ASCII
计算机刚出来的时候,只在美国使用,所以美国最开始制定了 ASCII 编码(American Standard Code for Information Interchange,美国信息交换标准代码),于 1963 年发布了 ASCII 的第一版,1967 年经历了一次主要修订,最后一次更新则是在 1986 年,至今为止共定义了 128 个字符;其中 33 个字符无法显示,可显示的字符为 95 个,编号范围是 32-126(0x20-0x7E)。
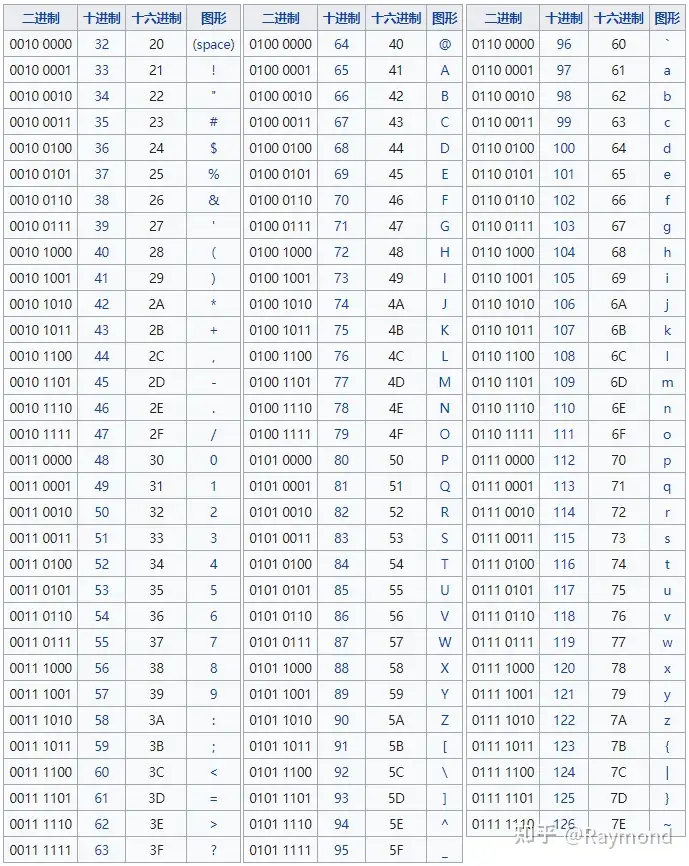
图片来自wikipedia
ISO-8859-1
后来计算机传入欧洲,ASCII 字符集包含的字符不能满足欧洲人民的使用,如一些希腊字母,所以西欧又制定了 ISO-8859-1 字符集,同样是单字节编码,向下兼容 ASCII。其编码范围是 0x00-0xFF,0x00-0x7F 之间完全和 ASCII 一致,0x80-0x9F 之间是控制字符,0xA0-0xFF 之间是文字符号。于 1987 年发布第一版。

图片来自wikipedia
字符集和字符编码
在讲完上面的各种编码之后,要区分清楚一个概念,那就是字符集和字符编码:
- 字符集就是编码和字符的对应关系,比如说,在 ASCII 编码中,一个'A'字符对应'0x42'。不同的对应关系导致了不同字符集的出现。
