1、需求:采集中科商务网区域工商信息
2、需求数据字段:
'名称': [title],'摘要': [content],'联系人': [lx_b],'联系电话': [tel],'电子邮件': [email],'公司地址': [address],'法定代表人': [fr],'经营状态': [state],'注册资本': [zczb],'统一社会信用代码': [tyshxdm],'纳税人识别号': [nsrsbh],'工商注册号': [gszch],'组织机构代码': [zzjgdm],'成立日期': [clrq],'公司类型': [type],'行政区划': [xzqh],'注册地址': [zc_add],'经营范围': [range]
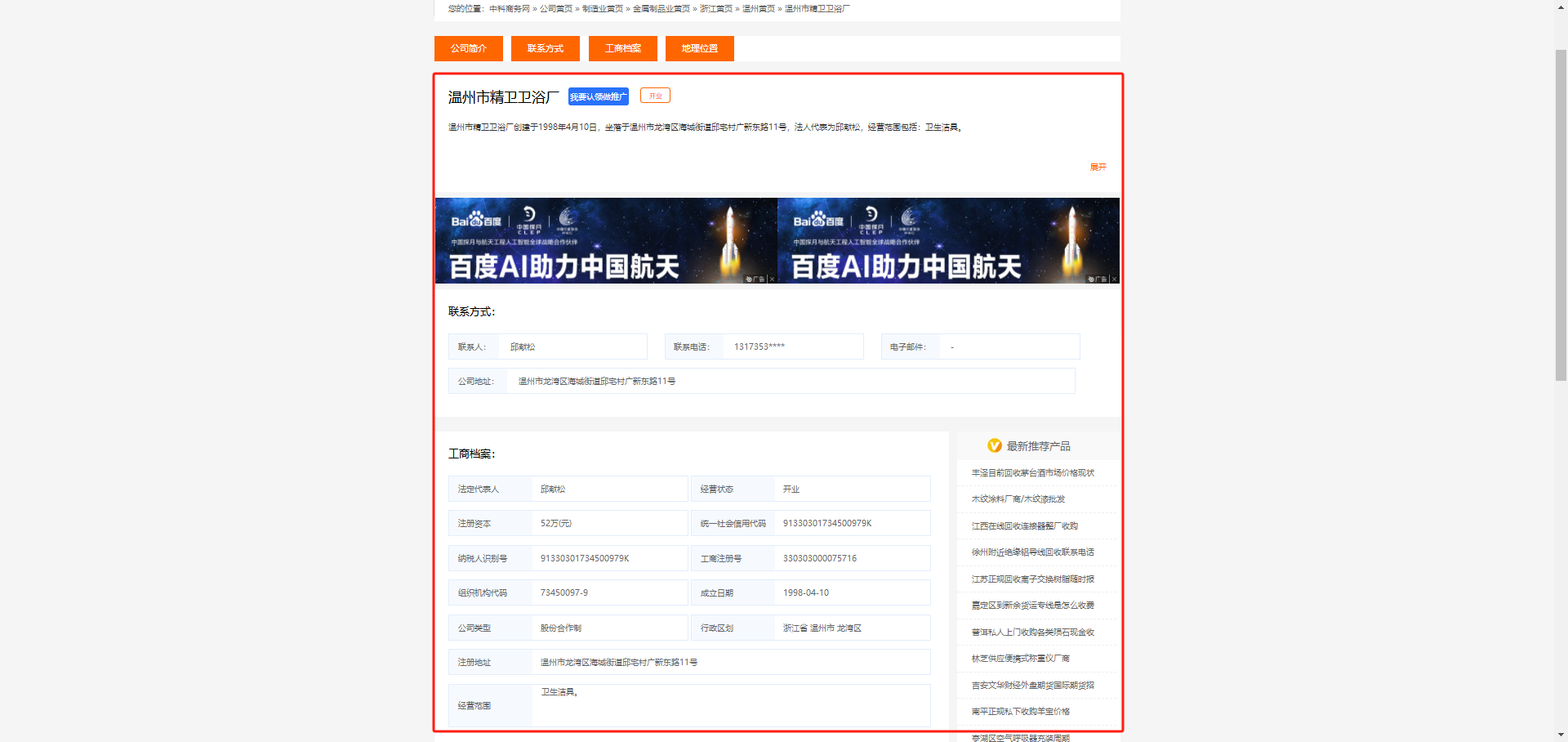
3、例图数据如下:
4、思路分析
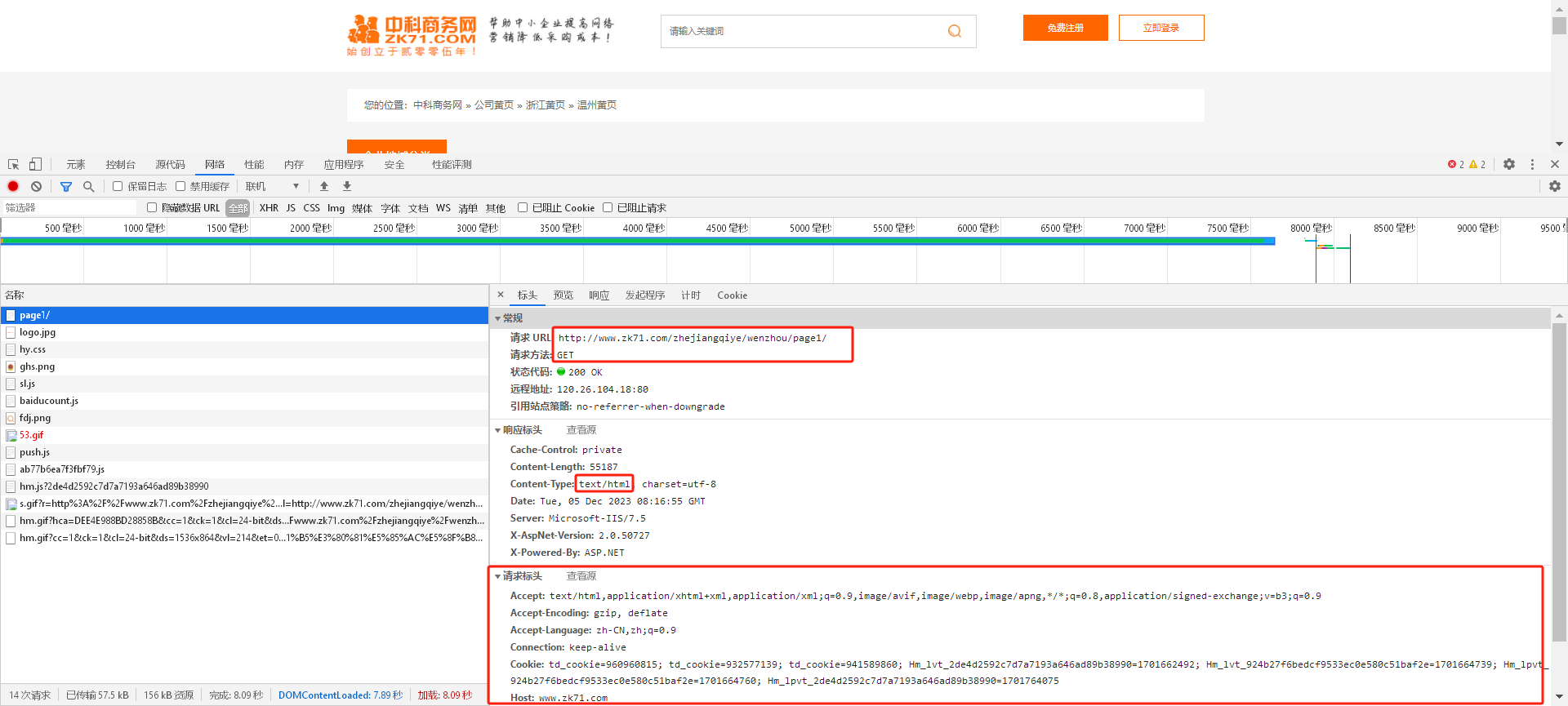
控制台查看关键信息:
页面请求返回的数据是- Content-Type:text/html; charset=utf-8
请求 URL:http://www.zk71.com/zhejiangqiye/wenzhou/page1/
请求方法:GET
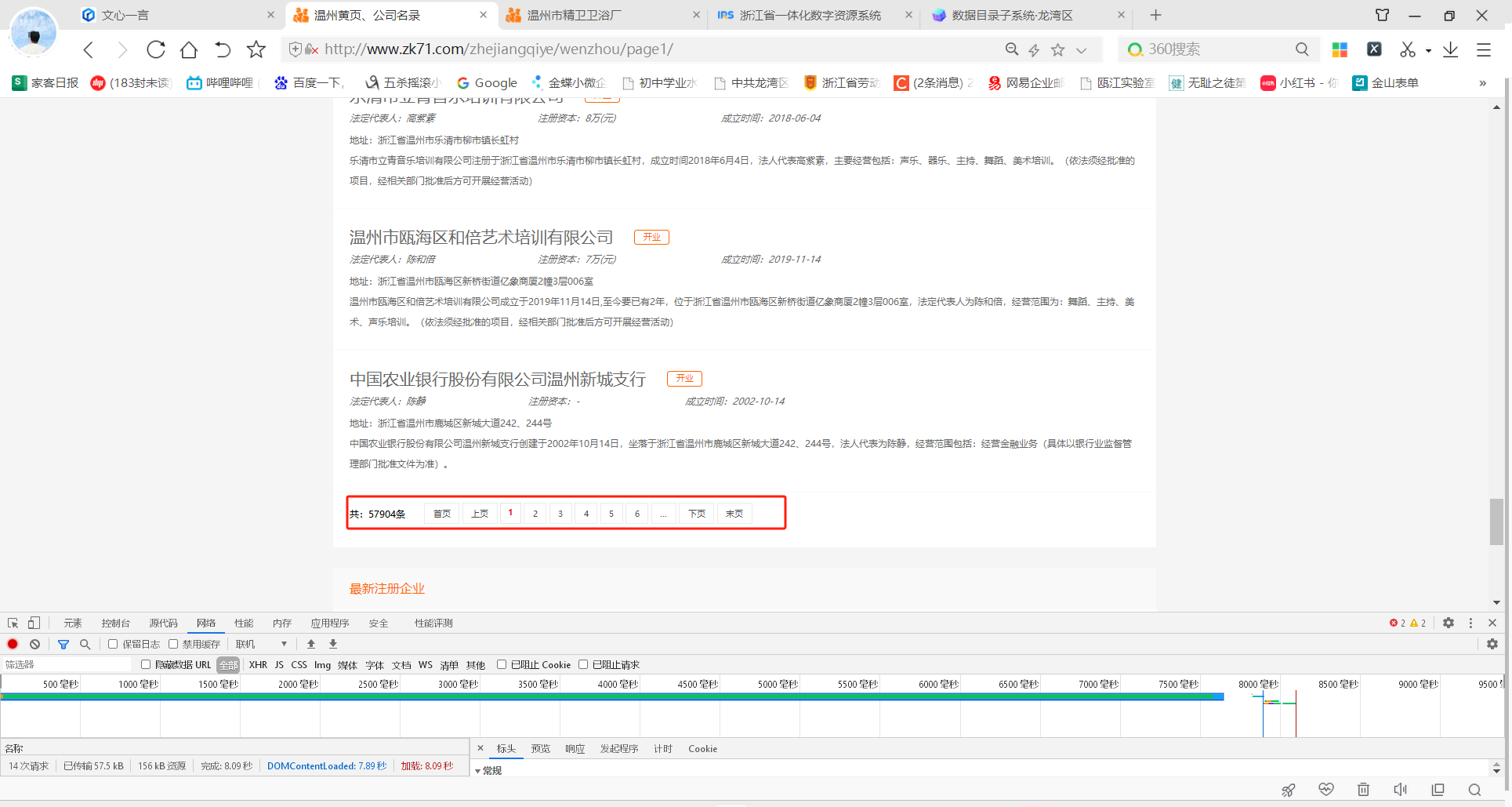
页面数据一共是57904条,那就先获取总页数做字符串拼接
url1=f"http://www.zk71.com/zhejiangqiye/wenzhou/page{m}/" m的值是1-2068页
获取到了所有项的超链接url就可以对数据进行请求获取页面的详细数据。
获取所有url并将所有数据存到一个空list表中,然后再调用list表中的url请求数据
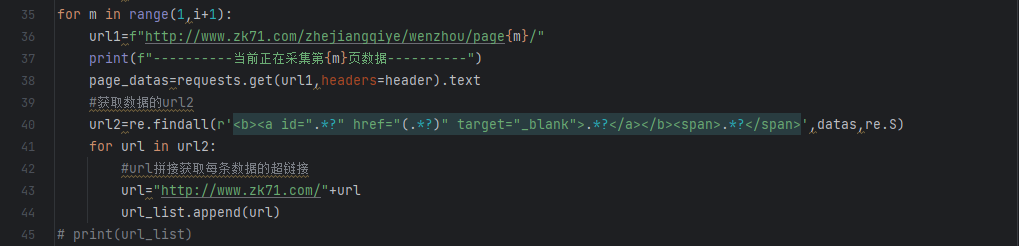
requests请求数据这里用的是正则匹配的
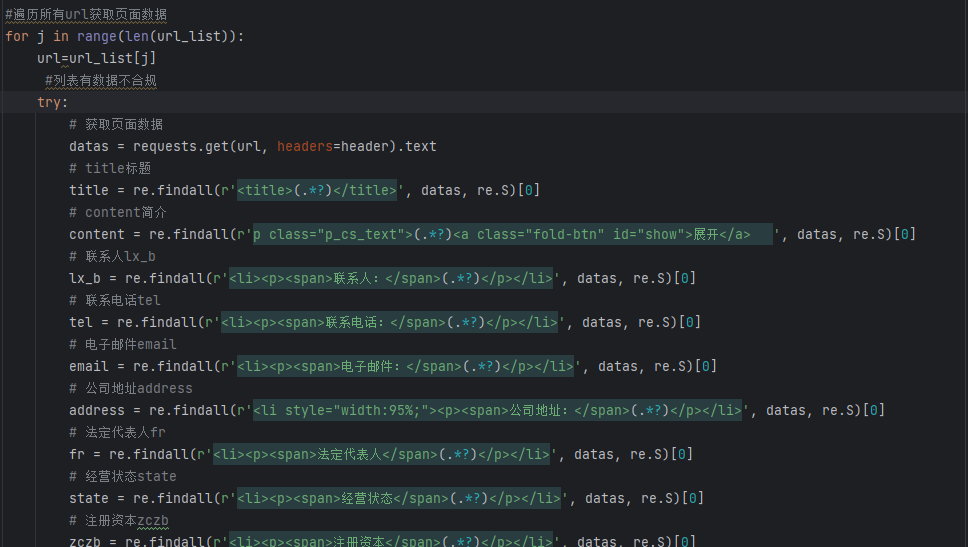
#详细代码如下:
