一、选题的背景
天气作为日常生活中不可忽视的因素,对人们的出行、衣食住行等方面均有影响。此次选题旨在通过对泉州市2022年天气数据的收集和分析,了解该地区各季节天气的变化情况,为当地居民提供参考信息,并为相关部门制定应急预案提供依据。
预期目标是建立一个完整、详细的数据集,包括每日的日期", "最高气温", "最低气温", '天气'等气象数据,并基于这些数据进行可视化分析,构建出图表,展示各类天气指标的趋势变化。通过这些可视化展示,能够更加直观地反映泉州市各季节天气特点和规律,为人们提供科学、准确的参考信息。
二、主题式网络爬虫设计方案
1.主题始网络爬虫名称
爬取泉州2022年天气数据并做可视化分析
2.本数据集的数据内容与数据特征分析
采集泉州2022年天气数据中的日期,最高气温,最低气温,天气等数据
对泉州一整年的雨季,旱季进行分析,给出泉州天气变化参考
3.数据分析的课程设计方案概述(包括实现思路与技术难点)
- 数据采集
首先确定需要采集的数据来源,从网站获取。使用Python中的Requests库发送HTTP请求获取网页源代码,利用BeautifulSoup或正则表达式等技术筛选出感兴趣的数据,存储到本地或数据库中。
- 数据可视化分析
将采集到的数据进行清洗、预处理等操作,使用Python中的Pandas库进行数据分析,并可视化展示。可以使用Matplotlib、Seaborn等第三方库进行数据可视化,生成折线图、柱状图、散点图、热力图等形式,直观呈现数据变化规律和趋势。
技术难点:
- 如何确定需要采集的数据来源,需要对数据本身有一定的了解。
- 对于网页源代码的处理需要一定的HTML和CSS基础。
- 数据清洗和预处理时需要考虑异常数据的处理方法。
- 数据可视化过程中需要根据不同数据类型选择不同的展示方式,需要对各种图表形式有一定的了解。
三、主题页面的结构与特征分析
1.主题页面的结构与特征分析
目标内容界面:
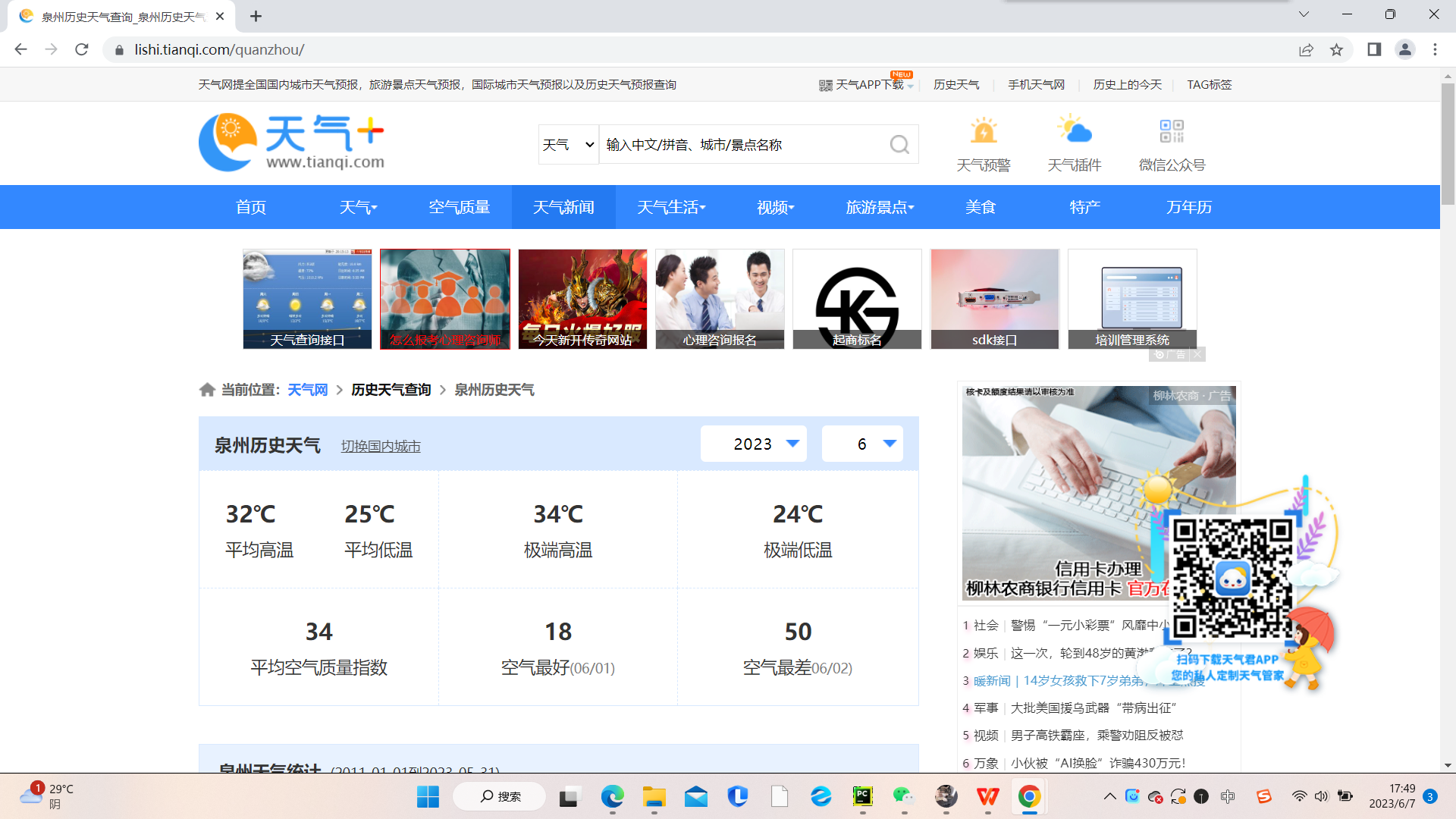
2. Htmls 页面解析
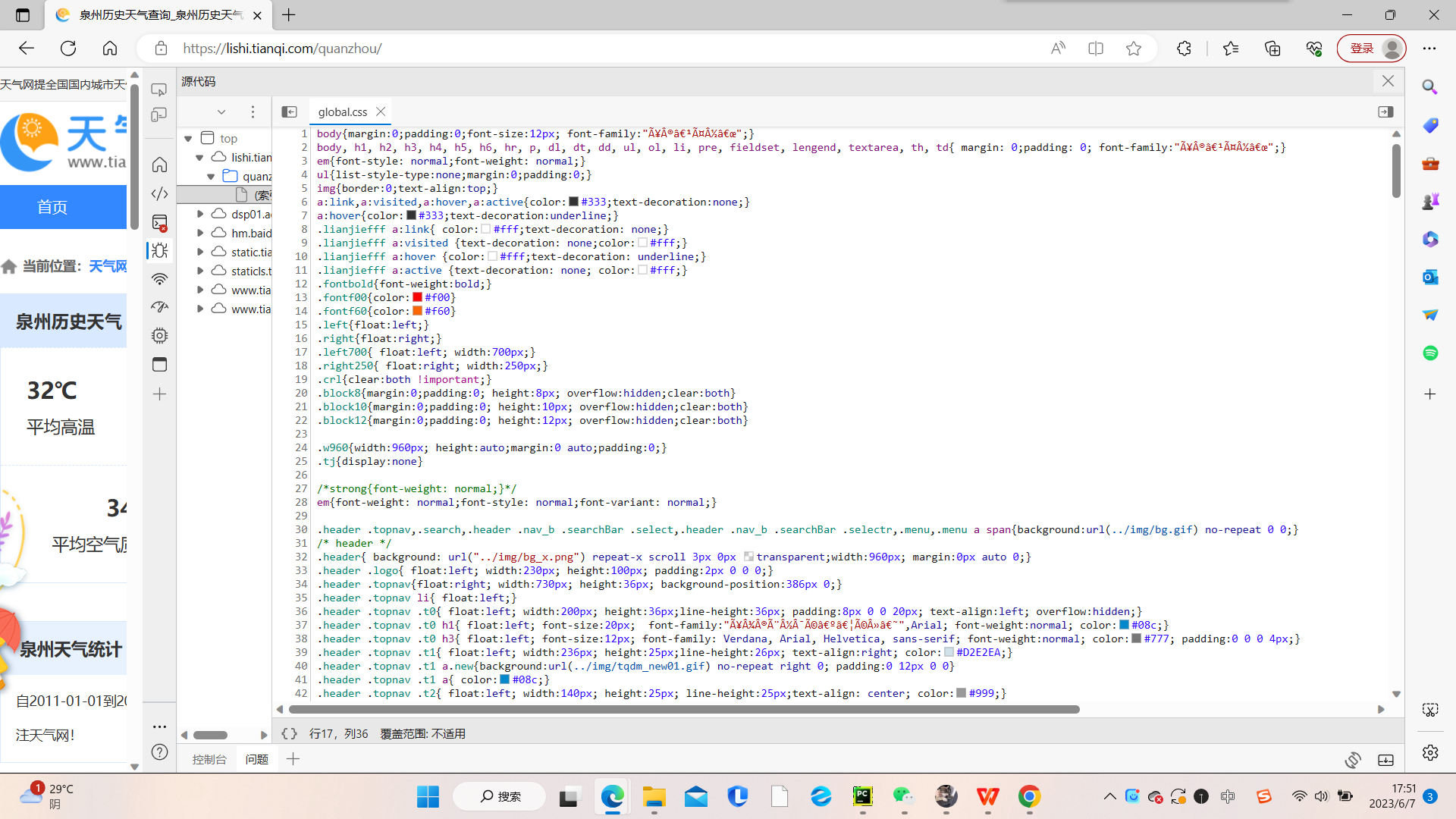
3.节点查找方法与遍历方法
查找方法:find(): 查找第一个匹配到的节点。find_all(): 查找所有匹配到的节点,并返回一个列表。
遍历方法:contents: 返回当前节点的直接子节点列表。 children: 返回当前节点的直接子节点的迭代器。descendants: 返回当前节点的所有子孙节点的迭代器。
parent: 返回当前节点的父节点。parents: 返回当前节点的所有祖先节点的迭代器。
四、网络爬虫程序设计(60分)
1.数据爬取与采集
数据源:https://lishi.tianqi.com/quanzhou/
所用到的库有
1 import requests # 模拟浏览器进行网络请求 2 from lxml import etree # 进行数据预处理 3 import csv # 进行写入csv文件

使用requests中的get方法对网站发出请求,并接收响应数据,
我们便得到了网页的源代码数据,
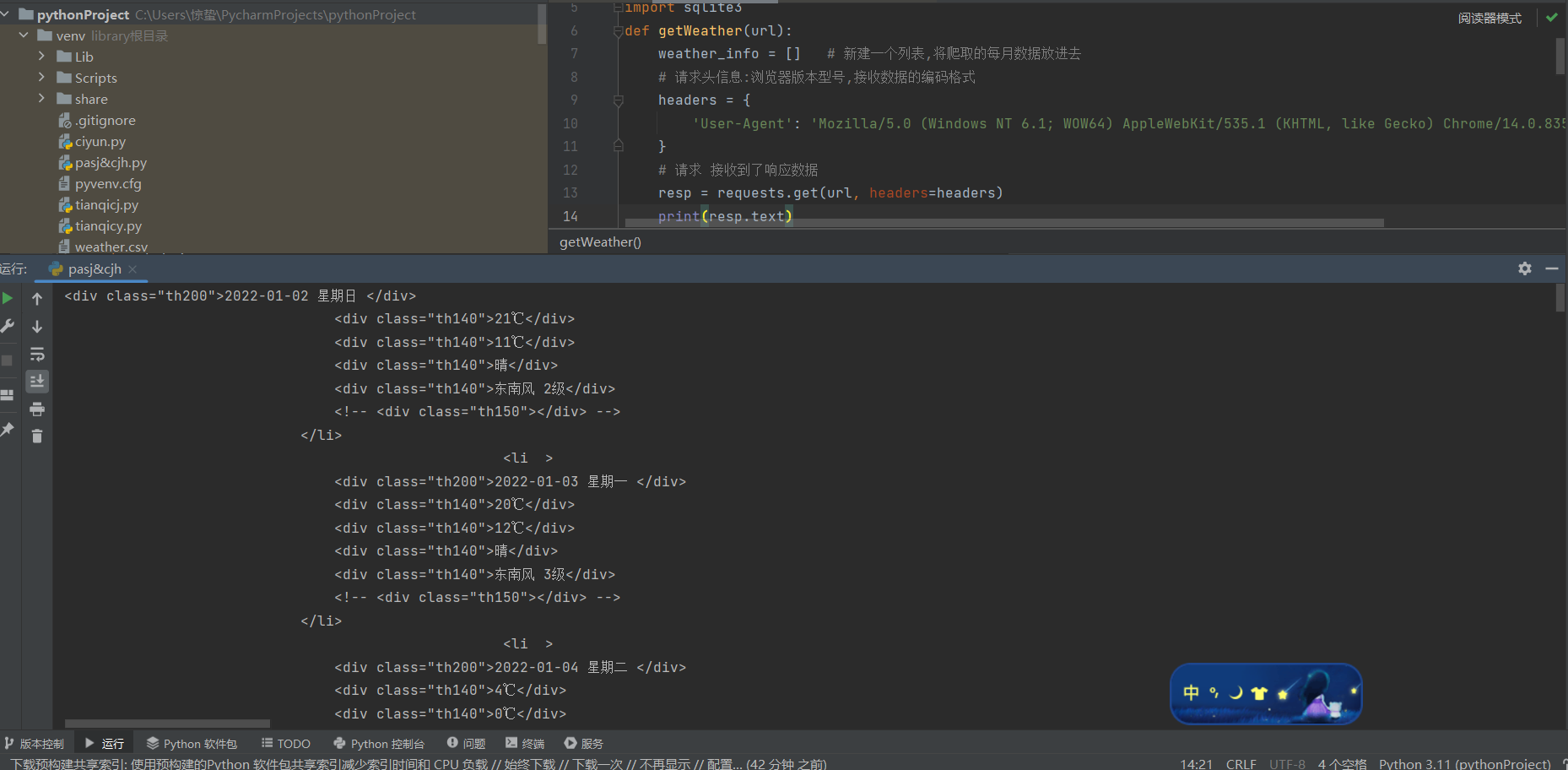
2.对数据进行清洗和处理
然后对爬取的网站源代码进行预处理


创建一个字典,并使用for循环将我们所提取的数据,放入字典中
1 for li in resp_list: 2 day_weather_info = {} 3 # 日期 4 day_weather_info['date_time'] = li.xpath("./div[1]/text()")[0].split(' ')[0] 5 # 最高气温 (包含摄氏度符号) 6 high = li.xpath("./div[2]/text()")[0] 7 day_weather_info['high'] = high[:high.find('℃')] 8 # 最低气温 9 low = li.xpath("./div[3]/text()")[0] 10 day_weather_info['low'] = low[:low.find('℃')] 11 # 天气 12 day_weather_info['weather'] = li.xpath("./div[4]/text()")[0] 13 weather_info.append(day_weather_info) 14 return weather_info
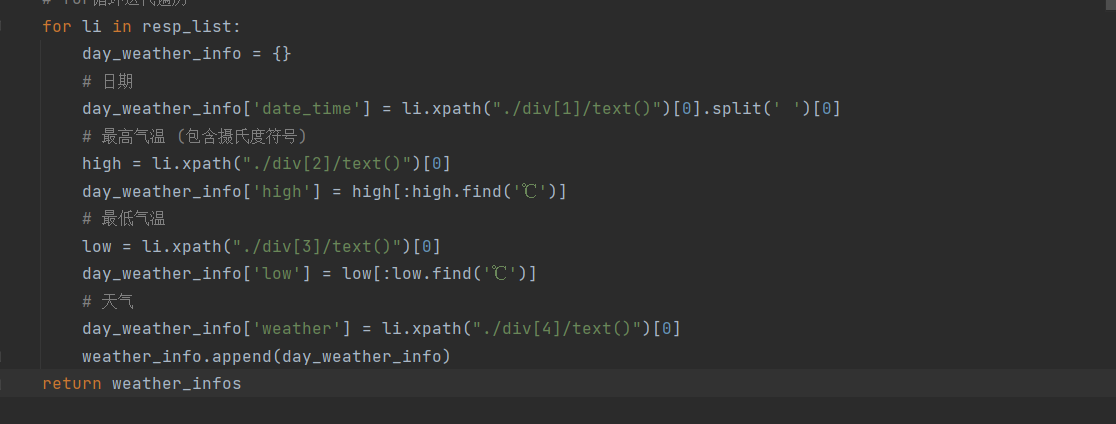
然后我们便得到了我们所需要的数据

接着爬取我们这个月的天气信息,存入列表中,然一次性写入我们的csv文件中,这样我们就得到了一个存有泉州2022全年天气情况的文件
# for循环生成有顺序的1-12 for month in range(1, 13): # 获取某一月的天气信息 # 三元表达式 weather_time = '2022' + ('0' + str(month) if month < 10 else str(month)) print(weather_time) url = f'https://lishi.tianqi.com/quanzhou/{weather_time}.html' # 爬虫获取这个月的天气信息 weather = getWeather(url) # 存到列表中 weathers.append(weather) print(weathers) # 数据写入(一次性写入) with open("weather.csv", "w",newline='') as csvfile: writer = csv.writer(csvfile) # 先写入列名:columns_name 日期 最高气温 最低气温 天气 writer.writerow(["日期", "最高气温", "最低气温", '天气']) # 一次写入多行用writerows(写入的数据类型是列表,一个列表对应一行) writer.writerows([list(day_weather_dict.values()) for month_weather in weathers for day_weather_dict in month_weather]) import sqlite3
文件如下:

3.对我们的数据进行一下词云处理
所用到的库
1 import requests 2 from lxml import etree 3 import csv 4 from wordcloud import WordCloud 5 import matplotlib.pyplot as plt
然后对数据在进行一次爬取与清理
1 # 从URL获取天气信息的函数 2 def getWeather(url): 3 weather_info = [] # 存储天气信息的列表 4 headers = { 5 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1' 6 } 7 resp = requests.get(url, headers=headers) # 发送GET请求到指定的URL 8 resp_html = etree.HTML(resp.text) # 解析响应的HTML 9 resp_list = resp_html.xpath("//ul[@class='thrui']/li") # 使用XPath选择器提取天气信息列表 10 for li in resp_list: 11 day_weather_info = {} # 存储每天天气信息的字典 12 day_weather_info['date_time'] = li.xpath("./div[1]/text()")[0].split(' ')[0] # 提取日期时间并存入字典 13 high = li.xpath("./div[2]/text()")[0] # 提取最高温度 14 day_weather_info['high'] = high[:high.find('℃')] # 去除温度单位并存入字典 15 low = li.xpath("./div[3]/text()")[0] # 提取最低温度 16 day_weather_info['low'] = low[:low.find('℃')] # 去除温度单位并存入字典 17 day_weather_info['weather'] = li.xpath("./div[4]/text()")[0] # 提取天气情况并存入字典 18 weather_info.append(day_weather_info) # 将每天天气信息字典添加到天气信息列表中 19 return weather_info 20 def main(): 21 weathers = [] # 存储所有月份的天气信息的列表 22 for month in range(1, 13): 23 weather_time = '2022' + ('0' + str(month) if month < 10 else str(month)) 24 print(weather_time) 25 url = f'https://lishi.tianqi.com/quanzhou/{weather_time}.html' 26 weather = getWeather(url) 27 weathers.append(weather) # 将每个月份的天气信息添加到weathers列表中 28 print(weathers) 29 30 weather_data = "" # 存储所有天气情况的字符串 31 for month_weather in weathers: 32 for day_weather_dict in month_weather: 33 weather = day_weather_dict['weather'] # 提取天气情况 34 weather_data += weather + " " # 将天气情况添加到weather_data字符串中,用空格分隔
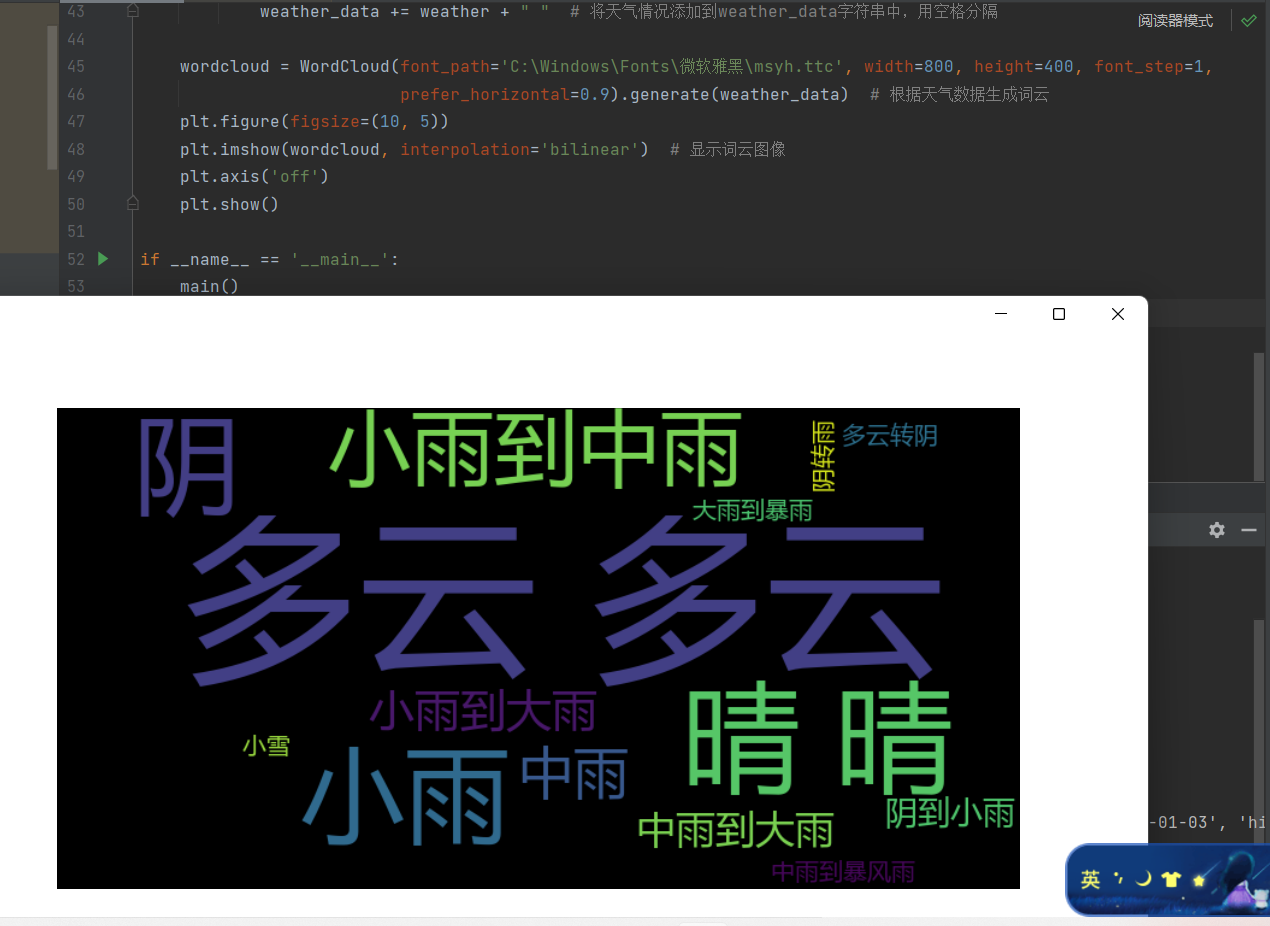
然后便得到了我们熟悉的数据

wordcloud的分词可视化处理
1 wordcloud = WordCloud(font_path='C:\Windows\Fonts\微软雅黑\msyh.ttc', width=800, height=400, font_step=1, 2 prefer_horizontal=0.9).generate(weather_data) # 根据天气数据生成词云 3 plt.figure(figsize=(10, 5)) 4 plt.imshow(wordcloud, interpolation='bilinear') # 显示词云图像 5 plt.axis('off') 6 plt.show() 7 8 if __name__ == '__main__': 9 main()
4.数据持久化
