目录

1.应用场景
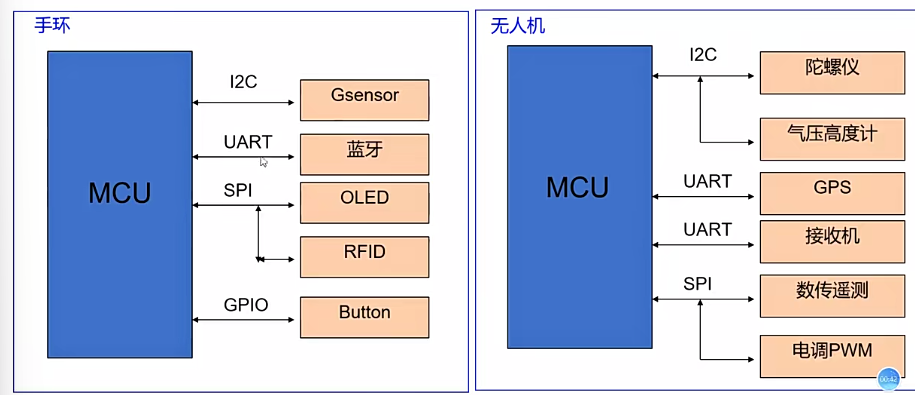
- 主要是I2C\UART\SPI协议
2.Cortex-M3 MCU成本与工艺选型
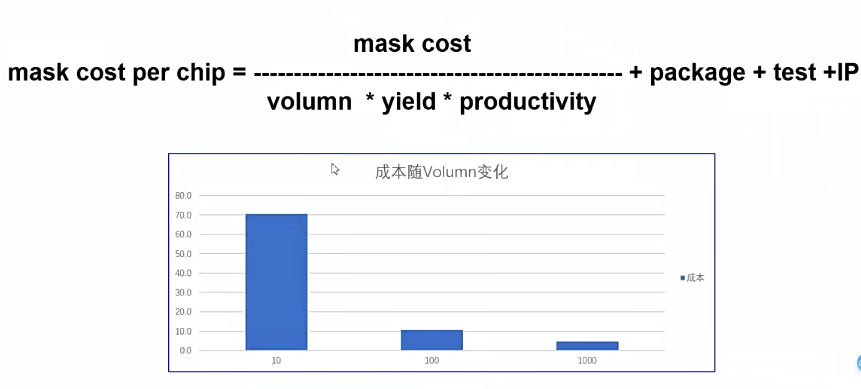
- 按照晶圆进行收费,28nm,12寸晶圆,400万美金
- 晶圆是圆形的,die是方形的,会存在浪费
- productivity - 大约是理论数量(晶圆总面积/裸片面积)的50%-60%
- yield - 生产工艺问题导致在晶圆上切出的die存在问题,存在良率问题
- package - 封装,将die的IO和外部的IO连在一起
- test - 芯片测试费用,ATE测试
- IP - ARM Core,主要是license费用
- volume - 数量
- 随着生产数量增加,成本越低。
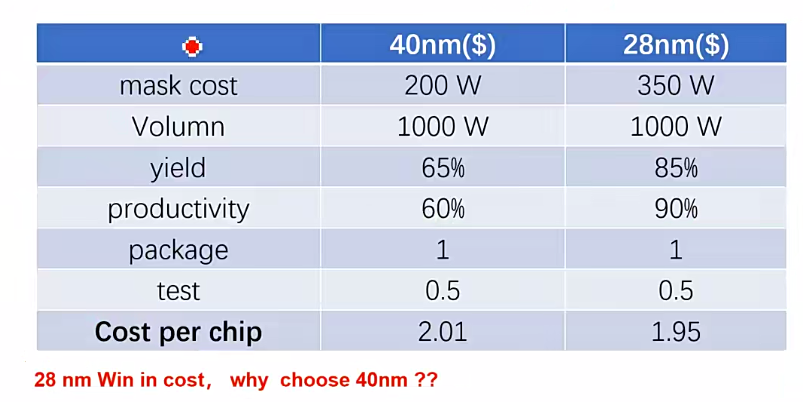
