1 标量的导数

2 亚导数
比如说\(y=|x|\)这个函数在x=0的时候时不可导的。当x>0,其到导数为1,x<0,其导数为-1,所以在x=0的这个地方的亚导数就是可以是[-1,1]中的一个数

梯度
这里主要搞得清楚他的形状
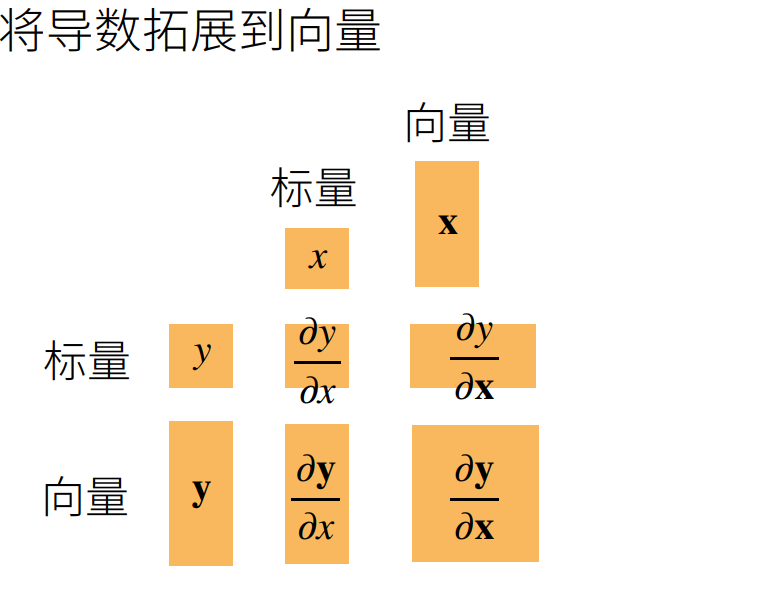
- ∂y/∂x
当y是标量,x是向量的时候:

