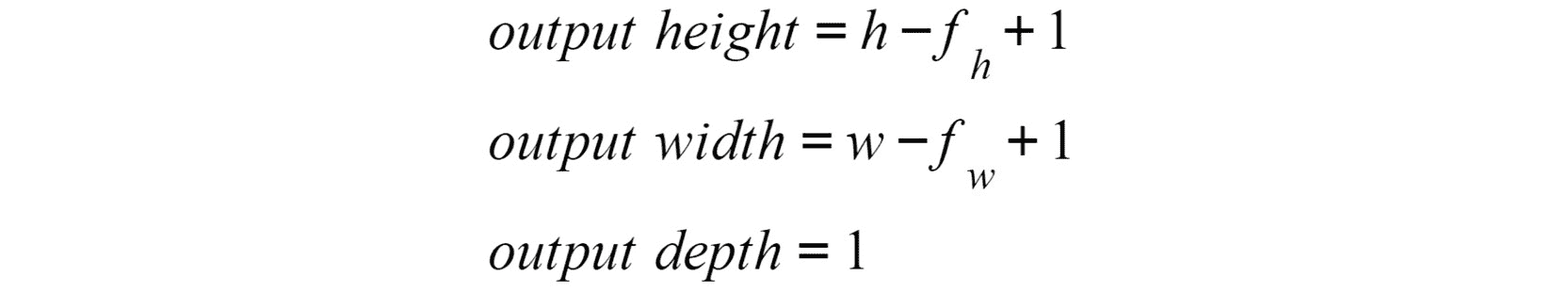
图 4.7:卷积层的输出高度,宽度和深度
此处,h表示输入图像的高度,w表示宽度,c表示深度(也称为通道),fh和fw是用户关于过滤器尺寸设置的值。
下图以矩阵形式描述了此尺寸转换,其中左侧的矩阵表示彩色图像,中间的矩阵表示将应用于图像所有通道的单个过滤器,而矩阵将应用于矩阵。 右边是图像和过滤器计算的输出:
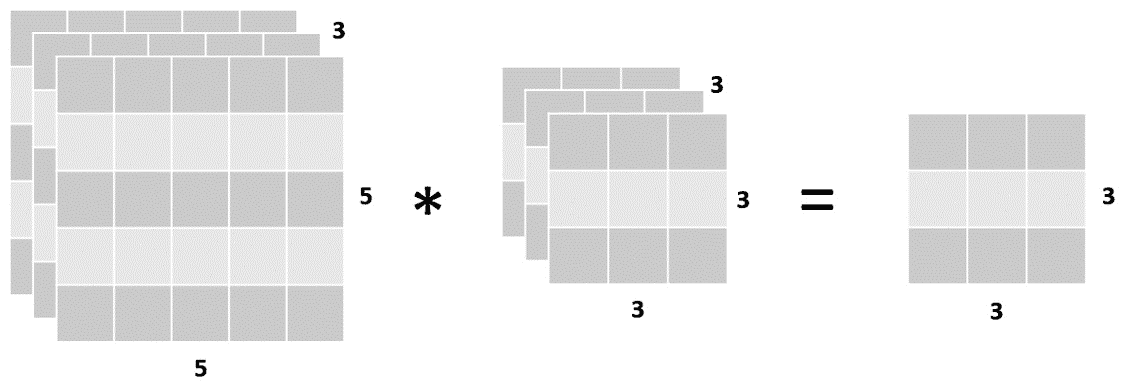
图 4.8:输入,过滤器和输出的尺寸
重要的是要提到,在单个卷积层中,可以将多个过滤器应用于相同的图像,所有过滤器都具有相同的形状。 考虑到这一点,将两个过滤器应用于其输入的卷积层的输出形状就其深度而言等于两个,如下图所示:
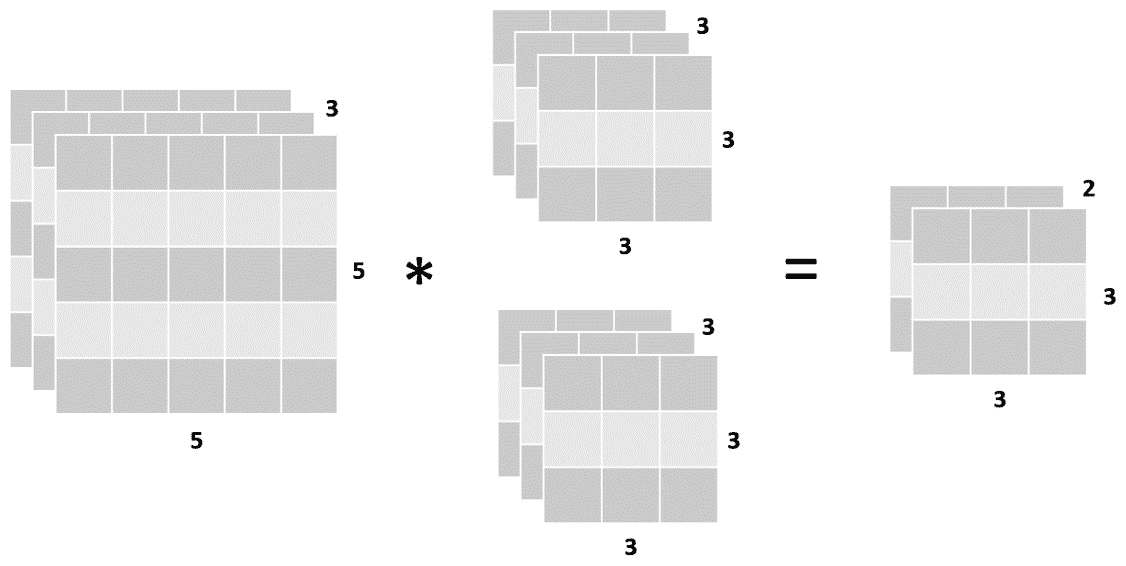
图 4.9:带两个过滤器的卷积层
这些过滤器中的每一个将执行不同的操作,以发现图像的不同特征。 例如,在具有两个过滤器的单个卷积层中,这些操作可以是垂直边缘检测和水平边缘检测。 随着网络在层数方面的增长,过滤器将执行更复杂的操作,这些操作将利用先前检测到的特征(例如,通过使用边缘检测器的输入来检测人的轮廓)。
过滤器通常每层增加。 这意味着,尽管第一卷积层具有 8 个过滤器,但通常会创建第二个卷积层,使其具有两倍的数量(16),第三层使它具有两倍的数量(32),依此类推 。
但是,必须指出的是,在 PyTorch 中,就像在许多其他框架中一样,您应该仅定义要使用的过滤器数量,而不是过滤器的类型(例如,垂直边缘检测器)。 每种过滤器配置(用于检测特定特征的所包含的数量)都是系统变量的一部分。
将向卷积层主题介绍两个附加概念,如下所示。
填充
顾名思义,填充参数将图像填充为零。 这意味着它将在图像的每一侧添加其他像素(用零填充)。
下图显示了一个示例,该示例已在每侧用一个图像填充:

图 4.10:用一个图填充一个输入图像的图形表示
一旦输入矩阵通过过滤器,就可以用来保持其形状。 这是因为,尤其是在前几层中,目标应该是从原始输入中保留尽可能多的信息,以便从中提取最多的特征。
为了更好地理解填充的概念,请考虑以下情形。
将3 x 3过滤器应用于形状为32 x 32 x 3的彩色图像将得到形状为30 x 30 x 1的矩阵。这意味着下一层的输入已缩小。 但是,通过向输入图像添加 1 的填充,输入的形状将更改为34 x 34 x 3,这将导致使用相同过滤器的输出为32 x 32 x 1。
使用填充时,以下公式可用于计算输出宽度:

图 4.11:使用填充应用卷积层后的输出宽度
在此,W表示输入矩阵的宽度,F表示过滤器的宽度,P表示填充。 可以使用相同的公式来计算输出的高度。
要获得形状与输入相等的输出矩阵,请使用以下公式计算填充的值(考虑到我们将在下一节中定义的步幅等于 1):
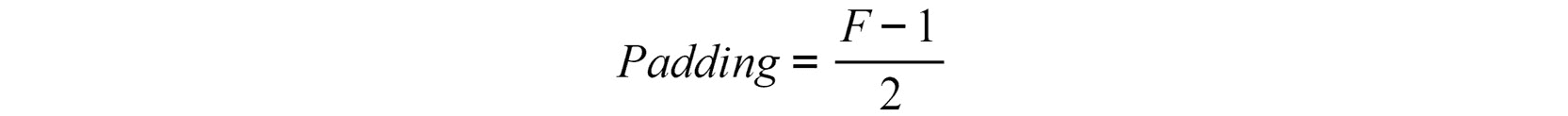
图 4.12:填充数字以获得形状与输入相等的输出矩阵
请记住,输出通道(深度)的数量将始终等于已应用于输入的过滤器的数量。
步幅
此参数是指过滤器将在水平和垂直方向上在输入矩阵上移动的像素数。 到目前为止,我们已经看到过滤器通过图像的左上角,然后向右移一个像素,依此类推,直到它垂直和水平通过图像的所有部分为止。 此示例是步幅等于 1 的卷积层之一,这是此参数的默认配置。
当步幅等于 2 时,移位将改为两个像素,如下图所示:
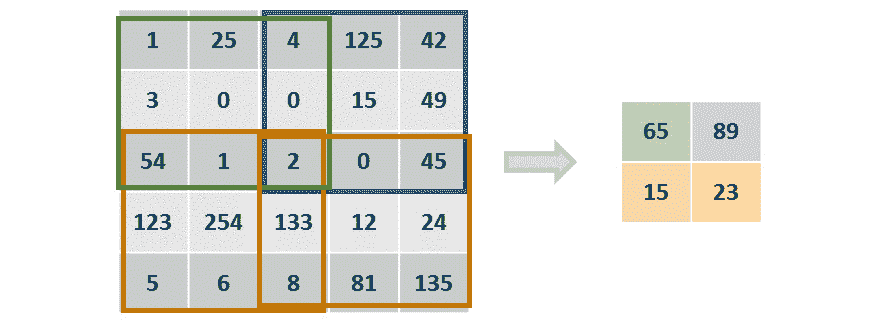
图 4.13:跨度为 2 的卷积层的图形表示
可以看出,初始操作发生在左上角。 然后,通过向右移动两个像素,第二个计算将在右上角进行。 接下来,计算向下移动两个像素以在左下角执行计算,最后,通过再次向右移动两个像素,最终的计算将在右下角进行。
注意
“图 4.12”中的数字是构成的,不是实际的计算。 重点应放在方框上,这些方框说明步幅等于 2 时的移动过程。
使用步幅时,以下方程式可用于计算输出宽度:
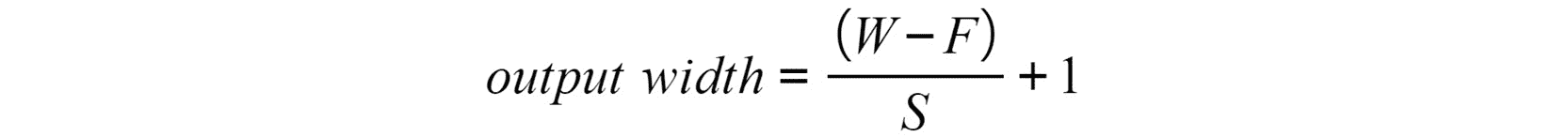
图 4.14:使用步幅的卷积层的输出宽度
在此,W表示输入矩阵的宽度,F表示过滤器的宽度,S表示步幅。 可以使用相同的公式来计算输出的高度。
引入这些参数后,用于计算从卷积层得出的矩阵的输出形状(宽度和高度)的最终方程式如下:
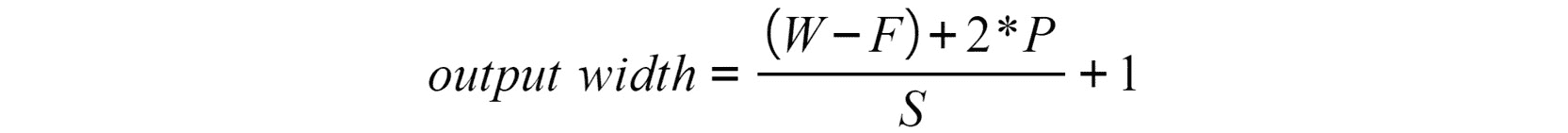
图 4.15:使用填充和跨度的卷积层后的输出宽度
每当值是浮点型时,都应四舍五入。 这基本上意味着输入的某些区域将被忽略,并且不会从中提取任何特征。
最后,一旦输入已通过所有过滤器,则将输出馈送到激活函数以破坏线性,这类似于传统神经网络的过程。 尽管在此步骤中可以应用多种激活函数,但是首选函数是 ReLU 函数,因为它在 CNN 中显示了出色的效果。 我们在此处获得的输出将成为后续层(通常是池化层)的输入。
练习 4.01:计算卷积层的输出形状
使用给定的方程式,请考虑以下情形并计算输出矩阵的形状:
注意
此练习不需要编码,而是由基于我们前面提到的概念的计算组成。
-
计算从卷积层派生的矩阵的输出形状,该卷积层的输入形状为
64 x 64 x 3,过滤器形状为3 x 3 x 3:Output height = 64 -3 + 1 = 62 Output width = 64 - 3 + 1 = 62 Output depth = 1 -
计算从卷积层派生的矩阵的输出形状,该卷积层的输入形状为
32 x 32 x 3,10 个形状为5 x 5 x 3的过滤器,填充为 2:Output height = 32 - 5 + (2 * 2) + 1 = 32 Output width = 32-5 + (2 * 2) + 1 = 32 Output depth = 10 -
计算从卷积层派生的矩阵的输出形状,该卷积层的输入形状为
128 x 128 x 1,五个形状为5 x 5 x 1的过滤器,步幅为 3:Output height = (128 - 5)/ 3 + 1 = 42 Output width = (128 - 5)/ 3 + 1 = 42 Output depth = 5 -
计算从卷积层派生的矩阵的输出形状,该卷积层的输入形状为
64 x 64 x 1,形状为8 x 8 x 1的过滤器,填充为 3,步幅为 3:Output height = ((64 - 8 + (2 * 3)) / 3) +1 = 21.6 ≈ 21 Output width = ((64 - 8 + (2 * 3)) / 3) +1 = 21.6 ≈ 21 Output depth = 1
这样,您就成功地计算了从卷积层得出的矩阵的输出形状。
在 PyTorch 中编码卷积层非常简单。 使用自定义模块,只需要创建网络类。 该类应包含定义网络架构(即网络层)的__init__方法和定义要对信息进行计算的forward方法。 穿过层,如以下代码片段所示:
import torch.nn as nn
import torch.nn.functional as F
class CNN_network(nn.Module):
def __init__(self):
super(CNN_network, self).__init__()
self.conv1 = nn.Conv2d(3, 18, 3, 1, 1)
def forward(self, x):
x = F.relu(self.conv1(x))
return x
在定义卷积层时,从左到右传递的参数是指输入通道,输出通道(过滤器数量),核大小(过滤器大小),步幅和填充。
前面的示例由一个卷积层组成,该卷积层具有三个输入通道,18 个过滤器,每个过滤器的大小为 3,步幅和填充等于 1。
等效于上一个示例的另一种有效方法是将自定义模块的语法与顺序容器的使用结合起来,如以下代码片段所示:
import torch.nn as nn
