ViT| Vision Transformer |理论 + 代码_哔哩哔哩_bilibili

1 不用卷积神经网络那些东西(CNN)了全部用Transforme 。
2 大规模数据训练,小规模数据应用。
3 效果相当 计算训练资源更少。
转换思想
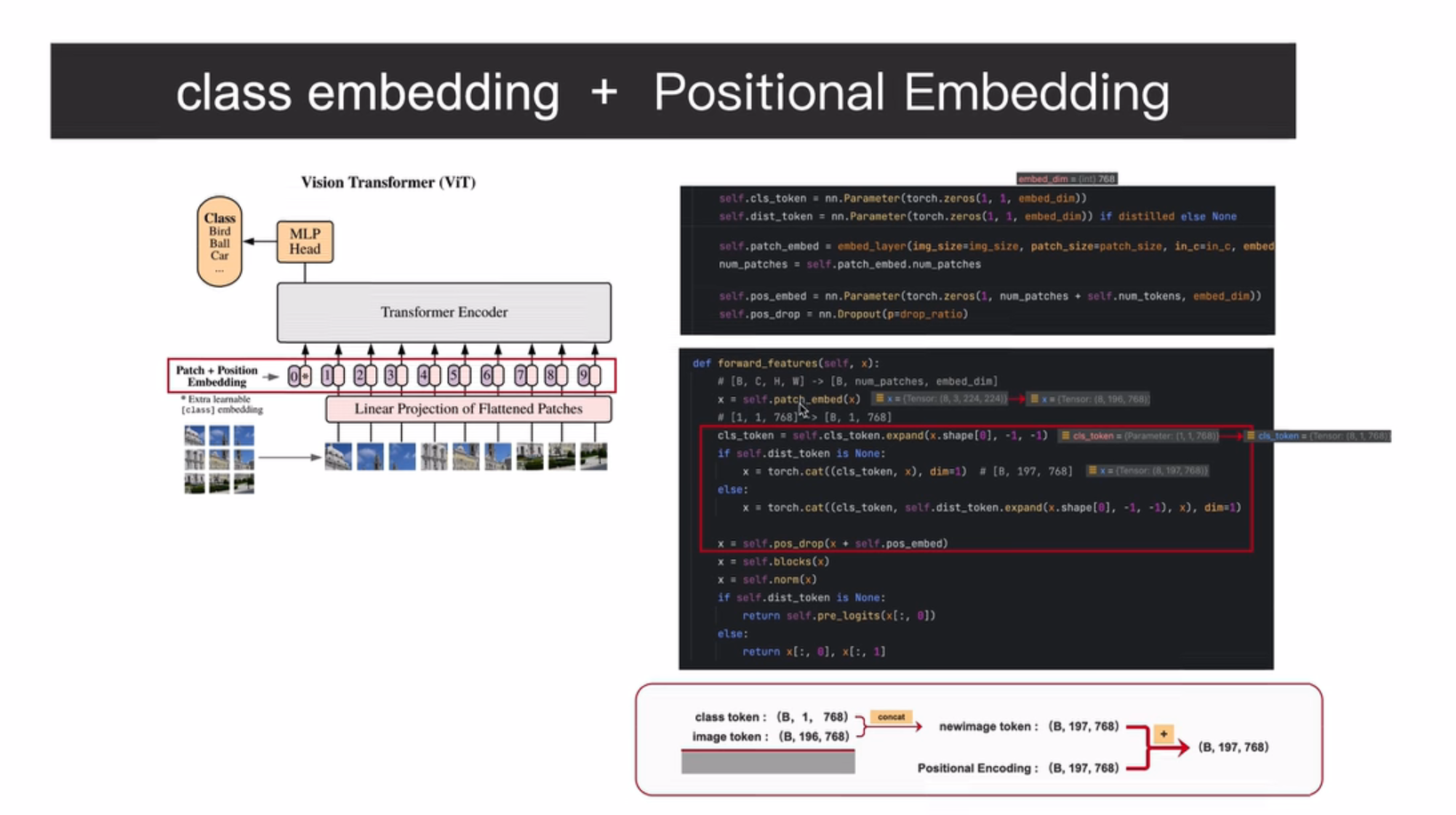
224*224像素图像 - 单个像素(视为一个词token) -16*16个像素 图像块patches(作为一个token 减少计算量) - 变为1个token词-- 共14*14=196个词(token) --- 送入TSFM网络
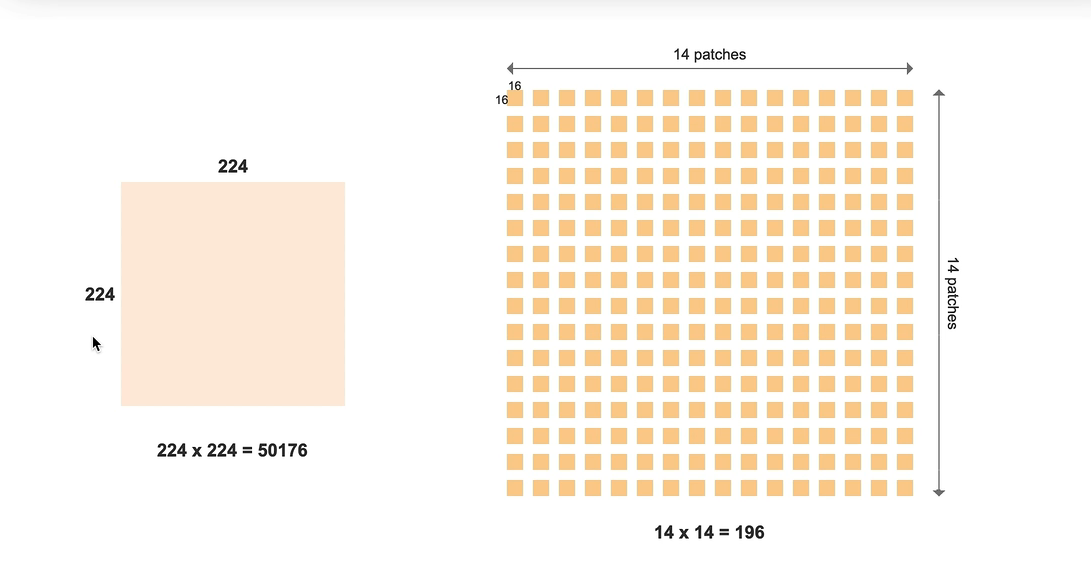
