几个贯穿始终的概念
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
当我们把人类学习简单事物的过程抽象为几个阶段,再将这些阶段通过不同的方法具体化为代码,依靠通过计算机的基础能力--计算。我们就可以让机器能够“学会”一些简单的事物。
我们首先将视线聚焦在最简单的判断题上。而包括OCR,CV,自然语言处理在本质上来说就是对给定的图像(语句)做判断
判断:给定输入,得到一个输出
数据由我们学习的内容所决定.但是从现实生活中收集而来的数据,并不是机器能够"食用"的,需要我们通过一定的数据预处理,清洗数据以备使用.
而算法和模型决定了了输出端和输入端之间的关系.机器是否能够学会处理输入端的数据,需要合适的算法和模型的帮助
而机器学习不仅要从0到1,还要从1到100.这就意味着机器需要不断的练习.来提高正确率.
所以数据、模型、算法和训练是贯穿我们学习机器学习过程的四个关键词.也是一个面对问题建立模型最终实现的过程.
-
数据部分:学习了解流行的数据流.知道数据处理的benchmark.学会常见的数据预处理方法,总结数据处理技巧.
-
模型部分:学习常见的模型.各个模型相互关联加强记忆
-
算法部分:误差损失函数,反向传播,梯度下降.
算法和模型的区别在于:模型是静态的神经网络,没有特殊性;而算法就是模型动态的调整以吻合特定问题的需要