class CNN_network(nn.Module):
def __init__(self):
super(CNN_network, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(3, 18, 3, 1, 1), \
nn.ReLU())
def forward(self, x):
x = self.conv1(x)
return x
在这里,层的定义发生在顺序容器内部。 通常,一个容器包括卷积层,激活函数和池化层。 一组新的层包含在其下面的不同容器中。
在前面的示例中,在顺序容器内定义了卷积层和激活层。 因此,在forward方法中,不需要卷积层的输出通过激活函数,因为已经使用容器对其进行了处理。
池化层
按照惯例,池化层是特征选择步骤的最后部分,这就是为什么池化层通常可以在卷积层之后找到的原因。 正如我们在前几章中所解释的那样,其思想是从图像的各个子部分中提取最相关的信息。 池化层的大小通常为 2,步幅等于其大小。
池化层通常将输入的高度和宽度减小一半。 考虑到要使卷积层找到图像中的所有特征,必须使用多个过滤器,并且此操作的输出可能变得太大,这意味着要考虑许多参数,这一点很重要。 池化层旨在通过保留最相关的特征来减少网络中的参数数量。 从图像的各个子部分中选择相关特征,可以通过获取最大数量或平均该区域中的数量来进行。
对于图像分类任务,最常见的是在平均池化层上使用最大池化层。 这是因为前者在保留最相关特征的任务中表现出更好的效果,而后者已被证明在诸如平滑图像等任务中表现更好。
要计算输出矩阵的形状,请使用以下公式:
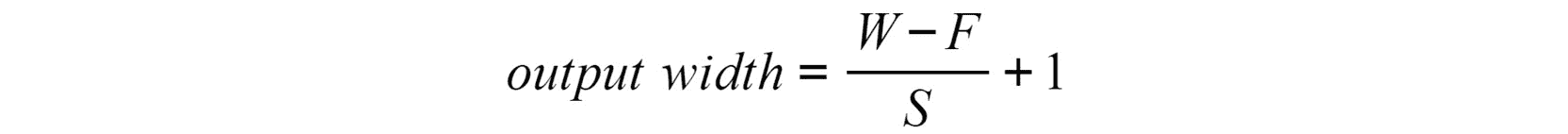
图 4.16:合并层后的输出矩阵宽度
此处,W表示输入的宽度,F表示过滤器的尺寸,S表示步幅。 可以使用相同的公式来计算输出高度。
输入的通道或深度保持不变,因为合并层将对图像的所有通道执行相同的操作。 这意味着池化层的结果仅会影响宽度和长度的输入。
练习 4.02:计算一组卷积和池化层的输出形状
以下练习将结合卷积层和池化层。 目的是确定经过一组层后的输出矩阵的大小。
注意
此练习不需要编码,而是由基于我们前面提到的概念的计算组成。
考虑以下几组层,并在所有转换结束时指定输出层的形状,并考虑256 x 256 x 3的输入图像:
-
卷积层,具有 16 个大小为 3 的过滤器,步幅和填充为 1。
-
池化层还具有大小为 2 的过滤器以及大小为 2 的步幅。
-
卷积层,具有八个大小为 7 的过滤器,跨度为 1,填充为 3。
-
池化层,其过滤器的大小为 2,步幅也为 2。
经过每一层后,矩阵的输出大小如下:
-
在第一个卷积层之后:
output_width/height = ((256 – 3) + 2 * 1)/1 + 1 = 256 output_channels = 16 filters were applied output_matrix_size = 256 x 256 x 16 -
在第一个池化层之后:
output_width/height = (256 – 2) / 2 + 1 = 128 output_channels = 16 as pooling does not affect the number of channels output_matrix_size = 128 x 128 x 16 -
在第二个卷积层之后:
output_width/height = ((128 – 7) + 2 =* 3)/1 + 1 = 128 output_channels = 8 filters were applied output_matrix_size = 128 x 128 x 8 -
在第二个池化层之后:
output_width/height = (128 – 2) / 2 + 1 = 64 output_channels = 8 as pooling does not affect the number of channels output_matrix_size = 64 x 64 x 8
这样,您就成功地计算了从一系列卷积和池化层派生的矩阵的输出形状。
使用与以前相同的编码示例,以下代码片段展示了 PyTorch 定义池化层的方法:
import torch.nn as nn
import torch.nn.functional as F
class CNN_network(nn.Module):
def __init__(self):
super(CNN_network, self).__init__()
self.conv1 = nn.Conv2d(3, 18, 3, 1, 1)
self.pool1 = nn.MaxPool2d(2, 2)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool1(x)
return x
可以看出,在__init__方法中将池化层(MaxPool2d)添加到网络架构中。 在这里,进入最大池化层的参数从左到右分别是过滤器(2)和步幅(2)的大小。 接下来,更新了forward方法,以使信息通过新的合并层。
同样,这里显示了一种同样有效的方法,其中使用了自定义模块和顺序容器:
import torch.nn as nn
class CNN_network(nn.Module):
def __init__(self):
super(CNN_network, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(3, 18, 3, 1, 1),\
nn.ReLU(),\
nn.MaxPool2d(2, 2))
def forward(self, x):
x = self.conv1(x)
return x
正如我们之前提到的,池化层还包含在激活函数下方与卷积层相同的容器中。 在新的顺序容器中,下面将定义一组后续层(卷积,激活和池化)。
同样,forward方法不再需要单独调用每个层; 而是通过容器传递信息,该容器既包含层又包含激活函数。
全连接层
在输入经过一组卷积和池化层之后,在网络架构的末尾定义一个或多个 FC 层。 来自第一 FC 层之前的层的输出数据从矩阵展平为向量,可以将其馈送到 FC 层(与传统神经网络的隐藏层相同)。
这些 FC 层的主要目的是考虑先前层检测到的所有特征,以便对图像进行分类。
除非是最后一层,否则不同的 FC 层会通过一个激活函数(通常是 ReLU 函数)传递,除非它是最后一层,否则它将使用 softmax 函数来输出属于每个类标签的输入的概率。
第一 FC 层的输入大小对应于前一层的平坦输出矩阵的大小。 输出大小是由用户定义的,同样,与 ANN 一样,设置此数字没有确切的科学依据。 最后一个 FC 层的输出大小应等于类标签的数量。
要在 PyTorch 中定义一组 FC 层,请考虑以下代码片段:
import torch.nn as nn
import torch.nn.functional as F
class CNN_network(nn.Module):
def __init__(self):
super(CNN_network, self).__init__()
self.conv1 = nn.Conv2d(3, 18, 3, 1, 1)
self.pool1 = nn.MaxPool2d(2, 2)
self.linear1 = nn.Linear(32*32*16, 64)
self.linear2 = nn.Linear(64, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool1(x)
x = x.view(-1, 32 * 32 *16)
x = F.relu(self.linear1(x))
x = F.log_softmax(self.linear2(x), dim=1)
return x
