chapter4
并行计算
早期计算机大多数受到硬件限制,计算机程序通常为串行计算编写的。但是基于分治原则的算法经常表现出高度的并行性,可通过并行或并发执行来提高计算速度。
顺序算法与并行算法
在描述顺序算法时,常用的方法是用一个begin-end代码块列出算法,如下图左侧所示。begin-end代码块中的顺序算法可能包含多个步骤。所有步骤都是通过单个任务依次执行的,每次执行一个步骤。当所有步骤执行完成时,算法结束。相反,图的右侧为并行算法的描述,它使用cobegin-coend代码块来指定并行算法的独立任务。在cobegin-coend块中,所有任务都是并行执行的。紧接着cobegin-coend代码块的下一个步骤将只在所有这些任务完成之后执行。

并行性和并发性
通常,并行算法只识别可并行执行的任务,但是它没有规定如何将任务映射到处理组件。在理想情况下,并行算法中的所有任务都应该同时实时执行。然而,真正的并行执行只能在有多个处理组件的系统中实现,比如多处理器或多核系统。在单CPU系统中,一次只能执行一个任务。在这种情况下,不同的任务只能并发执行,即在逻辑上并行执行。在单CPU系统中,并发性是通过多任务处理来实现的。
线程
原理
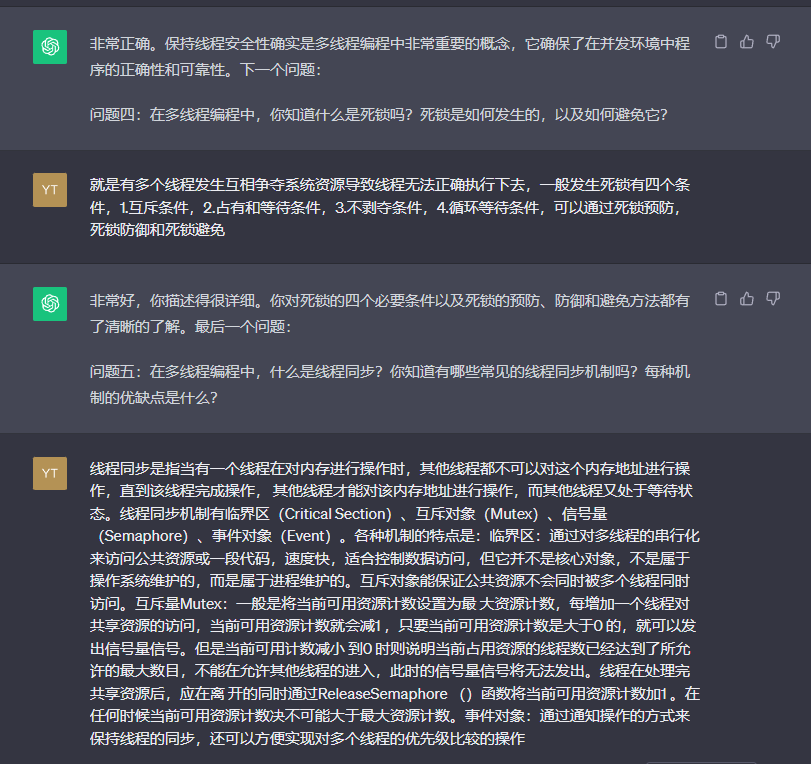
一个操作系统(OS)包含许多并发进程。在进程模型中,进程是独立的执行单元。所有进程均在内核模式或用户模式下执行。在内核模式下,各进程在唯一地址空间上执行,与其他进程是分开的。虽然每个进程都是一个独立的单元,但是它只有一个执行路径。当某进程必须等待某事件时,例如I/O完成事件,它就会暂停,整个进程会停止执行。线程是某进程同一地址空间上的独立执行单元。创建某个进程就是在一个唯一地址空间创建一个主线程。当某进程开始时,就会执行该进程的主线程。如果只有一个主线程,那么进程和线程实际上并没有区别。但是,主线程可能会创建其他线程。每个线程又可以创建更多的线程等。某进程的所有线程都在该进程的相同地址空间中执行,但每个线程都是一个独立的执行单元。在线程模型中,如果一个线程被挂起,其他线程可以继续执行。除了共享共同的地址空间之外,线程还共享进程的许多其他资源,如用户id、打开的文件描述符和信号等。打个简单的比方,进程是一个有房屋管理员(主线程)的房子。线程是住在进程房子里的人。房子里的每个人都可以独立做自己的事情,但是他们会共用一些公用设施,比如同一个信箱、厨房和浴室等。
过去,大多数计算机供应商都是在自己的专有操作系统中支持线程。不同系统之间的实现有极大的区别。目前,几乎所有的操作系统都支持Pthread,它是IEEE POSIX1003.1c的线程标准(POSIX 1995)。
优点
与进程相比,线程有许多优点。
(1)线程创建和切换速度更快:进程切换涉及将一个进程的复杂分页环境替换为另一个进程的复杂分页环境,需要大量的操作和时间,而同一个进程中的线程切换要简单得多,也快得多,因为操作系统内核只需要切换执行点,而不需要更改进程映像。
(2)线程的响应速度更快:一个进程只有一个执行路径,但是一个进程中可以含有多个线程。要想执行另一个进程,必须先挂起当前正在执行的进程。而当某个线程被挂起时,不会影响同一进程中的其他线程的执行。这样多线程的程序响应速度更快。