- 工艺升级,Mask费用会增加,yield也会上升,最终的单片成本会降低
- MCU在28nm或者是40nm,主要是因为MCU会高度集成一些模拟的器件Flash,AD/DA。模拟的工艺往往落后于数字,模拟工艺还停留在40nm。
- 工艺比较先进的芯片,Flash往往作为分离期间,Soc通过Flash Controller对Flash进行控制
3.Cortex-M3 MCU成本与工艺选型
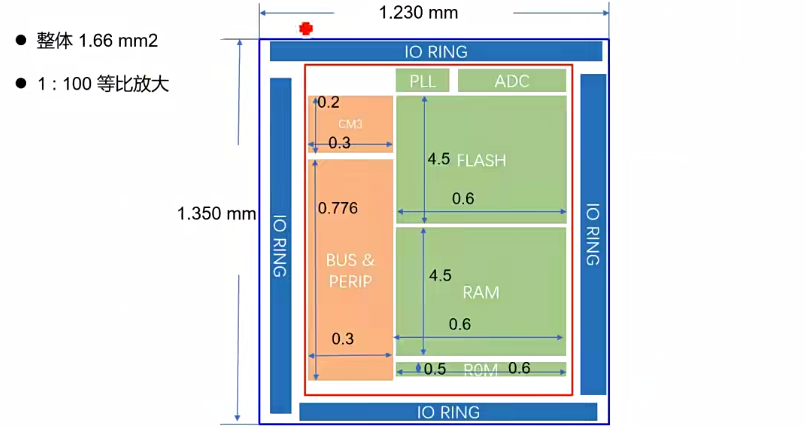
- Paper Floor Plan是按照比例进行放大的,便于后端人员进行布局布线
- 面积受限于Flash和RAM模拟部分的面积
4.Cortex-M3 MCU功耗预估
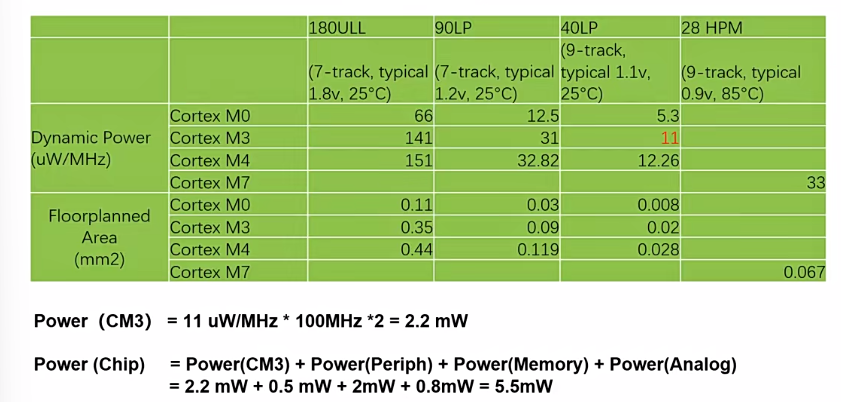
- track - 指的是CMOS的高度,track越高延时越小,有9-track和12-track。