使用与上一节相同的编码示例,在__init__方法内部,将两个 FC 层添加到网络。 接下来,在forward函数内部,使用view()函数将池化层的输出展平。 然后,它通过第一 FC 层,该层应用激活函数。 最后,数据连同其激活函数一起通过最终的 FC 层。
同样,使用与之前相同的编码示例,可以使用自定义模块和顺序容器将 FC 层添加到我们的模型中,如下所示:
import torch.nn as nn
class CNN_network(nn.Module):
def __init__(self):
super(CNN_network, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(1, 16, 5, 1, 2,), \
nn.ReLU(), \
nn.MaxPool2d(2, 2))
self.linear1 = nn.Linear(32*32*16, 64)
self.linear2 = nn.Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = x.view(-1, 32 * 32 *16)
x = F.relu(self.linear1(x))
x = F.log_softmax(self.linear2(x), dim=1)
return x
可以看出,顺序容器保持不变,并在__init__方法内在下面添加了两个 FC 层。 接下来,forward函数将信息传递通过整个容器,然后将输出平坦化以通过 FC 层。
一旦定义了网络的架构,就可以按照与 ANN 相同的方式来处理训练网络的以下步骤。
旁注–从 PyTorch 下载数据集
要从 PyTorch 加载数据集,请使用以下代码。 除了下载数据集之外,以下代码还显示了如何通过批量加载而不是一次加载图像来使用数据加载器来节省资源:
from torchvision import datasets
import torchvision.transforms as transforms
transform = \
transforms.Compose([transforms.ToTensor(), \
transforms.Normalize((0.5, 0.5, 0.5), \
(0.5, 0.5, 0.5))])
transforms变量用于定义要在数据集上执行的一组转换。 在这种情况下,数据集将被转换为张量并在其所有维度上进行规范化。
train_data = datasets.MNIST(root='data', train=True,\
download=True, transform=transform)
test_data = datasets.MNIST(root='data', train=False,\
download=True, transform=transform)
在前面的代码中,要下载的数据集是 MNIST。 这是一个流行的数据集,其中包含从零到九的手写灰度数字图像。 PyTorch 数据集提供训练和测试集。
从前面的代码片段可以看出,要下载数据集,有必要定义数据的根,默认情况下应将其定义为data。 接下来,定义您是要下载训练还是测试数据集。 我们将download参数设置为True。 最后,我们使用之前定义的transform变量对数据集执行转换:
dev_size = 0.2
idx = list(range(len(train_data)))
np.random.shuffle(idx)
split_size = int(np.floor(dev_size * len(train_data)))
train_idx, dev_idx = idx[split_size:], idx[:split_size]
考虑到我们需要第三组数据(验证组),前面的代码段用于将训练组划分为两组。 首先,定义验证集的大小,然后定义将用于每个数据集的索引列表(训练和验证集):
train_sampler = SubsetRandomSampler(train_idx)
dev_sampler = SubsetRandomSampler(dev_idx)
在前面的代码段中,PyTorch 的SubsetRandomSampler()函数用于通过随机采样索引将原始训练集分为训练集和验证集。 在接下来的步骤中将使用它来生成将在每次迭代中馈送到模型中的批量:
batch_size = 20
train_loader = torch.utils.data.DataLoader(train_data, \
batch_size=batch_size, \
sampler=train_sampler)
dev_loader = torch.utils.data.DataLoader(train_data, \
batch_size=batch_size, \
sampler=dev_sampler)
test_loader = torch.utils.data.DataLoader(test_data, \
batch_size=batch_size)
DataLoader()函数用于为每组数据批量加载图像。 首先,将包含集合的变量作为参数传递,然后定义批量大小。 最后,我们在上一步中创建的采样器用于确保随机创建每次迭代中使用的批量,这有助于提高模型的表现。 此函数的结果变量(train_loader,dev_loader和test_loader)将分别包含特征部分和目标的值。
注意
问题越复杂,网络越深,训练模型所需的时间就越长。 考虑到这一点,本章中的活动可能比上一章中的活动花费更长的时间。
活动 4.01:针对图像分类问题构建 CNN
在此活动中,将在来自 PyTorch 的图像数据集上训练 CNN(也就是说,框架提供了数据集)。 要使用的数据集是 CIFAR10,其中包含总共 60,000 张车辆和动物的图像。 有 10 个不同的类标签(例如“飞机”,“鸟”,“汽车”,“猫”等)。 训练集包含 50,000 张图像,而测试集包含剩余的 10,000 张图像。
注意
要进一步探索该数据集,请访问以下 URL。
让我们看一下我们的场景。 您在一家人工智能公司工作,该公司根据客户需求开发定制模型。 您的团队当前正在创建一个模型,该模型可以区分车辆的图像和动物的图像,更具体地说,可以识别不同种类的动物和不同类型的车辆。 他们为您提供了包含 60,000 张图像的数据集以构建模型。
注意
本章中的活动可能需要很长时间才能在常规计算机(CPU)上进行训练。 为了在 GPU 上运行代码,本书的 GitHub 存储库中的每个活动都有一个等效文件。
-
导入所需的库。
-
设置要对数据执行的转换,这将是数据到张量的转换以及像素值的归一化。
-
设置批量为 100 张图像,并从 CIFAR10 数据集下载训练和测试数据。
-
使用 20% 的验证大小,定义将用于将数据集分为这两组的训练和验证采样器。
-
使用
DataLoader()函数定义用于每组数据的批量。 -
定义您的网络架构。 使用以下信息来这样做:
Conv1:卷积层,将彩色图像作为输入,并将其通过大小为 3 的 10 个过滤器。应将 padding 和 stride 都设置为 1。
Conv2:一个卷积层,它将输入数据通过大小为 3 的 20 个过滤器传递。填充和跨距都应设置为 1。
Conv3:一个卷积层,它将输入数据通过大小为 3 的 40 个过滤器传递。填充和跨距都应设置为 1。
在每个卷积层之后使用 ReLU 激活函数。
每个卷积层之后的池化层,过滤器大小和跨度为 2。
展平图像后,滤除项设置为 20%。
Linear1:一个全连接层,接收上一层的展平矩阵作为输入,并生成 100 个单元的输出。 为此层使用 ReLU 激活函数。 此处,丢弃期限设置为 20%。
Linear2:一个全连接层,可生成 10 个输出,每个类标签一个。 将
log_softmax激活函数用于输出层。 -
定义训练模型所需的所有参数。 将周期数设置为 50。
-
训练您的网络,并确保保存训练和验证集的损失和准确率值。
-
绘制两组的损失和准确率。
