原文:NumPy Cookbook - Second Edition
译者:飞龙
在本章中,我们涵盖以下秘籍:
- 用
at()方法用花式索引代替 ufuncs - 通过使用
partition()函数选择快速中位数进行部分排序 - 使用
nanmean(),nanvar()和nanstd()函数跳过 NaN - 使用
full()和full_like()函数创建值初始化的数组 numpy.random.choice()随机抽样- 使用
datetime64类型和相关的 API
简介
自《NumPy 秘籍》第一版以来,NumPy 团队引入了新功能; 我将在本章中对其进行描述。 您可能不太可能阅读本书的第一版,而现在正在阅读第二版。 我在 2012 年撰写了第一版,并使用了当时可用的功能。 NumPy 具有许多功能,因此您不能期望涵盖所有功能,但是我在本章中介绍的功能相对重要。
使用at()方法为 ufuncs 建立花式索引
at()方法已添加到 NumPy 1.8 的 NumPy 通用函数类中。 此方法允许就地进行花式索引。 花式索引是不涉及整数或切片的索引,这是正常的索引。 “就地”是指将更改输入数组的数据。
at()方法的签名为ufunc.at(a, indices[, b])。 索引数组对应于要操作的元素。 我们仅必须为具有两个操作数的通用函数指定b数组。
操作步骤
以下步骤演示了at()方法的工作方式:
-
创建一个具有种子
44的7个从-4到4的随机整数的数组。np.random.seed(44) a = np.random.random_integers(-4, 4, 7) print(a)该数组如下所示:
[ 0 -1 -3 -1 -4 0 -1] -
将
sign通用函数的at()方法应用于第三和第五个数组元素:np.sign.at(a, [2, 4]) print(a)我们得到以下更改后的数组:
[ 0 -1 -1 -1 -1 0 -1]
另见
使用partition()函数通过快速中位数的选择进行部分排序
partition()子例程进行部分排序。 这应该比正常的分类工作少。
注意
有关更多信息,请参见这里。 有用的情况是选择组中的前五项(或其他一些数字)。 部分排序不能在顶部元素集中保留正确的顺序。
子例程的第一个参数是要排序的输入数组。 第二个参数是整数或与数组元素的索引相对应的整数列表。 partition()子例程正确地对那些索引处的项目进行排序。 一个指定的索引给出两个分区。 多个索自举致两个以上的分区。 该算法保证分区中小于正确排序项目的项目位于该项目之前。 否则,它们将放在该项目的后面。
操作步骤
让我们举例说明此解释:
-
创建一个具有随机数的数组以进行排序:
np.random.seed(20) a = np.random.random_integers(0, 7, 9) print(a)该数组具有以下元素:
[3 2 7 7 4 2 1 4 3] -
通过将数组划分为两个大致相等的部分,对数组进行部分排序:
print(np.partition(a, 4))我们得到以下结果:
[2 3 1 2 3 7 7 4 4]
工作原理
我们对 9 个元素的数组进行了部分排序。 该函数保证索引4,的中间只有一个元素在正确的位置。 这对应于尝试选择数组的前五项而不关心前五组中的顺序。 由于正确排序的项目位于中间,因此这也将返回数组的中位数。
另见
使用nanmean(),nanvar()和nanstd()函数跳过 NaN
试图估计一组数据的算术平均值,方差和标准差是很常见的。
一种简单但有效的方法称为 Jackknife 重采样。 Jackknife 重采样的想法是通过每次都遗漏一个值来从原始数据创建数据集。 本质上,我们试图估计如果至少一个值不正确会发生什么。 对于每个新数据集,我们都会重新计算我们感兴趣的统计估计量。这有助于我们了解估计量的变化方式。
操作步骤
我们将折刀重采样应用于随机数据。 通过将其设置为 NaN(非数字),我们将跳过每个数组元素一次。 然后,可以使用nanmean(),nanvar()和nanstd()计算算术平均值,方差和标准差:
-
首先为估算值初始化一个
30 x 3的数组,如下所示:estimates = np.zeros((len(a), 3)) -
遍历数组并通过在循环的每次迭代中将一个值设置为 NaN 来创建新的数据集。 对于每个新数据集,计算估计值:
for i in xrange(len(a)): b = a.copy() b[i] = np.nan estimates[i,] = [np.nanmean(b), np.nanvar(b), np.nanstd(b)] -
