一、选题背景
近年来,面对复杂严峻的国际环境,我国经济发展显示出了强大的韧性和潜力,经济增速始终在全世界主要经济体中处于领先位置,这为居民收入增长提供了坚实基础和保障。同时也要充分认识到,疫情防控平稳转段后,经济恢复是一个波浪式发展、曲折式前进的过程,不可能一帆风顺。经济全球化的日益深入发展,各国的经济发展也日益重要。在中国,省份是经济发展的基本单位,各省之间经济发展水平的差异较大。了解省份GDP的数据情况,对于政府部门制定地区经济政策、企业拓展市场等具有重要的参考意义。
二、数据分析实现步骤
数据来源:https://data.stats.gov.cn/easyquery.htm?cn=E0101
爬取国家统计局西南地区省份近13个月居民消费指数进行数据爬取,数据整理,经过数据清洗与预处理,数据可视化并完成数据分析
程序设计
需要的库
爬虫部分
1 #导入需要的包 2 import requests #访问请求 3 import re 4 import time 5 import selenium.webdriver as web 6 import xlwt 7 import os 8 import copy 9 import requests 10 import numpy as np 11 import pandas as pd 12 from bs4 import BeautifulSoup 13 import time 14 import json 15 #忽略警告 16 import warnings 17 warnings.filterwarnings("ignore") 18 #生成时间戳的函数 19 def getTime(): 20 return int(round(time.time() * 1000)) 21 #网址 22 url='https://data.stats.gov.cn/easyquery.htm?cn=E0101' 23 headers={'User-Agent':'Mozilla/5.0(Windows;U;Windows NT6.1;en-US;rv:1.9.1.6) Geko/20091201 Firefox/3.5.6'}#浏览器代理 24 key={}#参数键值对 25 key['m']='QueryData' 26 key['dbcode']='fsyd' 27 key['rowcode']='reg' 28 key['colcode']='sj' 29 key['wds']='[{"wdcode":"zb","valuecode":"A01010101"}]' 30 key['dfwds']='[{"wdcode":"sj","valuecode":"LAST13"}]' 31 key['k1']=str(getTime()) 32 r=requests.get(url,headers=headers,params=key,verify=False) 33 js=json.loads(r.text)#存入json文件 34 js
1 length=len(js['returndata']['datanodes'])#查询json文件长度 2 length

1 js['returndata']['datanodes'][1]['data'] #查询所需数值的位置

逐行读取数据
1 def getList(l): 2 List=[] 3 for i in range(l): 4 try: 5 List.append(eval(js['returndata']['datanodes'][i]['data']['strdata'])) 6 except SyntaxError: 7 List.append('') 8 return List 9 #根据每行数据得到整体的数据 10 lst=getList(length) 11 lst
转换格式并保存为df格式
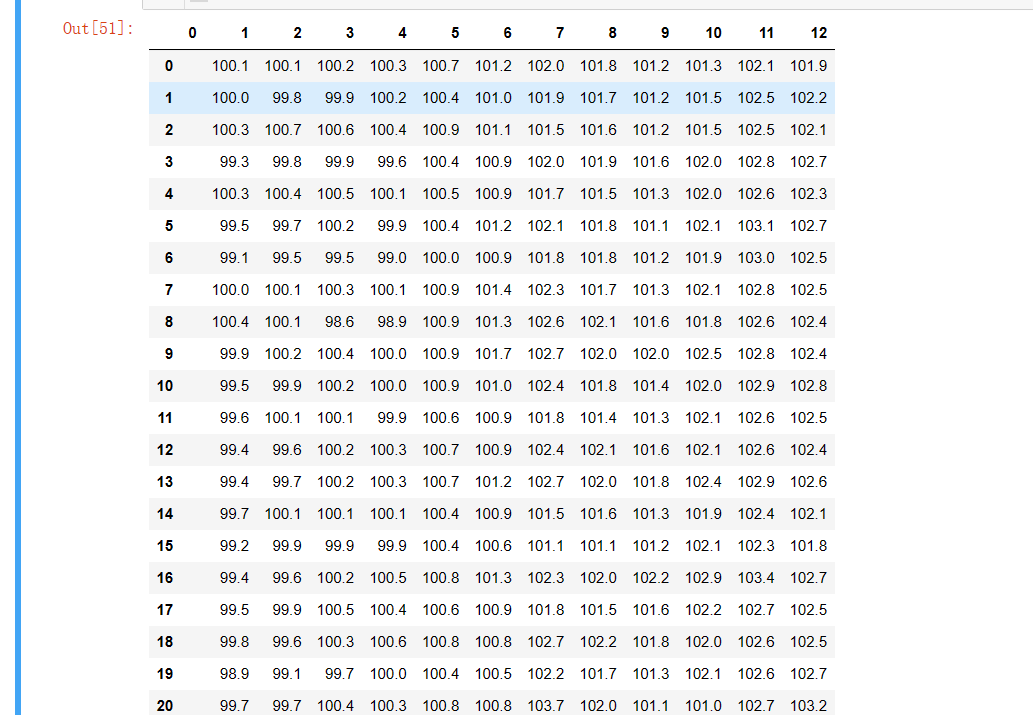
1 array=np.array(lst).reshape(31,13)#转换成9*13的格式 2 df=pd.DataFrame(array)#保存为df格式 3 df
重新写坐标值
1 df.columns=[ '2023年8月','2023年7月','2023年6月','2023年5月','2023年4月','2023年3月','2023年2月','2023年1月','2022年12月','2022年11月','2022年10月','2022年9月','2022年8月'] 2 df.index=['北京市','天津市','河北省','山西省','内蒙古自治区','辽宁省','吉林省','黑龙江省','上海市','江苏省','浙江省','安徽省','福建省','江西省','山东省','河南省','湖北省','湖南省','广东省','广西壮族自治区','海南省','重庆市','四川省','贵州省','云南省','西藏自治区','陕西省','甘肃省','青海省','宁夏回族自治区','新疆维吾尔自治区'] 3 df