-
在测试集上检查模型的准确率--它应该在 72% 左右。
注意
有关此活动的解决方案,请参见第 262 页。
由于数据在每个周期都经过重新排序,因此结果将无法完全重现。 但是,您应该能够获得与本书所获得的结果相似的结果。
这段代码可能需要一些时间才能运行,这就是为什么在本书的 GitHub 存储库中提供了等效的 GPU 版本解决方案的原因。
数据扩充
学习如何有效地编码神经网络是开发表现良好的解决方案所涉及的步骤之一。 此外,要开发出色的深度学习解决方案,至关重要的是找到一个感兴趣的领域,我们可以在其中提供解决当前挑战的解决方案。 但是一旦完成所有这些操作,我们通常会面临相同的问题:通过自收集或通过从互联网和其他可用来源下载来获得适当大小的数据集以从模型中获得良好的表现。
您可能会想到,即使现在可以收集和存储大量数据,但由于与之相关的成本,这并不是一件容易的事。 因此,在大多数情况下,我们只能处理包含数万个条目的数据集,而在引用图像时甚至更少。
在开发计算机视觉问题的解决方案时,这成为一个相关问题,主要是由于两个原因:
-
数据集越大,结果越好,并且更大的数据集对于获得足够好的模型至关重要。 考虑到训练模型是调整一堆参数的问题,以便能够映射输入和输出之间的关系,这是正确的。 这是通过最小化损失函数以使预测值尽可能接近基本事实来实现的。 在此,模型越复杂,所需的参数就越多。
考虑到这一点,有必要向模型提供大量示例,以便能够找到这样的模式,其中训练示例的数量应与要调整的参数的数量成比例。
-
计算机视觉问题中的最大挑战之一是使模型在图像的多种变体上都能表现良好。 这意味着图像不需要按照特定的对齐方式进行送入,也不必具有设定的质量,而是可以以其原始格式(包括不同的位置,角度,光照和其他变形)进行送入。 因此,有必要找到一种以这种变化提供模型的方法。
因此,设计了数据扩充技术。 简而言之,这是通过稍微修改现有示例来增加训练示例数量的一种措施。 例如,您可以复制当前可用的实例,并向这些重复项添加一些噪音以确保它们不完全相同。
在计算机视觉问题中,这意味着通过更改现有图像来增加训练数据集中的图像数量,这可以通过稍微更改当前图像以创建略有不同的重复版本来完成。
对图像的这些较小调整可以采取以下形式:轻微旋转,更改对象在帧中的位置,水平或垂直翻转,不同的配色方案以及变形等。 由于 CNN 将这些图像中的每一个视为不同图像,因此该技术行之有效。
例如,下图显示了一条狗的三幅图像,它们在人眼中是具有某些变化的同一幅图像,而在神经网络中却是完全不同的:

图 4.17:增强图像
能够识别图像中的物体而不管变化的 CNN 具有不变性。 实际上,CNN 对于每种类型的变化都可以是不变的。
PyTorch 数据扩充
使用Torchvision包在 PyTorch 中执行数据扩充非常容易。 该包除了包含流行的数据集和模型架构之外,还包含可以在数据集上执行的常见图像转换函数。
注意
在本节中,将提到其中一些图像转换。 要获取所有可能的转换的完整列表,请访问这里。
与在上一活动中使用的过程一样,将数据集归一化并将其转换为张量,执行数据扩充需要我们定义所需的转换,然后将其应用于数据集,如以下代码片段所示:
transform = transforms.Compose([\
transforms.HorizontalFlip(probability_goes_here),\
transforms.RandomGrayscale(probability_goes_here),\
transforms.ToTensor(),\
transforms.Normalize((0.5, 0.5, 0.5), \
(0.5, 0.5, 0.5))])
train_data = datasets.CIFAR10('data', train=True, \
download=True, transform=transform)
test_data = datasets.CIFAR10('data', train=False, \
download=True, transform=transform)
在这里,使用HorizontalFlip函数,将要下载的数据将进行水平翻转(考虑用户设置的概率值,并确定将进行此变换的图像的百分比)。 通过使用RandomGrayscale函数,图像将被转换为灰度(还考虑了概率)。 然后,将数据转换为张量并进行规范化。
考虑到模型是在迭代过程中进行训练的,其中多次输入训练数据,因此这些转换可确保第二次遍历数据集不会将完全相同的图像馈入模型。
此外,可以为不同的集合设置不同的变换。 这很有用,因为数据扩充的目的是增加训练示例的数量,但是用于测试模型的图像应基本保持不变。 但是,应该调整测试集的大小,以便将大小相等的图像输入模型。
这可以通过以下方式完成:
transform = {"train": \
transforms.Compose([transforms.RandomHorizontalFlip\
(probability_goes_here),\
transforms.RandomGrayscale\
(probability_goes_here),\
transforms.ToTensor(),\
transforms.Normalize\
((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]), \
"test": transforms.Compose([transforms.ToTensor(),\
transforms.Normalize\
((0.5, 0.5, 0.5), \
(0.5, 0.5, 0.5)),\
transforms.Resize(size_goes_here)])}
train_data = datasets.CIFAR10('data', train=True, download=True, \
transform=transform["train"])
test_data = datasets.CIFAR10('data', train=False, download=True, \
transform=transform["test"]
如我们所见,定义了一个字典,其中包含用于训练和测试集的一组转换。 然后,可以调用字典以将转换相应地应用于每个集合。
活动 4.02:图像数据扩充
在此活动中,数据扩充将引入到我们在上一个活动中创建的模型中,以测试其准确率是否可以提高。 让我们看一下以下情况。
您创建的模型不错,但是其准确率达不到期望的水平。 您被要求考虑一种可以改善模型表现的方法。 请按照以下步骤完成此活动:
-
复制上一个活动中的笔记本。
-
修改
transform变量的定义,使其除了将数据归一化并转换为张量外,还包括以下转换:对于训练/验证集,
RandomHorizontalFlip函数的概率为 50%(0.5),RandomGrayscale函数的概率为 10%(0.1)。对于测试集,请勿添加任何其他转换。
-
训练模型 100 个周期。由此得到的训练集和验证集的损失和准确率图应与这里所示的相似。
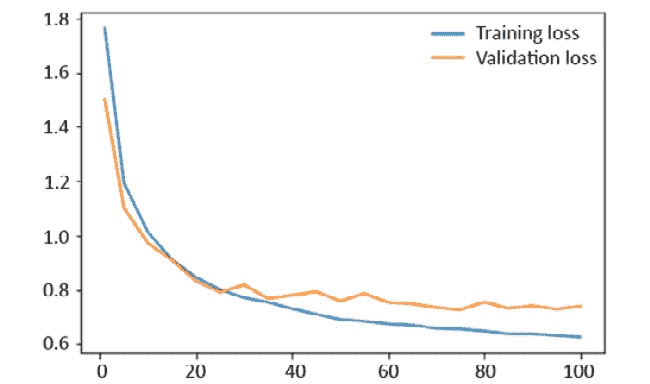
图 4.18:结果图显示集合的损失
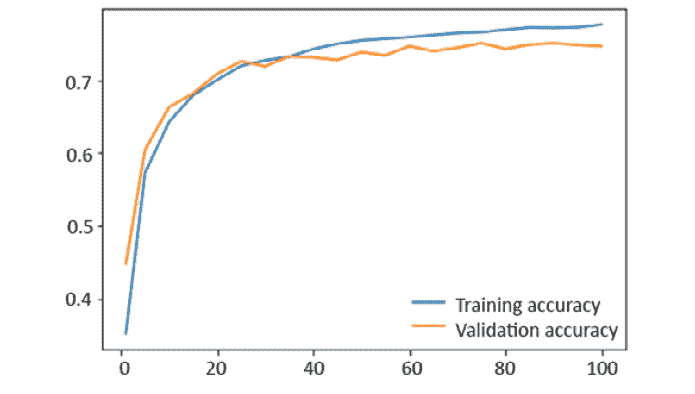
图 4.19:结果图显示了集合的准确率
注意
由于每个周期的数据打乱,结果将无法精确再现。 但是,您应该能够得到类似的结果。
-
计算测试集上所得模型的准确率。
预期输出:模型在测试集上的表现应为 75% 左右。
注意
此活动的解决方案可以在第 272 页上找到。
这段代码可能需要一些时间才能运行,这就是为什么在本书的 GitHub 存储库中提供了等效的 GPU 版本解决方案的原因。
批量归一化
通常会标准化输入层,以尝试加快学习速度,并通过将所有特征重新缩放为相同比例来提高性能。 因此,问题是,如果模型受益于输入层的归一化,为什么不对所有隐藏层的输出进行归一化以进一步提高训练速度呢?
