一、多表查询
1、内连接
隐式内连接
使用一张以上的表做查询就是多表查询
语法:SELECT {DISTINCT} *|列名.. FROM 表名 别名,表名 1 别名 {WHERE 限制条件 ORDER BY 排序字段 ASC|DESC...}
DROP TABLE "SCOTT"."EMP"; CREATE TABLE "SCOTT"."EMP" ( "EMPNO" NUMBER(4) NOT NULL , "ENAME" VARCHAR2(10 BYTE) , "JOB" VARCHAR2(9 BYTE) , "MGR" NUMBER(4) , "HIREDATE" DATE , "SAL" NUMBER(7,2) , "COMM" NUMBER(7,2) , "DEPTNO" NUMBER(2) );
插入14条数据
INSERT INTO "SCOTT"."EMP" VALUES ('7369', 'SMITH', 'CLERK', '7902', TO_DATE('1980-12-17 00:00:00', 'SYYYY-MM-DD HH24:MI:SS'), '800', NULL, '20'); INSERT INTO "SCOTT"."EMP" VALUES ('7499', 'ALLEN', 'SALESMAN', '7698', TO_DATE('1981-02-20 00:00:00', 'SYYYY-MM-DD HH24:MI:SS'), '1600', '300', '30'); INSERT INTO "SCOTT"."EMP" VALUES ('7521', 'WARD', 'SALESMAN', '7698', TO_DATE('1981-02-22 00:00:00', 'SYYYY-MM-DD HH24:MI:SS'), '1250', '500', '30'); INSERT INTO "SCOTT"."EMP" VALUES ('7566', 'JONES', 'MANAGER', '7839', TO_DATE('1981-04-02 00:00:00', 'SYYYY-MM-DD HH24:MI:SS'), '2975', NULL, '20'); INSERT INTO "SCOTT"."EMP" VALUES ('7654', 'MARTIN', 'SALESMAN', '7698', TO_DATE('1981-09-28 