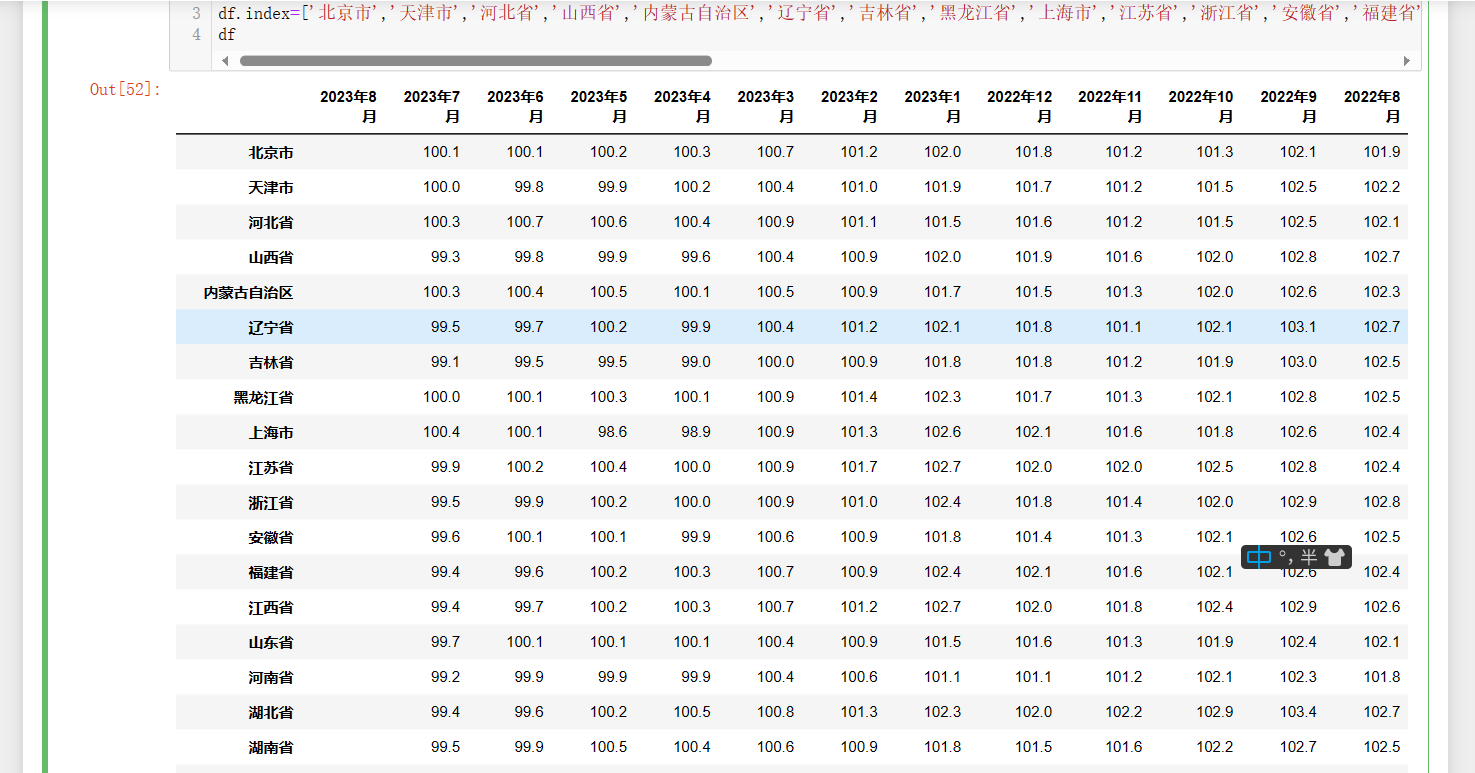
筛选目的的西南地区省份
df_new=df.loc[['重庆市','四川省','贵州省','云南省','西藏自治区']] df_new.columns=[ '2023年8月','2023年7月','2023年6月','2023年5月','2023年4月','2023年3月','2023年2月','2023年1月','2022年12月','2022年11月','2022年10月','2022年9月','2022年8月'] df_new
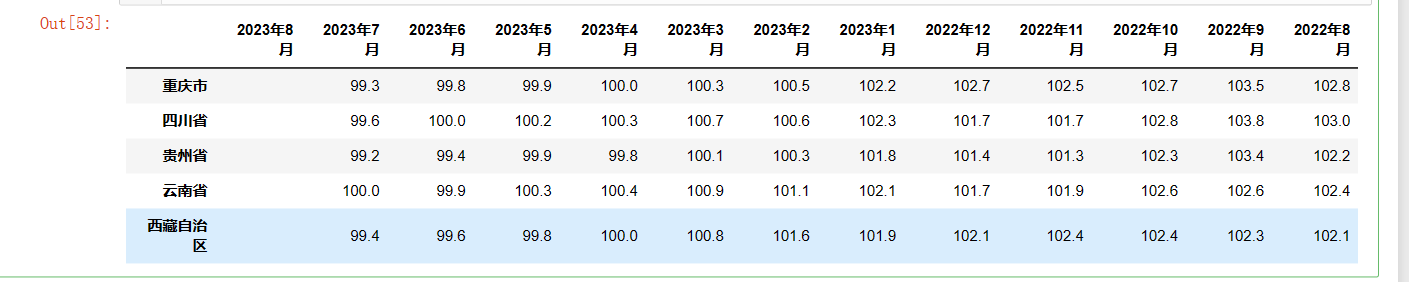
将数据保存到excel
1 df_new.to_excel('西南五省近13个月月度数据.xlsx',index=True) #存入excel表格,命名为’西南五省近13个月月度数据.xlsx‘
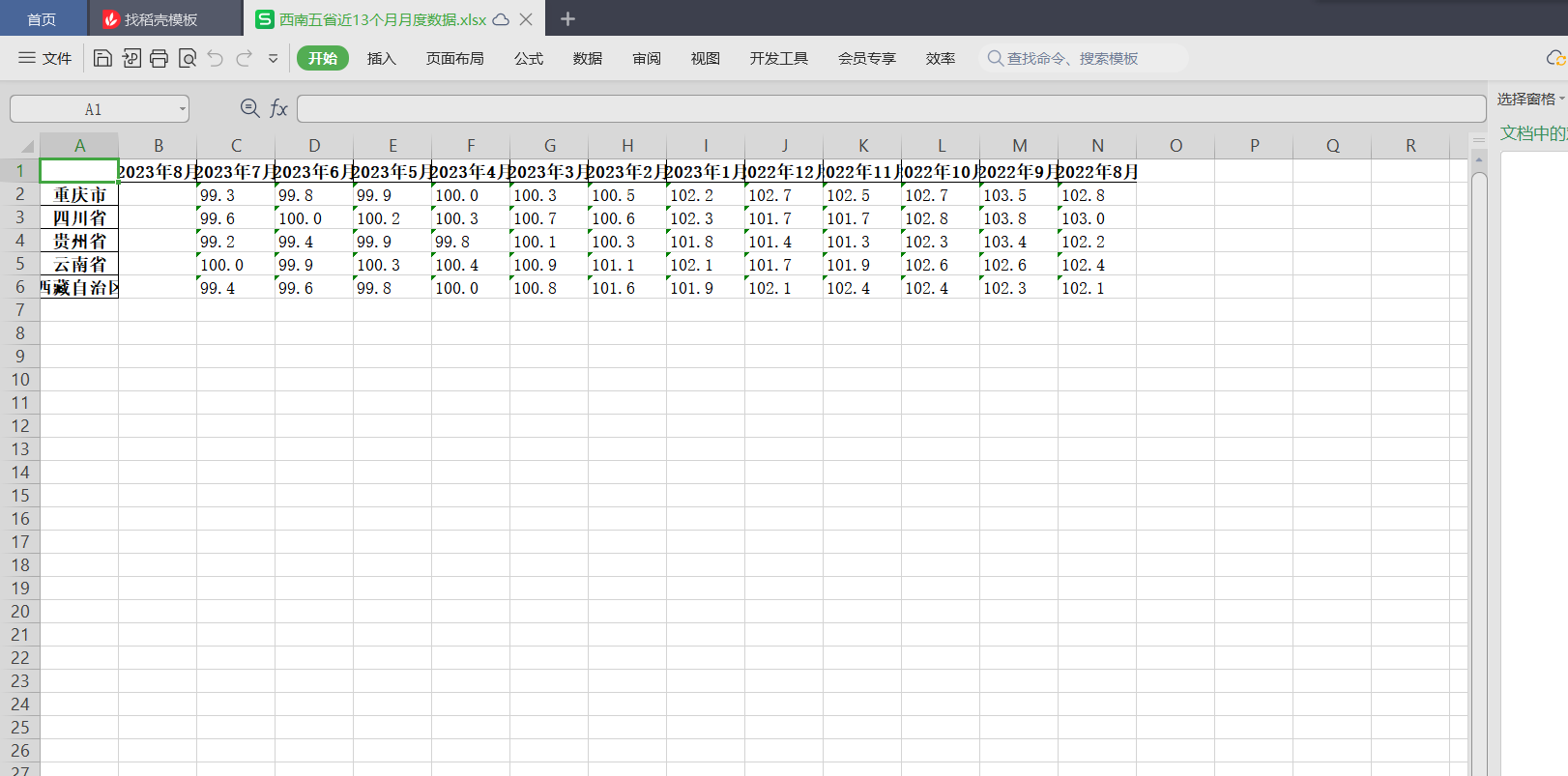

对数据进行清洗和处理
1 #读取数据表格 2 data=pd.read_excel('西南五省近13个月月度数据.xlsx',index_col=0) 3 #对数据进行清洗和处理 4 data.drop ('2023年8月', axis=1, inplace=True) #2023年8月是没有数值的,可以予以删除 5 data.fillna(method='ffill',inplace=True) #填补缺失值 6 data.to_excel('西南五省近13个月月度数据(处理后).xlsx',index=True)
文本分析
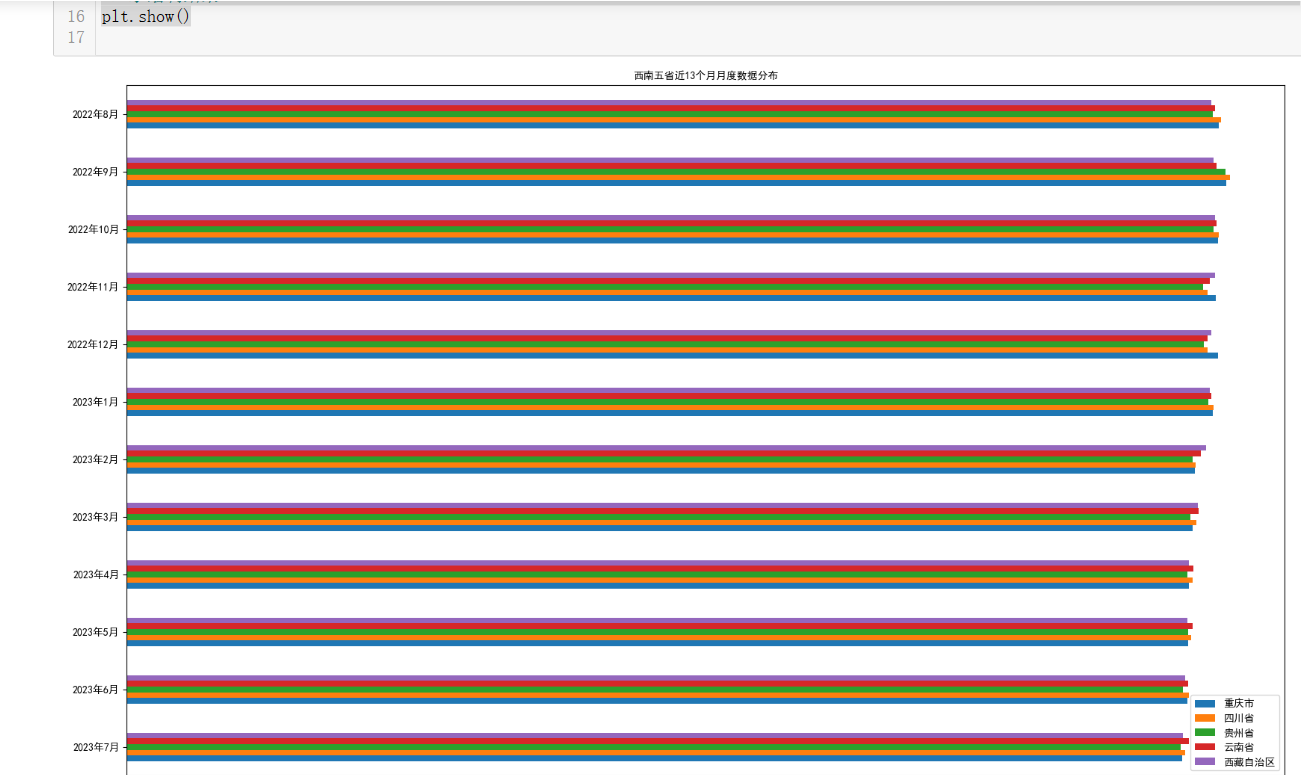
1 #读取数据表格 2 data=pd.read_excel('西南五省近13个月月度数据(处理后).xlsx',index_col=0) 3 import matplotlib.pyplot as plt 4 from pylab import mpl 5 import matplotlib 6 # 设置显示中文字体 7 mpl.rcParams["font.sans-serif"] = ["SimHei"] 8 #进行GDP排名,绘制柱形图 9 Font = {'family':'SimHei', 10 'weight':'bold', 11 'size':'12'} 12 #绘制柱状图,默认使用index作为横坐标 13 data.T.plot(kind='barh',figsize=(20,12)) 14 plt.title('西南五省近13个月月度数据分布',fontproperties='simhei') #设置标题 15 plt.xticks(fontproperties='simhei') #设置横坐标的字体 16 plt.legend() #显示图例 17 #显示绘制结果 18 plt.show()
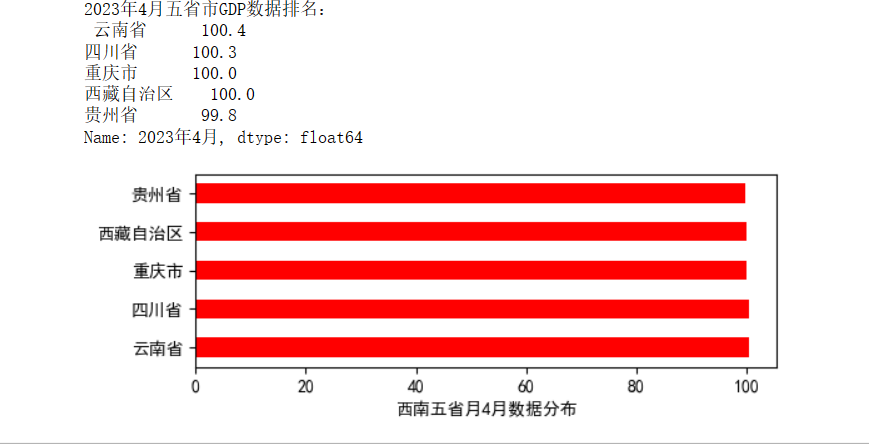
提取2023年4月份数据并排名
1 data_deal=data.loc[:,'2023年4月'] #筛选月份 2 data_deal_new=data_deal.copy() #复制 3 data_deal_new.sort_values(ascending = False,inplace=True) #排名 4 print('2023年4月五省市GDP数据排名:\n',data_deal_new) #输出 5 data_deal_new.plot(kind='barh',figsize=(6,2),color='r') #画图 6 plt.title('西南五省月4月数据分布',fontproperties='simhei') #设置标题 7 plt.xticks(fontproperties='simhei') #字体 8 #显示绘制结果 9 plt.show()
数据分析和可视化
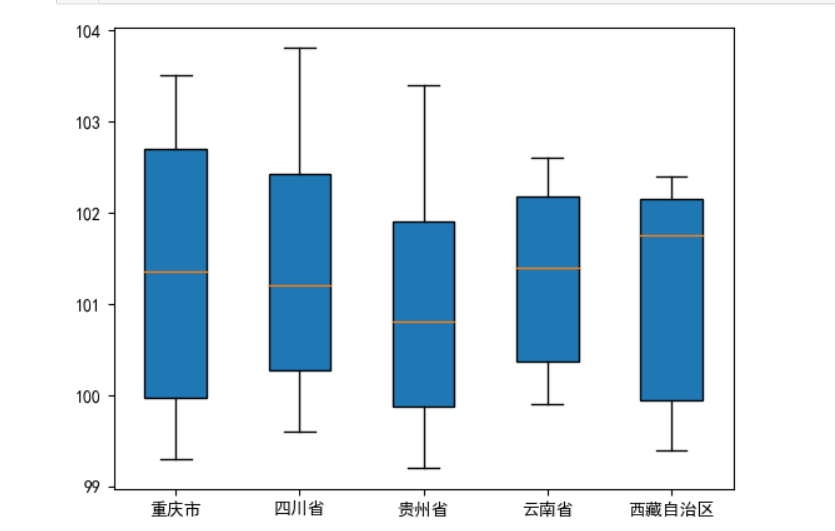
以五省市省GDP为例分析分布情况
1 import matplotlib.pyplot as plt 2 fig, ax = plt.subplots() # 子图 3 ax.boxplot(data.T,patch_artist = True) #画箱型图 4 ax.set_xticklabels(data.index) # 设置x轴刻度标签 5 plt.show() #显示图
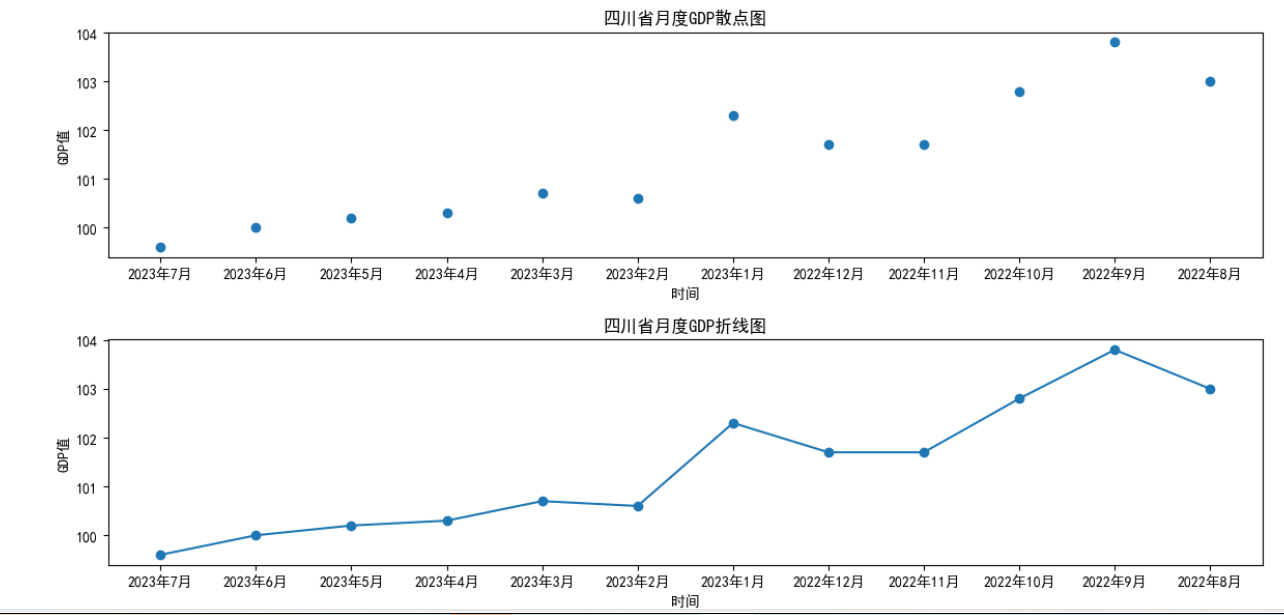