批量归一化顾名思义,是对隐藏层的输出进行归一化,以便减小每个层的方差,也称为协方差平移。 协方差偏移的这种减小是有用的,因为它使模型也可以在遵循与用于训练它的图像不同的分布的图像上很好地工作。
例如,以检测动物是否为猫为目的的网络为例。 当仅使用黑猫的图像训练网络时,批量归一化可以通过对数据进行归一化来帮助网络对不同颜色的猫的新图像进行分类,以便黑猫和彩色猫的图像都遵循相似的分布。 下图表示了这样的问题:

图 4.20:猫分类器-即使仅使用黑猫训练后,模型也可以识别有色猫
此外,批量归一化为模型的训练过程带来了以下好处,最终可以帮助您获得表现更好的模型:
-
它允许设置更高的学习率,因为批量归一化有助于确保任何输出都不是太高或太低。 更高的学习率等同于更快的学习时间。
-
它有助于减少过拟合,因为它具有正则化效应。这使得可以将丢弃概率设置为一个较低的值,这意味着在每个前向通道中忽略的信息较少。
注意
我们不应该主要依靠批量归一化来处理过拟合。
如前几节所述,通过减去批量平均值并除以批量标准差,可以对隐藏层的输出进行归一化。
此外,通常在卷积层以及 FC 层(不包括输出层)上执行批归一化。
PyTorch 批量归一化
在 PyTorch 中,考虑到有两种不同的类型,添加批归一化就像向网络架构添加新层一样简单,如下所述:
BatchNorm1d:此层用于在二维或三维输入上实现批量标准化。 它从上一层接收输出节点的数量作为参数。 这通常在 FC 层上使用。BatchNorm2d:这将批量归一化应用于四维输入。 同样,它采用的参数是上一层输出节点的数量。 它通常在卷积层上使用,这意味着它接受的参数应等于上一层的通道数。
据此,在 CNN 中批量标准化的实现如下:
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 3, 1, 1)
self.norm1 = nn.BatchNorm2d(16)
self.pool = nn.MaxPool2d(2, 2)
self.linear1 = nn.Linear(16 * 16 * 16, 100)
self.norm2 = nn.BatchNorm1d(100)
self.linear2 = nn.Linear(100, 10)
def forward(self, x):
x = self.pool(self.norm1(F.relu(self.conv1(x))))
x = x.view(-1, 16 * 16 * 16)
x = self.norm2(F.relu(self.linear1(x)))
x = F.log_softmax(self.linear2(x), dim=1)
return x
如我们所见,批量规范化层的初始定义与__init__方法内的其他任何层类似。 接下来,在forward方法内的激活函数之后,将每个批量归一化层应用于其对应层的输出。
活动 4.03:实现批量归一化
对于此活动,我们将在前一个活动的架构上实现批量归一化,以查看是否有可能进一步提高测试集上模型的表现。 让我们看一下以下情况。
您在表现方面所做的最后改进使您的队友印象深刻,现在他们对您的期望更高。 他们要求您最后一次尝试改进模型,以使准确率提高到 80%。 请按照以下步骤完成此活动:
-
复制上一个活动中的笔记本。
-
将批量归一化添加到每个卷积层以及第一个 FC 层。
-
训练模型 100 个周期。由此得到的训练集和验证集的损失和准确率图应该与这里的图相似。
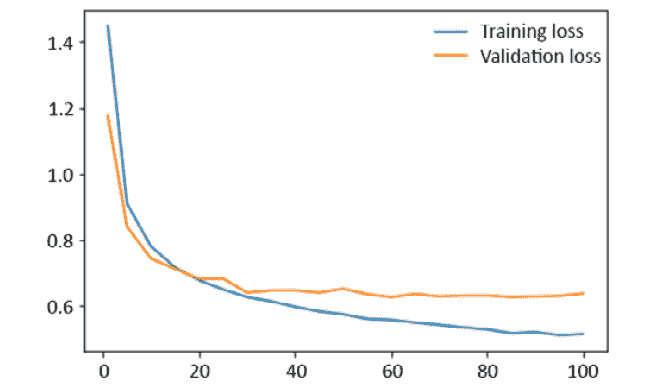
图 4.21:结果图显示了集合的损失
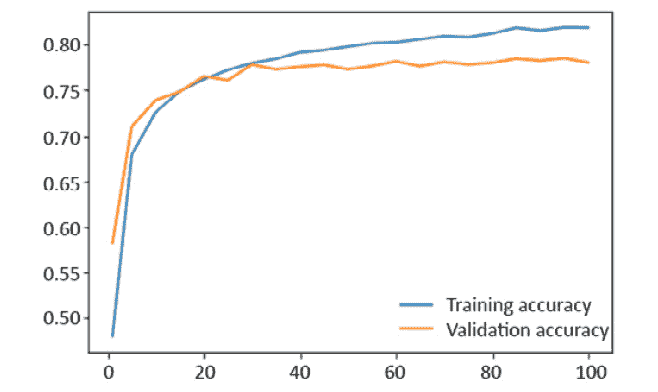
图 4.22:结果图显示了集合的损失
-
计算结果模型在测试集上的准确率--它应该是 78% 左右。
注意
此活动的解决方案可以在第 274 页上找到。
由于在每个周期对数据进行混洗,结果将无法完全重现。 但是,您应该能够获得与本书所获得的结果相似的结果。
这段代码可能需要一些时间才能运行,这就是为什么在本书的 GitHub 存储库中提供了等效的 GPU 版本解决方案的原因。
总结
本章重点介绍 CNN,它由一种在计算机视觉问题上表现出色的神经网络架构组成。 我们首先说明了为何广泛使用 CNN 来处理图像数据集的主要原因,并介绍了可以通过使用它们解决的不同任务。
本章通过解释卷积层,池化层以及最后的 FC 层的性质,说明了网络架构的不同构建块。 在每个部分中,都包括对每个层目的的解释,以及可用于有效编码 PyTorch 中的架构的代码段。
这导致引入了图像分类问题,该问题着重于对车辆和动物的图像进行分类。 这个问题的目的是将 CNN 的不同构建块付诸实践,以解决图像分类数据问题。
接下来,数据扩充被引入为一种工具,它通过增加训练示例的数量来提高网络表现,而无需收集更多图像。 该技术专注于创建现有图像的变体,以创建要馈送到模型的“新”图像。
通过实现数据扩充,本章的第二个活动旨在解决相同的图像分类问题,目的是比较结果。
最后,本章介绍了批量规范化的概念。 这包括标准化每个隐藏层的输出,以加快学习速度。 在解释了在 PyTorch 中应用批量归一化的过程之后,本章的最后一个活动旨在使用批量归一化解决相同的图像分类问题。
既然 CNN 的概念已经很清楚并且已经应用于解决计算机视觉问题,那么在下一章中,我们将探索 CNN 更加复杂的应用来创建图像,而不仅仅是对其进行分类。
五、样式迁移
概述
本章介绍了使用预训练的模型来创建或利用表现良好的算法而不必收集大量数据的过程。 在本章中,您将学习如何从 PyTorch 加载预训练的模型以创建样式迁移模型。 到本章末,您将能够通过使用预训练的模型来执行样式迁移。
简介
上一章介绍了传统 CNN 的不同构建块,以及一些改进其表现并减少训练时间的技术。 此处说明的架构虽然很典型,但并不是一成不变的,并且出现了许多 CNN 架构来解决不同的数据问题,这在计算机视觉领域最为普遍。
这些架构的配置和学习任务各不相同。 如今,由牛津机器人学院的 Karen Simonyan 和 Andrew Zisserman 创建的视觉几何组(VGG)架构是一种非常流行的方法。 它是为对象识别而开发的,并由于网络所依赖的大量参数而达到了最先进的表现。 它在数据科学家中受欢迎的主要原因之一是训练后的模型的参数(权重和偏差)的可用性,这使研究人员无需训练即可使用它,并且模型具有出色的表现。
在本章中,我们将使用这种经过预训练的模型来解决计算机视觉问题,该问题由于专门用于共享图像的社交媒体渠道的普及而特别著名。 它包括执行样式迁移,以便使用一个图像的样式(颜色和纹理)以及另一个图像的内容(形状和对象)创建新图像。
每天对常规图像应用过滤器以提高其质量和吸引力,同时在社交媒体个人资料上发布时,每天执行数百万次此任务。 尽管这看起来很简单,但本章将解释这些图像编辑应用幕后发生的魔术。
注意
样式迁移
简而言之,样式迁移包括修改图像的样式,同时又保留其内容。 一个示例是拍摄动物的图像,然后将样式迁移为类似莫奈的绘画,如下图所示:
图 5.1:样式迁移输入和输出–本章最后练习的结果
注意
可以在 GitHub 上找到此图像。
根据前面的图像,模型有两个输入:内容图像和样式图像。 内容是指图像的对象,而样式是指颜色和纹理。 结果,模型的输出应该是包含内容图像中的对象和样式图像的艺术外观的图像。
它如何工作?