00:00:00', 'SYYYY-MM-DD HH24:MI:SS'), '1250', '1400', '30'); INSERT INTO "SCOTT"."EMP" VALUES ('7698', 'BLAKE', 'MANAGER', '7839', TO_DATE('1981-05-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS'), '2850', NULL, '30'); INSERT INTO "SCOTT"."EMP" VALUES ('7782', 'CLARK', 'MANAGER', '7839', TO_DATE('1981-06-09 00:00:00', 'SYYYY-MM-DD HH24:MI:SS'), '2450', NULL, '10'); INSERT INTO "SCOTT"."EMP" VALUES ('7788', 'SCOTT', 'ANALYST', '7566', TO_DATE('1987-04-19 00:00:00', 'SYYYY-MM-DD HH24:MI:SS'), '3000', NULL, '20'); INSERT INTO "SCOTT"."EMP" VALUES ('7839', 'KING', 'PRESIDENT', NULL, TO_DATE('1981-11-17 00:00:00', 'SYYYY-MM-DD HH24:MI:SS'), '5000', NULL, '10'); INSERT INTO "SCOTT"."EMP" VALUES ('7844', 'TURNER', 'SALESMAN', '7698', TO_DATE('1981-09-08 00:00:00', 'SYYYY-MM-DD HH24:MI:SS'), '1500', '0', '30'); INSERT INTO "SCOTT"."EMP" VALUES ('7876', 'ADAMS', 'CLERK', '7788', TO_DATE('1987-05-23 00:00:00', 'SYYYY-MM-DD HH24:MI:SS'), '1100', NULL, '20'); INSERT INTO "SCOTT"."EMP" VALUES ('7900', 'JAMES', 'CLERK', '7698', TO_DATE('1981-12-03 