chapter13
网络编程内容
网络编程内容包括:TCP/IP协议、UDP和TCP协议、服务器-客户机计算、HTTP和Web页面、动态Web页面的PHP和CGI编程。
TCP/IP协议
TCP/IP(Comer 1988,2001;RFC1180 1991)是互联网的基础。TCP代表传输控制协议。IP代表互联网协议。目前有两个版本的IP,即IPv4和IPv6。IPv4使用32位地址,IPv6则使用128位地址。下面将对IPv4进行讨论,它仍然是目前使用最多的IP版本。TCP/IP的组织结构分为几个层级,通常称为TCP/IP堆栈。下图为TCP/IP的各个层级以及每一层级的代表性组件及其功能。

顶层是使用TCP/IP的应用程序。用于登录到远程主机的ssh、用于交换电子邮件的mail、用于 Web页面的http等应用程序需要可靠的数据传输。通常,这类应用程序在传输层使用TCP。另一方面,有些应用程序,例如用于查询其他主机的ping命令,则不需要可靠性。这类应用程序可以在传输层使用UDP来提高效率(RFC 768 1980; Comer 1988)。传输层负责以包的形式向IP主机发送/接收来自IP主机的应用程序数据。进程与主机之间的传输层或其上方的数据传输只是逻辑传输。实际数据传输发生在互联网(IP)和链路层,这些层将数据包分成数据帧,以便在物理网络之间传输。下图为TCP/IP网络中的数据流路径。

IP主机和IP地址
主机是支持TCP/IP协议的计算机或设备。每个主机由一个32位的IP地址来标识。为了方便起见,32位的P地址号通常用点记法表示,例如:134.121.64.1,其中各个字节用点号分开。主机也可以用主机名来表示,如dnsI.eec.wsu.edu。实际上,应用程序通常使用主机名而不是IP地址。在这个意义上说,主机名就等同于IP地址,因为给定其中一个,可以通过DNS(域名系统)(RFC 134 1987;RFC 1035 1987)服务器找到另一个,它将IP地址转换为主机名,反之亦然。
IP地址分为两部分,即NetworkID字段和HostID字段。根据划分,IP地址分为A~E类。例如,一个B类地址被划分为一个16位NetworkID,其中前2位是10,然后是一个16位的HostID字段。发往IP地址的数据包首先被发送到具有相同networkID的路由器。路由器将通过HostID将数据包转发到网络中的特定主机。每个主机都有一个本地主机名localhost,默认IP地址为127.0.0.1。本地主机的链路层是一个回送虚拟设备,它将每个数据包路由回同一个localhost。这个特性可以让我们在同一台计算机上运行TCP/IP应用程序,而不需要实际连接到互联网。
IP协议
IP协议用于在IP主机之间发送/接收数据包。IP尽最大努力运行。IP主机只向接收主机发送数据包,但它不能保证数据包会被发送到它们的目的地,也不能保证按顺序发送。这意味着IP并非可靠的协议。必要时,必须在IP层的上面实现可靠性。
IP数据包格式
IP数据包由IP头、发送方IP地址和接收方IP地址以及数据组成。每个IP数据包的大小最大为64KB。IP头包含有关数据包的更多信息,例如数据包的总长度、数据包使用TCP还是UDP、生存时间(TTL)计数、错误检测的校验和等。下图为IP头格式。

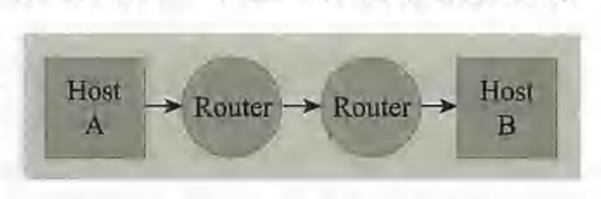
路由器
