学习目标

二叉树重建的概念

二叉树重建流程

例题和解题思路

2

3

4

5

[【二叉树】求先序排列]


代码



【算法分析】 后序遍历的最后一个是根节点,由这个根节点可以在中序遍历中确定左子树和右子树的大小和元素,然后递归的去处理左子树和右子树,由于是求先序序列,所以是先输出,再递归左子树,再递归右子树。 【参考代码】 #include<bits/stdc++.h> using namespace std; //处理中序遍历为s,后序遍历为t的字串 void dfs(string s, string t) { if (s.size() == 0) return; int id = s.find(t.back());//找到后序遍历的最后一个字符(根节点)在中序遍历中的位置 cout << s[id];//先输出,再递归左子树,再递归右子树 dfs(s.substr(0, id), t.substr(0, id));//中序遍历的左子树是从下标0开始的id个字符,后序遍历的左子树是从下标0开始的id个字符 dfs(s.substr(id + 1, s.size() - id - 1), t.substr(id, s.size() - id - 1));//中序遍历的右子树是从下标id+1开始的s.size() - id - 1个字符,后序遍历的右子树是从下标id开始的s.size() - id - 1个字符 } int main() { string s, t; cin >> s >> t; dfs(s, t); return 0; }
这段代码是用来处理二叉树的中序遍历和后序遍历的。具体来说,给定一个二叉树的中序遍历字符串 s 和后序遍历字符串 t,这段代码的目的是重新构造这棵二叉树并输出。 首先,让我们详细解释代码的每一部分: 头文件和命名空间 cpp #include<bits/stdc++.h> using namespace std; 这部分包括了bits/stdc++.h头文件,它是GCC编译器下的一个头文件,包含了几乎所有标准库的头文件。使用using namespace std;是为了避免在每次使用标准库时都要加上std::前缀。 dfs函数 cpp void dfs(string s, string t) { if (s.size() == 0) return; int id = s.find(t.back()); cout << s[id]; dfs(s.substr(0, id), t.substr(0, id)); dfs(s.substr(id + 1, s.size() - id - 1), t.substr(id, s.size() - id - 1)); } 这是一个递归函数,用于处理中序遍历为s和后序遍历为t的字符串。 如果s为空,则返回。 使用find函数找到后序遍历的最后一个字符(根节点)在中序遍历中的位置,这个位置是id。 输出中序遍历中的根节点。 递归处理左子树:使用substr函数分别获取中序和后序遍历的左子树字符串,然后递归调用dfs函数。 递归处理右子树:使用substr函数分别获取中序和后序遍历的右子树字符串,然后递归调用dfs函数。 主函数 cpp int main() { string s, t; cin >> s >> t; dfs(s, t); return 0; } 在主函数中,首先读入中序遍历字符串s和后序遍历字符串t。然后调用dfs函数来处理这两个字符串。 执行过程: 读入中序遍历字符串 s 和后序遍历字符串 t。 调用 dfs(s, t) 开始处理。 在 dfs 函数中,首先找到后序遍历的最后一个字符在中序遍历中的位置 id。 输出这个字符(这是根节点)。 递归处理左子树:找到左子树的中序和后序遍历字符串,并递归处理。 递归处理右子树:找到右子树的中序和后序遍历字符串,并递归处理。 这个过程会持续进行,直到中序遍历字符串为空。此时,这棵二叉树的构造完成,并且被打印出来。
[【二叉树】求后序排列]