它的结果是个横着的
矩阵求导
向量化的优点
1.简洁
比如说:
\(
\begin{split}\begin{cases}
y_1=W_1*X_{11}+W_2*X_{12}+...+W_n*X{1n}\\
y_2=W_1*X_{21}+W_2*X_{22}+...+W_n*X{1n}\\
.....\\
y_n=W_1*X_{n1}+W_2*X_{n2}+...+W_n*X{nn}\\
\end{cases}\end{split}\)
这个函数可以简化成
2.加速计算机的计算
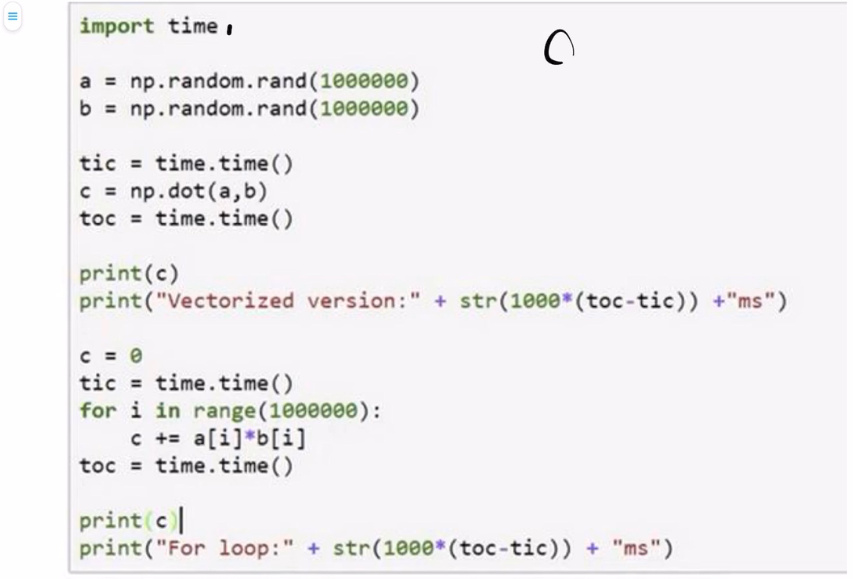
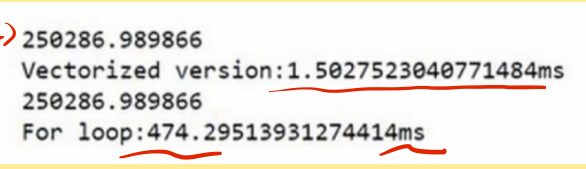
对于同样一个矩阵相乘的操作,我们可以我们可以看出用矩阵的话是1.5ms,但是如果用for循环的话是474ms。
标量函数和向量函数
标量函数
其实标量函数就是最后运算之后输出为标量的函数,例如:
- \(f(x)=x^2,其中x->x^2\)
- \(f(x)=x_1^2+x_2^2\),其中\(\begin{bmatrix} X_1\\ X_2\\ \end{bmatrix}=>X_1^2+X_2^2\)
这两个最终的运算结果都是一个标量。
向量函数
就是最后运算结果为一个向量,例如:
① \(f(x)=\begin{bmatrix}
f_1(x)=X\\
f_2(x)=X^2\\
\end{bmatrix}, x->\begin{bmatrix}
X\\
X^2\\
\end{bmatrix}\)
② \(f(x)=\begin{bmatrix} f_1(x)=X,f_2(x)=X^2\\ f_3(x)=X^3,f_4(x)=X^4\\ \end{bmatrix}, 其中:x->\begin{bmatrix} X,X^2\\ X^3,X^4\\ \end{bmatrix}\)
③ \(f(x)=\begin{bmatrix} f_1(x)=X_1+X_2,f_2(x)=X_1^2+X_2^2\\ f_3(x)=X_1^3+X_2^3,f_4(x)=X_1^4+X_2^4\\ \end{bmatrix} , \begin{bmatrix} X_1\\ X_2\\ \end{bmatrix} ->\begin{bmatrix} X_1+X_2,X_1^2+X_2^2\\ X_1^3+X_2^3,X_1^4+X_2^4\\ \end{bmatrix}\)
矩阵求导
\(\frac{dA}{dB}\):矩阵求导的本质就是矩阵A中的每一个元素对矩阵B中的每个元素求导。
然后从求导后的元素个数角度:
因为他是矩阵A中的每个元素对矩阵B中的每个元素,所以是这样的形状。
| A | B | \(\frac{dA}{dB}\) |
|---|---|---|
| $$1\times1$$ | $$1\times 1$$ | $$1\times 1$$ |
| $$1\times p$$ | $$1\times n$$ | $$p\times n$$ |
| $$q\times p$$ | $$m\times n$$ | $$p\times q\times m\times n$$ |
求导方法
\(YX\)拉伸,其中\(Y\)横向拉伸,\(X\)纵向拉伸。
这里的前面,后面指的是\(YX\)或者是\(XY\),这里本文用的是\(YX\)。
例一:f(x)标量,x向量
\(\frac{df(x)}{dx}\),其中f(x)就是Y,f(x)为标量函数,x为向量。也就是\(f(x)=f(x_1,x_2,x_3...x_n),x=[x_1,x_2,x_2...n]^T\)
我们按照上面的规则,f(x)是标量不变,拉伸,X纵向拉伸。
这个实际上就是将多元函数的偏导写在一个列向量中。
例二:f(x)向量,x标量
\(\frac{df(x)}{dx}\),f(x)为向量函数,x为向量。也就是\(f(x)=\begin{bmatrix}
f_1(x)\\
f_2(x)\\
...\\
f_n(x)\\
\end{bmatrix}\),然后这个f(x)横向拉伸,x不变。
最终结果就是:
\(\frac{df(x)}{dx}=\begin{bmatrix}
\frac{\partial f_1(x)}{\partial x},\frac{\partial f_2(x)}{\partial x}...\frac{\partial f_n(x)}{\partial x}\\
\end{bmatrix}\)
例三:f(x)为向量函数,x为向量函数
\(f(x)=\begin{bmatrix}
f_1(x)\\
f_2(x)\\
...\\
f_n(x)\\
\end{bmatrix},x=\begin{bmatrix}
x_1\\
x_2\\
...\\
x_n\\
\end{bmatrix}\)
然后我们按照我们的规则,前面的横向拉伸,后面的纵向拉伸,然后本质就是A中的每个元素对矩阵B中的每一个求导。
我们看完上面这个对矩阵求导后的形状应该就了解了,上面的图也应该就知道了。
常见矩阵求导公式的推导
例一:\(f(x)=A^T*X\),求\(\frac{df(x)}{dx}\)
其中:
\(A=\begin{bmatrix}
a_1\\
a_2\\
...\\
a_n\\
\end{bmatrix},x=\begin{bmatrix}
x_1\\
x_2\\
...\\
x_n\\
\end{bmatrix}\)
我们可以看出f(x)是标量,x是向量。
解:\(f(x)=A^T*X=\sum^n_1{a_i*x_i}\)
所以要把x纵向展开
\(\frac{df(x)}{dx}=\begin{bmatrix}
\frac{\partial f(x)}{\partial x_1}\\
\frac{\partial f(x)}{\partial x_2}\\
\frac{\partial f(x)}{\partial x_3}\\
...\\
\frac{\partial f(x)}{\partial x_n}\\
\end{bmatrix}=\begin{bmatrix}
a_1\\
a_2\\
a_3\\
...\\
a_n\\
\end{bmatrix}=A\)
ps:这里\(\frac{\partial f(x)}{\partial x_1}=a_1\)是因为\(f(x)=\sum^n_1{a_i*x_i}\),对于除了\(a_1*x_1\)在外的其他项,对\(x_1\)求偏导都是0。
也可以这样看,\(\frac{d(A^T*X)}{dx}=\frac{d(X^T*A)}{dx}=A\)
例二:\(f(x)=X^T*A*X\)
这个可以自己证明一下,最终结果为\((A+A^T)X\).
两种布局
- 两种布局:
- 向量求导时的拉伸方向:
都是前面的横向拉伸,后面的纵向拉伸
-
YX拉伸术-->分母布局
Y横向拉伸(f(x)横向拉伸)
X纵向拉伸 -
XY拉伸术-->分子布局
X横向拉伸
Y纵向拉伸(f(x)横向拉伸)