关于赛题
asisctf2023 nightjs 附件 一道 js 引擎题目,基于 serenityOS 上做的改编。(感觉 serenity 作者很 强迫症 善良得写了很多注释,连一行赋值语句都有注释,读起来超级愉悦)。

偷看了别人的wp来复现。给了 patch 文件之后,查看修改处的函数被什么函数引用,漏洞点就很明了了。攻击流程不难,不记录了。不过第一次见到脚本语言引擎的题目,有一些磕磕绊绊,这里总结一下收获。
js 执行过程
serenity js (和一般的脚本语言类似的)执行过程大概分为两个阶段:
- parce souce code to bytecode
- run bytecode 。
主要的处理部分在 parse_and_run 中。把源码解析成一个个字节码之后 run 的过程,其实就是找到每个 bytecode 对应的函数执行。
JS::Bytecode::Instruction::execute () 涉及从 bytecode 找到对应 function 的逻辑(感觉写的好优雅哇)。以 bytecode CALL 来举例,其类型是 Instruction::Type::Call 所对应的函数是 JS::Bytecode::Op::Call::execute_impl()。
ALWAYS_INLINE ThrowCompletionOr<void> Instruction::execute(Bytecode::Interpreter& interpreter) const
{
#define __BYTECODE_OP(op) \
case Instruction::Type::op: \
return static_cast<Bytecode::Op::op const&>(*this).execute_impl(interpreter);
switch (type()) {
ENUMERATE_BYTECODE_OPS(__BYTECODE_OP)
default:
VERIFY_NOT_REACHED();
}
#undef __BYTECODE_OP
}
这段函数中有两个宏,define __BYTECODE_OP(op) 在函数中定义了,而 ENUMERATE_BYTECODE_OPS 宏定义如下:
#define ENUMERATE_BYTECODE_OPS(O) \
O(Add) \
O(Append) \
O(BitwiseAnd) \
...太多了省略...\
O(UnsignedRightShift) \
O(Yield)
使得这一条语句可以从
switch (type()) {
ENUMERATE_BYTECODE_OPS(__BYTECODE_OP)
default:
VERIFY_NOT_REACHED();
扩展(宏ENUMERATE_BYTECODE_OPS(O))成为
switch (type()) {
__BYTECODE_OP(Add)
__BYTECODE_OP(Append)
__BYTECODE_OP(BitwiseAnd)
...太多了省略...
__BYTECODE_OP(UnsignedRightShift)
__BYTECODE_OP(Yield)
default:
VERIFY_NOT_REACHED();
在变换(宏 __BYTECODE_OP(op) )成为
switch (type()) {
case Instruction::Type::Add:
return static_cast<Bytecode::Op::Add const&>(*this).execute_impl(interpreter);
case Instruction::Type::Append:
return static_cast<Bytecode::Op::Append const&>(*this).execute_impl(interpreter);
case Instruction::Type::BitwiseAnd:
return static_cast<Bytecode::Op::BitwiseAnd const&>(*this).execute_impl(interpreter);
...太多了省略...
case Instruction::Type::UnsignedRightShift:
return static_cast<Bytecode::Op::UnsignedRightShift const&>(*this).execute_impl(interpreter);
case Instruction::Type::Yield:
return static_cast<Bytecode::Op::Yield const&>(*this).execute_impl(interpreter);
default:
VERIFY_NOT_REACHED();
如何调试
cpp 的代码经过优化即使编译时指定保存符号表,符号信息也太不完整,比如这题留下来的是函数名、类名。一些变量、结构体、类的信息就找不到了,所以有时候得对着内存嗯看布局。
因为命令较多,所以从文件中加载 gdb 命令:
# gdb ./js -x de(此文件名)
aslr on
set env LD_LIBRARY_PATH ./libjs
set args ./1.js
set substitute-path /pwn/asispwns/js/build/serenity/Meta/Lagom/../../ /mnt/d/wslubuntu2204/night/serenity-799b465fac5672f167d6fec599fe167bce92862d/
set substitute-path /pwn/asispwns/js/build/serenity/ /mnt/d/wslubuntu2204/night/serenity-799b465fac5672f167d6fec599fe167bce92862d/
add-symbol-file ./libjs/liblagom-js.so
b copy_data_block_bytes
gdb 设置源码路径
我希望 gdb 能够从我的机器加载源码,用到了这些命令:
info sources 查看写在二进制中的源码文件路径(显示的是出题人的文件路径,不是我的电脑的文件)
set substitute-path [from] [to] 替换源码路径。对于 info sources 的结果是绝对路径直接替换(正则)
directory 如果是相对路径可以用此命令设置查找的路径
动态库函数符号
对于动态库里的函数,如果没有程序没有 run,还没读取动态库的符号,可能无法在程序没有启动时下动态库函数的断点。
add-symbol-file [file] 可以提前读文件的符号表下断点
看内存
比如说我用 new ArrayBuffer(0x110); 实例化了一个 arraybuffer 对象,除了看函数返回值,还有其他方法找到这个对象在内存中的地址吗?