5. Cortex-M3 MCU整体架构
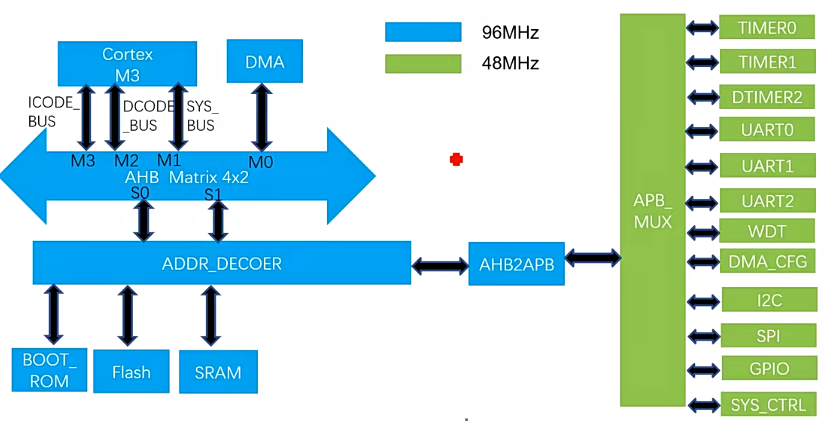
- core选择的是Cortex M3
- 存储系统选择:Boot-ROM、Flash、SRAM,Boot-ROM和Flash是可选择的,可以通过Boot-ROM进行启动,也可以通过Flash进行启动
- DMA配合CPU进行数据搬移,数据可以从内存中的一部分搬移到另外一部分,还可以从外设到内存,或者是从内存到外设。
- Cortex M3是一个RICS的系统,内存读写通过load-store指令,不管什么读写都需要经过寄存器间接进行load或者store。load是将数据从SRAM导入到CPU,Store是将数据从CPU导入到SRAM。
- load-store指令只能存取32bit数据,如果在内存中存取很大的数据效率就会比较低,DMA是一个硬件加速系统,可以解放CPU。
