摘要
介绍自编码器、生成式对抗网络、BERT等无监督深度学习方法,阐述其在电子健康档案数据挖掘领域中的应用及其挑战,指出无监督深度学习技术能够加速医疗知识发现和临床决策支持,促进个性化医学发展。
1. 引言
电子健康档案(Electronic Health Record,EHR)是一种用于收集、存储和提供个体健康记录的纵向医疗保健电子数据。通常包括:
-
人口统计
-
检查结果
-
疾病诊断
-
临床护理
-
用药管理
-
付款和保险等信息
随着人工智能技术发展,利用深度学习等数据驱动方法对EHR进行二次利用,在多个重要领域都有重要应用价值:
-
临床决策支持
ArslanTS,AkilotuB,ToramanSADeepLearning-based DecisionSupportSystem forDiagnosisofOSASUsingPTT Signals[J].MedHypotheses,2019(127): 15-22
-
疾病亚型发现
LandiI,GlicksbergBS,LeeH C,etalDeepRepresenta tionLearningofElectronicHealthRecordstoUnlockPatient StratificationatScale[J]. NPJDigitalMedicine,2020 (3):96
-
药物警戒
CocosA,FiksAG,MasinoAJDeepLearningforPharma covigilance:RecurrentNeuralNetworkArchitecturesforLa belingAdverseDrugReactionsinTwitterPosts[J].JAm MedInform Assoc,2017,24(4):813-821
-
医学概念提取
LiFFine-TuningBidirectionalEncoderRepresentations From Transformers(BERT)-BasedModelsonLargeScaleElectronicHealthRecordNotes:AnEmpiricalStudy [J].JmirMedicalInformatics,2019,7(3):e14830.
-
临床结局预测
MiottoR,LiL,KiddBA,etalDeepPatient:AnUnsuper visedRepresentationtoPredicttheFutureofPatientsfrom the ElectronicHealthRecords[J].SciRep,2016(6):26094.
然而EHR数据存在非结构化文本较多、数据隐私性较高、标注样本昂贵稀缺的问题,难以进行数据挖掘。
以自编码器AE,生成式对抗网络GAN和基于Transformer的双向编码器表征(BERT)为代表的无监督深度学习技术能从富含噪声、无标注的原始数据中提取关键信息并直接对数据进行建模,实现特征提取、数据生成、结构化表示等功能,在解决EHR数据挖掘难点方面具有潜力
2. 无监督深度学习技术
无监督学习可以在没有额外信息的情况下直接从原始数据中学习潜在的模式,以发现隐藏在原始数据中有价值的信息,例如:有效特征、类别、结构、概率分布等
其主要包括自编码器、生成式对抗网路、BERT等。无监督深度学习模型使用卷积神经网络CNN,循环神经网络RNN等作为每个网络层的基础结构,利用随机梯度下降SGD,Adam,RMSprop等优化方法训练深度神经网络以完成模型的学习。
因模型结构和计算过程的差异性,不同无监督深度学习方法在EHR数据挖掘主要应用方法不同,如下图。

本文对AE、GAN、BERT原理及其在EHR数据挖掘中的具体应用进行介绍。