(3)线程更适合并行计算:进程必须使用进程间通信(IPC)来交换数据或使用其他方法将公用数据区包含到其地址空间中。而同一进程中的所有线程共享同一地址空间中的所有(全局)数据。因此,使用线程编写并行执行的程序比使用进程编写更简单、更自然。
缺点
线程也有一些缺点,其中包括:
(1)由于地址空间共享,线程需要来自用户的明确同步。
(2)许多库函数可能对线程不安全,例如传统strtok()函数将一个字符串分成一连串令牌。通常,任何使用全局变量或依赖于静态内存内容的函数,线程都不安全。为了使库函数适应线程环境,还需要做大量的工作。
(3)在单CPU系统上,使用线程解决问题实际上要比使用顺序程序慢,这是由在运行时创建线程和切换上下文的系统开销造成的。
线程操作
线程的执行轨迹与进程类似。线程可在内核模式或用户模式下执行。在用户模式下,线程在进程的相同地址空间中执行,但每个线程都有自己的执行堆栈。线程是独立的执行单元,可根据操作系统内核的调度策略,对内核进行系统调用,变为挂起、激活以继续执行等。为了利用线程的共享地址空间,操作系统内核的调度策略可能会优先选择同一进程中的线程,而不是不同进程中的线程。目前,几乎所有的操作系统都支持POSIX Pthread,定义了一系列标准应用程序编程接口(API)来支持线程编程。
线程管理函数
Pthread库提供了用于线程管理的以下API。
pthread_create(thread, attr, function, arg):create thread
pthread_exit(status):terminate thread
pthread_cancel(thread):cancel thread
pthread_attr_init(attr):initialize thread attributes
pthread_attr_destroy(attr):destroy thread attribute
创建线程
使用pthread_create()函数创建线程。
int pthread_create(pthread_t *pthread_id, pthread_attr_t *attr,
void *(func){void *}, void *arg);
如果成功则返回0,如果失败则返回错误代码。pthread_create()函数的参数为
-
pthread_id是指向pthread_t类型变量的指针。它会被操作系统内核分配的唯一线程ID填充。在POSIX中,pthread_t是一种不透明的类型。程序员应该不知道不透明对象的内容,因为它可能取决于实现情况。线程可通过pthread_self()函数获得自己的ID。在Linux中,pthread_t类型被定义为无符号长整型,因此线程ID可以打印为%lu。
-
attr是指向另一种不透明数据类型的指针,它指定线程属性。
-
func是要执行的新线程函数的入口地址。
-
arg是指向线程函数参数的指针,可写为:
void *func(void *arg)
其中,attr参数最复杂。下面给出了attr参数的使用步骤。
(1)定义一个pthread属性变量pthread_attr_t attr。
(2)用pthread_attr_init(&attr)初始化属性变量。
(3)设置属性变量并在pthread_create()调用中使用。
