预警: 本次内容不算多, 但数学推导较复杂
Normalization
归一化的意义
之前内部的权重没有做过标准化. 实际上如果能标准化, 可以提升训练效果, 甚至可以提升精度(虽然不大). 设立专门的batch/layer normalization层的意义在于:
- 梯度更加规范
- 对于学习率(可以更高),初始化权重等要求降低, 因为值的标准化也可以提升训练速度
- 有时可以防止过拟合
不过有的时候, 归一化会破坏一些特征, 为此有时结果的均值和方差需要适当移动. 除此之外, 根据博客[机器学习]批归一化和层归一化 - 龍馬 - 博客园 (cnblogs.com)的总结, 这个还可以在一定程度上解决ReLU神经元死亡的问题.
归一化层实现
本次作业的基础几乎都是一篇论文, 为此我们必须认真阅读论文: [1502.03167] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (arxiv.org) 下面就是我本人的解释
这个论文主要的意思就是我们估计样本的均值和方差, 将其归一化, 再指定均值和方差的移动/缩放(注意, 这两个参数是可以学习的). 即:
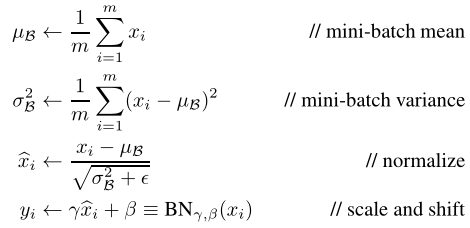
需要注意的是, 我们在测试集中, 不使用测试样本的方差计算,而是直接用训练集记录的计算, 这点论文没有提到. 具体做法就是指数平滑(按作业的意思就是带动量) 下面是代码:
if mode == 'train':
sample_mean = np.mean(x, axis=0) # 对每列单独进行归一化
# 比如说, 我们输出隐含层100,500张图片,那么输出为500*100, 我们对500个图片的1-100号输出列向量
# 分别做正则化, 互不影响
sample_var = np.var(x, axis=0)
x_hat = (x - sample_mean) / np.sqrt(sample_var + eps) # eps防止除0
out = gamma * x_hat + beta # 偏移
cache = (x, sample_mean, sample_var, x_hat, eps, gamma, beta) # 自己组织cache要用到的数据, 后面梯度要用到
# 因为gamma,beta也需要学习, 故也应当被记录
# running_mean是为了测试集记录的样本mean和var,遵循指数平滑原则
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_var
pass
elif mode == 'test':
out = (x - running_mean) * gamma / (np.sqrt(running_var))
pass求解梯度. 论文中已经给出了表达式:
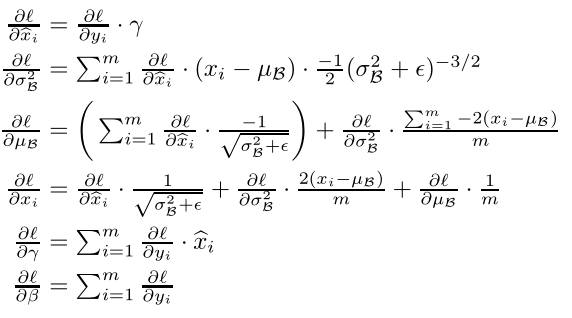
下面我再做一下解释:
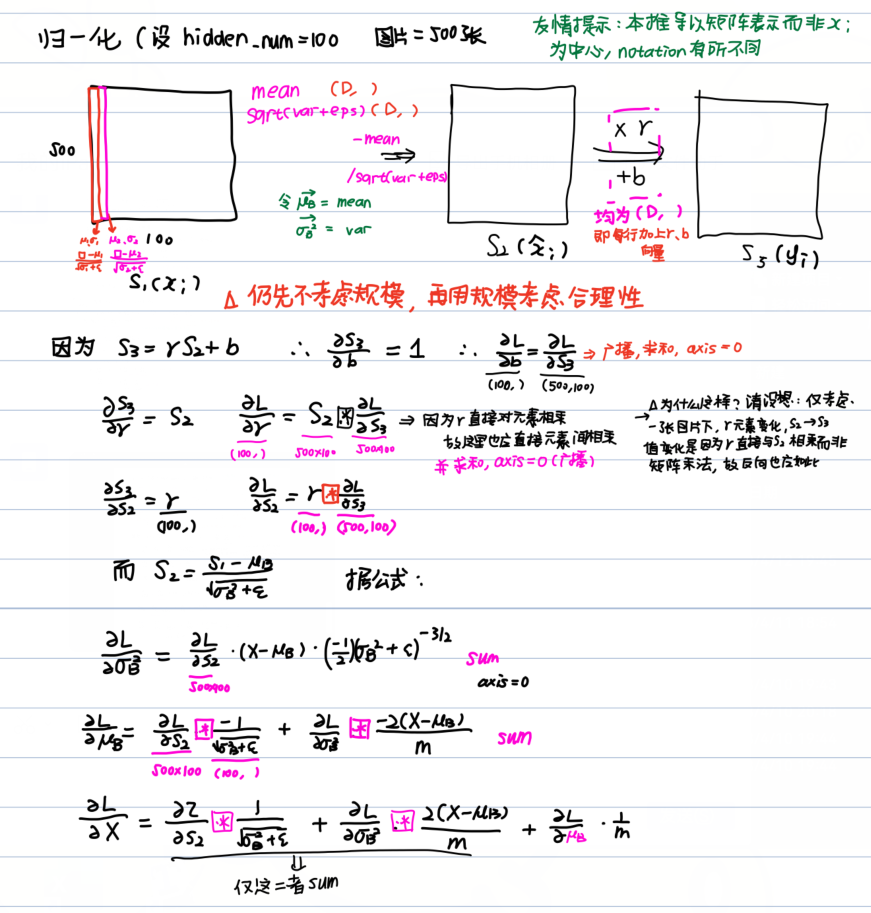
于是就能够写出来了, 这就是照搬公式的版本:
(x, mean, var, x_hat, eps, gamma, beta) = cache
N = x.shape[0]
dbeta = np.sum(dout, axis=0)
dgamma = np.sum(dout * x_hat, axis=0)
dx_hat = gamma * dout
dvar = np.sum((x - mean) * dx_hat, axis=0) * (-0.5 / np.sqrt(var + eps) ** 3)