3. 无监督深度学习技术原理及在EHR数据挖掘中的应用
3.1 自编码器AE
3.1.1 基本概念
一种使用反向传播算法使模型 期望预测输出值等于输入值的神经网络。其将高维 输入压缩为低维的隐层表征并用以重构输出值。自 编码器 由 编 码 器 (Encoder) 和 解 码 器 (Decoder) 构成。对于任一给定输入向量 x,首先在表示为 h= f(x) 的编码器中编码为低维隐层向量,再通过表 示为 y=g(h) 的解码器进行输出,其中 x与 y的 维度相同。因此自编码器计算过程可以用 y=g(f (x)) 表示,而模型训练目标为最小化输入向量与 输出向量之间的差异,可以表示为 minLoss(x,g (f(x)))。
3.1.2 特点
相较于主成分分析PCA等线性无监督学习方法,自编码器使用神经网络作为基础结构,通过不同激活函数实现非线性推广;同时自编码器可以通过叠加神经网络层数使编码器和解码器更复杂,从而学习得到更有效的表示,更为重要的是,字面密码器作为一种通用数据驱动型计算模型,可以使用从另一相关数据中预先训练得到的模型或部分模型,通过迁移学习和微调的方式增强当前任务自编码器表征性能以及降低训练耗时,大幅扩展自编码器应用范围,使其在小样本中有较好的效果
3.1.3 基于自编码器的EHR数据挖掘
目前AE在数据去噪以及数据降维、可视化等领域具有广泛应用,同时可用于特征提取、分类及异常值检测等任务。
由于AE能够以无监督方式自动学习有效特征且不同的EHR数据的特征类别具有较高的一致性,因此AE具有在大规模EHR数据中进行无监督学习的潜力,其编码器输出的低维稠密向量可在降维、聚类后用于患者分层,也可嵌入线性分层或与随机森林等分类模型用于临床结局预测;而其解码器输出的向量与模型的输入信息相似,可被设计以实现隐私保护、数据合成等。
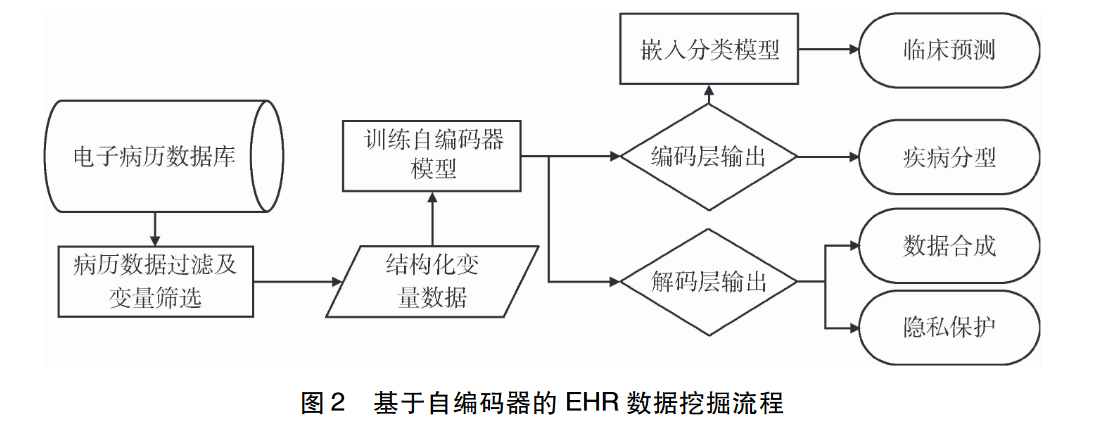
3.1.4 相关研究
-
Deep Patient使用3层去噪自编码器自动学习EHR数据中的分层规律和依存关系,将自编码器学习到的深层表征作为随机森林分类器的输入,用于预测患者未来患病的可能。结果表明基于自编码器模型的预测性能优于PCA、K-Means等传统算法无监督学习算法。
MiottoR,LiL,KiddBA,etalDeepPatient:AnUnsuper visedRepresentationtoPredicttheFutureofPatientsfrom the ElectronicHealthRecords[J].SciRep,2016(6):26094
-
convAE使用词嵌入、卷积神经网络和自编码器提取电子病历深度表征并在复杂疾病的临床亚型分型任务中取得最优性能
LandiI,GlicksbergBS,LeeH C,etalDeepRepresenta tionLearningofElectronicHealthRecordstoUnlockPatient StratificationatScale[J]. NPJDigitalMedicine,2020 (3):96.
-
SDAE是以哦那个规范化的堆叠式去噪自编码器,根据大量急性冠状动脉综合症EHR数据完成患者分层和临床风险预测任务并取得具有竞争优势的预测性能
HuangZ,DongW,DuanH,etalA RegularizedDeep LearningApproachforClinicalRiskPredictionofAcuteCor onarySyndrome Using Electronic Health Records[J]. IEEETransBiomedEng,2018,65(5):956-968.