00:00:00', 'SYYYY-MM-DD HH24:MI:SS'), '950', NULL, '30'); INSERT INTO "SCOTT"."EMP" VALUES ('7902', 'FORD', 'ANALYST', '7566', TO_DATE('1981-12-03 00:00:00', 'SYYYY-MM-DD HH24:MI:SS'), '3000', NULL, '20'); INSERT INTO "SCOTT"."EMP" VALUES ('7934', 'MILLER', 'CLERK', '7782', TO_DATE('1982-01-23 00:00:00', 'SYYYY-MM-DD HH24:MI:SS'), '1300', NULL, '10');
dept表
DROP TABLE "SCOTT"."DEPT"; CREATE TABLE "SCOTT"."DEPT" ( "DEPTNO" NUMBER(2) NOT NULL , "DNAME" VARCHAR2(14 BYTE) , "LOC" VARCHAR2(13 BYTE) );
插入4条数据
INSERT INTO "SCOTT"."DEPT" VALUES ('10', 'ACCOUNTING', 'NEW YORK'); INSERT INTO "SCOTT"."DEPT" VALUES ('20', 'RESEARCH', 'DALLAS'); INSERT INTO "SCOTT"."DEPT" VALUES ('30', 'SALES', 'CHICAGO'); INSERT INTO "SCOTT"."DEPT" VALUES ('40', 'OPERATIONS', 'BOSTON');
salgrade表
DROP TABLE "SCOTT"."SALGRADE"; CREATE TABLE "SCOTT"."SALGRADE" ( "GRADE" NUMBER , "LOSAL" NUMBER , "HISAL" NUMBER );
插入5条数据