打印每个估计量的方差:
print("Estimator variance", estimates.var(axis=0))屏幕上显示以下输出:
Estimator variance [ 0.00079905 0.00090129 0.00034604]
工作原理
我们用折刀重采样估计了数据集的算术平均值,方差和标准差的方差。 这表明算术平均值,方差和标准差有多少变化。 该秘籍的代码在本书的代码包的jackknife.py 文件中:
from __future__ import print_function
import numpy as np
np.random.seed(46)
a = np.random.randn(30)
estimates = np.zeros((len(a), 3))
for i in xrange(len(a)):
b = a.copy()
b[i] = np.nan
estimates[i,] = [np.nanmean(b), np.nanvar(b), np.nanstd(b)]
print("Estimator variance", estimates.var(axis=0))
另见
使用full()和full_like()函数创建初始化值的数组
full()和full_like()函数是 NumPy 的新增函数,旨在促进初始化。 这是文档中关于它们的内容:
>>> help(np.full)
Return a new array of given shape and type, filled with `fill_value`.
>>> help(np.full_like)
Return a full array with the same shape and type as a given array.
操作步骤
让我们看一下full()和full_like()函数:
-
用
full()创建一个1x2数组,并填充幸运数字7:print(np.full((1, 2), 7))因此,我们得到以下数组:
array([[ 7., 7.]])数组元素是浮点数。
-
指定整数数据类型,如下所示:
print(np.full((1, 2), 7, dtype=np.int))输出相应地更改:
array([[7, 7]]) -
full_like()函数检查数组的元数据,并将其重新用于新数组。 例如,使用linspace()创建一个数组,并将其用作full_like()函数的模板:a = np.linspace(0, 1, 5) print(a) array([ 0\. , 0.25, 0.5 , 0.75, 1\. ]) print(np.full_like(a, 7)) array([ 7., 7., 7., 7., 7.]) -
同样,我们用幸运数字
7填充数组。 要将数据类型修改为整数,请在以下行中使用 :print(np.full_like(a, 7, dtype=np.int)) array([7, 7, 7, 7, 7])
工作原理
我们用full()和full_like()产生了数组。 full()函数用数字7填充数组。 full_like()函数重新使用了数组的元数据来创建新的数组。 这两个函数都可以指定数组的数据类型。
使用numpy.random.choice()进行随机采样
自举的过程类似于粗加工。 基本的自举方法包括以下步骤:
- 从大小为 N 的原始数据生成样本。将原始数据样本可视化为一碗数字。 我们通过从碗中随机抽取数字来创建新样本。 取一个数字后,我们将其放回碗中。
- 对于每个生成的样本,我们计算感兴趣的统计估计量(例如,算术平均值)。
操作步骤
我们将应用numpy.random.choice()进行自举:
-
按照二项式分布生成数据样本,该数据样本模拟五次抛掷公平硬币:
N = 400 np.random.seed(28) data = np.random.binomial(5, .5, size=N) -
生成 30 个样本并计算其平均值(更多样本将得到更好的结果):
bootstrapped = np.random.choice(data, size=(N, 30)) means = bootstrapped.mean(axis=0) -
使用 matplotlib 箱形图可视化算术平均值分布:
plt.title('Bootstrapping demo') plt.grid() plt.boxplot(means) plt.plot(3 * [data.mean()], lw=3, label='Original mean') plt.legend(loc='best') plt.show()有关最终结果,请参考以下带注释的图:
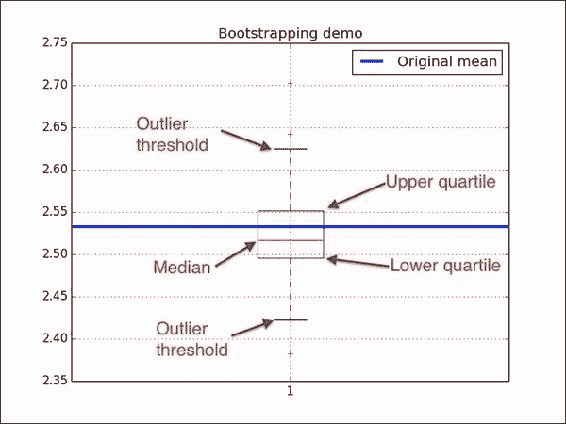
工作原理
我们模拟了一个实验,该实验涉及掷出五次公平硬币。 我们通过创建样本并计算相应的方法来自举数据。 然后,我们使用numpy.random.choice()进行自举。 我们用matplotlib箱形图直观地表示了均值。 如果您不熟悉箱形图,图中的注释将对您有所帮助。 箱形图中的以下元素很重要:
- 中位数由框中的一条线表示。
- 上下四分位数显示为框的边界。
- 胡须指示异常值的边界。 默认情况下,这些值从框的边界设置为
1.5 * (Q3 - Q1),也称为四分位间距。
另见
使用datetime64类型和相关的 API
datetime64类型表示相应的日期和时间。 您需要 NumPy 1.7.0 或更高版本才能使用此数据类型。
操作步骤
要熟悉datetime64,请按照下列步骤操作:
-
从字符串创建一个
datetime64,如下所示:print(np.datetime64('2015-05-21'))前一行输出以下输出:
numpy.datetime64('2015-05-21')我们使用
YYYY-MM-DD格式在 2015 年 5 月 21 日创建了datetime64类型,其中Y对应于年份,M对应于月份,D对应于每月的一天。 NumPy 符合 ISO 8601 标准 -- 一种表示日期和时间的国际标准。 -
ISO 8601 还定义了
YYYY-MM-DD,YYYY-MM和YYYYMMDD格式。 自己检查这些,如下所示:print(np.datetime64('20150521')) print(np.datetime64('2015-05'))该代码显示以下行:
numpy.datetime64('20150521') numpy.datetime64('2015-05') -
默认情况下,ISO 8601 使用本地时区。 可以使用
T[hh:mm:ss]格式指定时间。 例如,我们可以定义 1578 年 1 月 1 日和晚上 9:18。 如下:local = np.datetime64('1578-01-01T21:18') print(local)以下行显示了结果:
numpy.datetime64('1578-01-01T21:18Z') -
格式为
-[hh:mm]的字符串定义相对于 UTC 时区的偏移量。 我们可以使用 8 个小时的偏移量创建一个datetime64类型,如下所示:with_offset = np.datetime64('1578-01-01T21:18-0800') print(with_offset)然后,我们在屏幕上看到以下行:
numpy.datetime64('1578-01-02T05:18Z')最后的
Z代表 Zulu 时间,有时也称为 UTC。 -
相互减去两个
datetime64对象:print(local - with_offset)结果显示如下:
numpy.timedelta64(-480,'m')减法创建一个
timedelta64NumPy 对象,在这种情况下,它表示 480 分钟的增量。
工作原理
您了解了datetime64 NumPy 类型。 这种数据类型使我们可以轻松地操纵日期和时间。 它的功能包括简单的算术运算和使用常规 NumPy 函数创建数组。 请参考本书代码包中的datetime_demo.py文件:
import numpy as np
print(np.datetime64('2015-05-21'))
#numpy.datetime64('2015-05-21')
print(np.datetime64('20150521'))
print(np.datetime64('2015-05'))
#numpy.datetime64('20150521')
#numpy.datetime64('2015-05')
local = np.datetime64('1578-01-01T21:18')
print(local)
#numpy.datetime64('1578-01-01T21:18Z')
with_offset = np.datetime64('1578-01-01T21:18-0800')
print(with_offset)
#numpy.datetime64('1578-01-02T05:18Z')
print(local - with_offset)