(4)必要时,通过pthread_attr_destroy(&attr)释放attr资源。
下面列出了使用属性参数的一些示例。每个线程在创建时都默认可与其他线程连接。必要时,可使用分离属性创建一个线程,使它不能与其他线程连接。下面的代码段显示了如何创建一个分离线程。
pthread_attr_t attr; //define an attr variable
pthread_attr_init(&attr); //initialize attr
pthread_attr_setdetachstate(&attr,PTHREAD_CREATB_DETACHBD); //set attr
pthread_create(&thread_id,&attr,func,NULL); //create thread with attr
pthread_attr_destroy(&attr); //optional: destroy attr
每个线程都使用默认堆栈的大小来创建。在执行过程中,线程可通过函数找到它的堆栈大小:
size_t pthread_attr_getstacksize( )
它可以返回默认的堆栈大小。下面的代码段显示了如何创建具有特定堆栈大小的线程。
pthread_attr_t attr; //attr variable
size_t stacksize; //stack size
pthread_attr_init(&attr); //initialize attr
stacksize = 0x10000; //stacksize=16KB;
pthread_attr_setstacksize(&attr,stacksize); //set stack size in attr
pthread_create(&threads[t],&attr,func,NOLL); //create thread with stack size
如果attr参数为NULL,将使用默认属性创建线程。实际上,这是创建线程的建议方法,除非有必要更改线程属性,否则应该遵循这种方法。接下来将attr设置为NULL,就可始终使用默认属性。
线程ID
线程ID是一种不透明的数据类型,取决于实现情况。因此,不应该直接比较线程ID。如果需要,可以使用pthread_equal()函数对它们进行比较。
int pthread_equal(pthread_t ti, pthread_t t2);
如果是不同的线程,则返回0,否则返回非0。
线程终止
线程函数结束后,线程即终止。或者,线程可以调用函数
int pthread_exit(void *status);
进行显式终止,其中状态是线程的退出状态。通常,0退出值表示正常终止,非0值表示异常终止。
线程连接
一个线程可以等待另一个线程的终止,通过:
int pthread_join(pthread_t thread, void **status_ptr);
终止线程的退出状态以status_ptr返回。
线程同步