search 命令搜索内存即可
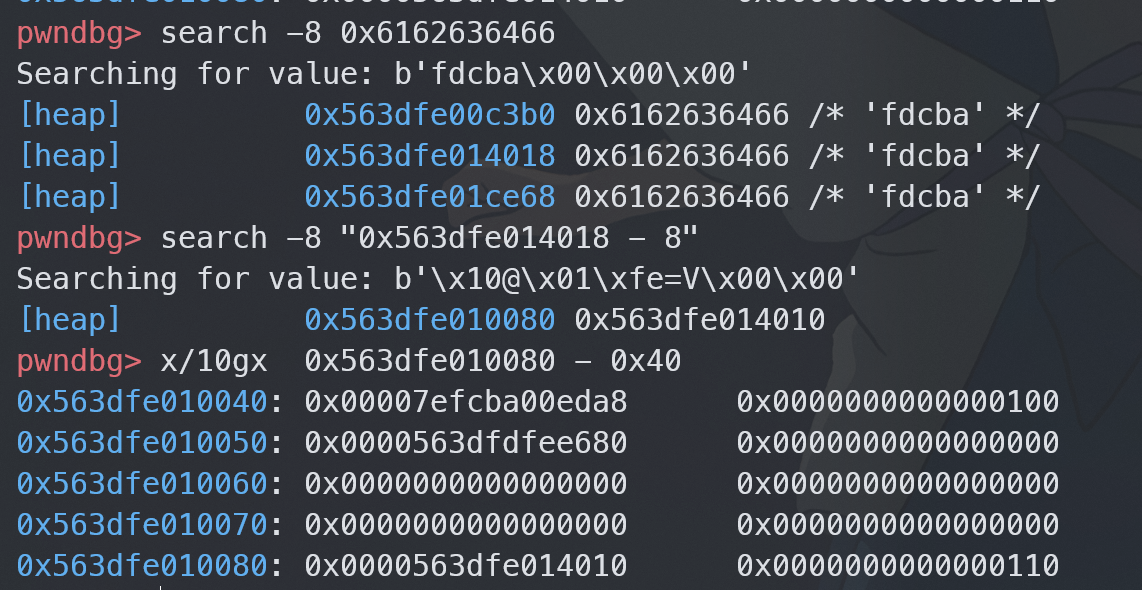
这样就找到了对象的内存。结合源码对照一下就知道布局是怎样得了
outline:
vtable 0x100
vtable 0
0 0
0 0
m_outline_buffer m_outline_capacity
0 0
m_size m_inline
m_detach_key 0x7ffei
函数调用信息
bt backtrace
info symbol addr 查看地址所在的函数
pwndbg> vmmap libc.so.6
LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA
Start End Perm Size Offset File
0x7efd501b1000 0x7efd501d9000 r--p 28000 0 /usr/lib/x86_64-linux-gnu/libc.so.6
0x7efd501d9000 0x7efd5036e000 r-xp 195000 28000 /usr/lib/x86_64-linux-gnu/libc.so.6
0x7efd5036e000 0x7efd503c6000 r--p 58000 1bd000 /usr/lib/x86_64-linux-gnu/libc.so.6
0x7efd503c6000 0x7efd503ca000 r--p 4000 214000 /usr/lib/x86_64-linux-gnu/libc.so.6
0x7efd503ca000 0x7efd503cc000 rw-p 2000 218000 /usr/lib/x86_64-linux-gnu/libc.so.6
pwndbg> info symbol (0x7efd501b1000 + 0xa5120)
malloc in section .text of /lib/x86_64-linux-gnu/libc.so.6
动态库加载