import requests import re import pandas as pd import time import random from lxml import etree url='http://www.zk71.com/zhejiangqiye/wenzhou/' #设置请求头agent池随机获取 user_agent = [ "Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50", "Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2 ", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36", ] header={ "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9", "Accept-Encoding": "gzip, deflate", "Accept-Language": "zh-CN,zh;q=0.9", "Cache-Control": "max-age=0", "Connection": "keep-alive", "Cookie": "td_cookie=932577139; td_cookie=870182477; Hm_lvt_2de4d2592c7d7a7193a646ad89b38990=1701662492; Hm_lvt_924b27f6bedcf9533ec0e580c51baf2e=1701664739; Hm_lpvt_924b27f6bedcf9533ec0e580c51baf2e=1701664760; Hm_lpvt_2de4d2592c7d7a7193a646ad89b38990=1701735836", "Host": "www.zk71.com", "Upgrade-Insecure-Requests": "1", "User-Agent": random.choice(user_agent) } datas=requests.get(url,headers=header).text #获取总页数,做翻页操作 pages=re.findall(r'>下页</a><a class="pager" href="/zhejiangqiye/wenzhou/page(.*?)/">末页</a>',datas,re.S)[0] i=int(pages) # 创建一个空表存储数据 all_data = [] url_list=[] for m in range(1,i+1): url1=f"http://www.zk71.com/zhejiangqiye/wenzhou/page{m}/" print(f"----------当前正在采集第{m}页数据----------") page_datas=requests.get(url1,headers=header).text #获取数据的url2 url2=re.findall(r'<b><a id=".*?" href="(.*?)" target="_blank">.*?</a></b><span>.*?</span>',datas,re.S) for url in url2: #url拼接获取每条数据的超链接 url="http://www.zk71.com/"+url url_list.append(url) # print(url_list) #遍历所有url获取页面数据 for j in range(len(url_list)): url=url_list[j] #列表有数据不合规 try: # 获取页面数据 datas = requests.get(url, headers=header).text # title标题 title = re.findall(r'<title>(.*?)</title>', datas, re.S)[0] # content简介 content = re.findall(r'p class="p_cs_text">(.*?)<a class="fold-btn" id="show">展开</a> ', datas, re.S)[0] # 联系人lx_b lx_b = re.findall(r'<li><p><span>联系人:</span>(.*?)</p></li>', datas, re.S)[0] # 联系电话tel tel = re.findall(r'<li><p><span>联系电话:</span>(.*?)</p></li>', datas, re.S)[0] # 电子邮件email email = re.findall(r'<li><p><span>电子邮件:</span>(.*?)</p></li>', datas, re.S)[0] # 公司地址address address = re.findall(r'<li style="width:95%;"><p><span>公司地址:</span>(.