import sqlite3 def create_weather_table(): conn = sqlite3.connect('weather.db') # 连接到数据库文件 cursor = conn.cursor() # 创建天气表格 cursor.execute('''CREATE TABLE IF NOT EXISTS weather ( date_time TEXT, high TEXT, low TEXT, weather TEXT )''') # 创建天气表格,如果不存在则创建 conn.commit() # 提交更改到数据库 conn.close() # 关闭数据库连接 def insert_weather_data(weather_data): conn = sqlite3.connect('weather.db') # 连接到数据库文件 cursor = conn.cursor() # 插入天气数据 for month_weather in weather_data: for day_weather_dict in month_weather: date_time = day_weather_dict['date_time'] # 获取日期时间 high = day_weather_dict['high'] # 获取最高温度 low = day_weather_dict['low'] # 获取最低温度 weather = day_weather_dict['weather'] # 获取天气情况 cursor.execute("INSERT INTO weather VALUES (?, ?, ?, ?)", (date_time, high, low, weather)) # 插入数据到天气表格 conn.commit() # 提交更改到数据库 conn.close() # 关闭数据库连接 def main(): create_weather_table() # 创建天气表格 weathers = [] # 存储所有月份的天气信息的列表 for month in range(1, 13): weather_time = '2022' + ('0' + str(month) if month < 10 else str(month)) print(weather_time) url = f'https://lishi.tianqi.com/quanzhou/{weather_time}.html' weather = getWeather(url) # 获取天气信息 weathers.append(weather) print(weathers) insert_weather_data(weathers) if __name__ == '__main__': main()
然后数据便以库文件的方式存入电脑中

5.数据可视化
所用到的库
1 import pandas as pd 2 from pyecharts import options as opts 3 from pyecharts.charts import Pie, Bar, Timeline, Line, Scatter
因为绘制的图形是动态的天气轮播图,而此时我们日期的数据类型为字符串,要将类型改为datetime

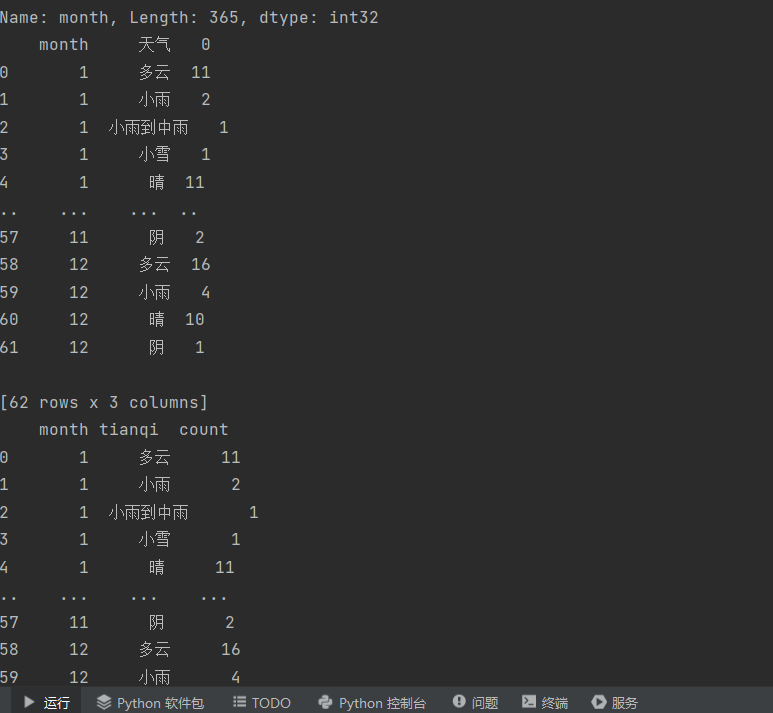
1 df_agg = df.groupby(['month','天气']).size().reset_index() 2 print(df_agg)

对每列数据进行一个命名
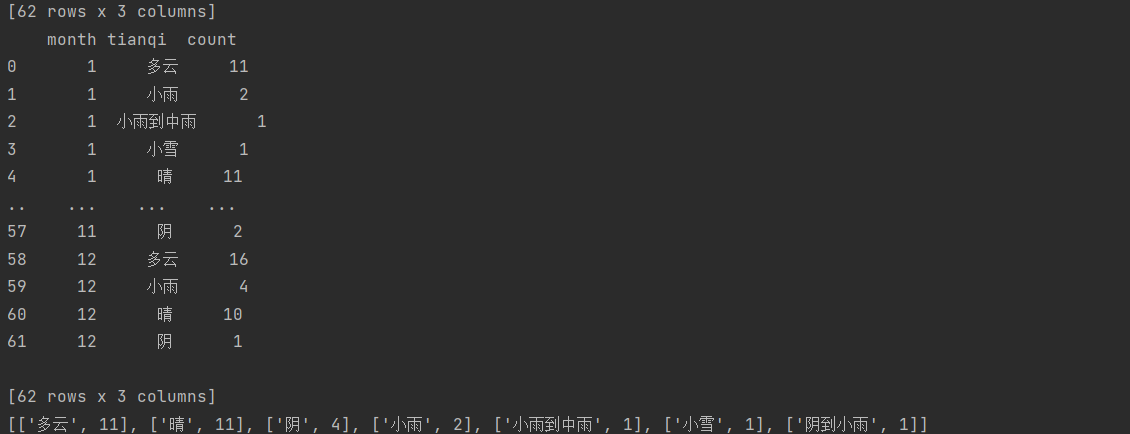
df_agg.columns = ['month','tianqi','count'] print(df_agg)
将数据转化为列表数据
1 print(df_agg[df_agg['month']==1][['tianqi','count']]\ 2 .sort_values(by='count',ascending=False).values.tolist())
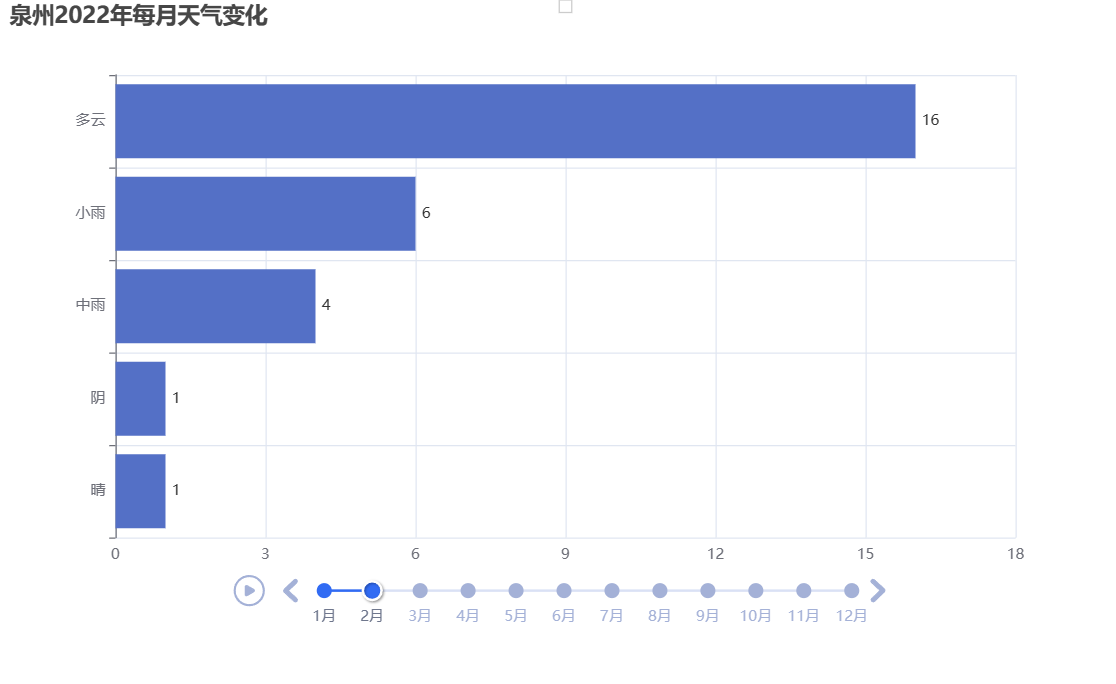
将处理好的数据传入图表中,绘制横放柱状轮播图
1 # 画图 2 # 实例化一个时间序列的对象 3 timeline = Timeline() 4 # 播放参数:设置时间间隔 1s 单位是:ms(毫秒) 5 timeline.add_schema(play_interval=1000) # 单位是:ms(毫秒) 6 7 # 循环遍历df_agg['month']里的唯一值 8 for month in df_agg['month'].unique(): 9 data = ( 10 11 df_agg[df_agg['month']==month][['tianqi','count']] 12 .sort_values(by='count',ascending=True) 13 .values.tolist() 14 ) 15 # print(data) 16 # 绘制柱状图 17 bar = Bar() 18 # x轴是天气名称 19 bar.add_xaxis([x[0] for x in data]) 20 # y轴是出现次数 21 bar.add_yaxis('',[x[1] for x in data]) 22 23 # 让柱状图横着放 24 bar.reversal_axis() 25 # 将计数标签放置在图形右边 26 bar.set_series_opts(label_opts=opts.LabelOpts(position='right')) 27 # 设置下图表的名称 28 bar.set_global_opts(title_opts=opts.TitleOpts(title='泉州2022年每月天气变化 ')) 29 # 将设置好的bar对象放置到时间轮播图当中,并且标签选择月份 格式为: 数字月 30 timeline.add(bar, f'{month}月') 31 32 # 将设置好的图表保存为'weathers.html'文件 33 timeline.render('weathers1.html')
