学期(2023-2024-1) 学号(20232411)《网络空间安全导论》第五周学习总结
教材学习内容总结
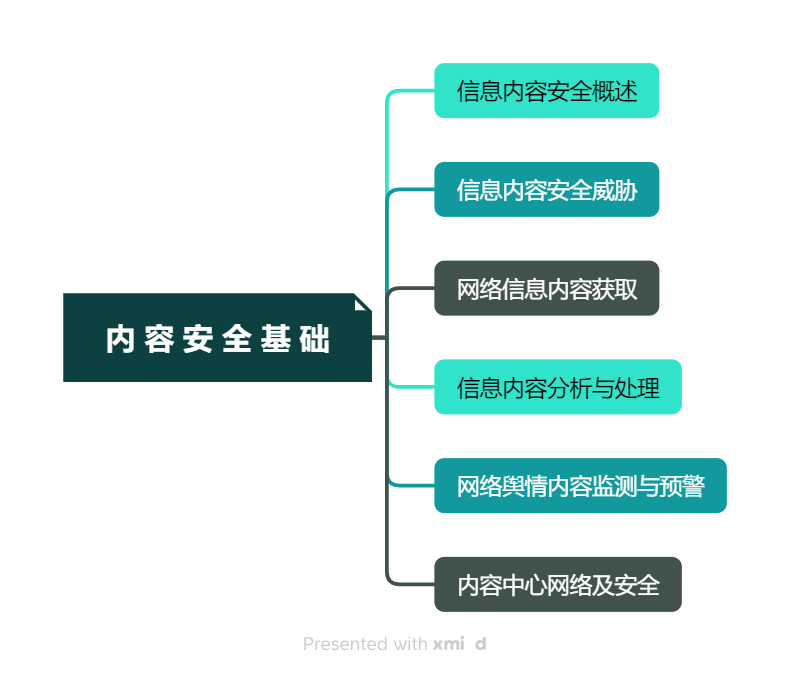
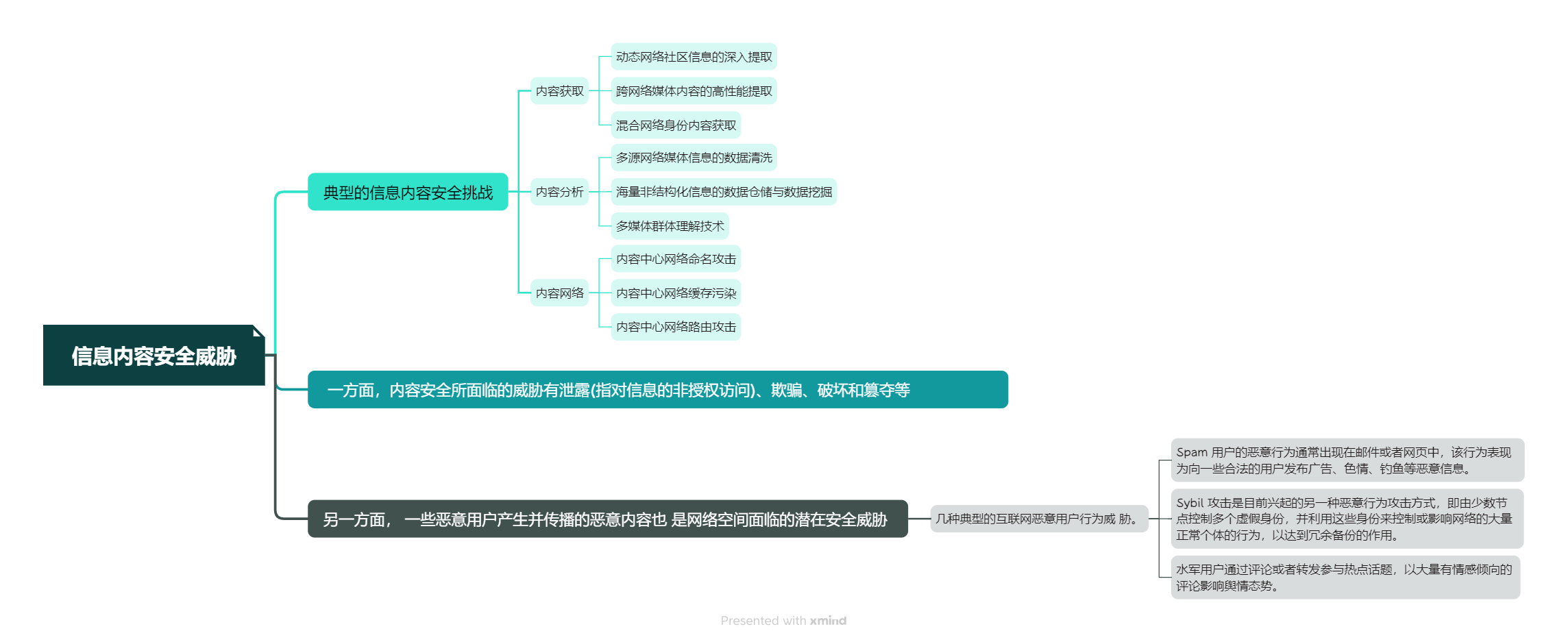
本周我学习了《网络空间安全导论》的第五章,其主要讲述了内容安全的概述,意义及其面对的主要威胁,以及信息内容的分析与处理方法,网络舆情系统的功能及应用。
在学习过程中,我总结了如下要点,以思维导图的方式呈现:


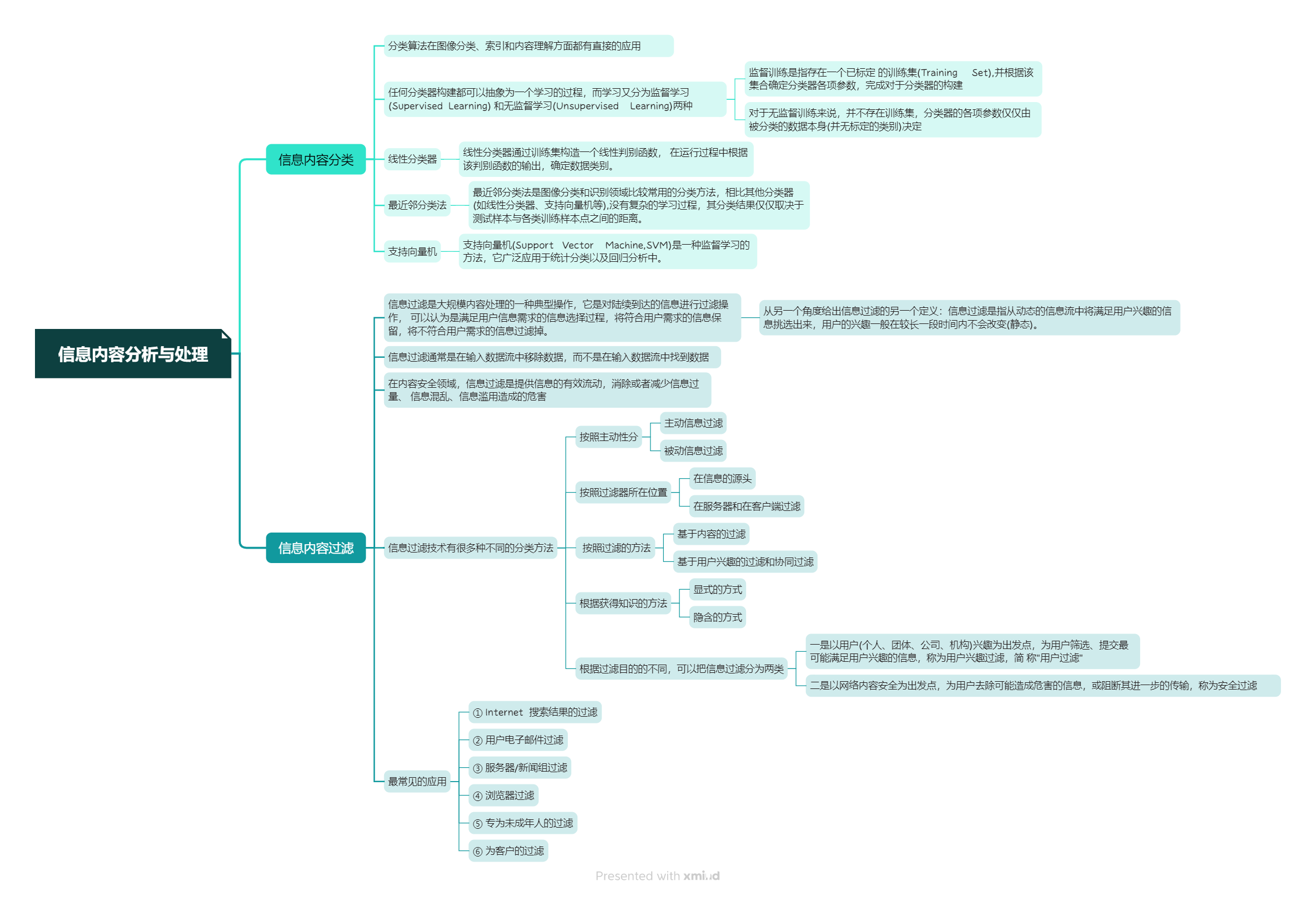
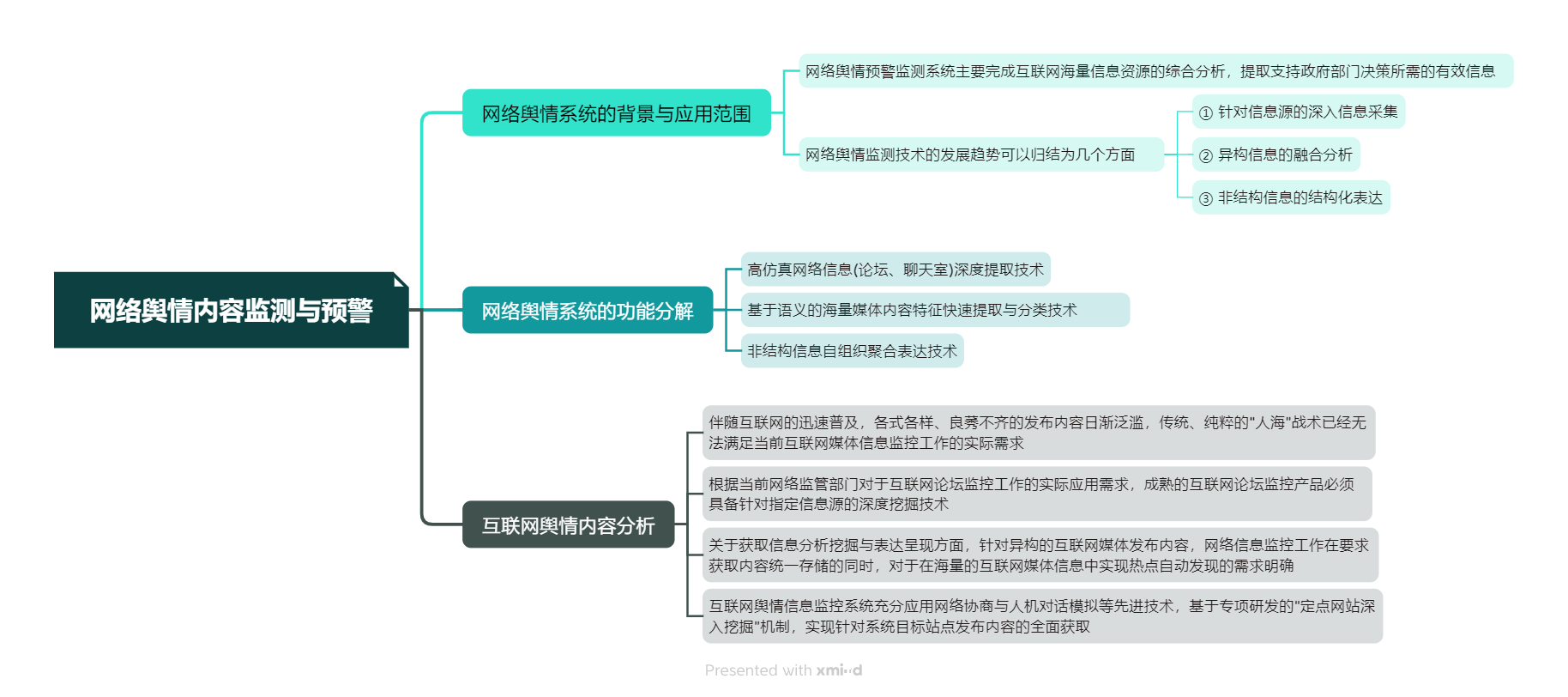