- AHB 4*2,四个Master和两个Slave
- APB不支持流水,每次固定两拍
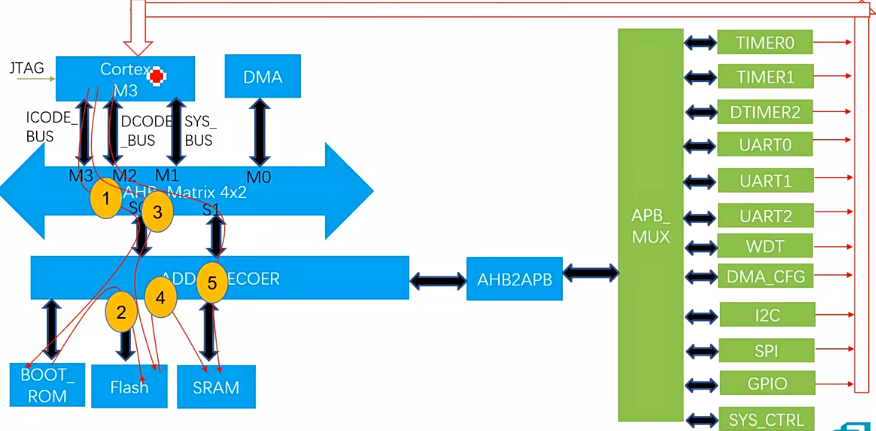
- CPU与外设通信:中断(外设发起中断,CPU收到之后执行中断使能程序)、CPU主动查询外设的状态(对CPU的负荷要求高)、设置状态寄存器,当外设完成任务的时候将寄存器置为1,CPU读取状态寄存器(类似于邮箱通信)
6.Memory Map
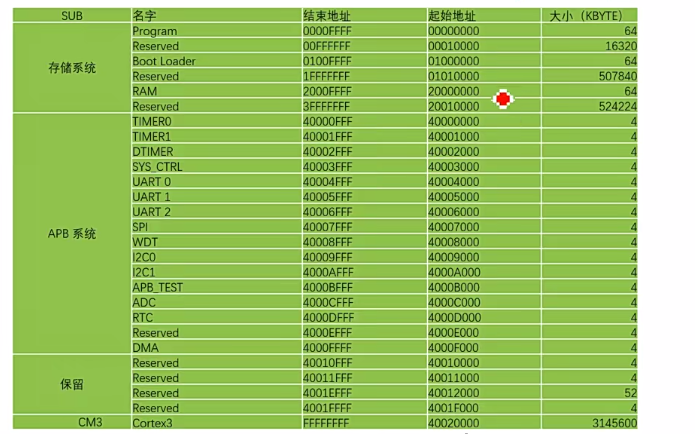
- program指的是Flash,因为默认是Flash进行启动,所以首地址一般是Flash地址
- Boot-ROM进行启动,会进行地址偏移
- Reserved表示保留地址空间
- 外设是按照4K的地址均匀分布的,4K地址均匀分布,APB经过地址译码之后都是规整的。
7.MCU电路设计,系统集成-为什么设计CRG