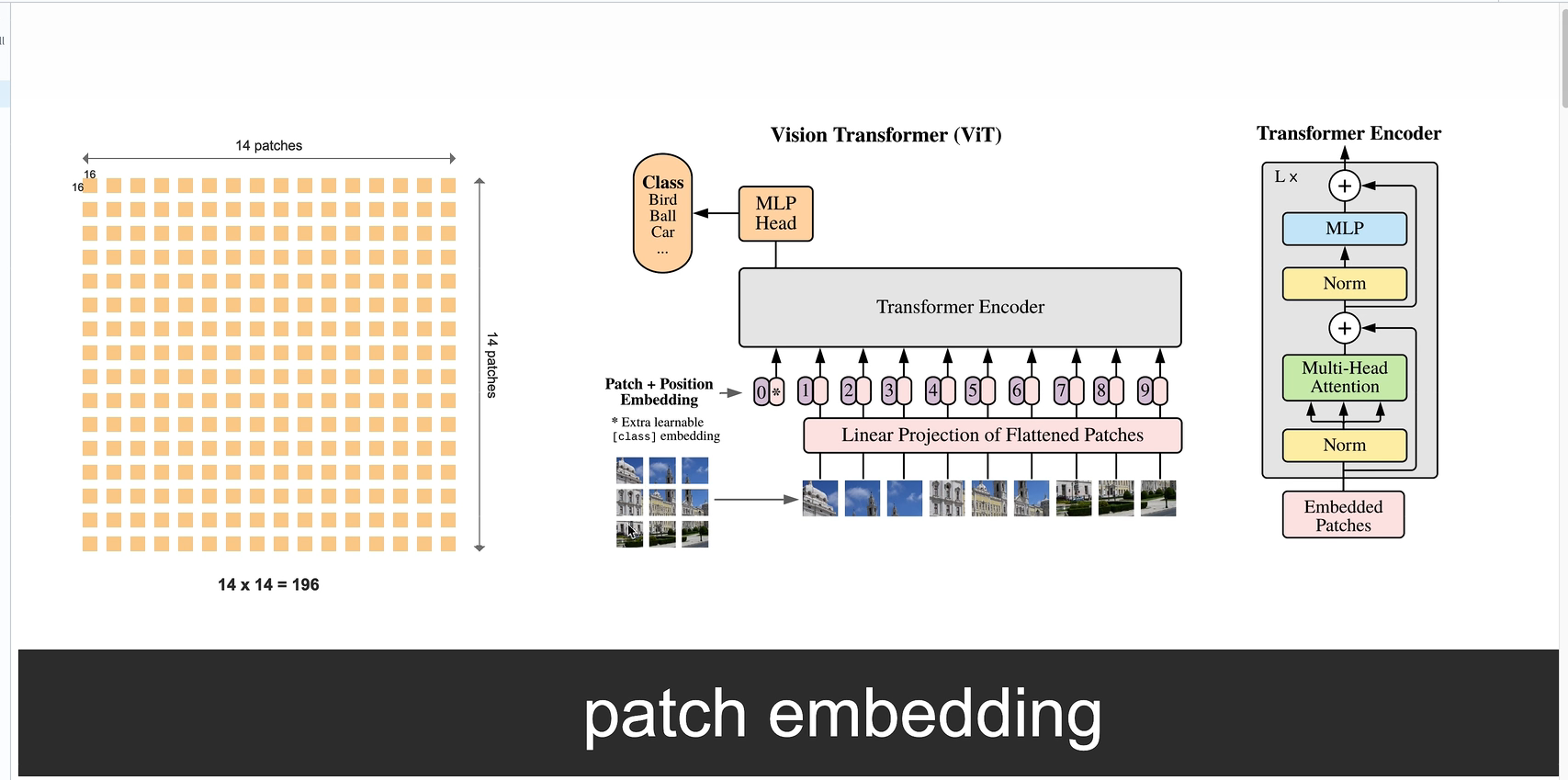
1 图中 3*3 是示意图 实际位14*14个块,词
2 分类标签token添加,,可以额外学习的,然后加入位置编码
3 得到10个结果,图像分类任务,只需要取出class token词对应的输出。
4 搞一个全连接层(简单理解),得到分类结果。、
代码
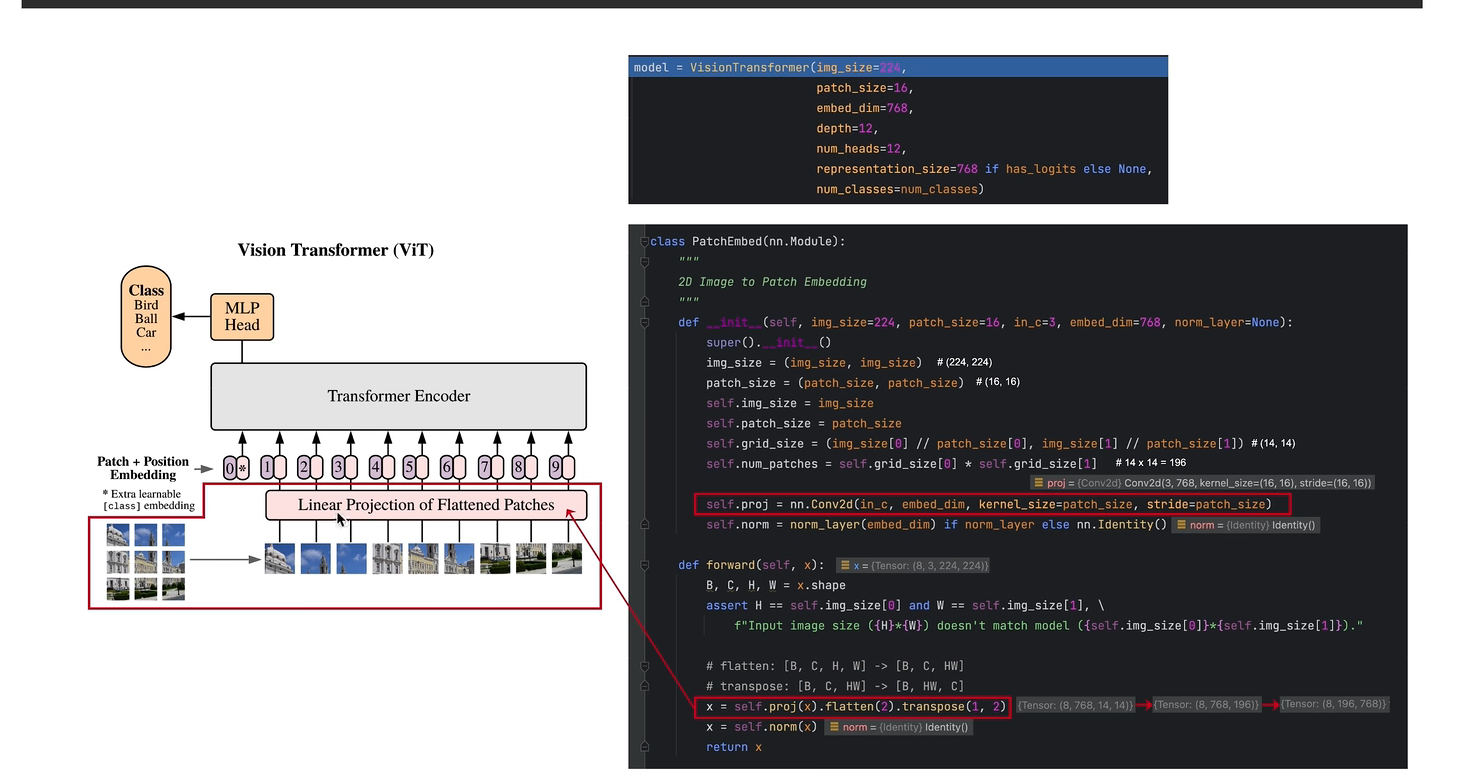
A 参数说明
1 图像尺寸 224*224
2 块大小 16*16

3 网格形状 grid_size 224/16=14个 (14,14)
4 网格总数 14*14=196个