3.1.5 应用价值
AE可作为自动学习EHR深层表示的通用框架,这种无监督学习方式不仅消除了昂贵费时的手工特征工程步骤,还能以数据驱动的方式学习真实世界样本中的潜在表示,具有广阔的临床应用场景
3.2 生成式对抗网络GAN
3.2.1 基本概念
GAN主要包括生成器和判别器两部分,其中生成器用于根据给定的输入信息生成一个尽可能“以假乱真”的数据,判别器用于判断生成器所生成的数据是否为真实样本。
最初训练过程中生成器仅恩生成充满噪声的数据,而判别器可以很精准的识别,之后模型不断地迭代,当生成器可以生成与真实数据分布相同的数据时,判别器无法判断数据来源,这是认为模型已经完成训练并可以应用相关数据的生成任务中去。
目前GAN已经成功应用于图像生成、风格迁移、信息补全等领域中并达到目前最先进技术效果;同时在文本生成、结构化数据生成等方面也有大量应用。
3.2.2 在EHR数据挖掘中的应用场景
对于部分特殊疾病来说,EHR数据是稀缺的;同时受医疗数据法律、隐私和安全等因素影响,完整EHR数据的获取难度较大。为了规避这些问题,可以考虑通过自动生成逼真的合成数据进行EHR数据挖掘;对于EHR扩增方面,相较于基于概率统计和临床实践指南的传统方法,基于GAN的无监督方法通用性更广,并且可以自动从数据中学习到真实样本分布,而不是依靠先验知识。基于GAN的EHR数据挖掘流程较为简单,研究者可以直接通过将随机噪声向量输入训练后的生成式对抗和网络以得到与训练EHR数据分布相似的合成数据,以解决EHR数据合成和隐私保护问题。
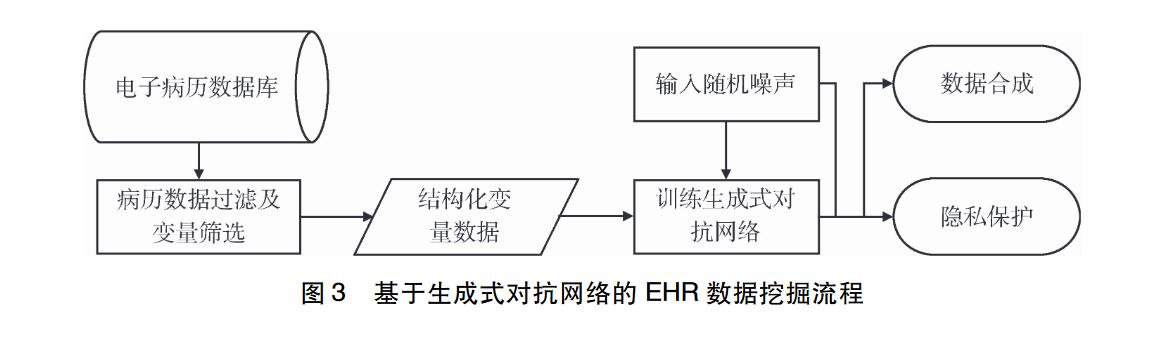
3.2.3 相关研究
-
DAAE将递归自编码器与GAN相结合,在生成时间序列EHR数据时取得了最优的似真性评分
DonghaLeeGeneratingSequentialElectronicHealth Re cordsUsingDualAdversarialAutoencoder[J].Journalof theAmerican MedicalInformaticsAssociation, 2020,27 (9):1411-1419. 19
-
MedGAN结合AE和GAN以合成高质量的EHR离散数据,在数据分布统计和预测建模等任务中实现了与真实数据相当的性能
ChoiE,BiswalS,MalinB,etal.Generatingmulti-label discretepatientrecordsusinggenerativeadversarialnetworks [C].AnnArbor,Michigan:MachineLearningforHealth careConference,PMLR,2017:286-305. 20
-
MedWGAN、MedBGAN为对MedGAN进行改进,提高了关联规则挖掘和疾病预测方面的性能。
BaowalyM K,LinCC,LiuCL,etalSynthesizingElec tronicHealthRecordsUsingImprovedGenerativeAdversari alNetworks[J].JournaloftheAmericanMedicalInfor maticsAssociation:JAMIA,2019,26(3):228-241
-
隐私保护方面,GAN生成的合成数据与真实样本没有显示映射,而针对MedGAN、DAAE等生成式对抗网络的隐私实验结果表明,基于生成式对抗网络产生的EHR合成样本的潜在隐私暴露风险较低
3.3 BERT
3.3.1 基本概念
BERT是一种基于Self-Attention的Transformer结构组成,相较于自然语言处理中较为常用的循环神经网络Transformer计算速度更快并能进行深层堆叠。BERT构建了两种无监督训练过程:
-
MLM(Mask Language Model)对部分输入句子中的字进行随机掩盖并通过训练BERT模型以预测被掩盖的字来学习句子内部关系
-
NSP(Next Sentence Prediction)一次输入两个句子并训练BERT模型以预测两个句子相邻的概率来学习句子之间的关系。
通过构建MLM和NSP训练目标,BERT能够以无监督的方式从无标注的文本中进行预训练,完成预训练过程之后,BERT模型可以通过在模型后端嵌入不同结构以应用到不同自然语言处理任务中,例如文本分类、命名实体识别、语义提取等
3.3.2 基于BERT的EHR数据挖掘
在EHR数据挖掘领域,由于BERT模型的参数量较为庞大、训练时间较慢,研究者常在开源的BERT预训练模型的基础上使用EHR自由文本进行微调。在下游任务方面,研究者可使用微调后的BERT模型输出临床文本的表示向量以用于语义相似性计算,或嵌入线性分类层进行临床预测任务研究

3.3.3 应用情况
-
医学识别方面,EHR-BERT从EHR中识别药物、诊断、不良事件等医学临床实体并将其规范化。识别医学临床实体可以将非结构化文本转化为结构化数据,这对临床决策支持、医学知识发现等基于EHR的数据挖掘研究具有重要作用
LiF,JinY,LiuW,etalFine-TuningBidirectionalEn coderRepresentationsFrom Transformers(BERT)-Based ModelsonLarge-ScaleElectronicHealthRecordNotes:An EmpiricalStudy[J].JMIR MedInform,2019,7(3): e14830.