INSERT INTO "SCOTT"."SALGRADE" VALUES ('1', '700', '1200'); INSERT INTO "SCOTT"."SALGRADE" VALUES ('2', '1201', '1400'); INSERT INTO "SCOTT"."SALGRADE" VALUES ('3', '1401', '2000'); INSERT INTO "SCOTT"."SALGRADE" VALUES ('4', '2001', '3000'); INSERT INTO "SCOTT"."SALGRADE" VALUES ('5', '3001', '9999');
查询员工表和部门表
select * from emp,dept;
由于emp表有14条记录,dept表有4条记录,故查询结果共有56条记录。
我们发现产生的记录数是 56 条,我们还会发现 emp 表是 14 条,dept 表是 4 条,56 正是 emp表和 dept 表的记录数的乘积,我们称其为笛卡尔积。
如果多张表进行一起查询而且每张表的数据很大的话笛卡尔积就会变得非常大,对性能造成影响,想要去掉笛卡尔积我们需要关联查询。
在两张表中我们发现有一个共同的字段是 depno,depno 就是两张表的关联的字段,我们可以使用这个字段来做限制条件,两张表的关联查询字段一般是其中一张表的主键,另一张表的外键。
select * from emp,dept where emp.deptno=dept.deptno
关联查询后,结果为14条记录
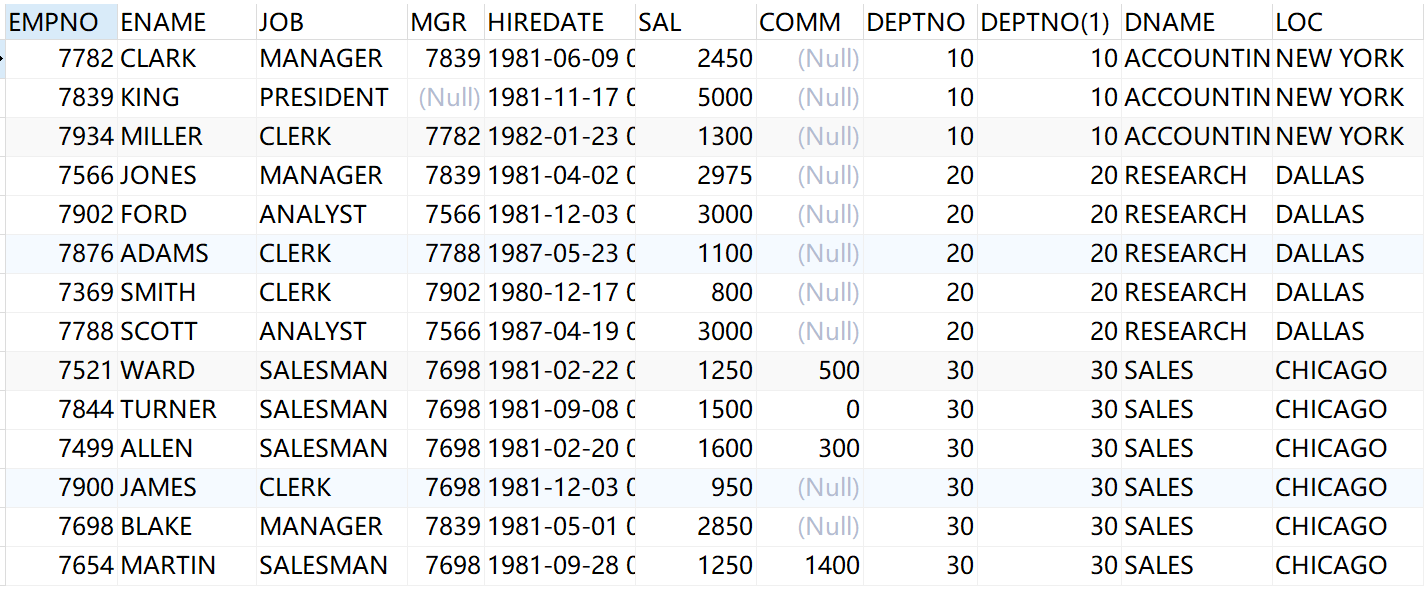
关联之后我们发现数据条数是 14 条,不在是 56 条。
多表查询我们可以为每一张表起一个别名
select * from emp e,dept d where e.deptno=d.deptno
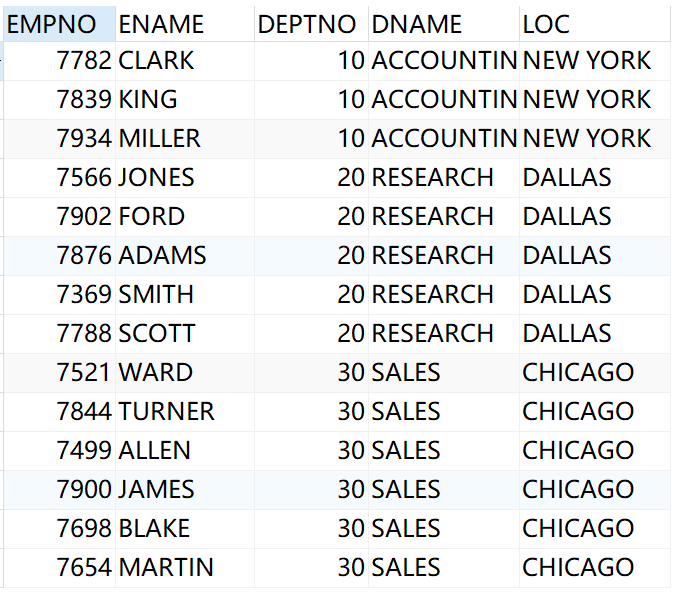
范例:查询出雇员的编号,姓名,部门的编号和名称,地址
select e.empno,e.ename,e.deptno,d.dname,d.loc from emp e,dept d where e.deptno=d.deptno
结果:
自关联查询
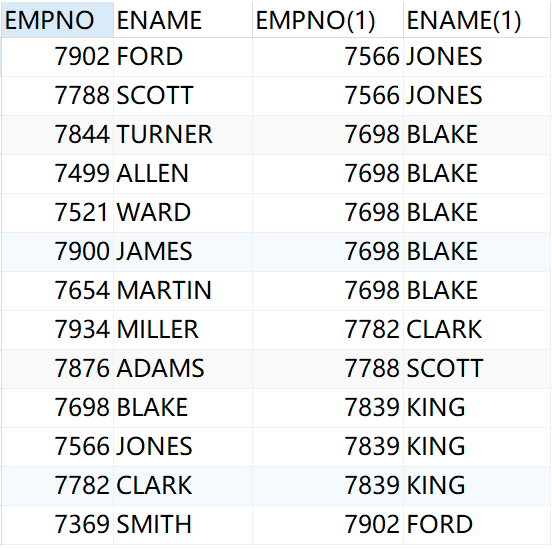
范例:查询出每个员工的上级领导
分析:emp 表中的 mgr字段是当前雇员的上级领导的编号,所以该字段对 emp表产生了自身关联,可以使用 mgr 字段和 empno 来关联
select e1.empno,e1.ename,e2.empno,e2.ename from emp e1,emp e2 where e1.mgr=e2.empno