- 训练部分:降低训练时间,提高性能
环境配置
- CUDA “训练”时的算力由显卡提供。CUDA为英伟达的底层显卡驱动(AMD暂时不了解)。
- 主要使用Python内置的数学库来实现,推荐使用Anaconda来配置.
CUDA
1.打开NVIDIA控制台
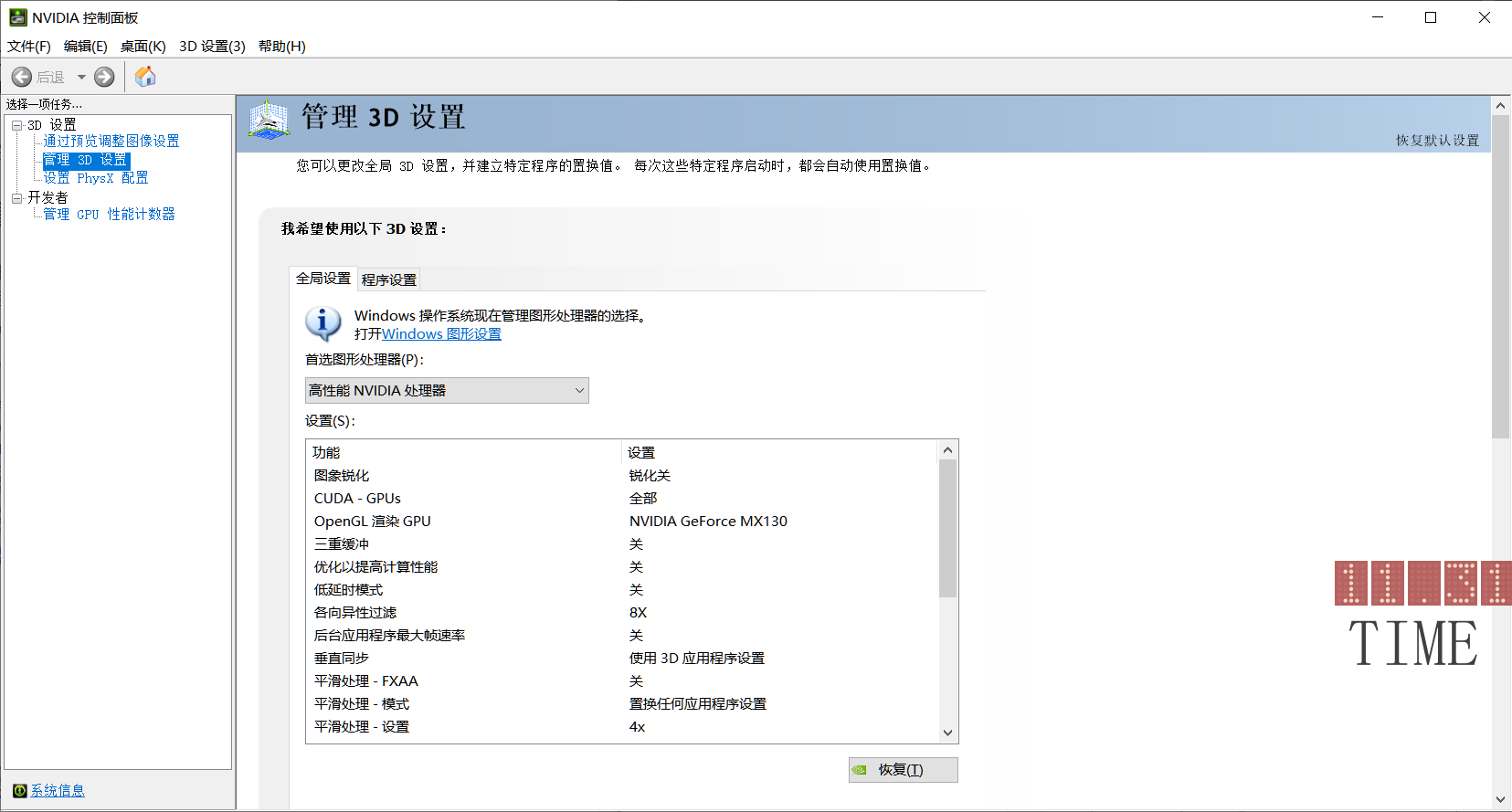
2.看一下有没有CUDA-GPUs

3.下载CUBA
在NVIDIA控制界面的左下角,点击系统性息
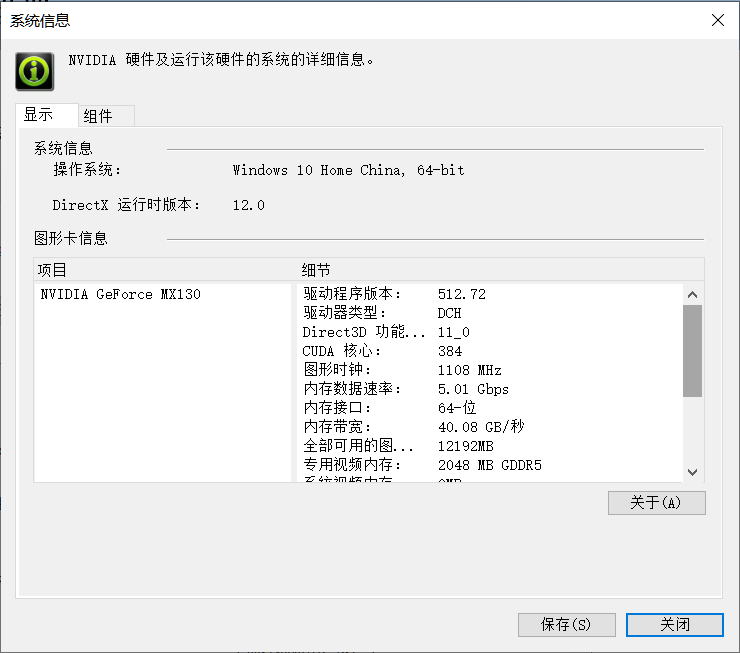
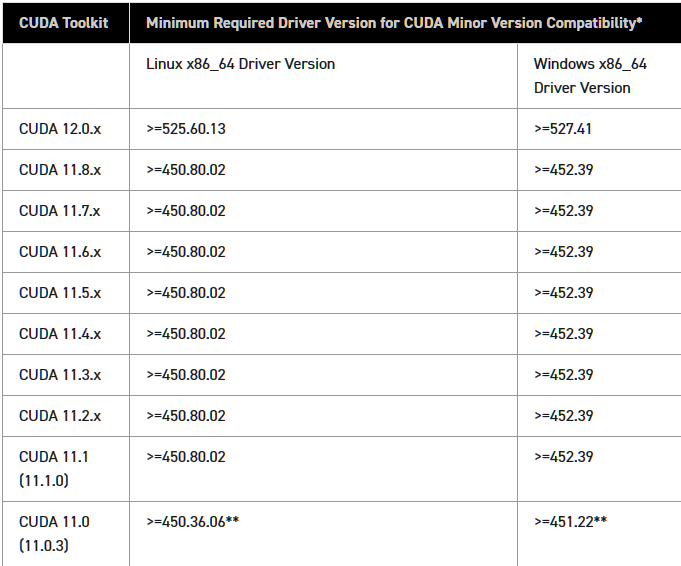
查看一下驱动程序版本,对照下图查看,下载支持的CUDA的版本
我的驱动版本是512.72,所以支持的最新驱动是CUBA 11.8.X
附上链接以供查阅
安装没有难度,只不过建议 路径不要出现中文字符,记住安装路径即可。安转完成之后 按下win+r键 打开cmd在命令行中输入nvcc -V然后回车,成功的话就会返回CUBA的版本号
安装Anaconda
这个安装比较简单(路径不要出现中文字符)建议去清华或者其他镜像库安装,下面讲述如何配置环境变量
环境配置
1.设置 -> 系统 -> 关于 -> 右侧目录中选择高级系统设置

点击环境变量
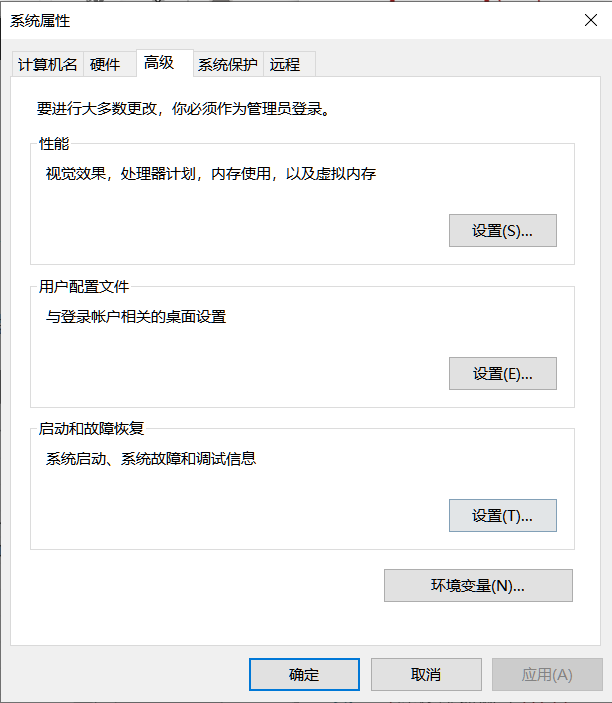