-
临床预测方面,TAPER利用BERT模型将EHR中的非结构化文本嵌入到统一向量空间中表示,有效的将患者信息编码为可用于下游任务的形式,增加EHR有效信息量并将其应用于存活、重复入院等临床结局事件预测之中
DarabiS,KachueeM,FazeliS,etalTAPER:Time-A warePatientEHR Representation [J]. IEEE JBiomed HealthInform,2020,24(11):3268-3275.
-
语义相似性方面,由于基于模板和临床笔记生成的EHR数据存在较多冗余信息,需要对EHR数据进行压缩,而计算临床文本片段的语义相似性是一种解决方法。
-
MahajanD、PoddarA和 LiangJJ等将多 任务学习方法应用于 ClinicalBERT模型中,在临床 语义文本相似性任务中取得了最优预测性能。
MahajanD,PoddarA,LiangJJ,etalIdentificationofSe manticallySimilarSentencesinClinicalNotes:IterativeIn termediateTraining Using Multi-Task Learning [J]. JMIRMedInform,2020,8(11):e22508.
3.4 无监督深度学习技术技术研究情况
目前,无监督深度学习技术研究在疾病亚型分析、临床结局预测等多个细分医学领域研究已取得较大成果,但其在EHR数据挖掘中的通用性应用尚未成熟,具体主要体现在大多研究的额建模数据来源不具有普适性和代表性。
例如ConvAE、EHR-BERT等研究使用数据规模教导,但均为医院未公开的EHR数据,虽然保证了数据一致性,但将其迁移至不太用来源的EHR数据会存在数据分布差异问题。
TAPER、DAAE等使用的MIMIC-III等公共EHR数据库进行建模,但缺乏实际应用场景下的外部验证集评估。因此如何有效的将无监督深度学习技术应用到EHR数据并指导临床实践仍有待进一步研究。