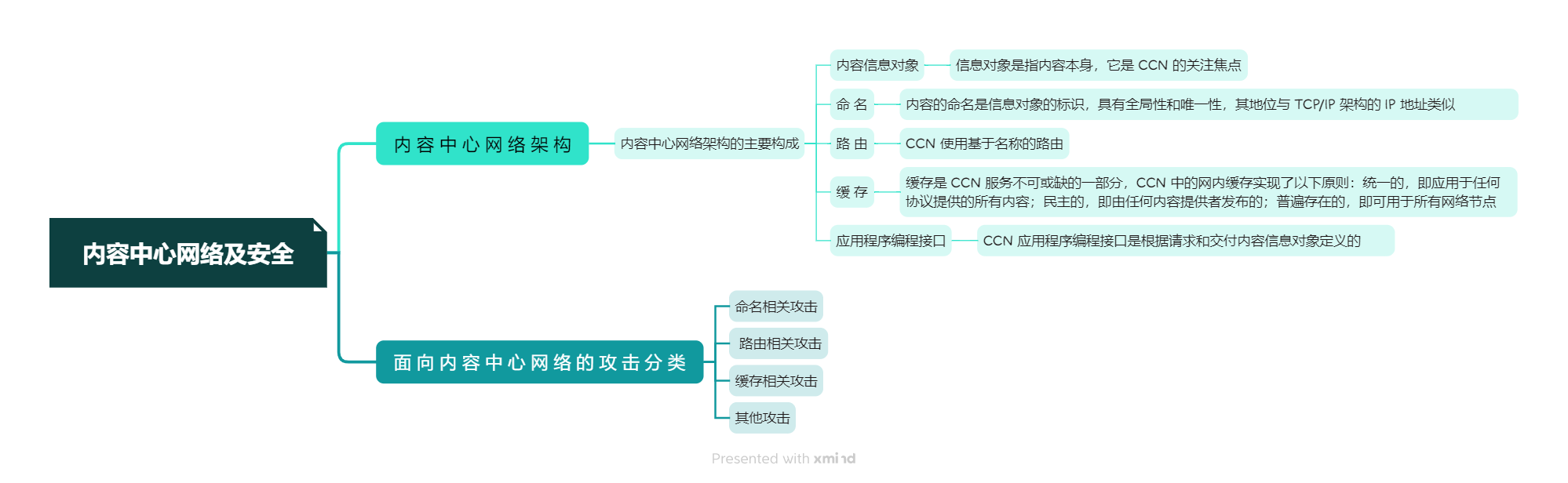
教材学习中的问题和解决过程
- 问题1:监督学习和无监督学习各有什么优劣?
- 问题1解决方案:通过研读课本及询问ChatGTP得知:
- 监督学习:
- 优点:
- 1.监督学习使用有标签的训练数据,可以通过比较预测结果和真实标签来进行模型的评估和优化。
- 2.监督学习可以进行分类和回归任务,能够预测离散值和连续值。
- 3.监督学习可以利用已知的标签信息进行模型训练,能够更好地理解数据的特征和关系。
- 缺点:
- 1.监督学习需要大量的标记数据,数据标注成本高,且可能存在标签噪声。
- 2.监督学习对数据的依赖性较高,当遇到新的未标记数据时,模型可能无法进行准确预测。
- 3.监督学习对特征的选择和提取要求较高,需要人工进行特征工程。