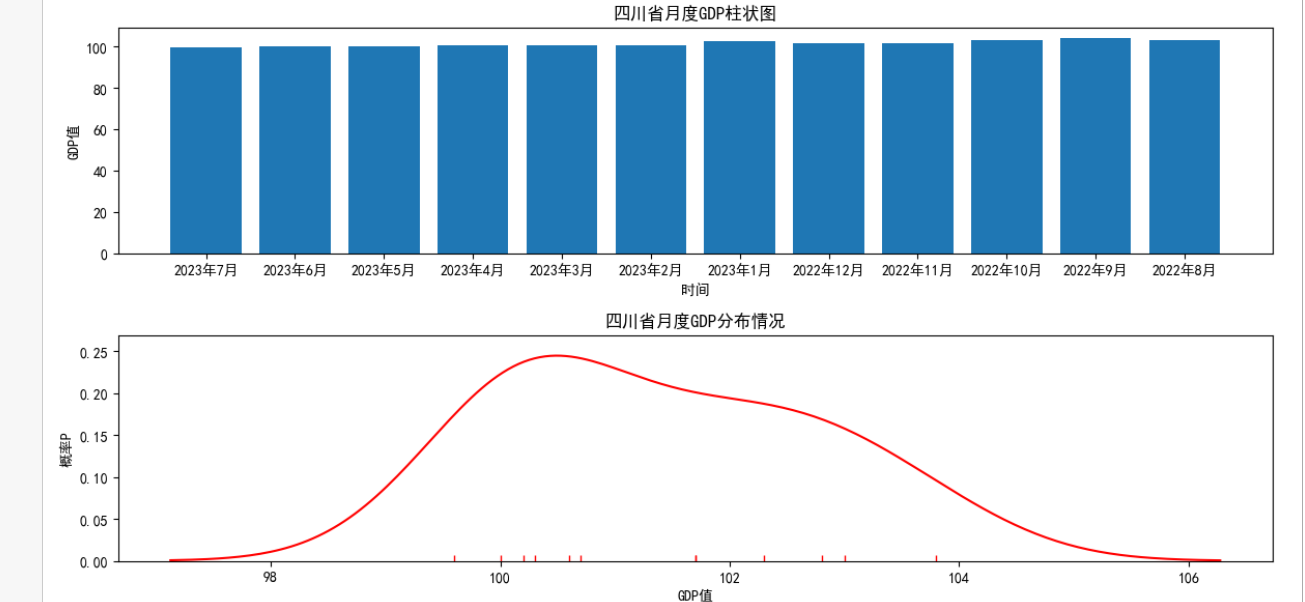
1 import seaborn as sns 2 #以四川省为例,提取四川省的数据并画变化趋势图 3 data_sichuan=data.loc['四川省',:] #筛选四川省数据 4 fig = plt.figure(figsize=(12,12)) #构建大图 5 ax1 = fig.add_subplot(4,1,1) #构建四个子图 6 ax2 = fig.add_subplot(4,1,2) 7 ax3=fig.add_subplot(4,1,3) 8 ax4=fig.add_subplot(4,1,4) 9 #设置图表1题和坐标轴标题 10 ax1.set_title("四川省月度GDP散点图") #散点图标题 11 ax1.set_xlabel('时间') #横坐标 12 ax1.set_ylabel('GDP值') #纵坐标 13 ax1.plot(data_sichuan.index,data_sichuan.values,"o") #点 14 #设置图表2题和坐标轴标题 15 ax2.set_title("四川省月度GDP折线图") #折线图标题 16 ax2.set_xlabel('时间') #横坐标 17 ax2.set_ylabel('GDP值') #纵坐标 18 ax2.plot(data_sichuan.index,data_sichuan.values,"-o") #点线 19 #设置图表3题和坐标轴标题 20 ax3.set_title("四川省月度GDP柱状图") #柱状图标题 21 ax3.set_xlabel('时间') #横坐标 22 ax3.set_ylabel('GDP值') #纵坐标 23 ax3.bar(data_sichuan.index,data_sichuan.values) 24 #设置图表4题和坐标轴标题 25 ax4.set_title('四川省月度GDP分布情况') #概率分布图标题 26 ax4.set_xlabel('GDP值') #横坐标 27 ax4.set_ylabel('概率P') #纵坐标 28 sns.distplot(data_sichuan.values,color='r', rug=True, hist= False,ax=ax4) 29 plt.tight_layout() #调整图间距 30 #显示图形 31 plt.show()
四川省和重庆市GDP数据对比
1 fig = plt.figure(figsize=(12,12)) #构建大图 2 ax1 = fig.add_subplot(2,1,1) #构建两个子图 3 ax2 = fig.add_subplot(2,1,2) 4 #设置图表1题和坐标轴标题 5 ax1.set_title("四川省与重庆市月度GDP折线图对比") #散点图标题 6 ax1.set_xlabel('时间') #横坐标 7 ax1.set_ylabel('GDP值') #纵坐标 8 ax1.plot(data_chongqing.index,data_chongqing.values,"-o",label='重庆') #点 9 ax1.plot(data_sichuan.index,data_sichuan.values,"-o",label='四川') #点 10 ax1.legend() 11 # #设置图表2题和坐标轴标题 12 ax2.set_title("四川省与重庆市月度GDP分布情况对比图") #折线图标题 13 ax2.set_xlabel('时间') #横坐标 14 ax2.set_ylabel('GDP值') #纵坐标 15 sns.distplot(data_chongqing.values, rug=True, hist= False,ax=ax2,label='重庆市') 16 sns.distplot(data_sichuan.values, rug=True, hist= False,ax=ax2,label='四川省') 17 ax2.legend() 18 plt.tight_layout() #调整图间距 19 #显示图形 20 plt.show()
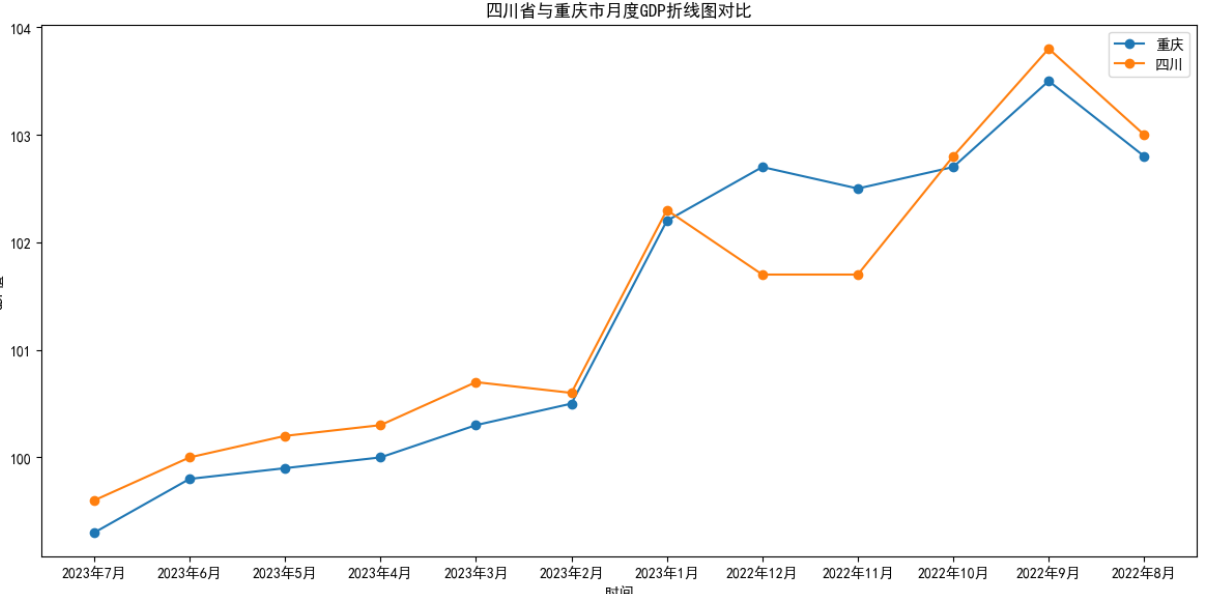
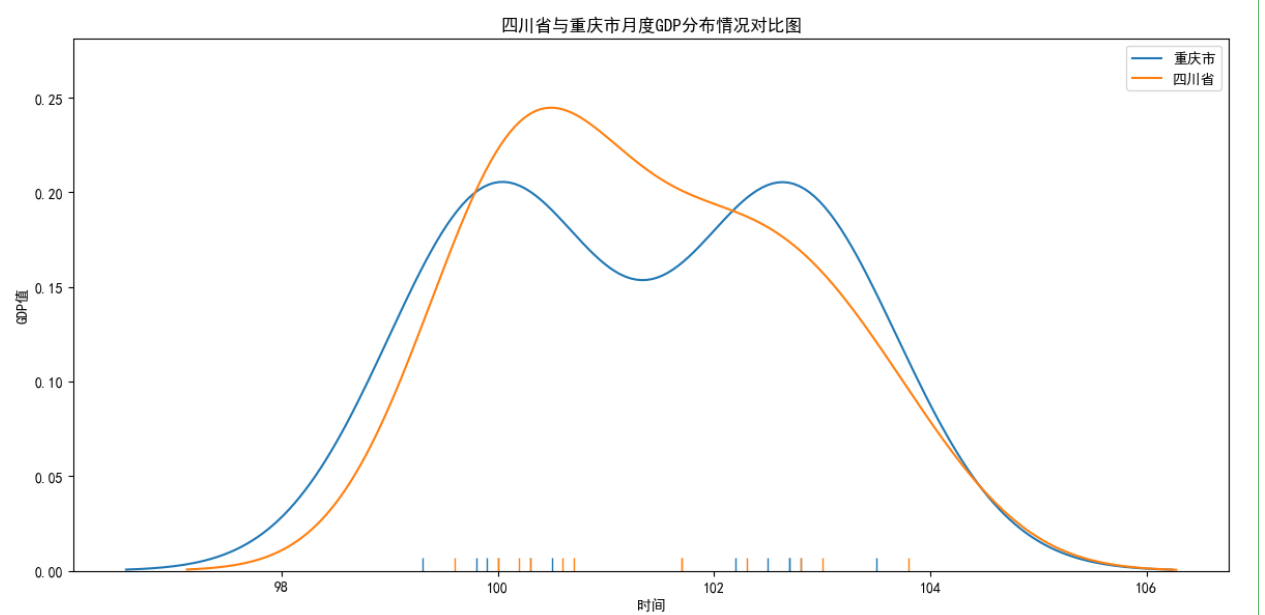
可以看出四川近13个月GDP略低于重庆
机器学习
对相似城市聚类