在本题中,从 liblagom-js.so 的地址可以计算 libc.so.6 的地址,两个动态库的偏移是固定的,于是想看看这些动态库加载的过程是怎样的。
Position Independent Code
Eli Bendersky 的文章 详细介绍了 PIC 和 x64 PIC 例子。
Position Independent Code (位置无关代码)是一种现在流行的动态库的格式,至少在 x64 上是强制 PIC 的。简单来说,动态库加载进内存不是以一个整体,而是分成好几个块(section)加载的。
比如我们可以用 vmmap 看见一个 lib 被分成多个段,有 code、data 段等。

这样安排的原因是,动态库不知道自己会被加载到内存的那个位置,因此在加载之前,和地址有关的代码部分是空余出来的,比如说数据和函数地址,在加载时候才会填上真正的地址。而且位置有关的部分(data)和位置无关的部分(code)属于不同的段,段与段的偏移是固定的,因此 code 段不用改变就可以从固定的偏移的地方读到 data 中的内容。如图:
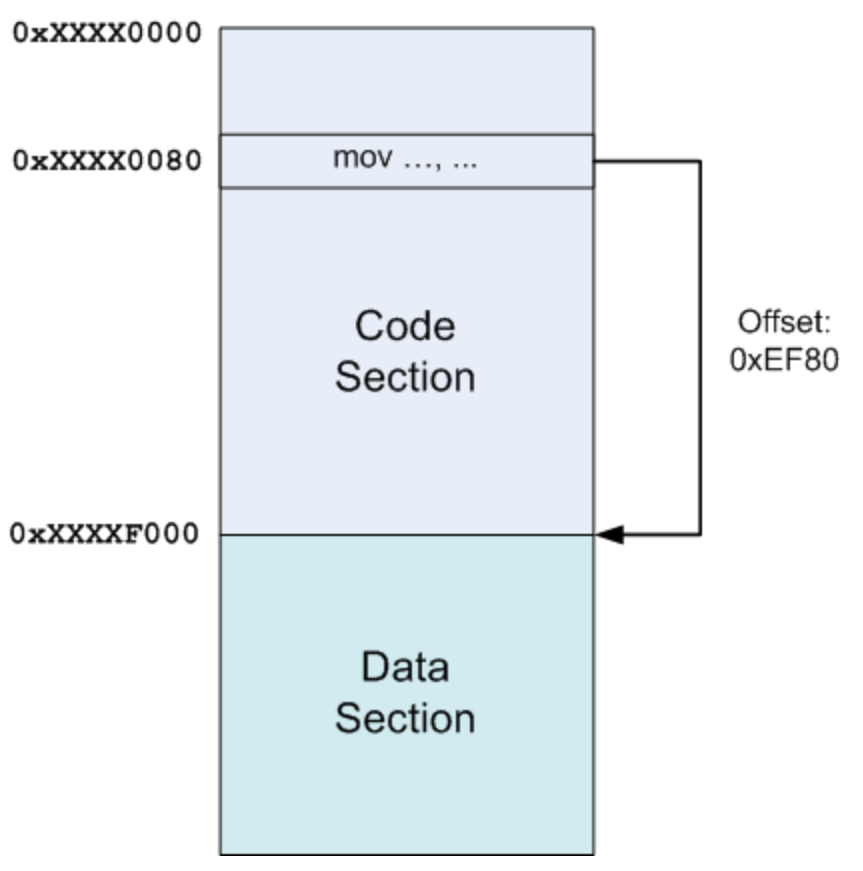
PIC 的好处是:
- 节约 RAM(位置无关代码被加载到内存中一次,然后映射到许多进程的虚拟内存中)
- 提升加载的效率(在加载时,只有位置相关部分需要被修改,不需要修改整个库的内容)
- 不同的 section 可以有不同的读写权限(不然 code 段也能随便写,容易被 hack)
dl-map-segments
现在去看看 glibc 怎么给一个动态库分配空间的,相关的代码在 _dl_map_segments 函数。
首先一次性分配一整个动态库所需的全部空间
l->l_map_start = _dl_map_segment (c, mappref, maplength, fd);

可以看见这 0x5000 的数据是没有分段的
随后根据存储 lib 的分段信息的 loadcmds 数组,分割这块已分配的虚拟内存
数组中的结构体定义如下
struct loadcmd
{