- 字符编码就是字符在内存中的二进制显示(也可以理解为从理论到实践)。比如,'爱'这个的Unicode对应的字符编码为'0x7231',而使用UTF-8的编码方式,'爱'的字符编码(内存中存储数据格式)为'0xE788B1',UTF-16BE的字符编码为'0x7231'
GB2312
当计算机被引进到中国之后,当时只有欧美国家的字符集,而没有中文的字符编码集,于是国家 1981 年 5 月 1 日发布了简体中文汉字编码国家标准,也就是 GB2312。
字符集
GB2312 字符集对所收录的汉字进行了“分区”处理,每区含有 94 个汉字/符号,共计 94 个区。用所在的区和位来表示字符(如下图所示),因此称为区位码。
- 01~09 区:共有 9 x 94 = 896 个区位,但实际上只使用了 682 个。包括了特殊符号、数字、英文字符、希腊字母、日文平假名及片假名字母、俄语西里尔字母等在内的 682 个全角字符;
- 10~15 区:空区,留待扩展;
- 16~55 区(3755 个,共 3760 个区位):常用汉字(也称一级汉字),按拼音排序;
- 56~87 区(3008 个):非常用汉字(也称二级汉字),按部首/笔画排序;
- 88~94 区:空区,留待扩展。
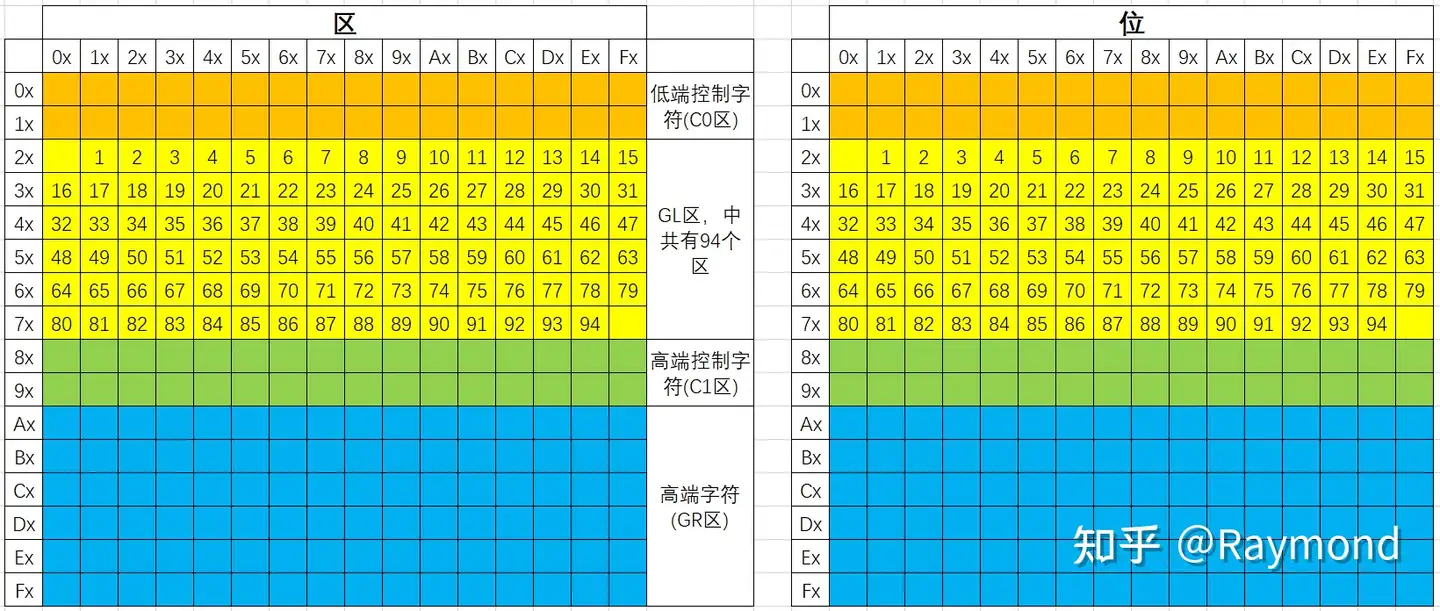
字符编码
GB 2312 的在内存中的字节表示采用了 EUC 储存方法,以便兼容于 ASCII。其中每个汉字及符号以两个字节来表示。第一个字节称为高位字节,第二个字节称为低位字节。