1 from sklearn.cluster import KMeans 2 from sklearn import preprocessing 3 # 建立模型 设置为3个簇 4 k_model = KMeans(n_clusters=3) 5 # 数据归一化 6 min_max_scaler = preprocessing.MinMaxScaler() 7 train_x = min_max_scaler.fit_transform(df) 8 # 训练模型 9 k_model.fit(train_x) 10 predict_y = k_model.predict(train_x) 11 df["聚类"] = predict_y 12 print('第一类:') 13 print(df[df['聚类']==0].index) 14 print('第二类:') 15 print(df[df['聚类']==1].index) 16 print('第三类:') 17 print(df[df['聚类']==2].index)

预测未来的趋势以四川省为例
1 from sklearn.linear_model import LinearRegression 2 #时间窗函数 3 def window(data_,side=3): 4 X=[] 5 y=[] 6 for i in range(len(data_)-side): 7 X.append([data_[i],data_[i+1]]) 8 y.append(data_[i+2]) 9 return X,y 10 11 # 生成随机回归训练数据集 12 data_need=data_sichuan.values 13 X,y=window(data_sichuan.values) 14 # 拟合模型 15 model = LinearRegression() 16 model.fit(X, y) 17 # 开始预测 18 #8月份 19 ynew = model.predict([[data_need[len(data_need)-2],data_need[len(data_need)-1]]]) 20 print('四川省2023年8月份值预测',ynew[0]) 21 #9月份 22 ynew_1=model.predict([[data_need[len(data_need)-1],ynew[0]]]) 23 print('四川省2023年9月份值预测',ynew_1[0]) 24 #10月份 25 ynew_2=model.predict([[ynew[0],ynew_1[0]]]) 26 print('四川省2023年10月份值预测',ynew_2[0])

三,总代码
1 #导入需要的包 2 import requests #访问请求 3 import re 4 import time 5 import selenium.webdriver as web 6 import xlwt 7 import os 8 import copy 9 import requests 10 import numpy as np 11 import pandas as pd 12 from bs4 import BeautifulSoup 13 import time 14 import json 15 import matplotlib.pyplot as plt 16 from pylab import mpl 17 import matplotlib 18 import seaborn as sns 19 #忽略警告 20 import warnings 21 warnings.filterwarnings("ignore") 22 23 #爬虫部分 24 #生成时间戳的函数 25 def getTime(): 26 return int(round(time.time() * 1000)) 27 28 #逐行读取数据的函数 29 def getList(l): 30 List=[] 31 for i in range(l): 32 try: 33 List.append(eval(js['returndata']['datanodes'][i]['data']['strdata'])) 34 except SyntaxError: 35 List.append('') 36 return List 37 38 #网址 39 url='https://data.stats.gov.cn/easyquery.htm?cn=E0101' 40 headers={'User-Agent':'Mozilla/5.0(Windows;U;Windows NT6.1;en-US;rv:1.9.1.6) Geko/20091201 Firefox/3.5.6'}#浏览器代理 41 #参数键值对 42 key={} 43 #网页部分的值 44 key['m']='QueryData' 45 key['dbcode']='fsyd' 46 key['rowcode']='reg' 47 key['colcode']='sj' 48 