结果为:
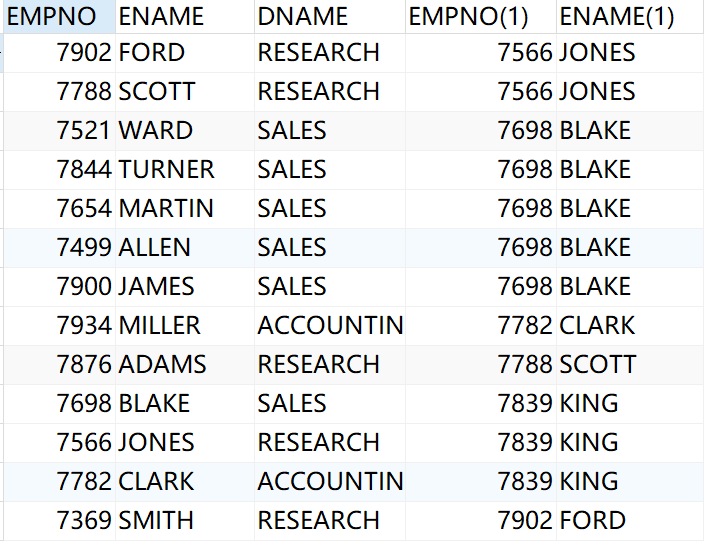
--范例:在上一个例子的基础上查询该员工的部门名称 select e1.empno,e1.ename,d.dname,e2.empno,e2.ename from emp e1,emp e2,dept d where e1.mgr=e2.empno and d.deptno = e1.deptno
结果:
范例:查询出每个员工编号,姓名,部门名称,工资等级和他的上级领导的姓名,工资等级
select e.empno,e.ename, case when s.grade=1 then 'first grade' when s.grade=2 then 'second grade' when s.grade=3 then 'third grade' when s.grade=4 then 'fouth grade' when s.grade=5 then 'fifth grade' end as grade1 , d.dname,e1.empno, e1.ename, case when s1.grade=1 then 'first grade' when s1.grade=2 then 'second grade' when s1.grade=3 then 'third grade' when s1.grade=4 then 'fouth grade' when s1.grade=5 then 'fifth grade' end as grade2 from emp e,emp e1,dept d,salgrade s ,salgrade s1 where e.mgr=e1.empno and d.deptno=e.deptno and e.sal between s.losal and s.hisal and e1.sal between s1.losal and s1.hisal
注意:1、salgrade表要用两张表进行区分。2、先根据sal在losal和hisal之间再根据grade的值来确定工资等级。
结果:

2、外连接
1、 左连接和右连接
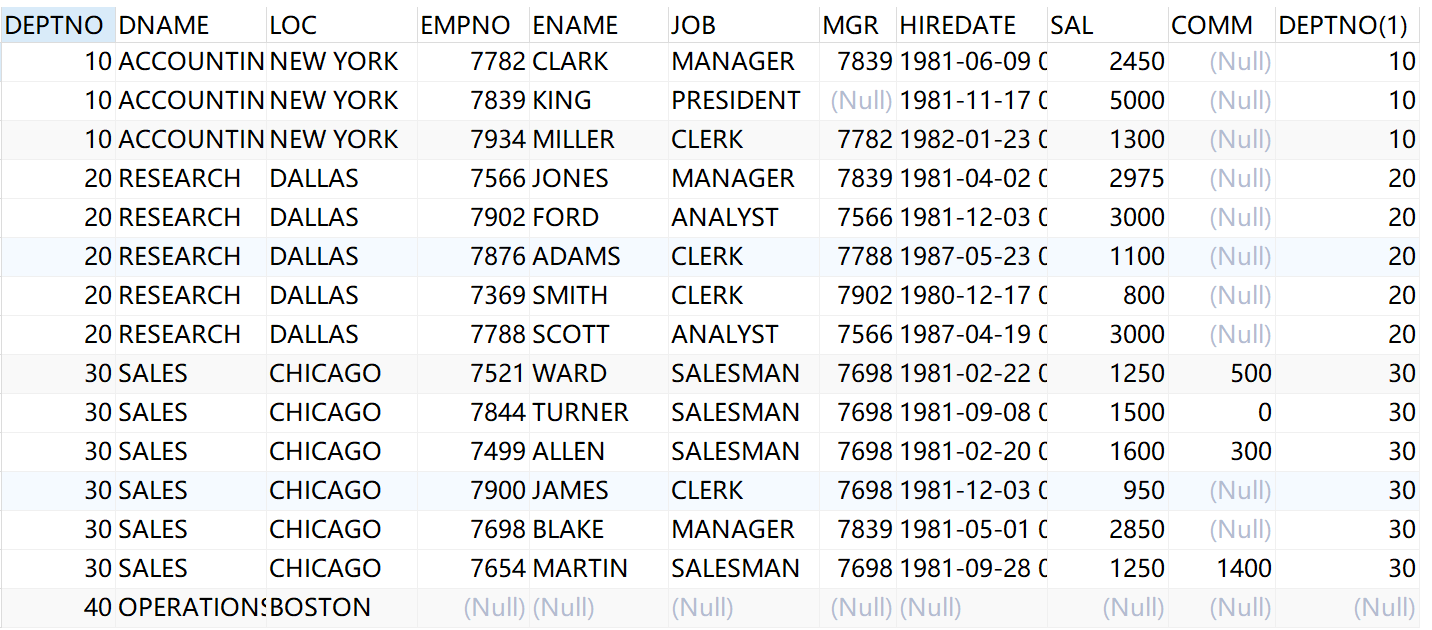
-- 查询出所有的部门下的员工 select * from dept left outer join emp on dept.deptno=emp.deptno