与解决上一章中说明的传统计算机视觉问题相反,样式迁移需要一组不同的步骤才能有效地将两个图像作为输入并创建一个新图像作为输出。
以下是解决样式迁移问题时要遵循的步骤的简要说明:
-
馈入输入:内容和样式图像都将馈入模型,并且它们必须具有相同的形状。 这里的常见做法是调整样式图像的大小,以使其与内容图像具有相同的形状。
-
加载模型:牛津大学的 VGG 创建了一个模型架构,该模型在样式迁移问题上表现出色,被称为 VGG 网络。 他们还将模型的参数提供给任何人,以便可以缩短或跳过模型的训练过程(这就是预训练模型的目的)。
注意
VGG 网络有不同的版本,并且都使用不同数量的层。 为了区分不同的版本,术语是这样的,即首字母缩写处的破折号和数字代表该特定架构的层数。 在本章中,我们将使用网络的 19 层版本,即 VGG-19。
因此,可以使用 PyTorch 的模型子包加载预训练的模型,以执行样式迁移任务,而无需训练大量图像的网络。
-
确定层的函数:鉴于手头有两项主要任务(识别图像的内容并区分另一幅图像的样式),不同的层将具有不同的函数来提取不同的特征。 对于样式图像,重点应该放在颜色和纹理上,对于内容图像,重点应该放在边缘和形状上。 在此步骤中,将不同的层分为不同的任务。
-
定义优化问题:与其他任何监督问题一样,有必要定义一个损失函数,该函数将负责测量输出和输入之间的差异。 与其他受监督的问题不同,样式迁移的任务要求您定义三个不同的损失函数,在训练过程中应将所有这些损失最小化。 这里介绍了三种损失函数:
内容损失:这仅在考虑与内容相关的特征的情况下测量内容图像与输出之间的距离。
样式损失:这仅在考虑与样式相关的特征时测量样式图像与输出之间的距离。
总损失:这结合了内容损失和样式损失。 两种损失都具有与之相关的权重,该权重用于确定它们参与总损失的计算。
-
参数更新:此步骤使用梯度来更新模型的不同参数。
使用 VGG-19 网络架构实现样式迁移
VGG-19 是由 19 层组成的 CNN。 它使用 ImageNet 数据库中的数百万张图像进行了训练。 该网络能够将图像分类为 1,000 种不同的类别标签,其中包括大量的动物和不同的工具。
注意
要浏览 ImageNet 数据库,请访问以下 URL。
考虑到其深度,该网络能够从各种图像中识别出复杂的特征,这使其特别适用于样式迁移问题,在这些问题中,特征提取对于不同阶段和不同目的至关重要。
本节将重点介绍如何使用预训练的 VGG-19 模型执行样式迁移。 本章的最终目标将是拍摄动物或风景的图像(作为内容图像)以及来自知名艺术家的一幅画(作为样式图像)以创建常规对象的新图像。 具有艺术风格。
但是,在进行此过程之前,以下是导入的列表以及其使用的简要说明:
-
NumPy:这将用于转换要显示的图像。
-
Torch:
torch.nn和torch.optim:它们将实现神经网络并定义优化算法。 -
PIL.Image:将按照以下代码片段加载图像:image = Image.open(image_name) image = transformation(image).unsqueeze(0)可以看出,第一步包括打开图像(此处,
image_name应该替换为图像的路径)。 接下来,可以将先前定义的任何变换应用于图像。注意
为了提醒您如何定义图像的变换,请重新访问“第 4 章”,“卷积神经网络”。
unsqueeze()函数用于根据将图像馈送到 VGG-19 模型的要求向图像添加额外的尺寸。 -
matplotlib.pyplot:这将显示图像。 -
torchvision.transforms和torchvision.models:将图像转换为张量并加载预训练的模型。
输入–加载和显示
执行样式迁移的第一步包括加载内容和样式图像。 在此步骤中,将处理基本的预处理,其中图像必须具有相同的大小(最好是用于训练预训练模型的图像的大小),该大小也将等于输出图像的大小。 此外,图像会转换为 PyTorch 张量,并且可以根据需要进行归一化。
最好始终显示已加载的图像,以确保它们符合要求。 考虑到此时图像已被转换为张量并进行了规范化,应该克隆张量,并且需要执行一组新的转换,以便我们可以使用 Matplotlib 显示它们。 这意味着张量应转换回 Python 图像库(PIL)图像,并且必须还原规范化过程,如以下示例所示:
image = tensor.clone()
image = image.squeeze(0)
img_display = \
transforms.Compose([transforms.Normalize((-0.5/0.25, \
-0.5/0.25, -0.5/0.25), \
(1/0.25, 1/0.25, \
1/0.25)), \
transforms.ToPILImage()])
首先,张量被克隆,附加维被删除。 接下来,定义转换。
要了解恢复归一化的过程,请考虑使用所有尺寸的均值 0.5 和标准差 0.25 进行归一化的图像。 恢复标准化的方法是使用平均值的负值除以标准差作为平均值(-0.5 除以 0.25)。 新的标准差应等于一除以标准差(1 除以 0.25)。 定义用于加载和显示图像的函数可以帮助节省时间,并确保对内容图像和样式图像执行相同的过程。 在下面的练习中将扩展此过程。
注意
本章的所有练习都应在同一笔记本中进行编码,合并后的代码将一起执行样式迁移任务。
练习 5.01:加载和显示图像
这是执行样式迁移的四个步骤中的第一步。 本练习的目的是加载并显示将在以后的练习中使用的图像(内容和样式图像)。 请按照以下步骤完成此练习:
注意
对于本章中的练习和活动,您将需要安装 Python 3.7,Jupyter 6.0,Matplotlib 3.1,NumPy 1.17,Pillow 6.2 和 PyTorch 1.3+(最好是 PyTorch 1.4,有或没有 CUDA)(如“前言”)。
在本书的 GitHub 存储库中,您将能够找到在本章中用于不同练习和活动的不同图像。
-
导入执行样式迁移所需的所有包:
import numpy as np import torch from torch import nn, optim from PIL import Image import matplotlib.pyplot as plt from torchvision import transforms, models如果有可用的 GPU,请定义一个名为
device的变量,该变量等于cuda,该变量将用于为您的计算机的 GPU 分配一些变量:device = "cuda" device -
设置用于两个图像的图像尺寸。 另外,设置要在图像上执行的转换,这应该包括调整图像的大小,将它们转换为张量以及对其进行规范化:
imsize = 224 loader = transforms.Compose([\ transforms.Resize(imsize), \ transforms.ToTensor(), \ transforms.Normalize((0.485, 0.456, 0.406), \ (0.229, 0.224, 0.225))])使用此代码,可以将图像调整为与最初用于训练 VGG-19 模型的图像相同的大小。 归一化也使用与归一化训练图像相同的值进行。
注意
使用规范化图像训练 VGG 网络,其中每个通道的平均值分别为 0.485、0.456 和 0.406,标准差分别为 0.229、0.224 和 0.225。
-
定义一个函数,该函数将接收图像路径作为输入,并使用
PIL打开图像。 接下来,应将转换应用于图像:def image_loader(image_name): image = Image.open(image_name) image = loader(image).unsqueeze(0) return image -
调用该函数以加载内容和样式图像。 将狗图像用作内容图像,将 Matisse 图像用作样式图像,这两者都可以在本书的 GitHub 存储库中找到:
content_img = image_loader("images/dog.jpg") style_img = image_loader("images/matisse.jpg")如果您的计算机有可用的 GPU,请改用以下代码段以达到相同的结果:
content_img = image_loader("images/dog.jpg").to(device) style_img = image_loader("images/matisse.jpg").to前面的代码片段将保存图像的变量分配给 GPU,以便使用这些变量的所有操作都由 GPU 处理。
-
调用该函数以加载内容和样式图像。 将狗图像用作内容图像,将 Matisse 图像用作样式图像,这两者都可以在本书的 GitHub 存储库中找到:...
unloader = transforms.Compose([\ transforms.Normalize((-0.485/0.229, \ -0.456/0.224, \ -0.406/0.225), \ (1/0.229, 1/0.224, 1/0.225)),\ transforms.ToPILImage()]) -
创建一个函数来克隆张量,压缩张量,并将上一步中定义的转换应用于张量:
def tensor2image(tensor): image = tensor.clone() image = image.squeeze(0) image = unloader(image) return image如果您的计算机具有可用的 GPU,请改用以下等效代码段:
def tensor2image(tensor): image = tensor.to('cpu').clone() image = image.squeeze(0) image = unloader(image) return image前面的代码片段将图像分配回 CPU,以便我们可以绘制它们。
-
调用两个图像的函数并绘制结果:
plt.figure() plt.imshow(tensor2image(content_img)) plt.title("Content Image") plt.show() plt.figure() plt.imshow(tensor2image(style_img)) plt.title("Style Image") plt.show()生成的图像应如下所示:

图 5.2:内容图像

图 5.3:样式图像
注意
要访问此特定部分的源代码,请参考这里。
您也可以通过这里在线运行此示例。 您必须执行整个笔记本才能获得所需的结果。
要访问此源代码的 GPU 版本,请参考这里。 此版本的源代码无法作为在线交互示例使用,需要通过 GPU 设置在本地运行。
这样,您已经成功加载并显示了用于样式迁移的内容和样式图像。
载入模型
像在许多其他框架中一样,PyTorch 有一个子包,其中包含不同的模型,这些模型先前已经过训练并可供公众使用。 考虑到从头开始训练神经网络非常耗时,这一点很重要。 从预先训练的模型开始可以帮助减少训练时间。 这意味着可以加载经过预训练的模型,以便我们可以使用它们的最终参数(应该是使损失函数最小的参数),而无需经过迭代过程。
如前所述,用于执行样式迁移任务的架构是 19 层 VGG 网络的架构,也称为 VGG-19。 在torchvision的model子包下提供了预训练的模型。 在 PyTorch 中保存的模型分为两部分:
-
