前言:
使用Ascend C编程语言进行算子开发时,因为多核自动并行,以及单核内流水线并行的编程范式(即将单核算子处理逻辑划分为多个流水任务“搬入、计算、搬出”)等特性,可以快速搭建算子实现的代码框架,开发者仅需要把关注点放在数据切分和计算逻辑实现上。固定shape算子切分相对简单,动态shape的算子需要如何去实现呢?有哪些需要注意的地方呢?笔者也是刚学习Ascend C算子开发的新人,根据官方文档,尝试写了一个动态shape的例程。输入向量shape32字节对齐后,并以32字节作为最小分配和计算单元,输入向量的shape可划分为核间可均分和不可均分两种情况,在这两种情况下,核内又存在均分和不均分这两种情况,本篇笔记对此进行了描述,并编程实现和验证。
一、概念回顾
首先回顾一下Tiling的基本概念,由于大多数情况下,Ai core的Local Memory的存储容量,无法完整的容纳下算子的输入与输出,因此需要先搬运一部分输入进行计算然后搬出,再搬运下一部分输入进行计算,直到得到完整的最终结果,这个数据切分、分块计算的过程称之为Tiling。根据算子的shape等信息来确定数据切分算法相关参数(比如每次搬运的块大小,以及总共循环多少次)的计算程序,称之为Tiling实现。Tiling实现完成后,获取到的Tiling切分算法相关参数,会传递给kernel侧,用于指导并行数据的切分。
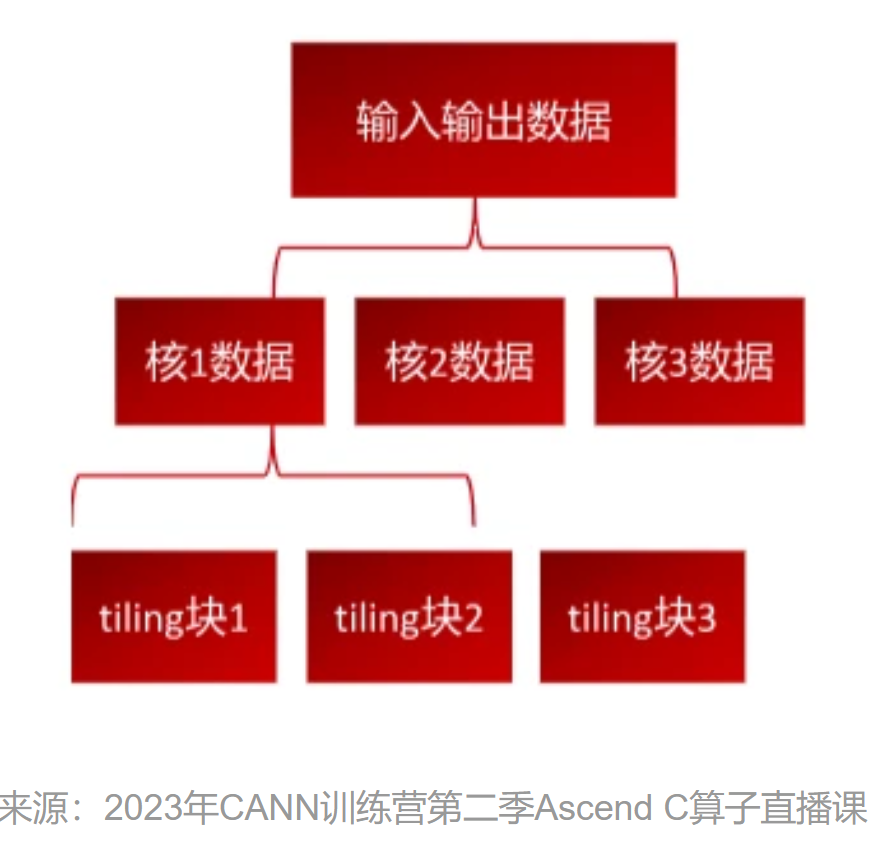
从上图可以看出,切分可分为核间切分和核内切分两块内容。核间切分是将数据分配给NPU的多个Aicore,也就是上图第二行中核1数据、核2数据等;分配到某个核计算的数据,也需要分批处理,这就是核内切分,如上图中的tiling块1、tiling块2等。
Tiling过程从编程实践上,在算子工程的op_host和op_kernel目录下的三个文件中:
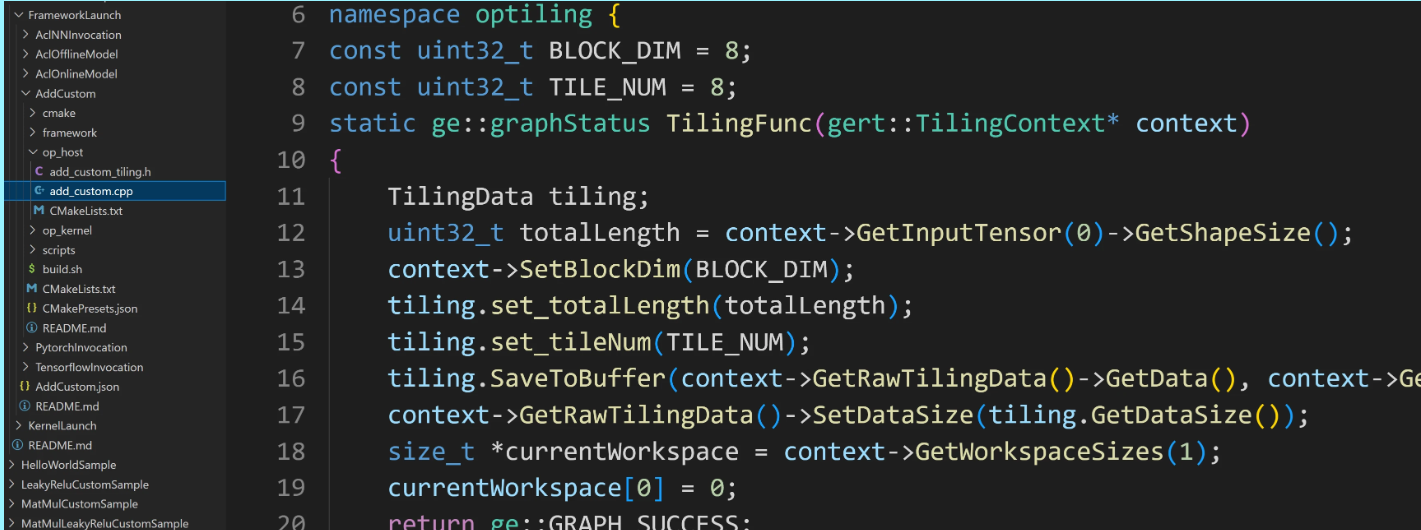
1、op_host文件夹下“算子Tiling结构定义头文件”、以及“算子host实现cpp文件”的Tiling实现函数里。主要逻辑如下图所示:

1)op_host目录下的“算子名称_tiling.h”,包括TilingData数据结构(切分算法相关参数)的定义和注册;以add_custom算子例程为例:

2)op_host目录下的算子host侧实现“算子名称.cpp”文件中的Tiling实现部分,根据算子的shape等信息来确定数据切分算法相关参数(比如每次搬运的块大小,以及总共循环多少次)的计算程序。由于Tiling实现中完成的均为标量计算,AI Core并不擅长,所以将其独立出来放在host CPU上执行;
2、 op_kernel目录下的算子device侧实现“算子名称.cpp”,根据TilingData传入的参数,结合API实现数据切分操作。
1)核间切分:体现在算子类的init函数中,通过SetGlobalBuffer,用来设置每个核需要处理的数据在Global Memmory上的起始地址。

2)核内切分,体现在算子类的三个函数中:
init函数的pipe.InitBuffer为TQue进行Local Memory内存分配

CopyIn函数中,DataCopy将输入向量从Global Memory拷贝到Local Memory,进行运算

CopyOut函数中,DataCopy将计算结果从Local Memory拷贝到 Global Memory

二、设计约束与策略
1、由于AICore里Unified buffer上的物理限制,要求数据存储必须保持32Byte对齐。
1)输入向量的shape不满足32字节对齐时,首先要进行32字节对齐。由于aclrtMalloc在Device(Global Memory)上申请线性内存时会,对用户申请的size向上对齐成32字节整数倍后再多加32字节。所以不需要担心对齐后会造成内存溢出。
2)进行tiling有关计算时,以32字节为最小单位进行计算。
2、AI Core与外部数据交互需要经过CPU数据总线,频繁调度可能会导致性能瓶颈。为了减少AICore与外部数据的搬运频度。代码设计时应尽可能减少AI Core与外部数据搬运次数。对于NCHW数据较小时,可考虑一次搬入Unified Buffer空间,数据较大时,应该尽可能最大利用Unified Buffer空间。
3、充分利用多核/流水线技术
1)昇腾AI处理器存在多个AI Core, 应该充分均衡利用多核计算能力,将计算部分均衡分配到多个AI Core上。
2)充分利用从AI Core外部空间到Unified Buffer、Unified Buffer到外部空间可独立搬运的硬件特性。在输入向量shape比较大时,采取dobule buffer机制,减少Vector指令的等待时间,为了开启使用Double Buffer,外部数据需要可以分成偶数块。
4、减少kernel的标量运算量。合理设计Tilingdata(切分参数),尽量不让kernel侧进行除法、求余运算,少用乘法运算。
三、实现逻辑
首先,我们需要调用Ascend C “Host侧实现API”中的“PlatformAscendC类”的有关函数,获取与“Host侧的Tiling函数”有关的硬件平台的信息。常用的有获取当前硬件平台的类型,可用的Vector和Cube核心数,以及ub的存储容量等。具体函数的用法请阅读官方文档:“Ascend C编程指南/API参考/Host侧实现API/平台信息获取/PlatformAscendC类” :https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/700alpha003/operatordevelopment/ascendcopdevg/atlasophostapi_07_0279.html

接着,调用API获取输入向量的shape和数据类型,并计算32字节对齐的数据量。比如输入的数据类型是float16,占用2个字节,这样16个float16作为最小的分配和计算单位,在代码中以ALIGN_NUM表示。

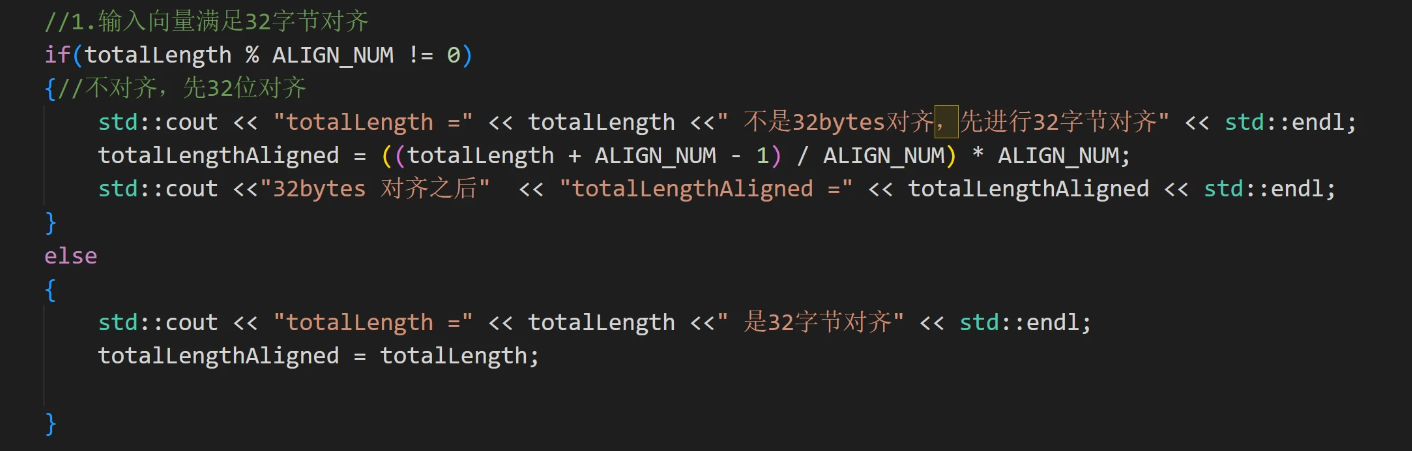
如果输入的shape不满足32字节对齐,还需要先进行32字节对齐,对齐后再进行Tiling计算。
接下来,我们就可以对shape进行分析,选取合适的切分变量,考虑host侧和device侧的具体实现。下述四种情形可以囊括所有的shape。
1、输入核间均分,核内均分,且均分后32字节对齐。
需要三个切分变量:blockLength:每个核上总计算数据大小;tileNum:每个核上总计算数据分块个数;tileLength:每个分块大小。
2、输入核间均分,核内不均分,且均分后32字节对齐,根据尽可能最大利用ub的原则,只有最后一分块数据不满。此时在上述3个切分变量基础上,增加lasttileLength,表示最后一个分块的大小。
采用四个切分变量:blockLength:每个核上总计算数据大小;tileNum:每个核上总计算数据分块个数;tileLength:每个分块大小;lasttileLength:最后一个分块大小。
当lasttileLength=tileLength时,就是第1种核间均分,核内均分的情况。
所以把上述两种情形,定义为TilingKey= 1。在host侧通过“context->SetTilingKey(1)”进行设置。在kernel侧的核函数中通过“TILING_KEY_IS(1)”进行解析,并通过临时变量“tilingKey”=1,传递给算子内的函数使用。
3、核间不均分,每个核内都均分的情形,需要区分分配到较多数据量的核和分配到较少数据量的核。
1)分配到较多数据量的核
formerNum:分配到较多数据量的核心数;formerLength:分配到数据数;formertileNum:多数据量核的核内切分数;formertileLength:核内每块数据量。
2)分配到较少数据量的核
tailNum:分配到较少数据量的核心数;tailLength:每核分到的数据量;tailtileNum:少数据量核的核内切分数;tailtileLength:核内每块数据量。
4、核间不均分,核内也有不均分的情况。参考2,给每个核增加一个变量表示最后一块数据量。formerlasttileLength:数据量多的核最后一个分块大小;taillasttileLength:数据量少的核最后一个分块大小。
3和4两种情况,在kernel侧的代码可以统一处理,定义为TilingKey= 2。此时
1)核间分配,原则是把所有的数据尽可能均匀地分配到每个核上,如果不能均分的话,那么会有部分核多算一个最小单位ALIGN_NUM,通过模的计算,可以得到多算一个最小单位的核的数量,也可以得到少算一个最小单位的核的数量。
2)核内分配的计算过程与上述的1和2两种情况类似。
Double buffer的处理,是将输入数据分成大小相等的两块,充分利用Aicore,数据搬入、计算、数据搬出并行特性实现。因此要求外部数据需要可以分成偶数块。为了简化处理,我们约束Unified Buffer可容纳的输入向量长度满足是最小分块的偶数,如果不是,则减1,这样就可以保证一套代码兼容开启或不开启double buffer功能了。Double buffer开启与否的差异还在于Kernel侧数据和数据搬出,不开启double buffer时,只需要对最后一个分块的起始地址做处理;开启double buffer后,因为数据块编程原来的一半,所以需要对最后两个分块的起始地址做处理。
四、host侧和kernel侧有关切分代码实现
在上一节中,讨论动态shape的四种方式,经过分析后,可以归结到两套切分参数,并使用TilingKey=1和2来区分,本节将讨论具体的代码实现。
1、核间均分情形(TilingKey= 1)时的tiling代码实现
1)host侧代码:进行计算和判断时,都带上了ALIGN_NUM,保证后续的计算都是以32字节为基本单位中。将核内均分当成核内不均分的一种特定情况,当最后一块数据与前面块数据相等时,就是均分;当数据少于ub决定的块数据长度时,只有一个分块,也按均分处理,但tileLength的长度设置为分块的实际长度。
if((totalLengthAligned / ALIGN_NUM) % block_dim == 0 )
{//核间可均分
std::cout << "block_dim =" << block_dim <<" 每个核或对齐后,满足32字节对齐,核间均分" << std::endl;
std::cout << "每个核分 :" << (totalLengthAligned / block_dim) << std::endl;
blockLength = totalLengthAligned / block_dim;
tile_num = blockLength / ALIGN_NUM / ub_block_num;
if((totalLengthAligned / block_dim / ALIGN_NUM) % ub_block_num == 0 || tile_num==0)
{ //满足32字节对齐,可以核内均分
if(tile_num==0)
{
tile_num=1;
std::cout << "每块分配:" << (totalLengthAligned / block_dim) << std::endl;
}
else
{
std::cout << "每块分配:" << (totalLengthAligned / block_dim /tile_num) << std::endl;
}
std::cout << "tile_num =" << tile_num <<" 每个核满足32字节对齐,核内均分" << std::endl;
if(blockLength < ub_block_num)
{
tileLength = ((blockLength / ALIGN_NUM) + 1)/2 * 2*ALIGN_NUM;
lasttileLength = tileLength;
}
else
{
tileLength = ub_block_num * ALIGN_NUM;
lasttileLength = tileLength;
}
}
else
{ //满足32字节对齐,核内不能均分
tile_num = tile_num + 1;
std::cout << "tile_num =" << tile_num <<" 每个核满足32字节对齐,核内不均分" << std::endl;
tileLength = ub_block_num * ALIGN_NUM;
lasttileLength = blockLength - (tile_num - 1)* tileLength;
std::cout << "前" << (tile_num-1) << "分配: tileLength = " << tileLength << std::endl;
std::cout << "最后一包分配: lasttileLength =" << lasttileLength << std::endl;
}
context->SetTilingKey(1);
std::cout << "context->SetTilingKey(1)" << std::endl;
tiling.set_blockLength(blockLength);
tiling.set_tileNum(tile_num);
tiling.set_tileLength(tileLength);
tiling.set_lasttileLength(lasttileLength);
tiling.SaveToBuffer(context->GetRawTilingData()->GetData(), context->GetRawTilingData()->GetCapacity());
context->GetRawTilingData()->SetDataSize(tiling.GetDataSize());
size_t *currentWorkspace = context->GetWorkspaceSizes(1);
currentWorkspace[0] = 0;
return ge::GRAPH_SUCCESS;
}
else
{
std::cout << "block_dim =" << block_dim <<" 每个核满足32字节对齐,核间不能均分" << std::endl;
}
2)kernel侧代码:
(1)init函数:——核间切分,并为TQue进行Local Memory内存分配
if (tilingKey == 1) {
this->blockLength = blockLength;
this->tileNum = tileNum
ASSERT(tileNum != 0 && "tile num can not be zero!");
this->tileLength = tileLength;
this->lasttileLength = lasttileLength;
xGm.SetGlobalBuffer((__gm__ half*)x + this->blockLength * GetBlockIdx(), this->blockLength);
yGm.SetGlobalBuffer((__gm__ half*)y + this->blockLength * GetBlockIdx(), this->blockLength);
}
pipe.InitBuffer(inQueueX, BUFFER_NUM, (this->tileLength / BUFFER_NUM) * sizeof(half));
pipe.InitBuffer(outQueueY, BUFFER_NUM, (this->tileLength / BUFFER_NUM) * sizeof(half));
CopyIN和CopyOUT中的处理需要注意Double buffer的处理,当开启Double buffer时,此时,处理次数是不开启double buffer的两倍;每次处理数据块为this->tileLength/2。为了方便处理,使用BUFFR_NUM代表是否开始double buffer功能。BUFFER_NUM=2时开启;=1不开启。
constexpr int32_t BUFFER_NUM = 2;//=2开启double buffer;=1不开启循环次数乘以BUFFER_NUM
__aicore__ inline void Process()
{
int32_t loopCount = this->tileNum * BUFFER_NUM;
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
}(2)CopyIN函数:
此处需要注意的就是处理最后一个分块数据的起始地址。
Double buffer不开启时,只需要将最后一个分块的起始地址向前移动(tileLength-lasttileLength)即可;Double buffer开启后,则需要处理最后2个分块的起始地址,此时每次搬运的数量为不开启时的一半(this->tileLength/2),倒数第2分块的起始地址向前移动(tileLength-lasttileLength),最后一个分块依次处理。
if(BUFFER_NUM == 1)
{
if (progress==this->tileNum -1) {
if(progress == 0){
//如果只有一包,则搬运的起始地址为0,tileLength为实际分块的数据量
DataCopy(xLocal, xGm[0], this->tileLength);
} else {
//将最后一个分块的起始地址向前移动tileLength-lasttileLength
DataCopy(xLocal, xGm[(progress-1) * this->tileLength + this->lasttileLength], this->tileLength);
}
}
else{
DataCopy(xLocal, xGm[progress * this->tileLength], this->tileLength);
}
}
if(BUFFER_NUM == 2)
{
//开启double buffer时,由于将输入数据分成了相等的2部分,分块大小为不开启double buffer的一半,
//所以需要对最后两个分块数据的起始地址做处理
if((progress == (this->tileNum * BUFFER_NUM -2)) || (progress == (this->tileNum * BUFFER_NUM -1))) {
//分块大小变为tileLength的一半
//倒数第2个分块数据的起始地址向前移动(tileLength-lasttileLength),最后一个分块的起始地址以此为基础进行移动
DataCopy(xLocal, xGm[(progress-2) * (this->tileLength/2) + this->lasttileLength], (this->tileLength/2));
}
else{
DataCopy(xLocal, xGm[progress * (this->tileLength/2) ], (this->tileLength/2) );
}
}(3)CopyOUT函数:
与CopyIN函数中的处理方法类似,差异在于CopyIN是将输入向量搬入,而CopyOUT是将输出结果搬出。不再赘述,代码如下:
if(BUFFER_NUM == 1)
{
if(progress==this->tileNum -1) {
if(progress == 0){
//如果只有一包,则搬运的起始地址为0,tileLength为实际分块的数据量
DataCopy(yGm[0], yLocal, this->tileLength);
}else {
//将最后一个分块的起始地址向前移动tileLength-lasttileLength
DataCopy(yGm[(progress-1) * this->tileLength + this->lasttileLength], yLocal, this->tileLength);
}
}
else{
DataCopy(yGm[progress * this->tileLength], yLocal, this->tileLength);
}
}
if(BUFFER_NUM == 2)
{
//开启double buffer时,由于将输入数据分成了相等的2部分,分块大小为不开启double buffer的一半,
//所以需要对最后两个分块数据的起始地址做处理
if((progress == (this->tileNum * BUFFER_NUM -2)) || (progress == (this->tileNum * BUFFER_NUM -1)) ) {
//分块大小变为tileLength的一半
//倒数第2个分块数据的起始地址向前移动(tileLength-lasttileLength),最后一个分块的起始地址以此为基础进行移动
DataCopy(yGm[(progress-2) * (this->tileLength/2) + this->lasttileLength], yLocal, (this->tileLength/2));
}
else{
DataCopy(yGm[progress * (this->tileLength/2)], yLocal, (this->tileLength/2));
}
}2、核间不均分情形(TilingKey= 2)时的代码实现
与核间均分(TilingKey= 1)的差异在于,有的核分配的数据多,有的核分配的数据少,采用下述代码,多数据比少数据多一个32字节的数据块。并分别用formerNum、formerLength表示分到多数据的核数,和分配到的长度;用tailNum、tailLength表示分到少数据的核数,和分配到的长度。切formerLength-tailLength=ALIGN_NUM(32字节最小块代表的输入向量个数)
uint32_t formerNum = (totalLengthAligned / ALIGN_NUM) % block_dim;
uint32_t tailNum = block_dim - formerNum;
// 计算大块和小块的数据量
uint32_t formerLength = (((totalLengthAligned + block_dim -1)/ block_dim + ALIGN_NUM - 1) / ALIGN_NUM) * ALIGN_NUM;
uint32_t tailLength = (totalLengthAligned / block_dim / ALIGN_NUM) * ALIGN_NUM;
std::cout << "分到大块的核数:" << formerNum <<"每核:" << formerLength << std::endl;
std::cout << "分到小块的核数:" << tailNum <<"每核:" << tailLength << std::endl;核内切分代码,以及kernel侧的处理与(TilingKey= 1)类似,只是需要分别考虑多数据核和少数据核两种情况,仿照核间均分处理的方式,为多数据核引入“formertileNum、formertileLength、formerlasttileLength”;为少数据核引入“tailtileNum、tailtileLength、taillasttileLength”,逻辑处理与核间均分处理类似。kernel侧的CopyIN和CopyOUT中也与核间均分的处理一致,此处均不再赘述。
只是需要注意在kernel侧进行核间数据处理时,需要根据GetBlockIdx()来区分是多数据核和少数据核。在Init函数中:
if(tilingKey == 2)
{
if (GetBlockIdx() < this->formerNum) {//分到大块核的处理
this->tileLength = this->formertileLength;
this->lasttileLength = this->formerlasttileLength;
xGm.SetGlobalBuffer((__gm__ half *)x + this->formerLength * GetBlockIdx(), this->formerLength);
yGm.SetGlobalBuffer((__gm__ half *)y + this->formerLength * GetBlockIdx(), this->formerLength);
} else {//分到小块核的处理,需要处理的数据量比大核少alignNum个
this->tileLength = this->tailtileLength;
this->lasttileLength = this->taillasttileLength;
xGm.SetGlobalBuffer((__gm__ half *)x + this->formerLength * this->formerNum + this->tailLength * (GetBlockIdx() - this->formerNum),this->tailLength);
yGm.SetGlobalBuffer((__gm__ half *)y + this->formerLength * this->formerNum + this->tailLength * (GetBlockIdx() - this->formerNum),this->tailLength);
}
}
五、结果验证