结果如下:
左连接右连接的另外一种表示方法:
使用(+)表示左连接或者右连接,当(+)在左边表的关联条件字段(即右边表的字段)上时是左连接,如果是在右边表的关联条件字段上就是右连接。
select * from dept,emp where dept.deptno=emp.deptno(+)
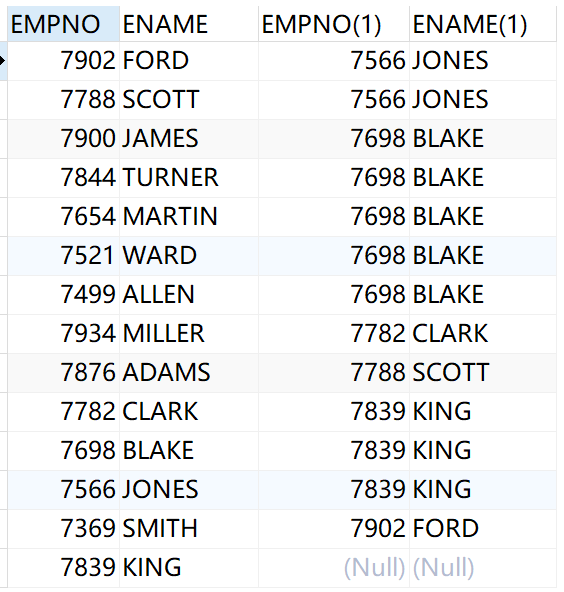
范例:查询出所有员工的上级领导
分析:我们发现使用我们以前的做法,即使用内连接,由于KING没有上级领导,所以KING没有被查询出来。发现 KING 的上级领导没有被展示,我们需要使用左右连接把他查询出来
select e1.empno,e1.ename,e2.empno,e2.ename from emp e1,emp e2 where e1.mgr=e2.empno(+)
结果为:
JOIN的左边尽量放小数据量的表,这样可以提高查询效率,优化查询速度。
多个left join的执行顺序
例如:
SELECT table_1.a, table_1.b, table_1.c FROM table_1 LEFT JOIN table_2 ON table_1.uid = table_2.uid LEFT JOIN talbe_3 ON table_1.uid = table_3.uid
执行顺序是:table_1和table_2先组合成一个虚拟表,然后这个虚拟表再和table_3关联。
二、left join需要注意的事项
1、筛选条件放在where后和on后是不一样的
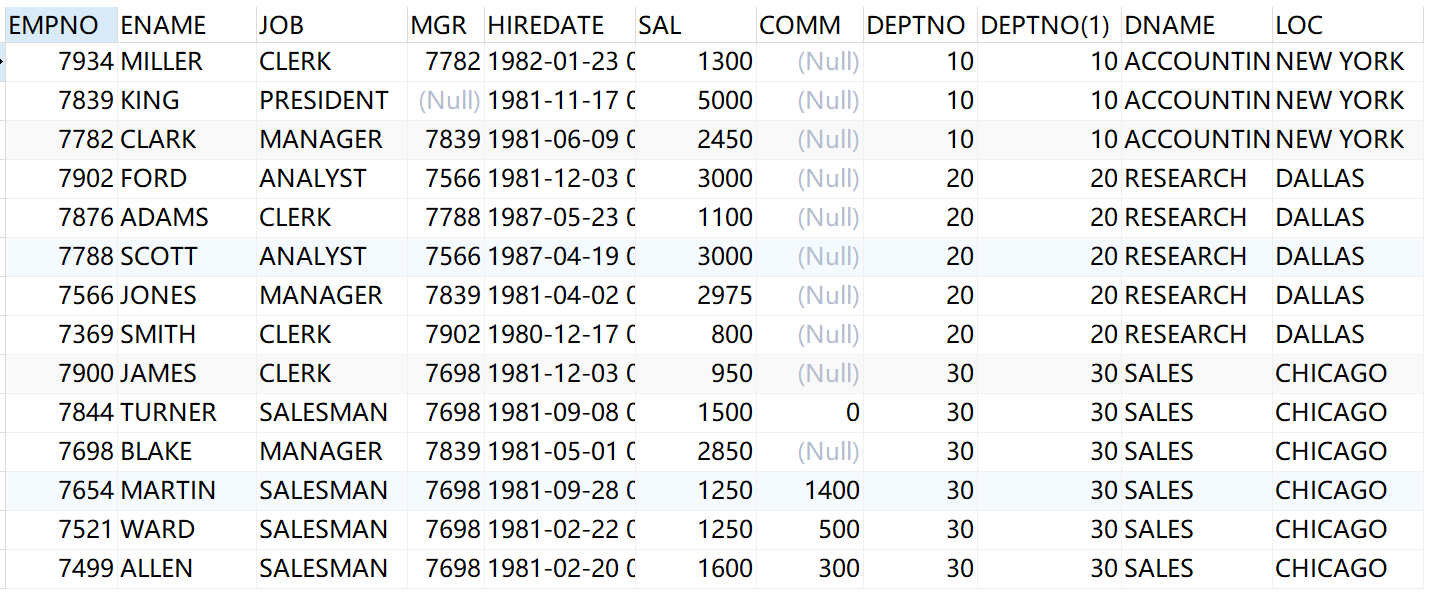
select * from emp left outer join dept on dept.deptno=emp.deptno
结果:
当筛选条件放到where后,表示对左外连接的数据进行筛选
select * from emp left outer join dept on dept.deptno=emp.deptno where dept.dname='SALES';
结果如下:

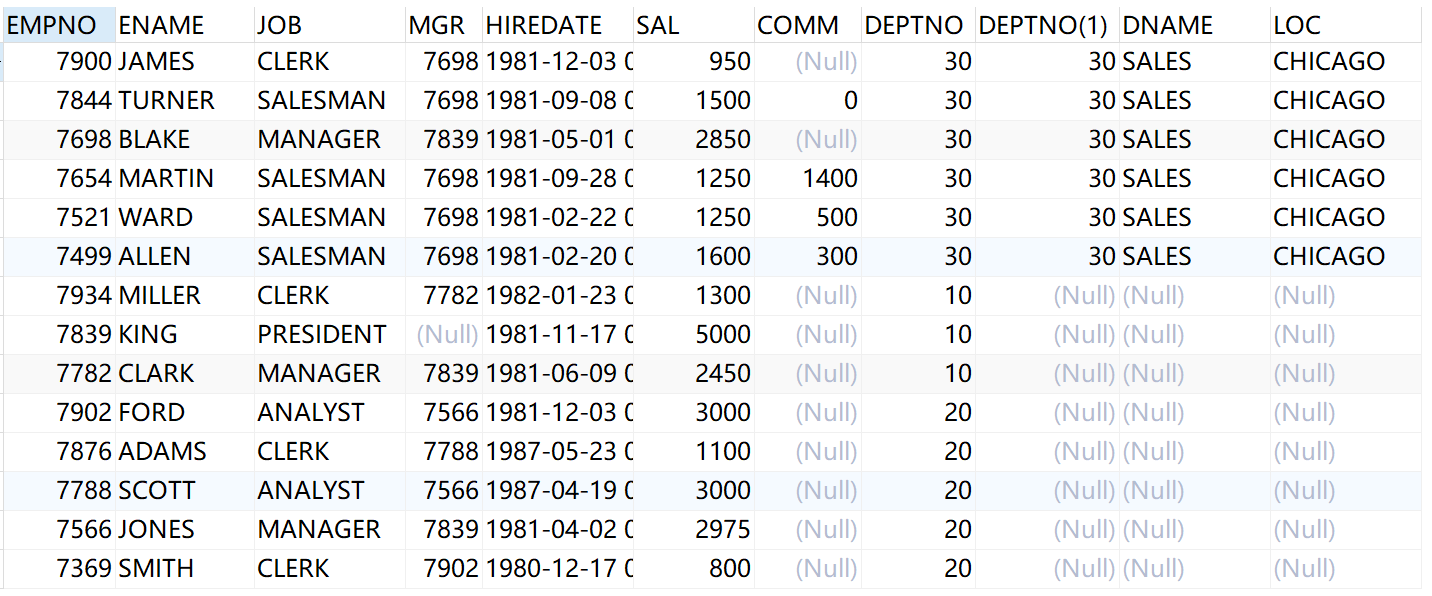
当筛选条件放到on后,表示在左外连接后,对右表的数据进行筛选,左表的数据全有。