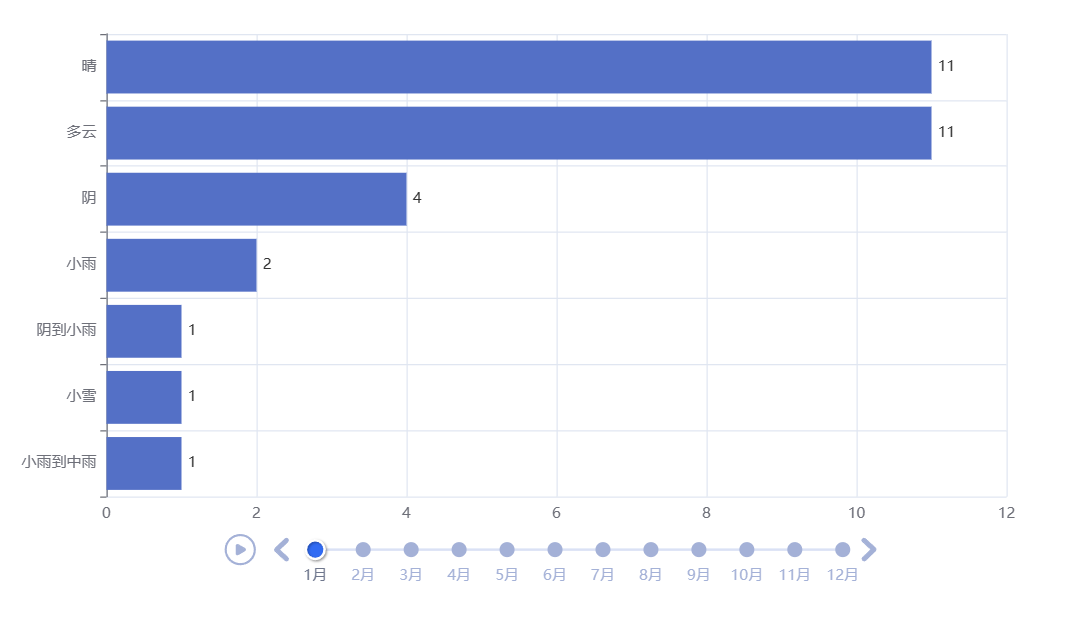 #由于视频上传不了,所以只放了两个月份的天气数据图片
#由于视频上传不了,所以只放了两个月份的天气数据图片
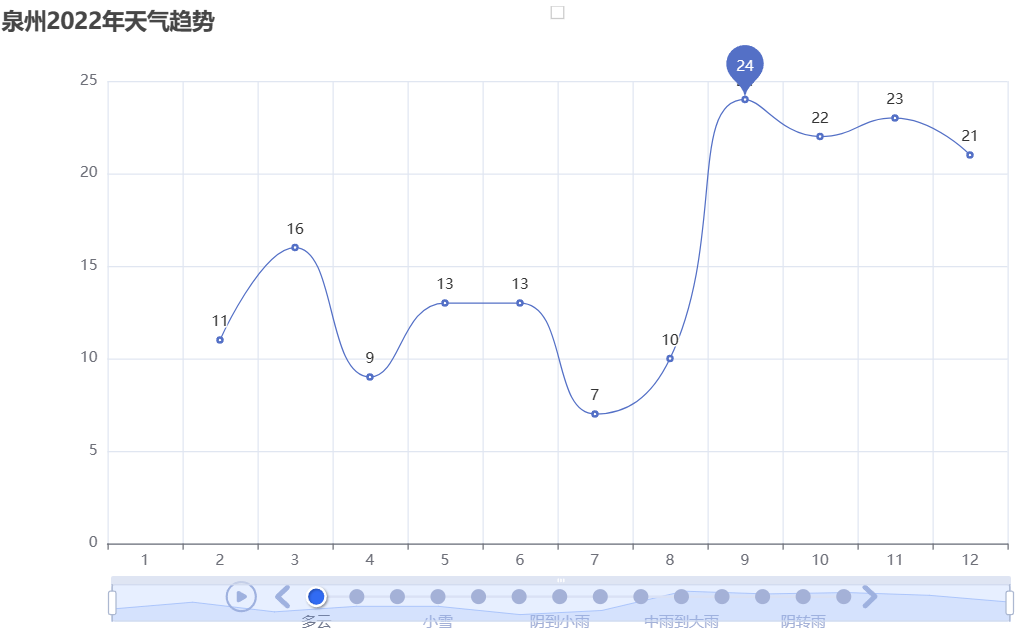
绘制折线图
1 # 画图 2 # 实例化一个时间序列的对象 3 timeline = Timeline() 4 # 播放参数:设置时间间隔 1s 单位是:ms(毫秒) 5 timeline.add_schema(play_interval=1000) # 单位是:ms(毫秒) 6 7 # 循环遍历df_agg['tianqi']里的唯一值(天气类型) 8 for tianqi in df_agg['tianqi'].unique(): 9 data = ( 10 df_agg[df_agg['tianqi'] == tianqi][['month', 'count']] 11 .sort_values(by='month', ascending=True) 12 .values.tolist() 13 ) 14 # print(data) 15 # 绘制折线图 16 line = Line() 17 # x轴是月份 18 line.add_xaxis([x[0] for x in data]) 19 # y轴是出现次数 20 line.add_yaxis(tianqi, [x[1] for x in data], is_smooth=True) 21 22 # 设置图线平滑曲线 23 line.set_series_opts( 24 markpoint_opts=opts.MarkPointOpts( 25 data=[opts.MarkPointItem(type_="max", name="最大值")] 26 ) 27 ) 28 29 # 设置下图表的名称 30 line.set_global_opts( 31 title_opts=opts.TitleOpts(title='泉州2022年天气趋势'), 32 datazoom_opts=opts.DataZoomOpts(type_="slider", range_start=0, range_end=100), 33 ) 34 35 # 将设置好的line对象放置到时间轮播图中,并且标签选择天气类型 36 timeline.add(line, tianqi) 37 38 # 将设置好的时间轮播图渲染为HTML文件 39 timeline.render("weather_trend.html")
绘制散点图
1 # 画图 2 # 实例化一个散点图对象 3 scatter = Scatter() 4 # 播放参数:设置时间间隔 1s 单位是:ms(毫秒) 5 timeline.add_schema(play_interval=1000) # 单位是:ms(毫秒) 6 7 # 循环遍历df_agg['month']里的唯一值 8 for month in df_agg['month'].unique(): 9 data = ( 10 df_agg[df_agg['month']==month][['tianqi','count']] 11 .sort_values(by='count',ascending=True) 12 .values.tolist() 13 ) 14 # 绘制散点图 15 scatter = Scatter() 16 # x轴是天气名称 17 scatter.add_xaxis([x[0] for x in data]) 18 # y轴是出现次数 19 scatter.add_yaxis('',[x[1] for x in data]) 20 21 # 设置下图表的名称 22 scatter.set_global_opts(title_opts=opts.TitleOpts(title=f'{month}月天气散点图')) 23 24 # 将设置好的scatter对象放置到时间轮播图当中,并且标签选择月份 格式为: 数字月 25 timeline.add(scatter, f'{month}月') 26 27 # 将设置好的时间轮播图渲染为html文件 28 timeline.render('scatter_timeline.html')
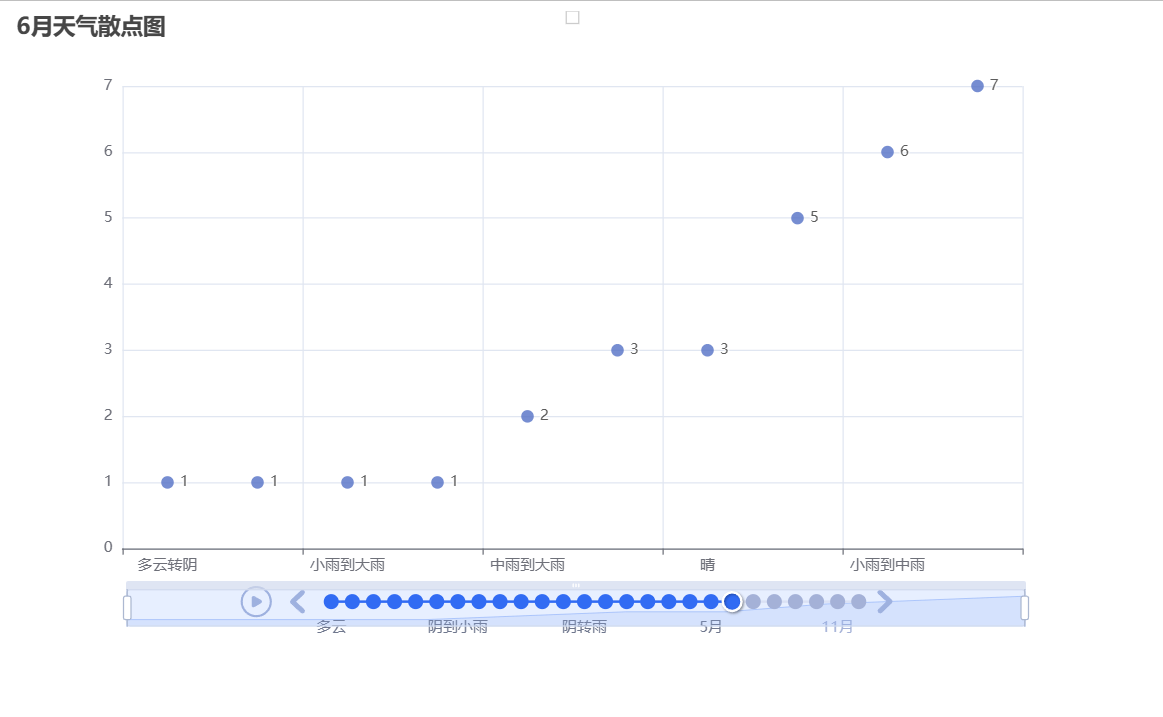
根据以上几个可视化图形可知
泉州市的降雨集中在5月至9月期间,而晴天比较多的月份是10月至来年3月。
6.将以上各部分的代码汇总,附上完整程序代码
(1)数据爬取与清洗,以及持久化部分