*?)</p></li>', datas, re.S)[0] # 法定代表人fr fr = re.findall(r'<li><p><span>法定代表人</span>(.*?)</p></li>', datas, re.S)[0] # 经营状态state state = re.findall(r'<li><p><span>经营状态</span>(.*?)</p></li>', datas, re.S)[0] # 注册资本zczb zczb = re.findall(r'<li><p><span>注册资本</span>(.*?)</p></li>', datas, re.S)[0] # 统一社会信代码tyshxdm tyshxdm = re.findall(r'<li><p><span>统一社会信用代码</span>(.*?)</p></li>', datas, re.S)[0] # 纳税人识别号nsrsbh nsrsbh = re.findall(r'<li><p><span>纳税人识别号</span>(.*?)</p></li>', datas, re.S)[0] # 工商注册号gszch gszch = re.findall(r'<li><p><span>工商注册号</span>(.*?)</p></li>', datas, re.S)[0] # 组织结构代码zzjgdm zzjgdm = re.findall(r'<li><p><span>组织机构代码</span>(.*?)</p></li>', datas, re.S)[0] # 成立日期clrq clrq = re.findall(r'<li><p><span>成立日期</span>(.*?)</p></li>', datas, re.S)[0] # 公司类型type type = re.findall(r'<li><p><span>公司类型</span>(.*?)</p></li>', datas, re.S)[0] # 行政区划xzqh xzqh = re.findall(r'<li><p><span>行政区划</span>(.*?)