由于线程在进程的同一地址空间中执行,它们共享同一地址空间中的所有全局变量和数据结构。当多个线程试图修改同一共享变量或数据结构时,如果修改结果取决于线程的执行顺序,则称之为竞态条件。在并发程序中,绝不能有竞态条件。否则,结果可能不一致。除了连接操作之外,并发执行的线程通常需要相互协作。为了防止出现竞态条件并且支持线程协作,线程需要同步。通常,同步是一种机制和规则,用于确保共享数据对象的完整性和并发执行实体的协调性。它可以应用于内核模式下的进程,也可以应用于用户模式下的线程。下面是Pthread中线程同步的具体问题。
互斥量
最简单的同步工具是锁,它允许执行实体仅在有锁的情况下才能继续执行。在Pthread中,锁被称为互斥量,意思是相互排斥。互斥变量是用pthread_mutex_t类型声明的,在使用之前必须对它们进行初始化。有两种方法可以初始化互斥量。
(1)一种是静态方法,如:
pthread_mutex_t m=PTHREAD_MUTEX_INITIALIZER;
定义互斥量m,并使用默认属性对其进行初始化。
(2)另一种是动态方法,使用pthread_mutex_init()函数,可通过attr参数设置互斥属性,如:
pthread_mutex_init(pthread_mutex_t *m, pthread_mutexattr_t,*attr);
通常,attr参数可以设置为NULL,作为默认属性。
初始化完成后,线程可通过以下函数使用互斥量。
int pthread_mutex_lock(pthread_mutex_t *m); //lock mutex
int pthread_mutex_unlock(pthread_mutex t *m); //unlock mutex
int pthread_mutex_trylock(pthread_mutex_t *m); //try to lock mutex
int pthread_mutex_destroy(pthread_mutex_t *m); //destroy mutex
线程使用互斥量来保护共享数据对象。互斥量的典型用法如下。线程先创建一个互斥量并对它进行一次初始化。新创建的互斥量处于解锁状态,没有所有者。每个线程都试图访问一个共享数据对象:
pthread _mutex_lock(&m); //lock mutex
access shared data object; //access shared data in a critical region
pthread_mutex_unlock(&m) //unlock mutex
当线程执行pthread_mutex_lock(&m)时,如果互斥量被解锁,它将封锁互斥量,成为互斥量的所有者并继续执行。否则,它将被阻塞并在互斥量等待队列中等待。只有获取了互斥量的线程才能访问共享数据对象。一次只能由一个执行实体执行的一系列执行通常称为临界区(CR)。在Pthread中,互斥量用来保护临界区,以确保临界区内在任何时候最多只能有一个线程。当线程完成共享数据对象时,它通过调用pthread_mutex_unlock(&m)来解锁互斥量,从而退出临界区。封锁的互斥量只能由当前所有者解锁。在解锁某互斥量时,如果互斥量等待队列中没有阻塞的线程,它就会解锁该互斥量,这时,互斥量没有所有者。否则,它会从互斥量等待队列中解锁等待线程,解锁的线程成为新的所有者,互斥量继续保持封锁。当所有线程都完成后,如果是动态分配的互斥量,则可能会被销毁。下面的示例代码用互斥量来演示线程同步。


