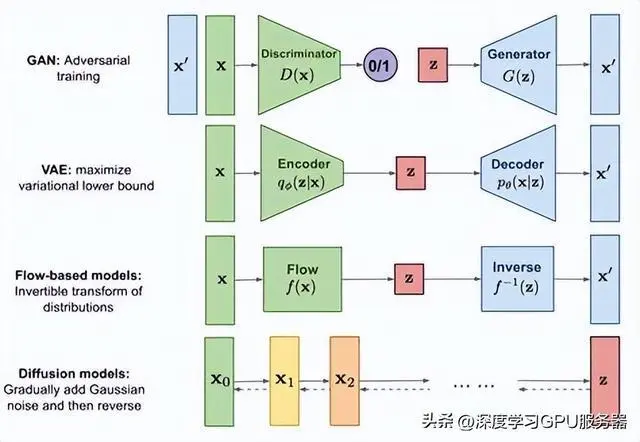
引文:https://baijiahao.baidu.com/s?id=1762593871720612037&wfr=spider&for=pc
随着生成型AI技术的能力提升,越来越多的注意力放在了通过AI模型提升研发效率上。业内比较火的AI模型有很多,比如画图神器Midjourney、用途多样的Stable Diffusion,以及OpenAI此前刚刚迭代的DALL-E 2。
对于研发团队而言,尽管Midjourney功能强大且不需要本地安装,但它对于硬件性能的要求较高,甚至同一个指令每次得到的结果都不尽相同。相对而言,Stable Diffusion因具备功能多、开源、运行速度快,且能耗低内存占用小成为更理想的选择。

AIGC和ChatGPT4技术的爆燃和狂飙,让文字生成、音频生成、图像生成、视频生成、策略生成、GAMEAI、虚拟人等生成领域得到了极大的提升。不仅可以提高创作质量,还能降低成本,增加效率。同时,对GPU和算力的需求也越来越高,因此GPU服务器厂商开始涌向该赛道,为这一领域提供更好的支持。
Stable Diffusion背后的原理
Latent Diffusion Models(潜在扩散模型)的整体框架如下图所示。首先需要训练一个自编码模型,这样就可以利用编码器对图片进行压缩,然后在潜在表示空间上进行扩散操作,最后再用解码器恢复到原始像素空间。这种方法被称为感知压缩(Perceptual Compression)。个人认为这种将高维特征压缩到低维,然后在低维空间上进行操作的方法具有普适性,可以很容易地推广到文本、音频、视频等领域
在潜在表示空间上进行diffusion操作的主要过程和标准的扩散模型没有太大的区别,所使用的扩散模型的具体实现为time-conditional UNet。但是,论文为扩散操作引入了条件机制(Conditioning Mechanisms),通过cross-attention的方式来实现多模态训练,使得条件图片生成任务也可以实现。
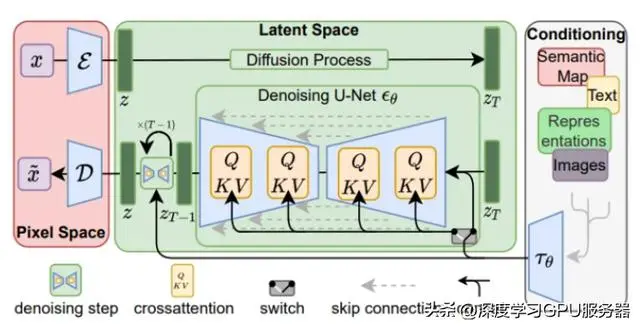
下面我们针对感知压缩、扩散模型、条件机制的具体细节进行展开。
图片感知压缩(Perceptual Image Compression)
感知压缩本质上是一个tradeoff。之前的许多扩散模型没有使用这种技术也可以进行,但是原有的非感知压缩的扩散模型存在一个很大的问题,即在像素空间上训练模型时,如果希望生成高分辨率的图像,则训练空间也是高维的。感知压缩通过使用自编码模型,忽略高频信息,只保留重要的基础特征,从而大幅降低训练和采样阶段的计算复杂度,使文图生成等任务能够在消费级GPU上在10秒内生成图片,降低了落地门槛。
感知压缩利用预训练的自编码模型,学习到一个在感知上等同于图像空间的潜在表示空间。这种方法的优势在于,只需要训练一个通用的自编码模型,就可以用于不同的扩散模型的训练,在不同的任务上使用。
因此,基于感知压缩的扩散模型的训练本质上是一个两阶段训练的过程,第一阶段需要训练一个自编码器,第二阶段才需要训练扩散模型本身。在第一阶段训练自编码器时,为了避免潜在表示空间出现高度的异化,作者使用了两种正则化方法,一种是KL-reg,另一种是VQ-reg,因此在官方发布的一阶段预训练模型中,会看到KL和VQ两种实现。在Stable Diffusion中主要采用AutoencoderKL这种实现。
效率与效果的权衡
分析不同下采样因子f∈{1,2,4,8,16,32}(简称LDM-f,其中LDM-1对应基于像素的DMs)的效果。为了获得可比较的测试结果,固定在一个NVIDIA A100上进行了实验,并使用相同数量的步骤和参数训练模型。实验结果表明,LDM-{1,2}这样的小下采样因子训练缓慢,因为它将大部分感知压缩留给扩散模型。而f值过大,则导致在相对较少的训练步骤后保真度停滞不前,原因在于第一阶段压缩过多,导致信息丢失,从而限制了可达到的质量。LDM-{4-16}在效率和感知结果之间取得了较好的平衡。与基于像素的LDM-1相比,LDM-{4-8}实现了更低的FID得分,同时显著提高了样本吞吐量。对于像ImageNet这样的复杂数据集,需要降低压缩率以避免降低质量。总之,LDM-4和-8提供了较高质量的合成结果。

一、优点
Diffusion Model相比于GAN,明显的优点是避免了麻烦的对抗学习。此外,还有几个不太明显的好处:首先,Diffusion Model可以“完美”用latent去表示图片,因为我们可以用一个ODE从latent变到图片,同一个ODE反过来就可以从图片变到latent。而GAN很难找到真实图片对应什么latent,所以可能会不太好修改非GAN生成的图片。其次,Diffusion Model可以用来做“基于色块的编辑”(SDEdit),而GAN没有这样的性质,所以效果会差很多。再次,由于Diffusion Model和score之间的联系,它可以用来做inverse problem solver的learned prior,例如我有一个清晰图片的生成模型,看到一个模糊图片,可以用生成模型作为先验让图片更清晰。最后,Diffusion Model可以求model likelihood,而这个GAN就很难办。Diffusion Model最近的流行一部分也可能是因为GAN卷不太动了。虽然严格意义上说,Diffusion Model最早出自Jascha Sohl-Dickstein在ICML 2015就发表的文章,和GAN的NeurIPS 2014也差不了多少;不过DCGAN/WGAN这种让GAN沃克的工作在2015-17就出了,而Diffusion Model在大家眼中做沃克基本上在NeurIPS 2020,所以最近看上去更火也正常。
二、不足之处
Diffusion model相比于GAN也存在一些缺陷。首先,无法直接修改潜在空间的维度,这意味着无法像StyleGAN中使用AdaIN对图像风格进行操作。其次,由于没有判别器,如果监督条件是“我想要网络输出的东西看起来像某个物体,但我不确定具体是什么”,就会比较困难。而GAN可以轻松地实现这一点,例如生成长颈鹿的图像。此外,由于需要迭代,生成速度比较慢,但在单纯的图像生成方面已经得到了解决。目前在条件图像生成方面的研究还不够充分,但可以尝试将Diffusion model应用于这一领域。