在快速发展的自然语言处理领域,Transformers 已经成为主导模型,在广泛的序列建模任务中表现出卓越的性能,包括词性标记、命名实体识别和分块。在Transformers之前,条件随机场(CRFs)是序列建模的首选工具,特别是线性链CRFs,它将序列建模为有向图,而CRFs更普遍地可以用于任意图。
本文中crf的实现并不是最有效的实现,也缺乏批处理功能,但是它相对容易阅读和理解,因为本文的目的是让我们了解crf的内部工作,所以它非常适合我们。
发射和转换分数
在序列标记问题中,我们处理输入数据元素的序列,例如句子中的单词,其中每个元素对应于一个特定的标签或类别。目标是为每个单独的元素正确地分配适当的标签。在CRF-LSTM模型中,可以确定两个关键组成部分:发射和跃迁概率。我们实际上将处理对数空间中的分数,而不是数值稳定性的概率:
发射分数(Emission scores),神经网络输出的各个Tag的置信度
它与观察给定数据元素的特定标签的可能性有关。例如在命名实体识别的上下文中,序列中的每个单词都与三个标签中的一个相关联:实体的开头(B),实体的中间单词(I)或任何实体之外的单词(O)。发射概率量化了特定单词与特定标签相关联的概率。这在数学上表示为P(y_i | x_i),其中y_i表示标签,x_i表示输入单词。
转换分数(Transition scores),又叫过渡分数,描述了序列中从一个标签转换到另一个标签的可能性,也就是CRF层中各个Tag之间的转换概率
这些分数支持对连续标签之间的依赖关系进行建模。通过捕获这些依赖关系,转换分数有助于预测标签序列的连贯性和一致性。它们表示为P(y_i | y*(i-1)),其中y_i表示当前标签,y*(i-1)表示序列中的前一个标签。
这两个组件的协同作用产生了一个鲁棒的序列标记模型。
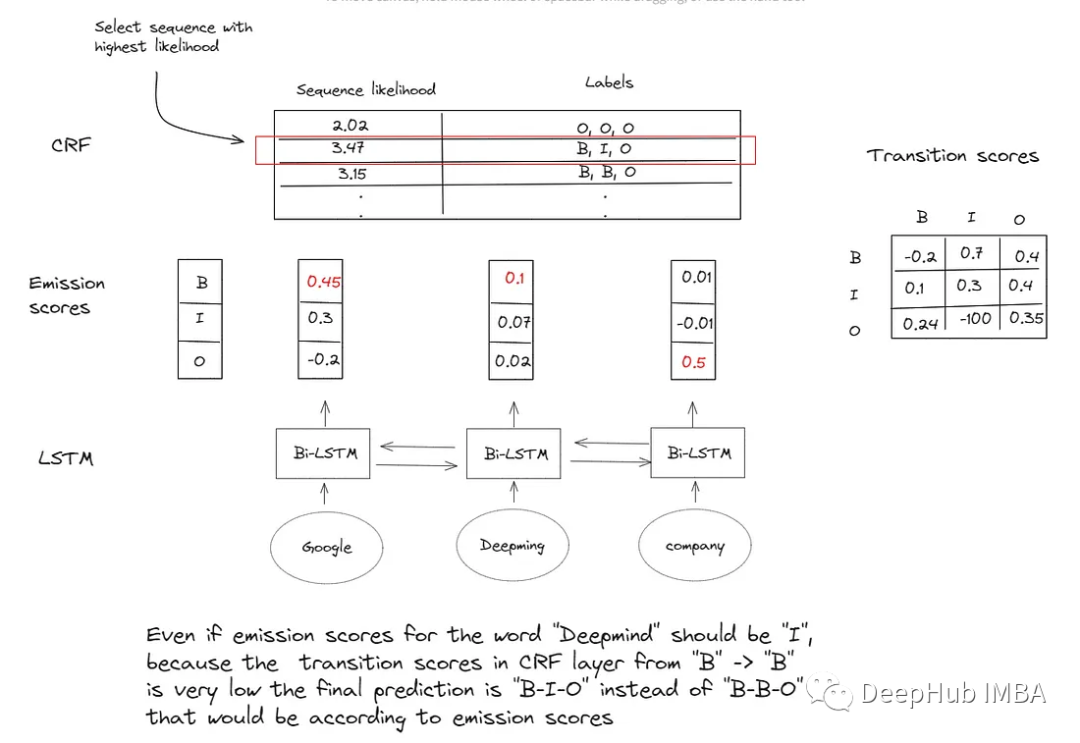
为了给给定的单词分配发射分数,可以使用各种特征函数,比如单词的上下文、它的形状(如大写模式,如果一个单词以大写字母开头,而不是在句子的开头,那么它很可能是一个实体的开头),形态学特征(包括前缀、后缀和词干)等等。定义这些特性可能是一项劳动密集型且耗时的工作。这就是为什么许多从业者选择双向LSTM模型,它可以根据每个单词的上下文信息计算发射分数,而无需手动定义任何特征。
随后在得到LSTM的发射分数后,需要构建了一个CRF层来学习转换分数。CRF层利用LSTM生成的发射分数来优化最佳标签序列的分配,同时考虑标签依赖性。
https://avoid.overfit.cn/post/122dcc337faf4674885e31841b32f50f