验证硬件平台选择“Atlas 训练系列产品”,AiCore中的向量计算单元为32个;自定义算子为sinh;数据类型为float16;为了方便计算,ub能容纳的输入向量数定义为:128字节,即4个最小分配单元,每个最小分配单元16个float16,每次可容纳64个float16。由于double buffer开启是在kernel侧,无法从打屏,下述情况均在double buffer开启和不开启两种情况下测试。开启和不开启double buffer,需要修改kernel侧代码,并重新编译算子工程,并部署。
1、输入向量32字节对齐的情况
1)核间均分、核内均分——输入向量shape为96*2048

2)核间均分,核内不均分——输入向量shape为32*80
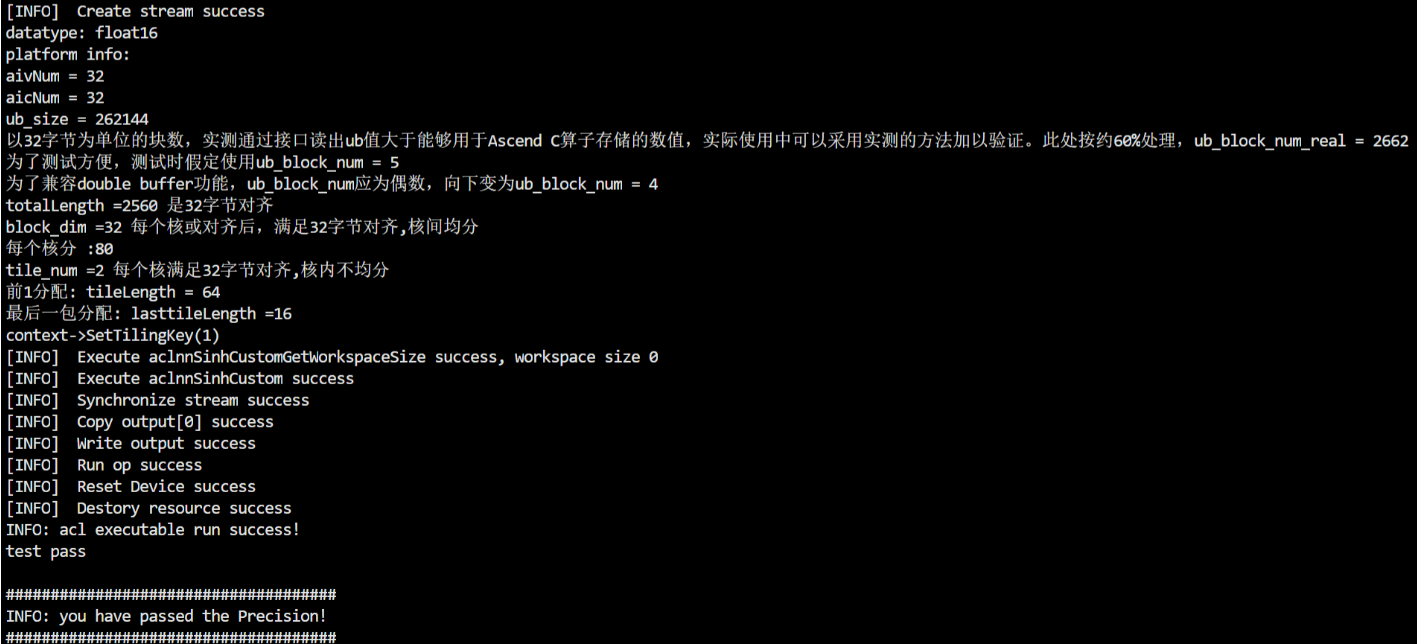
3)核间不均分,核内都均分——输入向量shape为31*64+48
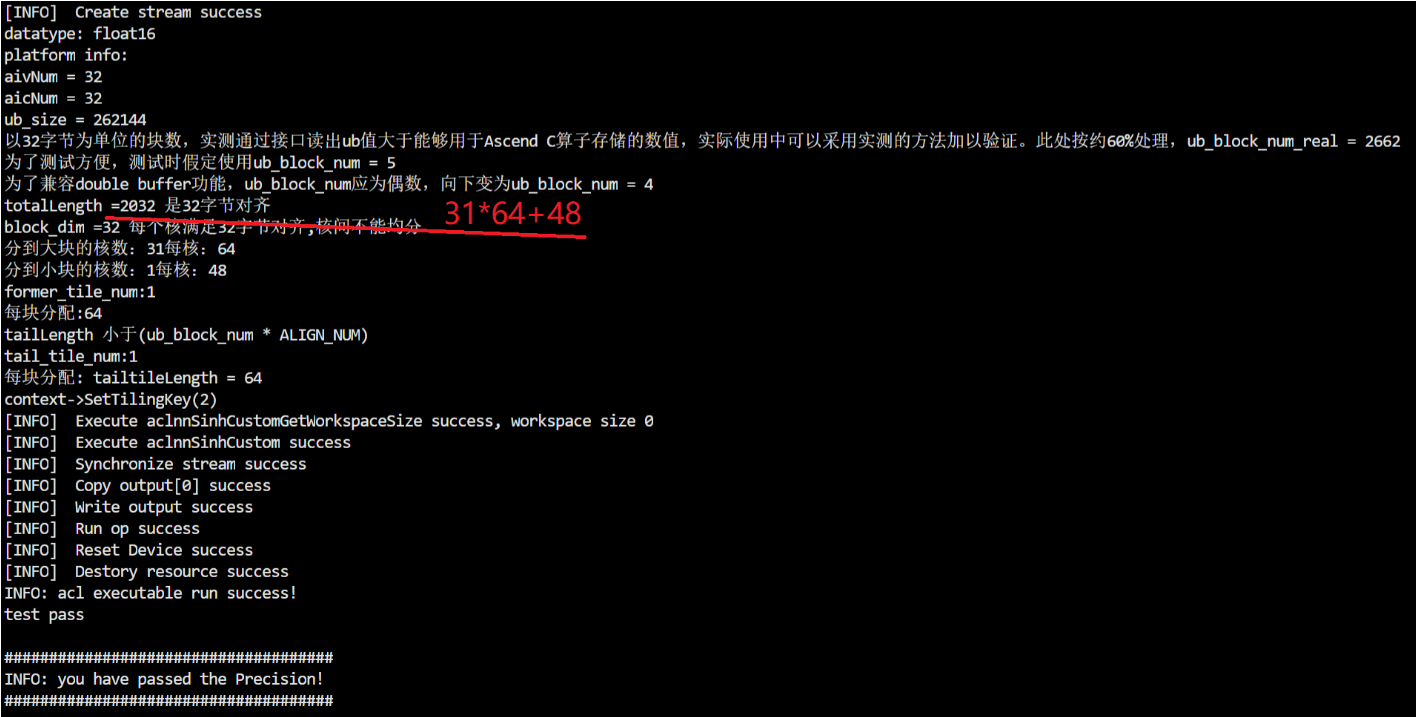
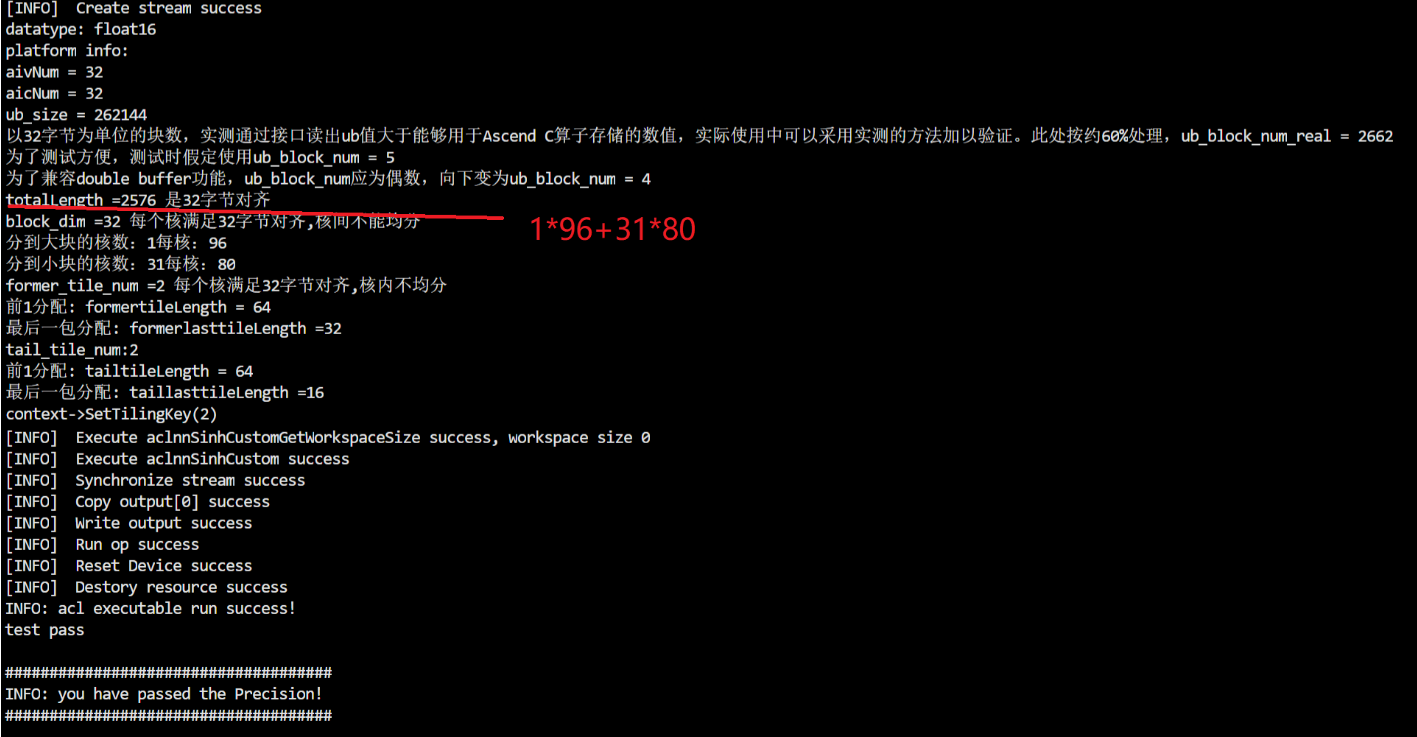
4)核间不均分,核内有不均分的情形——输入向量shape为1*96+31*80
2、输入向量不满足32字节对齐的情况——输入向量shape为32*64-3

3、输入数据量较少时——分配到若干核,输入向量shape为1*48,8*64
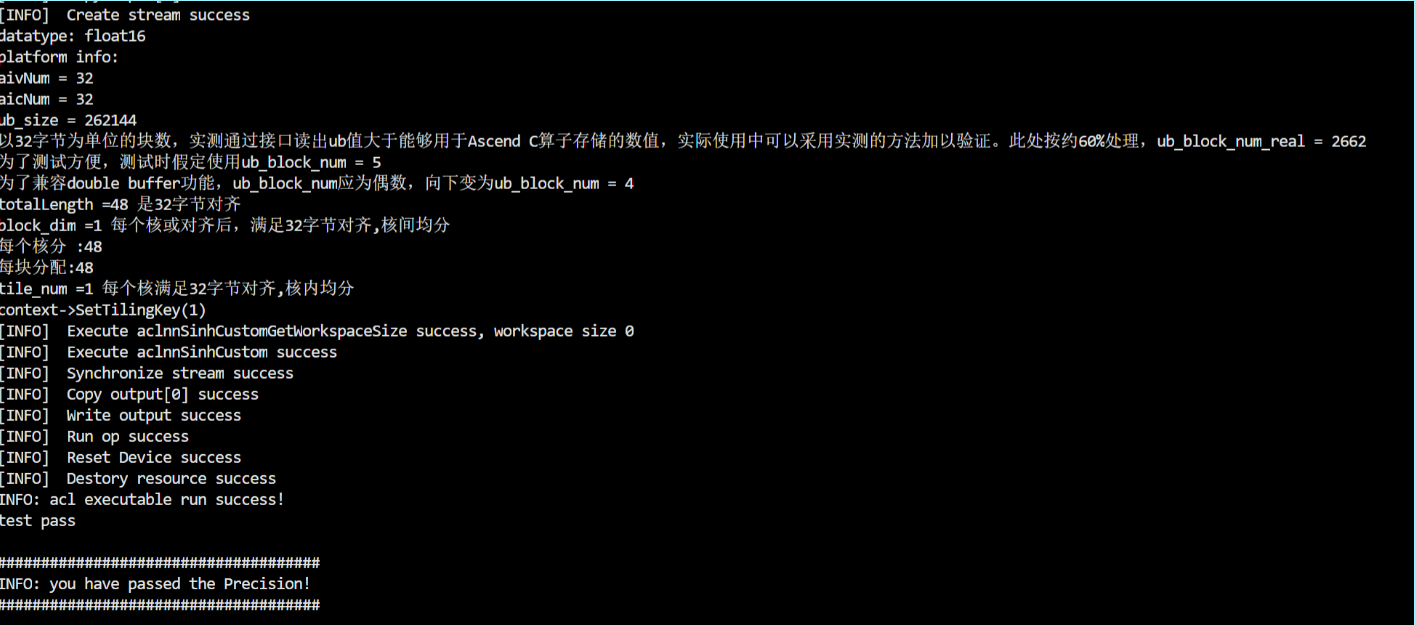
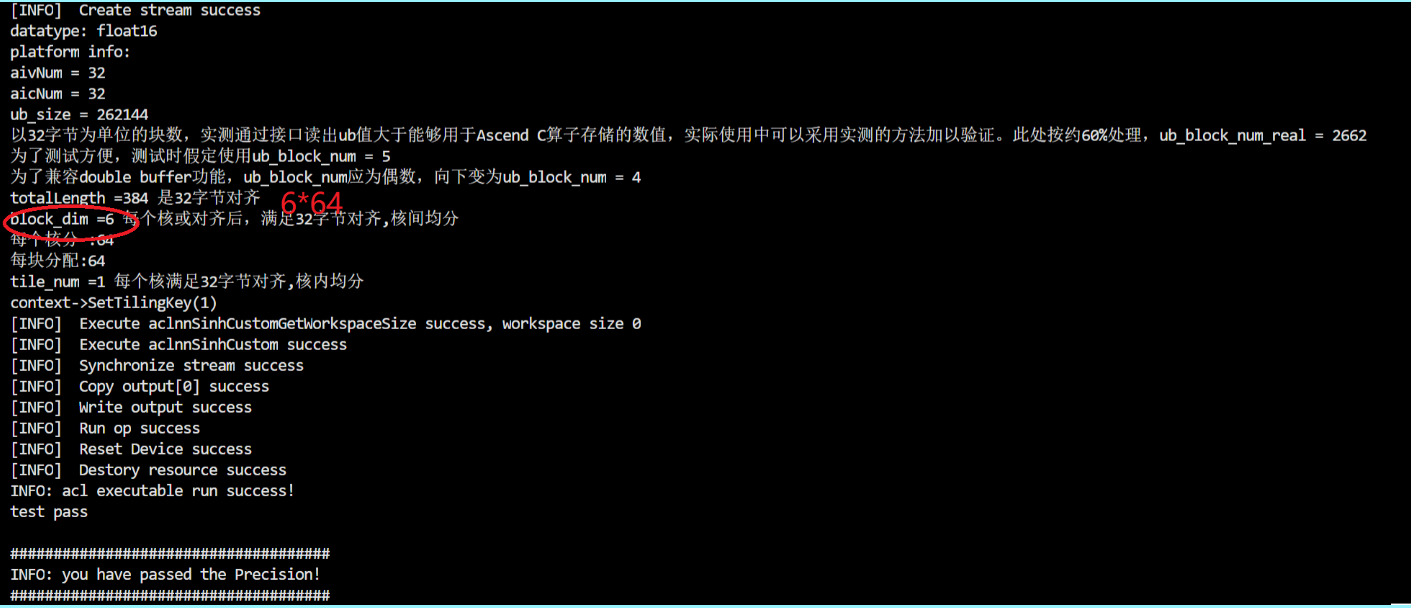
五、问题及解决方法
1、在算子类使用TILING_KEY_IS()导致的报错
当一个算子在不同的shape下,有不同的Tiling算法逻辑,不同的逻辑下,host侧Tiling算法有差异,对应的kernel侧实现也有差异。此时,需要通过TilingKey来关联host/kernel侧。host侧通过SetTilingKey()设置,kernel侧通过TILING_KEY_IS()获取TilingKey值,从而实现不同的逻辑分支。
P:在一个TilingKey来标识多分支的实现应用中,进行某一个分支的验证时,报错如下,而其余的分支有可以运行成功的,而且出错的分支,改写成固定shape进行单独验证时,也是可以通过。

S:导致上述报错的原因,是由于在算子类中使用了TILING_KEY_IS(),而TILING_KEY_IS()只能在核函数中使用。

咨询授课老师后,老师给出的解决方法是,将算子实现类中TILING_KEY_IS相关判断写到核函数中,并通过变量将对应的值传递到算子类中。

2、开启double buffer,致使VECIN上的QUE数量超过限制
P:有3个输入向量时,开启double buffer时,代码是可以在Atlas A2训练系列产品/Atlas 300I A2推理产品上能运行正确,但相同的代码在Atlas 训练系列产品/Atlas推理系列产品(Ascend 310P处理器)运行出错。不开启double buffer时,在两个产品上运行均是正确的。
A:这是因为同一个TPosition上QUE Buffer数量有数量约束,且不同处理器,约束数量不同。

当输入向量数量为3个,如果开启double buffer,会导致VECIN上QUE的数量是3*2=6个,超过了某些处理器的限制。改进方法,可以参考参考文档的描述。https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/700alpha003/operatordevelopment/ascendcopdevg/atlasascendc_api_07_0026.html