vgg19.features:这包括网络的所有卷积和池化层以及参数。 这些层负责从图像中提取特征。 有些层专门用于样式特征(例如颜色),而另一些层则专门用于内容特征(例如边缘)。 -
vgg19.classifier:这是指位于网络末端的线性层(也称为全连接层),包括其参数。 这些层是将图像分类为标签类别之一的层,例如,识别图像中的动物类型。注意
要探索 PyTorch 中可用的其他预训练模型,请访问这里。
根据前面的信息,仅应加载模型的特征部分,以便提取内容和样式图像的必要特征。 加载模型包括调用model子包,然后调用模型名称,并确保将pretrained参数设置为True(为了加载先前训练过程中的参数),并按照以下代码片段仅加载特征层:
model = models.vgg19(pretrained=True).features
考虑到那些将有助于检测所需特征的参数,每层中的参数(权重和偏差)应保持不变。 这可以通过定义模型不需要为任何这些层计算梯度来实现,如下所示:
for param in model.parameters():
param.requires_grad_(False)
在这里,对于先前加载的模型的每个参数,为了避免计算梯度, require_grad_方法设置为False,因为目标是利用预先训练的参数,而不更新它们。
练习 5.02:在 PyTorch 中加载预先训练的模型
使用与上一练习相同的笔记本,本练习旨在加载预先训练的模型,该模型将在后续练习中使用我们先前加载的图像执行样式迁移任务。
-
打开上一个练习中的笔记本。
-
从 PyTorch 加载 VGG-19 预训练模型:
model = models.vgg19(pretrained=True).feature如前所述,选择模型的特征部分。 这将使您能够访问模型的所有卷积和池化层,这些层将用于在本章的后续练习中提取特征。
-
通过先前加载的模型的参数执行
for循环。 设置每个参数,使其不需要进行梯度计算:for param in model.parameters(): param.requires_grad_(False)通过将梯度计算设置为
False,我们确保在训练过程中不计算梯度。如果您的计算机具有可用的 GPU,则将以下代码段添加到前面的代码段中,以便将模型分配给 GPU:
model.to(device)注意
要访问此特定部分的源代码,请参考这里。
您也可以通过这里在线运行此示例。 您必须执行整个笔记本才能获得所需的结果。
要访问此源代码的 GPU 版本,请参考这里。 此版本的源代码无法作为在线交互示例使用,需要通过 GPU 设置在本地运行。
这样,您已经成功加载了预训练的模型。
提取特征
正如我们前面提到的,VGG-19 网络包含 19 个不同的层,包括卷积,池化和全连接层。 卷积层在每个池化层之前先进入栈,其中五个是整个架构中的栈数。
在样式迁移领域,已经有不同的论文确定了对于识别内容和样式图像上的相关特征至关重要的那些层。 因此,常规上接受的是,每个栈的第一卷积层都能够提取样式特征,而仅第四栈的第二卷积层应用于提取内容特征。
从现在开始,我们将提取样式特征的层称为conv1_1,conv2_1,conv3_1,conv4_1和conv5_1,而负责提取内容特征的层将被称为conv4_2。
注意
这意味着样式图像的特征是从五个不同的层获得的,而内容图像的特征是仅从一层获取的。 每个层的输出都用于将输出图像与输入图像进行比较,目的是修改目标图像的参数,使其与内容图像的内容和样式图像的样式相似, 可以通过优化三个不同的损失函数来实现(将在本章中进一步说明)。
要提取每个层的特征,可以使用以下代码片段:
layers = {'0': 'conv1_1', '5': 'conv2_1', '10': 'conv3_1', \
'19': 'conv4_1', '21': 'conv4_2', '28': 'conv5_1'}
features = {}
x = image
for index, layer in model._modules.items():
x = layer(image)
if index in layers:
features[layers[index]] = x
在前面的代码段中,layers是一个字典,将所有相关层的位置(在网络中)映射到将用于识别它们的名称以及model._modules包含保存网络各层的字典。
通过使用循环遍历不同层,我们将图像传递到不同层,并保存感兴趣的层的输出(我们先前创建的layers词典中的层) 进入features词典。 输出字典由包含层名称的键和包含该层的输出特征的值组成。
为了确定目标图像是否包含与内容图像相同的内容,我们需要检查两个图像中是否存在某些特征。 但是,为了检查目标图像和样式图像的样式表示,必须检查相关性而不是两个图像的特征是否严格存在。 这是因为两个图像的样式特征都不精确,而是近似的。
语法矩阵用于检查这些相关性。 它包括创建一个矩阵,该矩阵查看给定层中不同样式特征的相关性。 这是通过将卷积层的向量化输出乘以相同的转置向量化输出来完成的,如下图所示:
图 5.4:克矩阵的计算
在上图中,A表示具有4x4尺寸(高度和宽度)的输入样式图像,而B表示将图像通过具有五个过滤器的卷积层后的输出。 最后,C表示语法矩阵的计算,其中左侧的图像表示B的向量化版本,右侧的图像是其转置版本。 从向量化输出的乘法中,创建一个5x5 Gram 矩阵,其值表示沿不同通道(过滤器)的样式特征方面的相似性(相关性)。
这些相关性可以用于确定与图像的样式表示相关的那些特征,然后可以将其用于更改目标图像。 考虑到在五个不同的层中获得了样式特征,可以安全地假定网络能够从样式图像中检测大小特征,并考虑到必须为每个层创建一个 gram 矩阵。
练习 5.03:设置特征提取过程
使用上一练习的网络架构和本章第一练习的图像,我们将创建几个函数,这些函数能够从输入图像中提取特征并为样式特征创建语法矩阵。
-
打开上一个练习中的笔记本。
-
打印我们在上一个练习中加载的模型的架构。 这将帮助我们识别相关层,以便我们可以执行样式迁移任务:
print(model) -
创建一个字典,用于将相关层的索引(键)映射到名称(值)。这将方便将来调用相关层的过程。
relevant_layers = {'0': 'conv1_1', '5': 'conv2_1', '10': \ 'conv3_1', '19': 'conv4_1', '21': \ 'conv4_2', '28': 'conv5_1'}要创建字典,我们使用上一步的输出,该输出显示网络中的每个层。 在那里,可以观察到第一堆叠的第一层标记为
0,而第二堆叠的第一层标记为5,依此类推。 -
创建一个函数,从输入图像中提取相关特征(仅从相关层中提取的特征)。将其命名为
features_extractor,并确保它将图像、模型和我们之前创建的字典作为输入。def features_extractor(x, model, layers): features = {} for index, layer in model._modules.items(): x = layer(x) if index in layers: features[layers[index]] = x return features输出应该是字典,键是层的名称,值是该层的输出特征。
-
在我们在本章第一个练习中加载的内容和样式图片上调用
features_extractor函数。
content_features = features_extractor(content_img, model, \
relevant_layers)
style_features = features_extractor(style_img, model, \
relevant_layers)
-
在风格特征上进行 Gram 矩阵计算。考虑到风格特征是从不同的层中获得的,这就是为什么要创建不同的克矩阵,每个层的输出都有一个。
style_grams = {} for i in style_features: layer = style_features[i] _, d1, d2, d3 = layer.shape features = layer.view(d1, d2 * d3) gram = torch.mm(features, features.t()) style_grams[i] = gram对于每一层,都将获得样式特征矩阵的形状以对其进行向量化。 接下来,通过将向量化输出乘以其转置版本来创建 gram 矩阵。
-
创建一个初始目标图像。该图像将在以后与内容和风格图像进行比较,并进行更改,直到达到所需的相似度。
target_img = content_img.clone().requires_grad_(True)优良作法是将初始目标图像创建为内容图像的副本。 此外,考虑到我们希望能够在迭代过程中对其进行修改,直到内容与内容图像的内容和样式与样式图像的相似为止,将其设置为需要梯度计算至关重要。
同样,如果您的计算机具有可用的 GPU,请确保同时使用以下代码段将目标图像分配给 GPU:
target_img = content_img.clone().requires_grad_(True).to(device) -
使用我们在本章第一个练习中创建的
tensor2image函数,绘制目标图像,它看起来应该和内容图像一样。plt.figure() plt.imshow(tensor2image(target_img)) plt.title("Target Image") plt.show()输出图像如下:
图 5.5:目标图像
注意
要访问此特定部分的源代码,请参考这里。
您也可以通过这里在线运行此示例。 您必须执行整个笔记本才能获得所需的结果。
要访问此源代码的 GPU 版本,请参考这里。 此版本的源代码无法作为在线交互示例使用,需要通过 GPU 设置在本地运行。
这样,您就成功完成了特征提取并计算了语法矩阵来执行样式迁移。
优化算法,损失和参数更新
尽管使用参数不变的预训练网络执行样式迁移,但是创建目标图像包含一个迭代过程,在此过程中,通过仅更新与目标图像有关的参数来计算并最小化三个不同的损失函数。
为了实现目标图像的创建,需要计算两个不同的损失函数(内容损失和样式损失),然后将它们放在一起以计算总损失函数,该函数将被优化以得到合适的目标图像。 但是,考虑到在内容和样式方面实现的测量精度差异很大,下面是对内容和样式损失函数的计算的说明,以及如何计算总损失的说明。
内容损失
它由一个函数组成,该函数基于给定层获得的特征映射来计算内容图像和目标图像之间的距离。 在 VGG-19 网络的情况下,仅根据conv4_2层的输出来计算内容损失。
内容损失函数背后的主要思想是最小化内容图像和目标图像之间的距离,以便后者在内容方面与前者高度相似。
内容损失可以计算为相关层的内容和目标图像的特征映射之间的均方差(conv4_2),可以使用以下公式实现:
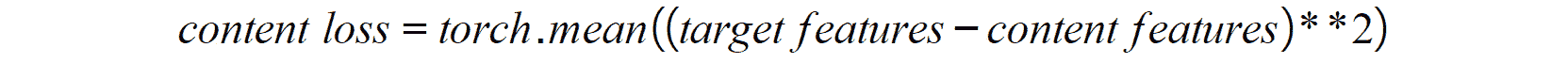
图 5.6:内容损失函数
样式损失
与内容损失类似,样式损失是一项函数,可通过计算均方差来衡量样式特征(例如颜色和纹理)方面的样式与目标图像之间的距离。
与内容损失的情况相反,它不比较从不同层派生的特征映射,而是比较根据样式和目标图像的特征映射计算出的语法矩阵。
必须使用循环为所有相关层(在本例中为五层)计算样式损失。 这将导致损失函数考虑来自两个图像的简单和复杂样式表示。