key['wds']='[{"wdcode":"zb","valuecode":"A01010101"}]' 49 key['dfwds']='[{"wdcode":"sj","valuecode":"LAST13"}]' 50 key['k1']=str(getTime()) 51 #读取文件 52 r=requests.get(url,headers=headers,params=key,verify=False) 53 #存入json文件 54 js=json.loads(r.text) 55 #查询json文件长度 56 length=len(js['returndata']['datanodes']) 57 #根据每行数据得到整体的数据 58 lst=getList(length) 59 #转换成9*13的格式 60 array=np.array(lst).reshape(31,13) 61 #保存为df格式 62 df=pd.DataFrame(array) 63 #重新写坐标值 64 df.columns=[ '2023年8月','2023年7月','2023年6月','2023年5月', 65 '2023年4月','2023年3月','2023年2月','2023年1月', 66 '2022年12月','2022年11月','2022年10月','2022年9月','2022年8月'] 67 df.index=['北京市','天津市','河北省','山西省','内蒙古自治区', 68 '辽宁省','吉林省','黑龙江省','上海市','江苏省','浙江省', 69 '安徽省','福建省','江西省','山东省','河南省','湖北省','湖南省', 70 '广东省','广西壮族自治区','海南省','重庆市','四川省','贵州省','云南省', 71 '西藏自治区','陕西省','甘肃省','青海省','宁夏回族自治区','新疆维吾尔自治区'] 72 73 #筛选目的5省份 74 df_new=df.loc[['重庆市','四川省','贵州省','云南省','西藏自治区']] 75 #坐标轴 76 df_new.columns=[ '2023年8月','2023年7月','2023年6月','2023年5月', 77 '2023年4月','2023年3月','2023年2月','2023年1月','2022年12月', 78 '2022年11月','2022年10月','2022年9月','2022年8月'] 79 #将数据保存到excel 80 df_new.to_excel('西南五省近13个月月度数据.xlsx',index=True) #存入excel表格,命名为’西南五省近13个月月度数据.xlsx‘ 81 df.drop('2023年8月', axis=1, inplace=True) 82 83 #数据清洗与预处理 84 #读取数据表格 85 data=pd.read_excel('西南五省近13个月月度数据.xlsx',index_col=0) 86 #对数据进行清洗和处理 87 #2023年8月是没有数值的,可以予以删除 88 data.drop ('2023年8月', axis=1, inplace=True) 89 data.fillna(method='ffill',inplace=True) #填补缺失值 90 data.to_excel('西南五省近13个月月度数据(处理后).xlsx',index=True) 91 92 #文本分析与排名 93 #读取数据表格 94 data=pd.read_excel('西南五省近13个月月度数据(处理后).xlsx',index_col=0) 95 # 设置显示中文字体 96 mpl.rcParams["font.sans-serif"] = ["SimHei"] 97 #进行GDP排名,绘制柱形图 98 Font = {'family':'SimHei', 99 'weight':'bold', 100 'size':'12'} 101 #绘制柱状图,默认使用index作为横坐标 102 data.T.plot(kind='barh',figsize=(20,12)) 103 plt.title('西南五省近13个月月度数据分布',fontproperties='simhei') #设置标题 104 plt.xticks(fontproperties='simhei') #设置横坐标的字体 105 plt.legend() #显示图例 106 #显示绘制结果 107 plt.show() 108 109 #提取2023年4月份数据并排名 110 data_deal=data.loc[:,'2023年4月'] #筛选月份 111 data_deal_new=data_deal.copy() #复制 112 