在path中添加anaconda文件夹和script

conda install镜像配置
软件本体下载慢,python的一些包也下载慢。所以我们可以配置清华的镜像。清华镜像网站
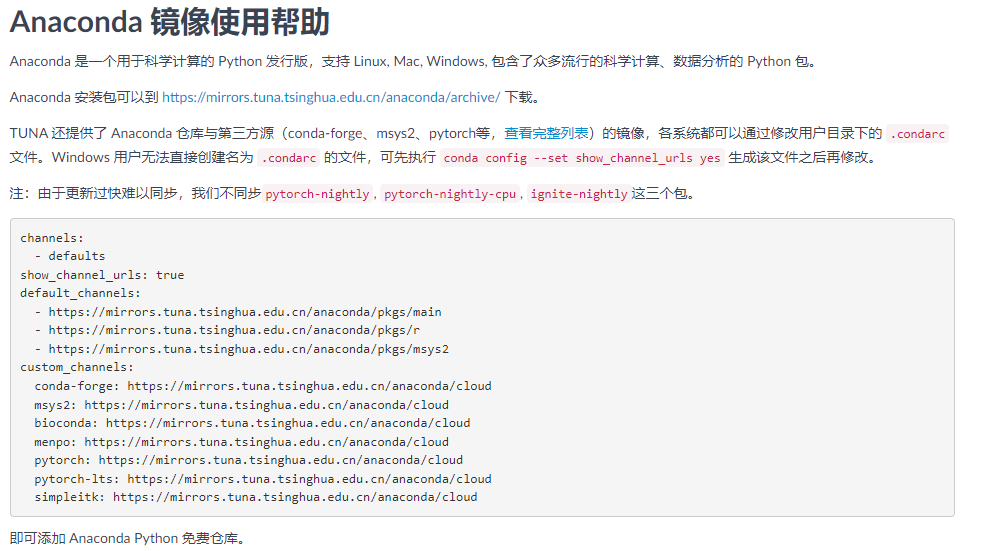
简要介绍:
1、现在用户目录下查看是否有.condarc文件 没有的话 在cmd命令行中执行
conda config -set show_channel_urls yes
然后进行修改。
2、修改之后执行
conda clean -i
Anaconda的使用
conda的好处在于我们可以按照需要配置环境,无论是Python版本还是其中包的版本和依赖
conda命令行
注意:使用conda命令时应该确定是对某个特定环境使用
conda –version #查看conda版本,验证是否安装
conda update conda #更新至最新版本,也会更新其它相关包
conda update –all #更新所有包
conda update package_name #更新指定的包
conda create -n env_name package_name #创建名为env_name的新环境,并在该环境下安装名为package_name 的包,可以指定新环境的版本号,例如:conda create -n python3 python=python3.7 numpy pandas,创建了python3环境,python版本为3.7,同时还安装了numpy pandas包
conda activate env_name #切换至env_name环境
conda deactivate #退出环境
conda info -e #显示所有已经创建的环境 或者使用 conda env list
conda create –name new_env_name –clone old_env_name #复制old_env_name为new_env_name
conda remove –name env_name –all #删除环境
conda list #查看所有已经安装的包
conda install package_name #在当前环境中安装包
conda install –name env_name package_name #在指定环境中安装包
conda remove – name env_name package #删除指定环境中的包
conda remove package #删除当前环境中的包
conda env remove -n env_name #强制删除环境
先来安装比较重要的一个包numpy来试试手
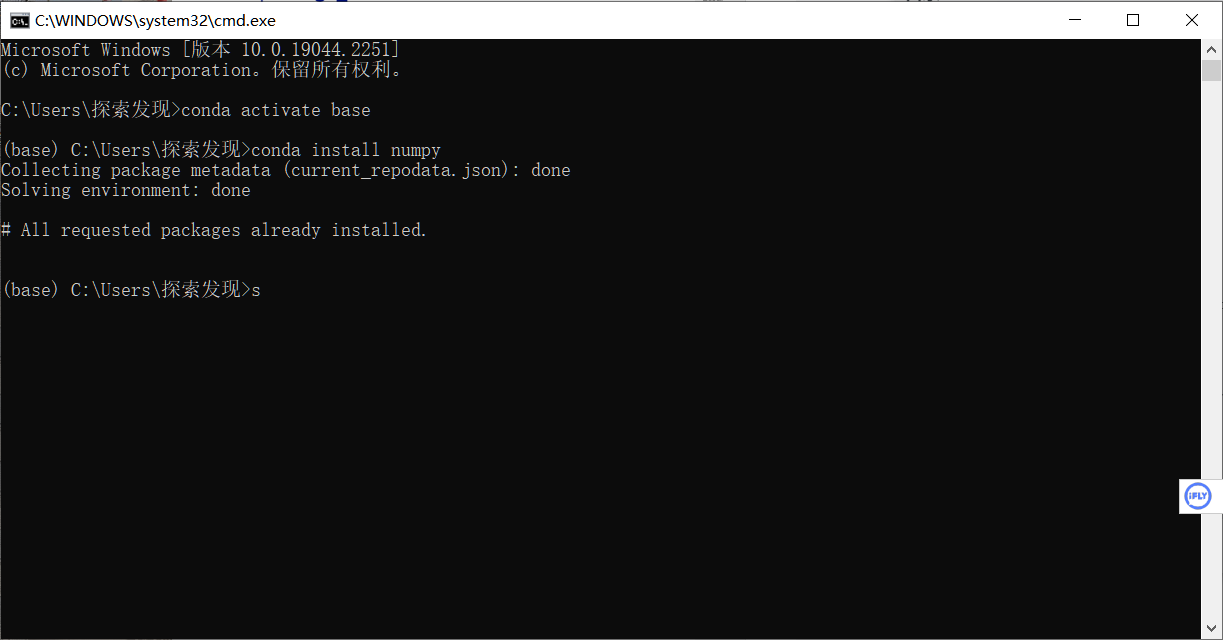
先要进入base环境 ,然后执行conda install 命令。
也可以自行创建新环境,然后在新环境中安装。
Anaconda Navigator 使用
四个主要的界面:
home页面

选择一个环境,然后打开应用开发.
有一些是自带安装了的,有一些是我们可以安装的
比如我们可以点击launch打开预先安装了的Jupyter Notebook
environment页面
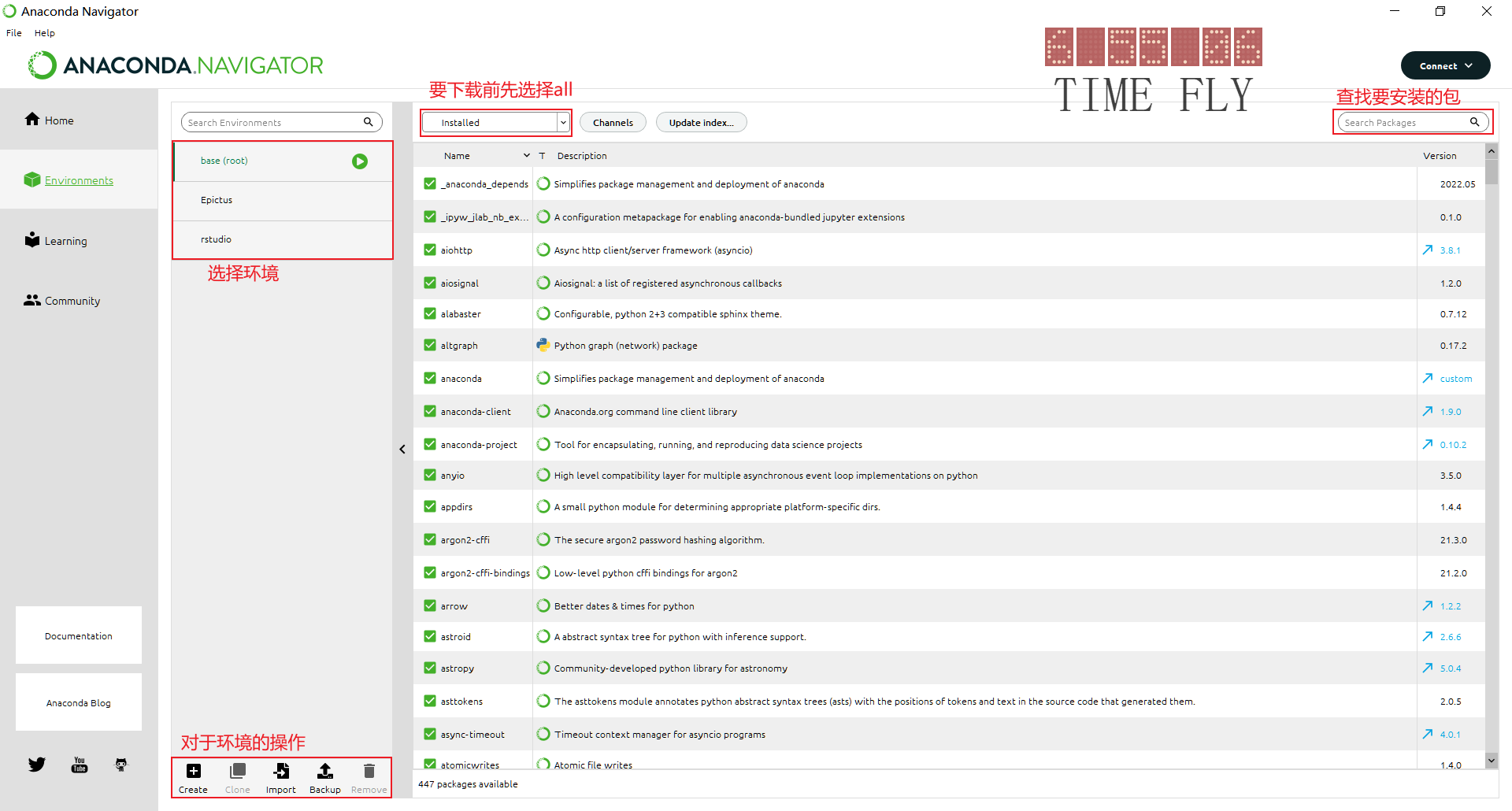
learning页面
提供了绝大多数python相关的官方文档.相比B站上的教程这里讲述的会更加具体详细系统可以按需查找
community页面
提供了常见的python论坛,像著名的stack overflow
Jupyter Notebook 使用
Jupyter Notebook小巧玲珑,实时交互,单独的cell之中可以单独执行,无需从头执行代码,自动保存,支持markdown,Latex公式学习思路,非常适合学习者使用.
+ Jupyter Notebook
+ 安装,打开,问题调试
+ Anaconda
+ 命令行
+ 调教
+ 修改打开的默认目录
+ 关闭,退出
+ 使用
+ 快捷键
+ Markdown
打开,安装,问题调试
可以在anaconda navigator中直接点lauch就行,不再赘述,如果打不开,修复bug,或者尝试通过命令行打开。
下面讲述
base环境
已经默认安装了Jupyter Notebook
我们win+r 再输入cmd 打开命令行
conda activate base激活base环境
Jupyter Notebook打开 Jupyter Notebook
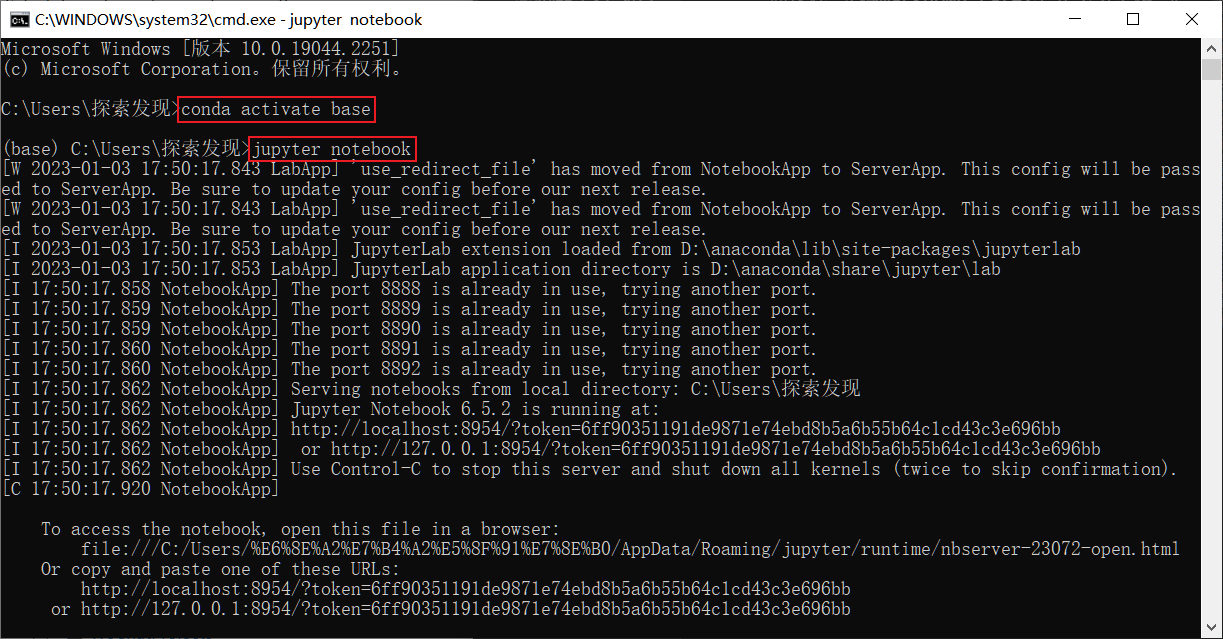
1.请不要关闭命令行窗口不然无法操作
2.如果没有跳转浏览器, 修复bug,或者打开浏览器打开最后的链接
新环境
创建一个名为Epictus的python环境
conda create -n Epictus python
不要忘记加上python了
也可以使用
conda create -n Epictus python=版本
安装指定版本的Python
新创建的环境中不包含 Jupyter Notebook使用
conda install Jupyter Notebook
再输入
Jupyter Notebook
调教
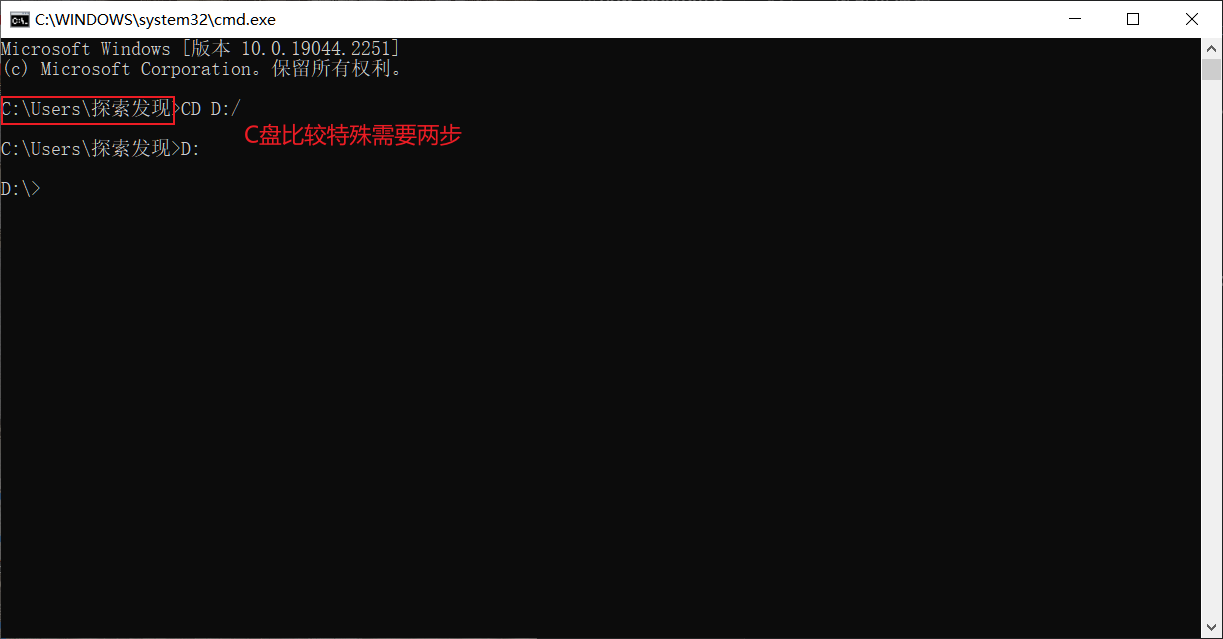
改变储存目录
我们只要在目标目录下打开 Jupyter Notebook即可
cd 目标路径
盘符:
关闭,退出
使用完毕可以在命令行窗口连按两次[Ctrl+c]关闭服务
使用
快捷键