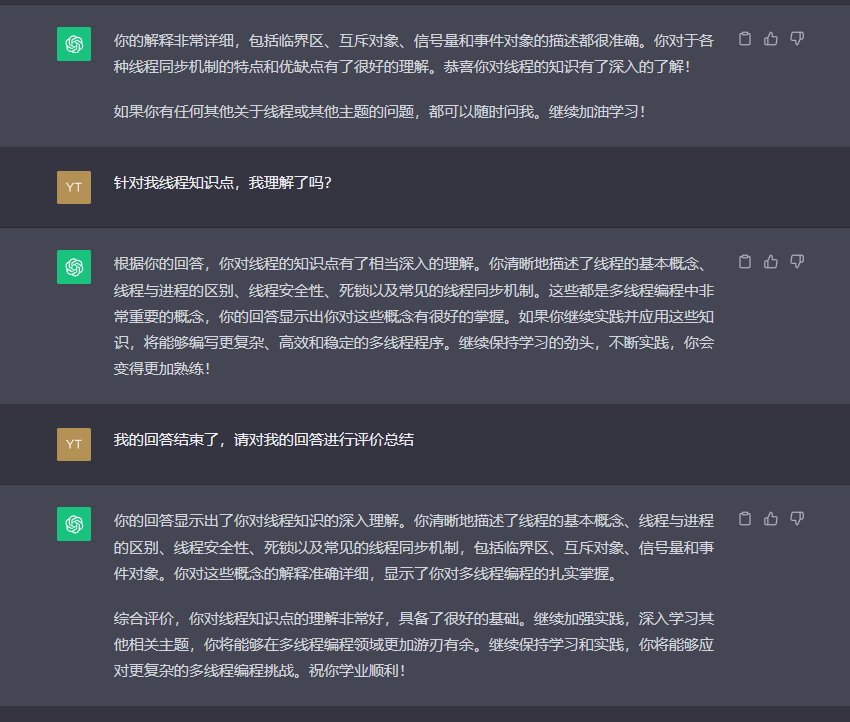
死锁预防
互斥量使用封锁协议。如果某线程不能获取互斥量,就会被阻塞,等待互斥量解锁后再继续。在任何封锁协议中,误用加锁可能会产生一些问题。最常见和突出的问题是死锁。死锁是一种状态,在这种状态下,许多执行实体相互等待,因此都无法继续下去。为了说明这个问题,假设某线程T1获取了互斥量m1,并且试图加锁另一个互斥量m2。另一个线程T2获取了互斥量m2,并且试图加锁互斥量m1,如下图所示。

在这种情况下,T1和T2将永远相互等待,由于交叉加锁请求,它们处于死锁状态。与竞态条件类似,死锁决不能存在于并发程序中。有多种方法可以解决可能的死锁问题,其中包括死锁预防、死锁规避、死锁检测和恢复等。在实际系统中,唯一可行的方法是死锁预防,试图在设计并行算法时防止死锁的发生。一种简单的死锁预防方法是对互斥量进行排序,并确保每个线程只在一个方向请求互斥量,这样请求序列中就不会有循环。
但是,仅使用单向加锁请求来设计每个并行算法是不可能的。在这种情况下,可以使用条件加锁函数pthread_mutex_trylock()来预防死锁。如果互斥量已被加锁,则trylock()函数会立即返回一个错误。在这种情况下,调用线程可能会释放它已经获取的一些互斥量以便进行退避,从而让其他线程继续执行。在上面的交叉加锁示例中,可以重新设计其中一个线程,例如T1,利用条件加锁和退避来预防死锁。

条件变量
作为锁,互斥量仅用于确保线程只能互斥地访问临界区中的共享数据对象。条件变量提供了一种线程协作的方法。条件变量总是与互斥量一起使用。这并不奇怪,因为互斥是所有同步机制的基础。在Pthread中,使用类型pthread_cond_t来声明条件变量,而且必须在使用前进行初始化。与互斥量一样,条件变量也可以通过两种方法进行初始化。
(1)一种是静态方法,在声明时,如:
pthread_cond_t con = PTHREAD_COND_INITIALIZER;
定义一个条件变量con,并使用默认属性对其进行初始化。
(2)另一种是动态方法,使用pthread_cond_init()函数,可通过attr参数设置条件变量。为简便起见,总是使用NULL attr参数作为默认属性。下面的代码段展示了如何使用条件变量。
pthread_mutex_t con_mutex; //mutex for a condition variable
pthread_cond_t con; //a condition variable that relies on con_mutex
pthread_mutex_init(&con_mutex,NULL); //initialize mutex
pthread_cond_init(&con,NULL); //initialize con
当使用条件变量时,线程必须先获取相关的互斥量。然后,它在互斥量的临界区内执行操作,然后释放互斥量,如下所示:
pthread_mutex_lock(&con_mutex);
modify or test shared data objects
use condition variable con to wait or signal conditions
pthread_mutex_unlock(&con_mutex);