data_deal_new.sort_values(ascending = False,inplace=True) #排名 113 print('2023年4月五省市GDP数据排名:\n',data_deal_new) #输出 114 data_deal_new.plot(kind='barh',figsize=(6,2),color='r') #画图 115 plt.title('西南五省月4月数据分布',fontproperties='simhei') #设置标题 116 #字体 117 plt.xticks(fontproperties='simhei') 118 #显示绘制结果 119 plt.show() 120 121 #数据分析与可视化部分 122 #以五省市省GDP为例分析分布情况 123 import matplotlib.pyplot as plt 124 fig, ax = plt.subplots() # 子图 125 ax.boxplot(data.T,patch_artist = True) #画箱型图 126 ax.set_xticklabels(data.index) # 设置x轴刻度标签 127 plt.show() #显示图 128 129 #以四川省为例,提取四川省的数据并画变化趋势图 130 data_sichuan=data.loc['四川省',:] #筛选四川省数据 131 fig = plt.figure(figsize=(12,12)) #构建大图 132 ax1 = fig.add_subplot(4,1,1) #构建四个子图 133 ax2 = fig.add_subplot(4,1,2) 134 ax3=fig.add_subplot(4,1,3) 135 ax4=fig.add_subplot(4,1,4) 136 #设置图表1题和坐标轴标题 137 ax1.set_title("四川省月度GDP散点图") #散点图标题 138 ax1.set_xlabel('时间') #横坐标 139 ax1.set_ylabel('GDP值') #纵坐标 140 ax1.plot(data_sichuan.index,data_sichuan.values,"o") #点 141 #设置图表2题和坐标轴标题 142 ax2.set_title("四川省月度GDP折线图") #折线图标题 143 ax2.set_xlabel('时间') #横坐标 144 ax2.set_ylabel('GDP值') #纵坐标 145 ax2.plot(data_sichuan.index,data_sichuan.values,"-o") #点线 146 #设置图表3题和坐标轴标题 147 ax3.set_title("四川省月度GDP柱状图") #柱状图标题 148 ax3.set_xlabel('时间') #横坐标 149 ax3.set_ylabel('GDP值') #纵坐标 150 ax3.bar(data_sichuan.index,data_sichuan.values) 151 #设置图表4题和坐标轴标题 152 ax4.set_title('四川省月度GDP分布情况') #概率分布图标题 153 ax4.set_xlabel('GDP值') #横坐标 154 ax4.set_ylabel('概率P') #纵坐标 155 sns.distplot(data_sichuan.values,color='r', rug=True, hist= False,ax=ax4) 156 plt.tight_layout() #调整图间距 157 #显示图形 158 plt.show() 159 160 #以重庆市为例,提取重庆市的数据并画变化趋势图 161 data_chongqing=data.loc['重庆市',:] #筛选重庆市数据 162 fig = plt.figure(figsize=(12,12)) #构建大图 163 ax1 = fig.add_subplot(4,1,1) #构建四个子图 164 ax2 = fig.add_subplot(4,1,2) 165 ax3=fig.add_subplot(4,1,3) 166 ax4=fig.add_subplot(4,1,4) 167 #设置图表1题和坐标轴标题 168 ax1.set_title("重庆市月度GDP散点图") #散点图标题 169 ax1.set_xlabel('时间') #横坐标 170 ax1.set_ylabel('GDP值') #纵坐标 171 ax1.plot(data_chongqing.index,data_chongqing.values,"o") #点 172 #设置图表2题和坐标轴标题 173 ax2.set_title("重庆市月度GDP折线图") #折线图标题 174 