Jupyter Notebook有两种不同的键盘输入模式。编辑模式允许您在单元格中键入代码或文本,并由绿色单元格边框指示。命令模式将键盘绑定到笔记本级别的命令,并由带有蓝色左边距的灰色单元格边框指示。
具体的快捷键按H键
编辑模式和命令模式按Esc键切换
markdown
在markdown中还可以输入latex公式
Matplotlib
最流行的Python绘图库,名字取自MATLAB,数据可视化工具
conda install Matplotlib进行安装
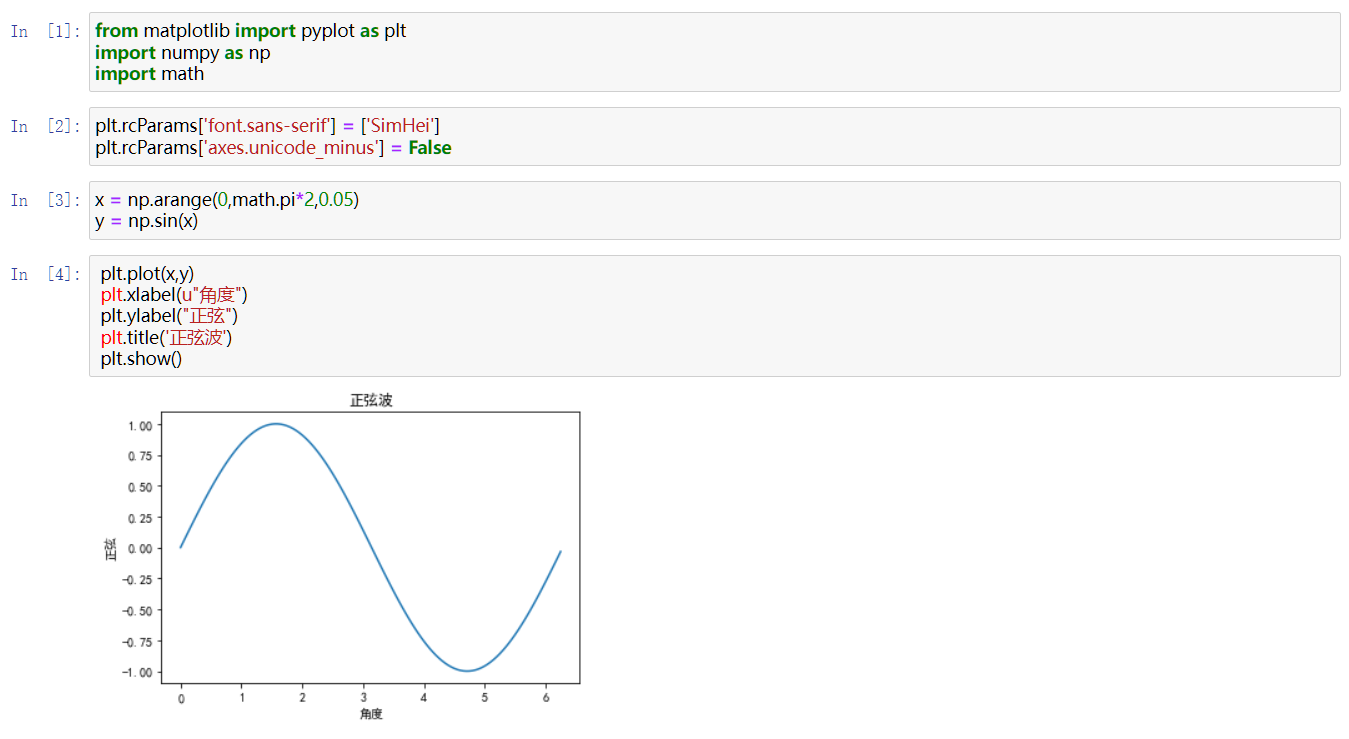
没有必要从头学,只要根据自己想要画的图找到代码再把自己的数据输入就OK了,经常出现的图代码也会熟悉的,属于熟能生巧的技能。
Numpy
大名鼎鼎的 Numpy究竟是什么
Numerical Python的缩写
- 一个开源的Python科学计算库
- 方便的矩阵,数组运算(与matlab相比各有千秋 numpy官方文档)
- 包括线性代数、傅里叶变换、随机数生成等大量函数
以上的特点使得Numpy比直接编写python代码:
- 更加简洁:数组和矩阵的引入
- 更加高效:数组储存效率比原生list高,numpy以c语言来实现
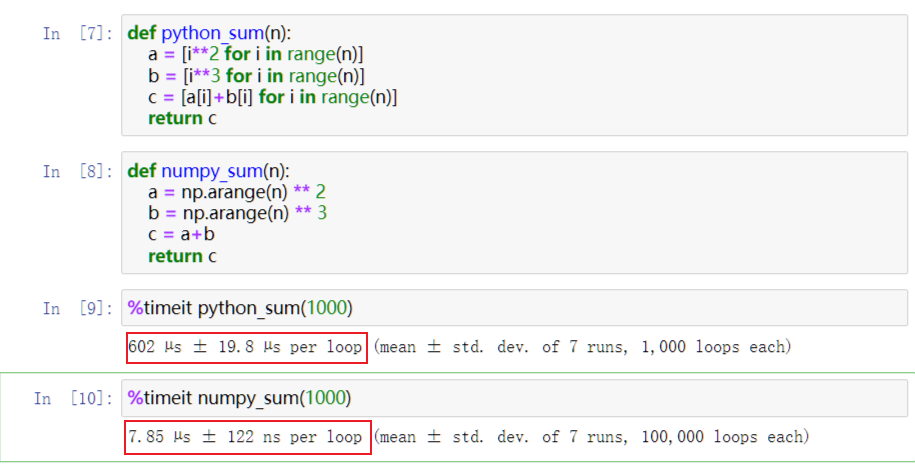
学习目标
主要利用的是其中narray这一对象,所以首先掌握对于narray的各项操作,然后对于其他的操作在后面实际操作中在学习.