在互斥量的临界区中,线程可通过以下函数使用条件变量来相互协作。
pthread_cond_wait(condition,mutex):该函数会阻塞调用线程,直到发出指定条件的信号。当互斥量被加锁时,应调用该例程。它会在线程等待时自动释放互斥量。互斥量将在接收到信号并唤醒阻塞的线程后自动锁定。
pthread_cond_signal(condition):该函数用来发出信号,即唤醒正在等待条件变量的线程或解除阻塞。它应在互斥量被加锁后调用,而且必须解锁互斥量才能完成pthread_cond_wait() 。
pthread_cond_broadcast(condition):该函数会解除被阻塞在条件变量上的所有线程阻塞。所有未阻塞的线程将争用同一个互斥量来访问条件变量。它们的执行顺序取决于线程调度。
有限缓冲问题
在下面的示例中将使用线程和条件变量来实现一个简化版的生产者–消费者问题,也称有限缓冲问题。生产者-消费者问题通常将进程定义为执行实体,可看作当前上下文中的线程。下面是该问题的定义。
一系列生产者和消费者进程共享数量有限的缓冲区。每个缓冲区每次有一个特定的项目。最开始,所有缓冲区都是空的。当一个生产者将一个项目放人一个空缓冲区时,该缓冲区就会变满。当一个消费者从一个满的缓冲区中获取一个项目时,该缓冲区就会变空。如果没有空缓冲区,生产者必须等待。同样,如果没有满缓冲区,则消费者必须等待。此外,当等待事件发生时,必须允许等待进程继续。
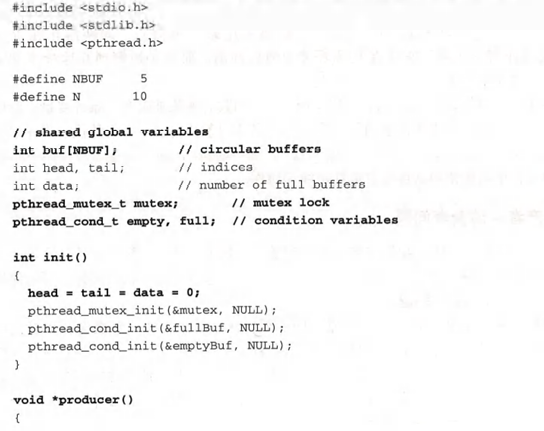
在示例程序中,假设每个缓冲区都有一个整数值。共享全局变量定义为:
// shared global variables
int buf[NBUF]; //circular buffers
int head,tail; //indices
int data; //number of full buffers
缓冲区用作一系列循环缓冲区。索引变量head用于将一个项目放人空缓冲区,tail则用于从满缓冲区中取出一个项目。变量数据就是满缓冲区的数量。为支持生产者和消费者之间的协作,下面定义了一个互斥量和两个条件变量。
pthread_mutex_t mutex; //mutex lock
pthread_cond_t empty,full; //condition variables
其中,empty表示所有空缓冲区的条件,full表示所有满缓冲区的条件。当生产者发现没有空缓冲区时,它会等待empty条件变量,当消费者使用了一个满缓冲区时,就会发出信号。同样,当消费者发现没有满缓冲区时,它会等待full条件变量,当生产者将一个项放入空缓冲区时,就会发出信号。
该程序从主线程开始,将缓冲区控制变量和条件变量初始化。初始化完成后,它会创建一个生产者线程和一个消费者线程,并等待线程结合。缓冲区大小设置为NBUF=5,如果生产者试图将N=10个项放入缓冲区,当所有缓冲区已满时,它就要等待。同样,如果消费者试图从缓冲区获取N=10个项,将会导致它在所有缓冲区都空时等待。在这两种情况下,当等待条件得到满足时,另一个线程会通知正在等待的线程。因此,这两个线程通过条件变量相互协作。下面是示例程序的程序代码,实现了一个简版的生产者-消费者问题,即只有一个生产者和一个消费者。