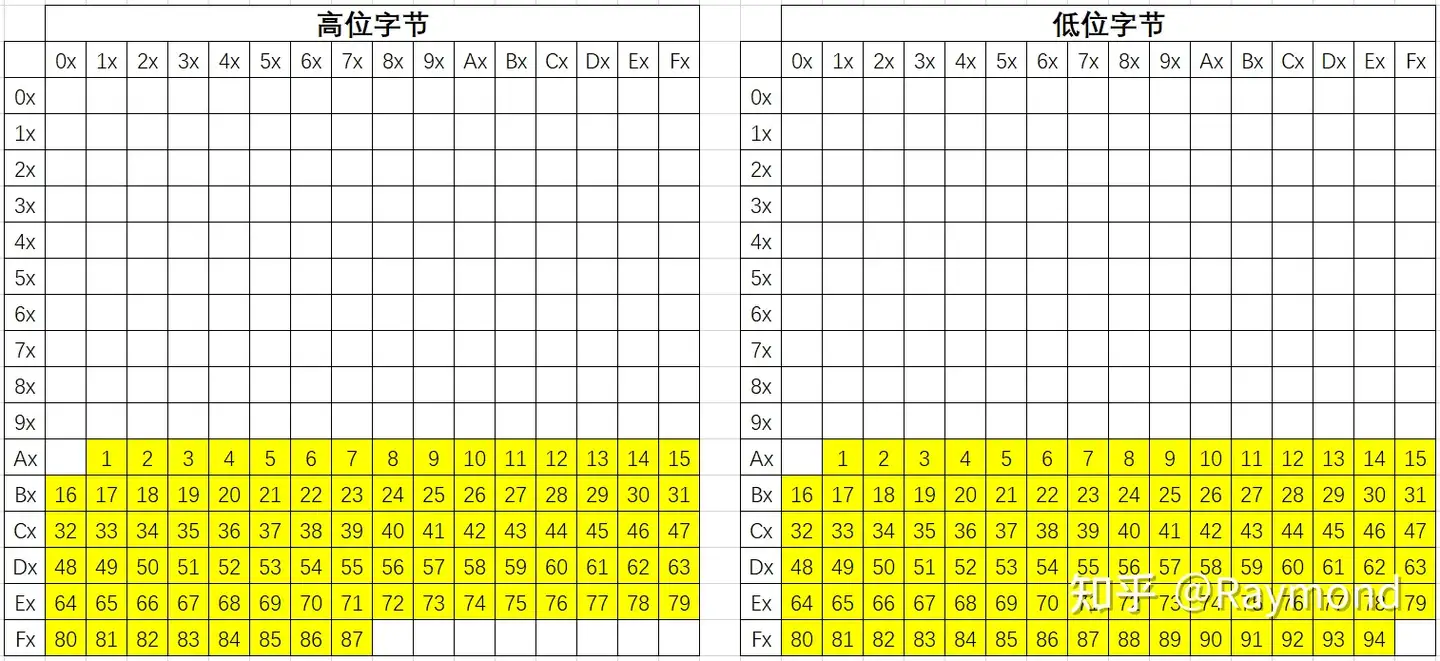
高位字节使用了 0xA1–0xF7(01–87区的区号加上0xA0),低位字节使用了0xA1–0xFE(01–94加上0xA0),所以GB2312字符编码是根据字符的区位号加0xA0(160)形成的。
GBK
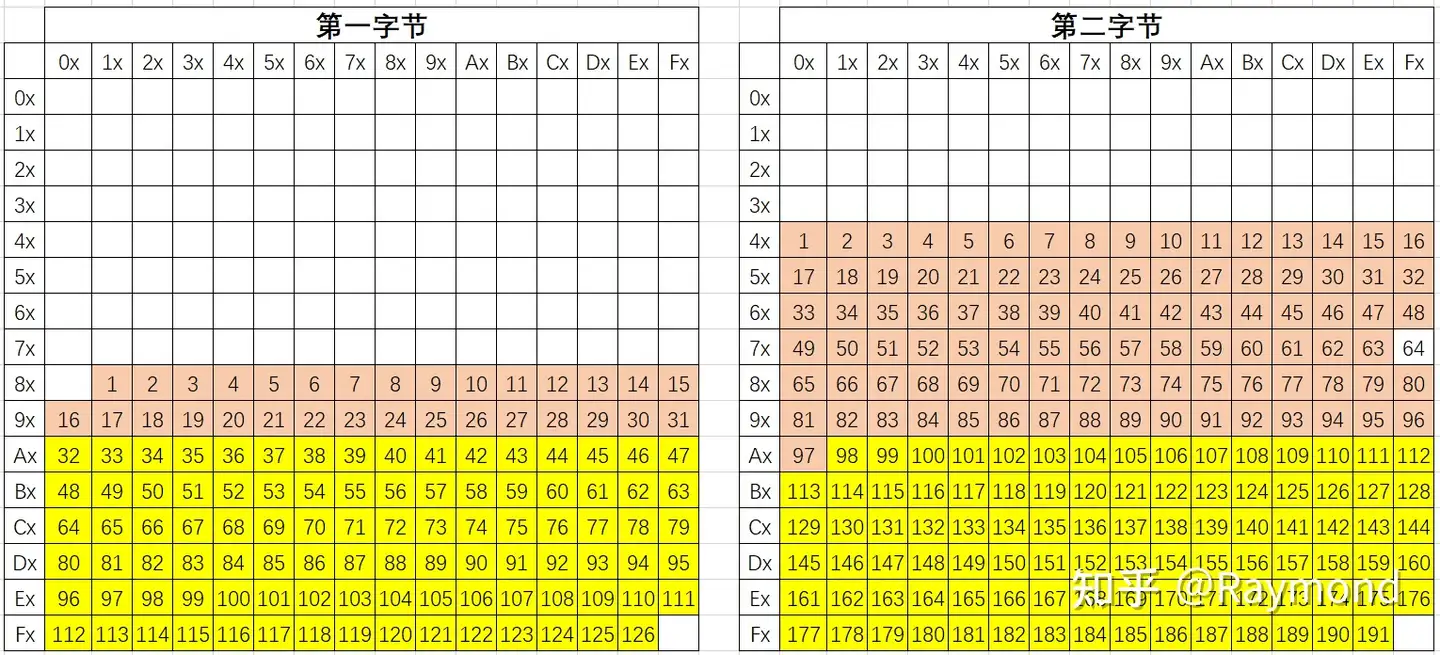
由于 GB2312 只收录 6763 个汉字,有不少汉字,部分人名用字(如朱总理的“镕”字),台湾及香港使用的繁体字等,并未收录在内。所以国家于 1995 年 12 月制定了汉字内码扩展规范,简称 GBK。GBK 同样对汉字采用双字节编码,可以说是对 GB2312 编码的扩充,向下完全兼容 GB2312-80 编码。GBK 突破了 ISO 2022 中 GR 区域字数(共 94²=8836 个字)的限制,GBK 编码的第一字节向 81–FE (126个选项,占用了C1区,从0x81-0xFE) 、第二字节向 40–FE (191个选项,占用了GL区、C1区,从0x40-0xFE) 进行扩展,总共可24066(126x191)个字符(如下图所示)。
GB18030
虽然 GBK 对 GB2312 进行了扩充,包含了生活中的常用字,但是仍有很多的偏僻字没录入。于是国家在 2000 年发布了 GB 18030-2000,在 GBK 基础上增加了 CJK 统一汉字扩充 A 的汉字(中日韩统一表意文字扩展 A 区),兼容 Unicode 3.0。