1 #-*- coding: utf-8 -*- 2 import requests # 模拟浏览器进行网络请求 3 from lxml import etree # 进行数据预处理 4 import csv # 写入csv文件 5 import sqlite3 6 def getWeather(url): 7 weather_info = [] # 新建一个列表,将爬取的每月数据放进去 8 # 请求头信息:浏览器版本型号,接收数据的编码格式 9 headers = { 10 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1' 11 } 12 # 请求 接收到了响应数据 13 resp = requests.get(url, headers=headers) 14 # 数据预处理s 15 resp_html = etree.HTML(resp.text) 16 # xpath提取所有数据 17 resp_list = resp_html.xpath("//ul[@class='thrui']/li") 18 # for循环迭代遍历 19 for li in resp_list: 20 day_weather_info = {} 21 # 日期 22 day_weather_info['date_time'] = li.xpath("./div[1]/text()")[0].split(' ')[0] 23 # 最高气温 (包含摄氏度符号) 24 high = li.xpath("./div[2]/text()")[0] 25 day_weather_info['high'] = high[:high.find('℃')] 26 # 最低气温 27 low = li.xpath("./div[3]/text()")[0] 28 day_weather_info['low'] = low[:low.find('℃')] 29 # 天气 30 day_weather_info['weather'] = li.xpath("./div[4]/text()")[0] 31 weather_info.append(day_weather_info) 32 return weather_info 33 34 weathers = [] 35 36 # for循环生成有顺序的1-12 37 for month in range(1, 13): 38 # 获取某一月的天气信息 39 # 三元表达式 40 weather_time = '2022' + ('0' + str(month) if month < 10 else str(month)) 41 print(weather_time) 42 url = f'https://lishi.tianqi.com/quanzhou/{weather_time}.html' 43 # 爬虫获取这个月的天气信息 44 weather = getWeather(url) 45 # 存到列表中 46 weathers.append(weather) 47 print(weathers) 48 49 50 # 数据写入(一次性写入) 51 with open("weather.csv", "w",newline='') as csvfile: 52 writer = csv.writer(csvfile) 53 # 先写入列名:columns_name 日期 最高气温 最低气温 天气 54 writer.writerow(["日期", "最高气温", "最低气温", '天气']) 55 # 一次写入多行用writerows(写入的数据类型是列表,一个列表对应一行) 56 writer.writerows([list(day_weather_dict.values()) for month_weather in weathers for day_weather_dict in month_weather]) 57 58 59 import sqlite3 60 61 62 def create_weather_table(): 63 conn = sqlite3.connect('weather.db') # 连接到数据库文件 64 cursor = conn.cursor() 65 66 # 创建天气表格 67 cursor.execute('''CREATE TABLE IF NOT EXISTS weather ( 68 date_time TEXT, 69 high TEXT, 70 low TEXT, 71 weather TEXT 72 )''') # 创建天气表格,如果不存在则创建 73 74 conn.commit() # 提交更改到数据库 75 conn.close() # 关闭数据库连接 76 77 78 def insert_weather_data(weather_data): 79 conn = sqlite3.connect('weather.db') # 连接到数据库文件 80 cursor = conn.cursor() 81 82 # 插入天气数据 83 for month_weather in weather_data: 84 for day_weather_dict in month_weather: 85 date_time = day_weather_dict['date_time'] # 获取日期时间 86 high = day_weather_dict['high'] # 获取最高温度 87 low = day_weather_dict['low'] # 获取最低温度 88 weather = day_weather_dict['weather'] # 获取天气情况 89 90 cursor.execute("INSERT INTO weather VALUES (?, ?, ?, ?)", (date_time, high, low, weather)) # 插入数据到天气表格 91 92 conn.commit() # 提交更改到数据库 93 conn.close() # 关闭数据库连接 94 95 96 def main(): 97 create_weather_table() # 创建天气表格 98 99 weathers = [] # 存储所有月份的天气信息的列表 100 for month in range(1, 13): 101 weather_time = '2022' + ('0' + str(month) if month < 10 else str(month)) 102 print(weather_time) 103 url = f'https://lishi.tianqi.com/quanzhou/{weather_time}.html' 104 weather = getWeather(url) # 获取天气信息 105 106 107 weathers.append(weather) 108 print(weathers) 109 110 insert_weather_data(weathers) 111 112 if __name__ == '__main__': 113 main()