ElfW(Addr) mapstart, mapend, dataend, allocend, mapalign;
ElfW(Off) mapoff;
int prot; /* PROT_* bits. */
};
prot 的取值可以是
#define PROT_READ 0x1 /* Page can be read. */
#define PROT_WRITE 0x2 /* Page can be written. */
#define PROT_EXEC 0x4 /* Page can be executed. */
#define PROT_NONE 0x0 /* Page can not be accessed. */
在 gdb 中可以看见长这样
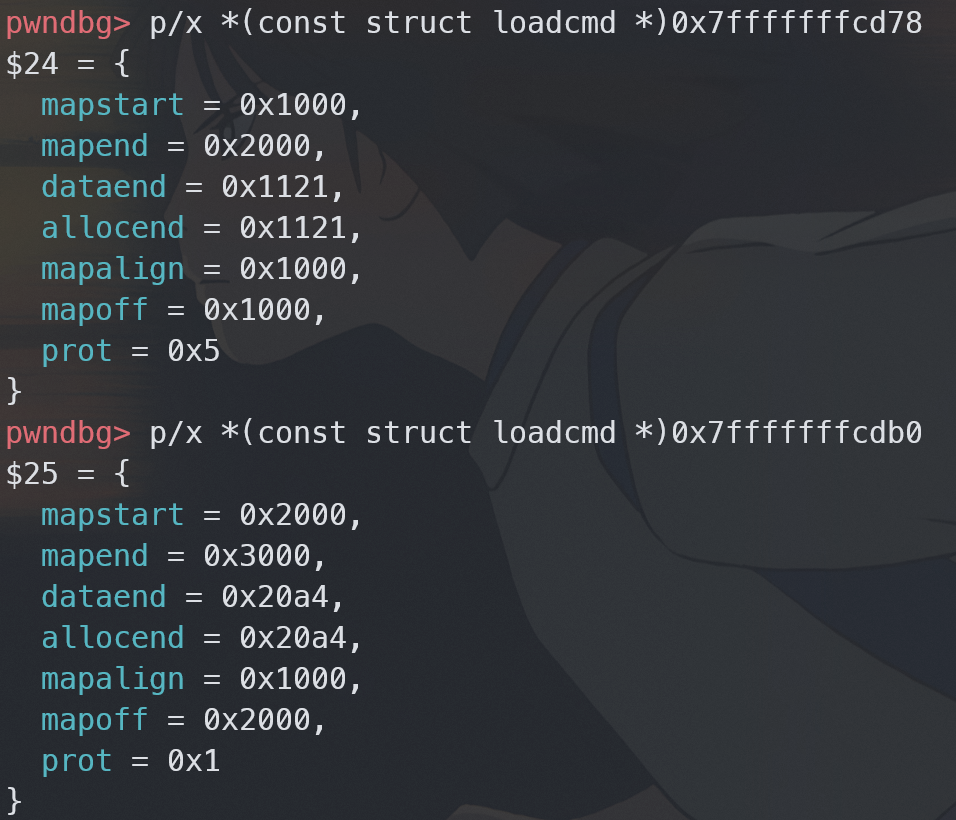
下面这个 while 循环的作用就是遍历 loadcmds 数组给整个动态库区域分段
while (c < &loadcmds[nloadcmds])
{
if (c->mapend > c->mapstart
/* Map the segment contents from the file. */
&& (__mmap ((void *) (l->l_addr + c->mapstart),
c->mapend - c->mapstart, c->prot,
MAP_FIXED|MAP_COPY|MAP_FILE,
fd, c->mapoff)
完成之后:
因为分配每个动态库的整体的空间时候(区别于 while 循环里面给动态库区域分段)使用的是
__mmap ((void *) mappref, maplength, c->prot,
MAP_COPY|MAP_FILE, fd, c->mapoff);
//如果动态库没有 preference 想要分配到哪里的话 mappref = 0,os 自己决定动态库的地址
因此动态库的位置怎么加载其实和 mmap 的算法有关系。mmap 的源码...下次一定看吧。
environ