# 注意: sum的位置无关紧要,比如把-0.5 / np.sqrt(var + eps) ** 3)包含进sum不影响结果
dmean = -1 / np.sqrt(var + eps) * np.sum(dx_hat, axis=0) + dvar * np.sum(-2 * (x - mean), axis=0) / N
# final gradient
dx = 1 / np.sqrt(var + eps) * dx_hat + 1 / N * dmean + dvar * 2 * (x - mean) / N我另外在网上看到一个版本, 引入了中间量, 下面是解说, 可以不看, 可以对过程有更深刻的理解:
x, mean, var, x_hat, eps, gamma, beta = cache
N = x.shape[0]
# 为了方便引入的中间量: (X-μ_B) 和 √(σ_B^2 + ε)
mu1 = x - mean
mu2 = np.sqrt(var + eps)
# dbeta和dgamma较简单
dbeta = np.sum(dout, axis=0) # 按照推导指示直接求和
dgamma = np.sum(x_hat * dout, axis=0) # 注意是*而非x_hat.dot
# dL/dS2
dS2 = dout * gamma
dmu1 = dS2 / mu2 # S2 = (X-μ_B) / √(σ_B^2 + ε) => ∂L/∂(X-μ_B) = ... [(N,D)]
dmu2 = - np.sum(mu1 / mu2 ** 2 * dS2, axis=0) # ∂L/∂mu2 = -mu1/(mu2^2) * ∂L/∂S2 [注意规模(D,)]
dx = dmu1 # ∂L/∂X = ∂L/∂(X-μ_B) + ... ∂L/∂X第一项完成 必须注意, 因为X和μ_B不独立,所以不能简单等于
dmean1 = -np.sum(dmu1, axis=0) # ∂L/∂μ_B = -∂L/∂(X-μ_B) + ... [注意规模(D,)] ∂L/∂μ_B 第一项完成
dvar = 0.5 * (1 / mu2) * dmu2 # ∂L/∂(σ_B^2) = ∂L/√(σ_B^2 + ε) * (1/2) * -√(σ_B^2 + ε)
dmu3 = 2.0 / N * (x - mean) * dvar # 第二项的系数
dx += dmu3 # ∂L/∂X第二项完成
dmean2 = -np.sum(dmu3, axis=0) # ∂L/∂μ_B 第二项完成
dx += 1.0 / N * dmean1
dx += 1.0 / N * dmean2不能不说这个确实是难, 不过归根到底就是公式的转化, 其实这么写还是复杂了, 要是直接照着我的图写公式还能更简单些...
更简单的backward函数
那个作业上的图看起来很复杂, 但我定睛一看, 我去, 这不是和我以矩阵为主的思想直接就不谋而合了吗? 话是这么说, 但因为规模的不同, 许多项不能轻易合并! 即使是在dX里面, 也不可避免会存在一些sum的表达形式. 这个我一直没想通, 结果我看到了一个巨漂亮的公式:
dgamma = np.sum(x_hat * dout, axis=0) # 这俩还是一样的
dbeta = np.sum(dout, axis=0)
dx = (1. / N) * gamma * (var + eps) ** (-1. / 2.) * (
N * dout - np.sum(dout, axis=0) - (x - mean) * (var + eps) ** (-1.0) * np.sum(dout * (x - mean),
axis=0))认真分析上面的公式, 我们看到, 虽然每一个都有∂L/∂S2, 但是我们却不能抽出来, 因为一个不求和, 一个求和, 二者是不能划等号的! 为了统一, 我们确认只有1/√(σ_B^2+ε)和γ是没有求和的统一公共项. 随后我们一点点拆分,就得到了上面的结果.