(2)数据可视化部分
1 #-*- coding: utf-8 -*- 2 3 # 数据分析 读取 处理 存储 4 import pandas as pd 5 from pyecharts import options as opts 6 from pyecharts.charts import Pie, Bar, Timeline, Line, Scatter 7 8 # 用pandas.read_csv()读取指定的excel文件,选择编码格式gb18030(gb18030范围比) 9 df = pd.read_csv('weather.csv',encoding='gb18030') 10 print(df['日期']) 11 12 # 将日期格式的数据类型改为month 13 df['日期'] = df['日期'].apply(lambda x: pd.to_datetime(x)) 14 print(df['日期']) 15 16 17 # 新建一列月份数据(将日期中的月份month 一项单独拿取出来) 18 df['month'] = df['日期'].dt.month 19 20 print(df['month']) 21 # 需要的数据 每个月中每种天气出现的次数 22 23 # DataFrame GroupBy聚合对象 分组和统计的 size()能够计算分组的大小 24 df_agg = df.groupby(['month','天气']).size().reset_index() 25 print(df_agg) 26 27 # 设置下这3列的列名 28 df_agg.columns = ['month','tianqi','count'] 29 print(df_agg) 30 31 # 转化为列表数据 32 print(df_agg[df_agg['month']==1][['tianqi','count']]\ 33 .sort_values(by='count',ascending=False).values.tolist()) 34 """ 35 [['阴', 20], ['多云', 5], ['雨夹雪', 4], ['晴', 2]] 36 """ 37 38 # 画图 39 # 实例化一个时间序列的对象 40 timeline = Timeline() 41 # 播放参数:设置时间间隔 1s 单位是:ms(毫秒) 42 timeline.add_schema(play_interval=1000) # 单位是:ms(毫秒) 43 44 # 循环遍历df_agg['month']里的唯一值 45 for month in df_agg['month'].unique(): 46 data = ( 47 48 df_agg[df_agg['month']==month][['tianqi','count']] 49 .sort_values(by='count',ascending=True) 50 .values.tolist() 51 ) 52 # print(data) 53 # 绘制柱状图 54 bar = Bar() 55 # x轴是天气名称 56 bar.add_xaxis([x[0] for x in data]) 57 # y轴是出现次数 58 bar.add_yaxis('',[x[1] for x in data]) 59 60 # 让柱状图横着放 61 bar.reversal_axis() 62 # 将计数标签放置在图形右边 63 bar.set_series_opts(label_opts=opts.LabelOpts(position='right')) 64 # 设置下图表的名称 65 bar.set_global_opts(title_opts=opts.TitleOpts(title='泉州2022年每月天气变化 ')) 66 # 将设置好的bar对象放置到时间轮播图当中,并且标签选择月份 格式为: 数字月 67 timeline.add(bar, f'{month}月') 68 69 # 将设置好的图表保存为'weathers.html'文件 70 timeline.render('weathers1.html') 71 72 73 # 画图 74 # 实例化一个时间序列的对象 75 timeline = Timeline() 76 # 播放参数:设置时间间隔 1s 单位是:ms(毫秒) 77 timeline.add_schema(play_interval=1000) # 单位是:ms(毫秒) 78 79 # 循环遍历df_agg['tianqi']里的唯一值(天气类型) 80 for tianqi in df_agg['tianqi'].unique(): 81 data = ( 82 df_agg[df_agg['tianqi'] == tianqi][['month', 