ax2.set_xlabel('时间') #横坐标 175 ax2.set_ylabel('GDP值') #纵坐标 176 ax2.plot(data_chongqing.index,data_chongqing.values,"-o") #点线 177 #设置图表3题和坐标轴标题 178 ax3.set_title("重庆市月度GDP柱状图") #柱状图标题 179 ax3.set_xlabel('时间') #横坐标 180 ax3.set_ylabel('GDP值') #纵坐标 181 ax3.bar(data_chongqing.index,data_chongqing.values) 182 #设置图表4题和坐标轴标题 183 ax4.set_title('重庆市月度GDP分布情况') #概率分布图标题 184 ax4.set_xlabel('GDP值') #横坐标 185 ax4.set_ylabel('概率P') #纵坐标 186 sns.distplot(data_chongqing.values,color='r', rug=True, hist= False,ax=ax4) 187 plt.tight_layout() #调整图间距 188 #显示图形 189 plt.show() 190 191 #四川省和重庆市GDP数据对比 192 # 构建大图 193 fig = plt.figure(figsize=(12,12)) 194 #构建两个子图 195 ax1 = fig.add_subplot(2,1,1) 196 ax2 = fig.add_subplot(2,1,2) 197 #设置图表1题和坐标轴标题 198 ax1.set_title("四川省与重庆市月度GDP折线图对比") 199 #散点图标题 200 ax1.set_xlabel('时间') #横坐标 201 ax1.set_ylabel('GDP值') #纵坐标 202 ax1.plot(data_chongqing.index,data_chongqing.values,"-o",label='重庆') #点 203 ax1.plot(data_sichuan.index,data_sichuan.values,"-o",label='四川') #点 204 ax1.legend() 205 # #设置图表2题和坐标轴标题 206 ax2.set_title("四川省与重庆市月度GDP分布情况对比图") #折线图标题 207 ax2.set_xlabel('时间') #横坐标 208 ax2.set_ylabel('GDP值') #纵坐标 209 sns.distplot(data_chongqing.values, rug=True, hist= False,ax=ax2,label='重庆市') 210 sns.distplot(data_sichuan.values, rug=True, hist= False,ax=ax2,label='四川省') 211 ax2.legend() 212 #调整图间距 213 plt.tight_layout() 214 #显示图形 215 plt.show() 216 217 #机器学习 218 # 对相似城市聚类 219 from sklearn.cluster import KMeans 220 from sklearn import preprocessing 221 # 建立模型 设置为3个簇 222 k_model = KMeans(n_clusters=3) 223 # 数据归一化 224 min_max_scaler = preprocessing.MinMaxScaler() 225 #归一化 226 train_x = min_max_scaler.fit_transform(df) 227 # 训练模型 228 k_model.fit(train_x) 229 predict_y = k_model.predict(train_x) 230 df["聚类"] = predict_y 231 print('第一类:') 232 print(df[df['聚类']==0].index) 233 print('第二类:') 234 print(df[df['聚类']==1].index) 235 print('第三类:') 236 print(df[df['聚类']==2].index) 237 238 # 预测未来的趋势 239 # 线性回归预测案例 240 # 导入相关方法 241 from sklearn.linear_model import LinearRegression 242 #时间窗函数 243 def window(data_,side=3): 244 #时间步为2 245 X=[] 246 y=[] 247 #每个3个一循环 248 for i