- 优点:
- 无监督学习:
- 优点:
- 1.无监督学习不需要标签数据,可以直接对未标记数据进行学习和分析。
- 2.无监督学习可以发现数据中的隐藏模式和结构,帮助理解数据的内在特征。
- 3.无监督学习可以用于数据降维、聚类、异常检测等任务。
- 缺点:
- 1.无监督学习的结果通常较难进行评估和验证,因为没有标签数据进行比较。
- 2.无监督学习的结果可能存在多个解释,解释性较差。
- 3.无监督学习对数据的依赖性较高,对数据质量和噪声敏感。
- 优点:
- 综上所述,监督学习适用于有标签数据且需要进行分类或回归预测的任务,而无监督学习适用于无标签数据且需要发现数据内在结构和模式的任务。
- 监督学习:
- 问题2:
- 问题2解决方案:通过查阅资料及chatGTP得出:
- 1.提高信息检索效率:信息内容过滤可以帮助用户快速找到所需的信息,避免浪费时间和精力在大量无用的信息上。
- 2.优化用户体验:通过过滤掉垃圾信息、重复信息和低质量信息,用户可以更轻松地获取到高质量、有用的信息,提升用户满意度和体验。
- 3.保护用户安全:信息内容过滤可以过滤掉含有恶意软件、病毒、欺诈等不安全内容的信息,保护用户的设备和个人信息安全。
- 4.个性化推荐:通过对用户的兴趣和偏好进行分析,信息内容过滤可以为用户提供个性化的推荐内容,提高用户的满意度和忠诚度。
- 5.降低信息过载:随着互联网的发展,信息爆炸式增长,用户面临着大量信息的困扰。信息内容过滤可以帮助用户过滤掉不相关或不感兴趣的信息,减轻信息过载的压力。
基于AI的学习