'count']] 83 .sort_values(by='month', ascending=True) 84 .values.tolist() 85 ) 86 # print(data) 87 # 绘制折线图 88 line = Line() 89 # x轴是月份 90 line.add_xaxis([x[0] for x in data]) 91 # y轴是出现次数 92 line.add_yaxis(tianqi, [x[1] for x in data], is_smooth=True) 93 94 # 设置图线平滑曲线 95 line.set_series_opts( 96 markpoint_opts=opts.MarkPointOpts( 97 data=[opts.MarkPointItem(type_="max", name="最大值")] 98 ) 99 ) 100 101 # 设置下图表的名称 102 line.set_global_opts( 103 title_opts=opts.TitleOpts(title='泉州2022年天气趋势'), 104 datazoom_opts=opts.DataZoomOpts(type_="slider", range_start=0, range_end=100), 105 ) 106 107 # 将设置好的line对象放置到时间轮播图中,并且标签选择天气类型 108 timeline.add(line, tianqi) 109 110 # 将设置好的时间轮播图渲染为HTML文件 111 timeline.render("weather_trend.html") 112 113 # 画图 114 # 实例化一个散点图对象 115 scatter = Scatter() 116 # 播放参数:设置时间间隔 1s 单位是:ms(毫秒) 117 timeline.add_schema(play_interval=1000) # 单位是:ms(毫秒) 118 119 # 循环遍历df_agg['month']里的唯一值 120 for month in df_agg['month'].unique(): 121 data = ( 122 df_agg[df_agg['month']==month][['tianqi','count']] 123 .sort_values(by='count',ascending=True) 124 .values.tolist() 125 ) 126 # 绘制散点图 127 scatter = Scatter() 128 # x轴是天气名称 129 scatter.add_xaxis([x[0] for x in data]) 130 # y轴是出现次数 131 scatter.add_yaxis('',[x[1] for x in data]) 132 133 # 设置下图表的名称 134 scatter.set_global_opts(title_opts=opts.TitleOpts(title=f'{month}月天气散点图')) 135 136 # 将设置好的scatter对象放置到时间轮播图当中,并且标签选择月份 格式为: 数字月 137 timeline.add(scatter, f'{month}月') 138 139 # 将设置好的时间轮播图渲染为html文件 140 timeline.render('scatter_timeline.html') 141 import numpy as np 142 from sklearn.linear_model import LinearRegression
(3)wordcloud分词可视化,词云部分
1 1 # -*- coding: utf-8 -*- 2 2 3 3 # 导入必要的库 4 4 import requests 5 5 from lxml import etree 6 6 import csv 7 7 from wordcloud import WordCloud 8 8 import matplotlib.pyplot as plt 9 9 10 10 # 从URL获取天气信息的函数s 11 11 def getWeather(url): 12 12 weather_info = [] # 存储天气信息的列表 13 13 headers = { 14 14 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1' 15 15 } 16 16 resp = requests.get(url, headers=headers) # 发送GET请求到指定的URL 17 17 resp_html = etree.HTML(resp.text) # 解析响应的HTML 18 18 resp_list = resp_html.xpath("//ul[@class='thrui']/li") # 使用XPath选择器提取天气信息列表 19 19 for li in resp_list: 20 20 day_weather_info = {} # 存储每天天气信息的字典 21 21 day_weather_info['date_time'] = li.xpath("./div[1]/text()")[0].split(' ')[0] # 提取日期时间并存入字典 22 22 high = li.xpath("./div[2]/text()")[0] # 提取最高温度 23 23 day_weather_info['high'] = high[:high.find('℃')] # 