- 架构:由Transformer论文衍生出来的大语言模型,主要有三种模型架构
- 预训练目标:FLM,PLM,MLM
- 调整:
- 微调:
Transformer
transfomer可以并行地计算?
transformer中encoder模块是完全并行的,而decoder不是完全并行的。
模型结构
使用原文表达如下:the encoder maps an input sequence of symbol representations \((x_1, x_2, \cdots, x_n)\) to a sequence of continuous representations $\pmb z = (z_1, z_2, \cdots, z_n) $. Given $\pmb z $, the decoder then generates an ouput sequence \((y_1, y2, \cdots, y_m)\) of symbols one element at a time.
因此在推理过程中,transformer网络结构中的decoder模块是自回归模式的,不能并行计算。
注: 自回归模式:之前时刻生成的,将作为当前时刻的输入(或其中一部分),并一起用来预测当前时刻的输出。如此循环直至结束
Attention机制
使用原文表达如下:“An attention function can be described as mapping a query and set of key-value pairs to an output where query, keys, values and output are all vectors. The output is computed as a weightd sum of the values, where the weight assigned to each value is computed by compatibility function of the query with the corresponding key.”
- query vector \(q\)
- a set of key-value pairs, \((k_1, v_1), \cdots, (k_r,v_r)\)
- scores of the query with the corresponding keys \(s_1, \cdots, s_r\)
- output vector \(z=s_1v_1 + \cdots + s_rv_r\)
Self-Attention机制
直观理解
以“The animal didn't cross the street because it was too tired”为例说明,下面图说明,是序列中每个单词都与序列中所有的单词都要计算一遍它们之间的某种相似度。而这种计算相似度量与序列中单词顺序无关,因此是可以并行的。

实际计算
创建querys, keys, values
随机初始化三个矩阵\(W_Q, W_K, W_V \in \mathbb{R}^{d \times d}\)(假设矩阵维度都是这样的),也是transformer中需要训练的参数。输入序列特征表示\(x_1, x_2, \cdots, x_n\),按行摆放,就构成了输入特征\(X \in \mathbb{R}^{n \times d}\),那么就将输入的\(n\)个特征序列都转换为对应的\(n\)个query vector, \(n\)个key vector, \(n\)个value vector, 矩阵化表示这些为 $$Q=XW_Q, K=XW_K, V=XW_V$$
这里的\(Q,K,V\)可以看成都是输入的\(n\)个特征的 不同表示,与原始的特征保持着一一对应关系,比如\(W_Q, W_K, W_V\)都是单位矩阵,那么\(Q,K,V\)就与\(X\)完全一致了。\(softmax(QK^T)\)就表示了输入的\(n\)个特征两两之间的相似性关系,而输出就是依据这个相似度量矩阵,对value vectors进行加权平均。因此序列每个位置的输出,都可以看出输入序列转换后表示的加权平均,加权系数是由当前位置特征与序列所有位置的特征相似度确定的(这里的特征都是转换后的特征),即$$z_i=softmax(\frac{QK^T}{\sqrt{d}})_i V$$
从实际计算过程也可以看出encoder是可以并行计算的。更细致的说明可以参考[1,2]
Encoder Attention层的网络结构
一般由self-attention op, residual op, norm op, feedforward op(linear op, activation op)这几种层操作构成,其它各种模型Attention层可能实现不同,大多数是这些op组成结构及顺序不同而已,本质上没有区别。因为Transformer是Attention开山祖师,因此这里展示一下其网络结构。
注:有一段时间大家密集讨论Transformer论文与代码实现不一致。所以这个论文中网络结构示意图是一个大致介绍,具体实现还是要看实验效果。结果好才是王道。
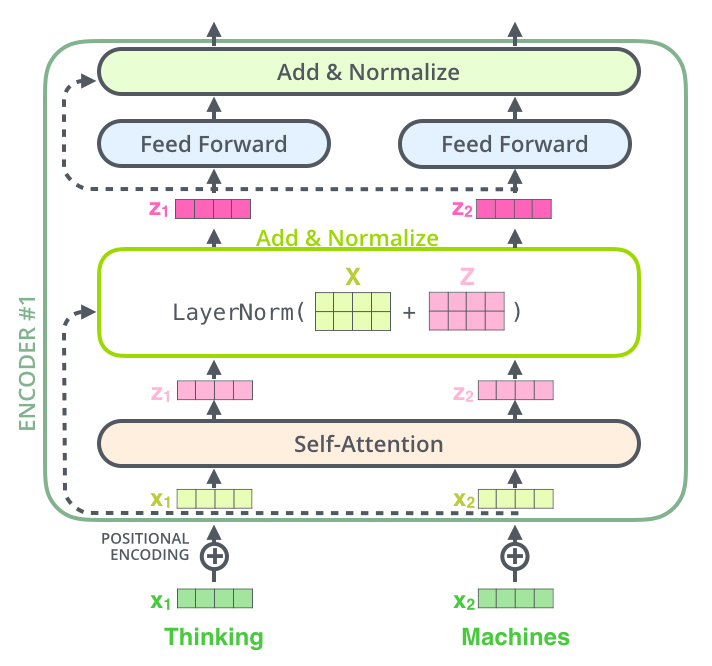
encoder-decoder Attention机制
问题1: Transformer中decoder各个层中的,的K,V来着哪里? encoder模块的最后输出,还是decoder层与coder层对应的K,V呢?