B卷积层
只用来数据处理
卷积层 (3 个通道, 输出通道768个特征, 卷积核(16,16),扩展0,步幅(16,16))
(N-卷积核+2*扩展数目+步长)/步长
(16-16++16)/16=1 个
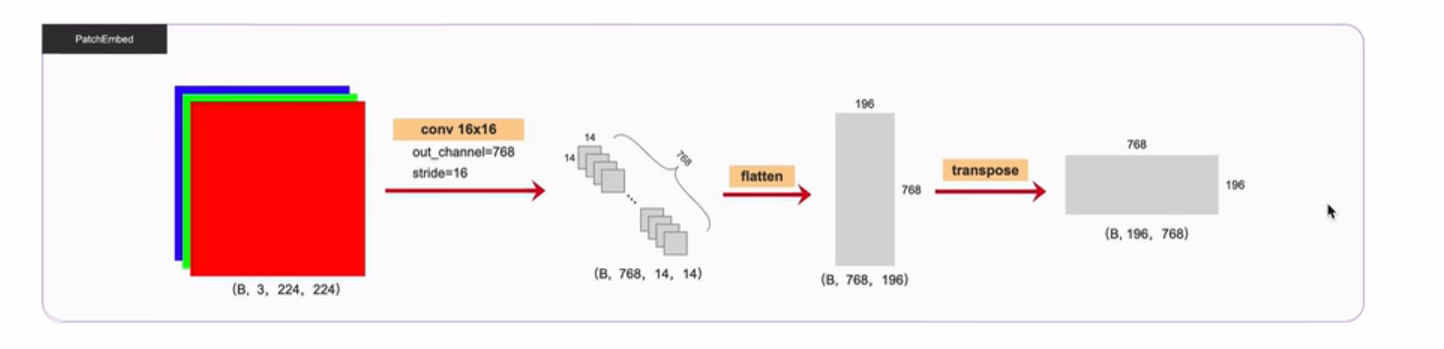
相当于 原来的16*16块变为一个像素,原有像素16*14*16*14=224*224个像素
原图 14*14个块 变为 14*14个像素=196个像素的 特征图
最后展平

输入
8个块 通道3 长宽224 224
结果 x 8个样本块 每个块14*14=196个像素 特征是人为i定义的768
- Transformer 模块 视觉 pytorch 10.5transformer模块 视觉pytorch transformer姿态 模型 视觉 adapter vit-adapter transformer视觉 ai_pytorch_transformer pytorch-vanilla transformer pytorch vanilla transformer架构pytorch 轻量 轻量级transformer视觉 正则transformer美图 视觉 ai_pytorch_transformer transformer pytorch ai transformer tensorflow pytorch gpt