GB 18030 的当前版本为 GB 18030-2005,于 2005 年 11 月 8 日发布,在 GB18030-2000 基础上增加了 CJK 统一汉字扩充 B 的汉字(中日韩统一表意文字扩展 A 区),更新至 Unicode 3.1。
GB 18030 主要有以下特点:
- 包含三种长度的编码:单字节的ASCII、双字节的GBK(略带扩展)、以及用于填补所有Unicode码位的四字节UTF区块。
- 编码空间庞大,最多可定义 161 万个字符。
- 完全支持 Unicode,无需动用造字区即可支持中国国内少数民族文字、中日韩和繁体汉字以及 emoji 等字符。
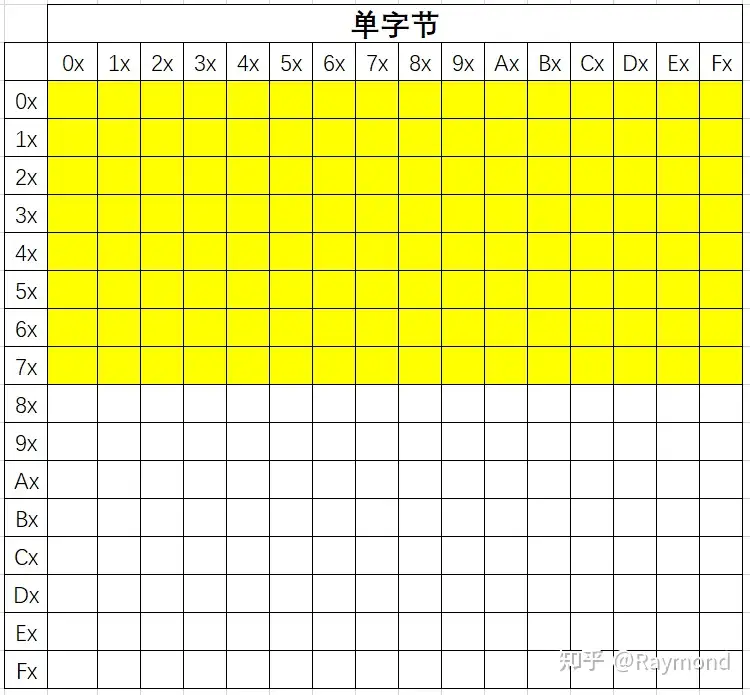
单字节
单字节使用了0x00–0x7F,所以单字节编码兼容ASCII字符集。
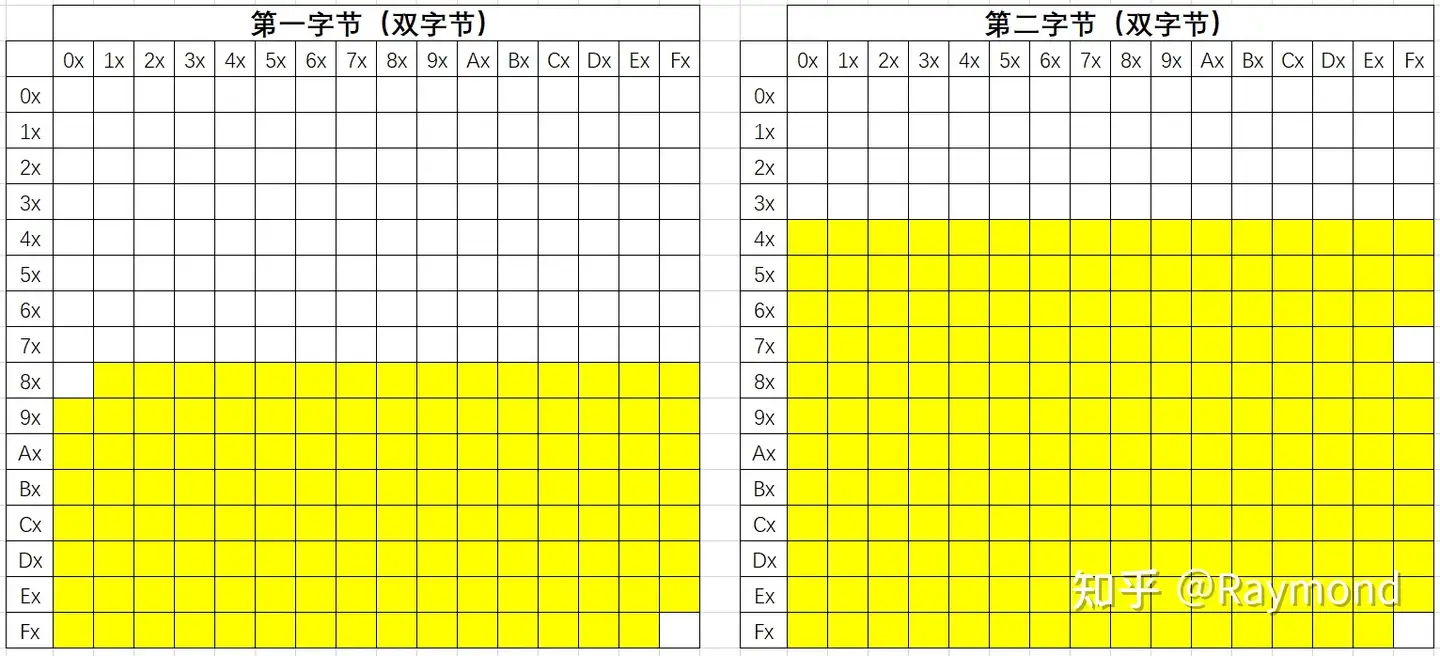
双字节
双字节编码第一字节使用了0x81-0xFE,第二字节使用0x40-0xFE(除去0x7F),跟GBK使用的字节编码一样,所以双字节编码兼容GBK。
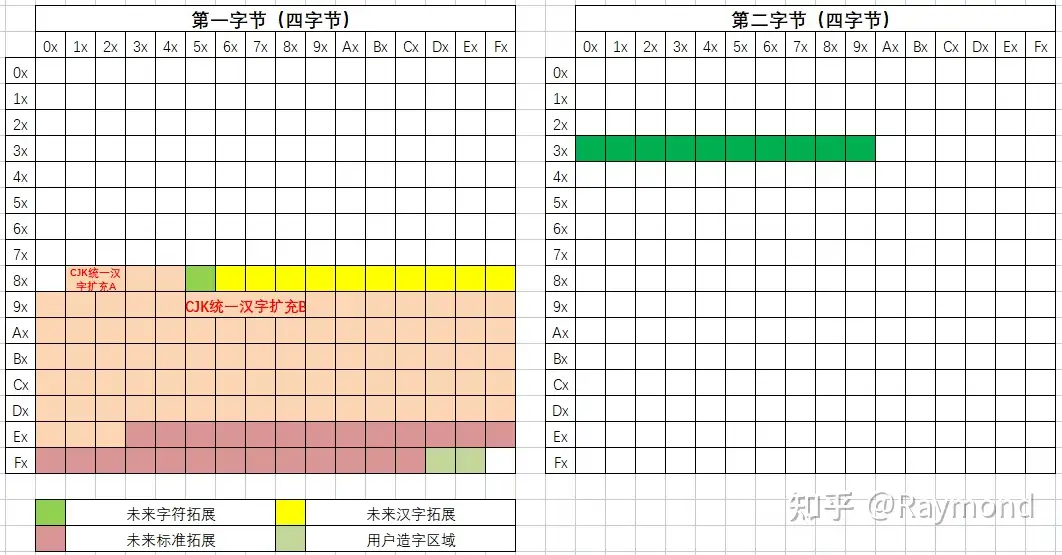
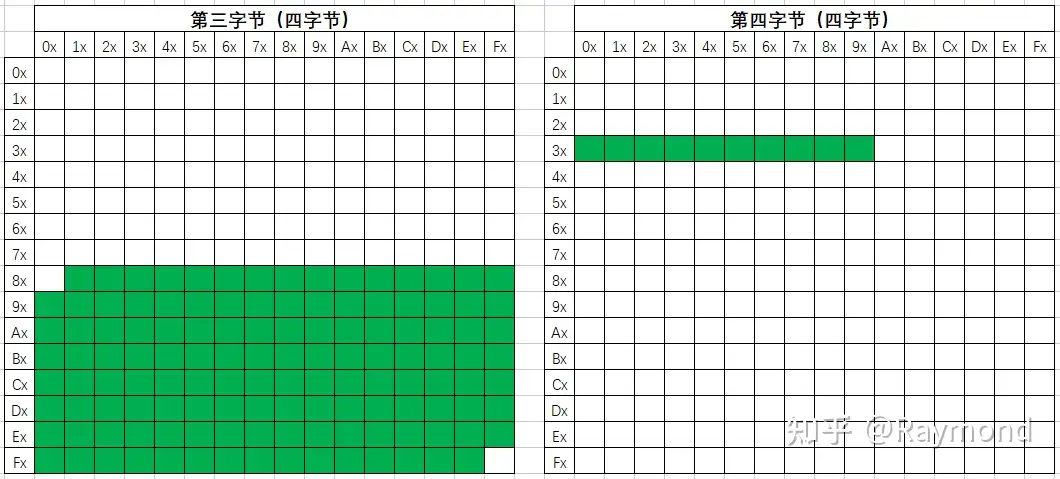
四字节
四字节编码总共可以表达1587600(126×10×126×10)种字符,足以覆盖Unicode的1112064(17×65536 − 2048个代理对)个有效码位。如下图所示,第一字节不同的区域和后面的字符组合,所形成的编码也是有各种不同的用处,包括未来字符拓展区、用户造字区域等。