IP主机之间可能相距很远。通常不可能从一个主机直接向另一个主机发送数据包。路由器是接收和转发数据包的特殊IP主机。如果有的话,一个IP数据包可能会经过许多路由器,或者跳跃到达某个目的地。下图显示了TCP/IP网络的拓扑结构。
每个IP包在IP报头中都有一个8位生存时间(TTL)计数,其最大值为255。在每个路由器上,TTL会减小1。如果TTL减小到0,而包仍然没有到达目的地,则会直接丢弃它。这可以防止任何数据包在IP网络中无限循环。
UDP
UDP(用户数据报协议)(RFC 768 1980; Comer 1988)在IP上运行,用于发送/接收数据报。与IP类似,UDP不能保证可靠性,但是快速高效。它可用于可靠性不重要的情况。例如,用户可以使用ping命令探测目标主机,如
ping 主机名或ping IP地址
ping是一个向目标主机发送带时间戳UDP包的应用程序。接收到一个pinging数据包后,目标主机将带有时间戳的UDP包回送给发送者,让发送者可以计算和显示往返时间。如果目标主机不存在或宕机,当TTL减小为0时,路由器将会丢弃pinging UDP数据包。在这种情况下,用户会发现目标主机没有任何响应。用户可以尝试再次ping,或者断定目标主机宕机。在这种情况下,最好使用UDP,因为不要求可靠性。
TCP
TCP(传输控制协议)是一种面向连接的协议,用于发送/接收数据流。TCP也可在IP上运行,但它保证了可靠的数据传输。通常,UDP类似于发送邮件的USPS,而TCP类似于电话连接。
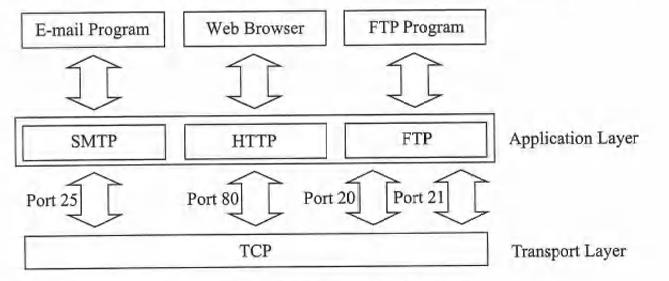
端口编号
在各主机上,多个应用程序(进程)可同时使用TCP/UDP。每个应用程序由三个组成部分唯一标识
应用程序 = (主机IP,协议,端口号)
其中,协议是TCP或UDP,端口号是分配给应用程序的唯一无符号短整数。要想使用UDP或TCP,应用程序(进程)必须先选择或获取一个端口号。前1024个端口号已被预留。其他端口号可供一般使用。应用程序可以选择一个可用端口号,也可以让操作系统内核分配端口号。下图给出了在传输层中使用TCP的一些应用程序及其默认端口号。
网络和主机字节序
计算机可以使用大端字节序,也可以使用小端字节序。在互联网上,数据始终按网络序排列,这是大端。在小端机器上,例如基于Intel x86的PC,htons()、htonl()、ntohs()、ntohl()等库函数,可在主机序和网络序之间转换数据。例如,PC中的端口号1234按主机字节序(小端)是无符号短整数。必须先通过htons(1234)把它转换成网络序,才能使用。相反,从互联网收到的端口号必须先通过ntohs(port)转换为主机序。
TCP/IP网络中的数据流
下图给出了TCP/IP网络中的各层数据格式和各层之间的数据流路径。
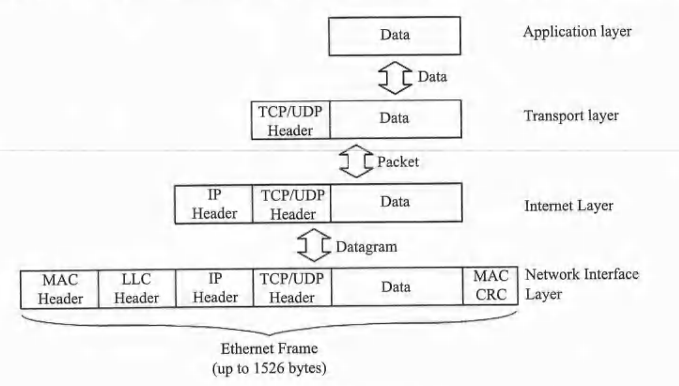
应用程序层的数据被传递到传输层,传输层给数据添加一个TCP或UDP报头来标识使用的传输协议。合并后的数据被传递到IP网络层,添加一个包含IP地址的IP报头来标识发送和接收主机。然后,合并后的数据再被传递到网络链路层,网络链路层将数据分成多个帧,并添加发送和接收网络的地址,用于在物理网络之间传输。IP地址到网络地址的映射由地址解析协议(ARP)执行(ARP 1982)。在接收端,数据编码过程是相反的。每一层通过剥离数据头来解包接收到的数据,重新组装数据并将数据传递到上一层。发送主机上的应用程序原始数据最终会被传递到接收主机上的相应应用程序。
网络编程
所有Unix/Linux系统都为网络编程提供TCP/TP支持。下面会阐释用于网络编程的平台和服务器-客户机计算模型。
网络编程平台
要进行网络编程就必须能够访问支持网络编程的平台。可通过下面几种方法访问这类平台。
(1)服务器上的用户账户:几乎所有的教育机构都为它们的教职工和学生提供了网络接入,通常是以无线连接的形式。每位机构成员都要能够登录服务器以接入互联网。服务器是否允许一般的网络编程取决于本地网络管理策略(国外)。
(2)单独PC或笔记本电脑:即便未接入服务器,仍然可以使用计算机的本地主机在单独计算机上进行网络编程。在这种情况下需要下载安装一些网络部件。例如,Ubuntu Linux用户可能需要安装和配置用于HTTP和CGI编程的Apache服务器。
服务器-客户机计算模型
大多数网络编程任务都基于服务器-客户机计算模型。在服务器–客户机(C-S)计算模型中,首先在服务器主机上运行服务器进程。然后,从客户机主机运行客户机。在UDP中,服务器等待来自客户机的数据报,处理数据报并生成对客户机的响应。在TCP中,服务器等待客户机连接。客户机首先连接到服务器,在客户机和服务器之间建立一个虚拟电路。建立连接后,服务器和客户机可以交换连续的数据流。
套接字编程
在网络编程中,TCP/IP的用户界面是通过一系列C语言库函数和系统调用来实现的,这些函数和系统调用统称为套接字API(Rago 1993;Stevens等2004)。为了使用套接字API,需要套接字地址结构,它用于标识服务器和客户机。netdb.h和sys/socket.h中有套接字地址结构的定义。
套接字地址
struct sockaddr_in{
sa_family_t sin_family; //AF_INET for TCP/IP
in_port_t sin_port; //port number
struct in_addr sin_addr; //IP address
};
struct in_addr{ //internet address
uint32_t s_addr ; //IP address in network byte order
};
在套接字地址结构中,
- TCP/IP网络的sin_family始终设置为AF_INET。
- sin_port包含按网络字节顺序排列的端口号。
- sin_addr是按网络字节顺序排列的主机IP地址。
套接字API
服务器必须创建一个套接字,并将其与包含服务器IP地址和端口号的套接字地址绑定。它可以使用一个固定端口号,或者让操作系统内核选择一个端口号(如果sin_port为0)。为了与服务器通信,客户机必须创建一个套接字。对于UPD套接字,可以将套接字绑定到服务器地址。如果套接字没有绑定到任何特定的服务器,那么它必须在后续的sendto()/recvfrom()调用中提供一个包含服务器IP和端口号的套接字地址。下面给出了socket()系统调用,它创建一个套接字并返回一个文件描述符
1.int套接字(int域,int类型,int协议)示例:
int udp_sock = socket(AF_INET,SOCK_DGRAM,0);
将会创建一个用于发送/接收UDP数据报的套接字。
int tcp_sock = socket(AF_INET,SOCK_STREAM,0);
将会创建一个用于发送/接收数据流的面向连接的TCP套接字。
新创建的套接字没有任何相联地址。它必须与主机地址和端口号绑定,以识别接收主机或发送主机。这通过bind()系统调用来完成。
*2.int bind(int sockfd, struct sockaddr addr, socklen_t addrlen)
bind()系统调用将addr指定的地址分配给文件描述符sockfd所引用的套接字,addrlen指定addr所指向地址结构的大小(以字节为单位)。对于用于联系其他UDP服务器主机的UDP套接字,必须绑定到客户机地址,允许服务器发回应答。对于用于接收客户机连接的TCP套接字,必须先将其绑定到服务器主机地址。
3.UDP套接字
UDP套接字使用sendto()/recvfrom()来发送/接收数据报。
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags, const struct sockaddr *dest_addr, socklen_t addrlen);
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen);
sendto()将缓冲区中的len字节数据发送到由dest_addr标识的目标主机,该目标主机包含目标主机IP和端口号。recvfrom()从客户机主机接收数据。除了数据之外,它还用客户机的IP和端口号填充src_addr,从而允许服务器将应答发送回客户机。
4.TCP套接字
在创建套接字并将其绑定到服务器地址之后,TCP服务器使用listen()和accept()来接收来自客户机的连接
int listen(int sockfd, int backlog);
listen()将sockfd引用的套接字标记为将用于接收连入连接的套接字。backlog参数定义了等待连接的最大队列长度。
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
accept()系统调用与基于连接的套接字一起使用。它提取等待连接队列上的第一个连接请求用于监听套接字sockfd,创建一个新的连接套接字,并返回一个引用该套接字的新文件描述符,与客户机主机连接。在执行accept()系统调用时,TCP服务器阻塞,直到客户机通过connect()建立连接。
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
connect()系统调用将文件描述符sockfd引用的套接字连接到addr指定的地址,addrlen参数指定addr的大小。addr中的地址格式由套接字sockfd的地址空间决定。
如果套接字sockfd是SOCK_DGRAM类型,即UDP套接字,addr是发送数据报的默认地址,也是接收数据报的唯一地址。这会限制UDP套接字与特定UDP主机的通信,但实际上很少使用。所以对于UDP套接字来说,连接是可选的或不必要的。如果套接字是SOCK_STREAM类型,即TCP套接字,connect()调用尝试连接到绑定到addr指定地址的套接字。
5.send()/read()以及 recv()/write()
建立连接后,两个TCP主机都可以使用send()/write()发送数据,并使用recv()/read()接收数据。它们唯一的区别是send()和recv()中的flag参数不同,通常情况下可以将其设置为0。
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
ssize_t write(sockfd, void *buf, size_t len);
ssize_t recv(int sockfd, void *buf, size_t len, int flags);
ssize_t read(sockfd, void *buf, size_t len);
UDP回显服务器-客户机程序
下图显示了服务器和客户机的算法。
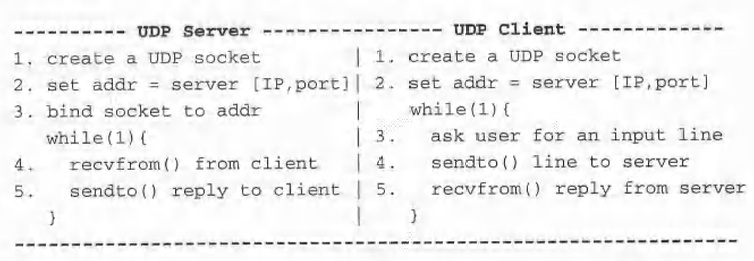
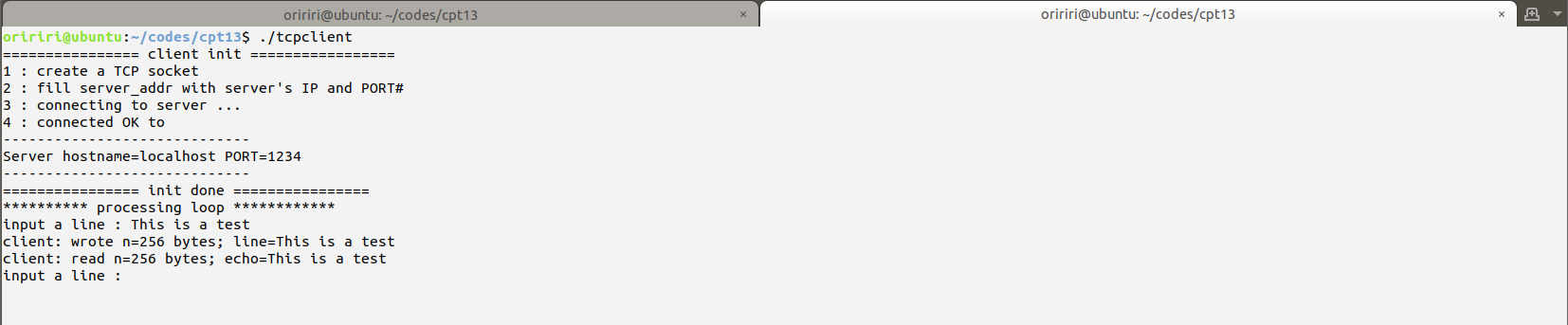
为简单起见,假设服务器和客户机都在同一台计算机上运行。服务器在默认本地主机上运行(IP = 127.0.0.1),使用固定端口号1234。使用UDP的服务器和客户机程序代码见教材代码实践中。
TCP回显服务器-客户机程序
为简单起见,假设服务器和客户机都在同一台计算机上运行,服务器端口号硬编码为1234。下图给出了TCP服务器和客户机的算法和操作顺序。

使用TCP的简单回显服务器-客户机程序代码见教材代码实践中。
主机名和IP地址
假设服务器和客户机在同一台计算机上运行(使用本地主机或IP=127.0.0.1),并且服务器使用固定端口号。想要在不同的主机上运行服务器和客户机,服务器端口号由操作系统内核分配,则需要知道服务器的主机名或IP地址及其端口号。如果某台计算机运行TCP/IP,它的主机名通常记录在/etc/hosts文件中。库函数
gethostname(char *name, sizeof(name))
在name数组中返回计算机的主机名字符串,但它可能不是用点记法表示的完整正式名称,也不是其IP地址。库函数
struct hostent *gethostbyname(void *addr, socklen_t len, int typo)
可以用来获取计算机的全名及其IP地址。它会返回一个指向<netdb.h>中hostent结构体的指针
struct hostent{
char *h_name; //official name of host
char **h_aliases; //alias list
int h_addrtype; //host address type
int h_length; //length of aadress
char **h_addr_list; //list of addresses
}
#define h_addr h_addr_list[0] //for backward compatibility
注意,h_addr被定义为一个char *,但它以网络字节序指向一个4字节的IP地址。h_addr的内容可以存取为
- u32 NIP = *(u32 *)h_addr是按网络字节序排列的主机IP地址。
- u32 HIP = ntohl(NIP)是按主机字节序排列的NIP。
- inet_ntoa(NIP)将NIP转换为一个用点记法表示的字符串。
服务器必须发布其主机名或IP地址和端口号,以便客户机连接。如何使用gethostbyname()和 getsockname()来获取服务器IP地址和端口号(若是动态分配)的代码见教材代码实践。
Web和CGI编程
Web编程通常包括Web开发中涉及的编写、标记和编码,其中包括Web内容、Web客户机和服务器脚本以及网络安全,而狭义上的Web编程指创建和维护Web页面。Web编程中最常用的语言是HTML、XHTML、JavaScript、Perl 5和PHP。
HTTP编程模型
HTTP是一种基于服务器-客户机的协议,用于互联网上的应用程序。它在TCP上运行,因为它需要可靠的文件传输。下图为HTTP编程模型。
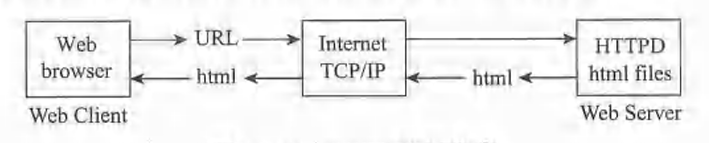
在HTTP编程模型中,HTTP服务器在Web服务器主机上运行。它等待HTTP客户机(通常是Web浏览器)的请求。在HTTP客户机端,用户输入以下形式的URL(统一资源定位符):
http://hostname[/filename]
向HTTP服务器发送请求,请求文件。在URL中,http标识http协议,hostname是http服务器的主机名,filename是请求的文件名。如果没有指定filename,默认文件名是index.html。客户机首先连接到服务器,以发送请求。服务器在接收到请求后,会将请求的文件发送回客户机。请求的文件通常是用HTML语言编写的Web页面文件,可在浏览器上解释和显示,但也可能是其他格式的文件,如视频、音频甚至是二进制文件。
在HTTP中,客户机可发出多个URL,将请求发送到不同的HTTP服务器。客户机与特定服务器保持永久连接不但没有必要,也不可取。客户机连接到服务器只是为了发送请求,发送完毕后会关闭连接。同样,服务器连接到客户机也只是为了发送应答,发送完毕后会再次关闭连接。每个请求或应答都需要一个单独的连接。这意味着HTTP是一种无状态协议,因为在连续的请求或应答之间不需要维护任何信息。自然,这将导致大量系统开销和效率低下。为弥补这一缺乏状态信息的问题,HTTP服务器和客户机可使用cookie来提供和维护它们之间的一些状态信息。
Web页面
Web页面使用HTML标记语言编写的文件,学习者可以通过w3school网站在线学习关于Web编程的所有语言。
托管Web页面
下面有三种方法可以托管Web页面。
(1)与商业Web托管服务提供商签约,按月缴费。对于大多数普通用户来说,根本不会选择这个方法。
(2)机构或部门服务器上的用户账户。如果在运行Linux的服务器上有一个用户账户,那么通过以下步骤可在用户主目录中轻松创建一个私人网站
- 登录到服务器上的用户账户。
- 在用户主目录中,创建一个权限为0755的public_html目录。
- 在public_html目录中,创建index.html文件和其他HTML文件。
(3)独立PC或笔记本电脑:这里所述的步骤适用于运行标准Linux的独立PC或笔记本电脑,但是它也应该适用于其他Unix平台。出于某种原因,Ubuntu Linux选择了不同的方式,偏离了Linux的标准设置。Ubuntu用户可以查看官方Ubuntu文档的HTTPD-Apache2 Web服务器网页,以了解详细信息。
为Web页面配置HTTPD
(1)下载并安装Apache服务器(Linux发行版中叫HTTPD)
(2)输入ps -x | grep httpd,查看httpd是否正在运行,如果没有运行,输入