</p></li>', datas, re.S)[0] # 注册地址zc_add zc_add = re.findall(r'<li style="width:99%;"><p><span>注册地址</span>(.*?)</p></li>', datas, re.S)[0] # 经营范围range range = re.findall(r' <li style="width:99%; overflow:hidden;"><p><span style=" height:74px; line-height:74px;">经营范围</span><em>(.*?)</em></p></li>',datas, re.S)[0] # 创建一个Pandas DataFrame来存储数据 data_dict = { '名称': [title], '摘要': [content], '联系人': [lx_b], '联系电话': [tel], '电子邮件': [email], '公司地址': [address], '法定代表人': [fr], '经营状态': [state], '注册资本': [zczb], '统一社会信用代码': [tyshxdm], '纳税人识别号': [nsrsbh], '工商注册号': [gszch], '组织机构代码': [zzjgdm], '成立日期': [clrq], '公司类型': [type], '行政区划': [xzqh], '注册地址': [zc_add], '经营范围': [range] } df = pd.DataFrame(data_dict) # 添加延时,参数为秒。 time.sleep(2) all_data.append(df) # 合并所有数据DataFrame final_df = pd.concat(all_data, ignore_index=True) # 保存到Excel文件 final_df.to_excel('温州黄页数据源信息.xlsx', index=False) print(f'爬取第{j}数据入EXCEL执行完毕') except requests.exceptions.RequestException as e: print(f"Error processing {url}: {e}")
存在问题:页面加载返回数据较慢,这里也设置了2秒的时延。由于是requests请求的,单线程进度慢。采集5万多条数据大概一天。
运行截图: