一、Dataframe基本概念
# 二维数组"Dataframe:是一个表格型的数据结构,包含一组有序的列,其列的值类型可以是数值、字符串、布尔值等。
data = {'name': ['Jack', 'Tom', 'Mary'],
'age': [18, 19, 20],
'gender': ['m', 'm', 'w']}
# Dataframe中的数据以一个或多个二维块存放,不是列表、字典或一维数组结构。
# Dataframe是一个表格型的数据结构,“带有标签的二维数组”。
# Dataframe带有index(行标签)和columns(列标签)
frame = pd.DataFrame(data)
# 查看数据,数据类型为dataframe
print(frame)
print(type(frame))
# .index查看行标签
print(frame.index, '\n该数据类型为:', type(frame.index))
# .columns查看列标签
print(frame.columns, '\n该数据类型为:', type(frame.columns))
# .values查看值,数据类型为ndarray
print(frame.values, '\n该数据类型为:', type(frame.values))
二、创建方法
1. 数组/list组成的字典
# Dataframe 创建方法一:由数组/list组成的字典
# 创建方法:pandas.Dataframe()
data1 = {'a':[1,2,3],
'b':[3,4,5],
'c':[5,6,7]}
data2 = {'one':np.random.rand(3),
'two':np.random.rand(3)} # 这里如果尝试 'two':np.random.rand(4) 会怎么样?
# 由数组/list组成的字典 创建Dataframe,columns为字典key,index为默认数字标签
# 字典的值的长度必须保持一致!
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
print(df1)
print(df2)
print('='*50)
# columns参数:可以重新指定列的顺序,格式为list,如果现有数据中没有该列(比如'd'),则产生NaN值
# 如果columns重新指定时候,列的数量可以少于原数据
df1 = pd.DataFrame(data1, columns = ['b','c','a','d'])
#df1 = pd.DataFrame(data1, columns = ['b','c'])
# index参数:重新定义index,格式为list,长度必须保持一致
df2 = pd.DataFrame(data2, index = ['f1','f2','f3']) # 这里如果尝试 index = ['f1','f2','f3','f4'] 会怎么样?
print(df2)
2.Series组成的字典
# 由Seris组成的字典 创建Dataframe,columns为字典key,index为Series的标签(如果Series没有指定标签,则是默认数字标签)
# Series可以长度不一样,生成的Dataframe会出现NaN值
data1 = {'one':pd.Series(np.random.rand(2)),
'two':pd.Series(np.random.rand(3))} # 没有设置index的Series
data2 = {'one':pd.Series(np.random.rand(2), index = ['a','b']),
'two':pd.Series(np.random.rand(3),index = ['a','b','c'])} # 设置了index的Series
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
print(df1,'\n')
print(df2)
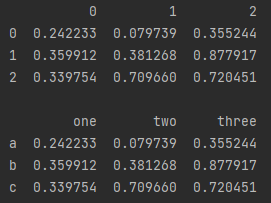
3.通过二维数组直接创建
# Dataframe 创建方法三:通过二维数组直接创建
# 通过二维数组直接创建Dataframe,得到一样形状的结果数据,如果不指定index和columns,两者均返回默认数字格式
ar = np.random.rand(9).reshape(3,3)
df1 = pd.DataFrame(ar)
# index和colunms指定长度与原数组保持一致
df2 = pd.DataFrame(ar, index = ['a', 'b', 'c'], columns = ['one','two','three']) # 可以尝试一下index或columns长度不等于已有数组的情况
print(df1,'\n')
print(df2)
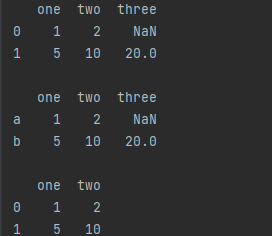
4.字典组成的列表
data = [{'one': 1, 'two': 2}, {'one': 5, 'two': 10, 'three': 20}]
df1 = pd.DataFrame(data)
# 由字典组成的列表创建Dataframe,columns为字典的key,index不做指定则为默认数组标签
# colunms和index参数分别重新指定相应列及行标签
df2 = pd.DataFrame(data, index = ['a','b'])
df3 = pd.DataFrame(data, columns = ['one','two'])
print(df1,'\n')
print(df2,'\n')
print(df3)
5.由字典组成的字典
data = {'Jack':{'math':90,'english':89,'art':78},
'Marry':{'math':82,'english':95,'art':92},
'Tom':{'math':78,'english':67}}
df1 = pd.DataFrame(data)
# 由字典组成的字典创建Dataframe,columns为字典的key,index为子字典的key
print(df1,'\n')
# columns参数可以增加和减少现有列,如出现新的列,值为NaN
# index在这里和之前不同,并不能改变原有index,如果指向新的标签,值为NaN (非常重要!)
df2 = pd.DataFrame(data, columns = ['Jack','Tom','Bob'])
df3 = pd.DataFrame(data, index = ['a','b','c'])
print(df2,'\n')
print(df3)
三、Dataframe索引
Dataframe既有行索引也有列索引,可以被看做由Series组成的字典(共用一个索引)
1.选择行与列
df = pd.DataFrame(np.random.rand(12).reshape(3,4)*100,
index = ['one','two','three'],
columns = ['a','b','c','d'])
print(df,'\n')
# 按照列名选择列,只选择一列输出Series,选择多列输出Dataframe
data1 = df['a']
data2 = df[['a','c']]
print(data1,type(data1),'\n')
print(data2,type(data2),'\n')
print('='*50)
# 按照index选择行,只选择一行输出Series,选择多行输出Dataframe
data3 = df.loc['one']
data4 = df.loc[['one','two']]
print(data3,type(data3),'\n')
print(data4,type(data4))
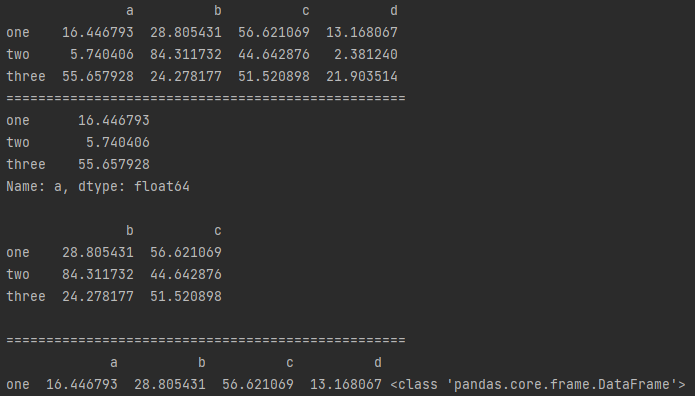
2.选择列
# df[] - 选择列
# 一般用于选择列,也可以选择行
df = pd.DataFrame(np.random.rand(12).reshape(3,4)*100,
index = ['one','two','three'],
columns = ['a','b','c','d'])
print(df)
print('='*50)
# df[]默认选择列,[]中写列名(所以一般数据colunms都会单独制定,不会用默认数字列名,以免和index冲突)
# 单选列为Series,print结果为Series格式
# 多选列为Dataframe,print结果为Dataframe格式
data1 = df['a']
data2 = df[['b','c']] # 尝试输入 data2 = df[['b','c','e']]
print(data1,'\n')
print(data2,'\n')
print('='*50)
# df[]中为数字时,默认选择行,且只能进行切片的选择,不能单独选择(df[0])
# 输出结果为Dataframe,即便只选择一行
# df[]不能通过索引标签名来选择行(df['one'])
# 核心笔记:df[col]一般用于选择列,[]中写列名
data3 = df[:1]
#data3 = df[0]
#data3 = df['one']
print(data3,type(data3))
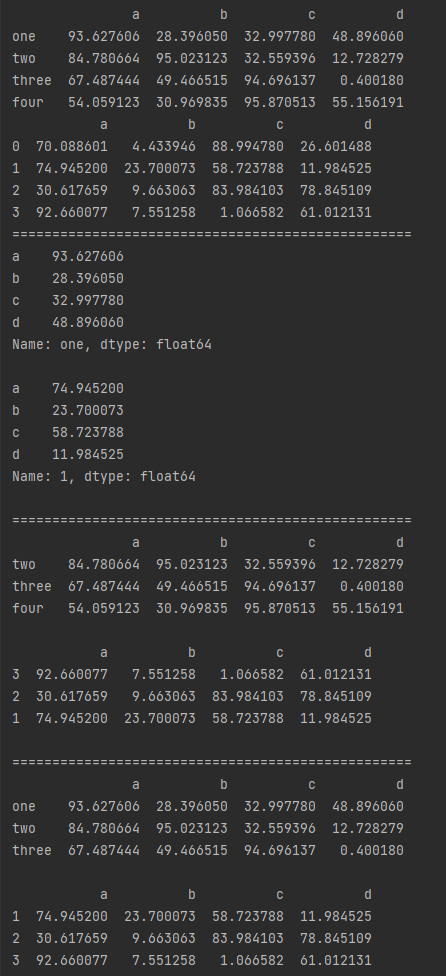
3.按index选择行
# df.loc[] - 按index选择行
# 核心笔记:df.loc[label]主要针对index选择行,同时支持指定index,及默认数字index
df1 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = ['one','two','three','four'],
columns = ['a','b','c','d'])
df2 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
columns = ['a','b','c','d'])
print(df1)
print(df2)
print('='*50)
# 单个标签索引,返回Series
data1 = df1.loc['one']
data2 = df2.loc[1]
print(data1,'\n')
print(data2,'\n')
print('='*50)
# 多个标签索引,如果标签不存在,则返回NaN
# 顺序可变
data3 = df1.loc[['two','three','four']]
data4 = df2.loc[[3,2,1]]
print(data3,'\n')
print(data4,'\n')
print('='*50)
# 切片索引 可以做切片对象
# 末端包含
data5 = df1.loc['one':'three']
data6 = df2.loc[1:3]
print(data5,'\n')
print(data6)
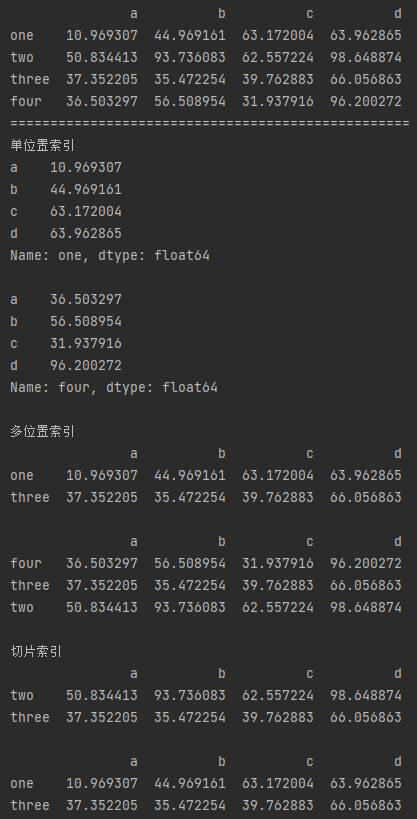
4.按照整数位置(从轴的0到length-1)选择行
# df.iloc[] - 按照整数位置(从轴的0到length-1)选择行
# 类似list的索引,其顺序就是dataframe的整数位置,从0开始计
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = ['one','two','three','four'],
columns = ['a','b','c','d'])
print(df)
print('='*50)
# 单位置索引
# 和loc索引不同,不能索引超出数据行数的整数位置
print('单位置索引')
print(df.iloc[0],'\n')
print(df.iloc[-1],'\n')
#print(df.iloc[4])
# 多位置索引 顺序可变
print('多位置索引')
print(df.iloc[[0,2]],'\n')
print(df.iloc[[3,2,1]],'\n')
# 切片索引
# 末端不包含
print('切片索引')
print(df.iloc[1:3],'\n')
print(df.iloc[::2])
5.布尔型索引
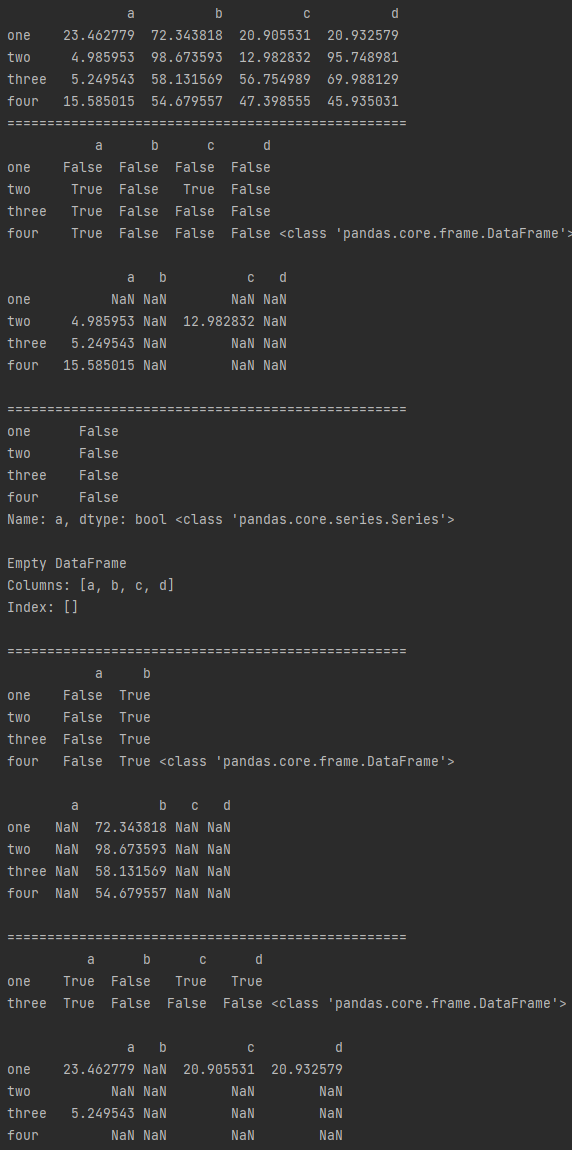
# 布尔型索引
# 和Series原理相同
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = ['one','two','three','four'],
columns = ['a','b','c','d'])
print(df)
print('='*50)
# 不做索引则会对数据每个值进行判断
# 索引结果保留 所有数据:True返回原数据,False返回值为NaN
b1 = df < 20
print(b1,type(b1),'\n')
print(df[b1],'\n') # 也可以书写为 df[df < 20]
print('='*50)
# 单列做判断
# 索引结果保留 单列判断为True的行数据,包括其他列
b2 = df['a'] > 50
print(b2,type(b2),'\n')
print(df[b2],'\n') # 也可以书写为 df[df['a'] > 50]
print('='*50)
# 多列做判断
# 索引结果保留 所有数据:True返回原数据,False返回值为NaN
b3 = df[['a','b']] > 50
print(b3,type(b3),'\n')
print(df[b3],'\n') # 也可以书写为 df[df[['a','b']] > 50]
print('='*50)
# 多行做判断
# 索引结果保留 所有数据:True返回原数据,False返回值为NaN
b4 = df.loc[['one','three']] < 50
print(b4,type(b4),'\n')
print(df[b4]) # 也可以书写为 df[df.loc[['one','three']] < 50]
6.多重索引
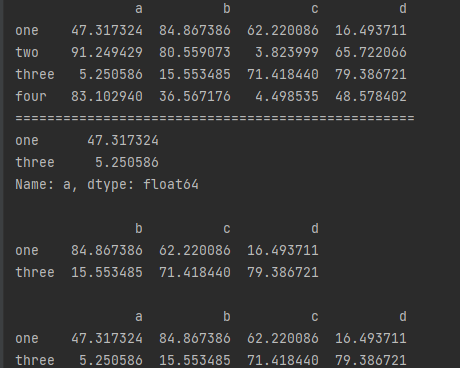
# 多重索引:比如同时索引行和列
# 先选择列再选择行 —— 相当于对于一个数据,先筛选字段,再选择数据量
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = ['one','two','three','four'],
columns = ['a','b','c','d'])
print(df)
print('='*50)
print(df['a'].loc[['one','three']],'\n') # 选择a列的one,three行
print(df[['b','c','d']].iloc[::2],'\n') # 选择b,c,d列的one,three行
print(df[df['a'] < 50].iloc[:2]) # 选择满足判断索引的前两行数据
四、Dataframe基本操作
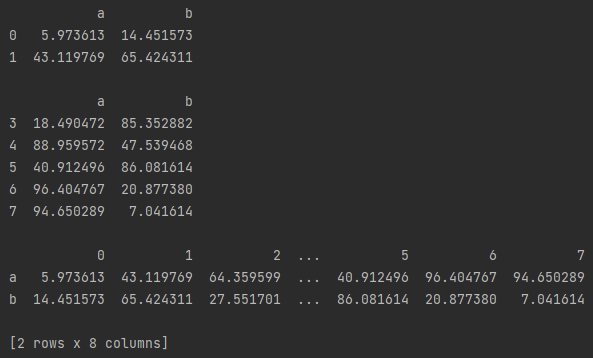
1.数据查看、转置
2.添加、修改、删除值
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
columns = ['a','b','c','d'])
print(df,'\n')
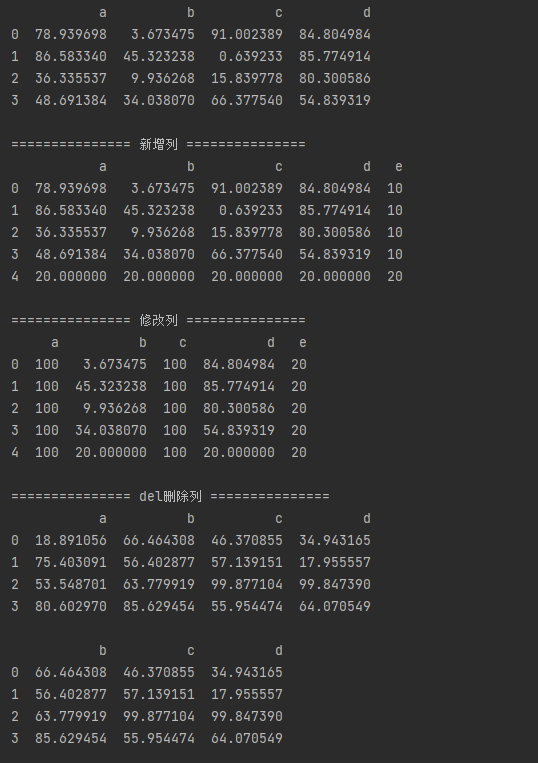
# 新增列/行并赋值
print('='*15,"新增列",'='*15,)
df['e'] = 10
df.loc[4] = 20
print(df,'\n')
# 索引后直接修改值
print('='*15,"修改列",'='*15,)
df['e'] = 20
df[['a','c']] = 100
print(df,'\n')
# 删除 del / drop()
print('='*15,"del删除列",'='*15,)
df1 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
columns = ['a','b','c','d'])
print(df1,'\n')
# del语句 - 删除列
del df1['a']
print(df1,'\n')
print('-----')
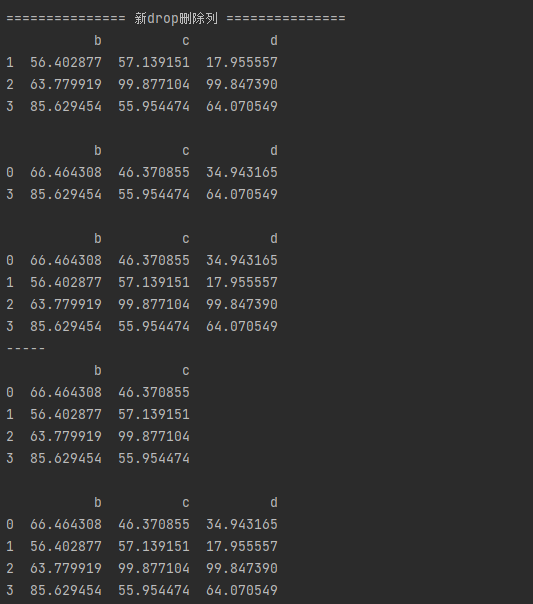
print('='*15,"新drop删除列",'='*15,)
# drop()删除行,inplace=False → 删除后生成新的数据,不改变原数据
print(df1.drop(0),'\n')
print(df1.drop([1,2]),'\n')
print(df1)
print('-----')
# drop()删除列,需要加上axis = 1,inplace=False → 删除后生成新的数据,不改变原数据
print(df1.drop(['d'], axis = 1),'\n')
print(df1)
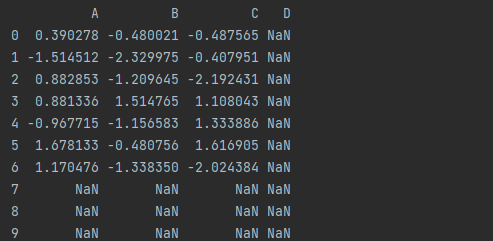
3.对齐
# 对齐
# DataFrame对象之间的数据自动按照列和索引(行标签)对齐
df1 = pd.DataFrame(np.random.randn(10, 4), columns=['A', 'B', 'C', 'D'])
df2 = pd.DataFrame(np.random.randn(7, 3), columns=['A', 'B', 'C'])
print(df1 + df2)
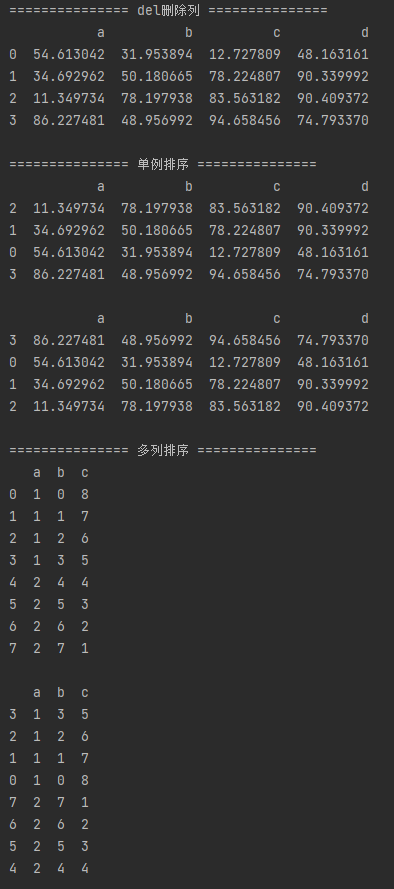
4.按值排序
# 排序1 - 按值排序 .sort_values
# 同样适用于Series
df1 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
columns = ['a','b','c','d'])
print(df1,'\n')
# 单列排序
# ascending参数:设置升序降序,默认升序
print('='*15,"单例排序",'='*15,)
print(df1.sort_values(['a'], ascending = True),'\n') # 升序
print(df1.sort_values(['a'], ascending = False),'\n') # 降序
# 多列排序,按列顺序排序
print('='*15,"多列排序",'='*15,)
df2 = pd.DataFrame({'a':[1,1,1,1,2,2,2,2],
'b':list(range(8)),
'c':list(range(8,0,-1))})
print(df2,'\n')
print(df2.sort_values(['a','c']))
5.索引排序
#print('='*15,"del删除列",'='*15,)
# 排序2 - 索引排序 .sort_index
# 按照index排序
# 默认 ascending=True, inplace=False
df1 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = [5,4,3,2],
columns = ['a','b','c','d'])
df2 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = ['h','s','x','g'],
columns = ['a','b','c','d'])
print(df1,'\n')
print(df1.sort_index(),'\n')
print(df2,'\n')
print(df2.sort_index())