去除温度单位并存入字典 24 24 low = li.xpath("./div[3]/text()")[0] # 提取最低温度 25 25 day_weather_info['low'] = low[:low.find('℃')] # 去除温度单位并存入字典 26 26 day_weather_info['weather'] = li.xpath("./div[4]/text()")[0] # 提取天气情况并存入字典 27 27 weather_info.append(day_weather_info) # 将每天天气信息字典添加到天气信息列表中 28 28 return weather_info 29 29 def main(): 30 30 weathers = [] # 存储所有月份的天气信息的列表 31 31 for month in range(1, 13): 32 32 weather_time = '2022' + ('0' + str(month) if month < 10 else str(month)) 33 33 print(weather_time) 34 34 url = f'https://lishi.tianqi.com/quanzhou/{weather_time}.html' 35 35 weather = getWeather(url) 36 36 weathers.append(weather) # 将每个月份的天气信息添加到weathers列表中 37 37 print(weathers) 38 38 39 39 weather_data = "" # 存储所有天气情况的字符串 40 40 for month_weather in weathers: 41 41 for day_weather_dict in month_weather: 42 42 weather = day_weather_dict['weather'] # 提取天气情况 43 43 weather_data += weather + " " # 将天气情况添加到weather_data字符串中,用空格分隔 44 44 45 45 wordcloud = WordCloud(font_path='C:\Windows\Fonts\微软雅黑\msyh.ttc', width=800, height=400, font_step=1, 46 46 prefer_horizontal=0.9).generate(weather_data) # 根据天气数据生成词云 47 47 plt.figure(figsize=(10, 5)) 48 48 plt.imshow(wordcloud, interpolation='bilinear') # 显示词云图像 49 49 plt.axis('off') 50 50 plt.show() 51 51 52 52 if __name__ == '__main__': 53 53 main()
五、总结
爬取泉州2022年天气数据经过数据处理和可视化分析后的结果,我对于数据采集,数据清洗,数据可视化的方法以及步骤更加的熟练。以下是我对其的总结。
- 数据采集
数据采集:数据采集是整个过程的第一步。在进行数据采集前,需要确定采集的目标、采集的数据类型、采集的源站点等信息。确定好这些信息后,就可以开始编写爬虫程序了。使用Python爬虫需要掌握一定的网络知识和编程技巧,同时也需要了解如何处理HTTP请求和响应。
- 数据清洗
采集到数据后,需要进行数据清洗。数据清洗包括去除噪声数据、填充缺失值、转换数据类型等步骤。数据清洗是保证数据质量的重要环节,也是后续分析的基础。
- 数据可视化
经过清洗后的数据可以进行可视化分析。在进行数据可视化前,需要先选择合适的可视化工具,例如Matplotlib、Seaborn、Plotly等。数据可视化的目标是将数据以图形的方式呈现出来,帮助人们更容易地理解数据背后的含义和关系。在进行数据可视化时,不同的图形类型适合不同的数据类型和分析目标,需要根据具体情况进行选择。
在完成此设计中,完成数据可视化中的轮播图是我对于此次设计比较满意的一个部分,但是整体代码不够简介,完成的速度太慢,效率较低。整体来说基本达到心中的预期。
对自身的建议:
- 选择合适的采集工具和技术
选择合适的采集工具和技术可以提高数据采集的效率和质量。需要根据目标网站的结构、数据类型等信息来选择采集工具和技术。常用的采集工具包括Scrapy、BeautifulSoup、Selenium等,需要熟悉它们的使用方法和注意事项。
- 进行有效的数据清洗
在进行数据清洗时,需要注意数据类型转换、缺失值填充、异常值处理等问题,以确保数据的准确性和完整性。同时,应该考虑使用自动化的方法和工具,例如Pandas库、NumPy库等。
- 选择合适的可视化工具和技术
选择合适的可视化工具和技术可以提高数据可视化的效果和吸引力。需要根据数据类型、分析目的等信息来选择可视化工具和技术。常用的可视化工具包括Matplotlib、Seaborn、Plotly等,需要熟悉它们的使用方法和注意事项。
- 常态化数据采集、清洗和可视化
对于需要长期采集、清洗和可视化的数据,建议实现常态化的数据采集、清洗和可视化。这可以通过自动化脚本和任务计划来实现,以减少人工干预和提高效率。
- 不断学习和改进
数据采集和可视化是一项技术密集型的工作,需要不断学习和改进。之后要定期了解最新的数据采集和可视化技术,同时也要关注相关领域的研究成果和最佳实践,以提高自己的技能水平和工作质量。
总之,使用Python爬虫完成对数据的采集和可视化分析是一项非常有用的技术,需要掌握一定的技术和方法,并不断进行改进和优化。