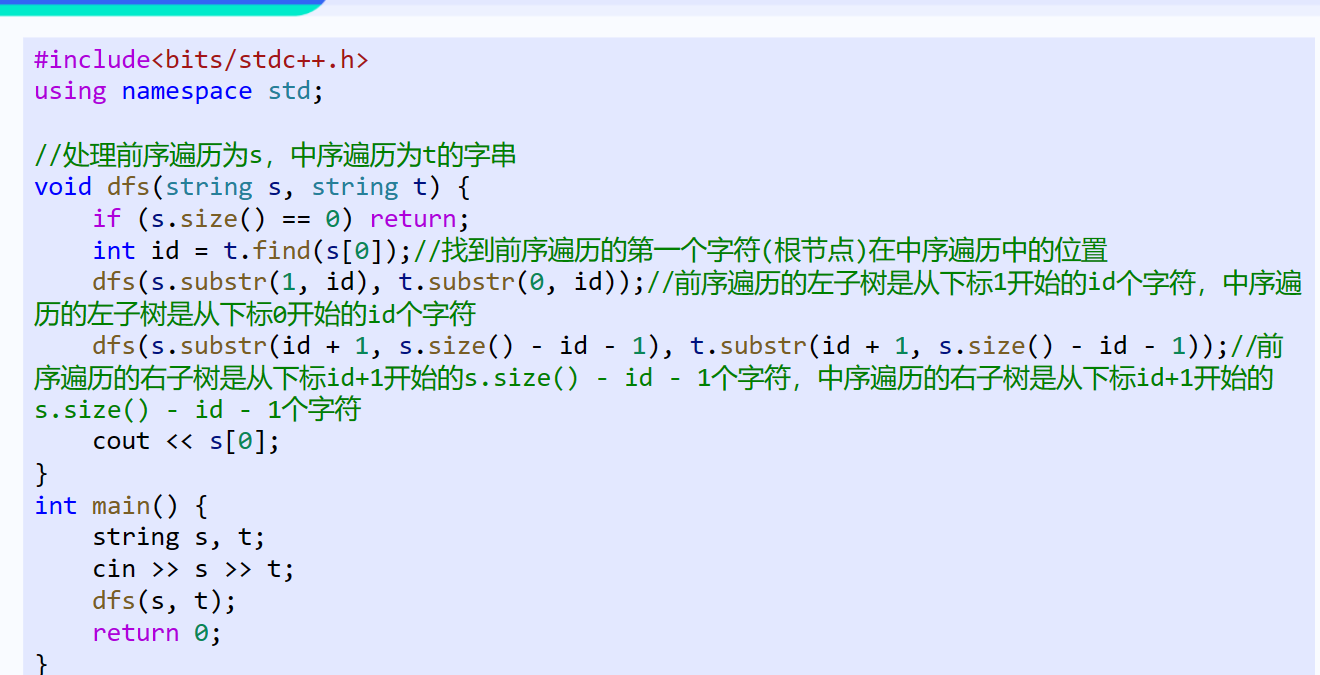
【算法分析】 前序遍历的第一个是根节点,由这个根节点可以在中序遍历中确定左子树和右子树的大小和元素,然后递归的去处理左子树和右子树,由于是求后序序列,所以是先递归左子树,再递归右子树,再输出。 【参考代码】 #include<bits/stdc++.h> using namespace std; //处理前序遍历为s,中序遍历为t的字串 void dfs(string s, string t) { if (s.size() == 0) return; int id = t.find(s[0]);//找到前序遍历的第一个字符(根节点)在中序遍历中的位置 dfs(s.substr(1, id), t.substr(0, id));//前序遍历的左子树是从下标1开始的id个字符,中序遍历的左子树是从下标0开始的id个字符 dfs(s.substr(id + 1, s.size() - id - 1), t.substr(id + 1, s.size() - id - 1));//前序遍历的右子树是从下标id+1开始的s.size() - id - 1个字符,中序遍历的右子树是从下标id+1开始的s.size() - id - 1个字符 cout << s[0]; } int main() { string s, t; cin >> s >> t; dfs(s, t); return 0; }
执行流程
这段代码是用来处理二叉树的前序遍历和中序遍历的。具体来说,给定一个二叉树的前序遍历字符串 s 和中序遍历字符串 t,这段代码的目的是重新构造这棵二叉树并输出。 这段代码中的 dfs 函数处理前序遍历为 s 和中序遍历为 t 的字符串,以重建二叉树。 代码的执行流程如下: main 函数从标准输入读取前序遍历和中序遍历的字符串 s 和 t。 调用 dfs(s, t) 开始处理。 在 dfs 函数中,首先找到前序遍历的第一个字符(根节点)在中序遍历中的位置 id。这个位置 id 是通过搜索 t 中 s[0] 的位置得到的。 递归处理左子树:使用 substr 函数分别获取前序遍历和种序遍历的左子树字符串,然后递归调用 dfs 函数。 递归处理右子树:使用 substr 函数分别获取前序遍历和种序遍历的右子树字符串,然后递归调用 dfs 函数。 最后,输出前序遍历的第一个字符(根节点)。 这个过程会持续进行,直到所有的字符都被处理完,此时二叉树就构造完成了,并被打印出来。
本节课作业讲解分析:
链接:https://pan.baidu.com/s/1acbyNex0-nwiFhXs_UBgvw?pwd=xb3i
提取码:xb3i