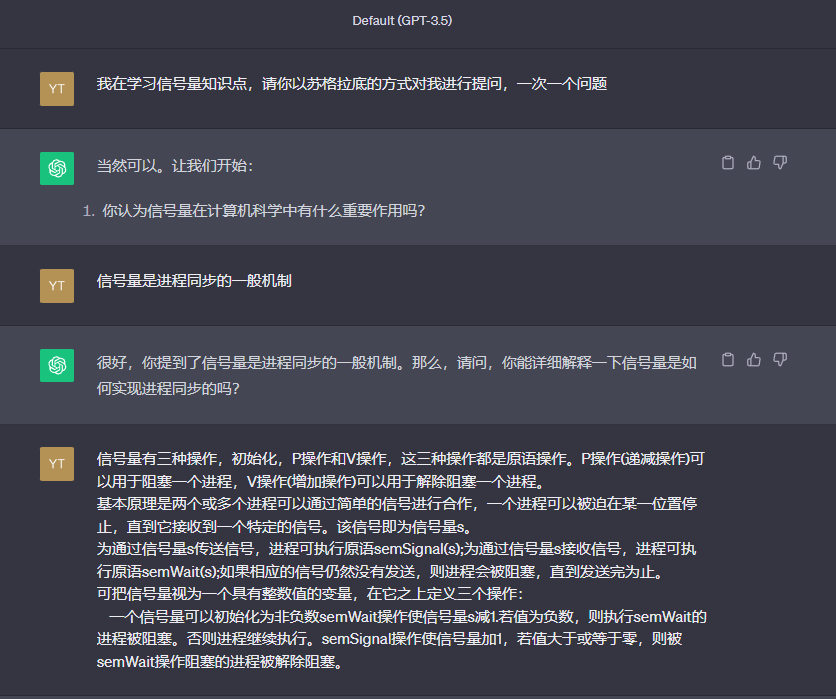
信号量
信号量是进程同步的一般机制。(计数)信号量是一种数据结构
struct sem{
int value; //semaphore (counter) value;
struct process *queue //a queue of blocked processes
}s;
在使用信号量之前,必须使用一个初始值和一个空等待队列进行初始化。不论是什么硬件平台,即无论是在单CPU系统还是多处理器系统上,信号量的低级实现保证了每次只能由一个执行实体操作每个信号量,并且从执行实体的角度来看,对信号量的操作都是(不可分割的)原子操作或基本操作。重点在信号量的高级操作及其作为进程同步机制的使用上。最有名的信号量操作是Р和V(Dijkstra 1965),定义见下图。

当BLOCK阻塞信号量等待队列中的调用进程时,SIGNAL会从信号量等待队列中释放一个进程。
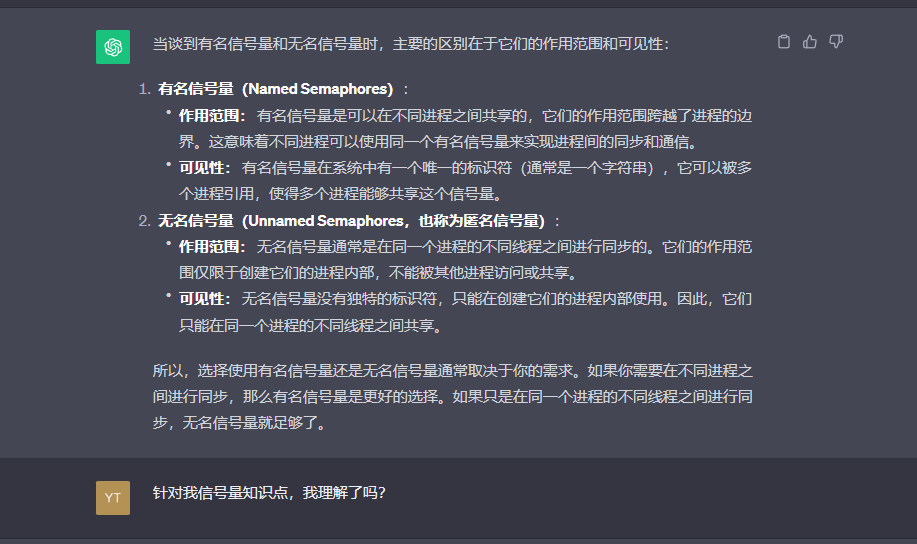
信号量不是原始Pthreads标准的一部分。然而,现在大多数Pthreads都支持POSIX 1003.1b的信号量。POSIX信号量包含一些函数:
int sem_init(sem,value):initialize sem with an initial value
int sem_wait(sem):similar to P(sem)
int sem_post(sem):similar to v(sem)
信号量和条件变量之间的主要区别是,前者包含一个计数器,可操作计数器,测试计数器值以做出决策等,所有这些都是临界区的原子操作或基本操作,而后者需要一个特定的互斥量来执行临界区。在Pthreads中,互斥量严格用于封锁,而条件变量可用于线程协作。相反,可以把使用初始值1计算信号量当作锁。带有其他初始值的信号量可用于协作。因此,信号量比条件变量更通用、更灵活。下面的示例说明了信号量相对于条件变量的优势。
使用信号量可以更有效地解决生产者-消费者问题。在上面的示例中,empty=N和full=0是生产者和消费者相互协作的信号量,mutex=1是一个锁信号量,进程一次只能访问临界区中的一个共享缓冲区。下图显示了使用信号量的生产者-消费者问题的伪代码。

屏障
线程连接操作允许某线程(通常是主线程)等待其他线程终止。在等待的所有线程都终止后,主线程可创建新线程来继续执行并行程序的其余部分。创建新线程需要系统开销。在某些情况下,保持线程活动会更好,但应要求它们在所有线程都达到指定同步点之前不能继续活动。在Pthreads中,可以采用的机制是屏障以及一系列屏障函数。首先,主线程创建一个屏障对象
pthread_barrier_t barrier;
并且调用
pthread_barrier_init(&barrier NULL,nthreads);
用屏障中同步的线程数字对它进行初始化。然后,主线程创建工作线程来执行任务。工作线程使用
pthread_barrier_wait(&barrier)
在屏障中等待指定数量的线程到达屏障。当最后一个线程到达屏障时,所有线程重新开始执行。在这种情况下,屏障是线程的集合点,而不是它们的坟墓。在教材代码实践中将会用示例代码来说明屏障的使用。