i386 静态 可执行文件_start 过程,没找到 x86_64 的,找了一个 i386 的来参考下。
_environ 指向环境变量列表(可用 export 命令设置的那些),因为在程序启动的过程中,环境变量列表存在栈上(甚至在 _start 之前就在了),因此可以拿到栈的位置。
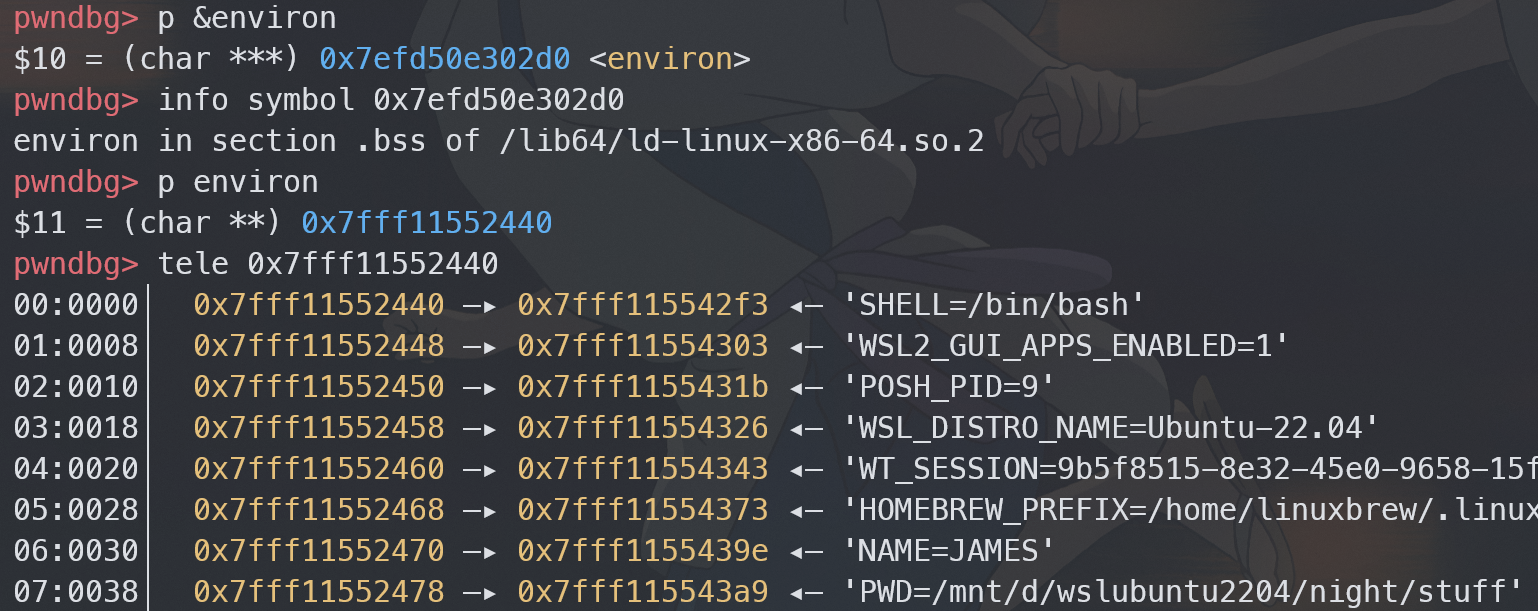
环境变量在程序启动的时候就会传入。比如说 execve 的参数 envp 就是环境变量表。
int execve(const char *pathname, char *const argv[], char *const envp[]);
x86_64 initial entry point code 在 \sysdeps\x86_64\dl-machine.h 中,此前装载器会把用户的参数和环境变量压入栈中,按照其压栈的方法,实际上栈顶的元素是argc,而接着其下就是argv和环境变量的数组。
_start:
movq %rsp, %rdi
call _dl_start
...
在 _dl_sysdep_start 中,计算栈地址给 _environ 变量赋值。
DL_FIND_ARG_COMPONENTS (start_argptr, _dl_argc, _dl_argv, _environ,
GLRO(dl_auxv));
# define DL_FIND_ARG_COMPONENTS(cookie, argc, argv, envp, auxp) \
do { \
void **_tmp; \
(argc) = *(long int *) cookie; \
(argv) = (char **) ((long int *) cookie + 1); \
(envp) = (argv) + (argc) + 1; \
for (_tmp = (void **) (envp); *_tmp; ++_tmp) \
continue; \
(auxp) = (void *) ++_tmp; \
} while (0)