HashMaph一些常见面试问题
一、hashmap底层如何实现的?
jdk1.7中通过数组+链表实现;jdk1.8中通过数组+链表+红黑树实现
它的主干是数组嘛,一个table数组
使用链表是为了解决哈希冲突嘛 所采用的链地址法
红黑树是为了避免链表过长导致的查询效率变低
它的一个底层存储原理是通过哈希表嘛
1.先创建一个默认长度为16,默认负载因子为0.75的数组,名为table
2.然后根据元素的hash值除以数组长度然后取余,余数值就是在数组中存储的位置
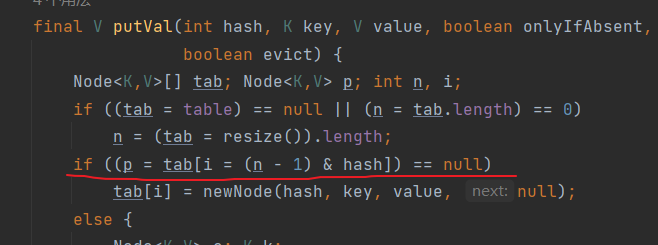
3.判断当前位置是否为空null,如果为null则直接存入
4.如果不为null则调用equals方法比较是否为同一个元素(不同元素的hash值取余后可能在同一位置),
不是同一个元素则存入数组(链表挂着),是同一个元素则不存(覆盖)
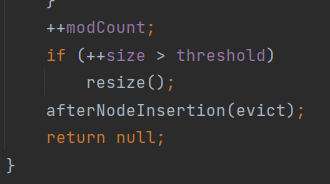
5.当数组存满到16*0.75=12的时候,就自动扩容,每次扩容到原来的两倍(左移一)
6.(jdk8以后(新元素挂在老元素后面))当数组长度大于等于64且链表长度大于8的时候自动转为红黑树,提高查找性能
二、寻址是怎么寻的?
i = (n - 1) & hash
用元素的hash值跟数组长度-1做与运算,实现取余操作(为什么不直接用%,因为计算机进行一些二进制运算会快很多)
举例:18->10010,16-1=15->1111 取余:10即2
三、hash函数怎么操作实现获取hash值的操作的?
在调用put方法的时候,会先调用hash函数,对原本元素的hash值进行一些处理
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
将获取到的hash值与这个获取到的哈希值右移16位后的数据做【异或】运算
(h=key.hashCode())^(h>>>16)//无符号右移
目的是为了减少哈希碰撞,
因为【存储的时候】都是跟数组长度length-1做【与运算】获取到的存储的下标的嘛
比如数组长度为16的时候-1=15二进制表示就是1111,做与运算只有低位有效了,
将获取到的hash值右移16位再做异或运算是为了让低位保留部分高位信息,从而减少哈希碰撞
四、为什么数组长度一直是2的整数幂?
第一:可以通过数组长度-1对元素的hash值进行与运算来【快速寻址】
(方便做与运算来快速寻址,因为对计算机来说做与运算要比做取余运算快很多)
第二:可以在扩容的时候保证【元素均匀分布】开来:如16扩容到32时,数组长度减一之后的二进制表示分别为1111和11111,再对hash值进行与运算时,前四位不变只看hash值的第五位是0还是1,而是0或是1的概率相等,所以会均匀分布开来。
五、初始化时hashmap的构造函数有指定容量的参数怎么实现的?
获取指定容量最近的2的整数幂的容量,进行右移1,2,4,8,16的操作然后进行或运算
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;//无符号右移
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
这个可以自行去用数据测试,比如14会变为16、18会变为32、5会变为8
六、HashMap线程不安全体现在哪里:
数据覆盖(进行put操作时):
1.寻址的时候嘛,线程A和线程B进行寻址时,定位到相同位置,而且该位置当前没有数据,线程A进行完if语句判断为null,准备插入时,它的时间片耗尽,导致只能将时间片给线程B来执行,由于A还没插入数据,所以线程B也判断为null,然后进行插入,插入完之后,时间片耗尽再给线程A,由于线程A之前已经判断了为空,所以直接插入,导致线程A的数据覆盖了线程B的数据。
2.判断是否需要扩容的时候也是同理,会导致两个线程都判断了,而size只加了1(假如原本size值为8,线程A在获取到size值后,时间片耗尽,cpu分配给线程B,线程B进行判断后size+1,当cpu再分配给线程A时,线程A会用最初获得的值8进行+1操作,故而造成两次put操作size只加了1)