select * from emp left outer join dept on dept.deptno=emp.deptno and dept.dname='SALES';
结果如下:
如果被关联的表中没有能匹配关联条件,这会让数据库用NULL去填充结果。
2、使用left join查询数据字典时需要先left join t_dict_type再left join t_dict_entry
当不使用left join时
select * from b_cts_product where product_name = '地西泮注射液' and authorized_no='H41024255';
此时只能查出一条数据
当我们先left join t_dict_type再left join t_dict_entry时
select t1.*,de.dictname as type from b_cts_product t1 left join t_dict_type dt on dt.dicttypecode = 'PRODUCT_TYPE' left join t_dict_entry de on de.dictcode = t1.type and dt.dicttypeid = de.dicttypeid where product_name = '地西泮注射液' and authorized_no='H41024255';
此时也只能查出一条数据。
当我们先left join t_dict_entry再left join t_dict_type时
select t1.*,de.dictname as type from b_cts_product t1 left join t_dict_entry de on de.dictcode = t1.type left join t_dict_type dt on dt.dicttypecode = 'PRODUCT_TYPE' and dt.dicttypeid = de.dicttypeid where product_name = '地西泮注射液' and authorized_no='H41024255';
此时能查询出26条数据,显然是不正确的。
这种情况下,left join之后数据量增加,因为t_dict_entry表中有重复的dictcode(如存在很多值为3的dictcode),并且正好符合关联条件的时候,结果表就会被撑大。