实践
将norm用在实际的网络中,可以明显发现归一化之后收敛速度有了很明显的加快.
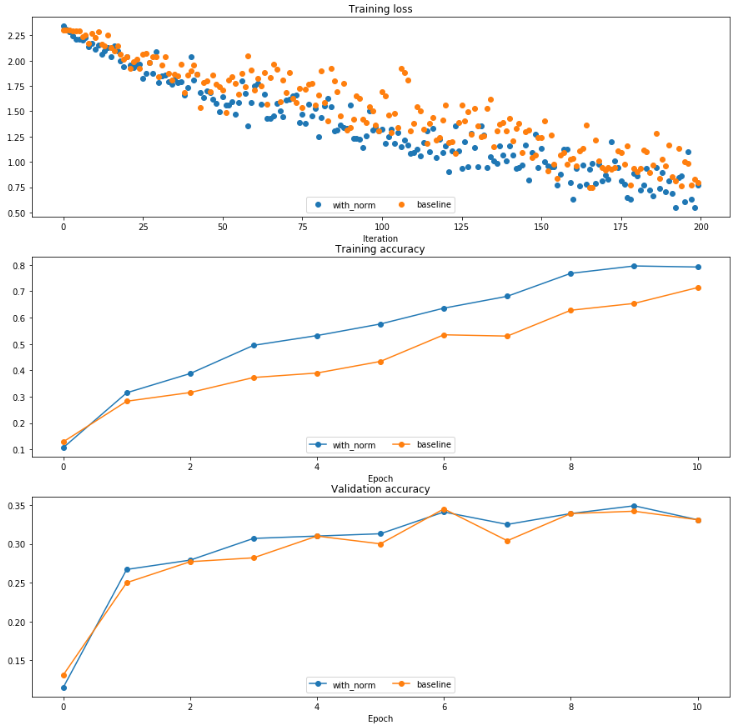
此外原本作业还设计了一个实验, 表明了拥有归一化层之后对初始weight的要求会低很多,最优weight scale附近batch norm下降会慢很多.
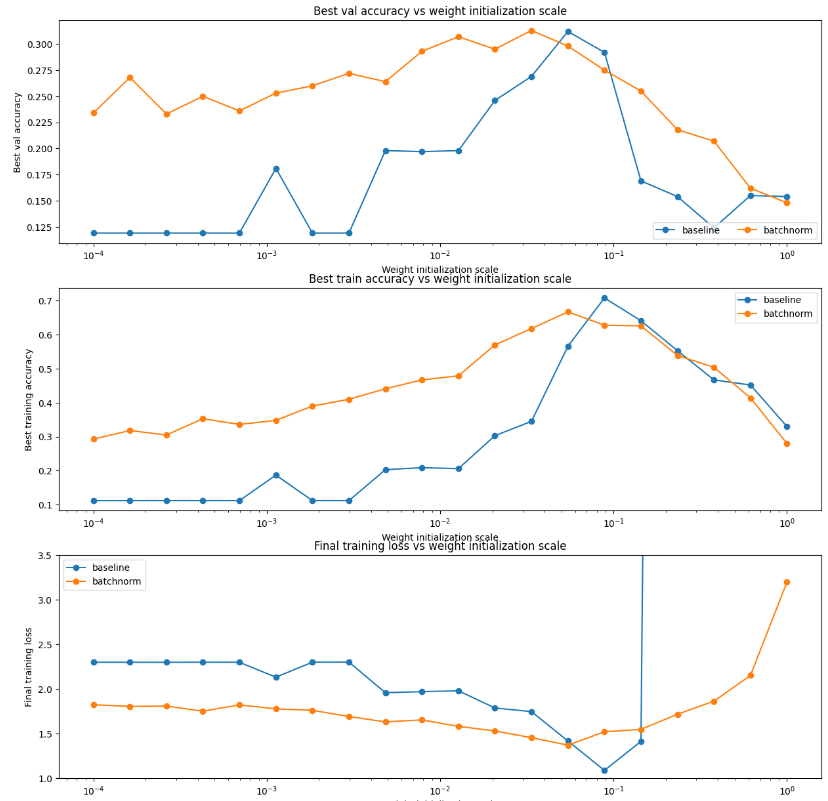
原始作业还测试了不同的batch size对batch norm的影响,这也是问题2的核心内容.