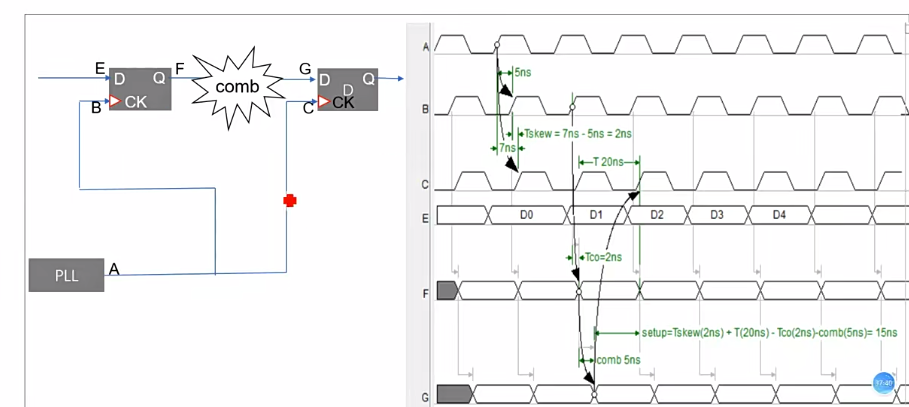
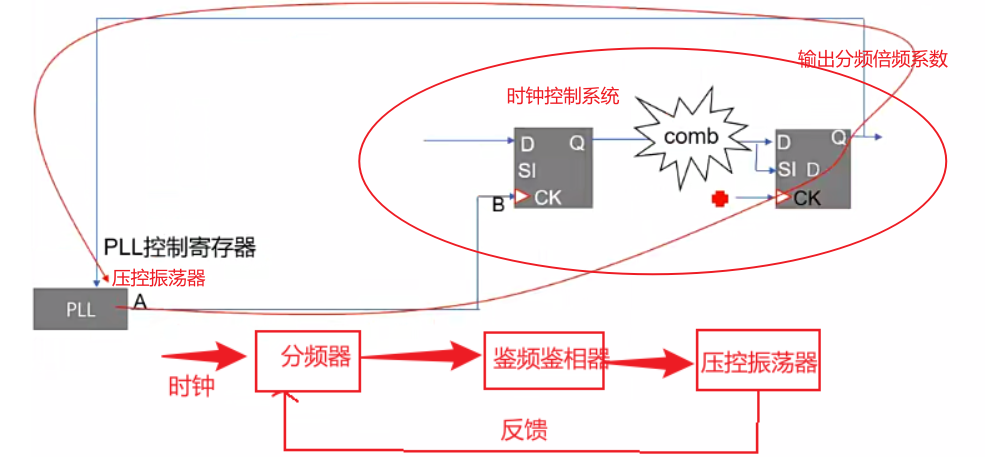
- CRG - Clock and Reset Generator
- 时钟从PLL(A)走出之后,到达B和C的时间是不同的,所以产生了skew,Tskew = 7ns-5ns = 2ns。B和C虽然是同一个时钟,但是B和C的时钟相位不同。
- setup时间的计算就是从同一个时钟起点出发,计算寄存器的数据端和时钟端的差
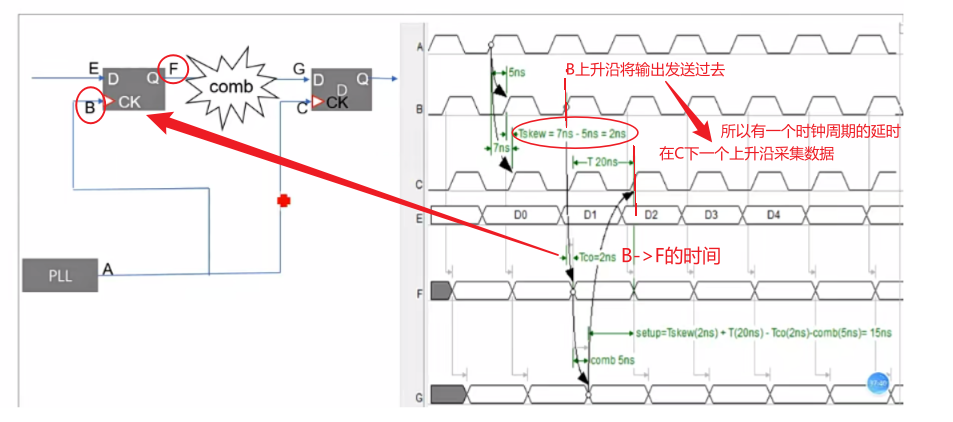
- 为了让时钟从A到B和C的时间尽可能相同,可以在时钟从A点出来之后插入buffer,两个时钟路径的buffer可以不同,做时钟树的平衡。
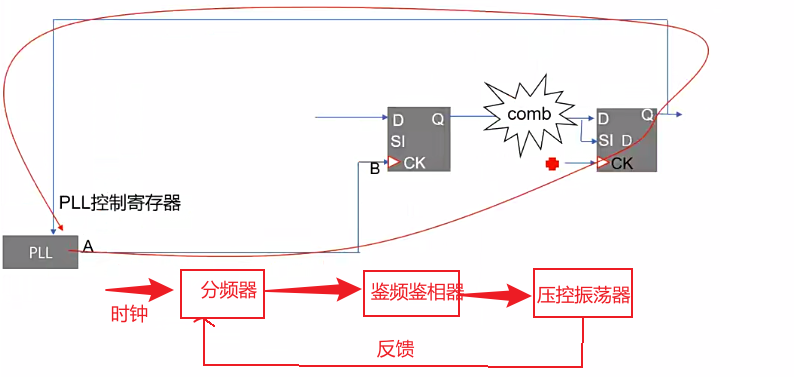
- PLL分频,其中有很多控制。压控振荡器是通过数字系统进行控制的。