答案1:是Transformer中encoder模块最后输出
首先,原文说明了这一点(但是decoder中的K,V不等于encoder的输出)
the encoder maps an input sequence of symbol representations \((x_1, x_2, \cdots, x_n)\) to a sequence of continuous representations $\pmb z = (z_1, z_2, \cdots, z_n) $. Given $\pmb z $, the decoder then generates an ouput sequence \((y_1, y2, \cdots, y_m)\) of symbols one element at a time.
其次,参考https://github.com/huggingface/blog/blob/main/encoder-decoder.md图示,很清楚展示了,decoder模块中的,K,V是encoder模块输出\(Z\)经过decoder模块各个层的\(W_{K}^{l}, W_{V}^{l}\)映射得到。
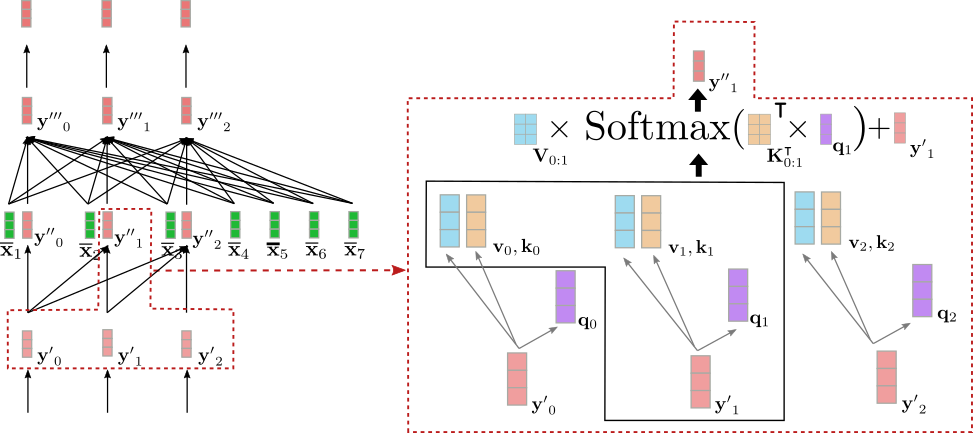
最后,通过下面代码可以看出,在训练过程中,decoder输入包括
- encoder的输出即src的经过encoder编码后的特征
- target
- src_mask
- target_mask
因此Transformer中decoder各个层中的K,V都来着encoder模块的输出,即输入经过encoder模块编码后的特征。
点击展开 Encoder-Decoder主体结构代码
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many
other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask,
tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
问题2:这个与之前的Attention不同之处是什么?
答案2:encoder中的Attention是self-attiention,放到中-英翻译任务中,是中文词这种同一种符号之间的Attention,而decoder层中的encoder-decoder Attention则是中文符号与英文符号之间的Attention,有一点“跨域”的味道。
问题3:Encoder-Decoder mask?
论文主要在Decoder模块提到了对Attention操作时,要Mask,之所以这样,是由于推理过程是自回归模式的,当前生成token是无法与之后生成的token建立联系的。而训练过程这个decoder完整输出是知道的,为了在训练过程中,阻止位置靠前的token与靠后的token建立联系,影响模型训练参数的更新,从而导致训练与推理不一致。于是引入了Mask。
参考 https://ifwind.github.io/2021/08/17/Transformer相关——(7)Mask机制/#xlnet中的mask
问题4:decoder模块,训练和推理有什么不同吗?
Encoder-Only
- bert
Encoder-Decoder
- T5
- GLM
Decoder-Only
- GPT 系列
- LLaMA
参考
http://jalammar.github.io/illustrated-transformer/
http://nlp.seas.harvard.edu/2018/04/03/attention.html
https://zhuanlan.zhihu.com/p/368592551
https://zhuanlan.zhihu.com/p/625184011
https://www.zhihu.com/question/588325646/answers/updated
https://blog.csdn.net/u012193416/article/details/130789895