sudo chmod +x /etc/rc.d/rc.httpd
使rc.httpd文件可执行。这将在下一次启动期间启动httpd。或者也可通过输入以下内容手动启动httpd
sudo /usr/sbin/httpd -kstart
(3)配置httpd.conf文件:HTTPD服务器的操作由/etc/httpd/目录中的httpd.conf文件控制。要允许个人用户网站,可按以下方式编辑httpd.conf文件。
如果这些行被注释掉了,就取消注释
Loadmodule dir_module MODULE_PATH
Include /etc/httpd/extra/httpd-userdir.conf
在第一个目录块中
<Directory />
Require all denied # deny requests for all files in /
</Directory>
将“Require all denied”行更改为“Require all granted”。
所有用户主目录都在/home目录中。将行
DocumentRoot /srv/httpd/htdocs更改为DocumentRoot /home
所有HTML文件的默认目录是htdoc。将行
<Directory /srv/httpd/htdocs>更改为<Directory /home>
编辑httpd.conf文件之后,重新启动httpd服务器或输入命令
ps -x | grep httpd # to see httpd PID
sudo kill -s 1 httpdPID
kill命令向httpd发送一个数字1信号,使它在不重新启动httpd服务器的情况下读取更新后的httpd.conf文件。
(4)通过adduser user_name创建一个用户账户。通过以下用户名登录到用户账户:
ssh user_name@localhost
像以前一样创建public_html目录和HTML文件。
然后打开Web浏览器并输入http://localhost/~user_name,以访问用户的Web网页。
动态Web页面
用标准HTML编写的Web页面都是静态的。当从服务器获取并用浏览器显示时,Web页面的内容不会变化。要显示包含不同内容的Web页面,必须再次从服务器获取不同的Web页面文件。动态Web页面是内容可以变化的页面。动态Web页面有两种,分别称为客户机端动态Web页面和服务器端动态Web页面。客户机端动态Web页面文件包含用JavaScript写的代码,这些代码由JavaScript解释器在客户机上执行。它可以响应用户输入、时间事件等来对Web页面进行本地修改,而不需要与服务器进行任何交互。服务器端动态web页面是真正的动态页面,因为它们是根据URL请求中的用户输入动态生成的。服务器端动态Web页面的核心在于服务器在HTML文件中执行PHP代码,或CGI程序通过用户输入生成HTML文件的能力。
PHP
PHP(超文本预处理器)(PHP 2017)是一种用于创建服务器端动态Web页面的脚本语言。PHP文件用.php后缀标识。它们本质上是HTML文件,包含Web服务器要执行的PHP代码。当Web客户机请求PHP文件时,Web服务器将首先处理PHP语句来生成一个HTML文件,然后将该文件发送给请求客户机。所有运行Apache HTTPD服务器的Linux系统都支持PHP,但是必须要启用它。要启用PHP,只需对httpd.conf文件进行少量修改,修改如下所示。