EHR数据挖掘的无监督深度学习模型及其主体模型结构和应用场景见下图
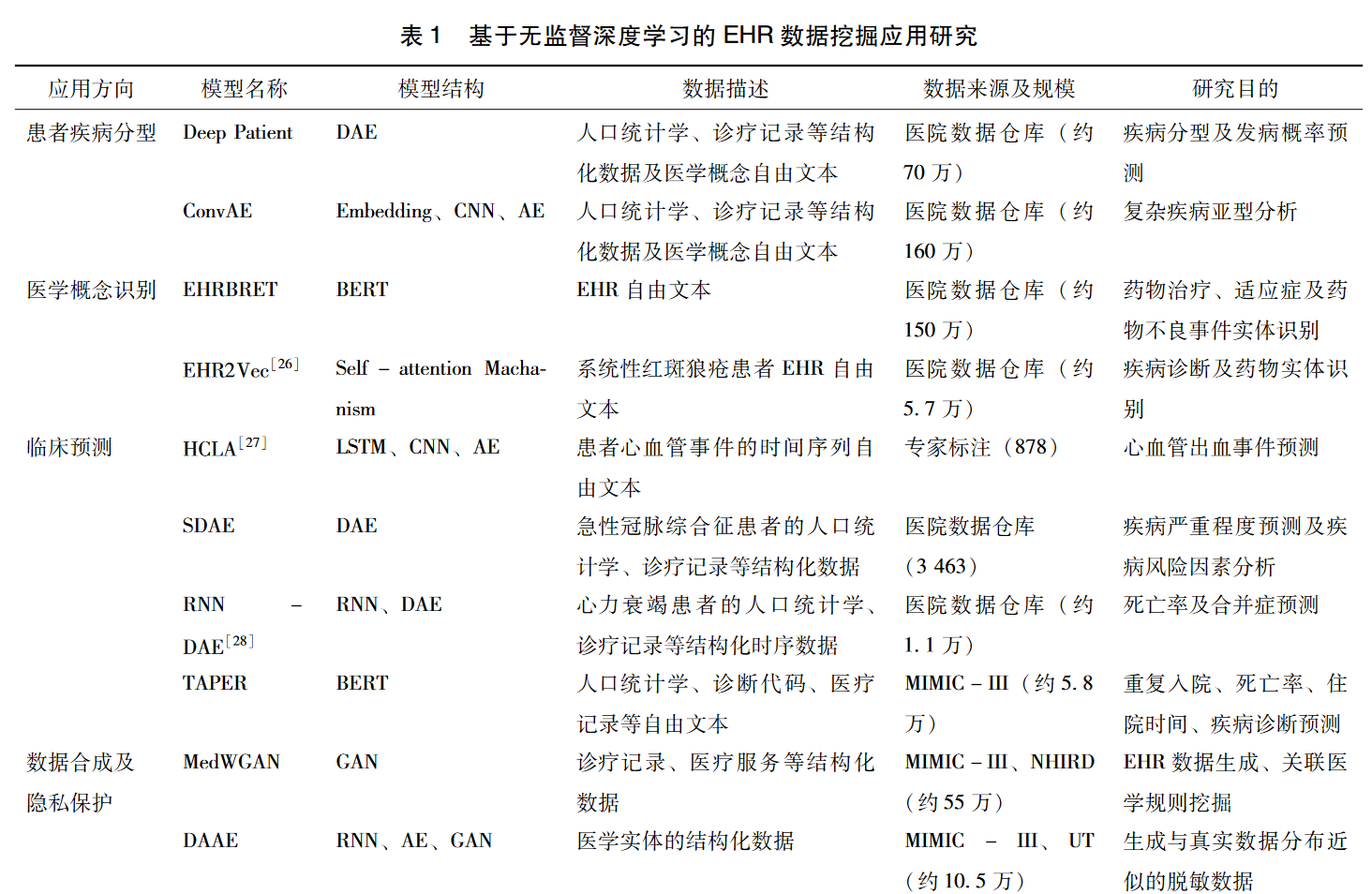

4.无监督深度学习的局限性
4.1缺乏可解释性
深度学习是一种“黑盒”模型,研究人员尚未能揭示深度学习模型在训练过程中学习参数矩阵的具体意义,EHR数据使用自编码器、BERT等无监督学习方法得到的潜在表示无法被合理的解释,而临床决策支持、患病风险预测等临床具体应用需要预测工具的计算方法具有可转化为临床知识的能力,这使得无监督学习在临床实践中应用较为受限。
4.2 异构数据处理困难
EHR中存储有包括人口统计学、疾病诊断、实 验室检查、影像报告、用药情况等多源异构数据, 从数据结构上来说包括非结构化文本、图像、类别 特征、实值特征等,单一无监督学习技术无法有效 处理全部 EHR信息。开发基于无监督学习的通用 异构信息处理框架是最大程度利用 EHR数据、促 进临床应用的重点研究方向。
4.3 缺乏通用基准测试
大多用于 EHR数据挖掘的无监督深度学习模 型多采用私有数据集,并且受患者数据敏感性限制 EHR数据共享较难推进;有研究声称该模型具有最 先进性能却较少有充足外部验证过程。因此缺乏通 用基准测试数据集和算法是目前开发适合于 EHR 数据的无监督深度学习模型的障碍。
在 EHR数据挖掘领域,使用海量 EHR数据 训练的无监督深度学习模型可用于生成模拟数据、 处理冗余文本信息和特征提取,是患者隐私保护、 结构化表 示 和 临 床 预 测 等 关 键 问 题 的 重 要 解 决 方 法。随着信息化技术的发展和人力成本的增加,急 剧扩增的 EHR数据中无标注样本的占比逐渐增大; 虽然 EHR数据共享不断加深,但数据隐私保护及 多源异构问题阻碍了监督学习在 EHR数据挖掘中 的广泛应用。而无监督深度学习相比于监督学习和 统计分析等方法具有数据驱动、通用性强等优点, 能够从大规模 EHR数据中挖掘、提取、发现有效 信息,助力临床医学研究。