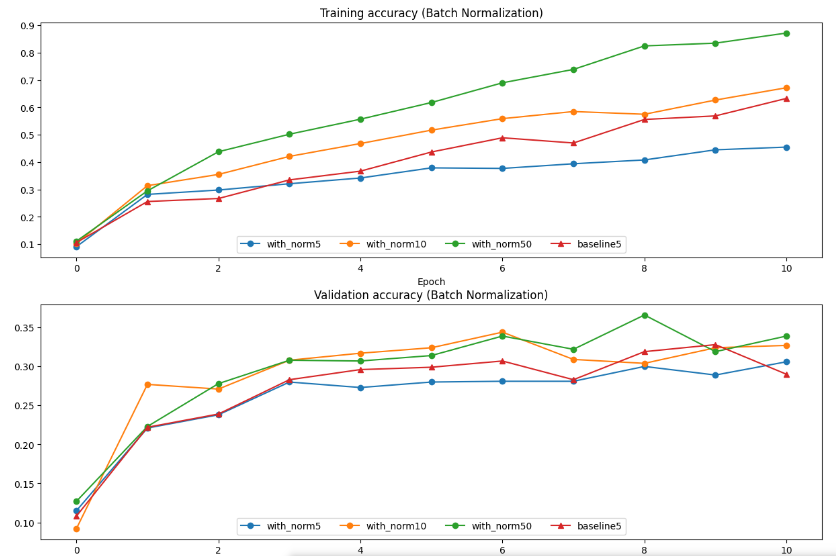
从这就得到了结论, 如果batch size不够大, 那么就会导致收敛速度不够快, 这也是batch norm的最大问题. 此外, 如果训练数据等的方差较大, 或者在RNN等动态场合下, 需要谨慎使用BN.
Layer normalization
下面的方式其实原理基本一样, 只是正则的对象从列变成了行. 仍然用之前的例子, 我们输出隐含层元素数100, 500张图片,那么输出矩阵为500*100, 我们就对500个图片所属的输出分别正则化,互不影响. 求mean/var对象也从axis=0变成了axis=1. 我们只需要对之前代码简单修改就可以直接用, 设计动量和指数平滑得这里不再需要了:
sample_mean = np.mean(x, axis=1, keepdims=True) # 注意axis=1要考虑keepdim,确保广播机制
sample_var = np.var(x, axis=1, keepdims=True)
x_hat = (x - sample_mean) / np.sqrt(sample_var + eps)
out = gamma * x_hat + beta
cache = (x, sample_mean, sample_var, x_hat, eps, gamma, beta)请注意, 这里的gamma和beta规模和前面是一样的, 它们依旧是行向量(D,), 操作也是一致的, 并没有颠倒.
随后是方向推导, 此时gamma和beta因为操作一致,表示也完全一致, 剩下的涉及的所有求和从axis=0 => axis=1, keepdims = True, 并记得把N改成shape[1]. 这个方法对于前面普通版本的两个都能够测试通过, 表明了其正确性. 但是这个用简单版本却不能通过, dx明显异常, 目前原因不知.
可以看出, 在这个情况下, 对于小batch_size效果更加好, 证明了其能够更好适应动态网络和嵌入式场景, 又保留了batch normalization的快速收敛性质.
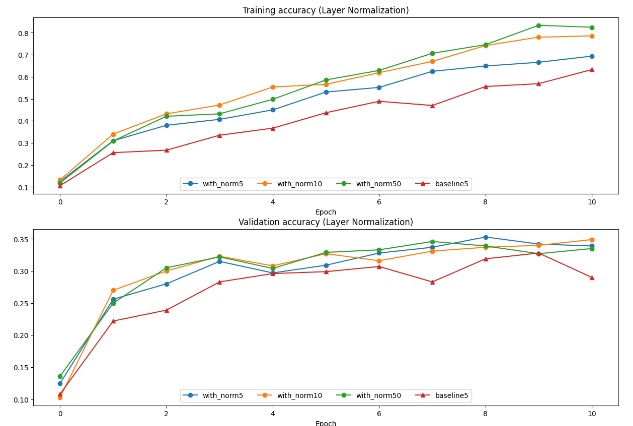
但是它也不是没有缺点, 例如, 在卷积网络中, 它可能会抹去掉图像特征, 导致无法正常收敛. 作业4中, 也有问道这点. 在深层网络中, layer的效果可以看出来仍然不错, 能显著加快收敛速度, 但是和batch对batch_size敏感一样, layer敏感的是行的长度, 对应选项2, 所以特征不够多/隐含层元素数量不足效果就没那么显著. 在正则化项太大的时候, weight会因为loss趋向于0, 这样norm层的作用就不会那么强了, 但是影响不如2那么大.
问题3和解答
问题1/2/4都已经在上面有所说明.

回答: batch_normalize是图片间的, 而layer_norm是图片内的, 所以1/2对layer无影响, 3对batch无影响.