(1)DirectoryIndex index.php #默认Web页面是index.php
(2)AddType应用程序/x-httpd-php.php #添加.php扩展类型
(3)包含/etc/httpd/mod_php.conf #加载php5模块
在httpd.conf中启用PHP后,重启httpd服务器,它将把PHP模块加载到Linux内核中。当Web客户机请求.php文件时,httpd服务器会复刻一个子进程,以执行.php文件中的PHP语句。由于子进程在映像中加载了PHP模块,因此可以快速高效地执行PHP代码。或者,httpd服务器也可以配置为将PHP作为CGI执行,这会比较慢,因为它必须使用fork-exec来调用PHP解释器。为了提高效率,可以让.php文件由PHP模块处理。有关PHP基本编程的学习,可以参考w3school中的PHP教程
CGI编程
CGI代表通用网关接口(RFC 3875 2004)。它是一种协议,允许Web服务器执行程序,根据用户输入动态生成Web页面。使用CGI,Web服务器不必维护数百万个静态Web页面文件来满足客户机请求。相反,它通过动态生成Web页面来满足客户机请求。下图显示了CGI编程模型。

在CGI编程模型中,客户机发送一个请求,该请求通常是一个HTML表单,包含供服务器执行的CGI程序的输入和名称。在接收到请求后,httpd服务器会派生一个子进程来执行CGI程序。CGI程序可以使用用户输入来查询数据库系统,如MysQL,从而根据用户输入生成HTML文件。当子进程结束时,httpd服务器将生成的HTML文件发送回客户机。CGI程序可用任何编程语言编写,如C语言、sh脚本和Perl。
配置CGI的HTTPD
在HTTPD中,CGI程序的默认目录是/srv/httpd/cgi-bin。这样网络管理员控制和监督可以执行CGI程序的用户。在许多机构中,出于安全原因,通常会禁用用户级CGI程序。为了允许用户级CGI编程,必须将httpd服务器配置为启用用户级CGI。编辑/etc/httpd/httpd.conf文件,并将CGI目录设置更改为
<Directory "/home/*/public_html/cgi-bin">
Options +ExecCGI
AddHandler cgi-script .cgi .sh .bin .pl
order allow,deny
Allow from all
</Directory>
修改后的CGI目录块将CGI目录设置为用户主目录中的public_html/cgi-bin/。cgi-script设置将后缀为.cgi、.sh、.bin和.pl(用于Perl脚本)的文件指定为可执行的CGI程序。
GPT提问环节
网络编程


套接字编程
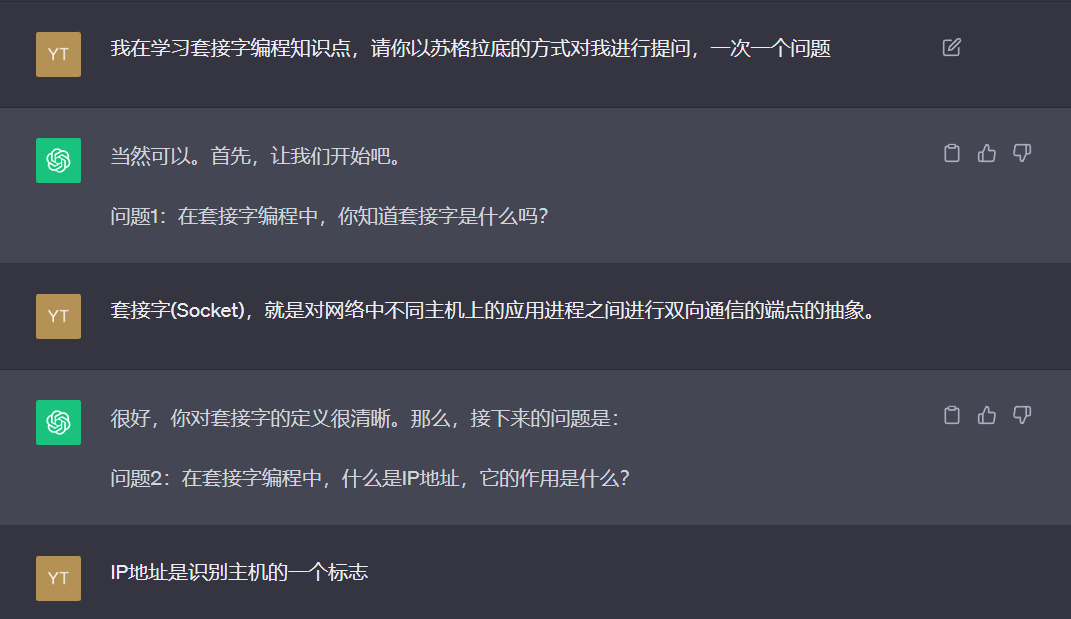


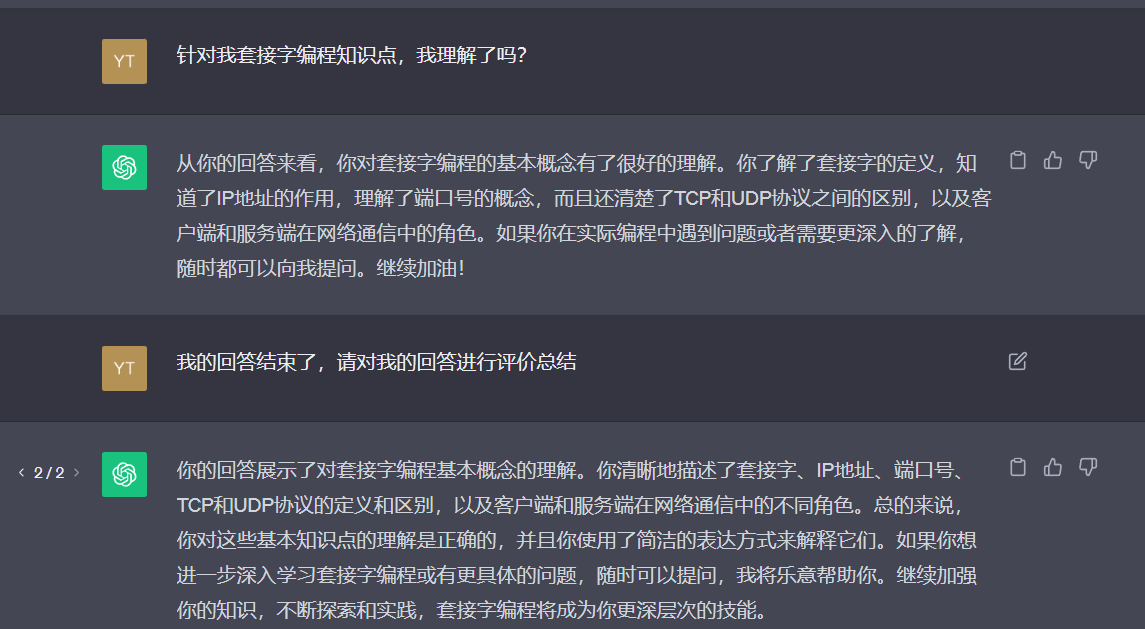
在学习中遇到的一些问题
问题:在编译UDP服务器客户机回显程序时出现了报错,然后询问GPT给出了下图的解释。
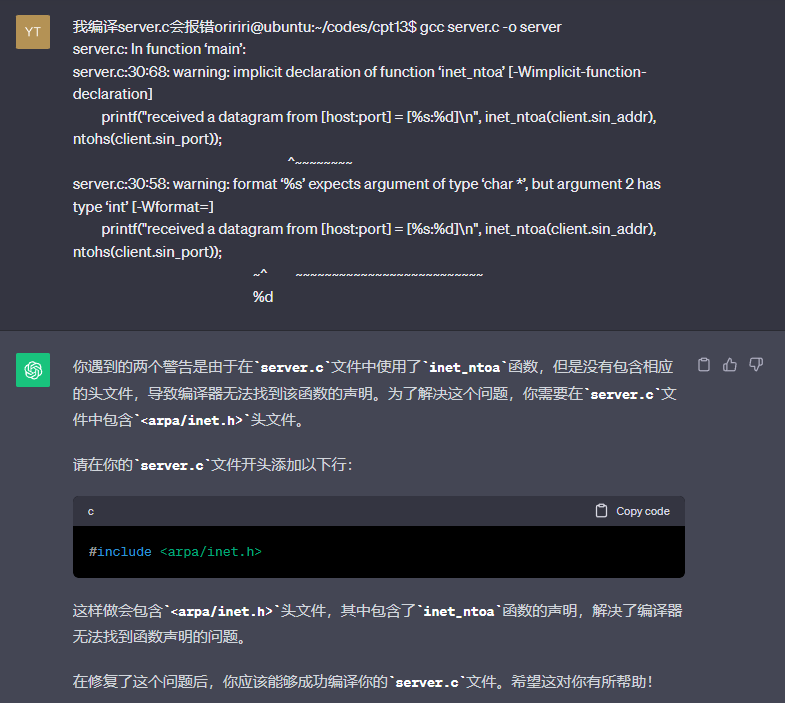
教材的代码中没有引用inet.h头文件,导致了编译报错,引用该库后编译就没有报错了。
代码实践