BIG5
同样,台湾地区使用中文繁体字,也没有现成的字符集可以使用,所以台湾地区制定了 Big5 字符集,采用双字节编码,共收录 13053 个中文字,1984 年实施。
Unicode
每个国家都有自己语言的编码方式,而由于互联网的普及,国与国之间人民群众的交流要求电脑能够处理不同的编码方式,但是由于每个国家字符编码的不同,乱码就产生了。所以人们需要一种能将世界上所有的符号都纳入其中的编码,于是国际统一码联盟在1991年首次发布了Unicode 1.0。
需要注意的是,Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。而且在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。所以Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF),UTF-8,UTF-16都是Unicode字符集的不同编码实现。
目前实例目前实际应用的统一码版本对应于UCS-2(通用字符集:Universal Character Set,简称UCS),也就是UTF-16,使用16位的编码空间,每个字符占用2个字节。这样理论上一共最多可以表示65536个字符,基本满足各种语言的使用。实际上当前版本的统一码并未完全使用这16位编码,而是保留了大量空间以作为特殊使用或将来扩展。
UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种对Unicode的可变长度字符编码。它可以用一至四个字节对Unicode字符集中的所有有效编码点进行编码,由于较小值的编码点一般使用频率较高,直接使用Unicode编码效率低下,大量浪费内存空间。UTF-8就是为了解决向后兼容ASCII码而设计,Unicode中前128个字符,使用与ASCII码相同的二进制值的单个字节进行编码,而且字面与ASCII码的字面一一对应,这使得原来处理ASCII字符的软件无须或只须做少部分修改,即可继续使用。因此,它逐渐成为网络传输中优先采用的编码方式。
UTF-8 的编码规则很简单,只有两条:
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
- 对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
----------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx根据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
UTF-16
根据前面所讲的,UTF-16就是使用固定长度的字节(2字节)来存储字符,所以无法兼容单字节的ASCII字符集。UTF-16的存储形式分为大尾序(Big endian)和小尾序(Little endian)。一般来说,Macintosh(苹果操作系统)使用大尾序格式,Microsoft、Linux使用小尾序格式。
为了让计算机清楚UTF-16文件的采用的是大尾序还是小尾序,一般会在UTF-16文件的开头,放置一个U+FEFF字符作为Byte Order Mark(UTF-16 LE以 FF FE 代表,UTF-16 BE以 FE FF 代表),以显示这个文本文件是以UTF-16编码,其中U+FEFF字符在Unicode中代表的意义是 ZERO WIDTH NO-BREAK SPACE,顾名思义,它是个没有宽度也没有断字的空白。
参考链接:
https://zh.wikipedia.org/wiki/ASCII
https://zh.wikipedia.org/wiki/ISO/IEC_8859-1
https://zh.wikipedia.org/wiki/ISO/IEC_2022
https://zh.wikipedia.org/wiki/Unicode
https://zh.wikipedia.org/wiki/UTF-16
https://tech.you zan.com/strings/
https://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
https://www.qqxiuzi.cn/bianma/zifuj