图形渲染隐式函数与采样方式
隐式函数
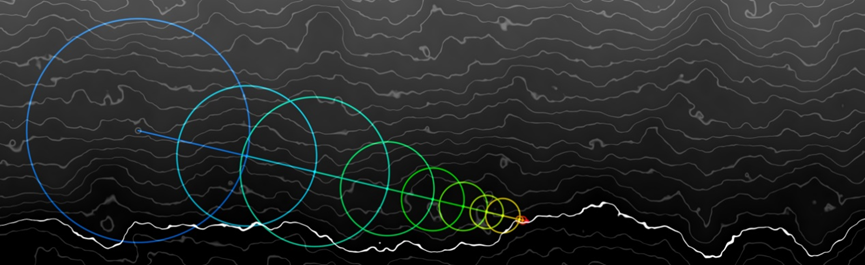
球体追踪是光线追踪的诸多形式的其中一种,是隐式函数的理想选择,不是光栅化或体素的替代品。很低效,但是很简单,并且非常灵活。球体追踪只需要4步:
- 构建视图。
只需要两个三角形和UV坐标。相关的代码如下:
vec2 screen_coordinates = gl_FragCoord.xy;
screen_coordinates /= resolution;
screen_coordinates = screen_coordinates - .5;
screen_coordinates *= resolution/min(resolution.x, resolution.y);
float field_of_view = 1.5;
vec3 direction = vec3(screen_coordinates, field_of_view);
direction = normalize(direction);
- 追踪光线。
追踪的步骤和射线步长如下所示:

对应的代码:
vec2 origin = vec2(0.0);
vec2 position = origin;
float surface_threshold = 0.001;
for(int i=0; i<128; i++)
{
float distance_to_surface = map(position);
if(distance_to_surface < surface_threshold)
break;
position += direction * distance_to_surface;
}
float distance_to_scene = distance(origin, position);
- 确定曲面的朝向。
在光线末端附近采样,比较它们的偏导数,通过除以毕达哥拉斯定理的结果进行归一化:

获得了表面的法线:

法线可以从场中的任何位置采样,而不仅仅是表面:

- 添加灯光。
增加光源的代码和效果如下:

通过以上几个步骤,就可以实现复杂而有趣的场景(来自shadertoy):

显式数据作为独立值存储在存储器中,如网格顶点、纹理像素等…从存储器中读取数据。隐式数据的代码是数据,一切都是程序性的,通过计算访问数据。

通过简单的加减乘除和mod、min、max、noise等操作可以实现复杂、自然的模型:

关于距离和噪音,有一些事情需要注意。大多数情况下,需要很多步骤才能找到物体表面,这也是个问题。追踪正弦曲线时,空间不是线性的。Mod和噪声操作同样如此(下图)。

噪声还会引起渲染瑕疵:

有人说你应该不惜一切代价避免噪声,因为它会破坏渲染,其他人则不同意,下面是非噪声和添加噪声的场景对比:

采样方式
在图形学中,采样是个有意思却蕴含着丰富的技术,包含了各式各样的方式。在光线追踪中,常见的采样有均匀、随机、低差异序列、重要性等方式。
均匀采样(Uniform Sampling)是不区分光源重要性的平均化采样,生成的光线样本在各个方向上概率都相同,并不会对灯光特殊对待,偏差与实际值通常会很大。蒙特卡洛采样(Monte Carlo Sampling)着重考虑了光源方向的采样,能突出光源对像素的贡献量,但会造成光源贡献量过度。重要性采样(Importance Sampling)则加入概率密度函数pdf,通过缩小采样结果,防止光源的贡献量太大。

左:完全伪随机序列生成的采用点;右:低差异序列生成的采样点。可以看出右边的更均匀。

蒙特卡洛采样使用随机样本来数值计算该积分。重要性采样的思想是尝试生成与具有类似形状的被积函数的概率密度函数(PDF)成比例的随机样本。
UE在实现TAA时采用了Halton、Sobal等序列:

相比随机采样,Halton获得的采样序列更加均匀,且可以获得没有上限的样本数(UE默认限制在8以内)。除此之外,还有Sobel、Niederreiter、Kronecker等低差异序列算法,它们的比较如下图:

所有采样技术都基于将随机数从单位平方扭曲到其它域,再到半球、球体、球体周围的圆锥体,再到圆盘。还可以根据BSDF的散射分布生成采样,或选择IBL光源的方向。有许许多多的采样方式,但它们都是从0到1之间的值开始的,其中有一个很好的正交性:有“你开始的那些值是什么”,然后有“你如何将它们扭曲到你想要采样的东西的分布,以使用第二个蒙特卡罗估计”。
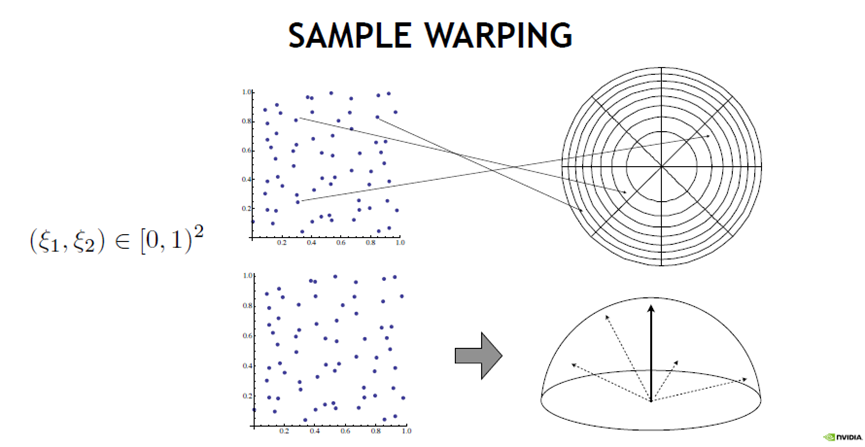
对应采样方式,常用的有均匀、低差异序列、分层采样、元素区间、蓝噪点抖动等方式。低差异类似广义分层,蓝色噪点类似不同样本之间的距离有多近。过程化模式可以使用任意数量的前缀,并且(某些)前缀分布均匀。

方差驱动的采样——根据迄今为止采集的样本,周期地估计每个像素的方差,在差异较大的地方多采样,更好的做法是在方差/估计值较高的地方进行更多采样,在色调映射等之后执行此操作。离线(质量驱动):一旦像素的方差足够低,就停止处理它。实时(帧率驱动):在方差最大的地方采集更多样本。计算样本方差(样本方差是对真实方差的估计):
float SampleVariance(float samples[], int n)
{
float sum = 0, sum_sq = 0;
for (int i=0; i<n; ++i)
{
sum += samples[i];
sum_sq += samples[i] * samples[i];
}
return sum_sq/(n*(n-1))) - sum*sum/((n-1)*n*n);
}
样本方差只是一个估计值,大量的工作都是为了降噪,MC渲染自适应采样和重建的最新进展。总体思路:在附近像素处加入样本方差,可能根据辅助特征(位置、法线等)的接近程度进行加权。高方差是个诅咒,一旦引入了一个高方差样本,就会有大麻烦了,可以考虑对数据进行均匀采样。
此外,对于不同粗糙度的表面,所需的光线数量和方向亦有所不同:

在计算阴影、AO等通道中,也使用了重要性采样来生成光线,相同视觉质量需要的光线更少。重要性采样过程中使用了半球、余弦采样、距离采样:

从左到右:半球、半球+余弦、半球+余弦+距离。
更进一步的,存在多重要性采样(Multiple Important Sampling,MIS),以便同时考量光源、BRDF、PDF等因素的影响,对采样的方向和位置等有所偏倚。

多重要性采样公式:

其中:  是从某个 PDF 中提取的样本数
是从某个 PDF 中提取的样本数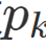 ,加权函数
,加权函数 采用可能生成样本的所有不同方式,并且可以通过幂启发式计算:
采用可能生成样本的所有不同方式,并且可以通过幂启发式计算:

除了以上方式,还有方差、域扭曲、准随机序列、低差异、分层等等采样方式。准蒙特卡罗(QMC)的特点是确定性、低差异序列/集合(Halton、Hammersley、Larcher-Pillichshammer)比随机的收敛速度更好,例如Sobol或(0-2)序列不需要知道样本数量,奇妙的分层特性。

若是继续拓广之,可以以任意形状任意数量的tap去采样,如双边、蓝噪声、棋盘、星状等,或者它们之间的结合:

为了避免阶梯式瑕疵,Inside使用了随机采样(蓝色噪点 + TRAA)。

双边上采样的其中一种模式。
更有甚者,可以通过旋转、升至更高维度以获得更多样本和低噪点:



总之,目前存在诸多采样方式,目的都是为了让光线追踪更快地收敛到准确结果,从而降低噪点,提升渲染性能。