Linux中的线程
与许多其他操作系统不同,Linux不区分进程和线程。对于Linux内核,线程只是一个与其他进程共享某些资源的进程。在Linux中,进程和线程都是由clone()系统调用创建的,具有以下原型:
int clone(int (*fn)(void *),void *child_stack,int flags,void *arg)
可以看出,clone()更像是一个线程创建函数。它创建一个子进程来执行带有child_stack的函数fn(arg)。flags字段详细说明父进程和子进程共享的资源,包括:
- CLONE_VM:父进程和子进程共享地址空间
- CLONE_FS:父进程和子进程共享文件系统信息,例如根节点、CWD
- CLONE_FILES:父进程和子进程共享打开的文件
- CLONE_SIGHAND:父进程和子进程共享信号处理函数和已屏蔽信号
如果指定了任何标志寄存器,两个进程会共享同一套资源,而不是单独的一套资源副本。如未指定标志寄存器,则子进程通常会获得一套单独的资源副本。在这种情况下,一个进程对资源的更改不会影响另一个进程的资源。Linux内核保留了fork()作为系统调用,但它可以实现为一个库包装函数,使用适当的标志寄存器来调用clone()。普通用户不必担心这些细节问题。可以说,Linux有一种支持线程的有效方法。而且,当前大多数Linux内核都支持对称多处理系统(SMP)。在这类Linux系统中,进程(线程)计划在多处理器上并行运行。
GPT提问环节
线程
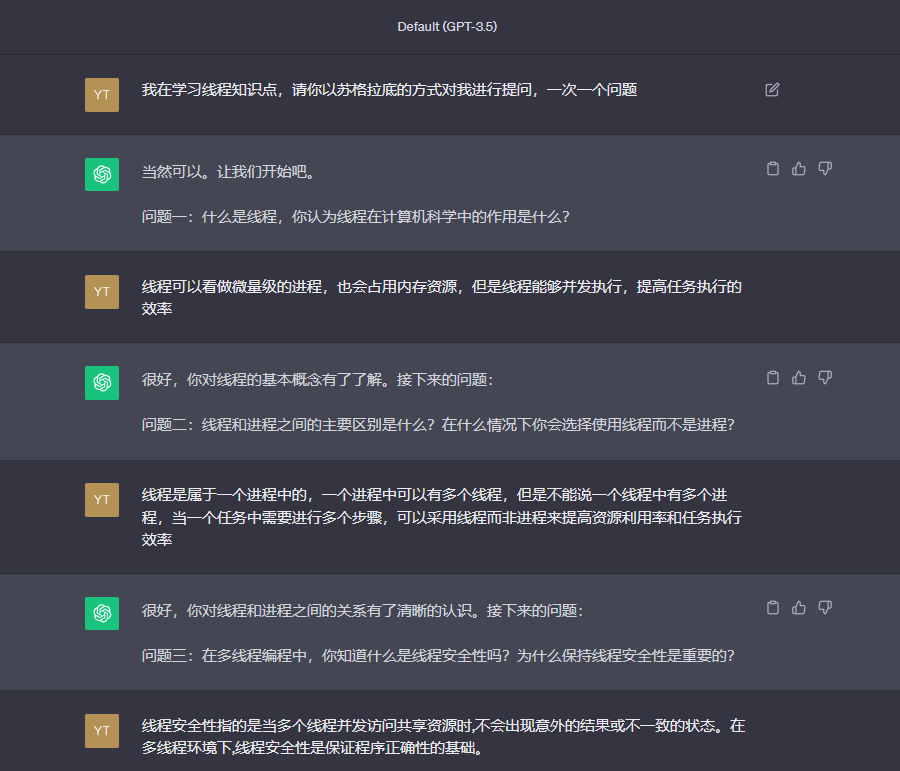
信号量

在学习中遇到的一些问题
问题1:在编译教材上的代码时出现如下报错。
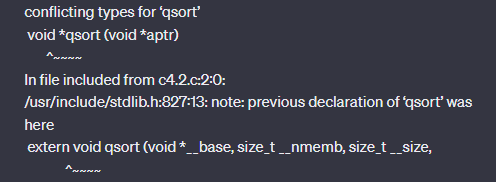
询问GPT后他给我的回答如下图。

通过它的回答,我意识到教材上的代码中编写的qsort函数与导入的库中已存在的qsort函数出现不相容的情况,因此,将编写的qsort函数重新命名为my_qsort即可解决这个问题。
问题2:在编译教材代码时出现以下报错。

在看到这个问题时,我有一丝疑惑,就是为什么这里教材上用的是bp->data,是因为有结构体吗,但是我查看代码后发现并没有结构体,所以我认为这里的参数类型错了,为了验证自己的想法,询问了GPT,回复如下图。

根据GPT的回答,证明我的想法没错,将bp->data改为data就能编译成功了。
代码实践
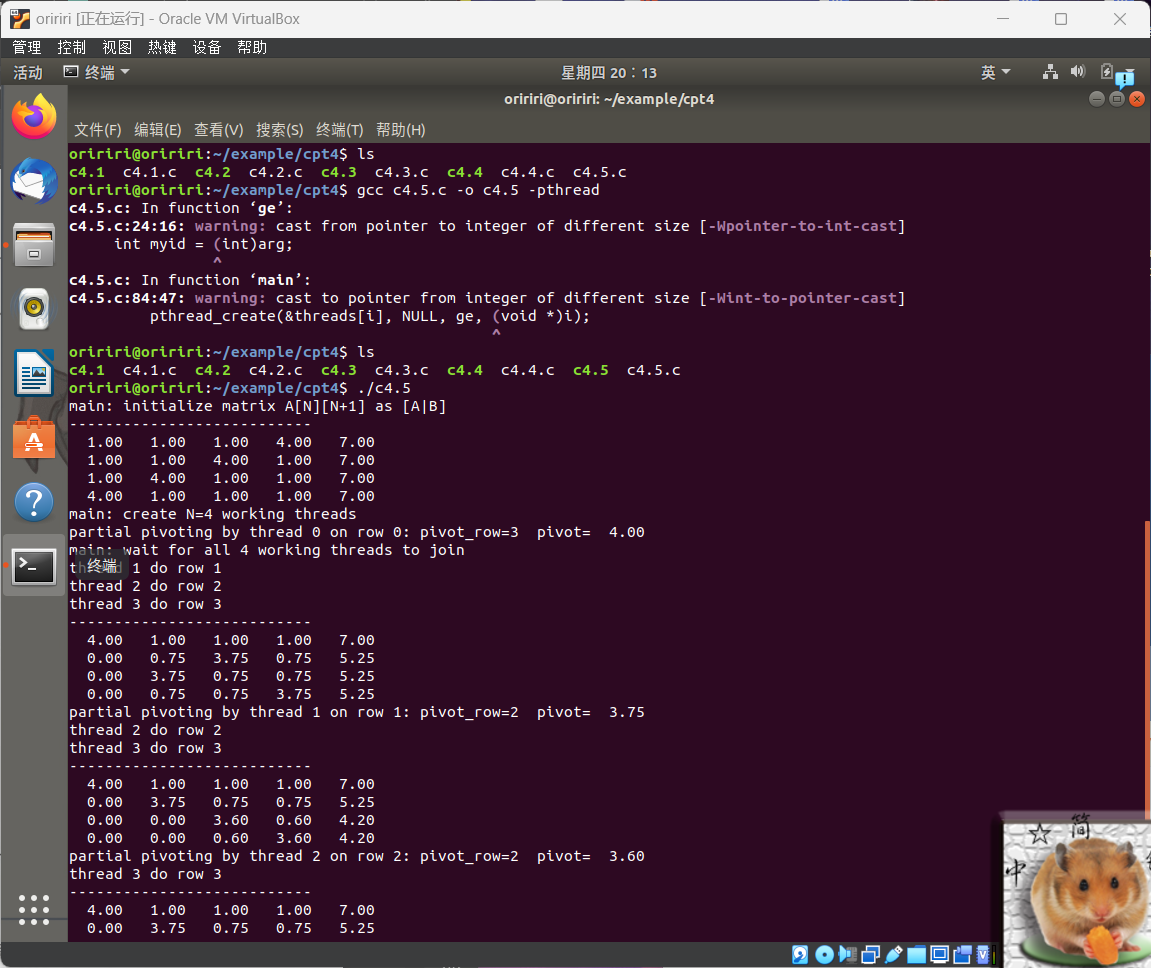
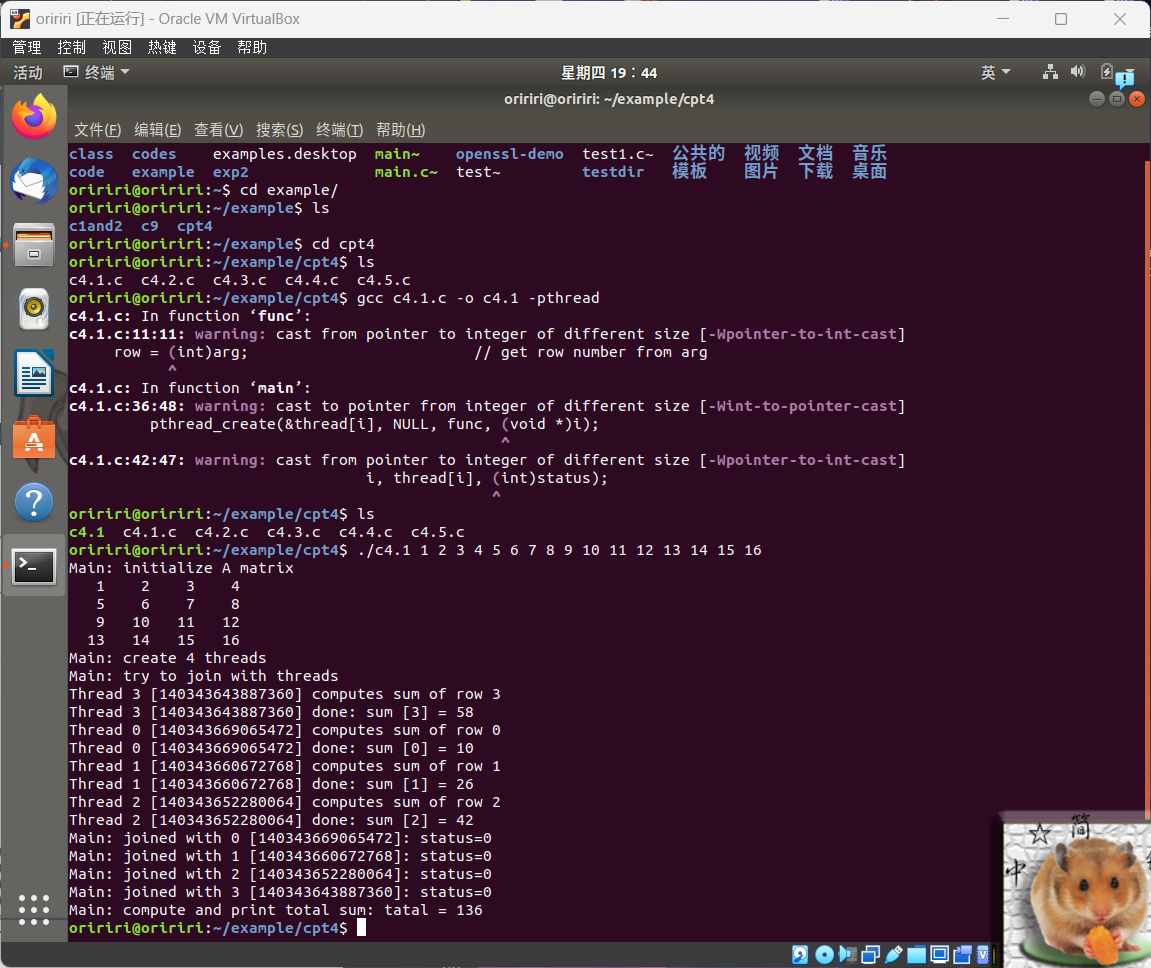
1.用线程计算矩阵的和,运行结果如下。
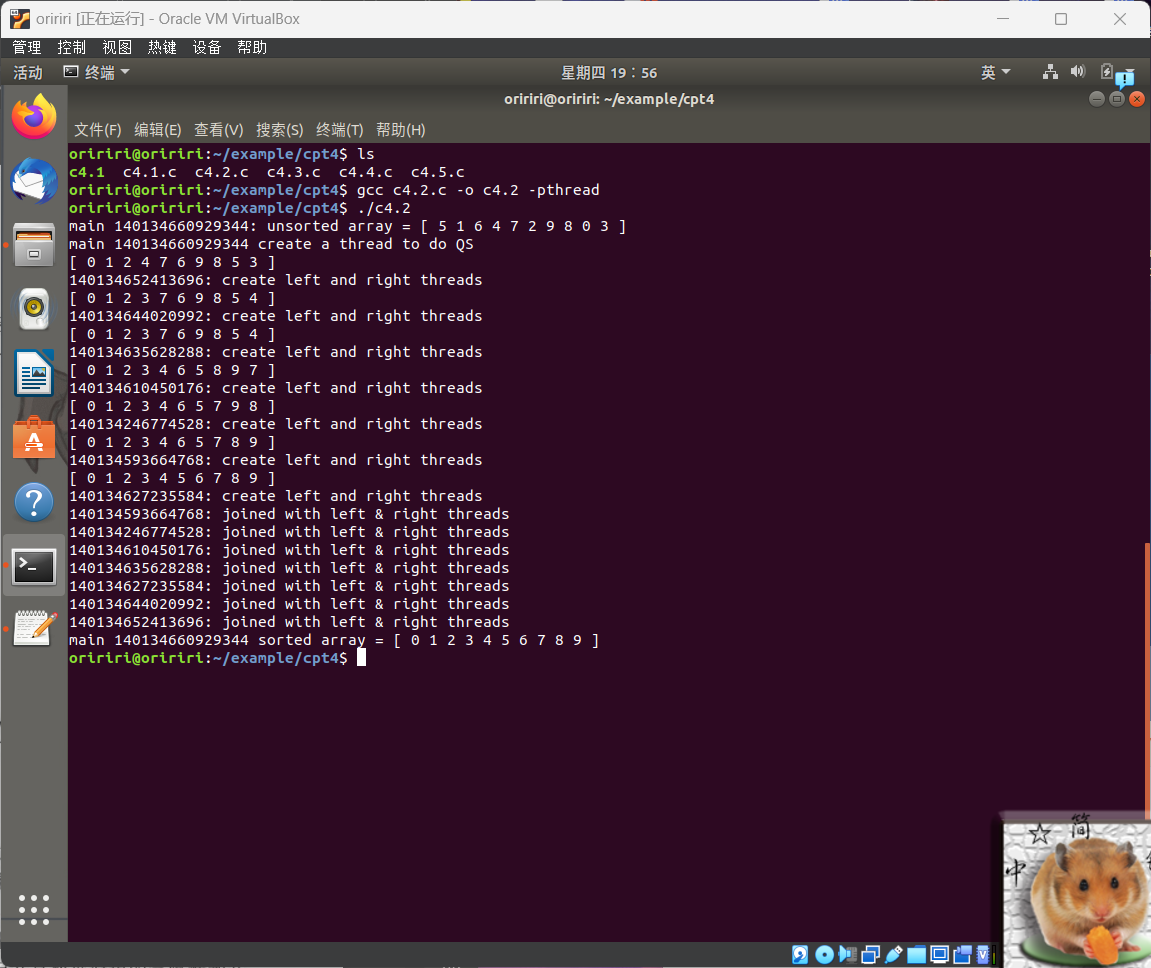
2.用线程快速排序,运行结果如下。
3.通过互斥量实现线程同步,运行结果如下。
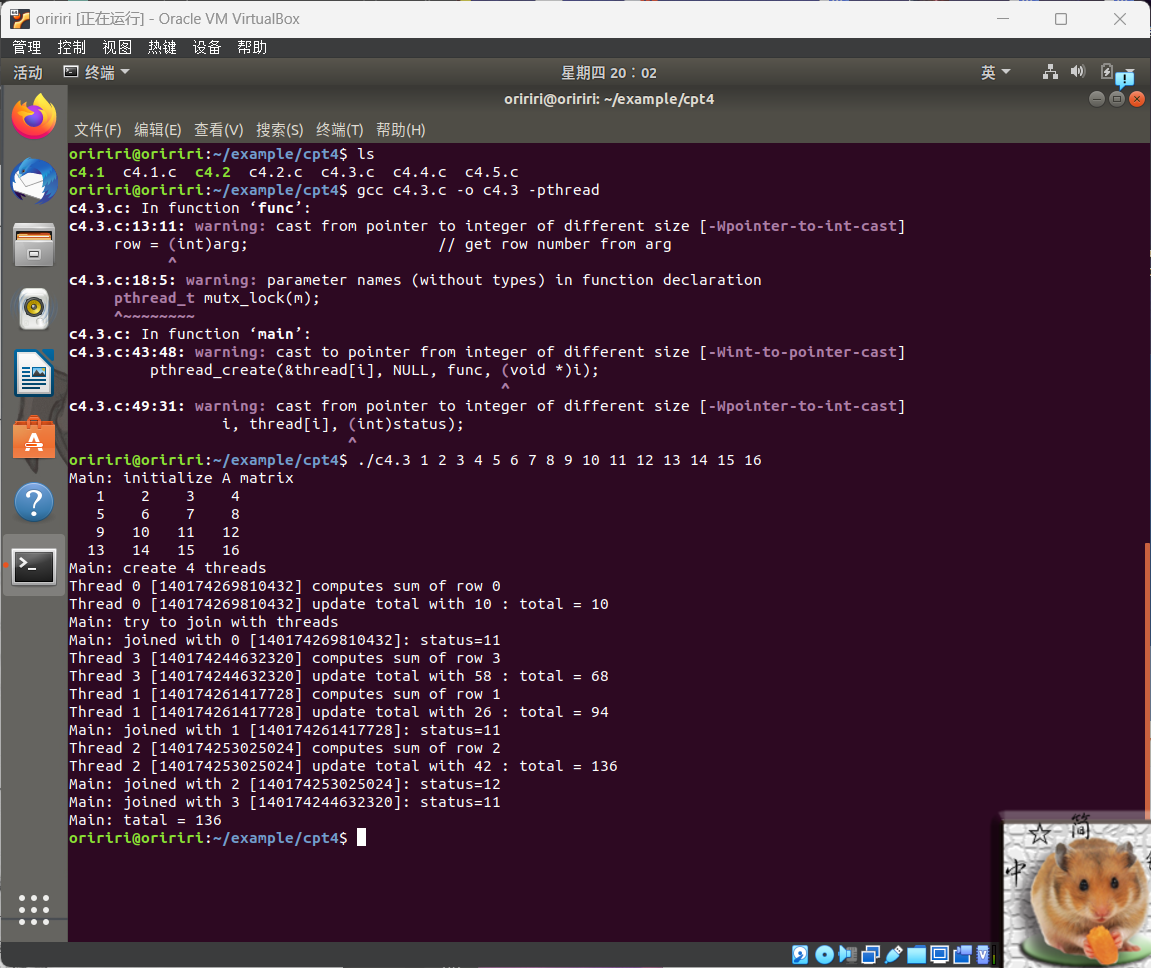
4.使用条件变量来实现线程协作,运行结果如下。
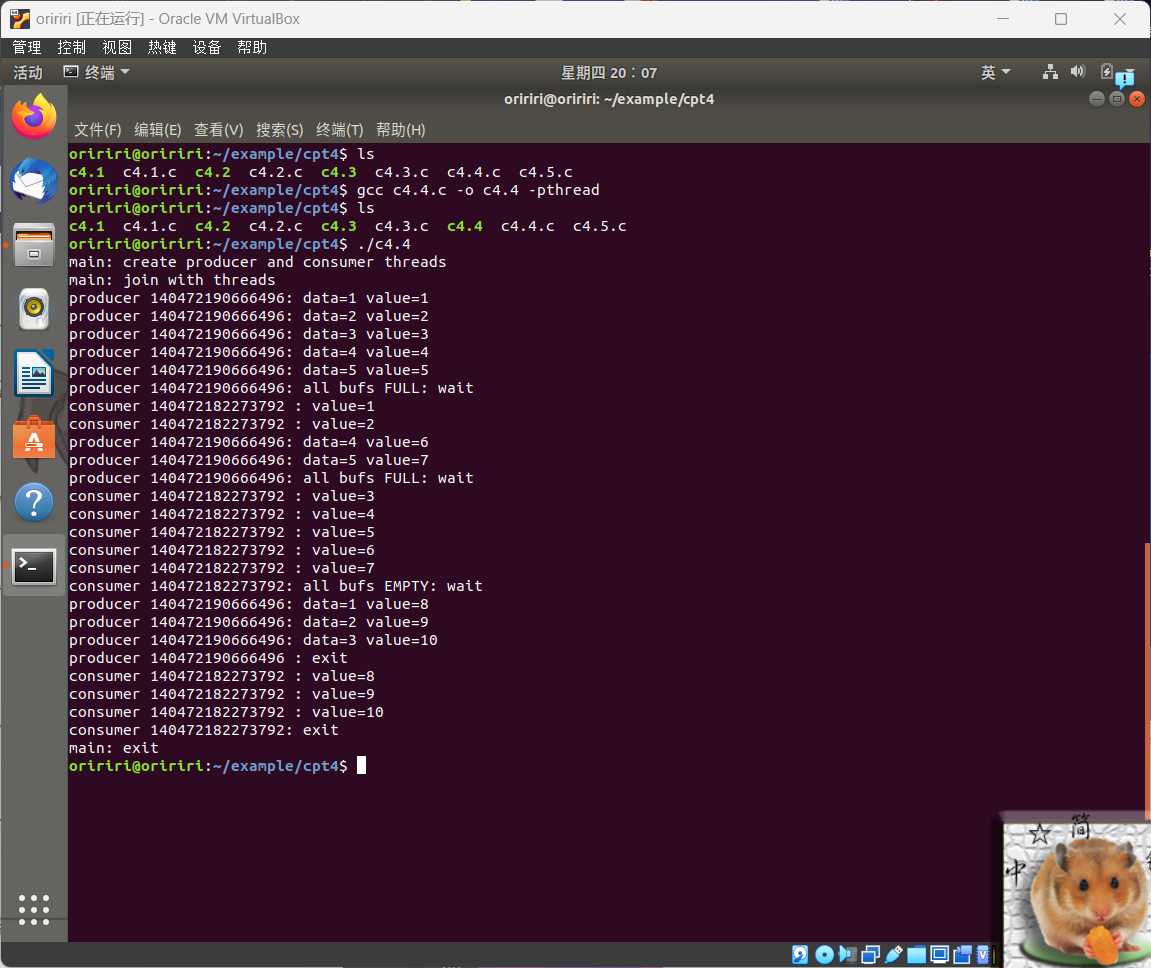
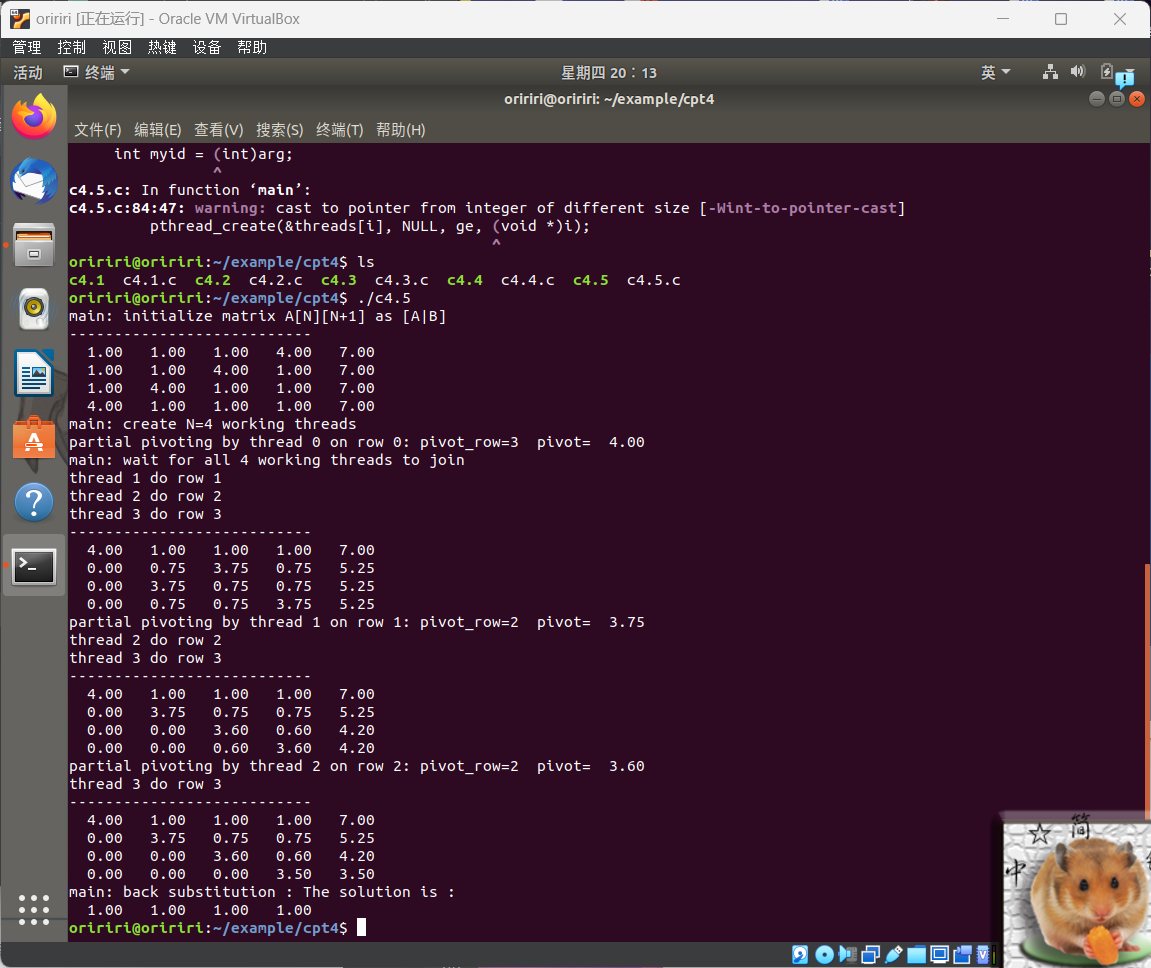
5.用并发线程解线性方程组,运行结果如下。