in range(len(data_)-side): 249 X.append([data_[i],data_[i+1]]) 250 y.append(data_[i+2]) 251 return X,y 252 253 # 生成随机回归训练数据集 254 data_need=data_sichuan.values 255 #划分X,y 256 X,y=window(data_sichuan.values) 257 # 拟合模型 258 model = LinearRegression() 259 model.fit(X, y) 260 # 开始预测 261 #8月份 262 ynew = model.predict([[data_need[len(data_need)-2],data_need[len(data_need)-1]]]) 263 print('线性回归预测结果') 264 print('四川省2023年8月份值预测',ynew[0]) 265 #9月份 266 ynew_1=model.predict([[data_need[len(data_need)-1],ynew[0]]]) 267 print('四川省2023年9月份值预测',ynew_1[0]) 268 #10月份 269 ynew_2=model.predict([[ynew[0],ynew_1[0]]]) 270 print('四川省2023年10月份值预测',ynew_2[0]) 271 272 # 预测未来的趋势 273 #随机森林模型预测 274 from sklearn.ensemble import RandomForestRegressor 275 # 拟合模型 276 model_rf = RandomForestRegressor() 277 model_rf.fit(X, y) 278 # 开始预测 279 #8月份 280 ynew = model_rf.predict([[data_need[len(data_need)-2],data_need[len(data_need)-1]]]) 281 print('随机森林预测结果') 282 print('四川省2023年8月份值预测',ynew[0]) 283 #9月份 284 ynew_1=model_rf.predict([[data_need[len(data_need)-1],ynew[0]]]) 285 print('四川省2023年9月份值预测',ynew_1[0]) 286 #10月份 287 ynew_2=model_rf.predict([[ynew[0],ynew_1[0]]]) 288 print('四川省2023年10月份值预测',ynew_2[0]) 289 290 #svr预测 291 from sklearn.svm import SVR 292 # 拟合模型 293 model_svr= SVR() 294 model_svr.fit(X, y) 295 # 开始预测 296 #8月份 297 ynew = model_svr.predict([[data_need[len(data_need)-2],data_need[len(data_need)-1]]]) 298 print('SVR预测结果') 299 print('四川省2023年8月份值预测',ynew[0]) 300 #9月份 301 ynew_1=model_svr.predict([[data_need[len(data_need)-1],ynew[0]]]) 302 print('四川省2023年9月份值预测',ynew_1[0]) 303 #10月份 304 ynew_2=model_svr.predict([[ynew[0],ynew_1[0]]]) 305 print('四川省2023年10月份值预测',ynew_2[0])
四,总结
1.
经过众多数据对比不难看出,西南五省居民消费指数在疫情后任然稳定上升。
消费直接关系到经济发展和民生改善。要把扩大消费同改善人民生活品质结合起来,适应不同收入群体实际需要,以高质量供给提高居民消费意愿。支持刚性和改善性住房需求、促进文娱体育会展消费、提升健康服务消费等,都事关民生。在扩大消费中持续不断改善民生,既能有效解决群众后顾之忧,又可以催生新的经济增长点。实现扩大消费和民生改善良性循环,就能在发展中不断增进民生福祉,为经济发展创造出更多有效需求。但与沿海地区省份相比,仍任重而道远。
2.
在爬取的过程中,自己对HTML的解析还不是很懂,国家统计局网站使用了一些反爬虫机制,比如IP限制、验证码等,这部分还是请教了学长协助我完成,
认识到了对数据处理和清洗的重要性,爬取的时候会出现缺失值、错误数据等等问题,需要对其进行数据清洗和整理
爬虫过程中遇到了网络连接问题,程序报错等异常情况,但最后还是顺利完成了