- 时钟有外部时钟和PLL时钟,可以在时钟输入端加一个Mux,当PLL时钟倍频或者分频的系数没有配置好的时侯,使用外部时钟,当PLL倍频和分频完成之后切换到PLL的时钟。
- 在DFT测试的时候,会将寄存器串联起来,寄存器反馈给PLL压控振荡器的分频或者倍频数是一直在切换(toggle)的,PLL产生的时钟就会乱掉,无法完成DFT测试。
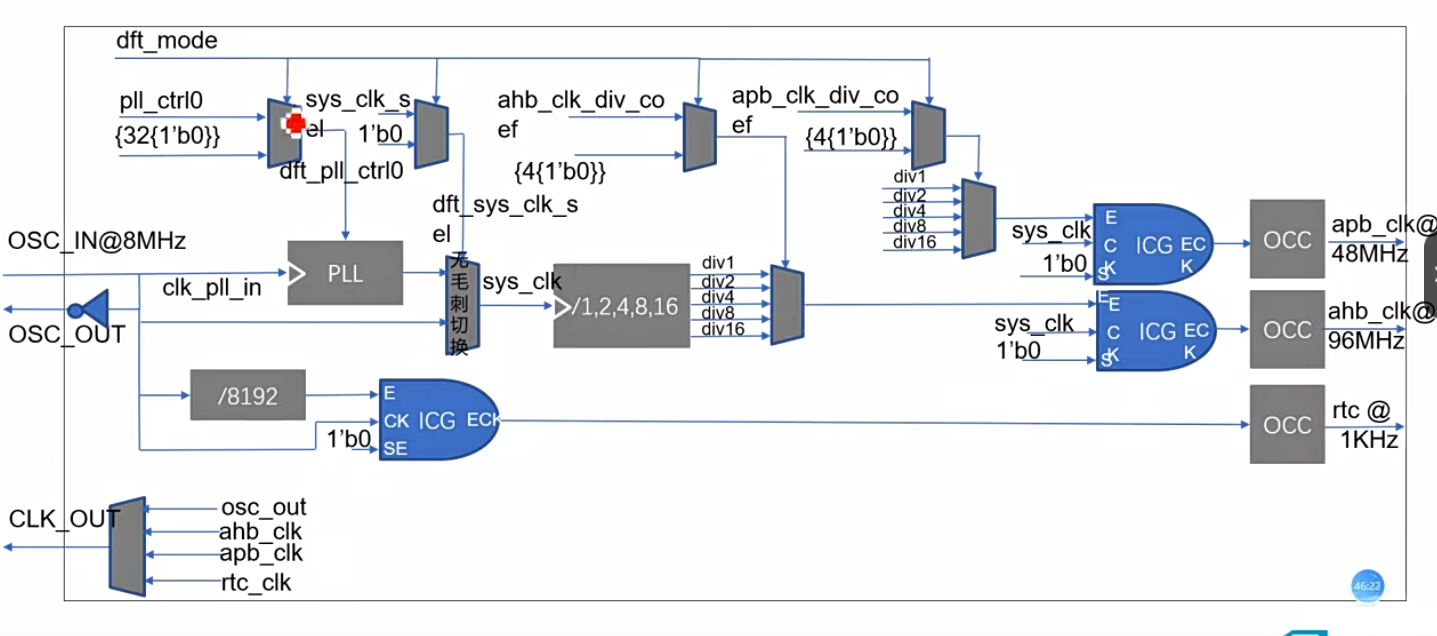
8.MCU电路设计,系统集成-IO MAP
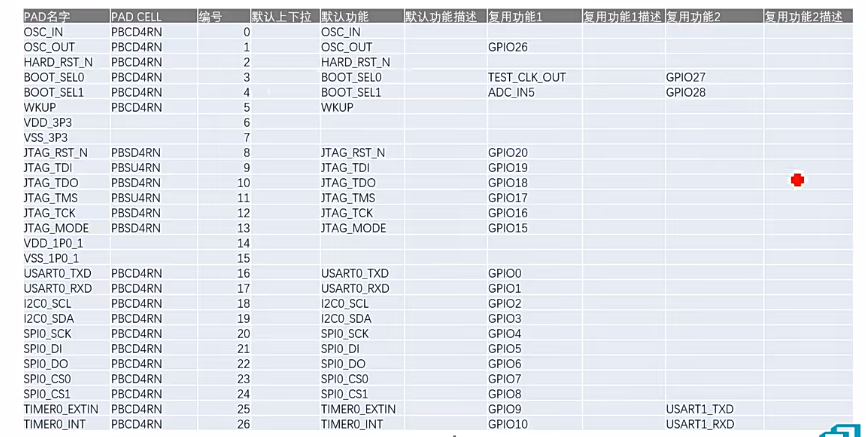
- wafer上切的die的越小,成本越低,die的大小取决于数字逻辑和模拟IP,还取决于边长,边长就取决于IO接口。不同时使用的接口可以进行复用。
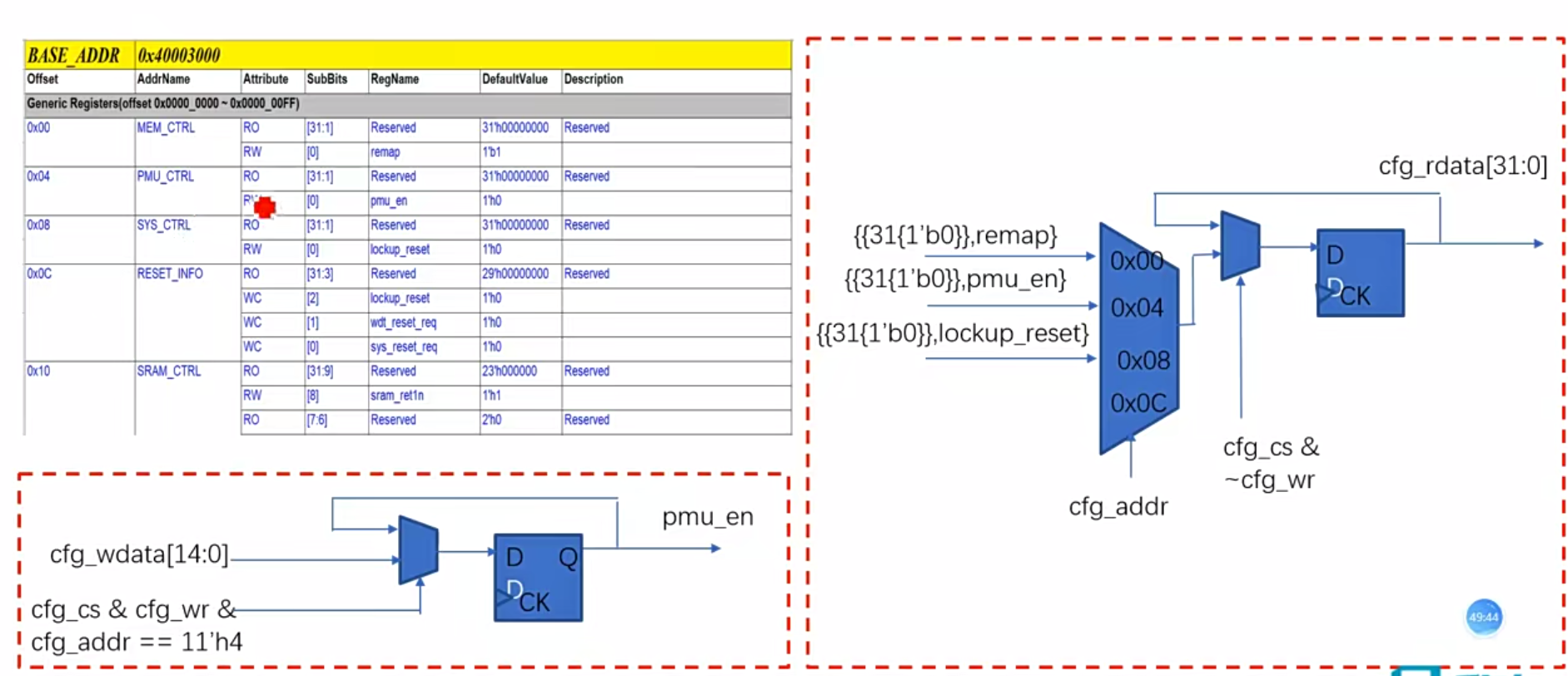
9.系统控制器