问题:
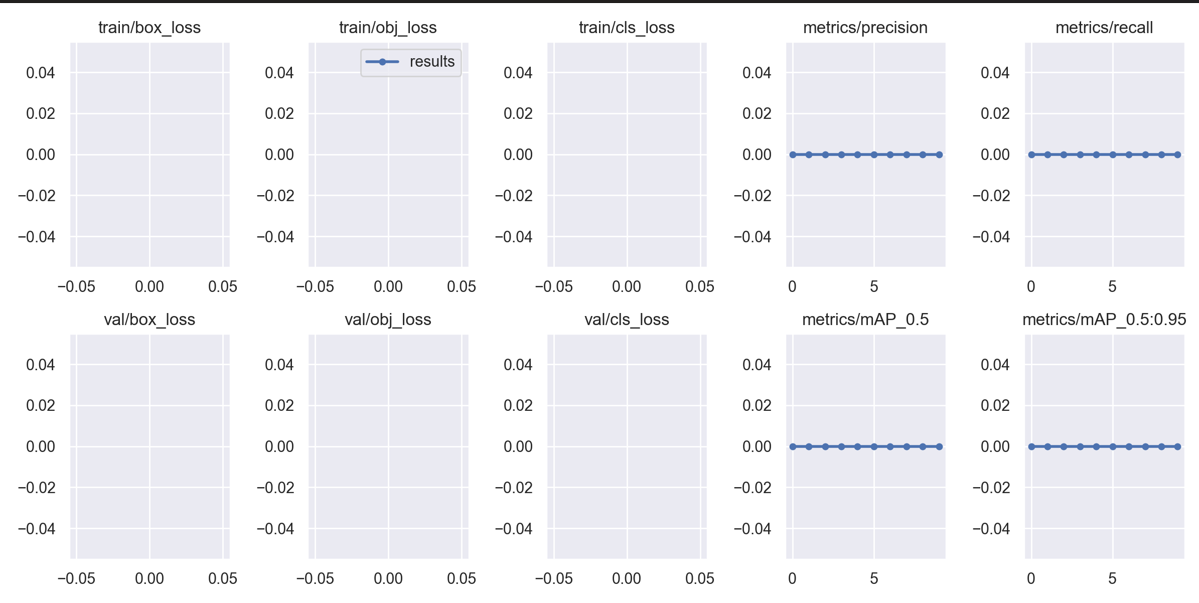
train训练得出的P\R\map全部为0
上网寻找寻找答案,大部分给出的原因解释如下:
①文件夹格式(名称和架构)有问题,这属于基本内容,不应该出错的。

2、这样做之后在运行train.py发现训练时就不会有nan值了。如果还有,那就应该就关闭这篇博客了,考虑下其他方法了。
然后,你就会发现validation时会出现P/R/map全部为0。然后你就继续在train.py里面搜索half关键字,把所有有.half()变为.float(),如下图:

到这一步为止,我train时出现为nan和0的问题已经解决了。
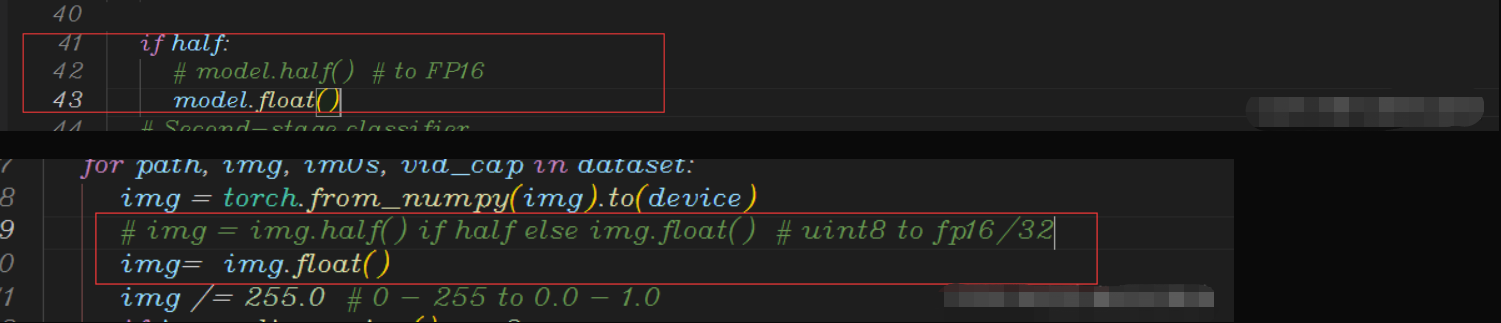
3、如果发现问题依旧没有解决,还需要在val.py里面将所有的half改为False,同时im.half() if half else im.float() 改为 im.float()。如下图:

以上3步完成之后,再次运行train.py发现没有问题了。
正确的Train结果截图:


以上是yolov5的训练出现问题的解决方案。
以下是链接里作者在yolov7训练时遇到的同样问题,放在这里供给参考。
经测试,train.py没有问题,主要还是在detect.py里面有问题。主要还是把每个地方.half()改为.float()或者把half赋值为False,如下图:
小结:
利用其他人的话来总结一下,其实,归根究底就是NVIDIA对GTX16xx相关CUDA包有问题,有其他人说吧PyTorch版本降为1.10.1和CUDA 10.2,我也试过,确实能解决问题,但是训练时长长了很多,而且现在PyTorch官方已经不怎么支持使用CUDA 10.2版本了。这个解决办法的原理,就是把显卡半精度浮点型数据改为单精度的浮点型去运算。这样虽然精度高了,但是训练时长也相应会增加一些、显存占用也会增加一些,但是,这样总比不能训练和不能检测要好些吧。