narray
实际上就是一个数表,只起到储存数的作用.
厉害的不是narray,而是其背后的代数学的发展.当然我们不能否认采用c语言之后对于性能的优化.但是归根到底是因为数表这一个方式更加适合运算.
更加适合求解方程组(在代数学中矩阵的出现就是为了求解方程)
更加适合加减乘除
属性
| 属性名 | 含义 |
|---|---|
| shape | array的形状 |
| ndim | 表示array的维度 |
| size | 表示array元素的数目 |
| dtype | array中元素的数据类型 |
| itemsize | 数组中每个元素的字节大小 |
创建array的方法
- 转化python原生的list和嵌套列表
- 使用预定函数arrange,linspace等创建等差数组
- 使用ones,ones_like,zeros,zeros_like,empty,empty_like,full,full_like,eye等创建
- 生成随机书的random模块创建
array的两个要点就是元素和形状,确定两者array就确定了.
前菜--Numpy;详细介绍
数据处理
- 数据采集
- 数据清洗
- 数据标准化
- 数据增强
数据采集
实际上就是爬虫。现代的数据网络每秒产生的数据就成千上万个,想要得到我们想要的数据,我们就必须要学会使用爬虫自动访问网页回去信息。
数据清洗
爬虫返回的数据千奇百怪,不乏有错误的“脏”数据,主要包括一致性检查和无效值/缺失值处理
但是对于圣都学习来说,这些错误本来就是需要,甚至对于干净的数据我们还要人为添加噪声.
所以我们的数据清洗主要是针对人为造成的错误
数据标准化
归一化,归一化有很多的理解的方式.把数据进行归一化的最直观的好处就是单位消失了.那后续的好处会在算法和模型的使用中显现出来的.
最简单的归一化方法就是离差标准化,也叫做min-max标准化或者缩放归一化.
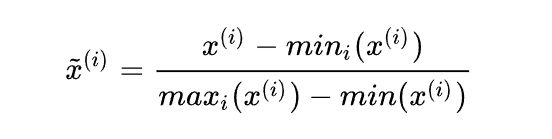
def Normalization(x):
return [(float(i)-min(x))/float(max(x)-min(x)) for i in x]
但是这种方法在每次最大值和最小值变化的时候都要重新计算
所以最为常见的方法是标准差归一化,也叫做z-score标准化。经过处理的数据符合高斯分布,均值为0,标准差为1
先求出整体样本的均值和标准差,让每个样本的取值减去均值在除以标准差
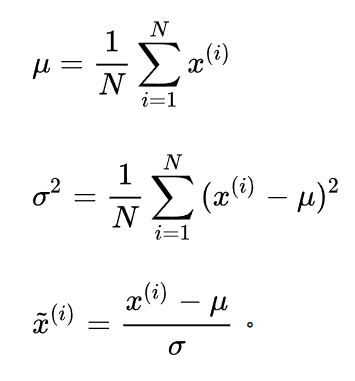
import numpy as np
def z_score(x):
x -= np.mean(x)
x /= np.std(x)
return x
还有Decimal scaling小数定标标准化,对数Logistic模式,atan模式,模糊量化模式。可以Google scholar一下
数据增强
深度学习模型是否强大和训练的数据集有很大的关系,至少要几千次的训练才能完成一个简单的人物。
当数据不够的时候怎么办呢?
我们可以对已有的数据进行整容,添加噪声等等的方法来自己造数据。
- PyTorch中就自带图像的旋转功能
- Mixup把几张图片混合起来
- 添加噪声
- GAN网络中有一个自动生成模型的功能
- 那对于自然语言处理,我们可以先机翻到英文在翻回来