此外,优良作法是将这些层中每个层的样式表示权衡在 0 到 1 之间,以便比提取非常复杂特征的层更多地强调提取更大和更简单特征的层。 这是通过为较早的层(conv1_1和conv2_1)赋予更高的权重来实现的,这些层从样式图像中提取了更多的通用特征。
对于每个相关层,可以使用以下方程式来计算样式损失:
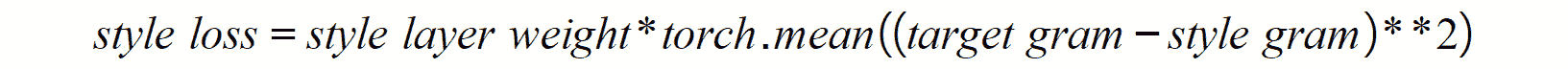
图 5.7:样式损失计算
总损失
最后,总损失函数由内容损失和样式损失共同组成。 通过更新目标图像的参数,在创建目标图像的迭代过程中将其值最小化。
同样,建议您为内容和样式损失分配权重,以确定它们是否参与最终输出。 这有助于确定目标图像样式化的程度,同时使内容仍然可见。 优良作法是将内容损失的权重设置为 1,而样式损失的权重必须更高,才能达到您的喜好比例。
分配给内容损失的权重通常称为alpha,而赋予样式损失的权重称为beta。
计算总损失的最终公式如下:
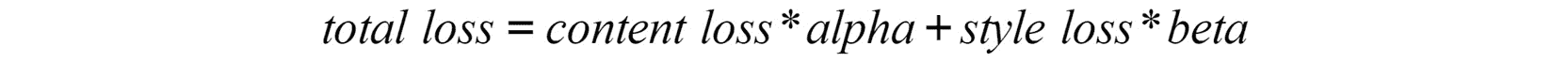
图 5.8:总损失计算
一旦确定了损失的权重,就可以设置迭代步骤的数量以及优化算法了,这只会影响目标图像。 这意味着,在每个迭代步骤中,将计算所有三个损失,以便我们可以使用梯度来优化与目标图像相关的参数,直到损失函数最小化并获得具有所需外观的目标图像为止。
与以前的神经网络的优化一样,以下是每次迭代中可以观察到的步骤:
- 从目标图像获取内容和样式方面的特征。 在初始迭代中,此图像将是内容图像的精确副本。
- 计算内容损失。 这是通过比较内容和目标图像的内容特征映射来完成的。
- 计算所有相关层的平均样式损失。 这是通过比较样式图像和目标图像所有层的 gram 矩阵来实现的。
- 计算总损失。
- 计算总损失函数相对于目标图像参数(权重和偏差)的偏导数。
- 重复此过程,直到达到所需的迭代次数。
最终输出将是内容与内容图像相似且样式与样式图像相似的图像。
练习 5.04:创建目标图像
在本章的最后练习中,您将执行样式迁移的任务。 该练习包括对负责执行不同迭代的部分进行编码,同时优化损失函数,以便获得理想的目标图像。 为此,至关重要的是利用我们在本章前面的练习中编程的代码位:
注意
在 GPU 上运行此代码时,需要进行一些更改。 请访问本书的 GitHub 存储库以修改此代码的 GPU 版本。
-
打开上一个练习中的笔记本。
-
定义一个字典,包含负责提取风格特征的每个层的权重。
style_weights = {'conv1_1': 1., 'conv2_1': 0.8, 'conv3_1': 0.6, \ 'conv4_1': 0.4, 'conv5_1': 0.2}确保使用与上一个练习中的层相同的名称作为键。
-
定义与内容和风格损失相关的权重。
alpha = 1 beta = 1e5 -
定义迭代步数,以及优化算法。如果我们想看到当时已经创建的图像的图,也可以设置迭代次数。
print_statement = 200 optimizer = torch.optim.Adam([target_img], lr=0.001) iterations = 2000该优化算法要更新的参数应该是目标图像的参数。
注意
如本练习中的示例所示,运行 2,000 次迭代将花费相当长的时间,具体取决于您的资源。 但是,为了获得出色的目标图像,可能需要更多的迭代。
为了使您理解每次迭代中目标图像发生的变化,可以进行几次迭代,但是建议您尝试更长的训练时间。
-
定义
for循环,在这个循环中,将计算所有三个损失函数,并执行优化过程。for i in range(1, iterations+1): # Extract features for all relevant layers target_features = features_extractor(target_img, model, \ relevant_layers) # Calculate the content loss content_loss = torch.mean((target_features['conv4_2'] \ - content_features['conv4_2'])**2) # Loop through all style layers style_losses = 0 for layer in style_weights: # Create gram matrix for that layer target_feature = target_features[layer] _, d1, d2, d3 = target_feature.shape target_reshaped = target_feature.view(d1, d2 * d3) target_gram = torch.mm(target_reshaped, \ target_reshaped.t()) style_gram = style_grams[layer] # Calculate style loss for that layer style_loss = style_weights[layer] \ * torch.mean((target_gram - style_gram)**2) #Calculate style loss for all layers style_losses += style_loss / (d1 * d2 * d3) # Calculate the total loss total_loss = alpha * content_loss + beta * style_losses # Perform back propagation optimizer.zero_grad() total_loss.backward() optimizer.step() # Print target image if i % print_statement == 0 or i == 1: print('Total loss: ', total_loss.item()) plt.imshow(tensor2image(target_img)) plt.show() -
绘制内容和目标图像来比较结果。这可以通过使用
tensor2image函数来实现,我们在之前的练习中创建了这个函数,以便将张量转换为可以使用matplotlib打印的 PIL 图像。fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(20, 10)) ax1.imshow(tensor2image(content_img)) ax2.imshow(tensor2image(target_img)) ax3.imshow(tensor2image(style_img)) plt.show()最终图像应类似于以下内容:
图 5.9:内容,样式和目标图像之间的比较
注意
要查看高质量的彩色图像,请访问本书的 GitHub 存储库。
这样,您就成功地执行了样式迁移。
注意
要访问此特定部分的源代码,请参考这里。
本部分当前没有在线交互示例,需要在本地运行。
要访问此源代码的 GPU 版本,请参考这里。 此版本的源代码无法作为在线交互示例使用,需要通过 GPU 设置在本地运行。
练习 5.01:执行样式迁移
在此活动中,我们将进行样式迁移。 为此,我们将编写本章所学的所有概念。 让我们看一下以下情况。
您需要更改一些图像,以使其具有艺术气息,为实现此目的,您决定创建一些代码,该代码使用预先训练的神经网络执行样式迁移。 请按照以下步骤完成此活动:
-
导入所需的库。
-
指定要对输入图像执行的转换。 确保将它们调整为相同的大小,将它们转换为张量,然后对其进行规范化。
-
定义图像加载器函数。 这应该打开图像并对其进行转换。 调用图像加载器函数加载两个输入图像。
-
为了能够显示图像,请定义一组新的转换,以恢复图像的规范化并将张量转换为 PIL 图像。
-
创建一个函数(
tensor2image),该函数能够对张量执行先前的转换。 调用两个图像的函数并绘制结果。 -
加载 VGG-19 模型。
-
创建一个字典,将相关层(键)的索引映射到名称(值)。 然后,创建一个函数以提取相关层的特征映射。 使用它们提取两个输入图像的特征。
-
计算样式特征的克矩阵。 另外,创建初始目标图像。
-
设置不同样式层的权重以及内容和样式损失的权重。
-
运行模型 500 次迭代。在开始训练模型之前,定义 Adam 优化算法,以 0.001 作为学习率。
注意
根据您的资源,训练过程可能需要几个小时。 因此,要获得出色的结果,建议您进行数千次迭代训练。 如果您希望查看训练过程的进度,则添加打印语句是一种很好的做法。
本章中显示的结果是通过运行大约 5,000 次迭代而获得的,如果不使用 GPU,则将花费很长时间(在本书的 GitHub 存储库中也找到了使用 GPU 的活动的解决方案)。 但是,仅看到一些小的更改,就可以按照本活动的建议运行它几百次迭代就足够了(500)。
-
绘制内容、风格、目标图片,比较结果。
5,000 次迭代后的输出应如下所示:
图 5.10:绘制内容和目标图像
注意
有关此活动的解决方案,请参见第 277 页。
要查看“图 5.10”的高质量彩色图像,请访问这里。
总结
本章介绍了样式迁移,这是当今很流行的任务,可以使用 CNN 来执行。 它包括同时获取内容图像和样式图像作为输入,并返回新创建的图像作为输出,以保留其中一个图像的内容和另一个图像的样式。 它通常用于通过将随机的常规图像与伟大艺术家的绘画相结合来赋予图像艺术外观。
尽管使用 CNN 进行样式迁移,但是按常规训练网络并不能实现创建目标图像的过程。 本章介绍了如何使用经过预训练的网络来考虑一些相关层的输出,这些层尤其擅长识别某些特征。
本章介绍了开发能够执行样式迁移任务的代码所需的每个步骤,其中第一步包括加载和显示输入。 正如我们前面提到的,模型有两个输入(内容和样式图像)。 每个图像都将经历一系列转换,目的是将图像调整为相等大小,将它们转换为张量,并对它们进行规范化,以使它们可以被网络正确处理。
接下来,加载预训练的模型。 如本章所述,VGG-19 是解决此类任务的最常用架构之一。 它由 19 个层组成,包括卷积层,池化层和全连接层,其中对于所讨论的任务,仅使用某些卷积层。 考虑到 PyTorch 提供了一个包含多个预训练网络架构的子包,加载预训练模型的过程非常简单。
一旦加载了网络,在检测某些对于样式迁移至关重要的特征时,网络的某些层将被识别为表现卓越的提供商。 尽管五个不同的层都具有提取与图像样式相关的特征(例如颜色和纹理)的能力,但是只有一层可以非常出色地提取内容特征(例如边缘和形状)。 因此,至关重要的是定义将用于从输入图像中提取信息以创建所需目标图像的那些层。
最后,是时候对该迭代过程进行编码了,以用于创建具有所需特征的目标图像。 为此,计算了三种不同的损失。 有一个用于比较内容图像和目标图像之间的内容差异(内容损失),另一个用于比较样式图像和目标图像之间的风格差异(样式损失), 通过计算克矩阵实现。 最后,有一个结合了内容损失和样式损失(总损失)。
通过最小化总损失的值来创建目标图像,这可以通过更新与目标图像有关的参数来完成。 尽管可以使用预先训练的网络,但获得理想目标图像的过程可能需要进行数千次迭代和相当多的时间。
在下一章中,将说明不同的网络架构,以便使用文本数据序列解决数据问题。 RNN 是保存内存的神经网络架构,允许它们处理序列数据。 它们通常用于解决与人类语言理解有关的问题。